Linux多线程服务端编程:使用muduo C++网络库 学习笔记 第三章 多线程服务器的适用场合与常用编程模型
本文中的多线程服务器指运行在Linux上的独占式网络应用程序。硬件平台为Intel x86-64系列的多核CPU,单路或双路SMP(Symmetric Multi-Processing,对称多处理,它是一种多核处理器架构,其中多个CPU核心共享系统的内存和其他资源,以协同执行并行计算任务)服务器(每台机器一共拥有四个核或八个核,十几GB内存),机器之间用千兆以太网连接。这大概是作者写作时民用PC服务器的主流配置。不考虑分布式存储,只考虑分布式计算,系统的规模大约是几十台到几百台服务器之间。
进程(process)粗略地讲是内存中正在运行的程序。本书的进程指的是Linux操作系统通过fork系统调用产生的东西,或Windows下CreateProcess()的产物,不是Erlang里那种轻量级进程(Actor)。
每个进程有自己独立的地址空间(address space),在同一个进程还是不在同一个进程是系统功能划分的重要决策点。《Erlang程序设计》把进程比作人,十分精当。
每个人有自己的记忆(memory),人与人通过谈话(消息传递)来交流,谈话既可以是面谈(同一台服务器),也可以在电话里谈(不同服务器,有网络通信)。面谈和电话谈的区别在于,面谈可以立即知道对方是否死了(crash,SIGCHLD),而电话谈只能通过周期性的心跳来判断对方是否还活着。
有了这些比喻,设计分布式系统时可以采取角色扮演,团队里的几个人各自扮演一个进程,人的角色由进程的代码决定(管登录的、管消息分发的、管买卖的等等),每个人有自己的记忆,但不知道别人的记忆,要想知道别人的看法,只能通过交谈(暂不考虑共享内存这种IPC)。然后就可以思考以下场景:
1.容错:万一有人死了。
2.扩容:新人中途加进来。
3.负载均衡:把甲的活挪给乙做。
4.退休:甲要修复bug,先别派任务,等他做完手上的事情就把它重启。
线程概念大概在1993年后才慢慢流行起来,距今作者写作不到20年,比不得有40年光辉历史的Unix操作系统。线程的出现给Unix添了不少乱,很多C库函数(strtok()、ctome())不是线程安全的,需要重新定义。signal的语意也大为复杂化。最早支持多线程的民用操作系统是Solaris 2.2和Windows NT 3.1,它们均发布于1993年,随后在1995年,POSIX threads标准确立。
线程的特点是共享地址空间,从而可以高效地共享数据。一台机器上的多个进程能高效地共享代码段(操作系统可以映射为同样的物理内存),但不能共享数据。如果多个进程大量共享内存,等于是把多进程程序当成多线程来写,掩耳盗铃。
多线程的价值,作者认为是为了更好地发挥多核处理器(multi-cores)的效能。在单核时代,多线程没有多大价值。Alan Cox说过:A computer is a state machine. Threads are for people who can’t program state machines."(计算机是一台状态机。线程是给那些不能编写状态机程序的人准备的。这句话中,Alan Cox暗示如果程序员完全理解并能有效地编程状态机,他们就不需要使用线程)。如果只有一块CPU、一个执行单元,那么确实如Alan Cox所说,按状态机的思路去写程序是最高效的。
对于单线程服务器的编程模型,UNP对此有很好的总结(第六章的IO模型、第三十章的客户端/服务器设计范式),这里不再赘述。在高性能的网络程序中,使用得最为广泛的恐怕是non-blocking IO + IO multiplexing模型,即Reactor模式,有以下程序使用它:
1.lighttpd,单线程服务器。(Nginx与之类似,每个工作进程有一个event loop)
2.libevent,libev。
3.ACE,Poco C++ libraries。
4.Java NIO,包括Apache Mina和Netty。
5.POE(Perl)。
6.Twisted(Python)。
相反,Boost.Asio和Windows I/O Completion Ports实现了Proactor模式,应用面似乎要窄一些。此外,ACE也实现了Proactor模式。
在non-blocking IO + IO multiplexing模型中,程序的基本结构是一个事件循环(event loop),以事件驱动(event-driven)和事件回调的方式实现业务逻辑:
// 示意代码,没有完整考虑各种情况
while (!done)
{int timeout_ms = max(1000, getNextTimedCallback());int retval = ::poll(fds, nfds, timeout_ms);if (retval < 0){// 处理错误,回调用户的error handler}else{// 处理到期的timers,回调用户的timer handlerif (retval > 0){// 处理IO时间,回调用户的IO event handler}}
}
以上代码中select/poll有伸缩性方面的不足,Linux下可替换为epoll,其他操作系统也有对应的高性能替代品。
Reactor模型的优点很明显,编程不难,效率也不错。不仅可用于读写socket,连接的建立,甚至DNS解析(gethostbyname函数是阻塞的,对陌生域名的解析的耗时可长达数秒,我们可以显式发起DNS解析,然后异步等待DNS服务器的响应)都可以用非阻塞方式进行,以提高并发度和吞吐量(throughput),对于IO密集型的应用是个不错的选择。lighttpd就是这样。
基于事件驱动的编程模型也有其本质缺点,它要求事件回调函数必须是非阻塞的。对于设计网络IO的请求响应式协议,它容易割裂业务逻辑,使其散布于多个回调函数之中,相对不容易理解和维护。现代的语言有一些应对方法(如coroutine),但本书只关注C++这种传统语言(C++20引入了coroutine)。
多线程服务器的常用编程模型:
1.每个请求创建一个线程,使用阻塞式IO操作。Java 1.4引入NIO前,这是Java网络编程的推荐做法,可惜伸缩性不佳。
2.使用线程池,同样使用阻塞式IO操作,与1相比,这是提高性能的措施。
3.使用non-blocking IO + IO multiplexing,即Java NIO(New I/O,它是Java平台的一组API,用于支持高性能、非阻塞的I/O操作)方式。
4.Leader/Follower等高级模式。
默认作者推荐第3种方式来编写多线程C++网络服务程序。
此种模型下,程序里的每个IO线程有一个event loop(或者叫Reactor),用于处理读写和定时事件(无论是周期性的还是单次的),代码框架跟单线程的non-blocking IO + IO multiplexing模型一样。
libev(不是libevent)的作者说:One loop per thread is usually a good model. Doing this is a almost never wrong, sometimes a better-performance model exists, but it is always a good start.。
这种方式的好处是:
1.线程数目基本固定,可以在程序启动时设置,不会频繁创建与销毁。
2.可以很方便地在线程间调配负载。
3.IO事件发生的线程是固定的,同一个TCP连接不用考虑事件并发。
Event loop代表了线程的主循环,需要让哪个线程干活,就把timer或IO channel(如TCP连接)注册到哪个线程的loop里即可。对实时性有要求的connection可以单独用一个线程;数据量大的connection可以独占一个线程,并把数据处理任务分摊到另几个计算线程中(用线程池);其他次要的辅助性connections可以共享一个线程。
对于non-trivial(比较复杂的,通常处理大量IO请求)的服务端程序,一般会采用non-blocking IO + IO multiplexing,每个connection/acceptor都会注册到某个event loop上,程序里有多个event loop,每个线程至多有一个event loop。
多线程程序对event loop提出了更高的要求,即线程安全,要允许一个线程往别的线程里塞东西(例如主IO线程收到一个新建连接,分配给某个子IO线程处理),这个loop必须得是线程安全的。
对于没有IO而只有计算任务的线程,使用event loop有点浪费,可以用blocking queue实现的任务队列:
typedef boost::function<void> Functor;
// 线程安全的阻塞队列
BlockingQueue<Functor> taskQueue;void workerThread()
{// running是个全局标志while (running){// this blocksFunctor task = taskQueue.tack();// 在产品代码中需要考虑异常处理task();}
}
