堆(二叉树,带图详解)
一.堆
1.堆的概念
2.堆的存储方式
逻辑结构
物理结构
2.堆的插入问题
3.堆的基本实现(代码)(以小堆为例)
1.堆的初始化
2. 向上调整
3.插入结点
4. 交换函数、堆的打印
5.向下调整
6.删除根节点并调整成小根堆
7.获取堆顶的元素
8.判断栈是否为空
9.另一种初始化数组的方法
10.两种实现堆排序的方法的比较
二、堆的应用与实现
1.堆的升序写法
升序堆:
2.向下调整建堆(大堆)
总结
🗡CSDN主页:d1ff1cult.🗡
🗡代码云仓库:d1ff1cult.🗡
🗡文章栏目:数据结构专栏🗡
一.堆
1.堆的概念
如果有一个关键码的集合K = { , , ,…, },把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,并满足: <= 且
<= ( >= 且 >= ) i = 0,1,
2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆是一种非线性结构,是完全二叉树
堆分为小根堆(小堆)和大根堆(大堆)两种,小堆中所有的父节点均小于他的子结点,大堆中所有的父结点均大于子节点。
堆的底层用数组存储
小根堆:
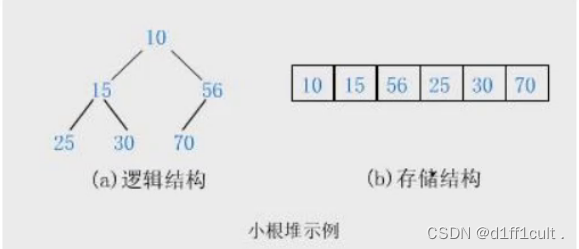
大根堆:
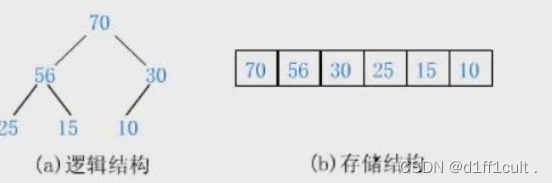
顺序存储下左右子树与父节点之间的关系:
leftchild=parent*2+1;rightchild=parent*2+2;
parent=(child-1)/2;
2.堆的存储方式
🗡逻辑结构
这里的逻辑结构是我们为了可以更好的李姐而想象出来的
🗡物理结构
堆在内存中就是这样存储的

2.堆的插入问题


插入90我们发现该堆仍然是小堆,其实这是一个巧合,当我们插入50的时候发现该堆不再是一个小堆,我们此时需要不断地对50进行调整才能使得该堆重新成为小堆。
接下来继续向堆中插入一个5
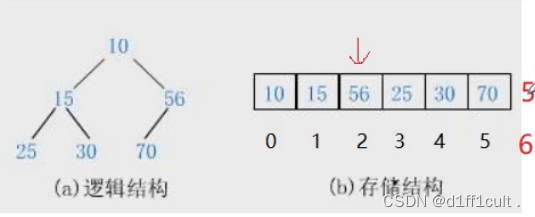
插入数据后调整的基本思路:此时5的下标为6,根据5的下标找到5的父亲结点(5-1)/2=2 ,5的父亲结点为56,再让5与56比较大小,发现56>5所以将56和5的位置进行交换,再继续让交换后的5找父亲节点,5的父亲结点的下标为(2-1)/2=0,5的父亲结点为10,再将5与10继续比较,10>5进行交换,此时5的下标为0为根节点,调整完毕。
第一次进行交换:56与5进行比较 5<56 交换5和56
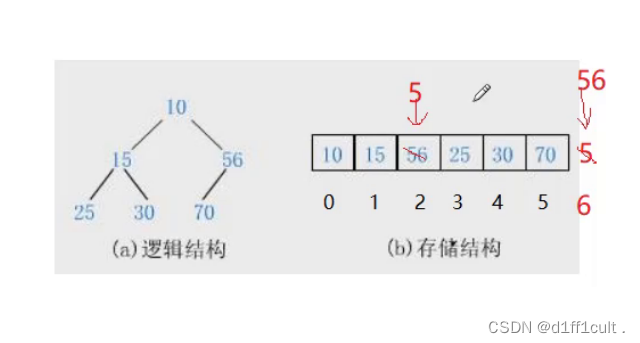
第二次进行交换: 找到交换后的5的父节点10,将10与5进行比较5<10则交换5与10的位置

