【C++入门篇】保姆级教程篇【上】
目录
一、第一个C++程序
二、C++命名空间
1)什么是命名空间?
2)命名空间的使用
3) std库与namespace展开
4)命名空间的嵌套使用
三、输入输出方式
四、缺省参数
1)什么是缺省参数?
2)多个缺省值的缺省参数
五、函数重载
1)什么是函数重载?
2)为什么C++可以用函数重载?
六、C++引用与指针
1)什么是引用?
2)引用的规则特点:
1、引用必须初始化才能用
2、引用不能传空指针
编辑
3、一个变量或对象可以有多个别名
编辑
4、没有所谓的二级引用
编辑
5、引用不能改变指向
3)引用与指针的区别?
4)引用的使用
七、内联函数
1)什么是内联函数?
2)内联函数的特性
前言:
说到C++大家总会想到C语言,毕竟C++也就是C plus plus 么,没有错,C++在语法上是兼容C语言的。我们C++的祖师爷本贾尼·斯特劳斯特卢普在写C程序的时候对于C的一些语法规则感到不合适,于是祖师爷在C的基础上开发了这样一门语言。今天,我们就要开启C++世界的大门了。
一、第一个C++程序
说到学习新的语言,那就不得不写下人生中第一个C++程序了————你好,世界。
#include<iostream>using namespace std;int main()
{cout << "Hello World!\n";return 0;
}是不是有当年学C语言那味了,首先我们来分析一下是如何打印出来"Hello World!"。
我们在C语言中是用printf函数打印字符串的,在C++中是用cout(console out:控制台输出)来向控制台输出内容的,在C语言中printf函数对不同类型的数据有对应的输出格式访问控制符,像%d,%s...才会打印出对应类型的数据,而在C++中的cout会自动识别变量类型,相比之下写起来更加方便。
而在cout 后面跟着 '<<'叫做流插入限定符,表示在‘<<’右边的数据流向左边,cout << "hello world\n"; 就是将字符串信息流 流入到控制台当中打印。
那么知道了cout和流插入限定符就可以打印了吗?很遗憾告诉你,还是不行,这就要涉及到using namespace std;这条语句了,那这是什么意思呢?那个头文件也和C语言也不一样啊,又是什么意思呢?让我来一一为你介绍。
二、C++命名空间
1)什么是命名空间?
话说在祖师爷那个年代C语言是主流的高级语言,当然祖师爷也不例外,写项目也是用的C语言,其中祖师也在写大型项目的时候总会遇到这样一个问题:不同的程序员负责实现不同的模块,但是在最后整合的时候总是会有两个程序员用的变量或函数的名字相同。例如:
#include<iostream>
#include<stdio.h>//C语言中printf函数所需要的头文件int printf = 1;int main()
{printf("%d", printf);return 0;
} 这种命名冲突要改是很麻烦的,祖师爷经常被这个东西搞得头疼,所以祖师爷在开发C++的时候直接规定了一种关键字来避免这种情况————namespace(命名空间)
这种命名冲突要改是很麻烦的,祖师爷经常被这个东西搞得头疼,所以祖师爷在开发C++的时候直接规定了一种关键字来避免这种情况————namespace(命名空间)
命名空间就是使用 namespace + 空间名 在namespace内部会自动生成“一堵墙”, 这堵墙将namespace内部内容的命名与整个程序以及库里的程序隔开,互不影响,就像这个世界上不止一个人叫张三,但是他们并不是同一个人。
2)命名空间的使用
那么我们知道了命名空间,但是该如何使用呢?我们把可能会冲突的变量或者函数放进命名空间内,在外部想要调用命名空间内的内容就需要 ‘::’ 叫做域作用限定符,是访问namespace的专用符号,使用方法是:空间名::内部变量/函数等,例如下面代码:
#include<iostream>namespace byte{int printf = 1;}int main()
{std::cout << byte::printf;return 0; }  这样就可以输出printf这个变量了,就不会造成命名冲突的问题。
这样就可以输出printf这个变量了,就不会造成命名冲突的问题。
3) std库与namespace展开
有些时候我们在命名空间内的函数或者变量在外部要多次调用的情况,每次调用之前都要加上空间名和域作用限定符,也是一件挺麻烦的事情,例如:
#include<iostream>
#include<stdlib.h>
#include<string.h>
#include<assert.h>namespace byte{typedef int STDataType;typedef struct Stack{STDataType* _a;int _top; // 栈顶int _capacity; // 容量 }Stack;// 初始化栈 Stack* StackInit(STDataType n){Stack *p = (Stack *)malloc(sizeof(Stack));//...p -> _a = (STDataType *)malloc(sizeof(STDataType) * n);//...p -> _top = -1;p -> _capacity = n;return p;}// 入栈 void StackPush(Stack* ps, STDataType data){assert(ps);//...ps -> _a[++ps -> _top] = data;return;}// 出栈 void StackPop(Stack* ps){assert(ps);if(ps -> _top > -1){ps -> _top -= 1;}return;}}void Test()
{byte::Stack *ps = byte::StackInit(5);byte::StackPush(ps, 1);byte::StackPush(ps, 1);byte::StackPush(ps, 1);byte::StackPush(ps, 1);byte::StackPop(ps);//...
}int main()
{Test();return 0; } 我们来模拟栈的实现(没有全部写出来),把栈的操作放在namespace里面在Test()中想要访问栈每次都需要在造作前面加上这么一些东西,写起来也很麻烦,所以祖师爷就规定了一种配套的关键字——using,使用方法是:using namespace 空间名;这样就可以展开命名空间,也就是打开那堵墙,在使用时就不需要加上前面那一大坨了,但这个时候就不能保证命名冲突了。
我们只需在命名空间下面加上这样一条语句:using namespace byte;
这样编译的效果和上面代码效果就是相同的了。
namespace还有一种局部展开的方式,将命名空间内的常用的变量或函数名局部展开,防止命名空间内的其他变量会与程序发生冲突,使用方法是:using 空间名::变量/函数名等 这样也是比较常用的展开方式。例如:
#include<iostream>
#include<stdlib.h>
#include<string.h>
#include<assert.h>namespace byte{typedef int STDataType;typedef struct Stack{STDataType* _a;int _top; // 栈顶int _capacity; // 容量 }Stack;// 初始化栈 Stack* StackInit(STDataType n){Stack *p = (Stack *)malloc(sizeof(Stack));//...p -> _a = (STDataType *)malloc(sizeof(STDataType) * n);//...p -> _top = -1;p -> _capacity = n;return p;}// 入栈 void StackPush(Stack* ps, STDataType data){assert(ps);//...ps -> _a[++ps -> _top] = data;return;}// 出栈 void StackPop(Stack* ps){assert(ps);if(ps -> _top > -1){ps -> _top -= 1;}return;}}using byte::StackPush;