这种方式实现线程池特别容易,以下是启动容量(并发数)为N的线程池:
int N = num_of_computing_threads;
for (int i = 0; i < N; ++i)
{// 伪代码,启动线程create_thread(&workerThread);
}
使用起来也很简单:
// Foo有calc成员函数
Foo foo;
boost::function<void()> task = boost::bind(&Foo::calc, &foo);
taskQueue.post(task);
上面简单实现了一个固定数目的线程池,功能大概相当于Java中的ThredPoolExecutor的某种“配置”(相当于其某种配置下的行为)。在真实项目中,这些代码都应该封装到一个class中,而不是使用全局对象。
muduo的线程池比这个略复杂,因为要提供stop()操作。
除了用BlockingQueue<T>实现任务队列,还可以用BlockingQueue<T>实现数据的生产者消费者队列,即T是数据类型而非函数对象,queue的消费者从中拿到数据进行处理。
BlockingQueue<T>是多线程编程的利器,它的实现可参照Java.util.concurrent里的(Array|Linked)BlockingQueue,这份Java代码可读性很高,代码的基本结构和教科书一致(一个mutex,2个condition variable,mutex用于保护队列的访问,两个条件变量中,一个用于通知当队列不为空时可以取出元素,另一个用于通知当队列不满时可以插入元素),健壮性高。如果不想自己实现,用线程的库更好。muduo里有一个基本的实现,包括无界的BlockingQueue和有界的BoundedBlockingQueue两个class。
作者推荐C++多线程服务端编程模式为one (event) loop per thread + thread pool:
1.event loop(也叫IO loop)用作IO multiplexing,配合non-blocking IO和定时器。
2.thread pool用来做计算,具体可以是任务队列或生产者消费者队列。
程序里具体用几个loop、线程池的大小等参数需要根据应用来设定,原本的原则是阻抗匹配(即系统组件之间的资源或处理速度能够匹配),使得CPU和IO都能高效地运作。
程序里可能还有个别执行特殊任务的线程,如logging,这对应用程序来说基本是不可见的,但在分配资源(CPU和IO)时要算进入,以免高估了系统的容量。
Linux下进程间通信(IPC)的方式数不胜数,光UNPv2列出的就有:匿名管道(pipe)、具名管道(FIFO)、POSIX消息队列、共享内存、信号(signals)等,更不必说Sockets了。同步原语(synchronization primitives)也很多,如互斥器(mutex)、条件变量(condition variable)、读写锁(reader-writer lock)、文件锁(record locking)、信号量(semaphore)等。
如何选择呢?根据作者经验,贵精不贵多,认真挑选三四样东西就能完全满足作者的工作需要。
进程间通信作者推荐Sockets(主要指TCP),其最大的好处在于:可以跨主机,具有伸缩性。反正都是多进程了,如果一台机器的处理能力不够,很自然地就能用多台机器来处理。把进程分散到同一局域网的多台机器上,程序改改host::port配置就能继续用。而前面列出的其他IPC都不能跨机器,这限制了scalability。
在编程上,TCP sockets和pipe都是操作文件描述符,用来收发字节流,都可以read/write/fcntl/select/poll等,不同的是,TCP是双向的,Linux的pipe是单向的,进程间双向通信还得开两个文件描述符,不方便(可用socketpair函数代替),且进程要有父子关系才能用pipe,这都限制了pipe的使用。在收发字节流这一通信模型下,没有必要Sockets/TCP更自然的IPC了。当然,pipe也有一个经典应用场景,即写Reactor/event loop时用来异步唤醒select(或等价的poll/epoll_wait)函数,Sun HotSpot JVM在Linux就是这么做的。
TCP port由一个进程独占,且操作系统会自动回收(listening port和已建立连接的TCP socket都是文件描述符,在进程结束时操作系统会关闭所有文件描述符)。这说明,即使程序意外退出,也不会给系统留下垃圾,程序重启后能比较容易地恢复,而不需要重启操作系统(用跨进程的mutex就有这个风险)。既然port是独占的,可以防止程序重复启动,后面那个进程抢不到port,自然就没法初始化了,避免造成意料之外的结果。
两个进程通过TCP通信,如果一个崩溃了,操作系统会关闭连接,另一个进程几乎立刻就能感知,可以快速failover。当然应用层的心跳也是必不可少的。
与其他IPC相比,TCP协议的一个天生的好处是可记录、可重现,tcpdump和Wireshark是解决两个进程间协议和状态争端的好帮手,也是性能(吞吐量、延迟)分析的利器。我们可以借此编写分布式程序的自动化回归测试(软件测试的一种方法,用于检查新的软件版本或代码修改是否引入了新的缺陷,同时确保现有功能仍然按预期工作,这种类型的测试旨在验证软件在经历更改后是否"回归"到了以前的稳定状态)。也可以用tcpcopy之类的工具进行压力测试。TCP还能跨语言,服务端和客户端不必用同一种语言。
如果网络库带连接重试功能,我们可以不要求系统里的进程以特定顺序启动,任何一个进程都能单独重启,即TCP连接是可再生的,连接的任何一方都可以退出再启动,重建连接后就能继续工作,这对开发牢靠的分布式系统意义重大。
使用TCP这种字节流方式通信,会有marshal/unmarshal(在TCP通信中,发送方需要将数据从应用程序的数据结构(例如对象或结构体)编码成字节序列,这个过程称为"marshal",而接收方需要将接收到的字节序列解码为应用程序可理解的数据结构,这个过程称为"unmarshal")的开销,这要求我们选用合适的消息格式,准确地说是wire format。
有人可能会说,具体问题具体分析,如果两个进程在同一台机器,就用共享内存,否则就用TCP,如MS SQL Server就同时支持这两种通信方式。试问,是否值得为那么一点性能提升而让代码的复杂度大大增加呢?何况TCP的local吞吐量一点也不低。TCP是字节流协议,只能顺序读取,有写缓冲;共享内存是消息协议,a进程填好一块内存让b进程来读,基本是停等(stop wait)方式,要把这两种方式揉到一个程序里,需要建一个抽象层,封装两种IPC,这会带来不透明性,且增加测试的复杂度。且万一通信的某一方崩溃,状态reconcile(表示在两个不同的状态或数据之间进行协调、调解、调和或修复,以使它们一致)也会比sockets麻烦(数据刚写到一半怎么办?)。再说,你舍得让几万块买来的SQL Server和其他应用程序共享机器资源吗,生产环境下的数据库服务器往往是独立的高配置服务器,一般不会同时运行其他占资源的程序。
TCP本身是个数据流协议,除了直接用它来通信外,还可在此只上构建RPC/HTTP/SOAP(Simple Object Access Protocol,是一种基于XML的通信协议,最初被设计用于在分布式系统中实现Web服务通信,但它可以用于各种不同的应用和通信方式)之类的上层通信协议。另外,除了点对点通信外,应用级的广播协议也是非常有用的,可以方便构建可观可控的分布式系统。
分布式系统的软件设计和功能划分一般应该以进程为单位,从宏观上看,一个分布式系统是由运行在多台机器上的多个进程组成的,进程之间采用TCP长连接通信。本章讨论分布式系统中单个服务进程的设计方法,第9章会谈到整个系统的设计。作者提倡用多线程,不是说把整个系统放到一个进程里实现,而是指功能划分后,在实现每一类服务进程时,在必要时可以借助多线程来提高性能。对于整个分布式系统,要做到能scale out,即享受增加机器带来的好处。
使用TCP长连接的好处有以下两点:
1.容易定位分布式系统中的服务之间的依赖关系。只要在机器上运行netstat -tpna | grep :port就能立刻列出用到某服务的客户端地址(Foreign列),然后在客户端的机器上用netstat或lsof命令找出是哪个进程发起的连接,这样在迁移服务器的时候能有效地防止出现outage(指服务中断或停机,特指服务器或服务无法正常运行,导致不可用的状态)。TCP短连接和UDP则不具备这一特性。
2.通过接收和发送队列的长度也较容易定位网络或程序故障。正常运行时,netstat打印的Recv-Q和Send-Q都应该接近0,或在0附近摆动。如果Recv-Q保持不变或持续增加,则通常意味着服务进程的处理速度变慢,可能发生了死锁或阻塞。如果Send-Q保持不变或持续增加,有可能是对方服务器太忙,来不及处理,也有可能是网络中间某个路由器或交换机故障造成丢包,甚至对方服务器掉线,这些因素都可能表现为数据发送不出去。通过持续监控Recv-Q和Send-Q就能及早预警性能或可用性故障。以下是服务端线程阻塞造成Recv-Q和客户端Send-Q激增的例子:

用一句话形容本书所指的服务器开发是:跑在多核机器上的Linux用户态的没有用户界面的,长期运行(不是7 X 24小时不重启,而是程序不会因为无事可做而退出,它会等待下一个请求的到来)的网络应用程序,通常是分布式系统的组成部件。
开发服务端程序的一个基本任务是处理并发连接,服务器处理并发连接有两种方式:
1.当“线程”很廉价时,一台机器上可以创建远高于CPU数目的“线程”。这时一个线程只处理一个TCP连接(甚至半个),通常使用阻塞IO。如Python gevent、Go goroutine、Erlang actor。这里的“线程”由语言的runtime自行调用,与操作系统线程不是一回事。
2.当线程很宝贵时,一台机器上只能创建与CPU数目相当的线程,这时一个线程要处理多个TCP连接上的IO,通常使用非阻塞IO和IO multplexing。如libevent、muduo、Netty。这时原生线程,能被操作系统的任务调度器看见。
在处理并发连接时,要充分发回硬件资源的作用,不能让CPU资源闲置。由于本书讨论的是C++变成,我们只考虑上述第2种方式,这是Linux下使用native语言编写用户态高性能网络程序的最成熟的模式。
我们的线程指的是pthread_create()的产物,是宝贵的那种原生线程,且作者指的Pthreads是NPTL(Native POSIX Thread Library,这是Linux操作系统上实现POSIX线程标准的一种库)的,每个线程由clone(clone是一种在Linux上创建新线程的系统调用)产生,对应一个内核的task_struct(每个线程都对应于Linux内核中的一个task_struct数据结构,task_struct包含了线程的各种信息,如寄存器状态、进程标识符、调度信息等)。
一个由多台机器组成的分布式系统必然是多进程的,因为进程不能跨OS边界,在这个前提下,我们把目光集中到一台机器,一台拥有至少4个核的普通服务器,如果要在一台多核服务器是哪个提供一种服务或执行一个任务,可用的模式(不是pattern(指一种可重复使用的、通用的解决问题的方法或设计),而是model(指对某个事物、概念或过程的抽象和表示),它们的中译是一样的)有:
1.运行一个单线程的进程。
2.运行一个多线程的进程。
3.运行多个单线程的进程。
4.运行多个多线程的进程。
这些模型之间的比较:
1.模式1是不可伸缩的,不能发挥多核机器的计算能力。
2.模式3是目前公认的主流模式,它有以下两种子模式:
(3a)简单地把模式1中的进程运行多份(如果能用多个TCP port对外提供服务的话)。
(3b)主进程+worker进程,如果必须绑定到一个TCP port,如httpd+fastcgi。
3.模式2是被很多人所鄙视的,认为多线程程序难写,且与模式3相比没有什么优势。
4.模式4更是千夫所指,它不但没有结合2和3的优点,反而汇聚了二者的缺点。
我们讨论模式2和模式3b的优劣,即:什么时候一个服务器程序应该是多线程的。从功能上讲,没有什么是多线程能做到而单线程做不到的,反之亦然,都是状态机。从性能上讲,无论是IO bound还是CPU bound的服务,多线程都没有什么优势。
Paul E. McKenney在《Is Parallel Programming Hard, And, If So, What Can You Do About It?》中指出,“As a rough rule of thumb, use the simplest tool that will get the job done“(作为一个粗略的经验法则,应该使用最简单的工具来完成任务)。比如说,使用速率为50MB/s的数据压缩库,在进程创建销毁的开销是800us,线程创建销毁开销是50us的前提下,考虑如何执行压缩任务:
1.如果是要偶尔压缩1GB的文本文件,预计运行时间是20s,那么起一个进程去做是合理的,因为进程启动和销毁的开销远远小于实际任务的耗时。
2.如果要经常压缩500kB的文本数据,预计运行时间是10ms,那么每次都起进程似乎有点浪费了,可以每次单独起一个线程去做。
3.如果要频繁压缩10kB的文本数据,预计运行时间是200us,那么每次起线程似乎也很浪费,不如直接在当前线程搞定。也可以用一个线程池,每次把压缩任务交给线程池,避免阻塞当前线程(特别要避免阻塞IO线程)。
由此可见,多线程并不是silver bullet,它有适用的场合,在回答什么时候该用多线程前,先谈谈必须用单线程的场合:
1.程序可能会fork。
2.限制程序的CPU占用率。
只在单线程程序中fork,否则会遇到很多麻烦,如果子进程由调用fork()的线程创建,那么子进程中只包括一个调用线程,但父进程的整个虚拟地址空间都会在子进程中进行复制,包括互斥锁、条件变量和其他pthreads对象的状态,为了处理由此可能引发的问题,可以使用pthread_atfork()。
一个程序fork后一般有两种行为:
1.立刻执行exec(),变成另一个程序,如shell和inetd。又比如lighttpd fork()出子进程,然后运行fastcgi程序。还有集群中运行在计算节点上的负责启动job的守护进程(即作者所谓的看门口进程)。
2.不调用exec(),继续运行当前程序,要么通过共享的文件描述符与父进程通信,协同完成任务;要么接过父进程传来的文件描述符,独立完成工作,如20世纪80年代的Web服务器NCSA httpd。
这两种行为里,只有看门狗进程必须坚持单线程,其他的均可替换为多线程程序(从功能上讲)。
对于单线程程序能限制程序的CPU占用率,也很容易理解,如在一个8核服务器上,一个单线程程序即便发生busy-wait(无论是因为bug,还是因为overload),占满1个core,其CPU使用率也只有12.5%。在最坏的情况下,系统还是有87.5%的计算资源可供其他服务进程使用。
因此对于一些辅助性的程序,如果它必须和主要服务进程运行在同一台机器(如它要监控其他服务进程的状态),那么做成单线程的能避免过分抢夺系统的计算资源。如如果要把生产服务器上的日志文件压缩后备份到NFS上,那么应该是用普通单线程压缩工具(gzip/bzip2),它们对系统造成的影响较小,在8核服务器上最多占满1个core。如果有人为了提高速度,开启了多线程压缩或同时起多个进程来压缩多个日志文件,有可能造成的结果是非关键任务耗尽了CPU资源,正常客户的请求响应变慢。
从编程角度,单线程程序的优势无需赘言:简单。程序的结构一般是一个基于IO multiplexing的event loop,或直接用阻塞IO。
event loop有一个明显的缺点,它是非抢占(non-preemptive)的。假设事件a的优先级高于事件b,处理事件a需要1ms,处理事件b需要10ms。如果事件b稍早于a发生,那么当事件a到来时,程序已经离开了poll调用,并开始处理事件b。事件a要等上10ms才有机会被处理,总的响应时间为11ms。这等于发生了优先级反转。这个缺点可以用多线程来克服,这也是多线程的主要优势。
无论是IO bound还是CPU bound的服务,多线程都没有绝对意义上的性能优势,这句话是说,如果用很少的CPU负载就能让IO跑满,或者用很少的流量就能让CPU跑满,那么多线程没啥用处。例如:
1.对于静态Web服务器,或FTP服务器,CPU的负载较轻,主要瓶颈在磁盘IO和网络IO方面。这时候往往一个单线程的程序就能撑满IO(指占用完IO资源)。用多线程并不能提高吞吐量,因为IO硬件容量已经饱和了。同理,这时增加CPU数目也不能提高吞吐量。
2.CPU跑满的情况比较少见,这里举一个虚构的例子。假设有一个服务,它的输入是n个整数,问能否从中选出m个整数,使其和为0(这里n<100,m>0)。这是著名的subset sum问题,是NP-Complete(在多项式时间内找不到解)的。对于这样一个服务,哪怕很小的n值也会让CPU算死。比如n=30,一次的输入不过200字节(32-bit整数),CPU的运算时间却能长达几分钟。对于这种应用,模式3a是最适合的,能发挥多核优势,程序也简单。
即无论任何一方早早地到达瓶颈,多线程程序都没啥优势。
多线程的适用场景是:提高响应速度,让IO和计算相互重叠,降低latency。虽然多线程不能提高绝对性能,但能提高平均响应性能。
一个程序要做成多线程的,大致要满足:
1.有多个CPU可用。单核机器上多线程没有性能优势(但或许能简化并发业务逻辑的实现)。
2.线程间有共享数据,即内存中的全局状态。如果没有共享数据,用模型3b就行。虽然我们应该把线程间的共享数据降到最低,但不代表没有。
3.共享的数据是可以修改的,而不是静态的常量表。如果数据不能修改,那么可以在进程间用shared memory,模式3就能胜任。
4.提供非均质的服务。即,事件的响应有优先级差异,我们可以用专门的线程来处理优先级高的事件,防止优先级反转。
5.latency和throughput同样重要,不是逻辑简单的IO bound或CPU bound程序。换言之,程序要有相当的计算量(否则计算量小,单线程收到请求后直接就完成了,不需要交给其他线程去做)。
