Hadoop3.0大数据处理学习1(Haddop介绍、部署、Hive部署)
Hadoop3.0快速入门
学习步骤:
- 三大组件的基本理论和实际操作
- Hadoop3的使用,实际开发流程
- 结合具体问题,提供排查思路
开发技术栈:
- Linux基础操作、Sehll脚本基础
- JavaSE、Idea操作
- MySQL
Hadoop简介
Hadoop是一个适合海量数据存储与计算的平台。是基于Google的GoogleFS、Map Reduce、BigTable实现的。
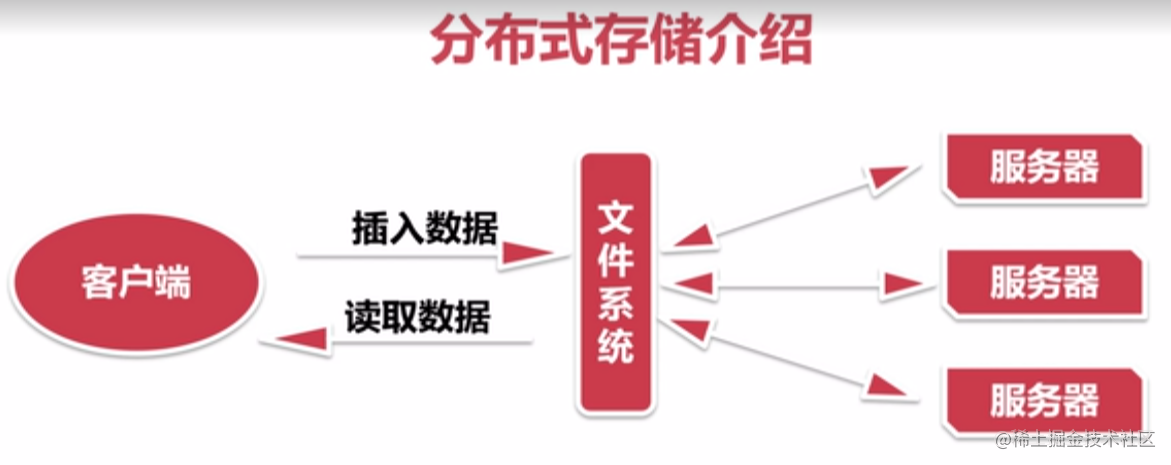
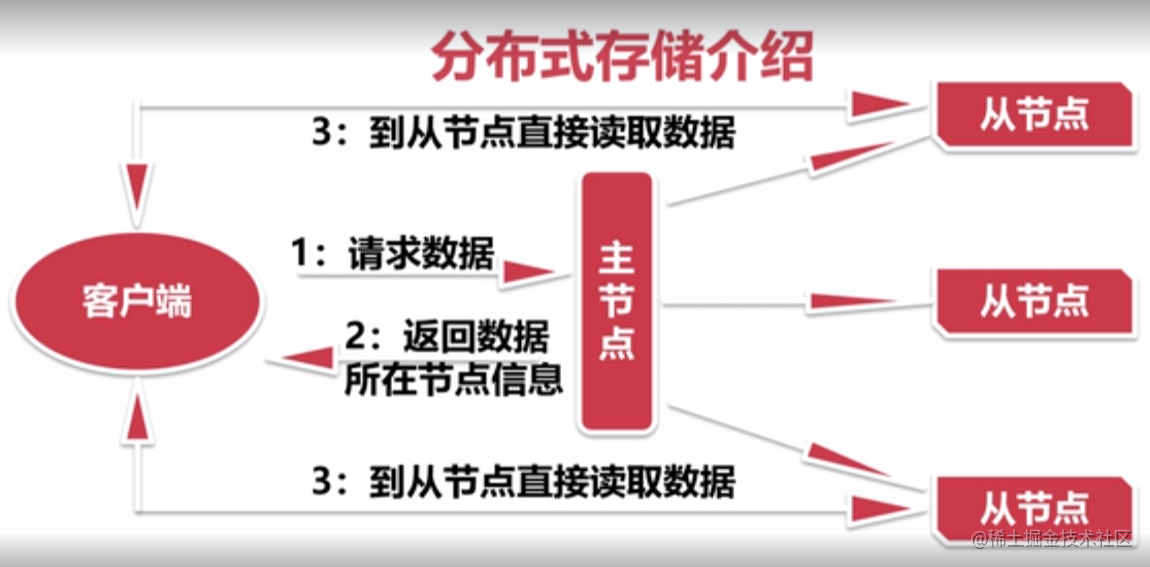
分布式存储介绍
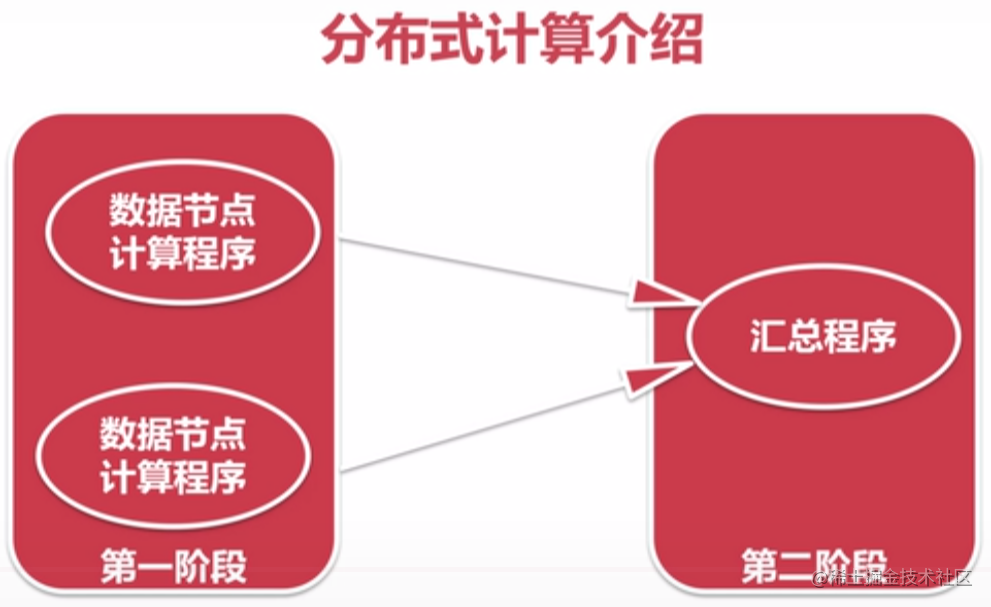
分布式计算介绍
- 移动数据:数据 -> 计算程序
- 移动计算:计算程序 -> 数据
- 分布式计算:各个节点局部计算 -> 第二阶段汇总程序
Hadoop三大核心组件

