linux 内存检测工具 kfence 详解
版本基于:
Linux-5.10
约定:
PAGE_SIZE:4K
内存架构:UMA
0. 前言
本文 kfence 之外的代码版本是基于 Linux5.10,最近需要将 kfence 移植到 Linux5.10 中,本文借此机会将 kfence 机制详细地记录一下。
kfence,全称为 Kernel Electric-Fence,是 Linux5.12 版本新 引入 的内存使用错误检测机制。
kfence 基本原理非常简单,它创建了自己的专有检测内存池 kfence_pool。然后在 data page 的两边加上 fence page 电子栅栏,利用 MMU 的特性把 fence page 设置为不可访问。如果对 data page 的访问越过 page 边界,就会立刻触发异常。
检测的内存错误有:
- OOB:out-of-bounds access,访问越界;
- UAF:use-after-free,释放再使用;
- CORRUPTION:释放的时候检测到内存损坏;
- INVALID:无效访问;
- INVALID_FREE,无效释放;
现在,kfence 检测的内存错误类型不如 KASAN 多,但,kfence 设计的目的:
- be enabled in production kernels,在产品内核中使能
- has near zero performance overhead,接近 0 性能开销
kfence 机制依赖 slab 和kmalloc 机制,熟悉这两个机制能更好理解 kfence。
1. kfence 依赖的config
//当使用 arm64时,该config会被默认select,详细看arch/arm64/Kconfig
CONFIG_HAVE_ARCH_KFENCE//kfence 机制的核心config,需要手动配置,下面所有的config都依赖它
CONFIG_KFENCE------------------ 下面所有config都依赖CONFIG_KFENCE-----------//依赖CONFIG_JUMP_LABEL
//用以启动静态key功能,主要是来优化性能,每次读取kfence_allocation_gate的值是否为0来进行判断,这样的性能
//开销比较大
CONFIG_KFENCE_STATIC_KEYS//kfence pool的获取频率,默认为100ms
// 另外,该config可以设置为0,表示禁用 kfence功能
CONFIG_KFENCE_SAMPLE_INTERVAL//kfence pool中共支持多少个OBJECTS,默认为255,从1~65535之间取值
// 一个kfence object需要申请两个pages
CONFIG_KFENCE_NUM_OBJECTS//stress tesing of fault handling and error reporting, default 0
CONFIG_KFENCE_STRESS_TEST_FAULTS//依赖CONFIG_TRACEPOINTS && CONFIG_KUNIT,用以启动kfence的测试用例
CONFIG_KFENCE_KUNIT_TEST1. kfence 原理
2. kfence中的重要数据结构
2.1 __kfence_pool
char *__kfence_pool __ro_after_init;
EXPORT_SYMBOL(__kfence_pool); /* Export for test modules. */kfence 中有个专门的内存池,在 memblock移交 buddy之前从 memblock 中申请的一块内存。
内存的首地址保存在全局变量 __kfence_pool 中。
这里来看下内存池的大小:
include/linux/kfence.h#define KFENCE_POOL_SIZE ((CONFIG_KFENCE_NUM_OBJECTS + 1) * 2 * PAGE_SIZE)每个 object 会占用 2 pages,一个page 用于 object 自身,另一个page 用作guard page
kfence pool 会在 CONFIG_KFENCE_NUM_OBJECTS 的基础上多申请 2 个pages,即kfence pool 的page0 和 page1。page0 大部分是没用的,仅仅作为一个扩展的guard page。多加上page1 方便简化metadata 索引地址映射。
下面弄一个图方便理解 kfence_pool
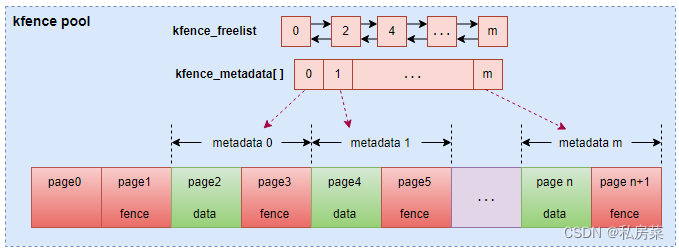
- page0 和 page1 就是上面所述的多出来的两个 pages;
- 其他的pages 是 CONFIG_KFENCE_NUM_OBJECTS * 2,每个object 拥有两个pages,第一个为object 本身,第二个为 fence page;
- kfence 定义一个全局变量 kfence_metadata 数组,数组的长度为CONFIG_KFENCE_NUM_OBJECT,里面管理所有的objects,包括obj当前状态,内存地址等信息;
- kfence pool 中可用的 metadata 会被存放在链表 kfence_freelist 中;
- 从图上可以看到,每一个object page 都会被两个 guard page 包裹了;
2.2 kfence_sample_interval
static unsigned long kfence_sample_interval __read_mostly = CONFIG_KFENCE_SAMPLE_INTERVAL;该变量用以存储 kfence 的采样间隔,默认使用的是 CONFIG_KFENCE_SAMPLE_INTERVAL 的值。当然,内核中还提供内存参数的方式进行配置:
static const struct kernel_param_ops sample_interval_param_ops = {.set = param_set_sample_interval,.get = param_get_sample_interval,
};
module_param_cb(sample_interval, &sample_interval_param_ops, &kfence_sample_interval, 0600);通过set、get 指定内核参数 kfence.sample_interval 的配置和获取,单位为毫秒。
可以通过设施 kfence.sample_interval=0 来禁用 kfence 功能。
2.3 kfence_enabled
该变量表示kfence pool 初始化成功,kfence 进入正常运行中。
kfence 中一共有两个地方会将 kfence_enables 设为false。
第一个地方:
mm/kfence/core.c#define KFENCE_WARN_ON(cond) \({ \const bool __cond = WARN_ON(cond); \if (unlikely(__cond)) \WRITE_ONCE(kfence_enabled, false); \__cond; \})在kfence 中很多地方需要确定重要条件不能为 false,通过 KFENCE_WARN_ON() 进行check,如果condition 为false,则将 kfence_enabled 设为 false。
第二个地方:
param_set_sample_interval() 调用时,如果采样间隔设为0,则表示 kfence 功能关闭。
2.4 kfence_metadata
这是一个 struct kfence_metadata 的全局变量。用以管理所有 kfence objects:
mm/kfence/kfence.hstruct kfence_metadata {struct list_head list; //kfence_metadata为kfence_freelist中的一个节点struct rcu_head rcu_head; //delayed freeing 使用//每个kfence_metadata带有一个自旋锁,用以保护data一致性//我们不能将同一个metadata从freelist 中抓取两次,也不能对同一个metadata进行__kfence_alloc() 多次raw_spinlock_t lock;//object 的当前状态,默认为UNUSEDenum kfence_object_state state;//对象的基地址,都是按照页对齐的unsigned long addr;/** The size of the original allocation.*/size_t size;//最后一次从对象中分配内存的kmem_cache//如果没有申请或kmem_cache被销毁,则该值为NULLstruct kmem_cache *cache;//记录发生异常的地址unsigned long unprotected_page;/* 分配或释放的栈信息 */struct kfence_track alloc_track;struct kfence_track free_track;
};2.5 kfence_freelist
/* Freelist with available objects. */
static struct list_head kfence_freelist = LIST_HEAD_INIT(kfence_freelist);
static DEFINE_RAW_SPINLOCK(kfence_freelist_lock); /* Lock protecting freelist. */用以管理所有的可用的kfence objeces
2.6 kfence_allocation_gate
这是个 atomic_t 变量,是kfence 定时开放分配的闸门,0 表示允许分配,非0表示不允许分配。
正常情况下,在 kfence_alloc() 进行内存分配的时候,会通过atomic_read() 读取该变量的值,如果为0,则表示允许分配,kfence 会进一步调用 __kfence_alloc() 函数。
当考虑到性能问题,内核启动了 static key 功能,即变量 kfence_allocation_key,详见下一小节。
2.7 kfence_allocation_key
这个是kfence 分配的static key,需要 CONFIG_KFENCE_STATIC_KEYS 使能。
#ifdef CONFIG_KFENCE_STATIC_KEYS
/* The static key to set up a KFENCE allocation. */
DEFINE_STATIC_KEY_FALSE(kfence_allocation_key);
#endif这是一个 static_key_false key。
如果 CONFIG_KFENCE_STATIC_KEYS 使能,在 kfence_alloc() 的时候将不再判断 kfence_allocation_gate 的值,而是判断该key 的值。
3. kfence 初始化
init/main.cstatic void __init mm_init(void)
{...kfence_alloc_pool();report_meminit();mem_init();...
}从《buddy 初始化》一文中得知,mm_init() 函数开始将进行buddy 系统的内存初始化。而在函数 mem_init() 中会通过 free 操作,将内存一个页块一个页块的添加到 buddy 系统中。
而 kfence pool 是在 mem_init() 调用之前,从memblock 中分配出一段内存。
3.1 kfence_alloc_pool()