6.利用异步操作。如logging。无论往磁盘写log file,还是往log server发消息都不应阻塞critical path。
7.能scale up。一个好的多线程程序能享受增加CPU数目带来的好处,目前主流是8核,很快就会用到16核的机器了。
8.具有可预测的性能。随着负载增加,性能缓慢下降,超过某个临界点后会急速下降。线程数目一般不随负载变化。
9.多线程能有效地划分责任与功能,让每个线程的逻辑比较简单,任务单一,便于编码。而不是把所有逻辑都塞到一个event loop里,不同类别的事件之间相互影响。
以上条件比较抽象,这里举两个具体(虽然是虚构的)的例子:假设要管理一个Linux服务器机群,这个机群里有8个计算节点,1个控制节点。机器的配置都是一样的,双路四核CPU(双路指服务器的主板(motherboard)上搭载了两个CPU插槽,这意味着每台服务器具有两颗CPU,每颗CPU都有四个核心),千兆网互联。现在要编写一个简单的机群管理软件,这个软件由3个程序组成:
1.运行在控制节点上的master,这个程序监视并控制整个机群的状态。
2.运行在每个计算节点上的slave,负责启动和终止job,并监控本机的资源。
3.供最终用户使用的client命令行工具,用于提交job。
根据以上分析,slave是个看门狗进程,它会启动别的job进程,因此必须是个单线程程序。另外它不应占用太多CPU资源,这也适合单线程模型。master应该是个模式2的多线程程序:
1.它独占一台8核机器,如果用模型1,等于浪费了87.5%的CPU资源。
2.整个机群的状态应该能完全放在内存中,这些状态是共享且可变的。如果用模式3,那么进程之间的状态同步会成大问题。而如果大量使用共享内存,则等于是掩耳盗铃,是披着多进程外衣的多线程程序。因为一个进程一旦在临界区内阻塞或crush,其他进程会全部死锁。
3.master的主要性能指标不是throughput,而是latency,即尽快响应各种事件。它几乎不会出现把IO或CPU跑满的情况。
4.master监控的事件有优先级区别,一个程序正常运行结束和异常崩溃的处理优先级不同,计算节点的磁盘满和机箱温度过高这两种报警条件的优先级也不同。如果用单线程,则可能会出现优先级反转。
5.假设master和每个slave之间用一个TCP连接,那么master采用2个或4个IO线程来处理8个TCP connections能有效降低延迟。
6.master要异步地往本地硬盘写log,这要求logging library有自己的IO线程。
7.master有可能要读写数据库,那么数据库连接这个第三方library可能有自己的线程,并回调master的代码。
8.master要服务于多个clients,用多线程也能降低客户响应时间。即它可以再用2个IO线程专门处理和clients的通信。
9.master还可以提供一个monitor接口,用来广播推送(pushing)机群的状态,这样用户不用主动轮询(polling)。这个功能如果用单独的线程来做,会比较容易实现,不会搞乱其他主要功能。
10.master一共开了十个线程:
(1)4个用于和slaves通信的IO线程。
(2)1个logging线程。
(3)1个数据库IO线程。
(4)2个和clients通信的IO线程。
(5)1个主线程,用于做些背景工作,如job调度。
(6)一个pushing线程,用于主动广播机群状态。
11.虽然线程数目略多于core数目,但是这些线程很多时候都是空闲的,可以依赖OS的进程调度来保证可控的延迟。
综上所述,master用多线程方式编写是自然且高效的。
再举一个TCP聊天服务器的例子,这里的聊天不完全指人与人聊天,也可能是机器与机器“聊天”。这种服务的特点是并发连接之间有数据交换,从一个连接收到的数据要转发给其他多个连接。因此我们不能按模式3的做法,把多个连接分到多个进程中分别处理(这会带来复杂的进程间通信),而只能用模式1或模式2。如果纯粹只有数据交换,那么模式1也能工作得很好,因为现在的CPU足够快,单线程应付几百个连接不在话下。
如果功能进一步复杂化,加上关键字过滤、黑名单、防灌水等功能,甚至要给聊天内容自动加上相关连接,每一项功能都会占用CPU资源。这时就要考虑模式2了,因为单个CPU的处理能力显得捉襟见肘,顺序处理导致消息转发的延迟增加。这时我们考虑把空闲的多个CPU利用起来,自然的做法是把连接分散到多个线程上,例如按round-robin的方式把1000个客户连接分配到4个IO线程上。这样充分利用多核加速。
一个多线程服务程序中的线程大致可分为三类:
1.IO线程,这类线程的主循环是IO multiplexing,阻塞地等在select/poll/epoll_wait系统调用上,这类线程也处理定时事件。当然它的功能不止IO,有些简单计算也可放入其中,如消息的编码或解码。
2.计算线程,这类线程的主循环是blocking queue,阻塞地等在condition variable上。这类线程一般位于thread pool中。这种线程通常不涉及IO,一般要避免任何阻塞操作。
3.第三方库所用的线程,比如logging、database connection。
服务器程序一般不会频繁启动和终止线程,甚至,作者写过的程序里,create thread只在程序启动时调用,在服务运行期间是不调用的。
在多核时代,要想充分发挥CPU性能,多线程编程是不可避免的,“鸵鸟算法”不是办法。学习多线程编程可以训练异步思维,提高分析并发事件的能力,这对设计分布式系统帮助巨大,因为运行在多台机器上的服务进程本质上是异步的。熟悉多线程编程的话,很容易就能发现分布式系统在消息和事件处理方面的race condition。
答疑:
1.Linux能同时启动多少线程?对于32-bit Linux,一个进程的地址空间是4GiB,其中用户态能访问3GiB左右,而一个线程的默认栈(stack)大小是10MB,心算可知,一个进程大约最多能同时启动300个线程。如果不改线程的调用栈大小,300左右是上限,因为程序的其他部分(数据段、代码段、堆、动态库等)同样要占用内存(地址空间)。
对于64-bit系统,线程数目可大大增加,具体数字没有测试过,在作者在实际项目中一台机器最多只用到过几十个用户线程,其中大部分还是空闲的。
2.多线程能提高并发度吗?如果指的是并发连接数,则不能。
由问题1可知,假如单纯采用thread per connection的模型,那么并发连接数量最多300,远低于基于事件的单线程程序能轻松达到的并发连接数(几千乃至上万,甚至几万)。所谓“基于事件”,指的是用IO multiplexing event loop的编程模型,又称Reactor模式。
如果采用前文推荐的one loop per thread呢?至少不逊于单线程程序。实际上单个event loop处理1万个并发长连接并不罕见,一个multi-loop的多线程程序应该能轻松支持5万并发连接。
thread per connection不适合高并发场合,其scalability不佳。one loop per thread的并发度足够大,且与CPU数目成正比。
3.多线程能提高吞吐量吗?对于计算密集型服务,不能。
假设有一个耗时的计算服务,用单线程算需要0.8s。在一台8核机器上,我们可以同时启动8个线程一起对外服务(如果内存够用)(如果内存够用,启动8个进程也一样,线程与进程相比,吞吐量大致相同)。这样完成单个计算仍然需要0.8s,但是由于这些进程的计算可以同时进行,理想情况下吞吐量可以从单线程的1.25qps(query per second)上升到10qps(实际情况可能要打个五折到八折)。
假如不用多线程而改用并行算法,用8个核一起算,理论上如果完全并行,加速比高达8,那么计算时间是0.1s,吞吐量还是10qps,但首次请求的响应时间却降低了很多。实际上根据Amdahl’s law(阿姆达尔定律是一种用于衡量并行计算性能和效率的数学模型,由计算机科学家Gene Amdahl在1967年提出,它用于描述在一个计算任务中,如果只有一部分可以并行化处理,那么整体性能提升会受到限制的情况),即便算法的并行度高达95%,8核的加速比也只有6,计算时间为0.133s,这样会造成吞吐量下降为7.5qps。不过以此为代价,换得响应时间的提升,在有些应用场合也是值得的。
再举一个例子,如果要在一台8核机器上压缩100个1GB的文本文件,每个core的处理能力为200MB/s。那么“每次起8个进程,每个进程压缩1个文件”与“依次压缩每个文件,每个文件用8个线程并行压缩”这两种方式的总耗时相当,因为CPU都是满载的。但第2种方式能较快地拿到第一个压缩完的文件,即首次响应的延时更小。这也回答了问题4。
如果用thread per request的模型,每个客户请求用一个线程去处理,那么当并发请求数大于某个临界值时,吞吐量反而会下降,因为线程多了以后上下文切换的开销也随之增加。thread per request是最简单的使用线程的方式,编程最容易,简单地把多线程程序当成一堆串行程序,用同步的方式顺序编程,比如在Java Servlet 2.x中,一次页面请求由一个函数同步完成:
