人工智能三要数之算法Transformer
1. 人工智能三要数之算法Transformer
人工智能的三个要素是算法、数据和计算资源。Transformer 模型作为一种机器学习算法,可以应用于人工智能系统中的数据处理和建模任务。
-
算法: Transformer 是一种基于自注意力机制的神经网络模型,用于处理序列数据的建模和表示学习。它通过自适应地关注输入序列中的不同位置,并利用多头注意力机制对序列中的关系进行建模。Transformer 的算法创新使得模型能够处理长距离依赖、捕捉全局关系,并在多个自然语言处理任务中取得卓越的性能。
-
数据: Transformer 模型的训练需要大量的数据。在自然语言处理任务中,可以使用大规模的文本语料库来训练 Transformer 模型。这些数据可以包括语言对、文本摘要、问题-回答对等。丰富和多样的数据有助于提高模型的泛化能力和性能,并使其适应不同领域和任务。
-
计算资源: Transformer 模型通常具有较大的模型规模和参数量,因此需要充足的计算资源进行训练和推理。训练大规模的 Transformer 模型可能需要使用多个图形处理器(Graphics Processing Units,GPU)或者专用的计算设备(如Google的TPU)。并行计算和分布式训练技术可以加速 Transformer 模型的训练过程,并提高模型的效率。
Transformer 模型作为一种算法,可以通过大规模数据的训练,并依赖充足的计算资源来实现在自然语言处理和其他任务中的应用。算法、数据和计算资源三者相互依赖,共同推动了 Transformer 模型在人工智能领域的发展和应用。
2. Transformer详细介绍
什么是Transformer
Transformer是一种基于自注意力机制的神经网络模型,由Vaswani等人于2017年提出,旨在解决自然语言处理中的序列建模问题。它在机器翻译任务中取得了重大突破,并在其他自然语言处理任务中也取得了显著的成果。
传统的序列模型如循环神经网络(RNN)和卷积神经网络(CNN)在处理长距离依赖关系时存在一定的局限性。而Transformer通过引入自注意力机制,能够在序列中捕捉全局的依赖关系,使得模型能够同时考虑序列中的所有位置。
Transformer的关键组成部分
Transformer模型由编码器(Encoder)和解码器(Decoder)构成,这两部分分别用于处理输入序列和生成输出序列。
自注意力机制(Self-Attention)
自注意力机制是Transformer的核心组件之一,用于计算序列中各个位置之间的关联程度。在自注意力机制中,每个位置的表示会与序列中其他位置的表示进行加权相加,得到该位置的上下文表示。这样的注意力机制允许模型在处理序列时,能够对不同位置的信息进行灵活的关注。
编码器(Encoder)
编码器由多个相同结构的层组成,每个层包含一个多头自注意力机制和一个前馈神经网络。编码器负责将输入序列中的每个位置进行编码,生成每个位置的高维表示。通过堆叠多个编码器层,模型能够对输入序列进行更加深入的抽象和建模。
解码器(Decoder)
解码器也由多个相同结构的层组成,每个层包含一个多头自注意力机制、一个源-目标注意力机制(用于关注编码器输出)和一个前馈神经网络。解码器负责根据编码器的输出和之前的预测,生成目标序列。解码器的输入在每个位置都来自前面已生成的部分,从而实现逐步生成输出序列的过程。
位置编码(Positional Encoding)
为了保留序列中位置信息,Transformer引入了位置编码。位置编码是一种将序列中每个位置与其对应的编码向量进行映射的技术。这些位置编码向量会与输入的词向量进行相加,以便模型能够区分不同位置的信息。
Transformer的优势和应用
Transformer具有以下几个优势,使得它在自然语言处理任务中表现出色:
-
并行计算:Transformer能够同时处理序列中的所有位置,而不需要依次进行计算。这种并行计算的能力使得Transformer在训练和推理时具有较高的效率。
-
捕捉长距离依赖:由于自注意力机制的引入,Transformer能够捕捉长距离的依赖关系,避免了传统序列模型中随着距离增加而衰减的问题。
-
上下文建模:Transformer能够全局地建模输入序列中的上下文关系,使得模型能够更好地理解和处理文本中的语义和语法结构。
3. Transformer 模型关键技术
Transformer 模型引入了一些关键的技术:
-
自注意力机制(Self-Attention Mechanism): 自注意力机制是 Transformer 模型的核心。它允许模型在生成表示时,根据输入序列中不同位置的重要性进行自适应的关注。自注意力机制通过计算查询(Query)和键(Key)之间的相似度,得到每个位置对查询的注意力权重,然后将注意力权重与值(Value)相乘并进行加权求和,得到最终的上下文表示。自注意力机制使得模型能够直接建模序列中不同位置之间的依赖关系,从而在捕捉长距离依赖时更加有效。
-
多头注意力机制(Multi-Head Attention): 多头注意力机制是对自注意力机制的扩展。它通过在每个注意力机制中引入多个独立的注意力头(Attention Head),使得模型能够同时学习多种不同的查询、键和值的表示。在多头注意力机制中,会对输入序列进行一次独立的注意力计算,然后将多个注意力头的结果进行拼接或加权求和,得到最终的上下文表示。多头注意力机制的引入有助于模型对不同相关性模式的建模能力。
-
残差连接(Residual Connections): 在深层的神经网络中,梯度消失或梯度爆炸问题可能会影响模型的训练。为了缓解这个问题,Transformer 引入了残差连接。在每个子层或子模块的输入和输出之间,会进行残差连接,即直接将输入与输出相加。这种连接方式使得模型能够更容易地传播梯度,加快训练速度并提高模型的性能。
-
层归一化(Layer Normalization): 层归一化是为了进一步稳定训练和提高模型的泛化能力而引入的。在每个子层或子模块的输入和输出之间,会应用归一化操作,将输入进行标准化处理。这有助于减少内部协变量偏移(Internal Covariate Shift)的影响,使得模型对输入的变化更加鲁棒。
-
位置编码(Positional Encoding): 由于 Transformer 模型没有显式的位置信息,为了使模型能够捕捉序列中的位置信息,需要引入位置编码。位置编码是一种将序列中每个位置的信息嵌入到表示中的技术。常用的位置编码方式包括正弦和余弦函数编码,通过将位置信息与输入向量相加,使得模型能够区分不同位置上的输入。
-
学习率调度(Learning Rate Scheduling): 在训练 Transformer 模型时,学习率的设置和调整非常重要。由于 Transformer 通常具有较大的模型规模,使用固定的学习率可能会导致训练过程出现困难。因此,常常采用学习率调度的方法,如逐渐减小学习率、使用预定的学习率曲线等,以提高模型的收敛速度和性能。