很奇怪,这个最后插入的5 从孙子一跃成为了爷爷(bushi
3.堆的基本实现(代码)(以小堆为例)
下面介绍几个主要的实现堆的函数。
typedef int HPDataType;typedef struct Heap
{HPDataType* a;int size;int capacity;
}HP;
void Swap(HPDataType* a, HPDataType* b);
void HeapPrint(HP* php);
void HeapInit(HP* php);
void HeapDestroy(HP* php);
void HeapPush(HP* php, HPDataType x);
void HeapPop(HP* php);
HPDataType HeapTop(HP* php);
void AdjustUp(HPDataType* a, int child);
void AdjustDown(HPDataType* a,int n,int parent);
bool HeapEmpty(HP* php);
void HeapInitArray(HP* php, int* a, int n);
void HeapSor🗡堆的初始化
将数组和容量以及数组大小全部置空。
void HeapInit(HP* php)
{assert(php);php->a = NULL;php->capacity = 0;php->size = 0;
}🗡向上调整
将插入的结点一步步调整,使该堆再次成为小堆
向上调整的前提:前面的数据是堆
AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child>0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (parent - 1) / 2;}else{break;}}
}🗡插入结点
插入一个结点,并将其调整成为一个小堆
void HeapPush(HP* php, HPDataType x)
{assert(php);if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDataType* tmp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * newcapacity);if (tmp == NULL){perror("realloc fail");}php->a = tmp;php->capacity = newcapacity;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size-1);
}🗡交换函数、堆的打印
void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}//交换函数
void HeapPrint(HP* php)
{assert(php);for (int i = 0; i < php->size; i++){printf("%d ", php->a[i]);}printf("\n");
}//堆的打印函数🗡向下调整
向下调整的前提:根结点左右子树都是堆
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while(child<n){if (child+1<n&&a[child] > a[child + 1])//保证child存的是左右孩子里面较小的那一个{++child;}if (a[child] < a[parent])// 父节点与两个儿子中较小的一个交换位置{Swap(&a[child], &a[parent]);parent = child;child = child * 2 + 1;}else{break;}}
}🗡删除根节点并调整成小根堆
void HeapPop(HP* php)
{assert(php); assert(php->size > 0);Swap(&php->a[0], php->a[php->size - 1]);--php->size;AdjustDowm(php->a, php->size, 0);
}
🗡获取堆顶的元素
HPDataType HeapTop(HP* php)
{assert(php);assert(php->size > 0);return php->a[0];
}🗡判断栈是否为空
bool HeapEmpty(HP* php){assert(php);return php->size == 0;}🗡另一种初始化数组的方法
void HeapInitArray(HP* php, int* a, int n){assert(php);assert(a);php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);if (php->a == NULL){perror("malloc fail");exit(-1);}php->size = n;php->capacity = n;memcpy(php->a, a, sizeof(HPDataType) * n); for (int i = 0; i < n; i++){AdjustUp(php->a, i);}}🗡两种实现堆排序的方法的比较
下面是使用HeapPush()函数实现堆排的过程 :
void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child>0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (parent - 1) / 2;}else{break;}}
}
void HeapPush(HP* php, HPDataType x)
{assert(php);if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDataType* tmp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * newcapacity);if (tmp == NULL){perror("realloc fail");}php->a = tmp;php->capacity = newcapacity;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size-1);
}这种方法是通过malloc函数开辟一块一块的空间,并通过不断地扩容将数据push到数组中,再对数组中的内容进行不断的向上调整从而达到堆排的目的。
下面是用AdjustUp()函数实现堆排的过程:
void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child>0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (parent - 1) / 2;}else{break;}}
}
void HeapSort(int* a, int n)
{for (int i = 0; i < n; i++){AdjustUp(a, i);}
}这种方法与HeapPush函数不同的地方在于该函数传参数时直接传入一个数组,省去了malloc开辟空间的消耗。
二、堆的应用与实现
🗡堆的升序写法
通常这里我们都会问一个问题,实现升序排序我们应该建一个小堆还是一个大堆?
答案是,升序时我们应该建一个大堆,那么为什么呢?
我们都知道小堆的根节点是整棵二叉树中最小的值,选出了最小的值之后,我们还要去找次小的值
首先是建小堆不适用的原因,这里有这样一个数组,我们将这个数组展开:
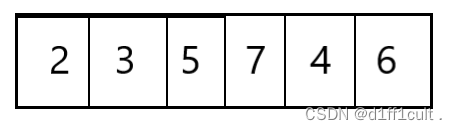
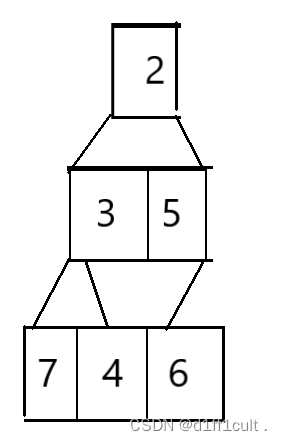
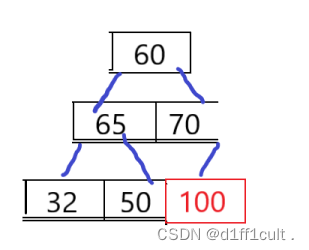
按照我们需要建升序堆的要求,我们会将最小的根节点删除掉,删除后如下图所示
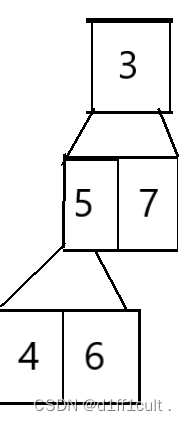
我们发现这个二叉树不再是堆,但是我们要选择次小值的话需要进行调整,就需要重新建堆,建堆的时间复杂度为o(n)=n*logn,代价还是比较大的,甚至不如遍历一遍来的快,所以我们这里摒弃了建小堆的想法,那么接下来就看看建大堆的优势在哪里了
建大堆的基本思想以及优势:
我们排升序,建一个大堆,将根节点和最后一个结点交换位置,那么最大的数就被交换到了数组的最后面,此时一个数字已经排好了,原本根节点的左右子树还是堆,我们就可以通过向下调整,来找出次打的值,此时我们不再把交换到数组最后的根节点看作树的结点,对剩下的数字进行向下调整,找出了次小的值,这里的时间复杂度O(n)仅仅为logn合计起来n个结点的时间复杂度O(n)=n*logn,消耗比较小。再与树的最后一个结点进行交换。过程我们用下面的数组进行演示。