HttpServlet.service(HttpServletRequest req, HttpServletResponse resp)
为了在并发请求数很高时也能保持稳定的吞吐量,我们可以用线程池,线程池的大小应满足“阻抗匹配原则”,见问题7。
线程池也不是万能的,如果响应一次请求需要所比较多的计算(如计算的时间占整个response time的1/5多),那么用线程池是合理的,能简化编程。如果在一次请求响应中,主要时间是在等待IO,那么为了进一步提高吞吐量,往往要用其他编程模型,如Proactor(异步IO),见问题8。
4.多线程能降低响应时间吗?如果设计合理,充分利用多核资源的话,可以。在突发(burst)请求时效果尤为明显。
例1:多线程处理输入。以memcached服务端为例。memcached一次请求响应大概分为3步:
(1)读取并解析客户端输入。
(2)操作hashtable。
(3)返回客户端。
在单线程模式下,这3步是串行执行的。在启用多线程模式时,它会启用多个输入线程(默认4个),并在建立连接时按round-robin法把新连接分派给其中一个输入线程,这正好是作者说的one loop per thread模型。这样一来,第一步的操作就能多线程并行,在多核机器上提高多用户的响应速度。第2步用了全局锁,还是单线程的,这可算是一个值得继续改进的地方。
比如,有两个用户同时发出了请求,这两个用户的连接正好分配在两个IO线程上,那么两个请求的第1步操作可以在两个线程上并行执行,然后汇总到第2步串行执行,这样总的响应时间比完全串行执行要短一些(在“读取并解析”所占的比重较大时,效果更为明显)。
例2:多线程分担负载。假设我们要做一个求解Sudoku(数独)的服务,这个服务程序在端口9981接受请求,输入为一行81个数字(待填数字用0表示),输出为填好后的81个数字(1~9),如果无解,输出“NO\r\n”。
由于输入格式很简单,我们用单个线程做IO就行了。先假设每次求解的计算用时为10ms,用前面的方法计算,单线程程序能达到的吞吐量上限为100qps;在8核机器上,如果用线程池来做计算,能达到的吞吐量上限为800qps。接下来我们看看多线程如何降低响应时间。
假设1个用户在极短的时间内发出了10个请求,如果用单线程“来一个处理一个”的模型,这些reqs会排在队列里依次处理(这个队列是操作系统的TCP缓冲区,不是程序里自己的任务队列)。在不考虑网络延迟的情况下,第1个请求的响应时间是10ms;第2个请求要等第一个算完了才能获得CPU资源,它等了10ms,算了10ms,响应时间是20ms;依此类推,第10个请求的响应时间为100ms;这10个请求的平均响应时间为55ms。
如果Sudoku服务在每个请求到达时开始计时,会发现每个请求都是10ms响应时间;而从用户的观点来看,10个请求的平均响应时间为55ms。这是因为我们计算请求响应时间时没有计算请求在TCP接收缓冲内的停留时间。
下面改用多线程:1个IO线程,8个计算线程(线程池)。二者之间用BlockingQueue沟通。同样是10个并发请求,第1个请求被分配到计算线程1,第2个请求被分配到计算线程2,依此类推,直到第8个请求被第8个计算线程承担。第9和第10号请求会等在BlockingQueue里,直到有计算线程回到空闲状态其才能被处理。(这里的分配实际上由操作系统来做,操作系统会从处于waiting状态的线程里挑一个,不一定是round-robin的)这样一来,前8个请求的响应时间差不多都是10ms,后2个请求属于第二批,其响应时间大约会是20ms,总的平均响应时间是12ms。可见这比单线程快了不少。
由于每道Sudoku题目的难度不一,对于简单题目,可能1ms就能算出来,复杂的题目最多用10ms。那么线程池方案的优势就更明显,它能有效降低“简单任务被复杂任务压住”的出现概率。
以上举得都是计算密集的例子,即线程在响应一次请求时不会等待IO。
5.多线程程序如何让IO和计算相互重叠,降低latency?基本思路是,把IO操作(通常是写操作)通过BlockingQueue交给别的线程去做,自己不必等待。
例1:日志(logging)。在多线程服务器程序中,日志(logging)至关重要,本例仅考虑写log file的情况,不考虑log server。
在一次请求响应中,可能要写多条日志消息,而如果用同步的方式写文件(fprintf或fwite函数),多半会降低性能,因为:
1.文件操作一般比较慢,服务线程会等在IO上,让CPU闲置,增加响应时间。
2.就算有buffer(先将日志存起来,用一次write代替多次write),还是不灵。多个线程一起写,为了不至于把buffer写错乱,往往要加锁。这会让服务线程互相等待,降低并发度。(同时用多个log文件不是办法,除非你有多个磁盘,且保证log files分散在不同的磁盘上,否则还是要受到磁盘IO的制约)
解决办法是单独用一个logging线程,负责写磁盘文件,通过一个或多个BlockingQueue对外提供接口。别的线程要写日志时,先把消息(字符串)准备好,然后往queue里一塞就行,基本不用等待。这样服务线程的计算就和logging线程的磁盘IO相互重叠,降低了服务线程的响应时间。
尽管logging很重要,但它不是程序的主要逻辑,因此对程序的结构影响越小越好,最好能简单到如同一条printf语句,且不用担心其他性能开销。而一个好的多线程异步logging库能帮我们做到这点,见第五章。(Apache的log4cxx和log4j都支持AsncAppender这种异步logging方式)
例2:memcached客户端。假设我们用memcached来保存用户最后发帖时间,那么每次响应用户发帖的请求时,程序里要去设置一下memcached里的值。这一步如果用同步IO,会增加延迟。
对于“设置一个值”这样的write-only idempotent操作(幂等性写操作,这种操作的幂等性保证了无论执行多少次,写入结果都相同),我们其实不用等memcached返回操作结果,这里也不用在乎set操作失败,那么可以借助多线程来降低响应延迟。比如我们可以写一个多线程版的memcached客户端,对于set操作,调用方只要把key和value准备好,调用一下asyncSet(),把数据往BlockingQueue上一放就能立即返回,延迟很小。剩下的事就留给memcached客户端的线程去操心,而服务线程不受阻碍。
其实所有的网络写操作都可以这么异步地做,但这也有一个缺点,就是每次asyncWrite()都要在线程间传递数据。其实如果TCP缓冲区是空的,我们就可以在本线程写完,不用劳烦专门的IO线程。Netty就使用了设个办法来进一步降低延迟。
以上仅讨论了“打一枪就跑”的情况,如果是一问一答,比如从memcached取一个值,那么“重叠IO”并不能降低响应时间,因为无论如何都要等memcached的回复。这是我们可以用别的方式来提高并发度,见问题8(虽不能降低响应时间,但也不要浪费线程在空等上)。
6.为什么第三方库往往要用自己的线程?event loop模型没有标准实现。如果自己写代码,尽可以按所用Reactor的推荐方式来编程。但第三方库不一定能很好地适应并融入这个event loop framwork,有时需要用线程来做一些串并转换(有些任务可能需要将串行操作(例如轮询或阻塞等待)与并行操作(事件循环)结合起来)。比方说检测串口上的数据到达可以用文件描述符的可读事件,因此可以方便地融入event loop。但是检测串口上的某些控制信号(例如DCD,Data Carrier Detect,数据载波检测,它是一种串行通信中使用的信号,通常在串口通信(例如RS-232或RS-485)中使用,DCD信号指示着接收设备是否检测到了另一端的数据载波)只能用轮询(ioctl(fd, TIOCMGET, &flags),它的作用是获取串口设备的控制信号状态)或阻塞等待(ioctl(fd, TIOCMIWAIT, TIOCM_CAR),等待串口设备上特定的控制信号状态发生变化,其中 TIOCM_CAR 表示DCD信号);要想融入event loop,需要单独起一个线程来查询串口信号翻转,在转换为文件描述符的读写事件(可通过pipe函数)。
对于Java,这个问题还好办一些,因为thread pool在Java里有标准实现,叫ExecutorService。如果第三方库支持线程池,那么它可以和主程序共享一个ExecutorService,而不是自己创建一堆线程(比如在初始化时传入主程序的obj)。对于C++,情况麻烦地多,Reactor和thread pool都没有标准库。
例1:libmemcached只支持同步操作。libmemcached支持所谓的“非阻塞操作”,但没有暴露一个能被select/poll/epoll的file describer,它的memcached_fetch始终会阻塞。它号称memcached_set可以是非阻塞的,实际意思是不必等待结果返回,但实际上这个函数会阻塞地调用write,仍可能阻塞在网络IO上。
