sqoop和flume简单安装配置使用
1. Sqoop
1.1 Sqoop介绍
-
Sqoop 是一个在结构化数据和 Hadoop 之间进行批量数据迁移的工具
-
结构化数据可以是MySQL、Oracle等关系型数据库
-
把关系型数据库的数据导入到 Hadoop 与其相关的系统
-
把数据从 Hadoop 系统里抽取并导出到关系型数据库里
-
-
底层用 MapReduce 实现数据
- 命令执行过程中,map 0% ,Reduce0%----》map 100% ,Reduce 100%

-
| id | name | age |
|---|---|---|
| 1 | zhangsan | 18 |

1.2 Sqoop安装
-
下载、上传、解压、重命名和授权
- https://mirrors.tuna.tsinghua.edu.cn/apache/sqoop/1.3.7/sqoop-1.3.7.bin__hadoop-2.6.0.tar.gz
-
上传到 /home/hadoop 目录,直接在xshell拖拽进入家目录即可
-
#Sqoop的安装 sudo tar -xvf sqoop-1.3.7.bin__hadoop-2.6.0.tar.gz -C /usr/local #改名 sudo mv /usr/local/sqoop-1.3.7.bin__hadoop-2.6.0/ /usr/local/sqoop #授权 sudo chown -R hadoop /usr/local/sqoop
1.3 Sqoop配置和验证
1.3.1 sqoop配置
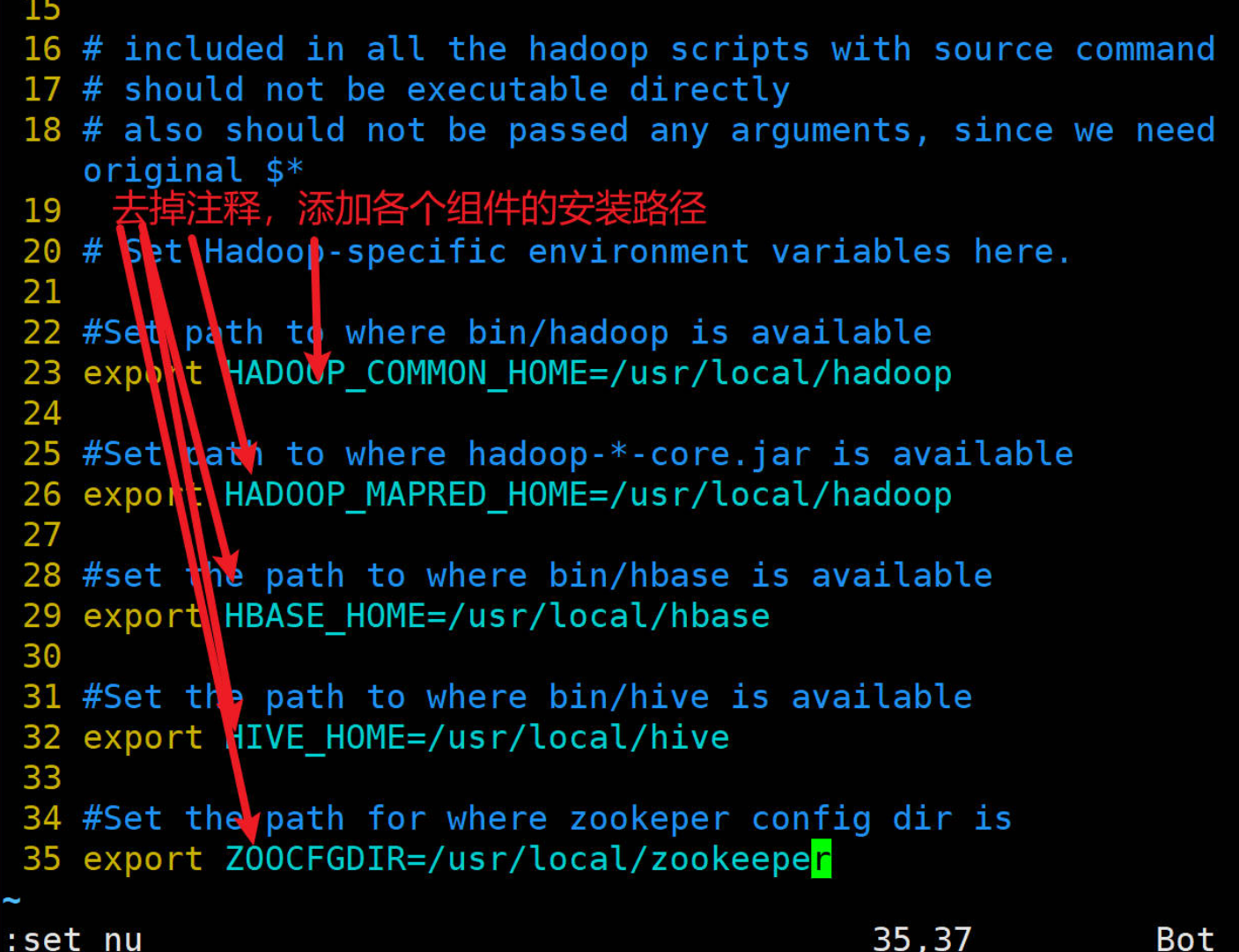
#1、修改配置文件