这些技术是 Transformer 模型的关键组成部分,它们共同作用使得 Transformer 在自然语言处理和其他序列建模任务中取得了显著的成功。通过自注意力机制、多头注意力机制、残差连接、层归一化、位置编码和学习率调度等技术的结合,Transformer 模型能够处理长距离依赖、捕捉全局关系,并在大规模数据上进行有效的训练和推理。
4. Transformer作为算法模型的主要模型
以下是一些使用Transformer作为算法模型的主要模型:
-
BERT (Bidirectional Encoder Representations from Transformers): BERT是Google于2018年提出的预训练语言理解模型。这个模型扩大了我们可以应用Transformers的领域,特别是在NLP任务中,如文本分类、命名实体识别和问答系统等。
-
GPT (Generative Pre-training Transformer): GPT是OpenAI开发的自然语言处理模型,它依靠Transformer结构为各种任务进行预训练。
-
T5 (Text-to-Text Transfer Transformer): Google的T5模型将所有NLP任务视为文本生成问题。
-
Transformer XL (extra long): 这个模型由谷歌DeepMind团队开发,它解决了Transformer模型在处理长序列时的问题。
-
DistilBERT: 这是BERT模型的一个“轻量版”,训练速度更快,模型规模更小,但在许多任务上的性能却非常接近原版BERT!
-
RoBERTa (A Robustly Optimized BERT Pretraining Approach): RoBERTa是Facebook AI推出的模型,是在BERT基础上的优化版本,加长了训练时间,使用了大规模未标注数据,消除了Next Sentence Prediction等进行了实验和优化。
5. Transformer广泛的应用
Transformer 模型在自然语言处理(Natural Language Processing,NLP)任务中被广泛应用,并取得了许多重要的突破。以下是一些常见的应用:
-
机器翻译(Machine Translation): Transformer 在机器翻译任务中取得了巨大成功。通过将源语言序列作为输入,目标语言序列作为输出,Transformer 模型能够学习到有效的语言表示和对齐模式,从而实现高质量的自动翻译。
-
文本摘要(Text Summarization): Transformer 在文本摘要任务中表现出色。通过对输入文本进行编码,并使用解码器生成摘要,Transformer 能够生成准确、连贯的文本摘要,包括单文档摘要和多文档摘要。
-
语言生成(Language Generation): Transformer 被广泛用于语言生成任务,如对话系统、问答系统和聊天机器人等。通过编码输入序列并使用解码器生成输出序列,Transformer 能够生成具有语法正确性和上下文连贯性的自然语言文本。
-
命名实体识别(Named Entity Recognition): Transformer 在命名实体识别任务中取得了显著的性能提升。通过对输入句子进行编码和标注,Transformer 能够识别和分类文本中的命名实体,如人名、地名、组织机构名等。
-
情感分析(Sentiment Analysis): Transformer 被广泛用于情感分析任务,包括情感分类和情感极性预测。通过对输入文本进行编码和分类,Transformer 能够自动识别文本的情感倾向,如正面、负面或中性。
-
文本分类(Text Classification): Transformer 在文本分类任务中得到了广泛应用。通过对输入文本进行编码和分类,Transformer 能够对文本进行自动分类,包括垃圾邮件过滤、新闻分类、情感分类等。
-
语义角色标注(Semantic Role Labeling): Transformer 在语义角色标注任务中取得了显著的性能提升。通过对输入句子进行编码和标注,Transformer 能够自动识别和标注句子中的谓词-论元结构,从而揭示句子的语义角色关系。
除了上述任务,Transformer 模型还在问答系统、机器阅读理解、语言模型等众多自然语言处理任务中取得了重要的进展。Transformer 模型以其强大的表示学习能力和并行计算性质,成为了自然语言处理领域的重要技术基础。
除了自然语言处理领域,Transformer 技术还在以下领域得到了广泛的应用:
-
计算机视觉(Computer Vision): Transformer 技术在计算机视觉领域也取得了显著的进展。例如,Vision Transformer(ViT)是一种将 Transformer 模型应用于图像分类任务的方法,通过将图像分割为图像块,并将它们表示为序列输入,从而实现对图像的处理和分类。Transformer 在计算机视觉中的应用还包括目标检测、图像生成和图像描述等任务。
-
语音识别(Speech Recognition): Transformer 技术也在语音识别领域得到了应用。例如,Conformer 是一种结合了 Transformer 和卷积神经网络(Convolutional Neural Network,CNN)的模型,用于语音识别任务。它在编码输入音频序列时利用了 Transformer 的自注意力机制,从而提高了语音识别的性能。
-
推荐系统(Recommendation Systems): Transformer 技术在推荐系统领域也得到了应用。例如,Transformer 模型可以用于建模用户和物品之间的关系,并预测用户对物品的兴趣和偏好。这样的模型可以用于个性化推荐、广告点击率预测和推荐排序等任务。
-
时间序列预测(Time Series Forecasting): Transformer 技术在时间序列预测中也发挥了重要作用。通过将时间序列数据转换为序列输入,并利用 Transformer 模型的自注意力机制进行建模,可以实现对时间序列的准确预测。这在金融市场预测、天气预测和交通流量预测等领域具有应用前景。
-
图像生成(Image Generation): Transformer 技术在图像生成领域也取得了一些突破。例如,Image GPT 是一种基于 Transformer 的图像生成模型,通过对图像像素序列进行建模,能够生成逼真的图像样本。这在计算机图形学、虚拟现实和创意艺术等领域具有应用潜力。
除了上述领域,Transformer 技术还在机器学习的其他领域和任务中得到了应用,如强化学习、多模态学习和分子设计等。Transformer 的强大表示学习能力和并行计算性质使其成为了一种通用且强大的模型架构,可以应用于各种复杂的数据建模和处理任务。
相关文章:
人工智能三要数之算法Transformer
1. 人工智能三要数之算法Transformer 人工智能的三个要素是算法、数据和计算资源。Transformer 模型作为一种机器学习算法,可以应用于人工智能系统中的数据处理和建模任务。 算法: Transformer 是一种基于自注意力机制的神经网络模型,用于处理序列数据的…...