using byte::StackPop;void Test()
{byte::Stack *ps = byte::StackInit(5);StackPush(ps, 1);StackPush(ps, 1);StackPush(ps, 1);StackPush(ps, 1);StackPop(ps);//...
}int main()
{Test();return 0; } 这样不经常使用的和命名冲突的就可以不展开使用了,常用的变量或函数就可以来展开使用,避免了不必要的麻烦。
想必你也发现了,我们在最开始打印hello world的时候发现有这样一条语句:using namespace std;实际上std也是一种命名空间,只不过std是C++库的命名空间,里面有很多用得到的函数模版等等,东西非常多,其中cout等也在std库内,所以使用的时候要展开命名空间。
值得注意的是,我们前面也说了,如果展开命名空间就不能保证命名冲突的问题了,而且std库内的的内容很多,保不准就会发生命名冲突,所以在写大型项目时最好不要展开std,但是在日常的练习中还是展开的。
4)命名空间的嵌套使用
我们在使用命名空间内容比较多的时候,也保不准命名空间内会出现命名冲突,所以C++就规定了可以允许命名空间嵌套命名空间,例如:
#include<iostream>namespace ptr{namespace spa1{int ptr = 1;}namespace spa2{int ptr = 2; }namespace spa3{int ptr = 3;}
}using std::cout;int main()
{cout << "spa1: " << ptr::spa1::ptr << std::endl;cout << "spa2: " << ptr::spa2::ptr << std::endl;cout << "spa3: " << ptr::spa3::ptr << std::endl;return 0;
}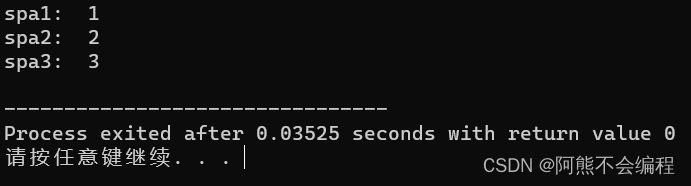 在C++的一些库里这种方式也很常见,但是嵌套太多层也是坑的很,还是谨慎使用嵌套功能为好。
在C++的一些库里这种方式也很常见,但是嵌套太多层也是坑的很,还是谨慎使用嵌套功能为好。
三、输入输出方式
C++的输出方式在最开始也已经提到了,cout:控制台输出,<<:流插入运算符。那么我们输出有了,我们输入呢?
在C语言中,我们输入的方式是调用<stdio.h>中的scanf函数来进行输入,与printf一样也需要输入格式访问控制符才能对输入数据类型进行判断。
在C++中,我们的输入为:cin(console in控制台输入),搭配'>>'(流提取运算符)使用,使用方式为:
std::cin >> 变量;//其中cin与cout一样会自动识别变量的类型
其中我们在使用输入输出的时候就需要包含头文件<iostream>也就是输入输出流文件,保证cout和cin的正常输入输出的使用。
其中cin和cout都是在std库内的,所以之前在使用的时候要展开std命名空间,这里在介绍一种C++中常用的换行符,不是'\n'而是叫做:endl(end line 结束行) 通常在cout结尾处使用,例如:
#include<iostream>int main()
{std::cout << "Hello World" << std::endl;return 0;
}其中endl也是内置在std库里的,这样写也是会有换行效果的。
到这里你可能还有一些疑问,我们如果想要对浮点数进行精度控制,C++是不是也有新的语法规则来写呢?很遗憾并没有,但是C++语法是兼容C的,所以如果想要对浮点数进行精度控制的时候,我们直接用printf函数进行精度控制就行。
四、缺省参数
1)什么是缺省参数?
祖师爷对C语言的函数部分也不是很满意,例如在栈的数据结构中,在栈的初始化期间,需要传参capacity容量来给栈开辟空间大小,在C语言中我们每次初始化时都需要给个值,祖师爷觉得有些麻烦,所以在C++里面出现了一个叫做缺省参数的语法规则,在函数传参时直接对参数进行赋值。
Stack *InitNewStack(int capacity = 3)
{//...
}这样在调用这个函数时,不传参数就默认capacity初始化为3, 传参就以传的参数为准。
那么什么是缺省参数呢?实际上,缺省参数是声明和定义函数时为函数的参数指定一个缺省值,在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
例如:
#include<iostream>using std::cout;
using std::cin;
using std::endl;void Func(int a = 0)
{cout << a << endl;
}int main()
{Func();//没有参数时使用形参默认值Func(1);//有参数时使用指定实参return 0;
}
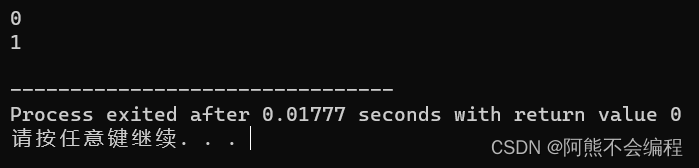
这就是缺省参数的具体用法。
2)多个缺省值的缺省参数
实际上,缺省参数可以有多个缺省值,而且在多个缺省值当中有着全缺省与半缺省之分。全缺省参数的函数在调用时没有传实参就会进行自动采用该参数的缺省值为参数,如果传参就以实参为参数,这点与上面的相同。
如果我们在全缺省函数传参传不完整参数会发生什么?我们不妨看以下代码:
#include<iostream>using std::cout;
using std::cin;
using std::endl;void Func(int a = 0, int b = 1, int c = 2)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}int main()
{Func();//不传参数cout << endl;Func(5);//传一个参数cout << endl;Func(5, 6);//传两个参数cout << endl;Func(5, 6, 7);//传三个参数cout << endl;return 0;
}
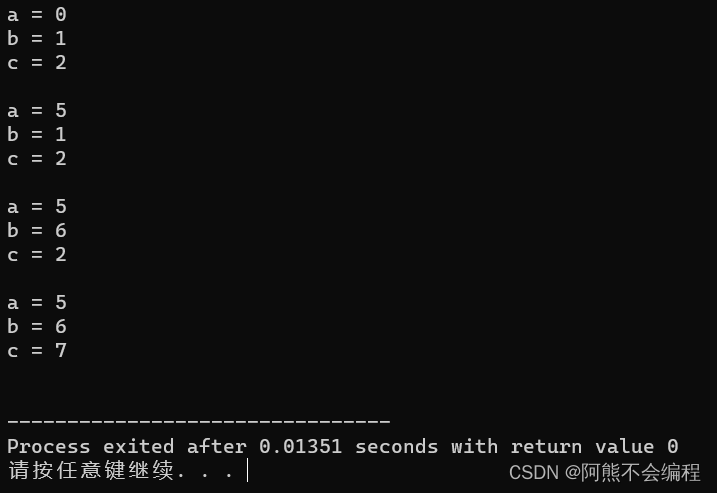
我们可以看到,全缺省参数的函数是可以传空参的,也可以传不完整的参数,同时,不知道聪明的你有没有发现,这里传参有个规律:当Func(5),Func(5, 6)的时候,Func(5)是将第一个参数初始化,后面两个参数为缺省值,Func(5, 6)是将前两个参数初始化,最后一个参数为缺省值。这其实就是祖师爷规定的默认传参顺序,对于全缺省函数传不完整参数,是从左到右进行传参的。
或许你又会有疑问,能不能前面不传参,后面传参?或者只有中间值传参?例如:
Func( , 6, 7); 或 Func( , 6 , );
实际上并不存在这种传参的方式,C++中这样是会报错的,所以缺省参数只能顺序传参。
还有一种叫做半缺省参数的函数,所谓半缺省就是函数参数一部分是缺省参数,一部分是普通参数,这类函数被称为半缺省参数函数,而且半缺省参数函数的缺省值只能从右往左给,例如:
#include<iostream>using std::cout;
using std::cin;
using std::endl;void Func(int a, int b = 1, int c = 2)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}int main()
{Func(0);cout << endl;Func(5);cout << endl;Func(5, 6);cout << endl;Func(5, 6, 7);cout << endl;return 0;