mv /usr/local/sqoop/conf/sqoop-env-template.sh /usr/local/sqoop/conf/sqoop-env.sh# 进入配置目录,把各个组件的路径写入
cd /usr/local/sqoop/conf/
sudo vim sqoop-env.sh
#2、上传 jar 文件
cd /usr/local/sqoop/lib/
#2.1 上传 MySQL 的驱动文件,拖拽上传进xshell#2.2拷贝 hive 的驱动文件
cp /usr/local/hive/lib/hive-common-2.3.7.jar /usr/local/sqoop/lib/#3、配置环境变量
#编辑环境变量
vim /home/hadoop/.bashrc#在环境变量最后添加以下内容
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SQOOP_HOME/bin#刷新环境变量
source /home/hadoop/.bashrc#验证是否安装成功
sqoop version
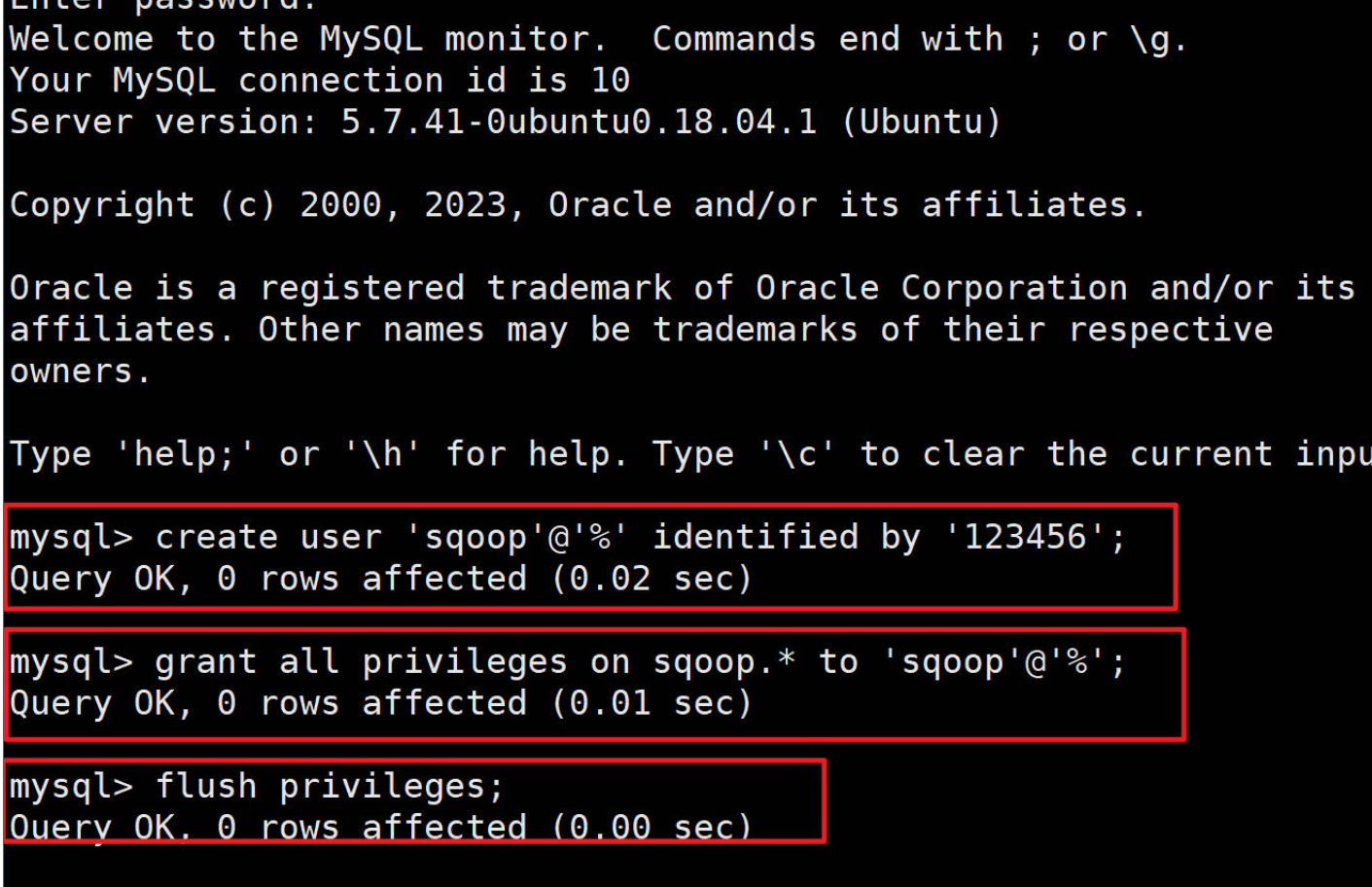
1.3.2 在MySQL中创建sqoop用户
#查看管理员账户和密码
sudo cat /etc/mysql/debian.cnf #用查看的账户和密码登录
mysql -u debian-sys-maint -p#登录成功再执行下面命令,可参考下图
#创建sqoop用户,
create user 'sqoop'@'%' identified by '123456';
#并对用户授权
grant all privileges on sqoop.* to 'sqoop'@'%';
#刷新使授权生效
flush privileges;#退出
exit;
执行MySQL示例:
1.3.3 验证sqoop是否成功运行及常见错误:
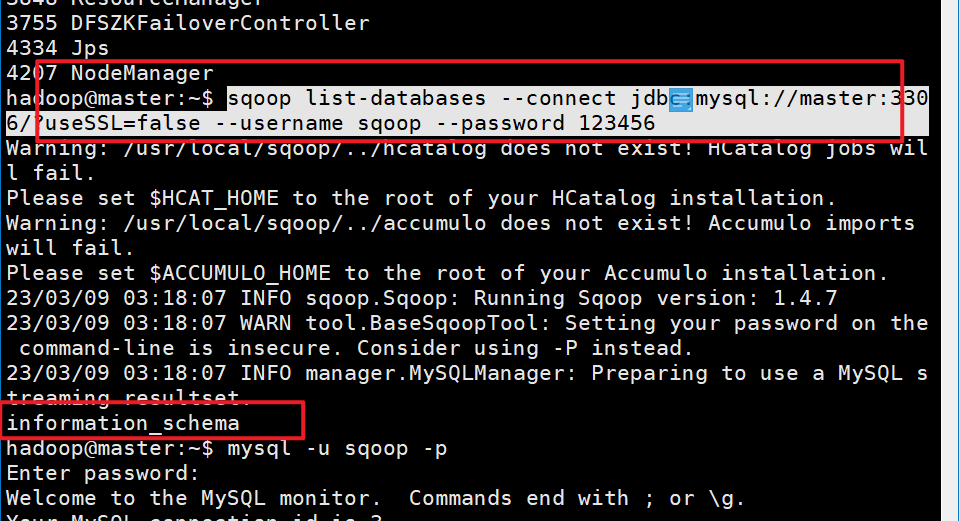
- #测试能否成功连接数据库
#测试能否成功连接数据库
sqoop list-databases --connect jdbc:mysql://master:3306/?useSSL=false --username sqoop --password 123456
使用命令报错时:
#测试能否成功连接数据库 sqoop list-databases --connect jdbc:mysql://master:3306/?useSSL=false --username sqoop --password 123456**报错信息如下:**ERROR manager.CatalogQueryManager: Failed to list databases
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
完整信息在下面:
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. 。。。at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)at org.apache.sqoop.Sqoop.main(Sqoop.java:252) Caused by: java.net.ConnectException: Connection refused (Connection refused)at java.net.PlainSocketImpl.socketConnect(Native Method)at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)at