【Gan教程 】 什么是变分自动编码器VAE?

名词解释:Variational Autoencoder(VAE)
一、说明
为什么深度学习研究人员和概率机器学习人员在讨论变分自动编码器时会感到困惑?什么是变分自动编码器?为什么围绕这个术语存在不合理的混淆?本文从两个角度理解变分自动编码器(VAE):深度学习和图形模型。
在概念和语言上存在差距。神经网络和概率模型的科学没有共享语言。我的目标是弥合这一想法差距,允许这些领域之间进行更多的协作和讨论,并提供一致的实现(Github链接)。如果这里的许多单词对您来说是新的,请跳转到词汇表。
变分自动编码器很酷。它们使我们能够设计复杂的数据生成模型,并将它们拟合到大型数据集中。他们可以生成虚构名人面孔的图像和高分辨率数字艺术品。

这些模型还在图像生成和强化学习中产生最先进的机器学习结果。变分自动编码器(VAEs)由Kingma等人和Rezende等人于2013年定义。
我们如何创建一种讨论变分自动编码器的语言?让我们首先使用神经网络来考虑它们,然后在概率模型中使用变分推理。
二、神经网络视角
在神经网络语言中,变分自动编码器由编码器、解码器和损失函数组成。
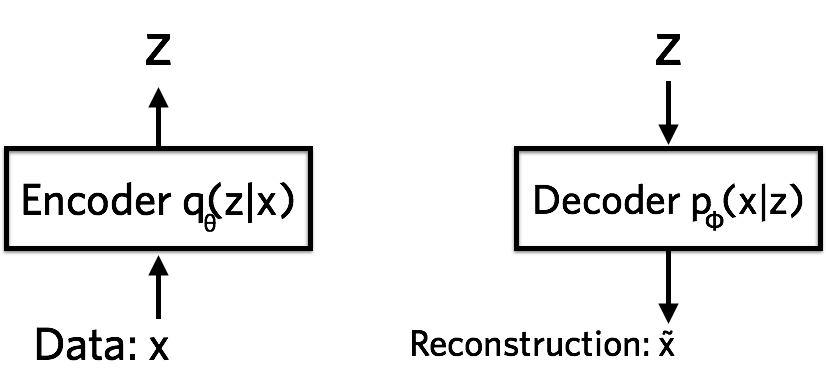
编码器将数据压缩到潜在空间 (Z) 中。解码器在给定隐藏表示的情况下重建数据。
编码器是一个神经网络。它的输入是一个数据点 x,其输出 是隐藏的表示形式z,并且具有权重和偏差θ. 具体来说,让我们说x是一张 28 x 28 像素的手写照片 数。编码器对以下数据进行“编码”:784784-维度成一个 潜在(隐藏)表示空间z,远小于784784尺寸。这通常被称为“瓶颈”,因为编码器 必须学会将数据有效地压缩到这个低维中 空间。让我们表示编码器.我们注意到, 低维空间是随机的:编码器将参数输出到
,这是一个高斯概率密度。我们可以样品 从此分布中获取表示的噪声值 z.
解码器是另一个神经网络。它的输入是表示 z它 将参数输出到数据的概率分布中,并且具有 权重和偏差 φ.解码器表示为 . 以手写数字为例运行,假设照片是黑色的,并且 白色,表示每个像素为00或11.概率分布 然后可以使用伯努利分布表示单个像素。这 解码器获取数字的潜在表示作为输入 z和输出784784伯努利参数,每个参数对应一个784-784图像中的像素。 解码器“解码”实值数字 z到784784实际价值 之间的数字00和11.原件信息784-784-维向量无法完美传输,因为解码器只能访问信息的摘要(以小于784x784-维度向量 z).丢失了多少信息?我们测量 这使用重建对数似然
.的 单位是 NAT。这个指标告诉我们解码器学会了多大的效率 重建输入图像 x鉴于其潜在的代表性 z.
变分自编码器的损失函数是带有正则化器的负对数似然。由于不存在所有数据点共享的全局表示,因此我们可以将损失函数分解为仅依赖于单个数据点的项li; 总体损失函数是:,其中,
对应的是
对应的损失函数。
![]()
第一项是重建损失,或预期的负对数似然 的我我-th数据点。期望是针对 编码器在表示上的分布。该术语鼓励 解码器来学习重建数据。如果解码器的输出没有 很好地重建数据,从统计学上讲,我们说解码器参数化了 对真实值没有太多概率质量的似然分布 数据。例如,如果我们的目标是对黑白图像和我们的模型进行建模 在实际存在黑点的地方存在高概率 白点,这将产生最糟糕的重建。穷 重建将产生很大的损失函数成本。
第二个术语是我们加入的正则表达式(我们将看到它是如何派生的 后来)。这是编码器之间的Kullback-Leibler背离度 分配和p(z).这种背离措施 使用时丢失的信息量(以 NAT 为单位)q代表p.这是衡量q是p接近程度的一种标准.
在变分自编码器中,p被指定为均值为零且方差为 1 的标准正态分布,或p(z)=Normal(0,1).如果编码器输出表示z与标准正态分布的 z 不同的,它将在损失中受到惩罚。这个正则项术语的意思是“保持表示每个数字的 z 足够多样化’。如果我们不包含正则化器,编码器可以学会作弊并为每个数据点提供欧几里德空间不同区域中的表示。
这很糟糕,因为然后两个相同数字的图像(例如由不同的人写的 2, 一个 和
) 最终可能会得到非常不同的表示形式:
,
.我们想要的表示空间 z为了有意义,所以我们惩罚这种行为。这具有使相似数字的表示保持紧密对齐的效果(例如,使数字二的表示
,
,
z保持足够近)。
如果编码器输出表示z 与标准正态分布的 z 不同,它将在损失中受到惩罚。
我们使用梯度下降训练变分自动编码器,以优化编码器和解码器参数的损耗 θ和 φ.对于具有步长的随机梯度下降 ρ,编码器参数使用l解码器也以类似方式更新。
2.1 概率模型透视
现在让我们从概率模型的角度考虑变分自动编码器。请暂时忘记你所知道的关于深度学习和神经网络的一切。将以下概念与神经网络分开思考将澄清事情。最后,我们将带回神经网络。
在概率模型框架中,变分自动编码器包含数据的特定概率模型 x和潜在变量 z.我们可以将模型的联合概率写为 p(x,z)=p(x∣ z)p(z).生成过程可以编写如下。
对于每个数据点i:
- 绘制潜在变量
- 绘制数据点
我们可以将其表示为图形模型:

