【MySQL索引与优化篇】索引的数据结构
文章目录
- 1. 概述
- 2. 常见索引结构
- 2.1 聚簇索引
- 2.2 二级索引(辅助索引、非聚簇索引)
- 2.3 联合索引
- 3. InnoDB的B+树索引的注意事项
- 3.1 根页面位置万年不动
- 3.2 内节点中目录项记录的唯一性
- 4. MyISAM中的索引方案
- 5. InnoDB和MyISAM对比
- 6. 小结
- 7. 补充:MySQL数据结构的合理性
- 7.1 全表遍历
- 7.2 Hash结构
- 7.3 二叉搜索树
- 7.4 AVL树
- 7.5 B-Tree
- 7.6 B+Tree
- 7.7 R树
- 8. 思考题
- 8.1 思考B+树的存储能力如何?为何说一般查找记录,最多只需1~3次磁盘IO?
- 8.2 为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
- 9. 小结
1. 概述
索引是帮助MySQL高效获取数据的数据结构,相当于书籍的目录。如果表很大有上千万条数据,就意味着要做 很多次磁盘I/O才能找到需要的数据。建立索引后若根据索引(innodb存储引擎使用的是B+树结构)查询,相比按顺序查找,将极大 减少磁盘I/0的次数,加快查找速度;降低 数据库的IO成本,这也是创建索引最主要的原因
索引是在存储引擎中实现的,因此每种存储引擎的索引不一定完全相同,并且每种存储引擎不一定支持所有索引类型。同时,存储引擎可以定义每个表的 最大索引数和 最大索引长度。所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节。
缺点:
- 创建索引和维护索引要
耗费时间,并且随着数据量的增加,所耗费的时间也会增加 - 索引需要占
磁盘空间 - 索引会
降低更新表的速度。当对表中的数据进行增删改操作的时候,索引也要动态地维护,这降低了数据的维护速度
因此,选择使用索引时,需要综合考虑索引的优点和缺点。
索引可以提高查询的速度,但是会影响插入记录的速度。面临频繁增删改情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后再创建索引。
2. 常见索引结构
首先需要知道,MySQL数据库从磁盘取数据到内存中是以最小单位数据页来取的,在前面章节架构篇的缓冲池中有提到(默认数据页大小是16KB)。
2.1 聚簇索引

特点:
-
使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义
页内的记录是按照主键的大小顺序排成一个单向链表- 各个存放
用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表 - 存放
目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表
-
B+树的
叶子节点存储的是完整的用户记录所谓完整的用户记录,就是指这个记录中存储了所有列的值 (包括隐藏列)。
我们把具有这两种特性的B+树称为 聚簇索引,所有完整的用户记录都存放在这个 聚簇索引 的叶子节点处。这种聚簇索引并不需要我们在MySQL语句中显式的使用INDEX 语句去创建,InnoDB 存储引擎会 自动 的为我们创建聚族索引(索引即数据)。
缺点:
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,一般会定义一个自增的ID列为主键
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于innoDB表,我们一般定义主键为不可更新
- 二级索引访问需要两次索引查找 ,第一次找到主键值,第二次根据主键值找到行数据
限制:
- MySQL数据库目前只有InnoDB数据引擎支持聚簇索引,而MylSAM并不支持聚簇索引
- 由于数据物理存储排序方式只能有一种,所以每个MySQL的
表只能有一个聚簇索引。一般情况下就是该表的主键 - 如果没有定义主键,lnnodb会选择
非空的唯一索引代替。如果没有这样的索引,lnnodb会隐式的定义一个主键来作为聚簇索引 - 为了充分利用聚簇索引的聚簇的特性,所以innodb表的主键列尽量 选用有序的顺序id,而不建议用无序的id比如UUID、MD5、HASH、字符串列作为主键无法保证数据的顺序增长
2.2 二级索引(辅助索引、非聚簇索引)
上边介绍的 聚簇索引 只能在搜索条件是 主键值 时才能发挥作用,因为B+树中的数据都是按照主键进行排序的。那如果我们想以别的列作为搜索条件该怎么办呢?肯定不能是从头到尾沿着链表依次遍历记录一遍。
答案:我们可以 多建几棵B+树,不同的B+树中的数据采用不同的排序规则。比方说我们用 c2 列的大小作为数据页、页中记录的排序规则,再建一棵B+树,效果如下图所示:

这个B+树与上面聚簇索引有一个主要的不同点:
- B+树的叶子节点存储的并不是完整的用户记录,而是
c2列+主键这两个列的值
二级索引查找流程:
当根据二级索引查找时,先根据二级索引找到主键值,再用主键值去聚簇索引中通过主键值查找数据(这个过程便是回表);如果索引中便包含了所要查找的数据列,如c2,则不需要进行回表,可直接取出数据,此时便称该索引为覆盖索引
c2值相同时还会有别的处理,具体可等后面看3.2。
2.3 联合索引
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让B+树按照 c2和c3列 的大小进行排序,这个包含两层含义:
- 先把各个记录和页按照c2列进行排序
- 在记录的c2列相同的情况下,采用c3列进行排序
为c2和c3列建立的索引的示意图如下:

如图所示,我们需要注意以下几点:
- 每条 目录项记录 都由 c2、c3、页号 这三个部分组成,各条记录先按照c2列的值进行排序,如果记录的c2列相同,则按照c3列的值进行排序
- B+树
叶子节点处的用户记录由 c2、c3和主键c1列 组成
以c2和c3列的大小为排序规则建立的B+树称为 联合索引,本质上也是一个二级索引。
3. InnoDB的B+树索引的注意事项
3.1 根页面位置万年不动
B+树的形成过程:
- 每当为某个表创建一个B+树索引(聚族索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个
根节点页面。最开始表中没有数据的时候,每个B+树索引对应的根节点中既没有用户记录,也没有目录项记录 - 随后向表中插入用户记录时,先把用户记录存储到这个
根节点中 - 当根节点中的可用
空间用完时继续插入记录,此时会将根节点中的所有记录复制到一个新分配的页,比如页a中,然后对这个新页进行页分裂的操作,得到另一个新页,比如页b。这时新插入的记录根据键值(也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到页a或者页b中,而根节点便升级为存储目录项记录的页
这个过程特别注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动。这样只要我们对某个表建立一个索引,那么它的根节点的页号便会被记录到某个地方,然后凡是 InnoDB 存储引擎需要用到这个索引的时候,都会从那个固定的地方取出根节点的页号,从而来访问这个索引
3.2 内节点中目录项记录的唯一性
在上述二级索引中,如果第二层目录项存在相同值,此时需要再插入一个相同值时,将无法得知将要插入的值应该插入到哪个叶子节点页面中去,故实际上二级索引为保持内节点的唯一性,还会再目录项中也加上主键值,这样就可以在目录项c2相同的情况下,再比较主键值即可得到叶子节点应该插入到哪了,如下图所示:

这种情况下,我们需要插入(9, 1, ‘x’)时就知道,我们需要插入到页5中。
4. MyISAM中的索引方案
| 索引/存储引擎 | MyISAM | InnoDB | Memory |
|---|---|---|---|
| B+树索引 | 支持 | 支持 | 支持 |
即使多个存储引擎支持同一种类型的索引,但是他们的实现原理也是不同的。Innodb和MyISAM默认的索引是B+树索引;而Memory默认的索引是Hash索引。
MyISAM引擎使用 B+Tree 作为索引结构,叶子节点的data域存放的是 数据记录的地址。
MyISAM 的索引方案虽然也使用树形结构,但是却 将索引和数据分开存储:
- 将表中的记录
按照记录的插入顺序单独存储在一个文件中,称之为数据文件。这个文件并不划分为若干个数据页,有多少记录就往这个文件中塞多少记录就成了。由于在插入数据的时候并没有刻意按照主键大小排序,所以我们并不能在这些数据上使用二分法进行查找 - 使用MyISAM存储引擎的表会把索引信息另外存储到一个称为
索引文件的另一个文件中。MyISAM 会单独为表的主键创建一个索引,只不过在索引的叶子节点中存储的不是完整的用户记录,而是主键值 + 数据记录地址的组合