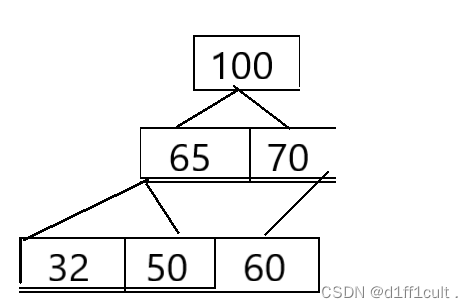
将根节点的数字与树的最后一个结点的数字进行交换,并不再把交换到后面的根节点看作树的内容
🗡升序堆:
void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child>0){if (a[child] > a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (parent - 1) / 2;}else{break;}}
}
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while(child<n){if (child+1<n&&a[child] > a[child + 1])//保证child存的是左右孩子里面较小的那一个{++child;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = child * 2 + 1;}else{break;}}
}
void HeapSort(int* a, int n)
{for (int i = 0; i < n; i++){AdjustUp(a, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}🗡向下调整建堆(大堆)
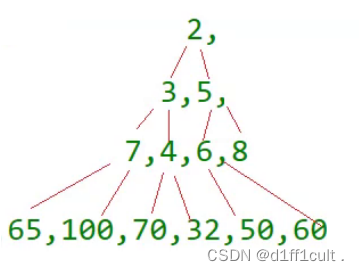
有这样一个数组,我们如果想通过用根节点直接向下调整建大堆,就必须保证根节点的左右子树都是大堆,所以我们就想出了倒着调整树的方法:
需要注意的是:单个叶子结点,既是大堆也是小堆。
这种建堆方法是从树的末尾开始找到第一个非叶子结点然后对其进行向下调整,从数组后面查找的第一个非叶子结点也就是树中最后一个结点的父节点,最后一个结点的下标为n-1,则它的父结点的下标为(n-1-1)/2 ,这棵树从后面查找的第一个非叶子结点是6,对6进行向下调整,如下图
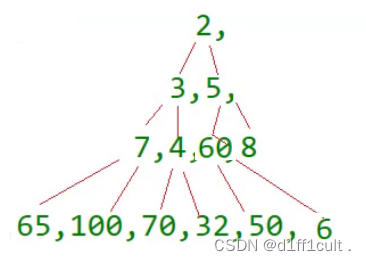
我们发现调整完成之后,结点5的左子树已经成为了大堆,右子树也是大堆,那我们就应该对下一个非叶子结点进行调整了,我们只需要将60位置的下标+1,就得到了下一个非叶子结点的下标,同理也对他进行调整,直到2的左右子树都调整为大堆
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while(child<n){if (child+1<n&&a[child] > a[child + 1])//保证child存的是左右孩子里面较小的那一个{++child;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = child * 2 + 1;}else{break;}}
}
void HeapSort(int* a, int n)
{//向上调整建堆(大堆或者小堆)//for (int i = 0; i < n; i++)//{// AdjustUp(a, i);//}//向下调整建堆for (int i = (n - 2) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}向上调整建堆,时间复杂度O(n)=n*logn,而向下调整建堆的时间复杂度O(n)=n.
总结
上述就是关于堆的一些知识,有不懂的地方欢迎提问。
相关文章:
堆(二叉树,带图详解)
一.堆 1.堆的概念 2.堆的存储方式 逻辑结构 物理结构 2.堆的插入问题 3.堆的基本实现(代码)(以小堆为例) 1.堆的初始化 2. 向上调整 3.插入结点 4. 交换函数、堆的打印 5.向下调整 6.删除根节点并调整成小根堆 7.获取堆…...
vue3 code format bug
vue code format bug vue客户端代码格式化缺陷,为了方便阅读和维护,对代码格式化发现这个缺陷 vue.global.min.3.2.26.js var Vuefunction(r){"use strict";function e(e,t){const nObject.create(null);var re.split(",");for(le…...