如果在我们的Reactor event handler里调用了libmemcached的函数,那么latency就堪忧了。如果想继续用libmemcached,我们可以为它做一次线程封装,按问题5例2的办法,同额外的线程专门做memcached的IO,而程序主体还是Reactor。甚至可以把memcached的数据就绪作为一个event,注入我们的event loop中,以进一步提高并发度(例子留待问题8讲)。
万幸的是,memcached的协议非常简单,大不了可以自己写一个基于Reactor的客户端,但数据库客户端就没那么幸运了。
例2:MySQL的官方C API不支持异步操作。MySQL的官方客户端只支持同步操作,对于UPDATE/INSERT/DELETE之类只要行为,不管结果的操作(如果代码需要得知其执行结果,则另当别论),我们可以用一个单独的线程来做,以降低服务线程的延迟。可仿照前面memcached_set的例子。麻烦的是SELECT,如果把它也异步化,就得动用更复杂的模式了,见问题8。
相比之下,PostgreSQL的C客户端libpq的设计要好得多,我们可以用PQsend-Query()来发起一次查询,然后用标准的select/poll/epoll来等待PQsocket。如果有数据可读,就用PQconsumuInput处理之,并用PQisBusy判断查询结果是否已就绪。最后用PQgetResult来获取结果。借助这套异步API,我们可以很容易地为libpq写一套wrapper,使之融入程序所用的event loop模型中。
7.什么是线程池大小的阻抗匹配原则?如果池中线程在执行任务时,密集计算所占的时间比重为P(0<0<=1),而系统一共有C个CPU,为了让这C个CPU跑满而又不过载,线程池大小的经验公式为T=C/P。T是个hint,考虑到P值的估计不是很准确,T的最佳值可以上下浮动50%。这个经验公式的原理很简单,T个线程,每个线程占用P的CPU时间,如果刚好占满C个CPU,那么必有C×P=C。下面验证一下边界条件的正确性。
假设C=8,P=1.0,线程池的任务完全是密集计算,那么T=8。只要8个活动线程就能让8个CPU饱和,再多也没用,因为CPU资源已经耗光了。
假设C=8,P=0.5,线程池的任务有一半是计算,有一半等在IO上,那么T=16。考虑操作系统能灵活、合理地调度sleeping/writing/running线程,那么大概16个“50%繁忙的线程”能让8个CPU忙个不停。启动更多线程并不能提高吞吐量,反而因为增加上下文切换的开销而降低性能。
如果P<0.2,这个公式就不适用了,T可以取一个固定值,如5×C。另外,公式里的C不一定是CPU总数,可以是“分配给这项任务的CPU数目”,比如在8核机器上分出4个核来做一项任务,那么C=4。
8.除了作者推荐的Reactor+thredpool,还有别的non-trivial多线程编程模型吗?有,Proactor。如果一次请求响应中要和别的进程打多次交道,那么Proactor模型往往能做到更高的并发度。当然,代价是代码变得支离破碎,难以理解(Proactor依赖于异步事件处理和回调机制,它将程序的执行流分散到多个回调函数或事件处理程序中,使代码更加分散,可能会增加调试和维护的复杂性)。
这里举HTTP proxy为例,一次HTTP proxy的请求如果没有命中本地cache,那么它多半会:
1.解析域名(不要小看这一步,对于一个陌生的域名,解析可能要花几秒的时间)。
2.建立连接。
3.发送HTTP请求。
4.等待对方回应。
4.把结果返回给客户。
这5步中跟2个server发生了3此round-trip,每次都可能花几百毫秒:
1.向DNS问域名,等待回复。
2.向对方的HTTP服务器发起连接,等待TCP三路握手完成。
3.向对方发送HTTP request,等待对方response。
而实际上HTTP proxy本身的运算量不大,如果用线程池,池中线程的数目会很庞大,不利于操作系统的管理调度。
这时我们有两个解决思路:
1.把“域名已解析”、“连接已建立”、“对方已完成响应”做成event,继续按照Reactor的方式来编程。这样一来,每次客户请求就不能用一个函数从头到尾执行完成,而要分成多个阶段,并且要管理好请求的状态(目前到了第几步?)。
2.用回调函数,让系统来把任务串起来。比如收到用户请求,如果没有命中本地缓存,那么需要执行:
(1)立刻发起异步的DNS解析startDNSResolve(),告诉系统在解析完之后调用DNSResolved()函数。
(2)在DNSResolved()中,发起TCP连接请求,告诉系统在连接建立之后调用connectionEstablished()。
(3)在connectionEstablished()中发送HTTP request,告诉系统在收到响应后调用httpResponsed()。
(4)最后,在httpResponsed()里把结果返回给客户。
.NET大量采用的BeginInvoke/EndInvoke操作也是这个编程模式。当然,对于不熟悉这种编程方式的人,代码会显得很难看。有关Proactor模式的例子可参看Boost.Asio的文档,这里不再多说。
Proactor模式依赖操作系统或库来高效地调度这些子任务,每个子任务都不会阻塞,因此能用比较少的线程达到很高的IO并发度。
Proactor能提高吞吐,但不能降低延迟,所以作者没有深入研究。另外,在没有语言只能支持的情况下,Proactor模式让代码非常破碎,在C++中使用Proactor是很痛苦的。因此最好在“线程”很廉价的语言中使用这种方式,这时runtime往往会屏蔽细节,程序用单线程阻塞IO的方式来处理TCP连接。
9.模式2和模式3a该如何取舍?模式2是一个多线程的进程,模式3a是多个相同的单线程进程。
作者认为,在其他条件相同的情况下,可以根据工作集(work set)的大小来取舍。工作集是指服务程序响应一次请求所访问的内存大小。
如果工作集较大,那么就用多线程,避免CPU cache换入换出,影响性能;否则,就用单线程多进程,享受单线程编程的便利。举例来说:
(1)如果程序有一个较大的本地cache,用于缓存一些基础参考数据(in-memory look-up table),几乎每次请求都会访问cache,那么多线程更适合一些,因为可以避免每个进程都自己保留一份cache,增加内存使用。(这一点可以用共享内存来解决,如果这些基础参考数据只是读取而不修改的话)
(2)memcached这个内存消耗大户用多线程服务端就比在同一台机器上运行多个memcached instance要好。(但如果你在16GiB内存的机器上运行32-bit memcached,那么此时多instance是必需的)
(3)求解Sudoku用不了多大内存。如果是单线程编程更方便的话,可以用单线程多进程来做。再在前面加一个单线程的load balancer,仿lighttpd+fastcgi的成例。
线程不能减少工作量,即不能减少CPU时间。如果解决一个问题需要执行一亿条指令(这个数字不大),那么用多线程只会让这个数字增加。但是通过合理调配这一亿条指令在多个核上的执行情况,我们能让工期提早结束。这听上去像统筹方法(指在管理、规划或决策中采用综合性的方法来考虑多个因素或利益相关者的需求和目标,这种方法旨在通过协调和整合各种因素,以达到整体的最佳效果或目标),其实也确实是统筹方法。
相关文章:
Linux多线程服务端编程:使用muduo C++网络库 学习笔记 第三章 多线程服务器的适用场合与常用编程模型
本文中的多线程服务器指运行在Linux上的独占式网络应用程序。硬件平台为Intel x86-64系列的多核CPU,单路或双路SMP(Symmetric Multi-Processing,对称多处理,它是一种多核处理器架构,其中多个CPU核心共享系统的内存和其…...
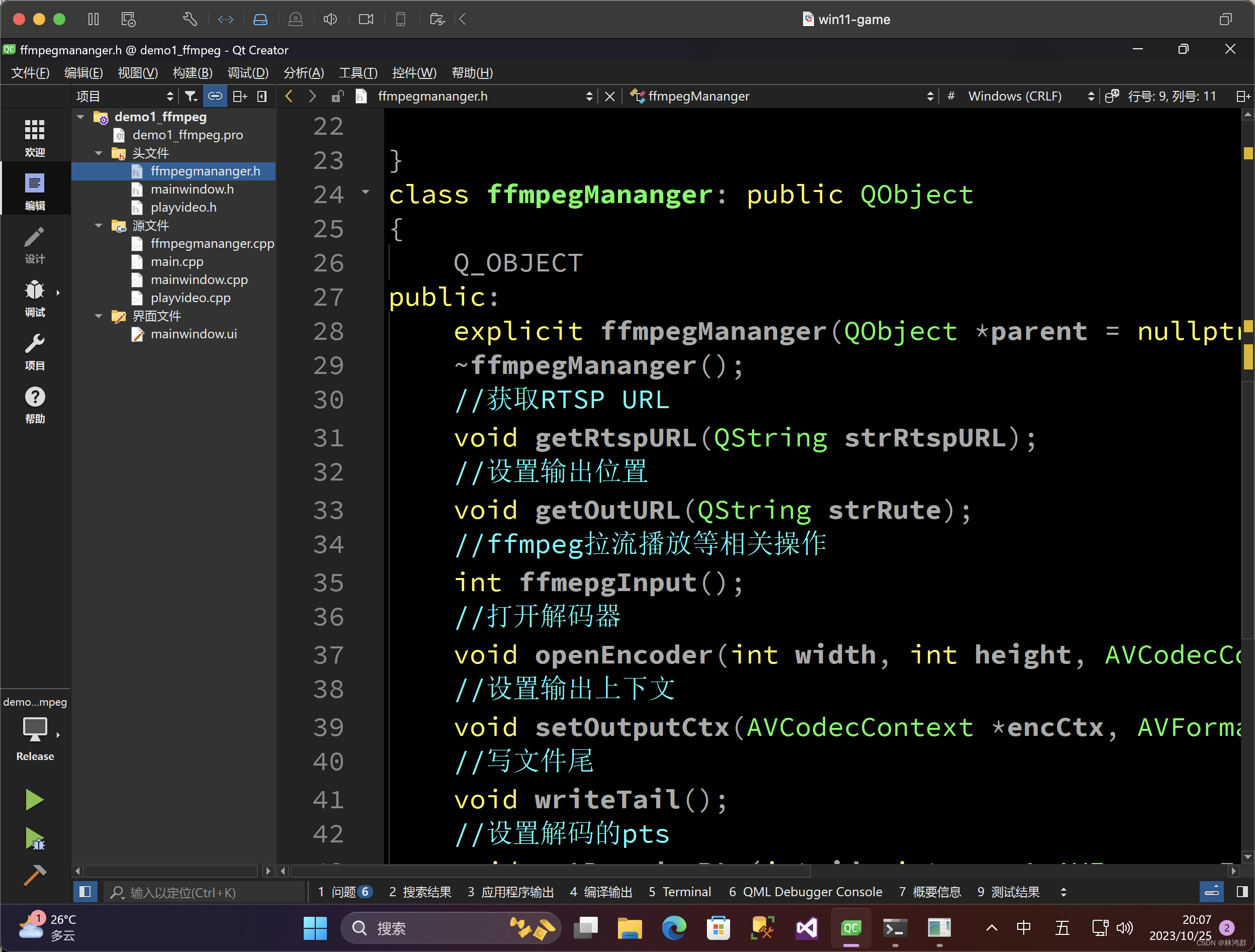
windows下使用FFmpeg开源库进行视频编解码完整步聚
最终解码效果: 1.UI设计 2.在控件属性窗口中输入默认值 3.复制已编译FFmpeg库到工程同级目录下 4.在工程引用FFmpeg库及头文件 5.链接指定FFmpeg库 6.使用FFmpeg库 引用头文件 extern "C" { #include "libswscale/swscale.h" #include "libavdevic…...
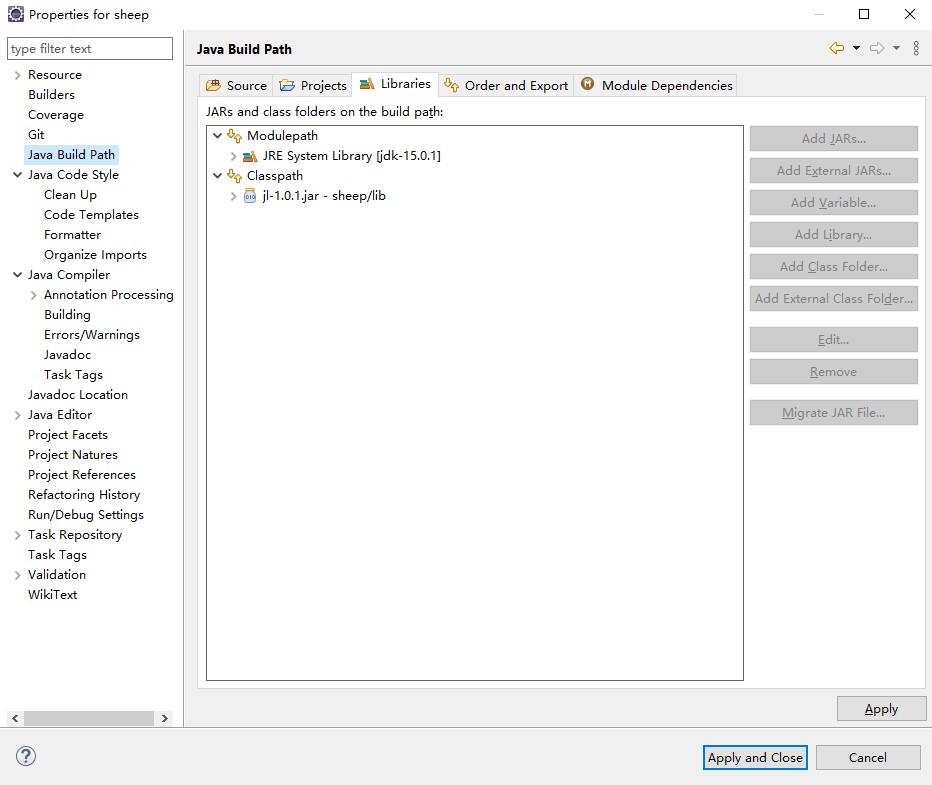
如何更改eclipse的JDK版本
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、有时候导入一些网上的资源需要更换JDK二、使用步骤1. 总结 一、有时候导入一些网上的资源需要更换JDK 具体操作如下 二、使用步骤 1. 在eclipse上方工具栏找…...
HarmonyOS第一课运行Hello World
前言 俗话说,工欲善其事必先利其器。鸿蒙第一课,我们先从简单的Hello World运行说起。要先运行Hello World,那么我们必须搭建HarmonyOS的开发环境。 下载与安装DevEco Studio 在HarmonyOS应用开发学习之前,需要进行一些准备工作&a…...