mm/kfence/core.cvoid __init kfence_alloc_pool(void)
{if (!kfence_sample_interval)return;__kfence_pool = memblock_alloc(KFENCE_POOL_SIZE, PAGE_SIZE);if (!__kfence_pool)pr_err("failed to allocate pool\n");
}代码比较简单:
- 确认 kfence_sample_interval 是否为0,如果为0 则表示kfence 为disabled;
- 通过 memblock_alloc() 申请 KFENCE_POOL_SIZE 的空间,PAGE_SIZE 对齐;
3.2 kfence_init()
该函数被放置在 start_kernel() 函数比较靠后的位置,此时buddy初始化、slab初始化、workqueue 初始化等已经完成。
mm/kfence/core.cvoid __init kfence_init(void)
{/* Setting kfence_sample_interval to 0 on boot disables KFENCE. */if (!kfence_sample_interval)return;if (!kfence_init_pool()) {pr_err("%s failed\n", __func__);return;}WRITE_ONCE(kfence_enabled, true);queue_delayed_work(system_unbound_wq, &kfence_timer, 0);pr_info("initialized - using %lu bytes for %d objects at 0x%p-0x%p\n", KFENCE_POOL_SIZE,CONFIG_KFENCE_NUM_OBJECTS, (void *)__kfence_pool,(void *)(__kfence_pool + KFENCE_POOL_SIZE));
}- 同样,当采样间隔设为0,即 kfence_sample_interval 为0 时,关闭kfence;
- 调用 kfence_init_pool() 对kfence pool 进行初始化;
- 变量 kfence_enabled 设为 true,表示 kfence 功能正常,可以正常工作;
- 创建工作队列 kfence_timer,并添加到 system_unbound_wq 中,注意这里延迟为0,即立刻执行 kfence_timer;
注意最后打印的信息,在kfence pool 初始化结束,会从dmesg 中看到如下log:
<6>[ 0.000000] kfence: initialized - using 2097152 bytes for 255 objects at 0x(____ptrval____)-0x(____ptrval____)系统中申请了 255 个 objects,共使用 2M 的内存空间。
3.2.1 kfence_init_pool()
mm/kfence/core.cstatic bool __init kfence_init_pool(void)
{unsigned long addr = (unsigned long)__kfence_pool;struct page *pages;int i;//确认 __kfence_pool已经申请成功,kfence_alloc_pool()会从memblock中申请if (!__kfence_pool)return false;//对于 arm64架构,该函数直接返回true//对于 x86架构,会通过lookup_address()检查__kfence_pool是否映射到物理地址了if (!arch_kfence_init_pool())goto err;//获取映射好的pages,从vmemmap 中查找pages = virt_to_page(addr);//配置kfence pool中的page,将其打上slab页的标记for (i = 0; i < KFENCE_POOL_SIZE / PAGE_SIZE; i++) {if (!i || (i % 2)) //第0页和奇数页跳过,即配置偶数页continue;//确认pages不是复合页if (WARN_ON(compound_head(&pages[i]) != &pages[i]))goto err;__SetPageSlab(&pages[i]);}//将kfence pool的前两个页面设为guard pages//主要是清除对应 pte项的present标志,这样当CPU访问前两页就会触发缺页异常,就会进入kfence处理流程for (i = 0; i < 2; i++) {if (unlikely(!kfence_protect(addr)))goto err;addr += PAGE_SIZE;}//遍历所有的kfence objects页面,kfence_metadata数组是专门对CONFIG_KFENCE_NUM_OBJECTS个对象的状态进行管理for (i = 0; i < CONFIG_KFENCE_NUM_OBJECTS; i++) {struct kfence_metadata *meta = &kfence_metadata[i];/* 初始化kfence metadata */INIT_LIST_HEAD(&meta->list); //初始化kfence_metadata节点raw_spin_lock_init(&meta->lock); //初始化spi lockmeta->state = KFENCE_OBJECT_UNUSED; //所有的起始状态是UNUSEDmeta->addr = addr; //保存该对象的page地址list_add_tail(&meta->list, &kfence_freelist); //将可用的metadata添加到kfence_freelist尾部//保护每个object的右边区域的pageif (unlikely(!kfence_protect(addr + PAGE_SIZE)))goto err;addr += 2 * PAGE_SIZE; //跳到下一个对象}//kfence pool是一直活着的,从此时起永远不会被释放//之前在调用 memblock_alloc()时在 kmemleak中留有记录,这里要删除这部分记录,防止与后面调用// kfence_alloc()分配时出现冲突kmemleak_free(__kfence_pool);return true;err:/** Only release unprotected pages, and do not try to go back and change* page attributes due to risk of failing to do so as well. If changing* page attributes for some pages fails, it is very likely that it also* fails for the first page, and therefore expect addr==__kfence_pool in* most failure cases.*/memblock_free_late(__pa(addr), KFENCE_POOL_SIZE - (addr - (unsigned long)__kfence_pool));__kfence_pool = NULL;return false;
}3.2.2 kfence_timer
在上面 kfence_init_pool() 成功完成之后,kfence_init() 会进入下一步:创建周期性的工作队列。
queue_delayed_work(system_unbound_wq, &kfence_timer, 0);注意最后一个参数为0,因为这里是kfence_init(),第一次执行 kfence_timer 会立即执行,之后的 kfence_timer 会有个 kfence_sample_interval 的延迟。
来看下 kfence_timer 的创建:
mm/kfence/core.cstatic DECLARE_DELAYED_WORK(kfence_timer, toggle_allocation_gate);通过调用 DECLARE_DELAYED_WORK() 初始化一个延迟队列,toggle_allocation_gate() 为时间到达后的处理函数。
下面来看下 toggle_allocation_gate():
mm/kfence/core.cstatic void toggle_allocation_gate(struct work_struct *work)
{//首先确定kfence功能正常if (!READ_ONCE(kfence_enabled))return;//将 kfence_allocation_gate 设为0// 这是kfence内存池开启分配的标志,0表示开启,非0表示关闭// 这样保证每隔一段时间,最多只允许从kfence内存池分配一次内存atomic_set(&kfence_allocation_gate, 0);#ifdef CONFIG_KFENCE_STATIC_KEYS//使能static key,等到分配的发生static_branch_enable(&kfence_allocation_key);//内核发出 hung task警告的时间最短时间长度,为CONFIG_DEFAULT_HUNG_TASK_TIMEOUT的值if (sysctl_hung_task_timeout_secs) {//如果内存分配没有那么频繁,就有可能出现等待时间过长的问题,// 这里将等待超过时间设置为hung task警告时间的一半,// 这样,内核就不会因为处于D状态过长导致内核出现警告wait_event_idle_timeout(allocation_wait, atomic_read(&kfence_allocation_gate),sysctl_hung_task_timeout_secs * HZ / 2);} else {//如果hungtask检测时间为0,表示时间无限长,那么可以放心等待下去,直到有人从kfence中// 分配了内存,会将kfence_allocation_gate设为1,然后唤醒阻塞在allocation_wait里的任务wait_event_idle(allocation_wait, atomic_read(&kfence_allocation_gate));}/* 将static key关闭,保证不会进入 __kfence_alloc() */static_branch_disable(&kfence_allocation_key);
#endif//等待kfence_sample_interval,单位是毫秒,然后再次开启kfence内存池分配queue_delayed_work(system_unbound_wq, &kfence_timer,msecs_to_jiffies(kfence_sample_interval));
}注意 static key 需要 CONFIG_KFNECE_STATIC_KEYS 使能。
这里使用 static key,主要是来优化性能,每次读取 kfence_allocation_gate 的值是否为0来进行判断,这样的性能开销比较大。
另外,在此次 toggle 执行完成后,会再次调用 queue_delayed_work() 进入下一次work,只不过有个 delay——kfence_sample_interval。
至此,kfence 初始化过程基本剖析完成,整理流程图大致如下:

4. kfence 申请
kfence 申请的核心接口是 __kfence_alloc() 函数,系统中调用该函数有两个地方:
- kmem_cache_alloc_bulk()
- slab_alloc_node()
第一个函数只有在 io_alloc_req() 函数中调用,详见 fs/io_uring.c
第二个函数,如果只考虑 UMA 架构函数调用,起点只会是 slab_alloc() 函数,调用的地方有:
kmem_cache_alloc()
kmem_cache_alloc_trace()
__kmalloc()函数的细节可以查看《slub 分配器之kmem_cache_alloc》和《slub 分配器之kmalloc详解》
slab_alloc() 函数进一步会调用 slab_alloc_node():
mm/slub.cstatic __always_inline void *slab_alloc_node(struct kmem_cache *s,gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)
{void *object;struct kmem_cache_cpu *c;struct page *page;unsigned long tid;struct obj_cgroup *objcg = NULL;s = slab_pre_alloc_hook(s, &objcg, 1, gfpflags);if (!s)return NULL;object = kfence_alloc(s, orig_size, gfpflags);if (unlikely(object))goto out;...out:slab_post_alloc_hook(s, objcg, gfpflags, 1, &object);return object;
}函数最开始会尝试调用 kfence_alloc() 申请内存,如果成功申请到,会跳过一堆slab 快速分配、慢速分配的流程。这里不过多分析,详细可以查看《slub 分配器之kmem_cache_alloc》一文。
下面正式进入 kfence_alloc() 的流程。
4.1 kfence_alloc()
include/linux/kfence.hstatic __always_inline void *kfence_alloc(struct kmem_cache *s, size_t size, gfp_t flags)
{
#ifdef CONFIG_KFENCE_STATIC_KEYSif (static_branch_unlikely(&kfence_allocation_key))
#elseif (unlikely(!atomic_read(&kfence_allocation_gate)))
#endifreturn __kfence_alloc(s, size, flags);return NULL;
}前面的逻辑判断,在上文第 2.6 节、第 2.7 节已经提前阐述过了,这里不再过多叙述。
下面直接来看下kfence 分配的核心处理函数 __kfence_alloc()。
4.2 __kfence_alloc()
mm/kfence/core.cvoid *__kfence_alloc(struct kmem_cache *s, size_t size, gfp_t flags)
{//在 kfence_allocation_gate 切换之前,会首先确认申请的 size,必须要小于1个pageif (size > PAGE_SIZE)return NULL;//需要从 DMA、DMA32、HIGHMEM分配内存的话,kfence内存池不支持// 因为kfence 内存池的内存属性不一定满足要求,例如dma一般要求内存不带cache的,而kfence// 内存池不能保证这一点if ((flags & GFP_ZONEMASK) ||(s->flags & (SLAB_CACHE_DMA | SLAB_CACHE_DMA32)))return NULL;//kfence_allocation_gate只需要变成非0, 因此继续写它并付出关联的竞争代价没有意义if (atomic_read(&kfence_allocation_gate) || atomic_inc_return(&kfence_allocation_gate) > 1)return NULL;#ifdef CONFIG_KFENCE_STATIC_KEYS//检查allocation_wait中是否有进程在阻塞,有的话,会起一个work来唤醒被阻塞的进程if (waitqueue_active(&allocation_wait)) {/** Calling wake_up() here may deadlock when allocations happen* from within timer code. Use an irq_work to defer it.*/irq_work_queue(&wake_up_kfence_timer_work);}
#endif//在分配之前,确定kfence_enable是否被disable掉了if (!READ_ONCE(kfence_enabled))return NULL;//从kfence 内存池中分配objectreturn kfence_guarded_alloc(s, size, flags);
}主要的分配函数是 kfence_guarded_alloc(),下面单独开一节剖析。
4.3 kfence_guarded_alloc()
mm/kfence/core.cstatic void *kfence_guarded_alloc(struct kmem_cache *cache, size_t size, gfp_t gfp)
{struct kfence_metadata *meta = NULL;unsigned long flags;struct page *page;void *addr;//获取kfence_freelist中的metadata,上锁保护raw_spin_lock_irqsave(&kfence_freelist_lock, flags);//如果kfence_freelist不为空,则取出第一个metadataif (!list_empty(&kfence_freelist)) {meta = list_entry(kfence_freelist.next, struct kfence_metadata, list);list_del_init(&meta->list);}raw_spin_unlock_irqrestore(&kfence_freelist_lock, flags);//如果是否从kfence_freelist中取出metadata,如果kfence_freelist为空,则表示没有可用的metadataif (!meta)return NULL;//尝试给meta上锁,极度不愿意看到上锁失败//当UAF 的kfence会进行report,此时会对meta进行上锁,并且report 代码是通过printk,而printk// 会调用kmalloc(),而kmalloc()最终会调用kfence_alloc()去尝试抓取同一个用于report 的object//这里防止死锁,并如果出现上锁失败,会将刚抓取的metadata放回kfence_freelist尾部后返回NULLif (unlikely(!raw_spin_trylock_irqsave(&meta->lock, flags))) {/** This is extremely unlikely -- we are reporting on a* use-after-free, which locked meta->lock, and the reporting* code via printk calls kmalloc() which ends up in* kfence_alloc() and tries to grab the same object that we're* reporting on. While it has never been observed, lockdep does* report that there is a possibility of deadlock. Fix it by* using trylock and bailing out gracefully.*/raw_spin_lock_irqsave(&kfence_freelist_lock, flags);list_add_tail(&meta->list, &kfence_freelist);raw_spin_unlock_irqrestore(&kfence_freelist_lock, flags);return NULL;}//对metadata 上锁成功,开始处理metadata//首先,通过medata获取page的虚拟地址,该函数见下文meta->addr = metadata_to_pageaddr(meta);//在free的时候,为了防止UAF,会将该object page进行kfence_protect,而//当该object page再次被分配值,需要unprotect//之所以这里条件只判断FREED,是因为在UNUSED 时处于初始化,该page还没有被使用过,并不需要考虑protectif (meta->state == KFENCE_OBJECT_FREED)kfence_unprotect(meta->addr);/** Note: for allocations made before RNG initialization, will always* return zero. We still benefit from enabling KFENCE as early as* possible, even when the RNG is not yet available, as this will allow* KFENCE to detect bugs due to earlier allocations. The only downside* is that the out-of-bounds accesses detected are deterministic for* such allocations.*///如果随机数产生器初始化之前分配,那么object地址从该页的起始地址开始,//当随机数产生器可以工作了,那么将object放到该页的最右侧if (prandom_u32_max(2)) {meta->addr += PAGE_SIZE - size;meta->addr = ALIGN_DOWN(meta->addr, cache->align);}//确定最终的object起始地址addr = (void *)meta->addr;//该函数详细的剖析可以查看下文//主要做了几件事情:// 1. 通过状态确定使用alloc_track还是free_track,这里肯定选择alloc_track// 2. 将当前进程的调用栈记录到 alloc_track中;// 3. 