模型在变分自动编码器中的图形模型表示。潜在变量 Z 是标准正态,数据来自 P(X|Z)。X 的阴影节点表示观测数据。对于手写数字的黑白图像,此数据可能性是伯努利分布的。
这是我们从概率模型角度讨论变分自动编码器时考虑的中心对象。潜在变量是从先验中提取的p(z).数据x有可能p(x∣z)以潜在变量为条件z.该模型定义了数据和潜在变量的联合概率分布:
p(x,z).我们可以将其分解为可能性和先验:p(x,z)=p(x∣ z)p(z).对于黑白数字,可能性是伯努利分布。
现在我们可以考虑这个模型中的推理了。目标是推断给定观测数据的潜在变量的良好值,或计算后验值p(z∣x).贝叶斯 说:
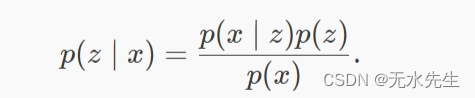
检查分母p(x).这被称为证据,我们可以通过边缘化潜在变量来计算它:p(x)=∫p(x∣ z)p(z)dz.不幸的是,这个积分需要指数时间来计算,因为它需要在潜在变量的所有配置上进行评估。因此,我们需要近似这种后验分布。
变分推理近似于具有一系列分布的后验.变分参数λ索引分布族。例如,如果q是高斯的,它将是每个数据点的潜在变量的均值和方差
![]()
我们怎么知道我们的变分后验有多好近似于真实后验
?我们可以使用Kullback-Leibler散度,它衡量使用时丢失的信息q近似值p(以纳特为单位):
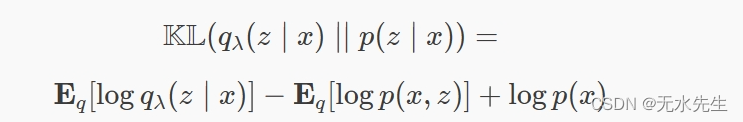
我们的目标是找到变分参数 λ这最大限度地减少了这种分歧。因此,最佳近似后验是:
![]()
为什么这无法直接计算?讨厌的证据 p(x)出现在背离中。如上所述,这是棘手的。我们还需要一个易于处理的变分推理的成分。请考虑以下函数:
![]()
请注意,我们可以将其与 Kullback-Leibler 散度相结合,并将证据重写为
![]()
根据詹森不等式,Kullback-Leibler背离总是大于或等于零。这意味着最小化Kullback-Leibler背离等效于最大化ELBO。缩写被揭示出来:证据下部允许我们进行近似的后验推理。我们不必计算和最小化近似和精确后验之间的Kullback-Leibler分歧。相反,我们可以最大化等效的 ELBO(但计算上易于处理)。
在变分自编码器模型中,只有局部潜在变量(没有数据点共享其潜在变量 z与另一个数据点的潜在变量)。因此,我们可以将 ELBO 分解为一个总和,其中每个项都依赖于单个数据点。这允许我们对参数使用随机梯度下降 λ(重要提示:变分参数在数据点之间共享 - 更多内容请点击此处)。变分自动编码器中单个数据点的 ELBO 为:
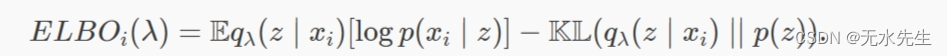
要看到这等效于我们之前对 ELBO 的定义,请将对数关节扩展到先验项和似然项,并对数使用乘积规则。