7-3、S曲线生成器【51单片机控制步进电机-TB6600系列】
摘要:本节介绍步进电机S曲线生成器的计算以及使用 一.计算原理 根据上一节内容,已经计算了一条任意S曲线的函数。在步进电机S曲线加减速的控制中,需要的S曲线如图1所示,横轴为时间,纵轴为角速度,其中w0为起…...
CDC实时数据同步
一丶CDC实时数据同步介绍 CDC实时数据同步指的是Change Data Capture(数据变更捕获)技术在数据同步过程中的应用。CDC技术允许在数据源发生变化时,实时地捕获这些变化,并将其应用到目标系统中,从而保持数据的同步性。…...
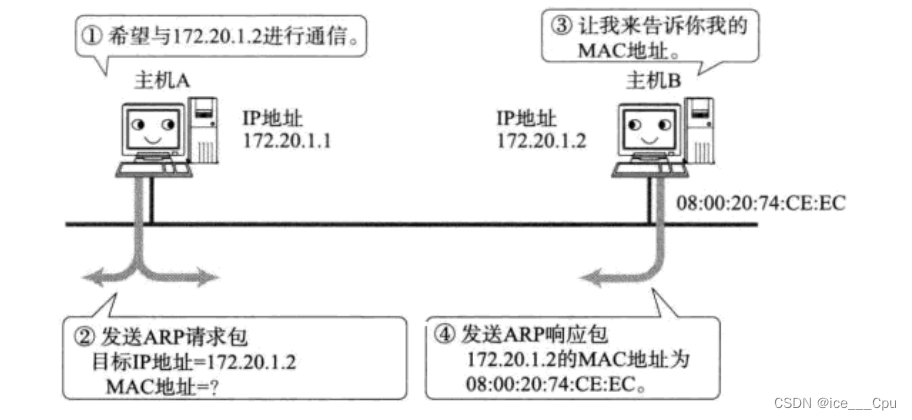
javaEE -10(11000字详解5层重要协议)
一:应用层重点协议 1.1: DNS DNS,即Domain Name System,域名系统。DNS是一整套从域名映射到IP的系统。 TCP/IP中使用IP地址来确定网络上的一台主机,但是IP地址不方便记忆,且不能表达地址组织信息&#x…...