Java ThreadPoolExecutor 线程池
import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; import java.util.concurrent.ArrayBlockingQueue;public class ThreadPoolExample {public static void main(String[] args) {// 创建线程池对象ThreadPoolExecutor threadPool new…...

网络协议--IP选路
9.1 引言 选路是IP最重要的功能之一。图9-1是IP层处理过程的简单流程。需要进行选路的数据报可以由本地主机产生,也可以由其他主机产生。在后一种情况下,主机必须配置成一个路由器,否则通过网络接口接收到的数据报,如果目的地址不…...
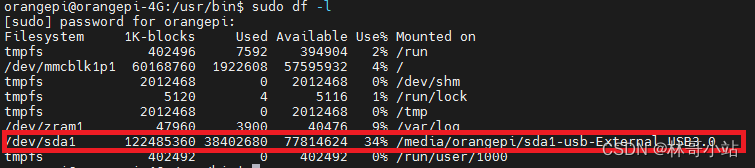
使用udevil自动挂载U盘或者USB移动硬盘
最近在折腾用树莓派(实际上是平替香橙派orangepi zero3)搭建共享文件服务器,有一个问题很重要,如何在系统启动时自动挂载USB移动硬盘。 1 使用/etc/fstab 最开始尝试了用/etc/fstab文件下增加:"/dev/sda1 /home/orangepi/s…...