}
这个函数就是一个半缺省函数 ,a没有缺省值,只有b,c有缺省值,那么运行起来会发生什么事呢?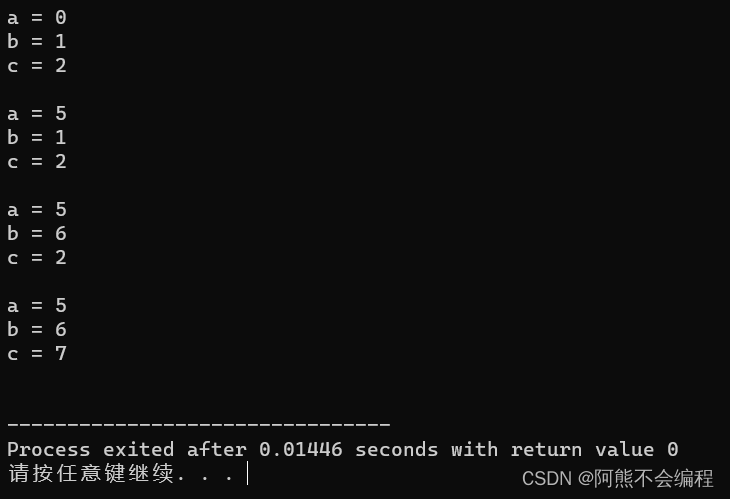
我们发现在Func(5, 6)中, 传的参数是依旧是从左往右进行传参的,既然如此,我们半缺省函数能不能缺省后边的值或者中间的值呢?
#include<iostream>using std::cout;
using std::cin;
using std::endl;void Func(int a = 0, int b, int c = 2)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}void Func2(int a = 0, int b = 1, int c)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}int main()
{return 0;
}
这种会发生什么情况? 我们发现这两种情况会报错,但是为什么会报错?报错信息显示形参缺少默认实参,也就是说,我们在传不完整参数的时候其实是不能确定你要传的是缺省参数还是普通形参,所以干脆C++把这种半缺省方式定义为错误的语法方式,最终半缺省函数传参只能从右往左进行缺省。
我们发现这两种情况会报错,但是为什么会报错?报错信息显示形参缺少默认实参,也就是说,我们在传不完整参数的时候其实是不能确定你要传的是缺省参数还是普通形参,所以干脆C++把这种半缺省方式定义为错误的语法方式,最终半缺省函数传参只能从右往左进行缺省。
注意:缺省参数函数的生命和定义不能同时出现缺省值,通常的做法是在声明时写缺省值,定义时默认不写。
五、函数重载
1)什么是函数重载?
祖师爷不仅对函数的参数有意见,对函数的命名也很有意见,有些功能相似的函数,或许只是参数不同,但是却要好几个不同的命名,像在函数名后面加1,2,3...用来区分不同的函数,其实也就是为了解决一词多义的问题,就例如网络段子“中国足球谁也赢不了,中国乒乓球谁也赢不了”,虽然都是赢不了,但是意义却不一样,祖师爷觉得这样很麻烦,不如干脆用同一个函数名得了,于是C++中出现了函数重载这一语法规则。
实际上,函数重载是函数的一种特殊情况,C++允许在同一个作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
函数重载又分为:1、参数类型不同。2、参数个数不同。3、参数顺序不同。代码如下:
#include<iostream>using namespace std;//1、参数类型不同
int f(int a, int b)
{cout << "f(int): " << a + b << endl; return a + b;
}double f(int a, double b)
{cout << "f(double): " << a + b << endl;return a + b;
}//2、个数不同
void f2(int index)
{cout << "f2(int index)" << endl;
}void f2()
{cout << "f2(NULL)" << endl;
}//3、顺序不同
void f3(int a, double b)
{cout << "f3(int, double)" << endl;
}void f3(double a, int b)
{cout << "f3(double, int)" << endl;
}int main()
{f(5, 5);f(3, 3.5);f2(0);f2();f3(4, 4.4);f3(4.4, 4);return 0;
}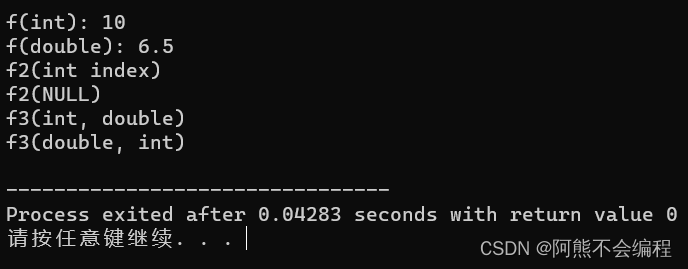 以上都是函数重载的方式的具体用法。
以上都是函数重载的方式的具体用法。
值得注意的是这里并没有说返回值不同而造成函数的重载,实际上仔细想想,如果两个函数都是相同的,只有返回值不一样,那么究竟是调用哪个函数呢?这就是造成重载的二义性的原因。
2)为什么C++可以用函数重载?
在学习完函数重载的过程中,有没有思考这样一个问题:为什么这么好用的东西C语言不支持呢?其实这里涉及到程序的编译与链接,实际上程序在从写下来到打印到控制台上需要经历预处理、编译、汇编、链接的几个过程,如果对于这几个过程没有一点概念的同学可以看看我的这篇文章:C语言预编译详解,可以稍微了解一些。
实际上,重载函数在编译生成汇编的过程中,C语言对于函数名并没有什么特殊的变化,但是C++在编译生成汇编的过程中函数名会生成某种符号规则来确定这个函数是否为重载。
六、C++引用与指针
我们在日常生活中身边的朋友不免有些外号,比如我的好朋友玩的好的都叫他‘小李子’,只听过小李在校园传奇故事的同学都叫他‘李哥’,那么这个李哥,和前面的小李,指的就是同一个人,而引用在语法层面上的理解就是,引用就是取别名。
1)什么是引用?
其实上面那个例子就已经能够说明什么是引用了,实际上,引用就是给变量取一个别名,编译器不会给它专门开一个空间,它与引用的变量共用同一块内存空间。
引用的格式如下:
类型& 引用变量名(对象名) = 引用实体;//左值引用
这里&符号左右可以带空格可以不带空格,没什么实际影响, 我们来看一下如何给一个引用:
#include<iostream>
#include<stdio.h>using namespace std;int main()
{int a = 0;int &b = a;//b是a的别名cout << "a:" << a << endl << "b:" << b << endl;printf("%p\n",a);printf("%p\n",b);return 0;
}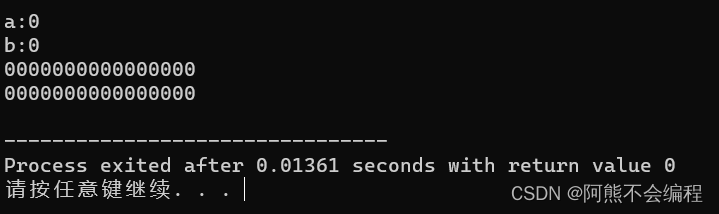 我们可以看到对于变量a,引用b是变量a的引用,变量b输出的内容是变量a的值,变量a与引用b都是指向同一片地址的。
我们可以看到对于变量a,引用b是变量a的引用,变量b输出的内容是变量a的值,变量a与引用b都是指向同一片地址的。
2)引用的规则特点:
1、引用必须初始化才能用
#include<iostream>
#include<stdio.h>using namespace std;int main()
{int a = 1;int &b;return 0;
} C++规定引用使用必须初始化。
C++规定引用使用必须初始化。
2、引用不能传空指针
#include<iostream>
#include<stdio.h>using namespace std;int main()
{int a = 1;int& b = nullptr;return 0;
}
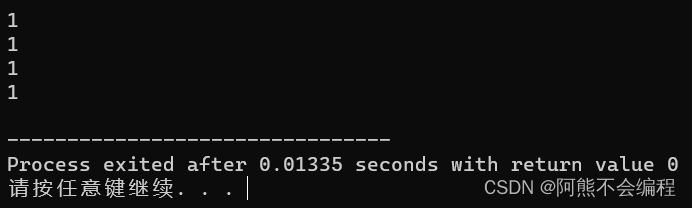
3、一个变量或对象可以有多个别名
#include<iostream>
#include<stdio.h>using namespace std;int main()
{int a = 1;int &b = a;int &c = a;int &d = a;cout << a << endl;cout << b << endl;cout << c << endl;cout << d << endl;return 0;
}
4、没有所谓的二级引用
#include<iostream>
#include<stdio.h>using namespace std;int main()
{int a = 1;int &b = a;int &&pb = b;return 0;
}
5、引用不能改变指向
#include<iostream>
#include<stdio.h>using namespace std;int main()
{int a = 1;int c = 2;int &b = a;int &b = c;return 0;
} 以上便是引用的一些规则的特点。
以上便是引用的一些规则的特点。
3)引用与指针的区别?
在汇编层面上来说,引用就是一个指针,但是不同的是,引用相当于常量指针,改变不了它所引用对象的地址。