360智慧生活旗舰产品率先接入“360智脑”能力实现升级
10月25日,360智慧生活秋季新品及视觉云方案发布会在深圳召开。360智能硬件产品,诸如 360可视门铃、360智能摄像机、360行车记录仪、360儿童手表和家庭防火墙等,都在各自的行业有着举足轻重得地位,而这次发布的系列新品,…...

【系统架构设计】 架构核心知识: 2 云原生架构
目录 一 云原生架构 1 云计算 2 分类 3 云计算架构 4 云原生架构设计原则...
Unity - 导出的FBX模型,无法将 vector4 保存在 uv 中(使用 Unity Mesh 保存即可)
文章目录 目的问题解决方案验证保存为 Unity Mesh 结果 - OK保存为 *.obj 文件结果 - not OK,但是可以 DIY importer注意References 目的 备忘,便于日后自己索引 问题 为了学习了解大厂项目的效果: 上周为了将 王者荣耀的 杨玉环 的某个皮肤…...

【疯狂Java】数组
1、一维数组 (1)初始化 ①静态初始化:只指定元素,不指定长度 new 类型[] {元素1,元素2,...} int[] intArr; intArr new int[] {5,6,7,8}; ②动态初始化:只指定长度,不指定元素 new 类型[数组长度] int[] princes new in…...