学习笔记二十二:K8s控制器Replicaset
K8s控制器Replicaset Replicaset控制器:概念、原理解读Replicaset概述Replicaset工作原理:如何管理PodReplicaset控制器三个组成部分 Replicaset资源清单文件编写技巧Replicaset使用案例:部署Guestbook留言板编写一个ReplicaSet资源清单资源清…...

2023-10-25 精神分析-领悟新技术的错误做法-持续数年的错误做法-记录与分析
摘要: 过去数年对于领悟技术, 采取的做法不能说是对达到目的毫无裨益,但是对突破技术和将技术融为自身这个目的来说, 没有达到。 而且随着时间的流逝, 过去已经熟悉的技术, 竟然会被忘掉!就像是没有涉猎过一样! 根本原因出在对技术的领悟的…...
方法)
Arrays 中的 asList()方法
public static <T> List<T> asList( T . . . a ){ return new ArrayList<>(a); } 返回由指定数组支持的固定大小的 list集合。对数组所做的更改将在返回的 l…...
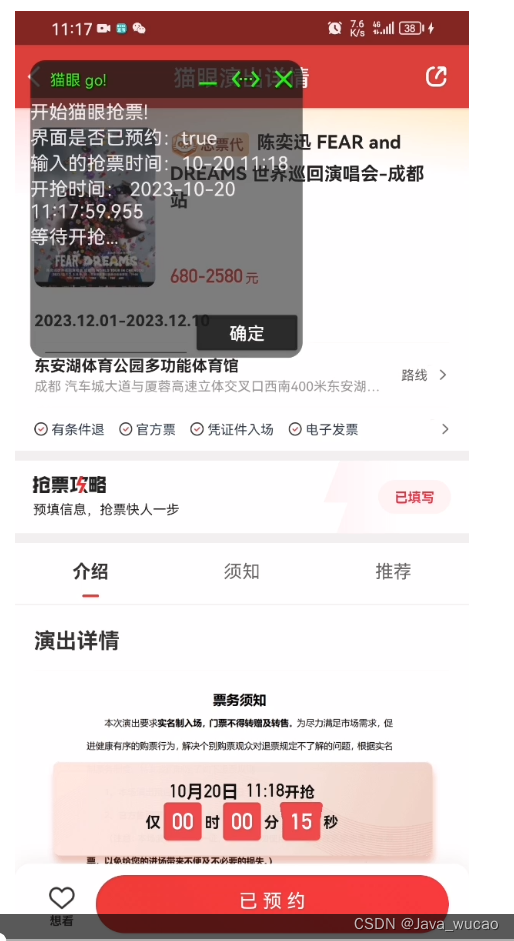
基于自动化工具autox.js的抢票(猫眼)
1.看到朋友圈抢周杰伦、林俊杰演唱会票贼难信息,特研究了一段时间,用autox.js写了自动化抢票脚本,购票页面自动点击下单(仅限安卓手机)。 2.脚本运行图 3.前期准备工作 (1)autox.js社区官网:AutoX.js (2)b站上学习资料:10分钟学会AutoX.js hello world_哔哩哔哩_bi…...