HDFS(分布式存储系统)
架构分析:
- HDFS负责海量数据的分布式存储。
- 支持主从架构,主节点支持多个NameNode,从节点支持多个DataNode。
- NameNode负责接收用户请求,维护目录系统的目录结构。DataNode主要负责存储数据。
MapReduce(分布式计算框架)
架构分析:
- MapReduce是一个编程模型,主要负责海量数据计算,主要由两个阶段组成:Map和Reduce。
- Map阶段是一个独立的程序,会在很多个节点上同时执行,每个节点处理一部分数据。
- Reduce节点也是一个独立的程序,在这先把Reduce理解为一个单独的聚合程序即可。
Yarn(资源管理与调度)
架构分析:
- 主要负责集权资源的管理和调度,支持主从架构,主节点最多可以有2个,从节点可以有多个。
- 主节点(ResourceManager)进程主要负责集群资源的分配和管理。
- 从节点(NodeManager)主要负责单节点资源管理。
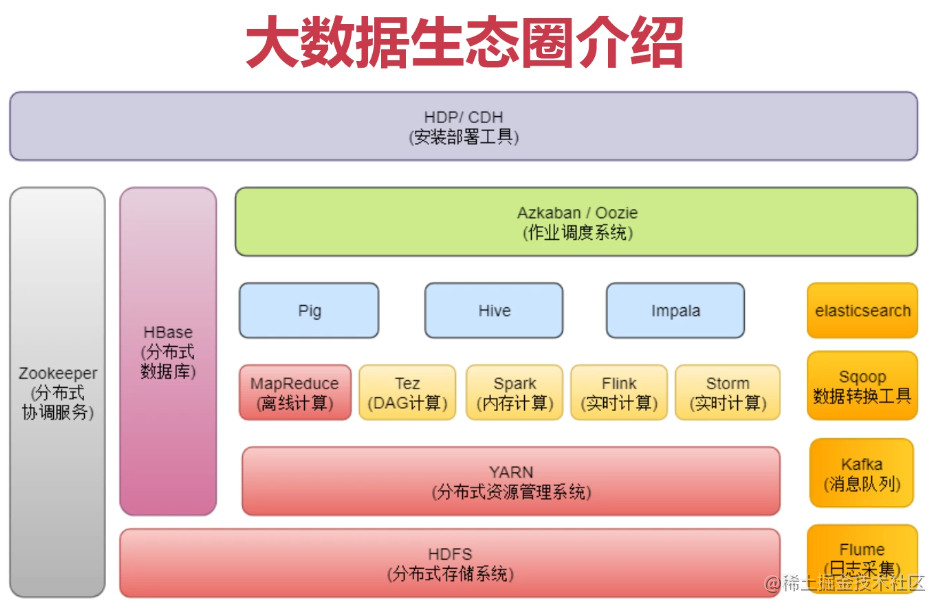
大数据生态圈
Hadoop安装部署
Hadoop发行版介绍
- 官方版本:Apache Hadoop,开源,集群安装维护比较麻烦
- 第三方发行版:Cloudera Hadoop(CDH),商业收费,使用Cloudera Manager安装维护比较方便
- 第三方发行版:HortonWorks(HDP),开源,使用Ambari安装维护比较方便。
伪分布式集群安装部署(使用1台Linux虚拟机安装伪分布式集群)
1. 静态IP设置
192.168.56.101
2. 主机名设置(临时、永久)
cent7-1
3. hosts文件修改(配置IP与主机名映射关系)
cent7-1 localhost
4. 关闭防火墙(临时、永久)
systemctl status firewalld.service
systemctl stop firewalld
systemctl status firewalld.service
5. ssh免密登录
ssh-keygen -t rsa
cd /root
cd .ssh/
cat id_rsa
cat id_rsa.pub >> authorized_keys
ssh cent7-1
6. JDK1.8安装
tar -zxvf jdk-8u191-linux-x64.tar.gz
vi /etc/profile
source /etc/profile# profile配置内容
export JAVA_HOME=/home/jdk8
export PATH=.:$JAVA_HOME/bin:$PATH
7. Hadoop伪分布式安装
# 解压Hadoop
tar -zxvf hadoop-3.2.4.tar.gz
# 进入配置文件目录
cd /home/hadoop-3.2.4/etc/hadoopvi core-site.xml vi hdfs-site.xml
- 配置core-site.xml
<property><name>fs.defaultFS</name><value>hdfs://cent7-1:9000</value><final>true</final>
</property>
<property><name>hadoop.tmp.dir</name><value>/home/hadoop_repo</value>
</property>
- 配置hdfs-site.xml
<!-- 指定HDFS副本的数量,伪分布式集群最多一个,也不支持多个 -->
<property><name>dfs.replication</name><value>1</value>
</property>
- 配置hdfs-site.xml