这里设表一共有三列,假设我们以Col1为主键,上图是一个MyISAM表的主索引 (Primary key) 示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主键索引和二级索引(Secondary key) 在结构上没有任何区别,只是主键索引要求key是唯一的,而非主键索引的key可以重复,故MyISAM的主键及非主键索引均为二级索引。
因此,MylSAM中索引检索的算法为: 首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
5. InnoDB和MyISAM对比
MyISAM的索引方式都是“非聚簇”的,与InnoDB包含1个聚簇索引是不同的,两种引擎中索引的区别:
- 在InnoDB存储引擎中,我们只需要根据主键值对
聚簇索引进行一次查找就能找到对应的记录,而在 MyISAM 中却需要进行一次回表操作,意味着MyISAM中建立的索引相当于全部都是二级索引 - lnnoDB的数据文件本身就是索引文件,而MyISAM索引文件和数据文件是
分离的,索引文件仅保存数据记录的地址 - lnnoDB的非聚簇索引data域存储相应记录
主键的值,而MylSAM索引记录的是地址。换句话说,InnoDB的所有非聚簇索引都引用主键作为data域 - MyISAM的回表操作是十分
快速的,因为是拿着地址偏移量直接到文件中取数据的,反观InnoDB是通过获取主键之后再去聚簇索引里找记录,虽然说也不慢,但还是比不上直接用地址去访问 - lnnoDB要求表
必须有主键( MyISAM可以没有)。如果没有显式指定,则MySQL系统会自动选择一个可以非空且唯一标识数据记录的列作为主键。如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型
6. 小结
- 不建议使用过长的字段作为主键,因为所有二级索引都引用主键索引,过长的主键索引会令二级索引变得过大
- 用非单调的字段作为主键在innoDB中不是个好主意,因为InnoDB数据文件本身是一棵B+Tree,非单调的主键会造成在插入新记录时,数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用
自增字段作为主键则是一个很好的选择(分布式系统要考虑主键唯一性,有雪花算法等解决方案后续研究) - 联合索引应将数据重复少的放前面,使得通过索引能按索引左侧字段尽快找到对应数据
- 联合索引遵守最左匹配原则,即查找逻辑为先查找索引最左侧字段,并逐个比对,而无法从索引右边字段开始
7. 补充:MySQL数据结构的合理性
从MySQL的角度讲,不得不考虑一个现实问题就是磁盘IO。如果我们能让索引的数据结构尽量减少硬盘的 I/0 操作,所消耗的时间也就越小。可以说,磁盘的 I/0 操作次数 对索引的使用效率至关重要
查找都是索引操作,一般来说索引非常大,尤其是关系型数据库,当数据量比较大的时候,索引的大小有可能几个G甚至更多,为了减少索引在内存的占用,数据库索引是存储在外部磁盘上的。当我们利用索引查询的时候不可能把整个索引全部加载到内存,只能 逐一加载,那么MySQL衡量查询效率的标准就是磁盘IO次数
7.1 全表遍历
需逐个加载数据页,如果在最后一页,需遍历全表,将数据页都加载进内存,要进行大量I/O操作。
7.2 Hash结构
哈希的查询/插入/修改/删除的平均时间复杂度都是O(1),但索引结构还是采取了树型,具体原因有:
- Hash 索引仅能满足(=) (<>)和 IN 查询。如果进行
范围查询,哈希型的索引,时间复杂度会退化为O(n);而树型的“有序”特性,依然能够保持O(log2N)的高效率 - Hash 索引还有一个缺陷,数据的存储是
没有顺序的,在ORDER BY的情况下,使用 Hash 索引还需要对数据重新排序。 - 对于联合索引的情况,Hash 值是将联合索引键合并后一起来计算的,无法对单独的一个键或者几个索引键进行查询
- 对于等值查询来说,通常 Hash 索引的效率更高,不过也存在一种情况,就是
索引列的重复值如果很多,效率就会降低。这是因为遇到 Hash 冲突时,需要遍历桶中的行指针来进行比较,找到查询的关键字,非常耗时。所以,Hash 索引通常不会用到重复值多的列上,比如列为性别、年龄的情况等
另外,InnoDB 本身不支持 Hash 索引,但是提供 自适应 Hash 索引 (Adaptive Hash index) 。什么情况下才会使用自适应 Hash 索引呢?如果某个数据经常被访问,当满足一定条件的时候,就会将这个数据页的地址存放到Hash 表中。这样下次查询的时候,就可以直接找到这个页面的所在位置。这样让 B+ 树也具备了 Hash 索引的优点。

自适应 Hash索引变量默认是开启的:
show variables like '%adaptive_hash_index';
7.3 二叉搜索树
如果利用树形结构作为索引结构,那么磁盘的0次数和索引树的高度是相关的。如果插入数据一直是逐渐变大,二叉搜索树就会形成一根链条,查找数据的时间复杂度会退化为O(n),为了提高查询效率就需要尽量降低树的高度,需要把原来“瘦高”的树结构变的矮胖,树的每层的分叉越多越好
7.4 AVL树
为解决二叉树退化为链表的问题,人们提出了平衡二叉搜索树(Balanced Binary Tree),又称AVL树(有别于AVL算法)。这样搜索的时间复杂度就能稳定在Log2N,但是当数据量大时,树的深度一样会很高,而每访问一次节点就许可进行一次磁盘I/O操作,需要消耗的时间一样很多。
7.5 B-Tree
针对以上问题,如果把二叉树改为M叉树(M>2),M叉平衡树的高度会远小于二叉树的高度,所以可以让树更加“矮胖”。B树的英文是Balance Tree,也就是多路平衡树。简写为B-Tree(-表示两个单词相连,念横杠而非B减树),与B+树典型区别是非叶子节点也会存储数据。对于大量的索引数据来说,采用B树的结构是非常合适的,因为树的高度要远小于二叉树的高度。