Java架构师内功计算机网络
目录 1 导学2 网络功能和分类3 OSI七层模型3.1 局域网和广域网协议4 TCP/IP协议5 通信技术和交换技术5.1 通信技术5.2 交换技术5.2.1 路由技术5.2.2 传输介质6 通信方式和交换方式7 IP地址7.1 IP地址表示7.2 子网划分8 IPv69 网络规划与设计10 网络存储技术10.1 廉价磁盘几余阵…...

vue 中 mixin 和 mixins 区别
目录 前言 用法 全局Mixin 局部Mixin 代码 理解 高质量的Mixin使用 在Vue.js框架中,Mixin是一种非常重要和强大的功能,它允许开发者创建可复用的代码片段,并将其应用到一个或多个组件中。Vue提供了两种方式来使用Mixin,分别…...
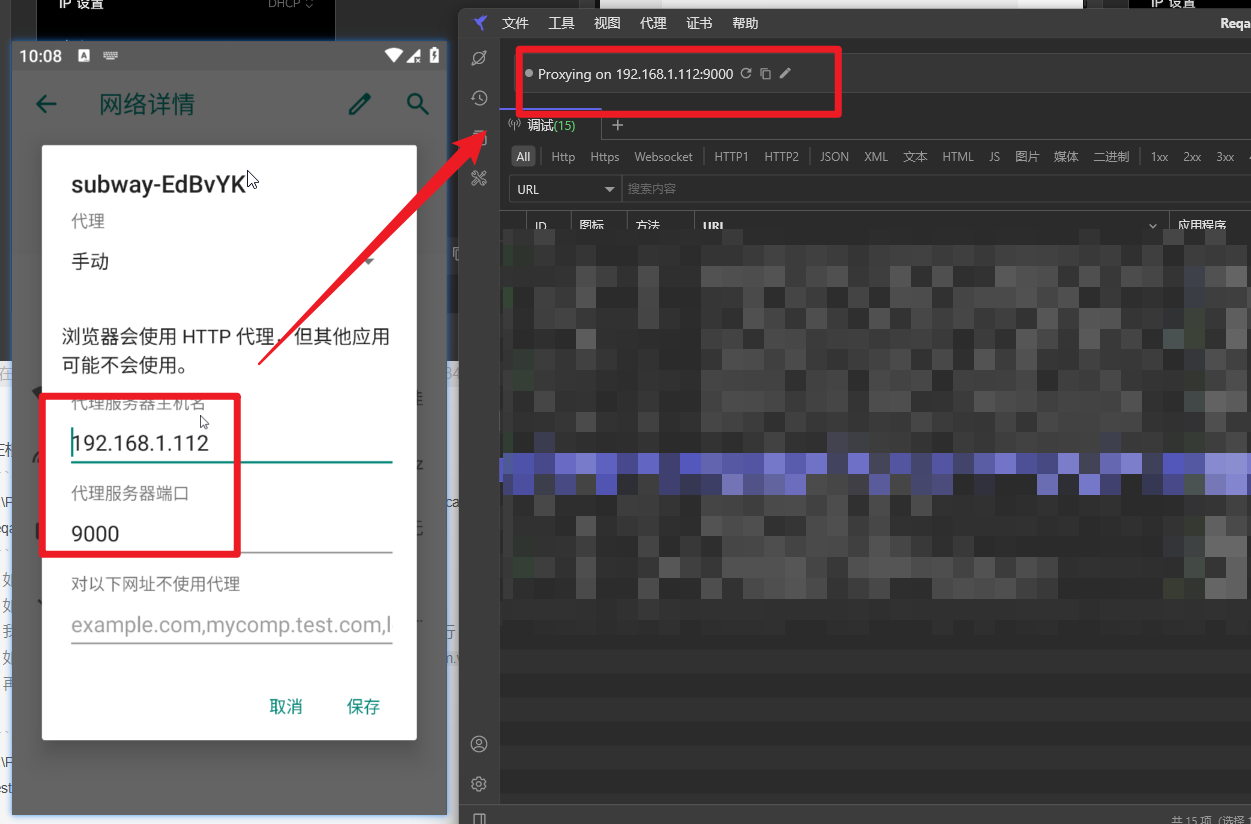
reqable(小黄鸟)+雷电抓包安卓APP
x 下载证书保存到雷电模拟器根目录(安装位置) 为什么? Android7以上,系统允许每个应用可以定义自己的可信CA集,部分的应用默认只会信任系统预装的CA证书,而不会信任用户安装的证书,之前的方法安装Burp/Fiddler证书都是用户证书…...