<!-- 指定MR运行在Yarn上 -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
- 配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager白名单 -->
<property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
- 配置 hadoop-env.sh
export JAVA_HOME=/home/jdk8
export HADOOP_LOG_DIR=/home/hadoop_repo/logs/hadoop
- 初始化hdfs
# 在Hadoop的目录下执行以下命令,
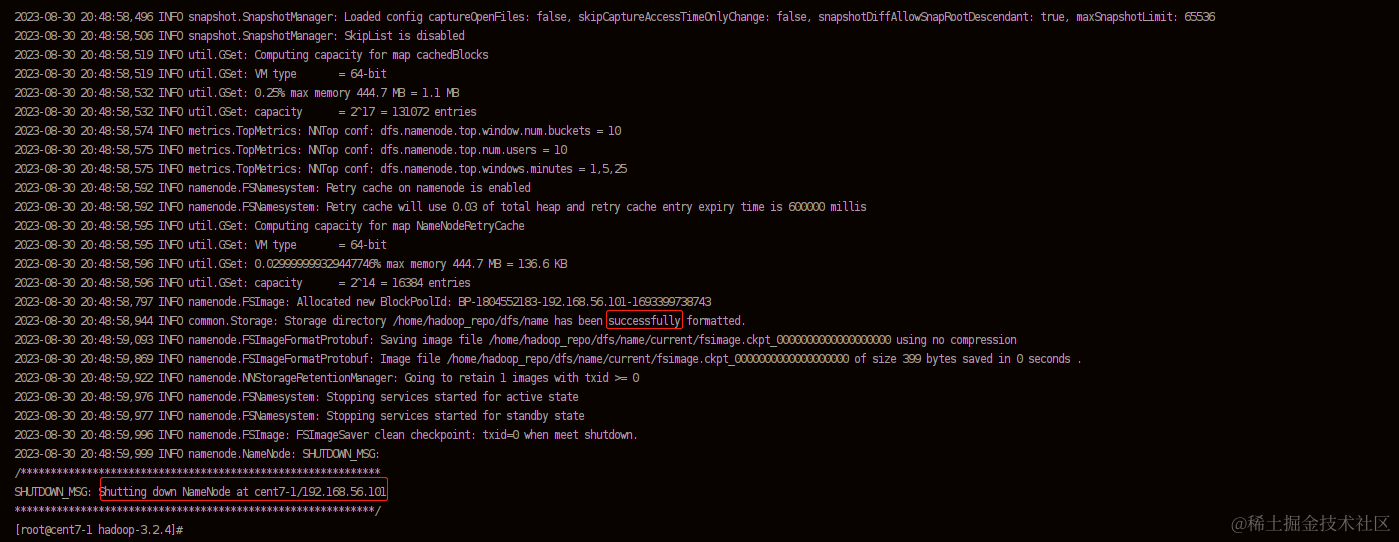
bin/hdfs namenode -format
看到以下内容说明执行成功!注意:hdfs格式化只能执行一次,如果失败需要删除文件夹后再进行格式化。
启动
[root@cent7-1 hadoop-3.2.4]# sbin/start-all.sh
Starting namenodes on [cent7-1]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [cent7-1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
# 提示缺少hdfs、yarn的用户信息
- 配置start-dfs.sh、stop-dfs.sh
vi sbin/start-dfs.sh
vi sbin/stop-dfs.sh
#增加配置
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 配置
vi sbin/start-yarn.sh
vi sbin/stop-yarn.sh
#增加配置
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 再次启动
[root@cent7-1 hadoop-3.2.4]# sbin/start-all.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [cent7-1]
上一次登录:三 8月 30 19:05:12 CST 2023从 192.168.56.1pts/1 上
Starting datanodes
上一次登录:三 8月 30 21:02:51 CST 2023pts/0 上
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Starting secondary namenodes [cent7-1]
上一次登录:三 8月 30 21:02:56 CST 2023pts/0 上
Starting resourcemanager
上一次登录:三 8月 30 21:03:49 CST 2023从 192.168.56.1pts/3 上
Starting nodemanagers
上一次登录:三 8月 30 21:04:13 CST 2023pts/0 上
[root@cent7-1 hadoop-3.2.4]# jps
10146 NameNode
10386 DataNode
10883 SecondaryNameNode
11833 ResourceManager
12954 Jps
12155 NodeManager
# 展示除了jps外的五个Hadoop组件进程表示启动成功
- 浏览器确认启动成功
- 访问HDFS:http://192.168.56.101:9870/
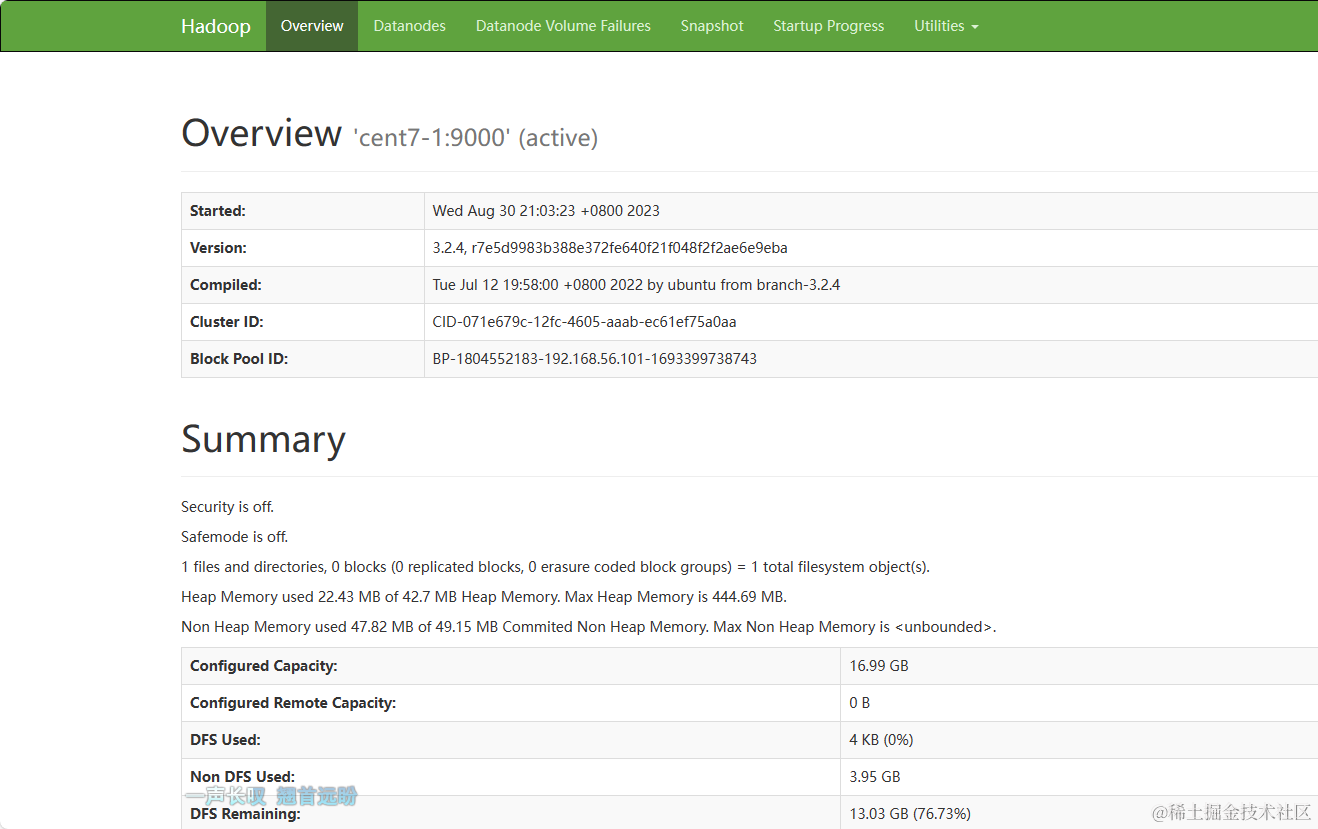
- 访问Hadoop:http://192.168.56.101:8088/