7.6 B+Tree
B+树也是一种多路搜索树,基于 B 树做出了改进,主流的 DBMS 都支持 B+ 树的索引方式,比如 MySQL。相比于B-Tree,B+Tree适合文件索引系统。

B+Tree和B-Tree的根本差异就是B+树的中间节点并不直接存储数据,这样的好处是?
- B+树的查询效率更稳定,因为中间节点无需存储数据,要查到数据必须查到数据的叶子节点
- B+树的查询效率更高,因为中间节点无需存储数据,B+树通常比B树
更矮胖,查询锁需要的磁盘I/O也会更少,同样的磁盘页,B+树可存储更多的节点关键字 - B+树查询范围的效率更高,B+树叶子节点间有指针,数据又是递增,范围查找可通过指针连接查找,而B树中要通过中序遍历,效率要低很多
B树和B+树都可以作为索引的数据结构,在MySQL中采用的是B+树,但B树和B+树各有自己的应用场景,不能完全说B+树比B树好
注意:索引树不会一次性加载(数据量大必然导致索引增大),而是逐一加载每一个磁盘页,因为磁盘页对应着索引树的节点
7.7 R树
R-Tree在MySQL很少使用,仅支持 geometry数据类型,支持该类型的存储引擎只有myisam、bdb、innodb、ndb、archive几种。举个R树在现实领域中能够解决的例子: 查找20英里以内所有的餐厅。如果没有R树你会怎么解决?一般情况下我们会把餐厅的坐标(x,y)分为两个字段存放在数据库中,一个字段记录经度,另一个字段记录纬度。这样的话我们就需要遍历所有的餐厅获取其位置信息,然后计算是否满足要求。如果一个地区有100家餐厅的话,我们就要进行100次位置计算操作了,如果应用到谷歌、百度地图这种超大数据库中,这种方法便必定不可行了。R树就很好的 解决了这种高维空间搜索问题。它把B树的思想很好的扩展到了多维空间,采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解结点的方法,保证树的平衡性。因此,R树就是一棵用来存储高维数据的平衡树。相对于B-Tree,R-Tree的优势在于范围查找
8. 思考题
8.1 思考B+树的存储能力如何?为何说一般查找记录,最多只需1~3次磁盘IO?
InnoDB 存储引擎中页的大小为 16KB,一般表的主键类型为INT(占用4个字节或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree 中的一个节点)中大概存储16KB/(8B+8B)=1K个键值 (因为是估值,为方便计算,这里的K 取值为10^3。也就是说一个深度为3的B+Tree 索引可以维护10^3 * 10^ 3 * 10^3 = 10 亿条记录。(这里假定一个数据页也存储10^3条行记录数据了)
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree 的高度一般都在 2~4 层。MySQL的InnoDB 存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要 1~3次磁盘I/0 操作。
8.2 为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
- B+树的磁盘读写代价更低,B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了
- B+树的查询效率更加稳定
9. 小结
使用索引可以帮助我们从海量的数据中快速定位想要查找的数据,不过索引也存在一些不足,比如占用存储空间、降低数据库写操作的性能等,如果有多个索引还会增加索引选择的时间。当我们使用索引时,需要平衡索引的利(提升查询效率)和弊(维护索引所需的代价)。
在实际工作中,我们还需要基于需求和数据本身的分布情况来确定是否使用索引,尽管 索引不是万能的,但 数据量大的时候不使用索引是不可想象的 ,毕竟索引的本质,是帮助我们提升数据检索的效率
相关文章:
【MySQL索引与优化篇】索引的数据结构
文章目录 1. 概述2. 常见索引结构2.1 聚簇索引2.2 二级索引(辅助索引、非聚簇索引)2.3 联合索引 3. InnoDB的B树索引的注意事项3.1 根页面位置万年不动3.2 内节点中目录项记录的唯一性 4. MyISAM中的索引方案5. InnoDB和MyISAM对比6. 小结7. 补充:MySQL数据结构的合…...

Qt Widget 删除之后还会显示 问题
目录 问题描述:Qt QWidget 删除之后还会显示 解决方案: Part1: 使用 deleteLater Part2: 使用 setParent(nullptr) 父控件为空 还有一种不常用的方法 隐藏: 问题描述:Qt QWidget 删除之后还会显示 Qt 无论使用 while (Layo…...