在语法层面上来说:
1、引用是别名,指针存的是地址。
2、指针解引用要加上*,而引用是自动解引用的
3、引用不会分配空间,但是指针会分配空间
4、指针有空指针,但是引用没有空引用
5、指针运用自增运算符是指向下一位,而引用使用自增运算符是对内容+1
6、指针有多级指针,但是引用只有一级引用
7、对指针用sizeof是指针变量的大小,对引用sizeof是引用变量的大小
8、引用比指针更加安全
4)引用的使用
既然说到引用对象的地址不可改变,值可以变,对于指针来说,值和地都可以随意改变,他俩相比较下,引用对象的地址不可变,值可变,指针指向对象的地址可变,值也可变。当值不可变时又是什么情况呢?
#include<iostream>
#include<stdio.h>using namespace std;int main()
{const int a = 1;int &b = a;return 0;
}其实这个时候虽然a被加上了const变成了常量, 但是依然可以通过b对a的值进行修改,这种我们可以称之为权限放大,就是b的权限要高于a了,那么有权限放大就有权限缩小与平等权限,没错,实际上权限缩小就是对a不加任何修饰,对引用b加上const修饰,这样b不可修改,a却可以,平等权限就是两个变量前都加上const,这样就都不能改变了。
//权限缩小
int a = 0;
const int &b = a;
//权限平等
const int c = 0;
const int &d = c;引用还有什么作用?我们不妨以指针的视角看一下,指针除了可以作为指针变量,指针还可以传参,还可以作为返回值。那么我们引用是否也可以传参,作为返回值呢?
答案是可以的,而且引用做返回值在一定程度上会提高程序的运行效率。这是因为我们在传参数时实际上是拷贝一份实参传给形参的,而加上了引用就不需要在进行拷贝了,便可以直接访问内容。
而引用作为返回值也是比较奇怪的:
#include<iostream>
#include<stdio.h>using namespace std;int& Add(int a, int b)
{int c = a + b;return c;
}int main()
{int a = 1, b = 2;int ind = Add(a, b);cout << ind << endl;return 0;
} 首先,以引用作为返回值表示返回的ind是c的别名,这个就相当对在函数里返回一个局部指针,出了作用域就会销毁,但是现在的编译器都比较高级,可能会保留下来这个值,所以就能看到这个值是3,我们再看下面这段代码:
首先,以引用作为返回值表示返回的ind是c的别名,这个就相当对在函数里返回一个局部指针,出了作用域就会销毁,但是现在的编译器都比较高级,可能会保留下来这个值,所以就能看到这个值是3,我们再看下面这段代码:
#include<iostream>
#include<stdio.h>using namespace std;int &Add(int a, int b)
{int c = a + b;return c;
}int main()
{int ind = Add(5,5);cout << ind << endl;Add(3,4);cout << ind << endl;return 0;
}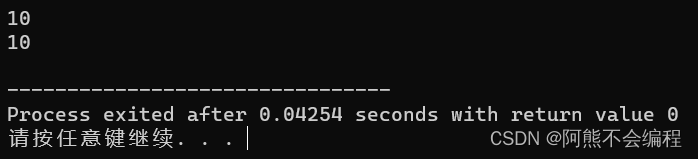
这里我们两次调用了Add这个函数,可是两次的值都是第一次调用的结果(语法规定除了作用域为随机值,这里是进行了优化),第一次调用后将调用的c拷贝了一份给了ind,这时他俩并不指向同一块空间,所以第二次调用时并不会影响ind的值。
但是我们想要正常运行且能多次调用呢?看看下面这段代码:
#include<iostream>
#include<stdio.h>using namespace std;int &Add(int a, int b)
{int c = a + b;return c;
}int main()
{int &ind = Add(5,5);cout << ind << endl;Add(3,4);cout << ind << endl;return 0;
}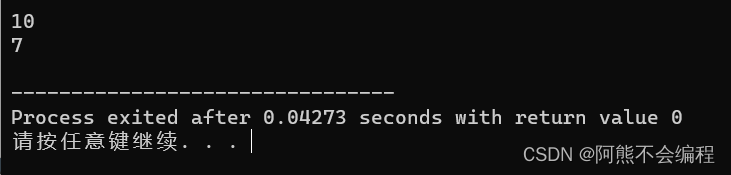 这里我们将ind为引用来接收引用的返回值,他们指向了同一块空间,多次调用时就不会是同一个结果了。
这里我们将ind为引用来接收引用的返回值,他们指向了同一块空间,多次调用时就不会是同一个结果了。
七、内联函数
1)什么是内联函数?
我们在C语言中其实有个很好用的东西————宏,但是学过C的都知道,宏很难用,虽然它写的程序运行很快,但是不能进行调试,特别容易出错,我们的祖师爷还是比较喜欢宏的,于是祖师爷去劣留优,也增加了一些新的规则,创建了一种新的关键字——inline关键字。
内联函数也就是普通函数前面加上inline关键字就变成了内联函数,内联函数本质上和宏一样,都是对文本进行替换,而且可以对函数进行调试,这样可以节省很多函数调用销毁的开销,但同时会让目标文件变大。
2)内联函数的特性
这个时候你可能就会说了,那以后每个函数都用inline关键字不香吗?实际上内联函数的适用场景是短小、多次重复调用的函数,因为内联本质上还是文本替换,全都进行展开的话编译器会吃不消,所以编译器默认最多你的函数在10行左右及以下,inline才会有效,否则就是个普通的函数。
内联函数的声明和定义不能分离,在预处理过程会进行文本替换,替换后函数的地址就找不到了,那么就会在运行时报错。
 创作不易,还望各位佬能多多三连【可怜】【可怜】~~
创作不易,还望各位佬能多多三连【可怜】【可怜】~~
相关文章:
【C++入门篇】保姆级教程篇【上】
目录 一、第一个C程序 二、C命名空间 1)什么是命名空间? 2)命名空间的使用 3) std库与namespace展开 4)命名空间的嵌套使用 三、输入输出方式 四、缺省参数 1)什么是缺省参数? 2࿰…...