获取当前进程的pid,并存放到track中// 4. 将当前最新状态更新到 metadata中,这里metadata状态变成ALLOCATED,进入分配metadata_update_state(meta, KFENCE_OBJECT_ALLOCATED);//将当前的kmem_cache记录到metadata中WRITE_ONCE(meta->cache, cache);//记录object 的sizemeta->size = size;//将metadata页中除了给object用的size空间之外的填充成一个跟地址相关的pattern数// 目的是在释放时检查是否发生越界访问//该函数详细的剖析,可以查看下文for_each_canary(meta, set_canary_byte);//获取对应的struct page结构虚拟地址,并进行赋值page = virt_to_page(meta->addr);page->slab_cache = cache;if (IS_ENABLED(CONFIG_SLUB))page->objects = 1;if (IS_ENABLED(CONFIG_SLAB))page->s_mem = addr;//metadata 数据处理完成,解锁raw_spin_unlock_irqrestore(&meta->lock, flags);/* Memory initialization. *///如果gfp设置了__GFP_ZERO,则返回true,从而会调用memzero_explicit()对object区域清零if (unlikely(slab_want_init_on_alloc(gfp, cache)))memzero_explicit(addr, size);//kmem_cache如果设定了构造,则调用if (cache->ctor)cache->ctor(addr);if (CONFIG_KFENCE_STRESS_TEST_FAULTS && !prandom_u32_max(CONFIG_KFENCE_STRESS_TEST_FAULTS))kfence_protect(meta->addr); /* Random "faults" by protecting the object. *///COUNTER_ALLOCATED,记录当前已经被分配出去的metadata数量,释放的时候会减1atomic_long_inc(&counters[KFENCE_COUNTER_ALLOCATED]);//COUNTER_ALLOCS,记录从kfence内存池分配内存的总的次数atomic_long_inc(&counters[KFENCE_COUNTER_ALLOCS]);return addr;
}4.3.1 metadata_to_pageaddr()
mm/kfence/core.cstatic inline unsigned long metadata_to_pageaddr(const struct kfence_metadata *meta)
{unsigned long offset = (meta - kfence_metadata + 1) * PAGE_SIZE * 2;unsigned long pageaddr = (unsigned long)&__kfence_pool[offset];/* The checks do not affect performance; only called from slow-paths. *//* Only call with a pointer into kfence_metadata. */if (KFENCE_WARN_ON(meta < kfence_metadata ||meta >= kfence_metadata + CONFIG_KFENCE_NUM_OBJECTS))return 0;/** This metadata object only ever maps to 1 page; verify that the stored* address is in the expected range.*/if (KFENCE_WARN_ON(ALIGN_DOWN(meta->addr, PAGE_SIZE) != pageaddr))return 0;return pageaddr;
}主要是获取metadata page 的虚拟地址。
通过参数 meta 确定 offset,接着就可以确定该 metadata 的虚拟地址。
注意这里的两处 KFENCE_WARN_ON(),笔者在上文第 2.3 节已经剖析过,kfence 不希望condition 成立,一旦成立 kfence_enabled 会被置为 false。
当然,如果 metadata 没有越界且metadata 的虚拟地址是页对齐,那就将该虚拟地址返回。
疑问:
笔者个人觉得这里的第一个判断条件可以提前到函数最开始,这样性能上更好一些。
4.3.2 metadata_update_state()
mm/kfence/core.cstatic noinline void metadata_update_state(struct kfence_metadata *meta,enum kfence_object_state next)
{struct kfence_track *track =next == KFENCE_OBJECT_FREED ? &meta->free_track : &meta->alloc_track;lockdep_assert_held(&meta->lock);/** Skip over 1 (this) functions; noinline ensures we do not accidentally* skip over the caller by never inlining.*/track->num_stack_entries = stack_trace_save(track->stack_entries, KFENCE_STACK_DEPTH, 1);track->pid = task_pid_nr(current);/** Pairs with READ_ONCE() in* kfence_shutdown_cache(),* kfence_handle_page_fault().*/WRITE_ONCE(meta->state, next);
}- 根据需要配置的object 状态,确定后面保存alloc或者free调用栈;
- 调用 stack_trace_save() 将调用栈保存到 track->stack_entries 中;
- 调用 task_pid_nr() 获取当前进程的pid;
- 设置metadata 的当前状态;
4.3.3 for_each_canary()
mm/kfence/core.cstatic __always_inline void for_each_canary(const struct kfence_metadata *meta, bool (*fn)(u8 *))
{//获取该 metadata的的页起始地址,按页向下对齐即可const unsigned long pageaddr = ALIGN_DOWN(meta->addr, PAGE_SIZE);unsigned long addr;lockdep_assert_held(&meta->lock);/** We'll iterate over each canary byte per-side until fn() returns* false. However, we'll still iterate over the canary bytes to the* right of the object even if there was an error in the canary bytes to* the left of the object. Specifically, if check_canary_byte()* generates an error, showing both sides might give more clues as to* what the error is about when displaying which bytes were corrupted.*///以object为界,分别对其左侧、右侧的canay bytes进行迭代,直到fn() 返回false//不管怎样,都会对右侧的canary bytes进行迭代,哪怕左侧迭代出错了//在check_canary_byte()会提示哪个byte被损坏的错误提示for (addr = pageaddr; addr < meta->addr; addr++) {if (!fn((u8 *)addr))break;}/* Apply to right of object. */for (addr = meta->addr + meta->size; addr < pageaddr + PAGE_SIZE; addr++) {if (!fn((u8 *)addr))break;}
}第二个参数是回调函数,对于 kfence 只有两种情况:
- 在 alloc 的时候为 set_canary_byte() 函数,用以设置canary byte;
- 在free 的时候为 check_canary_byte() 函数,用以检测是否有memory corruption;
mm/kfence/core.cstatic inline bool set_canary_byte(u8 *addr)
{*addr = KFENCE_CANARY_PATTERN(addr);return true;
}mm/kfence/kfence.h#define KFENCE_CANARY_PATTERN(addr) ((u8)0xaa ^ (u8)((unsigned long)(addr) & 0x7))set_canary_byte() 会将该字节写上个跟地址相关的 pattern 数。
mm/kfence/core.cstatic inline bool check_canary_byte(u8 *addr)
{if (likely(*addr == KFENCE_CANARY_PATTERN(addr)))return true;atomic_long_inc(&counters[KFENCE_COUNTER_BUGS]);kfence_report_error((unsigned long)addr, false, NULL, addr_to_metadata((unsigned long)addr),KFENCE_ERROR_CORRUPTION);return false;
}check_canary_byte() 用以确定该 canary byte是否被损坏。
如果出现越界访问了,则会进行处理:
- KFENCE_COUNTER_BUGS 计数增加;
- 调用kfence_report_error() 对该metadata 进行 ERROR_CORRUPTION 记录;
至此,kfence 内存分配的流程基本剖析完成,下面整理个流程:

5. kfence 释放
kfence 释放的核心接口是 __kfence_free() 函数,系统中调用该函数有两个地方:
- kmem_cache_free_bulk()
- slab_free()
在 kfree() 和 kmem_cache_free() 中会调用 slab_free() 函数。
函数的细节详细可以查看《slub 分配器之kmem_cache_free》和《slub 分配器之kmalloc详解》
slab_free() 进一步会调用 __slab_free() 函数:
mm/slub.cstatic void __slab_free(struct kmem_cache *s, struct page *page,void *head, void *tail, int cnt,unsigned long addr){void *prior;int was_frozen;struct page new;unsigned long counters;struct kmem_cache_node *n = NULL;unsigned long flags;stat(s, FREE_SLOWPATH);if (kfence_free(head))return;...
}函数最开始会调用 kfence_free() 进行确认该内存是否来源于 kfence,如果不是 kfence 内存,则会继续往下执行 slab的正常free 流程,详细可以查看《slub 分配器之kmem_cache_free》一文。
下面正式进入 kfence_free() 的流程。
5.1 kfence_free()
include/linux/kfence.hstatic __always_inline __must_check bool kfence_free(void *addr)
{if (!is_kfence_address(addr))return false;__kfence_free(addr);return true;
}函数做了两件事情:
- is_kfence_address() 确定该内存是否来源于 kfence 内存池;
- 如果是kfence 内存,调用__kfence_free() 进行释放处理;
5.1.1 is_kfence_address()
include/linux/kfence.hstatic __always_inline bool is_kfence_address(const void *addr)
{return unlikely((unsigned long)((char *)addr - __kfence_pool) < KFENCE_POOL_SIZE && __kfence_pool);
}
代码比较简单,该内存如果来源于kfence 内存池,那么 addr - __kfence_pool 肯定就是内存偏移,这个偏移是不可能超过内存池最大size KFNECE_POOL_SIZE,另外,__kfence_pool 这个变量肯定不能为NULL。
下面直接来看下kfence 释放的核心处理函数 __kfence_free()。
5.2 __kfence_free()
mm/kfence/core.cvoid __kfence_free(void *addr)
{struct kfence_metadata *meta = addr_to_metadata((unsigned long)addr);//如果metadata对应的kmem_cache有SLAB_TYPESAFE_BY_RCU,那么不能立即释放,// 而是进行异步处理,当过了一个宽限期再释放if (unlikely(meta->cache && (meta->cache->flags & SLAB_TYPESAFE_BY_RCU)))call_rcu(&meta->rcu_head, rcu_guarded_free);elsekfence_guarded_free(addr, meta, false);
}函数共三个注意点:
- 通过 addr 获取 metadata,详细看下文第 5.2.1 节;
- 确定meta中kmem_cache 是否有 SLAB_TYPESAFE_BY_RCU;
- 调用 kfence_guarded_free() 进行kfence 内存释放;
可以看到,主要的释放函数是 kfence_guarded_free(),下面单独开一节剖析,详细看下文第 5.3 节。
5.2.1 addr_to_metadata()
mm/kfence/core.cstatic inline struct kfence_metadata *addr_to_metadata(unsigned long addr)
{long index;/* The checks do not affect performance; only called from slow-paths. */if (!is_kfence_address((void *)addr))return NULL;/** May be an invalid index if called with an address at the edge of* __kfence_pool, in which case we would report an "invalid access"* error.*/index = (addr - (unsigned long)__kfence_pool) / (PAGE_SIZE * 2) - 1;if (index < 0 || index >= CONFIG_KFENCE_NUM_OBJECTS)return NULL;return &kfence_metadata[index];
}该函数是 metadata_to_pageaddr()的逆过程:
- 首先确定 addr 有效性,是否为 kfence 内存;
- 接着确定 addr 相对于 __kfence_pool 的偏移,注意会将 __kfence_pool 前两个page 自动跳过;
- 最后根据偏移,从 kfence_metadata 数组中获取到 metadata;
5.3 kfence_guarded_free()
mm/kfence/core.cstatic void kfence_guarded_free(void *addr, struct kfence_metadata *meta, bool zombie)
{struct kcsan_scoped_access assert_page_exclusive;unsigned long flags;raw_spin_lock_irqsave(&meta->lock, flags);if (meta->state != KFENCE_OBJECT_ALLOCATED || meta->addr != (unsigned long)addr) {/* Invalid or double-free, bail out. */atomic_long_inc(&counters[KFENCE_COUNTER_BUGS]);kfence_report_error((unsigned long)addr, false, NULL, meta,KFENCE_ERROR_INVALID_FREE);raw_spin_unlock_irqrestore(&meta->lock, flags);return;}/* Detect racy use-after-free, or incorrect reallocation of this page by KFENCE. */kcsan_begin_scoped_access((void *)ALIGN_DOWN((unsigned long)addr, PAGE_SIZE), PAGE_SIZE,KCSAN_ACCESS_SCOPED | KCSAN_ACCESS_WRITE | KCSAN_ACCESS_ASSERT,&assert_page_exclusive);if (CONFIG_KFENCE_STRESS_TEST_FAULTS)kfence_unprotect((unsigned long)addr); /* To check canary bytes. *//* Restore page protection if there was an OOB access. */if (meta->unprotected_page) {memzero_explicit((void *)ALIGN_DOWN(meta->unprotected_page, PAGE_SIZE), PAGE_SIZE);kfence_protect(meta->unprotected_page);meta->unprotected_page = 0;}/* Check canary bytes for memory corruption. */for_each_canary(meta, check_canary_byte);/** Clear memory if init-on-free is set. While we protect the page, the* data is still there, and after a use-after-free is detected, we* unprotect the page, so the data is still accessible.*/if (!zombie && unlikely(slab_want_init_on_free(meta->cache)))memzero_explicit(addr, meta->size);/* Mark the object as freed. */metadata_update_state(meta, KFENCE_OBJECT_FREED);raw_spin_unlock_irqrestore(&meta->lock, flags);/* Protect to detect use-after-frees. */kfence_protect((unsigned long)addr);kcsan_end_scoped_access(&assert_page_exclusive);if (!zombie) {/* Add it to the tail of the freelist for reuse. */raw_spin_lock_irqsave(&kfence_freelist_lock, flags);KFENCE_WARN_ON(!list_empty(&meta->list));list_add_tail(&meta->list, &kfence_freelist);raw_spin_unlock_irqrestore(&kfence_freelist_lock, flags);atomic_long_dec(&counters[KFENCE_COUNTER_ALLOCATED]);atomic_long_inc(&counters[KFENCE_COUNTER_FREES]);} else {/* See kfence_shutdown_cache(). */atomic_long_inc(&counters[KFENCE_COUNTER_ZOMBIES]);}
}
参考:
https://www.kernel.org/doc/html/latest/dev-tools/kfence.html
相关文章:
linux 内存检测工具 kfence 详解
版本基于: Linux-5.10 约定: PAGE_SIZE:4K 内存架构:UMA 0. 前言 本文 kfence 之外的代码版本是基于 Linux5.10,最近需要将 kfence 移植到 Linux5.10 中,本文借此机会将 kfence 机制详细地记录一下。 k…...