- 访问HDFS:http://192.168.56.101:9870/
停止
sbin/stop-all.sh
分布式集群安装部署(使用3台Linux虚拟机安装分布式集群)
客户端节点安装介绍
HIVE安装部署
mysql安装部署
yum install mysql
hive下载与部署
apache-hive-hive-3.1.3安装包下载_开源镜像站-阿里云 (aliyun.com)
source /etc/profile
export HIVE_HOME=/home/hive
export PATH=$HIVE_HOME/bin:$PATH
配置hive/conf/hive-site.xml文件
<configuration>
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://cent7-1:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property> <name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value>
</property>
<property> <name>javax.jdo.option.ConnectionUserName</name><value>hdp</value>
</property>
<property> <name>javax.jdo.option.ConnectionPassword</name><value>admin</value>
</property>
<!--自定义远程连接用户名和密码-->
<property><name>hive.server2.authentication</name><value>CUSTOM</value><!--默认为none,修改成CUSTOM-->
</property>
<!--指定解析jar包-->
<property><name>hive.server2.custom.authentication.class</name><value>com.ylw.CustomHiveServer2Auth</value>
</property>
<property><name>hive.server2.custom.authentication.file</name><value>/home/hive/user.pwd.conf</value>
</property>
<!--设置用户名和密码-->
<property><name>hive.jdbc_passwd.auth.root</name><!--用户名为最后一个:root--><value>admin</value>
</property>
<property><name>hive.metastore.port</name><value>9083</value><description>Hive metastore listener port</description>
</property>
<property><name>hive.server2.thrift.port</name><value>10000</value><description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description>
</property>
<property><!-- <value>新的最大工作线程数</value>--><name>hive.server2.thrift.max.worker.threads</name><value>200</value>
</property>
<property><name>hive.metastore.local</name><value>false</value><description>controls whether to connect to remote metastore server or open a new metastore server in Hive Client JVM</description>
</property>
<property><name>hive.server2.transport.mode</name><value>binary</value><description>Expects one of [binary, http].Transport mode of HiveServer2.</description>
</property>
</configuration>
启动与停止hive
nohup hive --server metastore &
nohup hive --service hiveserver2 &
jps
#看到是否有两个runJar ,如果有说明启动成功
# 查看端口占用
netstat -anop |grep 10000
ps -aux|grep hive
相关文章:
Hadoop3.0大数据处理学习1(Haddop介绍、部署、Hive部署)
Hadoop3.0快速入门 学习步骤: 三大组件的基本理论和实际操作Hadoop3的使用,实际开发流程结合具体问题,提供排查思路 开发技术栈: Linux基础操作、Sehll脚本基础JavaSE、Idea操作MySQL Hadoop简介 Hadoop是一个适合海量数据存…...
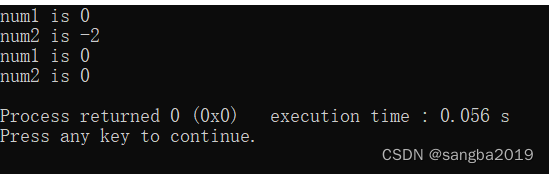
C笔记:引用调用,通过指针传递
代码 #include<stdio.h> int max1(int num1,int num2) {if(num1 < num2){num1 num2;}else{num2 num1;} } int max2(int *num1,int *num2) {if(num1 < num2){*num1 *num2; // 把 num2 赋值给 num1 }else{*num2 *num1;} } int main() {int num1 0,num2 -2;int…...
【方法】如何给PDF文件添加“打开密码”?
PDF文件可以在线浏览,但如果想要给文件添加“打开密码”,就需要用到软件工具,下面小编分享两种常用的工具,小伙伴们可以根据需要选择。 工具一:PDF编辑器 PDF阅读器一般是没有设置密码的功能模块,PDF编辑器…...
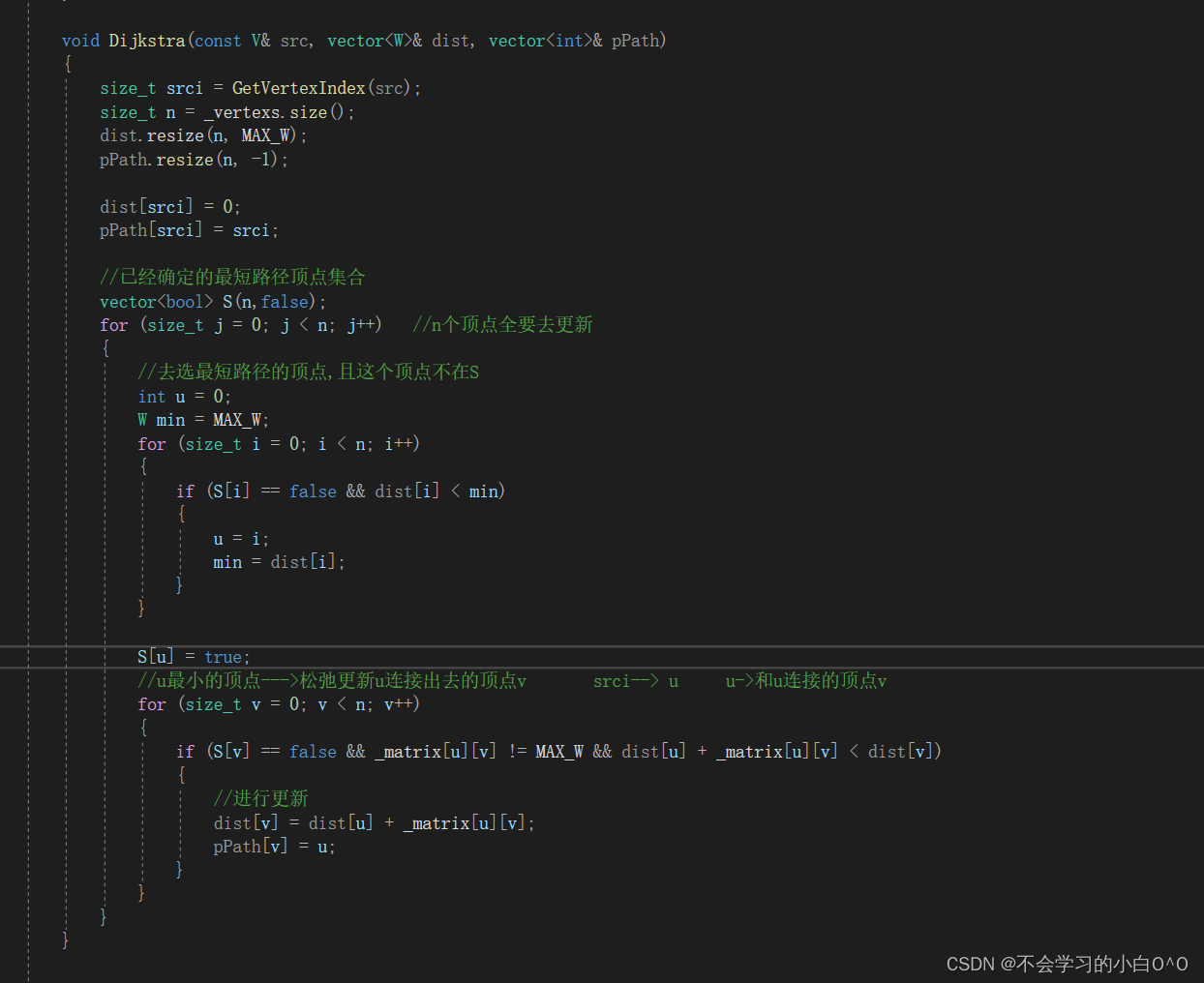
单源最短路径 -- Dijkstra
Dijkstra算法就适用于解决带权重的有向图上的单源最短路径问题 -- 同时算法要求图中所有边的权重非负(这个很重要) 针对一个带权有向图G , 将所有节点分为两组S和Q , S是已经确定的最短路径的节点集合,在初始时为空&…...