让我们与神经网络语言建立联系。最后一步是参数化近似后部 qθ(z∣x,λ)使用将作为输入数据的推理网络(或编码器) x和输出参数 λ.我们对可能性进行参数化 p(x∣z)使用生成网络(或解码器),该网络采用潜在变量并将参数输出到数据分布 pφ(x∣z).推理和生成网络具有参数 θ和 φ分别。参数通常是神经网络的权重和偏差。我们使用随机梯度下降来优化这些以最大化ELBO(没有全局潜在变量,因此小批量我们的数据是犹太洁食的)。我们可以编写 ELBO 并将推理和生成网络参数包含为:
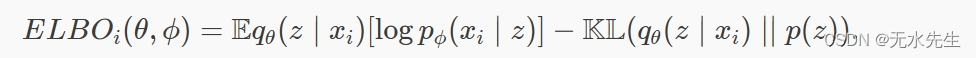
这个证据下限是我们从神经网络角度讨论的变分自动编码器的损失函数的负数;
. .然而,我们从关于概率模型和近似后验推理的原则推理中得出了它。我们仍然可以将Kullback-Leibler散度项解释为正则表达式,将预期可能性项解释为重建“损失”。但概率模型方法清楚地说明了这些术语存在的原因:最小化近似后验之间的Kullback-Leibler分歧 qλ(z∣x)和模型后部 p(z∣x).
模型参数呢?我们掩盖了这一点,但这是重要的一点。术语“变分推理”通常是指相对于变分参数最大化ELBO。 λ.我们还可以根据模型参数最大化 ELBO φ(例如,生成神经网络参数化可能性的权重和偏差)。这种技术称为变分EM(期望最大化),因为我们最大化了数据相对于模型参数的预期对数似然。
就是这样!我们遵循了变分推理的配方。我们已经定义了:
- 概率模型 p潜在变量和数据
- 变分族 q让潜在变量近似于我们的后验变量
然后我们用变分推理算法来学习变分参数(梯度上升在ELBO上学习 λ).我们使用变分EM作为模型参数(ELBO上的梯度上升来学习 φ).
2.2 实验
现在,我们已准备好查看模型中的示例。我们有两种选择来衡量进展:从先前或之后抽样。为了让我们更好地了解如何解释学习到的潜在空间,我们可以可视化潜在变量的后验分布。 qλ(z∣x)看来。
在计算上,这意味着输入图像 x通过推理网络得到正态分布的参数,然后取潜变量的样本 z.我们可以在训练期间绘制此图,以查看推理网络如何学习更好地近似后验分布,并将不同类别数字的潜在变量放置在潜在空间的不同部分。请注意,在训练开始时,潜在变量的分布接近先前的分布(一个圆形斑点00).
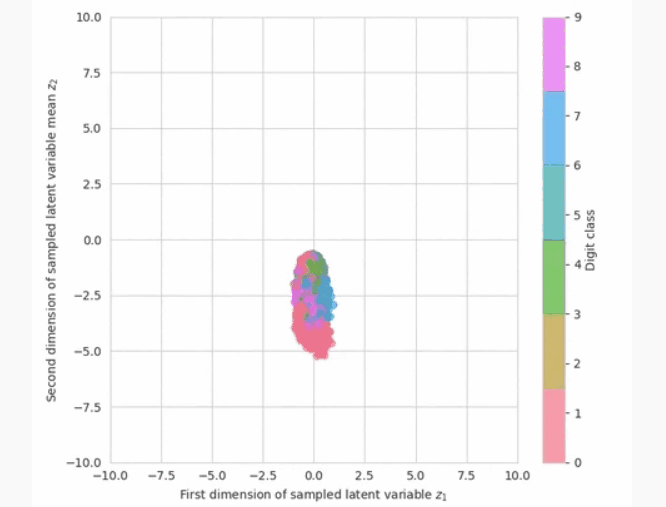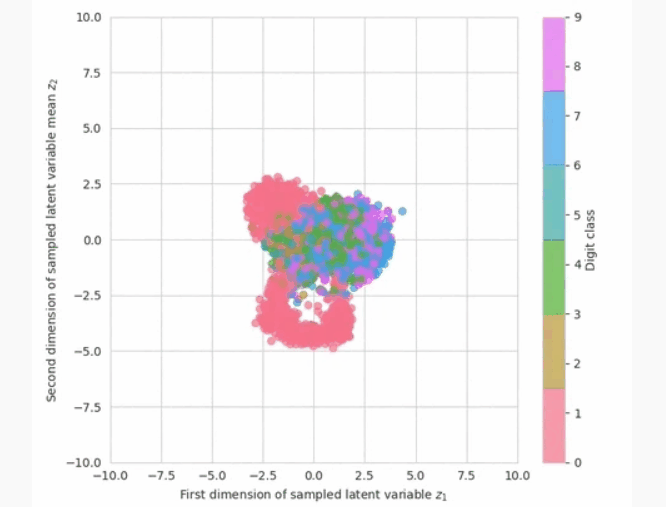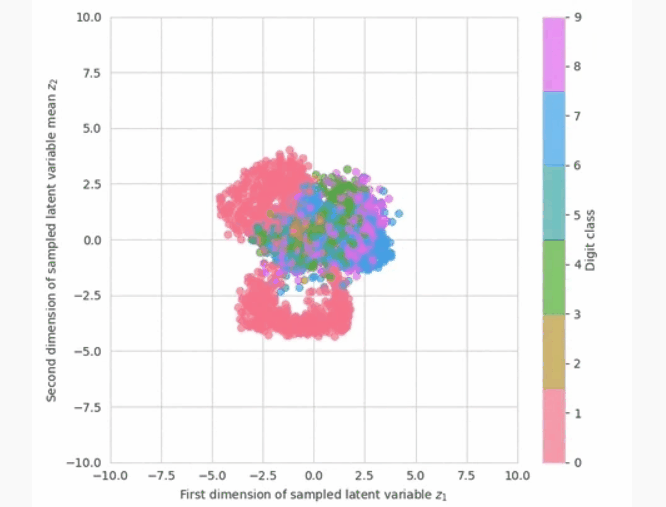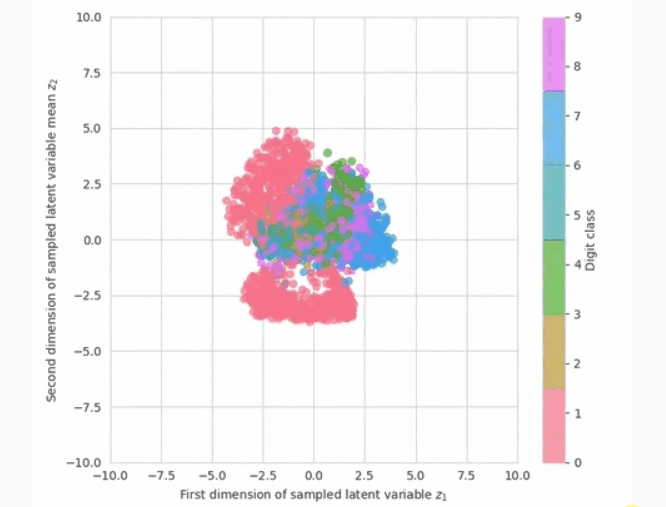
在训练期间可视化学到的近似后验。随着训练的进行,数字类在二维潜在空间中变得分化。
我们还可以可视化先前的预测分布。我们将潜在变量的值固定为在−3−3和33.然后我们可以从生成网络参数化的可能性中抽取样本。这些“幻觉”图像向我们展示了模型与潜在空间的每个部分相关联的内容。
通过查看可能性样本来可视化先前的预测分布。X 轴和 Y 轴表示 -3 到 3 之间的等间距潜在变量值(二维)。