关系型数据库的问题和NoSQL数据库的应用
1.关系型数据库的问题 系统使用通用的商用关系型数据库,系统内部数据采用中央集中方式存储。系统投入使用后,初期用户数量少,系统运行平稳。一段时间后,用户数出现了爆炸式增长,系统暴露出诸多问题,集中表…...
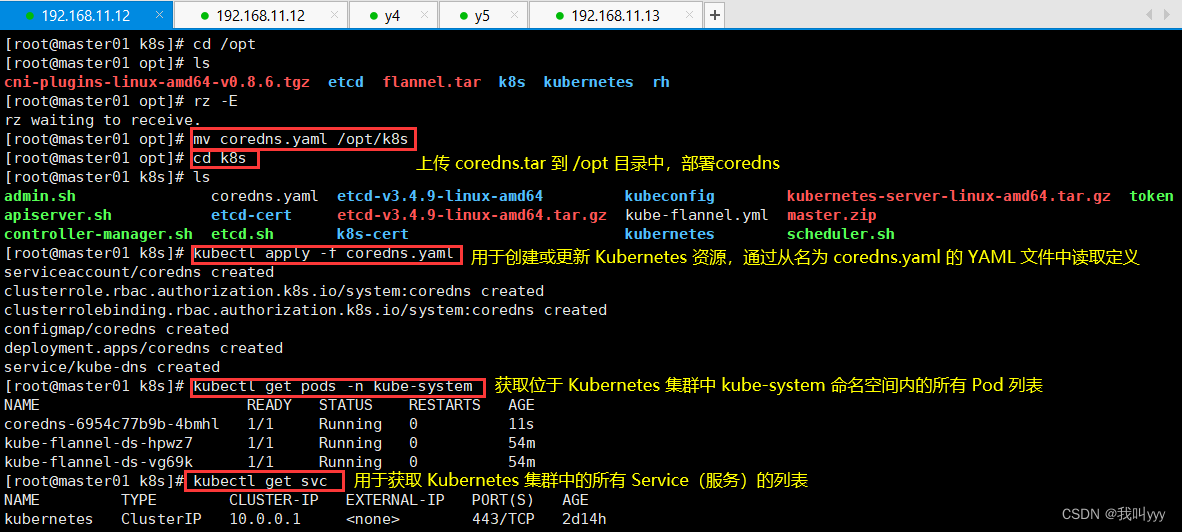
二进制安装k8s
192.168.11.12 master01 192.168.11.12 y4 node01 192.168.11.14 y5 node02 192.168.11.15 对环境进行初始化,主机192.168.11.12、主机y4、主机y5,三台主机都要做以下操作,唯一不同的就是修改主…...
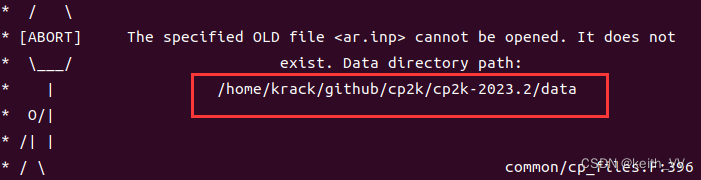
超简洁ubuntu linux 安装 cp2k
文章目录 打开下载网址解压接下来的步骤讲解 将解压的包移到对应路径下最后运行 打开下载网址 需要从github下载:下载网址 两个都可以从windows下先下载,再复制到linux中, 如果不能复制,右键这两个,复制链接…...