用傲梅分区软件分割分区重启系统蓝屏BAD_SYSTEM_CONFIG_INFO,八个解决参考方案
环境: Win11 专业版 HP 笔记本 傲梅分区软件 闪迪16G U盘 Win10 官方镜像文件 Win11PE 系统安装U盘 USB固态硬盘盒 问题描述: 起因 开始使用windows自动磁盘管理工具压缩不了磁盘,提示无法将卷压缩到超出任何不可移动的文件所在点,关闭系统保护还原,删除系统创建…...

7-1、S曲线加减速原理【51单片机控制步进电机-TB6600系列】
摘要:本节介绍步进电机S曲线相关内容,总共分四个小节讨论步进电机S曲线相关内容 根据上节内容,步进电机每一段的速度可以任意设置,但是每一段的速度都会跳变,当这个跳变值比较大的时候,电机会发生明显的…...

golang 通過ssh連接遠程服務器 控制
1.下載依賴 go get golang.org/x/crypto/ssh 2.import import ("fmt""log""time""golang.org/x/crypto/ssh" )3.使用 func pwdConnect(sshHost, sshUser, sshPassword string, sshPort int) (*ssh.Client, error) {// 创建ssh登录…...
Python深度学习实战-基于tensorflow.keras六步法搭建神经网络(附源码和实现效果)
实现功能 第一步:import tensorflow as tf:导入模块 第二步:制定输入网络的训练集和测试集 第三步:tf.keras.models.Sequential():搭建网络结构 第四步:model.compile():配置训练方法 第五…...