三、变分学视角
3.1 词汇表
我们需要以清晰简洁的方式决定用于讨论变分自动编码器的语言。以下是我发现令人困惑的术语表:
- 变分自动编码器(VAE):在神经网络语言中,VAE由编码器、解码器和损失函数组成。在概率模型术语中,变分自动编码器是指潜在高斯模型中的近似推理,其中近似后验和模型似然由神经网络(推理和生成网络)参数化。
- 损失函数:在神经网络语言中,我们想到损失函数。训练意味着最小化这些损失函数。但在变分推理中,我们最大化 ELBO(这不是损失函数)。这会导致尴尬,例如在神经网络框架中调用优化器仅支持最小化。
optimizer.minimize(-elbo) - 编码器:在神经网络世界中,编码器是输出表示的神经网络 z数据数量 x.在概率模型术语中,推理网络参数化潜在变量的近似后验 z.推理网络将参数输出到分布 Q(z∣x).
- 解码器:在深度学习中,解码器是学习重建数据的神经网络 x给定一个表示 z.就概率模型而言,数据的可能性 x给定潜在变量 z由生成网络进行参数化。生成网络将参数输出到似然分布 p(x∣z).
- 局部潜在变量:这些是
对于每个数据点
.没有全局潜在变量。因为只有局部潜在变量,所以我们可以很容易地将ELBO分解为项
仅依赖于单个数据点 xi.这可以实现随机梯度下降。
- 推理:在神经网络中,推理通常意味着在给定新的、从未见过的数据点的情况下预测潜在表示。在概率模型中,推理是指在给定观测数据的情况下推断潜在变量的值。
3.2 均值场与摊销推理
这个问题对我来说非常令人困惑,我可以看到对于来自深度学习背景的人来说可能会更加困惑。在深度学习中,我们想到输入和输出、编码器和解码器以及损失函数。这可能会导致在学习概率建模时模糊、不精确的概念。
让我们讨论均值场推理与摊销推理有何不同。这是我们在进行近似推理以估计潜在变量的后验分布时面临的选择。我们可能有各种限制:我们是否有很多数据?我们有大型计算机或 GPU 吗?我们是否有局部的、每个数据点的潜在变量,还是在所有数据点之间共享的全局潜在变量?
均值场变分推理是指对变分分布的选择,该变分分布在 N数据点,没有共享参数:
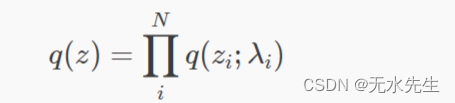
这意味着每个数据点都有空闲参数λi (例如对于高斯潜在变量)。我们如何为一个新的、看不见的数据点进行“学习”?我们需要最大化每个新数据点的 ELBO,相对于其平均场参数λi.
摊销推理是指跨数据点“摊销”推理成本。一种方法是共享(摊销)变分参数 λ跨数据点。例如,在变分自动编码器中,参数 θ的推理网络。这些全局参数在所有数据点之间共享。如果我们看到一个新的数据点并想看看它的近似后验是 看起来,我们可以再次运行变分推理(最大化 ELBO 直到收敛),或者相信共享参数“足够好”。与平均场相比,这可能是一个优势。
哪一个更灵活?平均场推理严格来说更具表现力,因为它没有共享参数。每个数据的参数λi可以确保我们的近似后验最忠实于数据。另一种思考方式是,我们通过跨数据点绑定参数来限制变分族的容量或表示能力(例如,使用跨数据共享权重和偏差的神经网络)。
四、示例 PyTorch/TensorFlow 实现
以下是用于生成本文中数字的实现:Github链接
4.1 脚注:重新参数化技巧
实现变分自编码器的最后一件事是如何取随机变量参数的导数。如果我们被给予 z从分布中提取的 qθ(z∣x),我们想要取函数的导数 z关于 θ,我们如何做到这一点?这 z样本是固定的,但直观地它的导数应该是非零的。
对于某些分布,可以以巧妙的方式重新参数化样本,以使随机性与参数无关。我们希望样本确定地依赖于分布的参数。例如,在具有平均值的正态分布变量中 μ和标准设计 σ,我们可以像这样从中采样:

这里 .从∼ 表示从分布到等号的抽签,= 是关键的一步。我们已经定义了一个确定性地依赖于参数的函数。因此,我们可以取函数的导数,包括 z, f(z)关于其分布参数 μ和 σ.
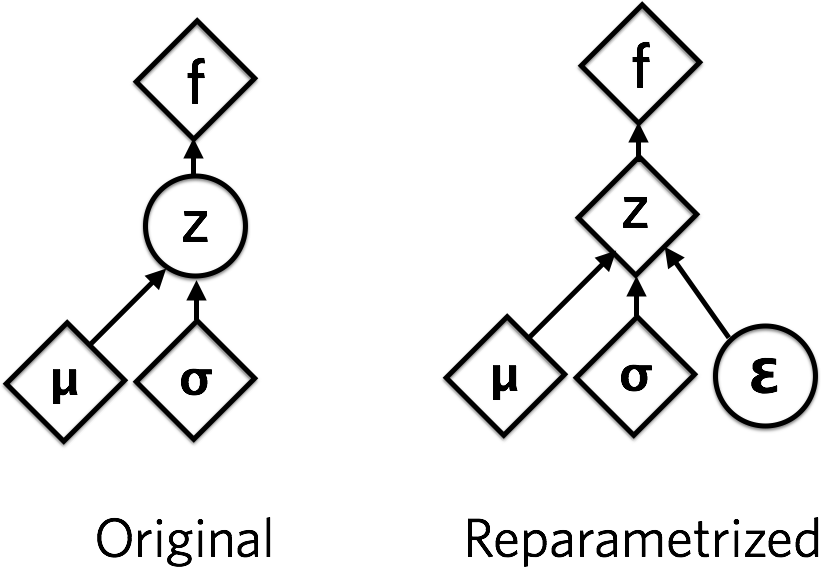
重新参数化技巧允许我们将正态分布随机变量 Z 的随机性推入 EPSILON,该 EPSILON 是从标准法线采样的。菱形表示确定性依赖关系,圆圈表示随机变量。
在变分自编码器中,均值和方差由带有参数的推理网络输出 θ我们优化。重新参数化技巧允许我们反向传播(使用链式规则取导数)关于 θ通过目标(ELBO),它是潜在变量样本的函数 z.
4.2 进一步阅读和改进
- 如果我们小心的话,伯努利可能性对于MNIST数据集来说是一个不正确的选择。手写数字“接近”二进制值,但实际上是连续的。本文修复了连续伯努利分布的问题。
五、参考资料
- 许多想法和数字来自Shakir Mohamed关于重新参数化技巧和自动编码器的优秀博客文章。 Durk Kingma创造了重新参数化技巧的伟大视觉效果。变分推理的重要参考是本教程和 David Blei 的课程笔记。Dustin Tran 有一篇关于变分自动编码器的有用博客文章。由变分自动编码器生成的标题分子样本来自本文。
- 感谢Rajesh Ranganath,Andriy Mnih,Ben Poole,Jon Berliner,Cassandra Xia和Ryan Sepassi在本文中的讨论和许多概念。感谢Batuhan Koyuncu重新生成GIF!
- 关于Hacker News和Reddit的讨论。在David Duvenaud的课程大纲“可微推理和生成模型”中出现。
相关文章:
【Gan教程 】 什么是变分自动编码器VAE?
名词解释:Variational Autoencoder(VAE) 一、说明 为什么深度学习研究人员和概率机器学习人员在讨论变分自动编码器时会感到困惑?什么是变分自动编码器?为什么围绕这个术语存在不合理的混淆?本文从两个角度…...
T113-S3-buildroot文件系统tar解压缩gz文件
目录 前言 一、现象描述 二、解决方案 三、tar解压缩.gz文件 总结 前言 本文主要介绍全志T113-S3平台官方SDK,buildroot文件系统tar不支持.gz文件解压缩的问题以及如何配置buildroot文件系统解决该问题的方法介绍。 一、现象描述 在buildroot文件系统中ÿ…...