解决el-tooltip滚动时悬浮框相对位置发生变化
获取最外层box的class,并在内层添加el-scrollbar <template><div class"ChartsBottom"><el-scrollbar><ul class""><li v-for"(item, index) in list" :key"index"><div class"con…...

Java精品项目源码第61期汽车零件销售商城系统(代号V063)
Java精品项目源码第61期汽车零件销售商城系统(代号V063) 大家好,小辰今天给大家介绍一个汽车零件销售商城系统,演示视频公众号(小辰哥的Java)对号查询观看即可 文章目录 Java精品项目源码第61期汽车零件销售商城系统(代号V063)难…...

Python OpenCV剪裁图片并修改对应的Labelme标注文件
Python OpenCV剪裁图片并修改对应的Labelme标注文件 前言前提条件相关介绍实验环境剪裁图片并修改对应的Labelme标注文件代码实现 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-P…...

【JAVA学习笔记】44 - 注解,元注解
项目代码 一、注解的引入 1)注解(Annotation)也被称为元数据(Metadata),用于修饰解释包、类、方法、属性、构造器、局部变量等数据信息。 2)和注释一样,注解不影响程序逻辑,但注解可以被编译或运行,相当于嵌入在代码中的补充信息。 3)在Ja…...

Android 安卓Kotlin-协程
当谈到现代异步编程时,Kotlin协程(Kotlin Coroutines)是一个备受欢迎的工具。它提供了一种更具可读性和可维护性的方式来处理异步任务,而无需陷入回调地狱。本篇博客将深入探讨Kotlin协程,涵盖其基本概念、用法、特性以…...
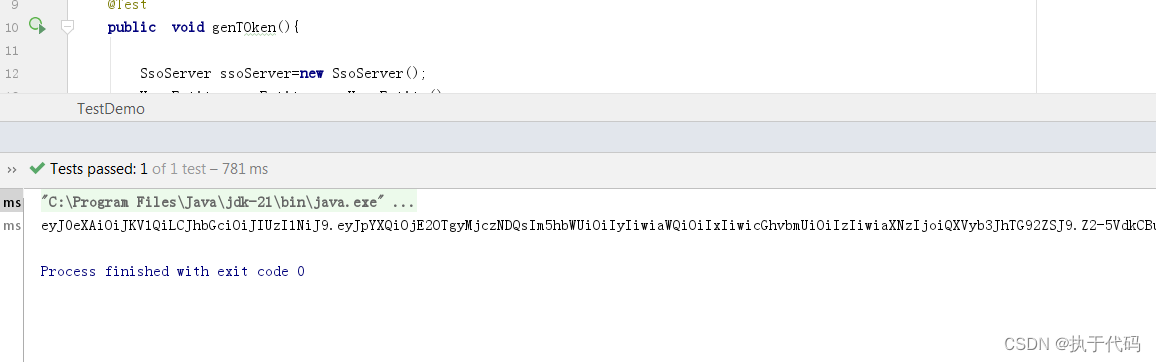
SSO 系统设计_token 生成
SSO 系统设计_token 生成 目录概述需求: 设计思路实现思路分析1.增加依赖2.代码编写3.测试 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wai…...

电表安数大小和省电有关吗?
电表的安数是指电表能够正常工作的电流范围,通常用来表示电表的容量。电表的安数越大,表示电表能够承受的电流就越大。电表的安数与省电之间并没有直接的关系,但是电表的安数大小会影响到电表的准确性和稳定性。如果电表的安数太小࿰…...

树上形态改变统计贡献:1025T4
http://cplusoj.com/d/senior/p/SS231025D 答案为 ∑ w [ x ] − w [ s o n [ x ] ] \sum w[x]-w[son[x]] ∑w[x]−w[son[x]], x x x 非儿子 要维护断边,LCT固然可以,但不一定需要 发现如果发生了变化,只会由重儿子变成次重儿子…...

如何处理与智能床相关的医疗建议和医疗器械证明?
如何处理与智能床相关的医疗建议和医疗器械证明? 摘要:作为一名iOS技术博主,我遇到了一个困扰,我的应用在审核中被拒绝了。这次拒绝涉及到我们公司生产的智能床,该床收集用户的体征数据并提供睡眠建议。苹果指出我们未…...