高等数学啃书汇总重难点(七)微分方程
同济高数上册的最后一章,总的来说,这篇章内容依旧是偏记忆为主,说难不难说简单不简单: 简单的是题型比较死,基本上就是记公式,不会出现不定积分一般花样繁多的情况;然而也就是背公式并不是想的…...

阿里云对象存储OSS文件无法预览,Bucket设置了Referer
您发起的请求头中没有Referer字段或Referer字段为空,与请求Bucket设置的防盗链策略不相符。 解决方案 您可以选择以下任意方案解决该问题。 在请求中增加Referer请求头。 GET /test.txt HTTP/1.1 Date: Tue, 20 Dec 2022 08:48:18 GMT Host: BucketName.oss-examp…...

数字孪生技术:工业数字化转型的引擎
数字孪生是一种将物理实体数字化为虚拟模型的技术,这些虚拟模型与其物理对应物相互关联。这种虚拟模型通常是在数字平台上创建的,它们复制了实际设备、工厂、甚至整个供应链的运作方式。这使工业企业能够实现以下益处: 1. 实时监测和分析 数…...

算法刷题-哈希表
算法刷题-哈希表 242. 有效的字母异位词 给定两个字符串 *s* 和 *t* ,编写一个函数来判断 *t* 是否是 *s* 的字母异位词。 **注意:**若 *s* 和 *t* 中每个字符出现的次数都相同,则称 *s* 和 *t* 互为字母异位词。 思路 用一个哈希表来记…...

2023NOIP A层联测17 黑暗料理
题目大意 给出一个长度为 n n n的序列 a i a_i ai,要求删去若干个数,使得剩下的数中任意两个数都不是质数。在满足条件的情况下最多能保留几个数。 有 T T T组数据。 1 ≤ T ≤ 4 , 1 ≤ n ≤ 750 , 1 ≤ a i ≤ 1 0 9 1\leq T\leq 4,1\leq n\leq 75…...

关于nacos的配置获取失败及服务发现问题的排坑记录
nacos配置更新未能获取到导致启动报错 排查思路: 1、是否添加了nacos的启动pom依赖 参考: <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId><…...
【QT】其他常用控件1
新建项目 scrollArea 滚动 toolBox 插入 tabWidget stackedWidget 切换 索引是0 运行后,没有切换按钮,结合pushbutton,加两个Button 代码 #include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent)…...
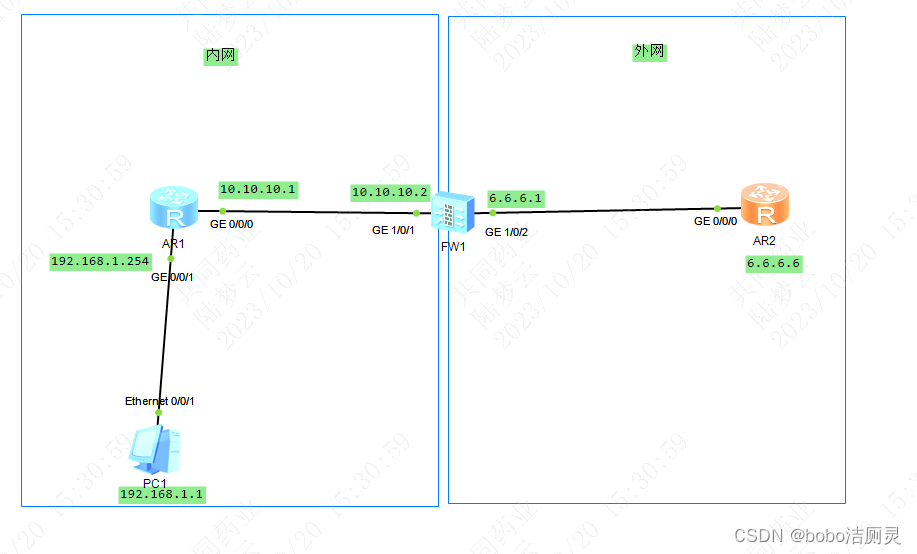
交换机/防火墙-基础配置-23.10.11
update 优化了目录逻辑 -10.24.2023 一.前置知识 1.MAC地址 交换机在给主机之间传递信息包时,通过MAC地址来标识每台主机 主机间发生信息包交换时,交换机就会将通信过的主机的mac地址存下 dis mac-address 交换机转发的数据包中,会包含一…...
-- Json字符 与 JsonObject 的相互转化)
alibaba.fastjson的使用(四)-- Json字符 与 JsonObject 的相互转化
目录 1. Json字符串转JsonObject 2. JsonObject转Json字符串 1. Json字符串转JsonObject 使用到的方法1: static JSONObject parseObject(String text) 使用到的方法2: public String getString(String key) /*** 将Json字符串转为JsonObject对象* 取值不存在时,返回null…...