单片机核心/RTOS必备 (ARM汇编)
ARM汇编概述 一开始,ARM公司发布两类指令集: ARM指令集,这是32位的,每条指令占据32位,高效,但是太占空间。Thumb指令集,这是16位的,每条指令占据16位,节省空间。 要节…...

2023/10/25
如果你越来越冷漠 你以为你成长了 但其实没有 长大应该是变得温柔 对全世界都温柔...
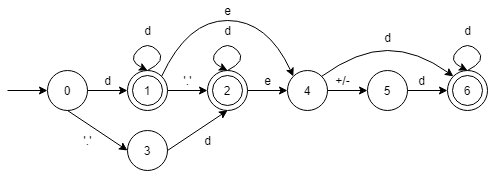
如何做一个无符号数识别程序
1.状态分析 我们可以把无符号数分为:整数,带小数,带指数部分三种形式。以此构建一个DFA。首先需识别输入是整数还是小数点,若是整数部分输入然后还要再循环识别一次是否有小数点,最后识别是否有指数部分,指…...
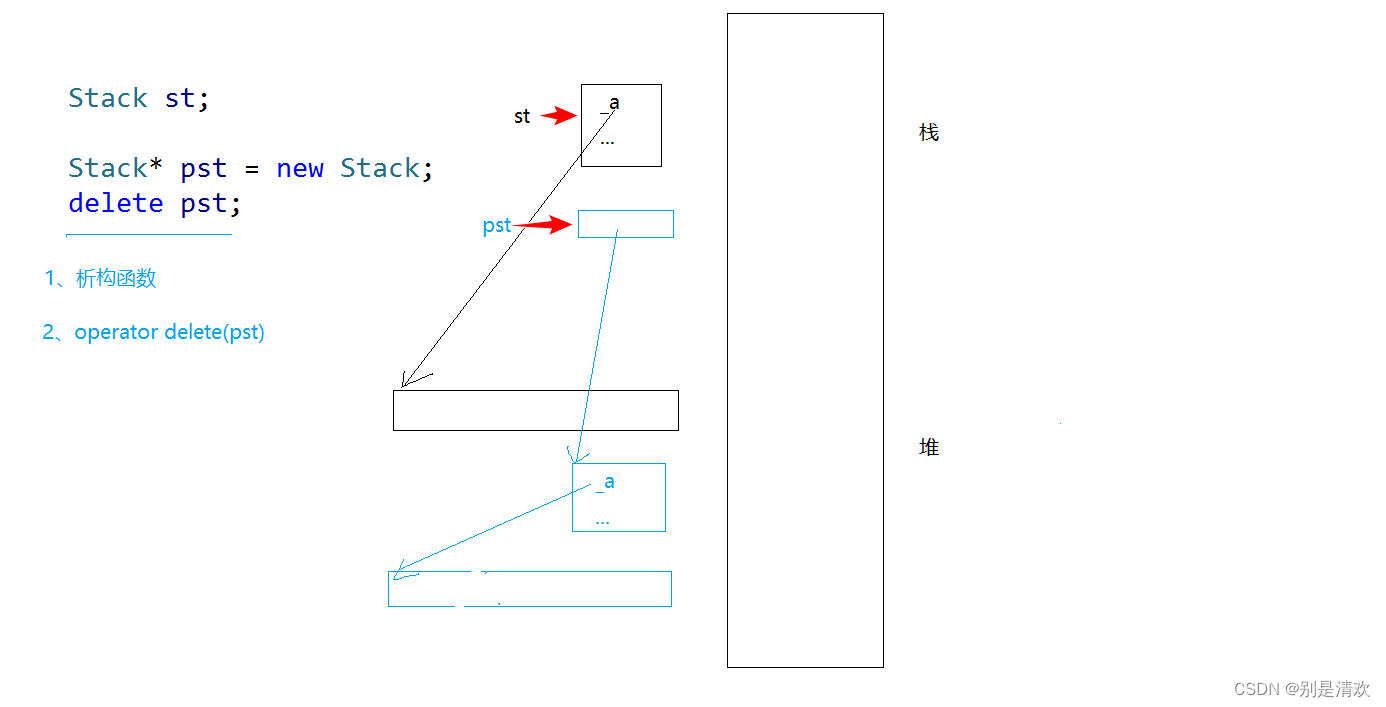
C++初阶:C/C++内存管理
一.C/C内存分布 先来回顾一下C语言内存分区示意图如下: 代码区: 程序执行代码一般存放在代码区,字符串常量以及define定义的常量也可能存放在代码区。 常量区: 字符串,数字等常量以及const修饰的全局变量往往存放在…...
新成果展示:AlGaN/GaN基紫外光电晶体管的设计与制备
紫外光电探测器被广泛应用于导弹预警、火灾探测、非可见光通信、环境监测等民事和军事领域,这些应用场景的实现需要器件具有高信噪比和高灵敏度。因此,光电探测器需要具备响应度高、响应速度快和暗电流低的特性。近期,天津赛米卡尔科技有限公…...