软件测试面试题:压测时,QPS一直上不去,如何排查?
在进行系统压测时,QPS(Queries Per Second)即每秒查询数,无法达到预期值是一个常见的问题,本文就来介绍下QPS一直上不去时应该如何排查。 一. 检查硬件资源 CPU使用率 使用top或nmon命令来查看CPU使用率。如果CPU使…...

探索JavaScript ES6+新特性
JavaScript是一门十分流行的编程语言,它不断发展演变以适应现代Web开发需求。ES6(也称为ECMAScript 2015)是JavaScript的第六个版本,引入了许多令人兴奋的新特性和语法糖。本文将介绍一些ES6中最有趣和实用的特性。 箭头函数 箭…...

Elasticsearch常见错误
一 read_only_allow_delete" : "true" 当我们在向某个索引添加一条数据的时候,可能(极少情况)会碰到下面的报错: {"error": { "root_cause": [ { "type": "cluster_block_exception", "r…...

mysql源码编译安装
下载地址:http://dev.mysql.com/downloads/mysql/5.1.html#downloads 免费版,只能下载mysql社区版。MySQL Community Server 选择合适的版本迚行下载: 安装前,如果不存在mysql 用户,则建立之 [rootlocalhost ~]# useradd mys…...
On Moving Object Segmentation from Monocular Video with Transformers 论文阅读
论文信息 标题:On Moving Object Segmentation from Monocular Video with Transformers 作者: 来源:ICCV 时间:2023 代码地址:暂无 Abstract 通过单个移动摄像机进行移动对象检测和分割是一项具有挑战性的任务&am…...

[AutoSar NVM] 存储架构
依AutoSAR及公开知识辛苦整理,禁止转载。 专栏 《深入浅出AutoSAR》, 全文 2900 字. 图片来源: 知乎 汽车的ECU内存中有很多不同类型的变量,这些变量包括了车辆各个系统和功能所需的数据。大部分变量在ECU掉电后就会丢失&#x…...