告别手改脚本!用CANoe Panel面板做个变量控制台,测试效率翻倍
告别手改脚本!用CANoe Panel面板打造智能变量控制台 在车载网络测试领域,效率提升往往隐藏在那些被忽视的日常操作细节中。当测试工程师频繁打开CAPL脚本修改超时阈值、调整诊断ID或切换测试模式时,不仅打断了工作流,更在团队协作…...

3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略
3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 想要快速获取网易云音乐和QQ音乐的歌词吗?1…...

3D打印乐高手机支架:低成本打造高清视频会议摄像头方案
1. 项目概述与核心思路如果你和我一样,对视频会议、直播时笔记本自带摄像头那“感人”的画质感到无奈,同时又觉得单独购买一个高品质的网络摄像头是一笔不小的开销,那么这个项目绝对值得你花上一个周末的时间来折腾。它的核心思路非常巧妙&am…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

模拟电路布局优化:多智能体强化学习实践
1. 模拟电路布局优化的挑战与机遇在集成电路设计领域,模拟电路布局一直是个令人头疼的问题。作为一名从业十余年的模拟电路设计师,我深刻体会到传统布局方法在面对现代工艺挑战时的局限性。每次手工调整晶体管位置时,那种"差之毫厘&…...

构建轻量级应用沙盒:Microverse原理与实践指南
1. 项目概述:一个轻量级、可移植的“微宇宙”开发沙盒最近在折腾一些边缘计算和嵌入式AI应用的原型验证,经常遇到一个头疼的问题:开发环境和部署环境不一致。在本地笔记本上跑得好好的Python脚本,放到树莓派或者Jetson Nano上&…...

自建轻量级Docker镜像中心:聚合管理与加速部署实践
1. 项目概述:一个面向容器化开发者的中心化镜像仓库最近在和一些做容器化开发的朋友交流时,大家普遍提到一个痛点:随着团队项目增多,Docker镜像的管理变得越来越零散。有的镜像放在Docker Hub,有的放在阿里云镜像服务&…...

017、Docker在TinyML开发中的应用
017 Docker在TinyML开发中的应用 从一次“环境地狱”说起 上个月帮团队调一个STM32上的TinyML推理延迟问题,模型是MobileNetV2量化版,在开发板上跑得好好的,换到同事的Ubuntu 20.04机器上编译,死活链接不上CMSIS-NN库。折腾半天发现他系统里默认的arm-none-eabi-gcc版本是…...
)
【仅开放72小时】ElevenLabs德文语音生成高级提示词库(含137个Schwäbisch/Bavarian方言指令模板)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs德文语音生成技术概览与方言适配价值 ElevenLabs 的德语语音合成引擎基于多说话人、多风格的端到端扩散模型架构,支持高保真、低延迟的实时语音生成。其德语语音库覆盖标准高地德…...

Go语言LLM应用开发框架:统一接口与工具调用实战
1. 项目概述:一个为Go语言量身打造的LLM应用开发框架如果你正在用Go语言构建一个需要集成大语言模型(LLM)的应用,比如一个智能客服机器人、一个代码生成工具,或者一个文档分析系统,那么你很可能已经体会过那…...