虚拟机VMware Workstation Pro安装配置使用服务器系统ubuntu-22.04.3-live-server-amd64.iso
虚拟机里安装ubuntu-23.04-beta-desktop-amd64开启SSH(换源和备份)配置中文以及中文输入法等 一、获取Ubuntu服务器版 获取Ubuntu服务器版 二、配置虚拟机 选择Custom(advanced): 选择Workstation 17.x: 选择“I will install the operating system later.”…...
)
《C程序设计》笔记(ch1-2)
第1章 程序设计和C语言 1.2 什么是计算机语言 人和计算机都能识别的语言,就是计算机语言。 符号语言用一些英文字母和数字表示一个指令。汇编程序:符号语言的指令→机器指令。 编译程序:源程序→机器指令。 1.4 最简单的C语言程序 每一…...
【Overload游戏引擎细节分析】Lambert材质Shader分析
一、经典光照模型:Phong模型 现实世界的光照是极其复杂的,而且会受到诸多因素的影响,这是以目前我们所拥有的处理能力无法模拟的。经典光照模型冯氏光照模型(Phong Lighting Model)通过单独计算光源成分得到综合光照效果,然后添加…...
二进制搭建 Kubernetes+部署网络组件+部署CornDNS+负载均衡部署+部署Dashboard
二进制搭建 Kubernetes v1.20 k8s集群master01:20.0.0.50 kube-apiserver kube-controller-manager kube-scheduler etcd k8s集群master02:20.0.0.100k8s集群node01:20.0.0.110 kubelet kube-proxy docker etcd k8s集群node02:20.…...
】)
【 OpenGauss源码学习 —— 列存储(update_pages_and_tuples_pgclass)】
列存储(update_pages_and_tuples_pgclass) 概述update_pages_and_tuples_pgclass 函数ReceivePageAndTuple 函数estimate_cstore_blocks 函数get_attavgwidth 函数get_typavgwidth 函数 vac_update_relstats 函数 测试案例 声明:本文的部分内…...
爬虫进阶-反爬破解7(逆向破解被加密数据:全方位了解字体渲染的全过程+字体文件的检查和数据查看+字体文件转换并实现网页内容还原+完美还原上百页的数据内容)
目录 一、全方位了解字体渲染的全过程 1.加载顺序 2.实践操作:浏览器中调试字体渲染 3.总结: 二、字体文件的检查和数据查看 1.字体文件的操作软件 2.映射关系的建立 3.实践操作:翻找样式和真实内容 4.总结: 三、字体文…...