ES10 新特性
1. Object.fromEntries Object.fromEntries() 方法把可迭代对象的键值对列表转换为一个对象。 语法: Object.fromEntries(iterable)iterable:类似 Array 、 Map 或者其它实现了可迭代协议的可迭代对象。返回值:一个由该迭代对象条目提供对应属性的新对象。相当于 Object.e…...

宝塔安装脚本
Centos安装脚本 yum install -y wget && wget -O install.sh https://download.bt.cn/install/install_6.0.sh && sh install.sh ed8484bec Ubuntu/Deepin安装脚本 wget -O install.sh https://download.bt.cn/install/install-ubuntu_6.0.sh && sud…...
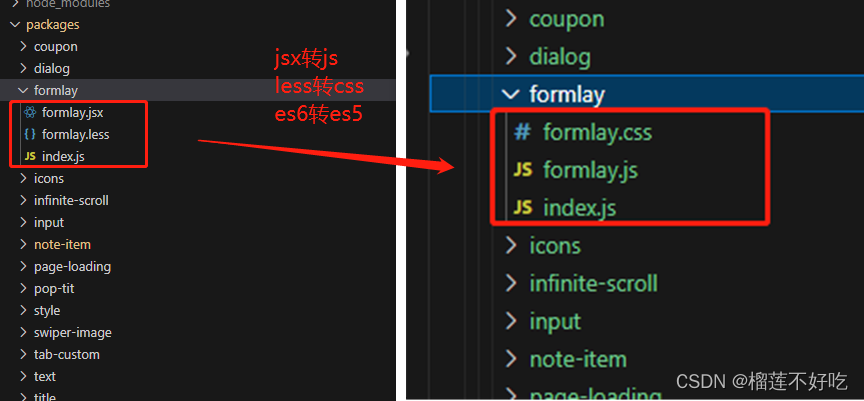
gulp打包vue3+jsx+less插件
最终转换结果如下 在根目录下添加gulpfile.js文件,package.json添加命令npm run gulp var gulp require(gulp) var babel require(gulp-babel) var less require(gulp-less) var del require(del); var spawn require(child_process).spawn;const outDir &…...

华为ICT——第四章深度学习和积卷神经
接第三章的末尾: 目录 接第三章的末尾: 1:自适应阈值分割: 2:形态处理: 4:膨胀: 5:腐蚀 6:开运算 7:闭运算 8:特征描述子 9…...
)
MongoDB 学习笔记(基础)
概论 出现背景:MongoDB 是文档型数据库,由于传统的关系型数据库(如 MySQL),在数据操作的“三高”需求以及应对 web 的网站需求面前显得有些吃力,在此环境下 MongoDB 出世了 三高需求: (1) 对数…...

【TGRS 2023】RingMo: A Remote Sensing Foundation ModelWith Masked Image Modeling
RingMo: A Remote Sensing Foundation Model With Masked Image Modeling, TGRS 2023 论文:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber9844015 代码:https://github.com/comeony/RingMo MindSpore/RingMo-Framework (gitee.com) …...

性能测试 —— 生成html测试报告、参数化、jvm监控
1.生成HTML的测试报告 1.1配置 (1)找到jmeter 的安装目录,下的bin中的jmeter.properties(jmeter配置文件) (2) ctrl f ,搜索jmeter.save.saveservice.output_format,取消井号 并且 把等号后的xml改为csv,…...
堆(二叉树,带图详解)
一.堆 1.堆的概念 2.堆的存储方式 逻辑结构 物理结构 2.堆的插入问题 3.堆的基本实现(代码)(以小堆为例) 1.堆的初始化 2. 向上调整 3.插入结点 4. 交换函数、堆的打印 5.向下调整 6.删除根节点并调整成小根堆 7.获取堆…...
vue3 code format bug
vue code format bug vue客户端代码格式化缺陷,为了方便阅读和维护,对代码格式化发现这个缺陷 vue.global.min.3.2.26.js var Vuefunction(r){"use strict";function e(e,t){const nObject.create(null);var re.split(",");for(le…...