Ivs+keepalived:高可用集群
Ivskeepalived:高可用集群 keepalived为lvs应运而生的高可用服务。lvs的调度器无法做高可用,keepalived这个软件就是为了实现调度器的高可用。 注意:keepalived不是专门为lvs集群服务的,也可以做其他代理服务器的高可用。 lvs的高可用集群&a…...
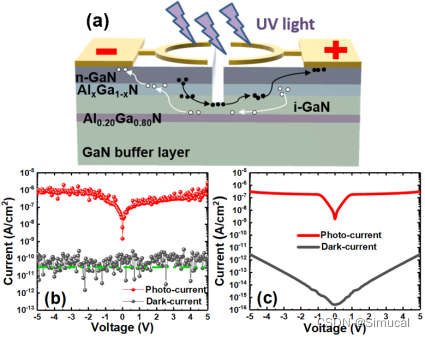
win10安装spark
一、进入spark下载页面 连接 Downloads | Apache Spark 二、解压下载后的.tgz文件 直接解压即可 三、运行 运行bin目录下的 spark-shell.cmd 提示 Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.hom…...
)
基于Spring Boot 的毕业生实习就业管理系统(绿色)
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于Spring Boot 的毕业生实习就业管理系…...
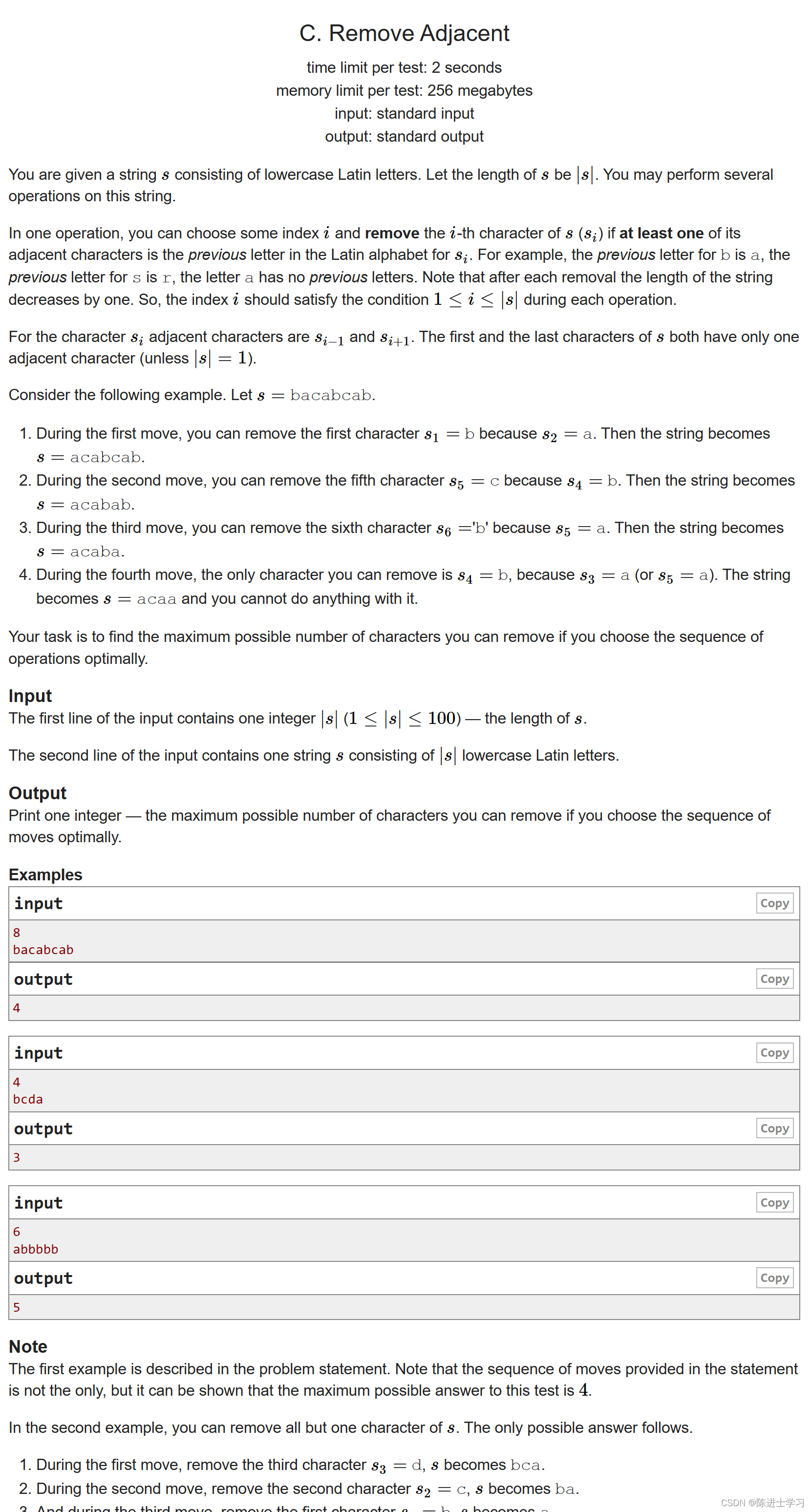
1600*C. Remove Adjacent(贪心字符串)
Problem - 1321C - Codeforces 解析: 贪心,从z到a遍历,每次循环减去符合题意的字符。 #include<bits/stdc.h> using namespace std; signed main(){int n;string s;cin>>n>>s;for(char iz;i>a;i--){for(int j0;j<s.…...
)
CRC校验码2018-架构师(六十一)
以下关于串行总线的说法中,正确的是()。 串行总线一般都是双全工总线,适宜于长距离传输数据串行总线传输的波特率是总线初始化时预先定义好的,使用中不可改变串行总线是按位(BIT)传输数据的&am…...