系统架构设计师之RUP软件开发生命周期
系统架构设计师之RUP软件开发生命周期...
VM虚拟机 13.5 for Mac
VMware Fusion Pro for Mac是一款强大的虚拟机软件,可以在Mac操作系统中创建、运行和管理多个虚拟机,使用户可以在一台Mac电脑上同时运行多个操作系统和应用程序。 以下是VMware Fusion Pro for Mac的主要特点: 1. 支持多种操作系统ÿ…...

一篇教你学会Ansible
前言 Ansible首次发布于2012年,是一款基于Python开发的自动化运维工具,核心是通过ssh将命令发送执行,它可以帮助管理员在多服务器上进行配置管理和部署。它的工作形式依托模块实现,自己没有批量部署的能力。真正具备批量部署的是…...
Mysql第四篇---数据库索引优化与查询优化
文章目录 数据库索引优化与查询优化索引失效案例数据准备1. 全值匹配2 最佳左前缀法则(联合索引)主键插入顺序4 计算、函数导致索引失效5 类型转换(自动或手动)导致索引失效6 范围条件右边的列索引失效7 不等于(!或者<>)索引失效8 is null可以使用索引, is not null无法使…...

SpringBoot手动获取实例
1.首先创建一个接口里面是关于建库建表的方法 public interface MetaMapper {//三个核心建表方法void createExchangeTable();void createQueueTable();void createBingdingTable(); } 2.启动类中定义一个ConfigurableApplicationContext 类型的变量context接收SpringApplica…...