leetcode 503. 下一个更大元素 II、42. 接雨水
下一个更大元素 II 给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是 nums[0] ),返回 nums 中每个元素的 下一个更大元素 。 数字 x 的 下一个更大的元素 是按数组遍历顺序,这个数字之后的第一个比它更大的数&…...
【德哥说库系列】-PostgreSQL跨版本升级
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...
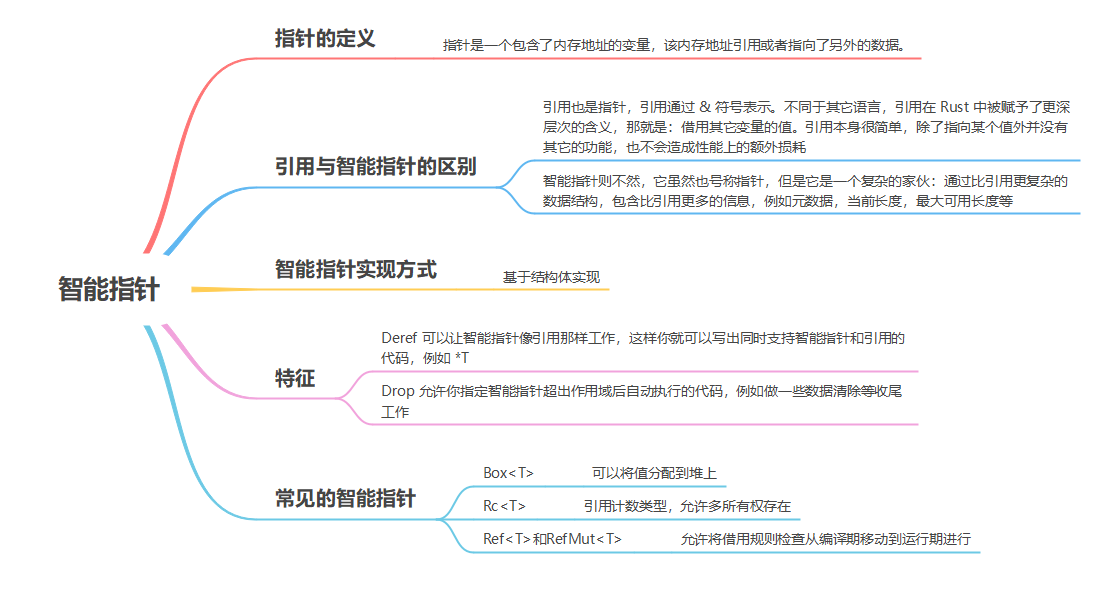
rust学习——智能指针
智能指针 在各个编程语言中,指针的概念几乎都是相同的:指针是一个包含了内存地址的变量,该内存地址引用或者指向了另外的数据。 在 Rust 中,最常见的指针类型是引用,引用通过 & 符号表示。不同于其它语言…...

系列一、Spring Framework
一、谈谈你对Spring的理解 Spring是一个生态,是一个轻量级的开源容器框架,可以构建Java应用所需要的一切基础设施,它的出现是为了解决企业级应用开发中业务逻辑层和其他各层对象与对象之间耦合的问题,通常情况下所说的Spring是指S…...

PULP Ubuntu18.04
1. 安装eda工具:questasim_10.7_linux64,网上有教程和方法,如有问题,可私信我 2. 代码下载: git clone https://github.com/pulp-platform/pulp 编译代码 cd pulp source setup/vsim.sh make checkout make scripts …...