7-3、S曲线生成器【51单片机控制步进电机-TB6600系列】
摘要:本节介绍步进电机S曲线生成器的计算以及使用 一.计算原理 根据上一节内容,已经计算了一条任意S曲线的函数。在步进电机S曲线加减速的控制中,需要的S曲线如图1所示,横轴为时间,纵轴为角速度,其中w0为起…...
CDC实时数据同步
一丶CDC实时数据同步介绍 CDC实时数据同步指的是Change Data Capture(数据变更捕获)技术在数据同步过程中的应用。CDC技术允许在数据源发生变化时,实时地捕获这些变化,并将其应用到目标系统中,从而保持数据的同步性。…...
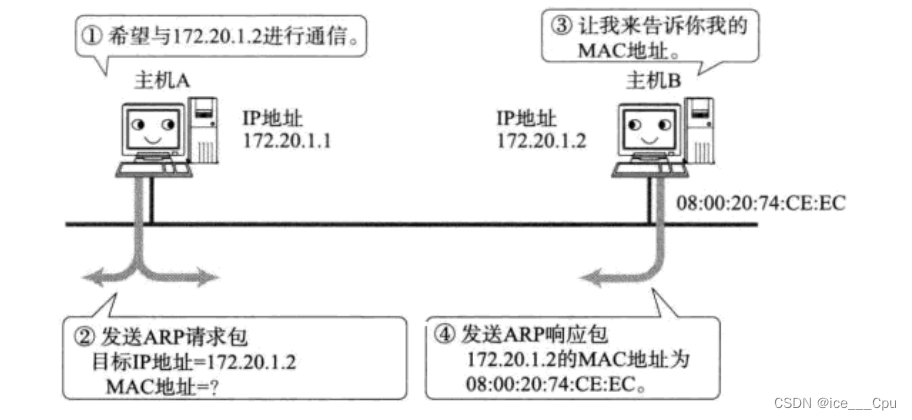
javaEE -10(11000字详解5层重要协议)
一:应用层重点协议 1.1: DNS DNS,即Domain Name System,域名系统。DNS是一整套从域名映射到IP的系统。 TCP/IP中使用IP地址来确定网络上的一台主机,但是IP地址不方便记忆,且不能表达地址组织信息&#x…...

抖音图片怎么去水印?2026年在线去水印工具+方法盘点,总有一款适合你
开篇:为什么要去水印? 保存抖音图片时,总会遇到水印的困扰。这些水印包含抖音logo、发布者名称,有时还会有账号信息。对于自媒体创作者、内容整理者或普通用户来说,去除水印往往是必需的。本文将介绍当下最实用的抖音图…...

Free-NTFS-for-Mac深度剖析:打破macOS与Windows文件系统壁垒的完整解决方案
Free-NTFS-for-Mac深度剖析:打破macOS与Windows文件系统壁垒的完整解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mountin…...

轻量级监控系统Monikhao:自托管部署与核心架构解析
1. 项目概述:一个轻量级、可自托管的监控解决方案最近在折腾个人服务器和家庭网络监控时,发现了一个挺有意思的项目:khaodius/monikhao。乍一看这个名字,可能会觉得有点陌生,但如果你对自建监控系统有需求,…...
)
别再点‘忽略’了!开机弹出Visual C++ Runtime Library错误的终极排查指南(附Adobe软件关联排查)
Visual C Runtime Library错误:从崩溃到根治的全链路解决方案 每次开机时那个刺眼的Visual C Runtime Library错误弹窗,就像一位不请自来的访客,固执地打断你的工作节奏。对于依赖Adobe Creative Cloud或达芬奇等创意工具的专业人士来说&…...

Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南
Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or Ker…...

怎么判断一家工厂还在不在正常生产?6 类活跃度信号,从纸面到现场
跑工厂的销售员都遇到过这种事:手机里存着一份名单,导航开两小时,到门口才发现卷帘门焊死、车间长草、保安说"厂子去年就搬了"。 问题出在哪?大多数人判断"这家工厂在不在",靠的是工商登记——执照…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...

Lingoose:轻量级LLM编排框架的设计哲学与工程实践
1. 项目概述:从“Lingo”到“Goose”,一个轻量级LLM编排框架的诞生最近在折腾大语言模型应用开发的朋友,估计都绕不开一个核心问题:如何高效、优雅地编排和串联多个LLM调用、工具调用以及数据处理流程?当你从简单的单次…...

Navis:开源项目标准化开发环境与工具链配置框架实践
1. 项目概述:一个为开发者打造的“导航星图”如果你和我一样,常年混迹在开源项目的海洋里,那么你一定对这种感觉不陌生:面对一个全新的、功能强大的开源工具,兴奋地克隆了仓库,然后……就卡在了第一步。REA…...

从仿生结构到步态算法:8自由度并联腿机器狗行走全解析
1. 8自由度并联腿机器狗的结构奥秘 第一次拆解机器狗时,我对着那些复杂的连杆结构发了半小时呆。直到发现它的腿部运动原理和公园里的跷跷板惊人相似——这个发现让我瞬间理解了8自由度并联腿的精妙之处。这种结构就像给机器人装上了"机械肌腱"࿰…...