云原生之深入解析如何合并多个kubeconfig文件
项目通常有多个 k8s 集群环境,dev、testing、staging、prod,kubetcl 在多个环境中切换,操作集群 Pod 等资源对象,前提条件是将这三个环境的配置信息都写到本地机的 $HOME/.kube/config 文件中。默认情况下kubectl会查找$HOME/.kub…...
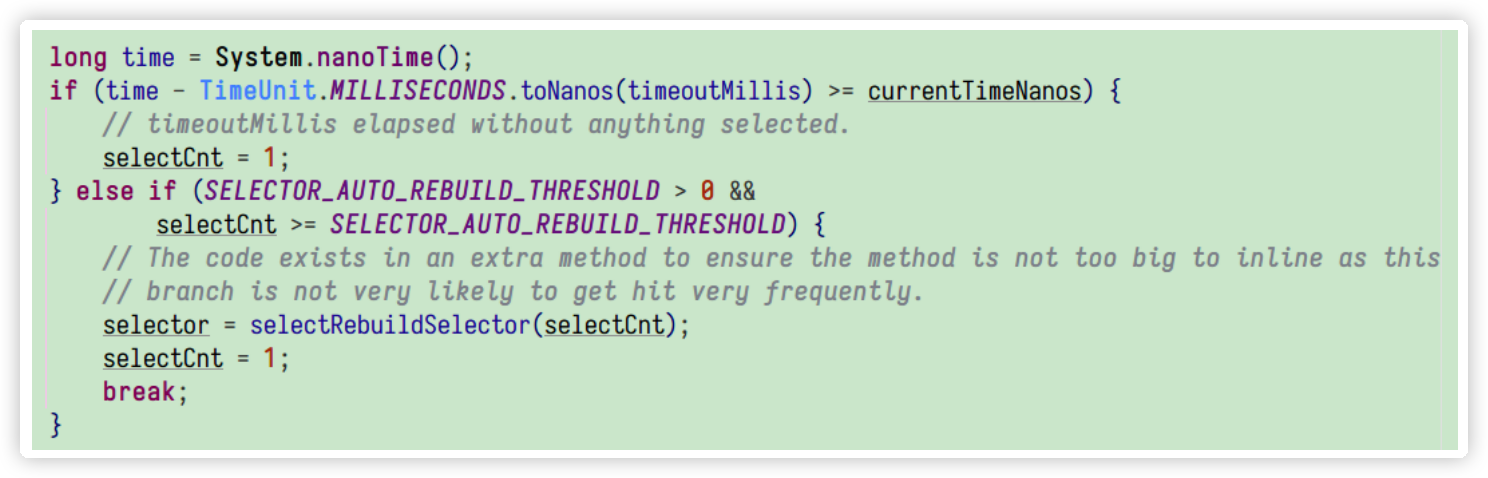
Netty实战-实现自己的通讯框架
通信框架功能设计 功能描述 通信框架承载了业务内部各模块之间的消息交互和服务调用,它的主要功能如下: 基于 Netty 的 NIO 通信框架,提供高性能的异步通信能力;提供消息的编解码框架,可以实现 POJO 的序列化和反序…...
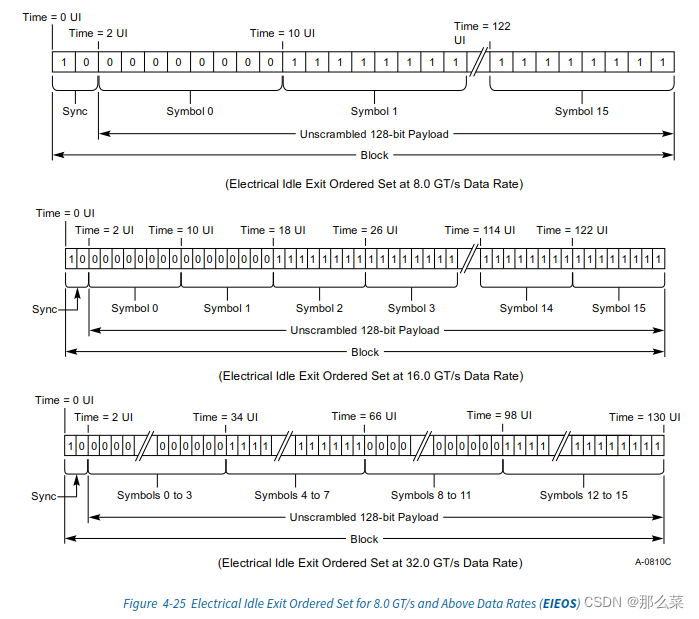
S4.2.4.3 Electrical Idle Sequence(EIOS)
一 本章节主讲知识点 1.1 EIOS的具体码型 1.2 EIOS的识别规则 1.3 EIEOS的具体码型 二 本章节原文翻译 当某种状态下,发送器想要进入电器空闲状态的时候,发送器必须发送EIOSQ,也既是:电器Electrical Idle Odered Set Sequenc…...

MySQL的优化利器:索引条件下推,千万数据下性能提升273%
MySQL的优化利器:索引条件下推,千万数据下性能提升273%🚀 前言 上个阶段,我们聊过MySQL中字段类型的选择,感叹不同类型在千万数据下的性能差异 时间类型:MySQL字段的时间类型该如何选择?千万…...

回归预测 | MATLAB实现BO-BiLSTM贝叶斯优化双向长短期神经网络多输入单输出回归预测
回归预测 | MATLAB实现BO-BiLSTM贝叶斯优化双向长短期神经网络多输入单输出回归预测 目录 回归预测 | MATLAB实现BO-BiLSTM贝叶斯优化双向长短期神经网络多输入单输出回归预测效果一览基本介绍模型搭建程序设计参考资料 效果一览 基本介绍 MATLAB实现BO-BiLSTM贝叶斯优化双向长…...

SOCKS5代理在全球电商、游戏及网络爬虫领域的技术创新
随着全球化进程的加速,跨界电商和游戏行业的出海战略愈发重要。在这个大背景下,技术如SOCKS5代理和网络爬虫成为连接不同领域、优化用户体验和提升市场竞争力的重要桥梁。本文将深入探讨SOCKS5代理技术在跨界电商、游戏和网络爬虫领域的应用及其对行业发…...
Flutter extended_image库设置内存缓存区大小与缓存图片数
ExtendedImage ExtendedImage 是一个Flutter库,用于提供高级图片加载和显示功能。这个库使用了 image 包来进行图片的加载和缓存。如果你想修改缓存大小,你可以通过修改ImageCache的配置来实现。 1. 获取ImageCache实例: 你可以通过PaintingBinding…...

OAuth 2.0 and OIDC 三大安全机制对比:State vs Nonce vs PKCE
一、问题背景 OAuth 2.0 和 OpenID Connect 的授权流程依赖浏览器重定向,这天然暴露了多种攻击面: 攻击类型描述CSRF攻击者诱导用户的浏览器携带恶意授权码完成绑定Token 重放窃取的 id_token 被重复提交给客户端授权码劫持恶意应用在同一设备上拦截授…...

从零构建高性能技术博客:SSG选型、自动化部署与SEO优化实战
1. 项目概述:一个技术博客的诞生与演进“wangtunan/blog”,这看起来只是一个简单的GitHub仓库名,背后却是一个技术人持续输出、构建个人知识体系的完整实践。它不仅仅是一个存放Markdown文件的代码库,更是一个集成了现代前端技术栈…...

杰理701N可视化SDK:从stream.bin生成到工程导入的EQ调音闭环
1. 杰理701N可视化SDK与EQ调音基础 第一次接触杰理701N的开发者可能会好奇,这个可视化SDK到底能做什么?简单来说,它就像给声学工程师配了一把"声音雕刻刀"。通过图形化界面,你可以实时调整蓝牙耳机、音箱等设备的音效表…...

DLSS Swapper终极指南:免费开源工具让游戏DLSS管理变得简单快速
DLSS Swapper终极指南:免费开源工具让游戏DLSS管理变得简单快速 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 如果你正在寻找一款能够智能管理游戏DLSS、FSR和XeSS文件的免费开源工具,那么DLS…...

如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南
如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否厌倦了每次启动Minecraft都要手动配…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...

LC正弦波振荡器原理、设计与调试:从巴克豪森判据到电路实战
1. 从直流到交流:正弦波振荡器的核心价值与分类在电子电路的世界里,我们常常需要将稳定的直流电源,转换成特定频率和幅度的交流信号。这个看似“无中生有”的过程,正是正弦波振荡器的核心使命。无论是你手机里的无线通信模块、收音…...

柔性3D打印与生物仿生设计:从TPU材料到空气喷涂的完整实践
1. 项目概述:当柔性3D打印遇上生物仿生美学如果你和我一样,玩3D打印玩久了,总会对那些千篇一律的硬质塑料件感到一丝审美疲劳。我们总在追求更高的精度、更强的结构,却常常忽略了材料本身可以带来的、截然不同的体验。直到我开始接…...

基于CircuitPython的嵌入式游戏开发:从帧缓冲区到对象池的Flappy Bird实现
1. 项目概述:当Flappy Bird遇上CircuitPython如果你玩过经典的Flappy Bird,也捣鼓过像Raspberry Pi Pico这样的微控制器,那你有没有想过把这两者结合起来?我最近就用CircuitPython在RP2040开发板上完整复刻了一个“猫版”Flappy B…...

3分钟快速上手:m4s-converter让B站缓存视频秒变MP4格式
3分钟快速上手:m4s-converter让B站缓存视频秒变MP4格式 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在当今数字内容时代ÿ…...