Docker harbor私有仓库部与管理
目录 搭建本地私有仓库 Docker容器的重启策略 Harbor 简介 什么是Harbor Harbor的特性 Harbor的构成 Docker harbor私有仓库部署 Harbor.cfg配置文件中的参数 维护管理Harbor 总结 搭建本地私有仓库 #首先下载 registry 镜像 docker pull registry#在 daemon.json …...
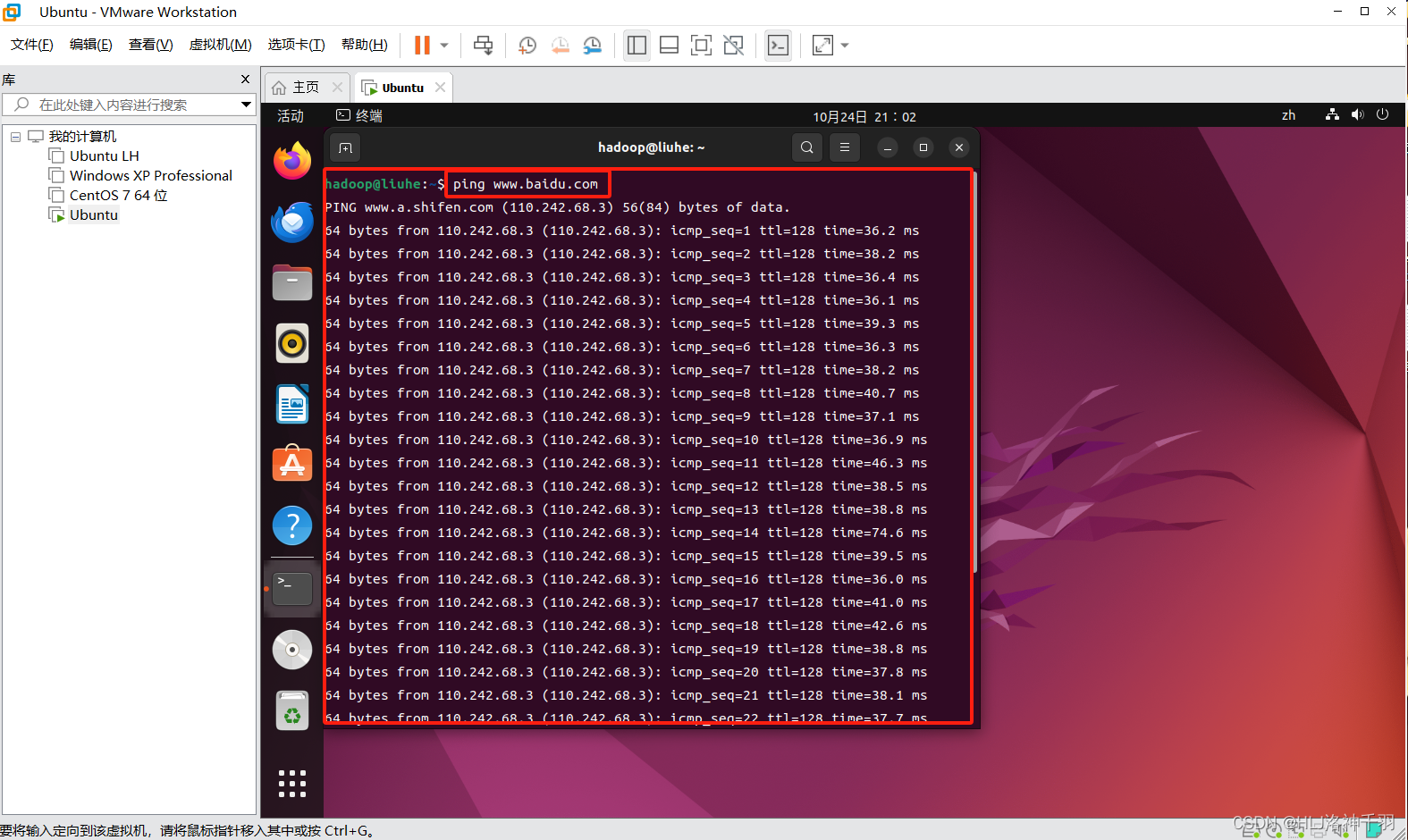
解决虚拟机联网问题
虚拟机开机后发现右上角缺少联网标志(下面有正常联网标志),这样就是连不上网的 不信你可以打开Ubuntu里面的浏览器或ping www.baidu.com 1.编辑虚拟机设置-->网络适配器-->如图所示 2.选择编辑-->虚拟网络编辑器 3.更改设置 4此处可以选择还原默认设置&am…...
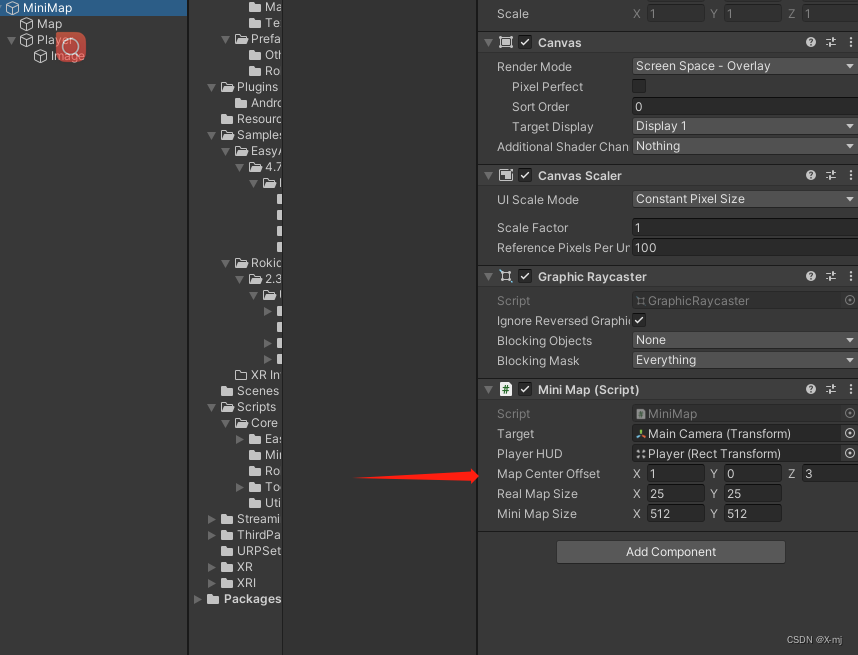
Unity 自定义小地图
最近工作做了个小地图,再此记录下思路。 1、准备所需素材 显示为地图(我们取顶视图)。创建一个Cube,缩放到可以把实际地图包住。实际地图的尺寸和偏移量 。我这里长宽都是25,偏移量(1,0&…...