Java--多态及抽象类与接口
1.多态 以不同参数调用父类方法,可以得到不同的处理,子类中无需定义相同功能的方法,避免了重复代码编写,只需要实例化一个继承父类的子类对象,即可调用相应的方法,而只需要维护附父类方法即可。 package c…...
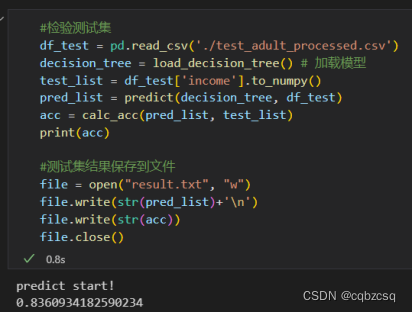
Python手搓C4.5决策树+Azure Adult数据集分析
前言 课上的实验 由于不想被抄袭,所以暂时不放完整代码 Adult数据集可以在Azure官网上找到 Azure 开放数据集中的数据集 - Azure Open Datasets | Microsoft Learn 数据集预处理 删除难以处理的权重属性fnlwgt与意义重复属性educationNum去除重复行与空行删除…...

【tg】6: MediaManager的主要功能
【tg】2:视频采集的输入和输出 的管理者是 media manager‘ media 需要 network的支持:NetworkInterface friend class MediaManager::NetworkInterfaceImpl;NetworkInterfaceImpl 直接持有 MediaManager 的指针即可:发送rtp包、rtcp包、设置socket选项?...