栈(Stack)的概念+MyStack的实现+栈的应用
文章目录 栈(Stack)一、 栈的概念1.栈的方法2.源码分析 二、MyStack的实现1.MyStack的成员变量2.push方法3.isEmpty方法和pop方法4.peek方法 三、栈的应用1.将递归转化为循环1.调用递归打印2.通过栈逆序打印链表 栈(Stack) 一、 栈…...

C语言进阶第九课 --------动态内存管理
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...
嵌入式 Tomcat 调校
SpringBoot 嵌入了 Web 容器如 Tomcat/Jetty/Undertow,——这是怎么做到的?我们以 Tomcat 为例子,尝试调用嵌入式 Tomcat。 调用嵌入式 Tomcat,如果按照默认去启动,一个 main 函数就可以了。 简单的例子 下面是启动…...

初始化固定长度的数组
完全解析Array.apply(null,「length: 1000」) 创建固定长度数组,并且初始化值。直接可以使用map、forEach、reduce等有遍历性质的方法。 如果直接使用Array(81),map里面的循环不会执行。 //方法一 Array.apply(null, { length: 20 })//方法二 Array(81)…...
实现基于 Jenkins 的多服务器打包方案
实现基于 Jenkins 的多服务器打包方案 在实际项目中,我们经常会遇到需要将一个应用程序或服务部署到不同的服务器上的需求。而使用 Jenkins 可以很方便地自动化这个过程。 设置参数 首先,我们需要设置一些参数,以便在构建过程中指定要部署…...

探索现代IT岗位:职业机遇的海洋
目录 1 引言2 传统软件开发3 数据分析与人工智能4 网络与系统管理5 信息安全6 新兴技术领域 1 引言 随着现代科技的迅猛发展,信息技术(IT)行业已经成为了全球经济的关键引擎,改变了我们的生活方式、商业模式和社会互动方式。IT行…...

np.linspace精确度
前言 今天发现一个大坑,如果是序列是小数的话,不要用np.linspace,而要用np.arrange指定等差序列。比如入下图中a和b是一样的意思,但是b是有较大误差的。 anp.arange(0,4,0.4) bnp.linspace(0,4,10) print("a",a) prin…...

GD32_定时器输入捕获波形频率
GD32_定时器输入捕获波形频率(多通道轮询) 之前项目上用到一个使用定时器捕获输入采集风扇波形频率得到风扇转速的模块,作为笔记简单记录以下当时的逻辑结构和遇到的问题,有需要参考源码、有疑问或需要提供帮助的可以留言告知 。…...

Java并发编程:CompletableFuture实战
Java并发编程:CompletableFuture实战 引言 Java 8引入的CompletableFuture是现代异步编程的重要工具,它不仅解决了Future的局限性,还提供了丰富的API用于组合、转换和处理异步结果。相比传统的Future,CompletableFuture支持流式调…...

柔性LED灯丝DIY:从电路原理到创意饰品制作全攻略
1. 项目概述:当生日遇上柔性LED灯丝给孩子的生日派对准备一份独一无二的、会发光的惊喜,是很多家长和手工爱好者的心愿。这次,我们不买现成的塑料灯牌,而是亲手做一个能戴在头上或挂在脖子上的“生日数字灯冠”。这个项目的核心&a…...

SAP KO88结算时,如何用BADI_FINS_ACDOC_POSTING_EVENTS把成本中心塞进自定义字段?
SAP KO88结算实战:通过BADI_FINS_ACDOC_POSTING_EVENTS实现成本中心到自定义字段的精准映射 在SAP工单结算(KO88)的复杂业务场景中,财务凭证的标准化字段往往无法满足企业多维度的分析需求。特别是当需要将特定成本中心信息映射到…...

AI智能体生态的包管理器:agenticmarket-cli 设计与实践
1. 项目概述:一个面向AI智能体生态的命令行工具如果你和我一样,长期在AI智能体(Agent)这个领域里折腾,那你肯定经历过这样的场景:为了测试一个最新的开源智能体框架,你需要先找到它的GitHub仓库…...

3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验
3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验 【免费下载链接】TaskbarX Center Windows taskbar icons with a variety of animations and options. 项目地址: https://gitcode.com/gh_mirrors/ta/TaskbarX 你是否厌倦了Windows任务栏图标总是靠左…...

开源虚拟世界引擎Vircadia核心架构与部署实战指南
1. 项目概述:一个开源虚拟世界的核心引擎如果你对构建一个属于自己的、去中心化的虚拟世界感兴趣,那么你很可能已经听说过或者正在寻找一个合适的底层引擎。今天要聊的这个项目,就是这样一个领域的重量级选手:vircadia/vircadia-n…...

openpilot自动驾驶系统深度解析:架构剖析与实战指南
openpilot自动驾驶系统深度解析:架构剖析与实战指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/…...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...
)
STM8硬件IIC驱动BNO055传感器避坑指南(附完整代码)
STM8硬件IIC驱动BNO055传感器实战解析与优化 BNO055作为一款集成了9轴传感器融合算法的智能芯片,能够直接输出姿态角数据,极大简化了嵌入式系统中姿态解算的复杂度。然而在实际应用中,许多开发者发现使用STM32等常见MCU的模拟IIC接口难以稳定…...
)
【Midjourney数字艺术风格终极指南】:20年AI视觉专家亲授7大核心风格参数调优法则(含V6.1新增Realism Mode实测数据)
更多请点击: https://intelliparadigm.com 第一章:Midjourney数字艺术风格演进与V6.1核心变革 Midjourney自V1发布以来,其图像生成范式经历了从纹理模拟到语义理解、从风格模仿到跨模态协同的深层跃迁。V6.1标志着模型首次在原生架构中集成…...