CSS设置超出范围滚动条和滚动条样式
CSS设置超出范围滚动条和滚动条样式 效果展示 当块级内容区域超出块级元素范围的时候,就会以滚动条的形式展示,你可以滚动里面的内容,里面的内容不会超出块级区域范围。 未设置超出隐藏,显示滚动条 超出隐藏,显示滚动…...

EtherCAT从站转CclinkIE协议网关应用案例
远创智控的YC-ECT-CCLKIE网关,一款具有强大功能的ETHERCAT通讯网关。 它可以将ETHERCAT网络和CCLINK IE FIELD BASIC网络无缝连接起来。作为ETHERCAT总线中的从站,本网关可以接收来自ETHERCAT主站的数据,并将其传输到CCLINK IE FIELD BASIC网…...

腾讯云 AI 绘画:文生图、图生图、图审图 快速入门
腾讯云 AI 绘画是腾讯云推出的一款基于人工智能的图像生成和编辑产品,能够根据输入的图片或描述文本,智能生成与输入内容相关的图片,支持多样化的图片风格选择。 在本文中,我们将介绍如何使用腾讯云 AI 绘画的三项主要功能&#…...

前端项目中,强缓存和协商缓存的配置
前端缓存分为HTTP缓存和浏览器缓存 HTTP缓存(本文重点) 强缓存协商缓存 浏览器缓存 比较熟悉的 cookie,localstorage sessionstorage indexDB…或者cacheStorage 请求的缓存,如果本地有取本地的 这里主要笔记http缓存 先说总结的内容 webpack配置&am…...

【LeetCode】2. 两数相加
题目链接 文章目录 Python3方法: 模拟 ⟮ O ( n ) 、 O ( 1 ) ⟯ \lgroup O(n)、O(1)\rgroup ⟮O(n)、O(1)⟯ C Python3 方法: 模拟 ⟮ O ( n ) 、 O ( 1 ) ⟯ \lgroup O(n)、O(1)\rgroup ⟮O(n)、O(1)⟯ # Definition for singly-linked list. # cl…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

AI应用开发利器:ai-devkit工具包核心功能与工程实践指南
1. 项目概述与核心价值最近在折腾AI应用开发,发现一个挺有意思的项目,叫codeaholicguy/ai-devkit。乍一看名字,你可能会觉得这又是一个“AI开发工具包”,市面上类似的工具已经多如牛毛了。但深入用下来,我发现它不太一…...

从零到一:基于HappyBase的HBase Python应用实战指南
1. 环境准备与基础配置 第一次接触HBase和HappyBase时,环境配置往往是最让人头疼的部分。记得我刚开始搭建环境时,花了整整两天时间才把所有服务调通。为了让各位少走弯路,我把这些年积累的经验都整理在这里。 首先需要明确的是,…...

恶劣环境下LED发光服饰的可靠系统构建:从设计到工艺的工程实践
1. 项目概述与核心挑战如果你曾经尝试过制作一件会发光的服装,无论是为了音乐节、万圣节还是水下表演,你大概都体会过那种“亮一次,修三次”的挫败感。LED灯带在工作室的桌面上测试时完美无瑕,一旦穿到身上,开始活动、…...

Touchpoint:命令行工具集中管理工作上下文,提升开发效率
1. 项目概述:一个被低估的开发者效率工具如果你和我一样,日常开发工作需要在多个代码仓库、项目管理工具(如Jira、Linear)、文档平台(如Confluence、Notion)和沟通软件(如Slack)之间…...

5分钟掌握小红书无水印下载:让内容保存效率提升300%
5分钟掌握小红书无水印下载:让内容保存效率提升300% 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#…...

3个维度深度解析:UABEA如何重塑Unity资源处理生态
3个维度深度解析:UABEA如何重塑Unity资源处理生态 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity游戏开发和资源处理的复杂生态中,开发者常常面临一个核心挑战…...

DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具
DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的免费开源工具,专为PC游戏玩家设计,能够智能管理、…...

手机号归属地查询系统:3步构建可视化定位工具
手机号归属地查询系统:3步构建可视化定位工具 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirrors/lo/l…...
)
别再让用户等上传!用@ffmpeg/ffmpeg在浏览器里直接压缩视频(附ThinkPHP项目实战)
浏览器端视频压缩实战:基于FFmpeg.wasm与ThinkPHP的高效集成方案 引言 在当今内容为王的互联网时代,视频已成为用户生成内容(UGC)的核心载体。然而,高清视频带来的大文件体积往往成为用户体验的瓶颈——上传等待时间长…...