判断日期区间或季节等
使用JavaScript的Date对象来获取当前日期,并通过比较判断是否在指定的日期范围内(如3月16日-9月15日)。以下是一个示例代码: var currentDate new Date(); // 获取当前日期 var startRange new Date(currentDate.getFullYear()…...
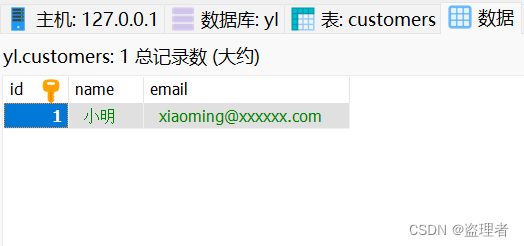
入门人工智能 —— 学习数据持久化、使用 Python 将数据保存到mysql(7)
入门人工智能 —— 学习数据持久化、使用 Python 将数据保存到mysql 什么是数据持久化?使用 Python 进行数据持久化步骤 1: 安装 MySQL步骤 2: 安装必要的 Python 库步骤 3: 连接到 MySQL 数据库步骤 4: 创建数据表步骤 5: 插入数据步骤 6: 查询数据步骤 7: 关闭连接…...
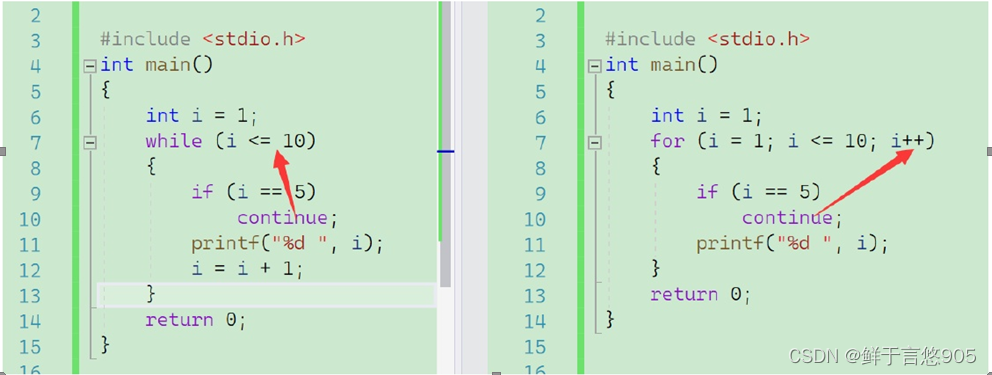
c语言从入门到实战——分支和循环
分支和循环 前言1. if语句1.1 if1.2 else1.3 分支中包含多条语句1.4 嵌套if1.5 悬空else问题 2. 关系操作符3. 条件操作符4. 逻辑操作符:&& , || , !4.1 逻辑取反运算符4.2 与运算符4.3 或运算符4.4 练习:闰年的判断4.5 短路 5. swit…...
rust解法)
交易所(Exchange, ACM/ICPC NEERC 2006, UVa1598)rust解法
你的任务是为交易所设计一个订单处理系统。要求支持以下3种指令。 BUY p q:有人想买,数量为p,价格为q。 SELL p q:有人想卖,数量为p,价格为q。 CANCEL i:取消第i条指令对应的订单(输…...

shell_51.Linux获取用户输入_无显示读取,从文件中读取
无显示读取 有时你需要从脚本用户处得到输入,但又不想在屏幕上显示输入信息。典型的例子就是输入密码,但除此之外还有很多种需要隐藏的数据。 -s 选项可以避免在 read 命令中输入的数据出现在屏幕上(其实数据还是会被显示,只不过 …...

NOIP2023模拟2联测23 集训
题目大意 给定 n n n个数 a 1 , a 2 , ⋯ , a n a_1,a_2,\cdots,a_n a1,a2,⋯,an,你需要找到一个集合 S S S,使得 S S S中严格大于 S S S的平均数的数字个数尽量多,输出最多的个数。 注意:这里的集合是可重集,…...
【设计模式】第3节:设计模式概论
设计模式不是代码,而是某类问题的通用方案。设计模式的本质是提高软件的维护性、通用性和扩展性,并降低软件的复杂度。一共有24种设计模式,可以分为创建型模式、结构型模式和行为型模式三大类。设计模式中比较重要的有:单例模式、…...
风力发电功率预测(CEEMDAN-LSTM-CNN-CBAM模型,Python代码)
1.前言 1.1.运行效果:风力发电功率预测(CEEMDAN-LSTM-CNN-CBAM模型,Python代码)_哔哩哔哩_bilibili 1.2.环境库: 如果库版本不一样, 一般也可以运行,这里展示我运行时候的库版本,是…...