NPM-安装报错connect ETIMEDOUT
报错信息request to https://registry.npm.taobao.org/yarn failed, reason: connect ETIMEDOUT 解决方案: 1、npm set strict-ssl false 2、设置代理 npm config set proxy http://xxx:xxxopenproxy.ali.com:8080npm如何在安装的时候指定源 npm install -g yarn1.…...

机器学习之查准率、查全率与F1
文章目录 查准率(Precision):查全率(Recall):F1分数(F1 Score):实例P-R曲线F1度量python实现 查准率(Precision): 定义: …...
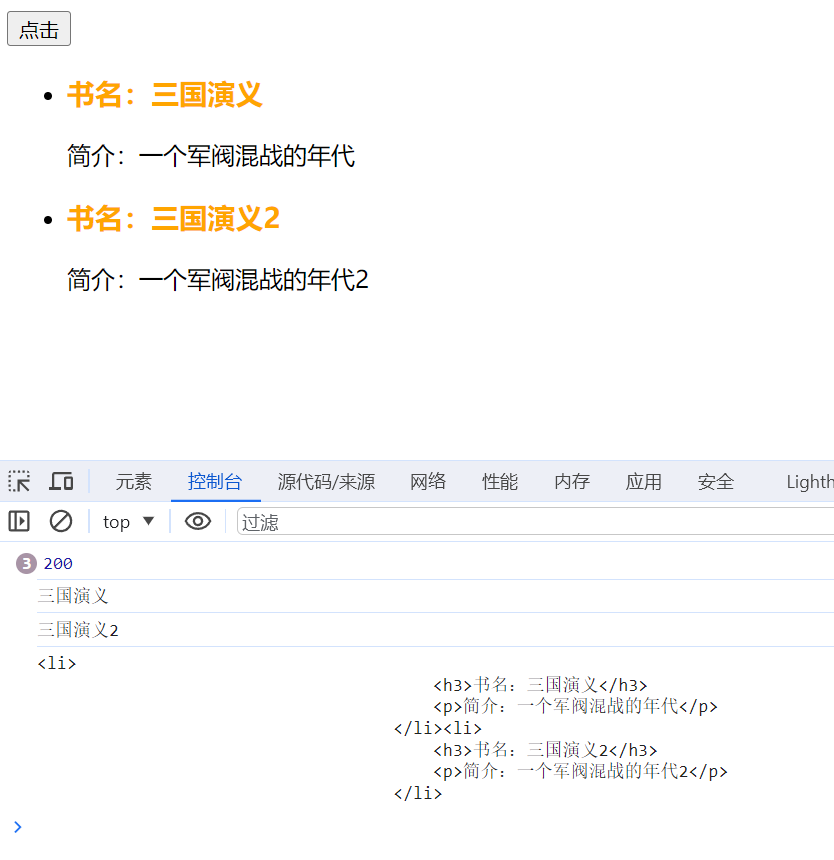
*Django中的Ajax 纯js的书写样式1
搭建项目 建立一个Djano项目,建立一个app,建立路径,视图函数大多为render, Ajax的创建 urls.py path(index/,views.index), path(index2/,views.index2), views.py def index(request):return render(request,01.html) def index2(requ…...