力扣每日一题66:加一
题目描述: 给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。 最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。 你可以假设除了整数 0 之外,这个整数不会以零开头。 示例 1: 输…...
项目管理工具ConceptDraw PROJECT mac中文版自定义列功能
ConceptDraw PROJECT Mac是一款专业的项目管理工具,适用于MacOS平台。它提供了成功规划和执行项目所需的完整功能,包括任务和资源管理、报告和变更控制。 这款软件可以与ConceptDraw office集成,利用思维导图和数据可视化的强大功能来改进项目…...

Kafka-Java二:Spring实现kafka消息发送的ack机制
写在前面 如果只有一个kafka实例的话,那么文章中提到kafka集群kafka实例 一、什么是消息发送者端的ack机制 ack机制:消息确认发送成功的标识 由谁发起该标识:kafka集群 发起该标识的场景:kafka集群确认已经收到了消息。 由谁接收…...

163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具
163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量歌词而烦恼吗?163MusicLy…...

Codesys ST语言PID调参避坑指南:从仿真到实战,手把手教你搞定温控/电机项目
Codesys ST语言PID调参避坑指南:从仿真到实战的工程化解决方案 在工业自动化领域,PID控制算法占据着核心地位。无论是恒温控制、电机调速还是压力调节,一个精心调校的PID控制器往往能决定整个系统的性能表现。然而,许多工程师在掌…...

Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复“变砖“设备
Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复"变砖"设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器因固件升级失败、意外断电或系统崩…...

OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统
OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

免费额度即将失效?ElevenLabs 2024.6.1新规生效前,必须完成的5项额度迁移准备
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs免费额度机制的本质解析 ElevenLabs 的免费额度并非按“每月重置”的静态配额,而是一种基于账户生命周期的动态信用池(Credit Pool),其底层由实…...

Linuxbonding链路生产排障流程
Linuxbonding链路生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

DriveBench:面向真实驾驶场景的长序列多智能体交互基准测试框架
1. 项目概述:从“世界基准”到“驾驶基准”的演进如果你在自动驾驶或者计算机视觉领域摸爬滚打过几年,一定对“基准测试”(Benchmark)这个词又爱又恨。爱的是,它提供了一个相对公平的擂台,让不同算法、不同…...

Forge模组开发效率提升:Gradle插件自动化构建与热部署实践
1. 项目概述:一个为Forge模组开发者准备的“瑞士军刀”如果你是一名Minecraft Forge模组的开发者,或者你正打算踏入这个充满创造力的领域,那么你大概率经历过这样的场景:为了测试一个简单的功能改动,你需要反复地执行g…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

AXI交叉开关IP核:SoC内部高并发数据传输的核心枢纽设计与实战
1. 项目概述:一个高效、可配置的片上总线交叉开关在复杂的数字系统设计,尤其是片上系统(SoC)领域,多个主设备(如CPU、DMA控制器)需要同时访问多个从设备(如内存、外设控制器…...