精通代码复用:设计原则与最佳实践
精通代码复用:设计原则与最佳实践 在你开始设计的所有层次上,从单一函数、类,到整个库和框架,都需要从一开始就考虑到代码复用。在接下来的文本中,所有这些不同的层次都被称为组件。以下策略将帮助你合理地组织你的代…...
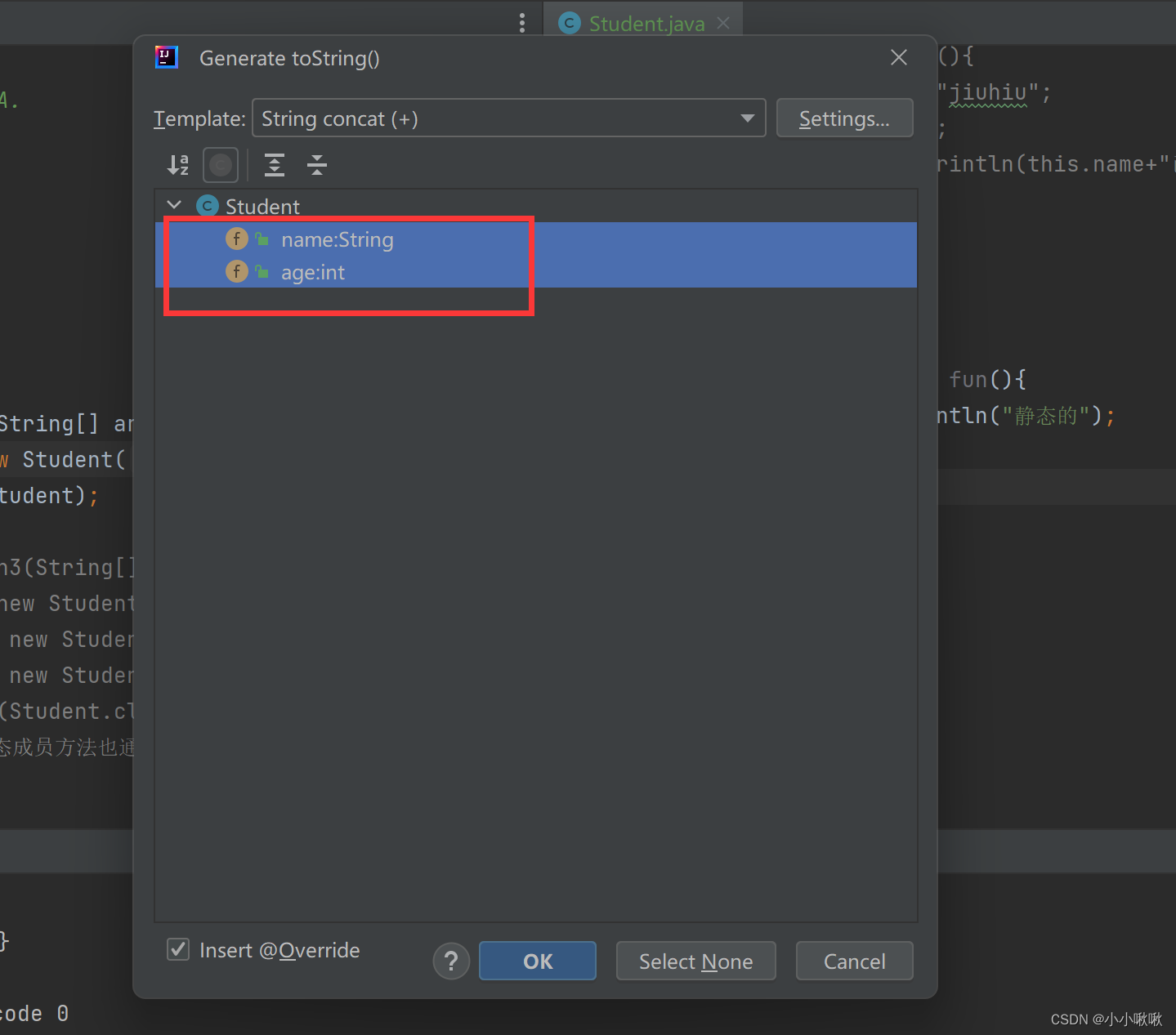
【static + 代码块+toString打印对象】
文章目录 static成员static修饰成员变量static成员变量初始化代码块 对象的打印写show方法打印对象调用toString打印对象 总结 static成员 举例:一个班的学生,在实例化每个人的名字,年龄,学号等学员信息时都不一样,但…...

【vue3 】 创建项目vscode 提示无法找到模块
使用命令创建 vue3 创建新应用 npm create vuelatest会看到一些可选功能的询问? √ 请输入项目名称: … vue-project √ 是否使用 TypeScript 语法? … 否 / 是 √ 是否启用 JSX 支持? … 否 / 是 √ 是否引入 Vue Router 进行单…...
盘点算法比赛中常见的AutoEDA工具库
在完成竞赛和数据挖掘的过程中,数据分析一直是非常耗时的一个环节,但也是必要的一个环节。 能否使用一个工具代替人来完成数据分析的过程呢,现有的AutoEDA工具可以一定程度上完成上述过程。本文将盘点常见的AutoEDA工具,欢迎收藏转…...
ICLR 2023丨3DSQA:3D 场景中的情景问答
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/pdf/2210.07474.pdf 主页链接:http://sqa3d.github.io 图 1:3D 场景中情景问答 (SQA3D) 的任务图示。给定场景上下文 S(例如&#…...