谈谈node架构中的线程进程的应用场景、事件循环及任务队列
本文作者系360奇舞团前端开发工程师 文章标题:谈谈node架构中的线程进程的应用场景、事件循环及任务队列 Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,nodejs是单线程执行的,它基于事件驱动和非阻塞I/O模型进行多任务的执行。在理…...

http代理IP它有哪些应用场景?如何提升访问速度?
随着互联网的快速发展,越来越多的人开始关注网络速度和安全性。其中,代理IP技术作为一种有效的网络加速和安全解决方案,越来越受到人们的关注。那么,http代理IP有哪些应用场景?又如何提升访问速度呢? 一、h…...

Armv8/Armv9的VIPT的别名问题是如何解决的
https://www.cse.unsw.edu.au/~cs9242/02/lectures/03-cache/node8.html https://developer.arm.com/documentation/ddi0406/b/System-Level-Architecture/Virtual-Memory-System-Architecture–VMSA-/Address-mapping-restrictions...
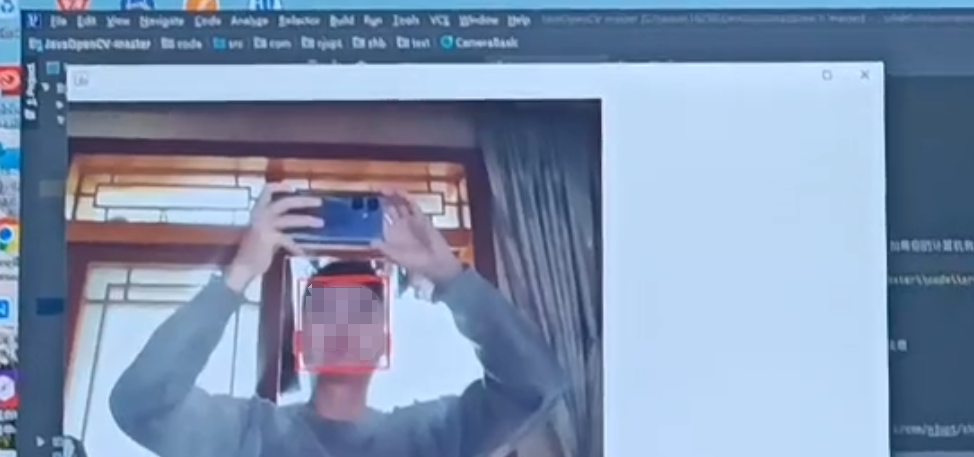
java/javaswing/窗体程序,人脸识别系统,人脸追踪,计算机视觉
源码下载地址 支持:远程部署/安装/调试、讲解、二次开发/修改/定制 源码下载地址...
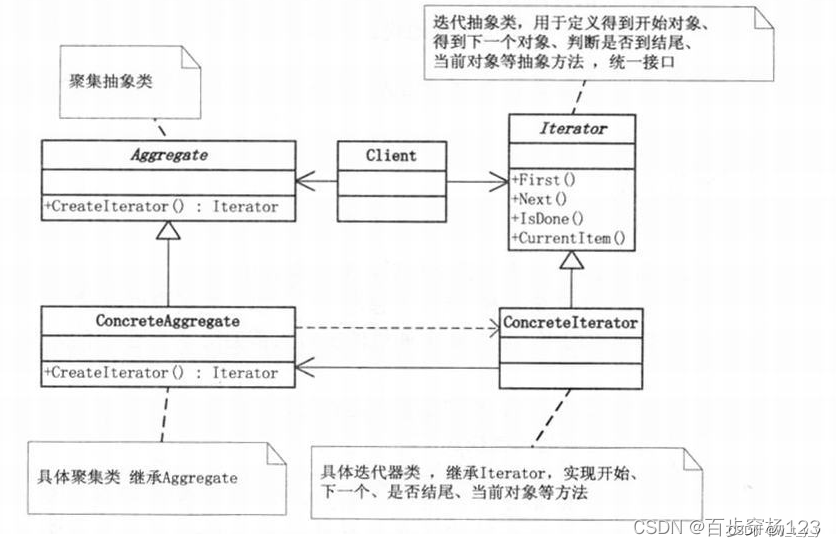
设计模式(16)迭代器模式
一、介绍: 1、定义:迭代器模式 (Iterator Pattern) 是一种行为型设计模式,它提供一种顺序访问聚合对象(如列表、集合等)中的元素,而无需暴露聚合对象的内部表示。迭代器模式将遍历逻辑封装在一个迭代器对象…...
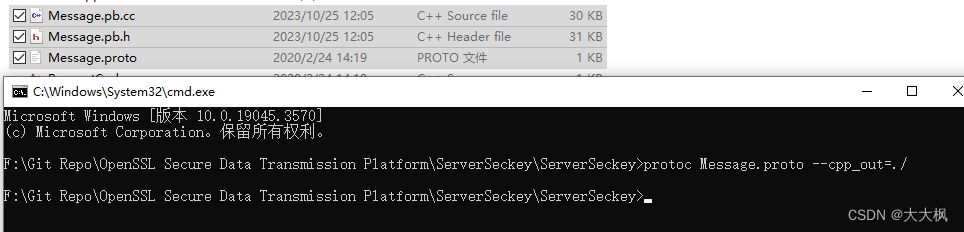
Openssl数据安全传输平台011:秘钥协商服务端
0. 代码仓库 https://github.com/Chufeng-Jiang/OpenSSL_Secure_Data_Transmission_Platform/tree/main/Preparation 编译protobuf类文件 VS2022 protobuf3.17 Message.proto protoc Message.proto --cpp_out./...