ChatGPT的前世今生:从概念到现实的AI之旅
ChatGPT的前世今生:从概念到现实的AI之旅 随着技术的飞速发展,人工智能已经从科幻小说中的概念转变为我们日常生活中不可或缺的一部分。其中,ChatGPT无疑是这个领域的佼佼者。那么,让我们一起探索ChatGPT的发展历程,从…...

MINA架构DEMO
参考:Java中的MINA框架_java mina_小陈拾光的博客-CSDN博客 MINA:一个简洁易用的基于TCP/IP通信的JAVA框架。 <dependency><groupId>org.apache.mina</groupId><artifactId>mina-core</artifactId><version>2.1.5&…...

CGAL::Point_set_3 成员函数自查表
参考来源: CGAL 6.1.1 - 3D Point Set: CGAL::Point_set_3< Point, Vector > Class Template Reference 一、基础构造 / 容量 返回值函数名作用小 demoPoint_set_3()构造空点集Point_set ps;size_tnumber_of_points()获取点数auto n ps.number_of_points(…...
和描述文件生成避坑指南:从App ID创建到真机测试UDID添加)
iOS证书(.p12)和描述文件生成避坑指南:从App ID创建到真机测试UDID添加
iOS证书与描述文件生成全流程解析:从核心概念到实战避坑 第一次接触iOS应用打包的开发者,往往会在证书和描述文件这一关卡住。明明按照教程一步步操作,却总是遇到各种报错——"证书无效"、"描述文件不匹配"、"设备未…...

大麦抢票自动化工具:3分钟提升10倍成功率的技术秘籍
大麦抢票自动化工具:3分钟提升10倍成功率的技术秘籍 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 你是否经历过这样的场景?…...
)
UniApp地图组件实战:5分钟搞定腾讯位置服务+自定义气泡弹窗(附避坑指南)
UniApp腾讯地图组件深度实战:从Key申请到自定义弹窗全流程解析 1. 腾讯位置服务Key申请与配置 在manifest.json中配置腾讯地图Key是第一步,但90%的开发者会忽略安全配置细节。正确的申请流程应该是: 访问腾讯位置服务官网,进入控制…...

如何通过Bilibili-Evolved打造个性化B站体验?解锁高效视频浏览新方式
如何通过Bilibili-Evolved打造个性化B站体验?解锁高效视频浏览新方式 【免费下载链接】Bilibili-Evolved 强大的哔哩哔哩增强脚本 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Evolved 你是否曾经在B站浏览时遇到这样的困扰:界面广告太…...

三极管倍频 vs 锁相环倍频:短波通信场景下的5个关键性能对比实验
三极管倍频与锁相环倍频在短波通信中的5组实测性能对决 短波通信系统的核心挑战之一在于如何生成高稳定度的射频信号。当工程师需要在有限频谱资源中实现高效传输时,频率合成技术的选择往往决定了系统整体性能。本文将基于实际测试平台,对比分析三极管倍…...

从Markdown到清晰语音:我是如何用ttsfrd + CosyVoice模型搞定技术文档朗读的
从Markdown到清晰语音:技术文档朗读的工程化实践 每天早上七点,我都要挤进这座城市最拥挤的地铁线。作为开发者,通勤时间曾是知识更新的黑洞——直到我发现将技术文档转为语音的解决方案。这不仅改变了我的学习方式,更为视障程序员…...

TinySAM完整指南:如何在5分钟内实现高效图像分割
TinySAM完整指南:如何在5分钟内实现高效图像分割 【免费下载链接】TinySAM 项目地址: https://gitcode.com/gh_mirrors/ti/TinySAM TinySAM是一款革命性的轻量化"分割任何物体"模型,它通过知识蒸馏和量化技术,在保持强大零…...

Verilog条件语句实战:如何避免if-else嵌套中的常见陷阱?
Verilog条件语句实战:如何避免if-else嵌套中的常见陷阱? 在数字电路设计中,条件语句的正确使用直接关系到电路的功能实现和性能表现。Verilog作为硬件描述语言,其if-else和case语句的灵活运用是每位工程师必须掌握的技能。但看似简…...

别再手动测PLC了!用C# + Modbus Poll/Slave + VSPD三件套,5分钟搞定ModbusRTU通信仿真
工业自动化开发者的效率革命:C#与Modbus仿真工具链实战指南 在工业自动化领域,时间就是金钱。传统PLC调试过程中,工程师常常需要反复连接真实硬件设备,忍受着物理线路故障、设备资源占用和不可复现的测试环境等问题。这种低效的工…...