【23种设计模式】里氏替换原则
个人主页:金鳞踏雨 个人简介:大家好,我是金鳞,一个初出茅庐的Java小白 目前状况:22届普通本科毕业生,几经波折了,现在任职于一家国内大型知名日化公司,从事Java开发工作 我的博客&am…...

嵌入式系统设计师考试笔记之操作系统基础复习笔记一
目录 1、嵌入式软件基础 (1)嵌入式软件的特点: (2)嵌入式软件分类: (3)无操作系统的嵌入式软件的两种实现方式: (4)有操作系统的三大优点&am…...
Unity开发之观察者模式(事件中心)
观察者模式是一种对象行为模式。它定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。在观察者模式中,主体是通知的发布者,它发出通知时并不需要知道谁是它的观察者&#…...
16、window11+visual studio 2022+cuda+ffmpeg进行拉流和解码(RTX3050)
基本思想:需要一个window11 下的gpu的编码和解码代码,逐开发使用,先上个图 几乎0延迟的,使用笔记本的显卡 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.0\extras\demo_suite>deviceQuery.exe deviceQuery.exe Starting...CUDA Device Query (Runtime API…...

ChatGPT资源宝库:从提示工程到项目实践的完整指南
1. 项目概述:一份关于ChatGPT的“Awesome”清单意味着什么?如果你最近在GitHub上搜索过任何与ChatGPT、AI或提示工程相关的内容,那么你大概率见过一个以“awesome-”开头的仓库。而sindresorhus/awesome-chatgpt无疑是这个领域里最知名、最常…...

AI应用开发利器:ai-devkit工具包核心功能与工程实践指南
1. 项目概述与核心价值最近在折腾AI应用开发,发现一个挺有意思的项目,叫codeaholicguy/ai-devkit。乍一看名字,你可能会觉得这又是一个“AI开发工具包”,市面上类似的工具已经多如牛毛了。但深入用下来,我发现它不太一…...

为开源项目OpenClaw配置Taotoken作为后端模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源项目OpenClaw配置Taotoken作为后端模型供应商 OpenClaw是一个功能强大的开源智能体(Agent)框架&…...

开源技能图谱工具SkillPort:Go语言构建的知识管理利器
1. 项目概述:一个技能图谱与知识管理的开源利器 最近在整理个人技术栈和团队知识库时,我一直在寻找一个能直观展示技能关联、又能深度管理学习路径的工具。市面上的笔记软件要么太“平”,只能线性记录;要么太“重”,像…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...

基于Nginx-Lua镜像构建高性能可编程网关的实践指南
1. 项目概述:一个为现代Web架构而生的Nginx镜像如果你和我一样,长期在容器化环境中部署和管理Web服务,那么你一定对Nginx的灵活性和Lua脚本的强大能力印象深刻。但将这两者结合,并打包成一个稳定、安全、功能齐全的Docker镜像&…...

MQ-3与MiCS-5524气体传感器对比:从原理到实战的选型指南
1. 项目概述与核心价值在嵌入式开发、环境监测乃至一些创意DIY项目中,气体检测是一个常见且关键的需求。无论是为了安全预警(如天然气泄漏),还是进行环境质量评估(如VOC监测),选择一款合适的传感…...

DeepMind Lab:强化学习研究的3D视觉仿真平台搭建与实战指南
1. 项目概述:一个被低估的强化学习研究“健身房”如果你在深度强化学习(Deep Reinforcement Learning, DRL)这个圈子里待过一段时间,或者正试图入门,那么你大概率听说过OpenAI的Gym、Unity的ML-Agents,甚至…...

桌面自动化技能库:基于PyAutoGUI与Selenium的工程化实践
1. 项目概述:一个桌面操作员的技能库最近在GitHub上看到一个挺有意思的项目,叫Marways7/cua_desktop_operator_skill。光看这个名字,可能有点摸不着头脑,但作为一个在自动化运维和桌面支持领域摸爬滚打多年的老手,我立…...

RTX 5090功耗600W:高功耗显卡的系统级挑战与实战装机指南
1. 项目概述:从一则功耗新闻到显卡生态的深度解构最近,一则关于英伟达下一代旗舰显卡RTX 5090功耗可能高达600W的消息,在硬件圈和AI计算领域激起了不小的波澜。对于普通玩家而言,这或许只是一个“电老虎”又升级了的谈资ÿ…...