java.net.Socket.connect(Socket.java:589)at com.mysql.jdbc.StandardSocketFactory.connect(StandardSocketFactory.java:211)at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:301)... 24 more原因:没有开启远程登录,需要修改配置
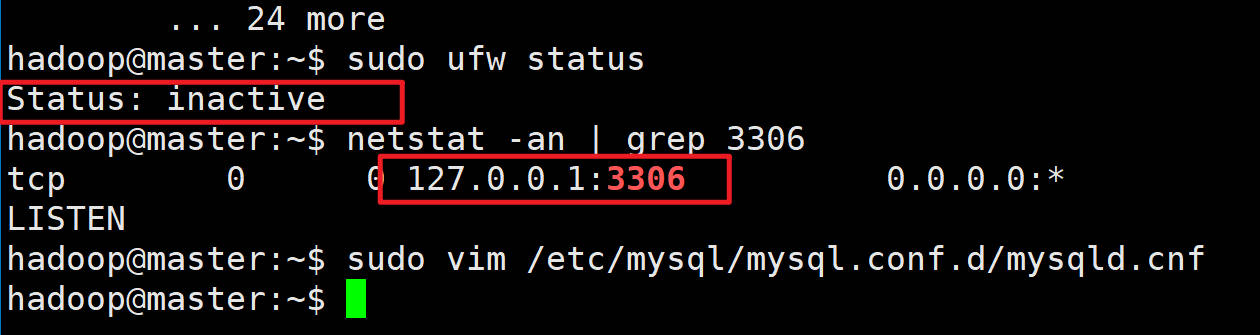
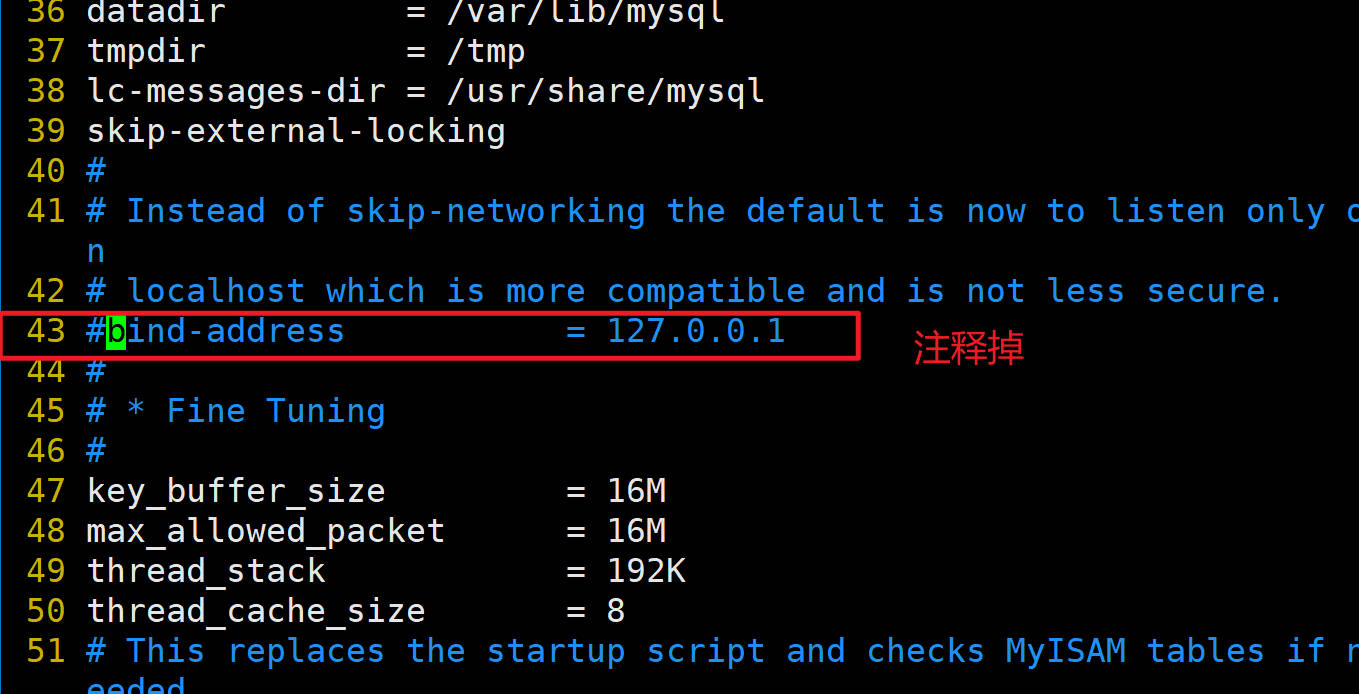
**解决方案:**#查看状态(防火墙是inactive状态) sudo ufw status #查看端口 netstat -an | grep 3306
~~~shell#编辑端口
#注释掉43行的bind-address
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf##修改端口,需要重启虚拟机
sudo reboot
成功状态:
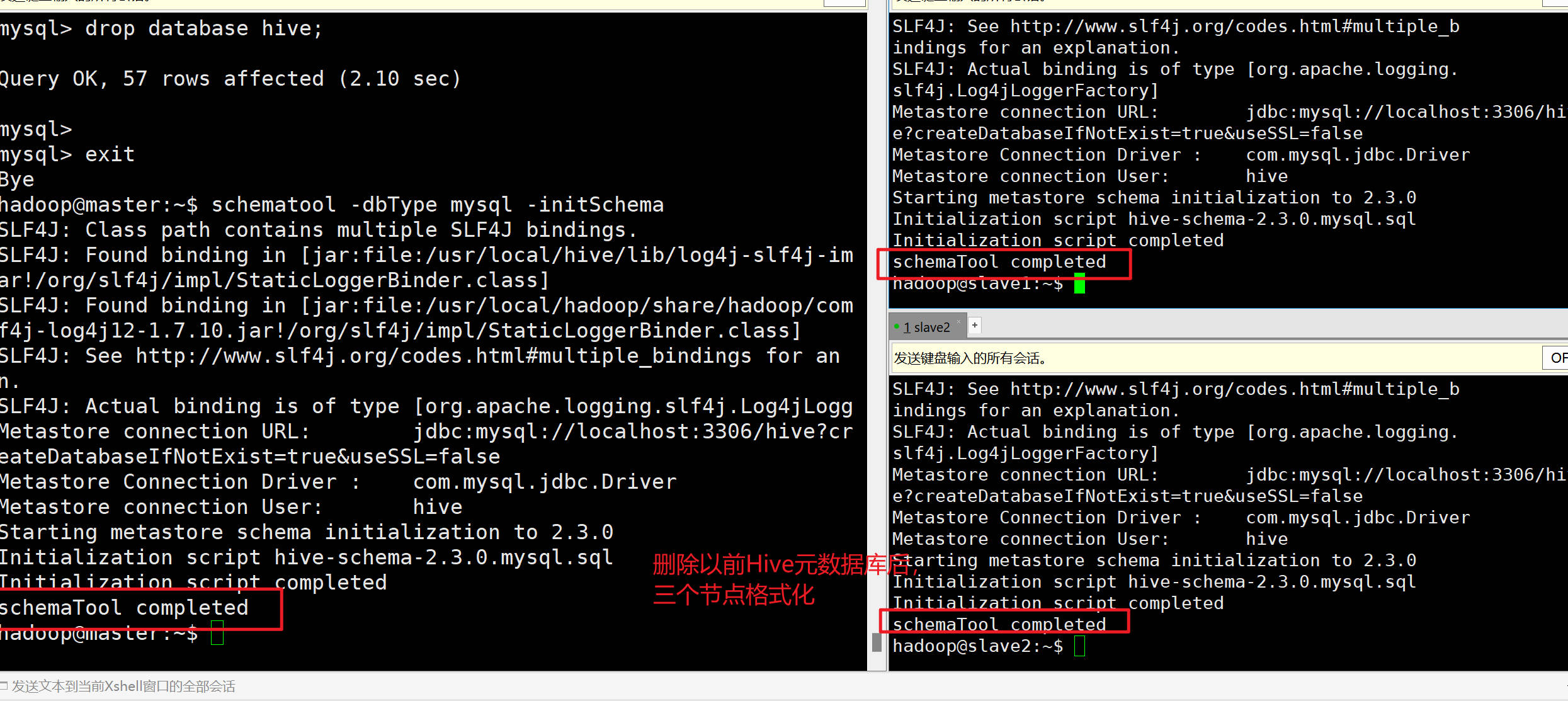
**如果Sqoop转移数据到Hive不成功需注意:**之前Hive初始化是在单机伪分布式状态下进行的,和现在集群状态不符,需要重新格式化HIve,删除MySQL的hive元数据库
#hive如果想重新配置的同学 #在配置完master的hive之后,不要初始化,根据情形进行下面操作 #情形一:如果单机节点没有配好,#按照Hive单机的安装步骤,在master配置完hive后,需要同步给slave1和slave2scp /usr/local/hive hadoop@slave1:/usr/local/scp /usr/local/hive hadoop@slave2:/usr/local/#同步系统环境变量scp /home/hadoop/.bashrc hadoop@slave1:/home/hadoopscp /home/hadoop/.bashrc hadoop@slave2:/home/hadoop#三个节点上刷新source /home/hadoop/.bashrc#情形二:单机已经成功,其他节点是克隆出来的#查看mysql数据里的hive元数据信息#查看默认的账号和密码,使用以下命令:sudo cat /etc/mysql/debian.cnfmysql -u debian-sys-maint -p #输入cat命令显示的密码#当前节点数据库有哪些show databases;#查看的密码#三个节点都要执行超级用户登录后,查看有没有hive的数据库,有的话删除drop database hive;#三个节点初始化操作schematool -dbType mysql -initSchema验证状态-Hive初始化成功:
再次执行查询数据库命令:
#测试能否成功连接数据库 sqoop list-databases --connect jdbc:mysql://master:3306/?useSSL=false --username sqoop --password 123456
1.3.4 使用前的数据准备
1.3.4.1 mysql数据准备(下面操作可在dbeaver中进行)
#(1)使用sqoop用户登录MySQL,使用以下命令:
#如果使用dbeaver连接MySQL,不用在输入这步命令了
mysql -u sqoop -p#(2)创建并使用使用sqoop数据库,使用以下命令:
create database sqoop
use sqoop#(3)创建student表用于演示导入MySQL数据到HDFS,使用以下命令:
CREATE TABLE IF NOT EXISTS `student`(
`id` int PRIMARY KEY COMMENT '编号',`name` varchar(20) COMMENT '名字',`age` int COMMENT '年龄'
)COMMENT '学生表';#(4) 向student表插入一些数据,使用以下命令:
INSERT INTO student VALUES(1, 'zhangsan', 20);
INSERT INTO student VALUES(2, 'lisi', 24);
INSERT INTO student VALUES(3, 'wangwu', 18);
INSERT INTO student VALUES(4, 'zhaoliui', 22);#(5) 创建student2表用于装载Hive导出的数据,使用以下命令:
CREATE TABLE IF NOT EXISTS `student2`(
`id` int PRIMARY KEY COMMENT '编号',
`name` varchar(20) COMMENT '名字',
`age` int COMMENT '年龄'
)COMMENT '学生表';
dbeaver远程登录MySQL失败:
#查看状态
sudo ufw status
#查看端口
netstat -an | grep 3306#编辑端口
#注释掉43行的bind-address
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
#bind-address = 127.0.0.1##修改端口,需要重启虚拟机
sudo reboot
数据准备完成后:
- student表:
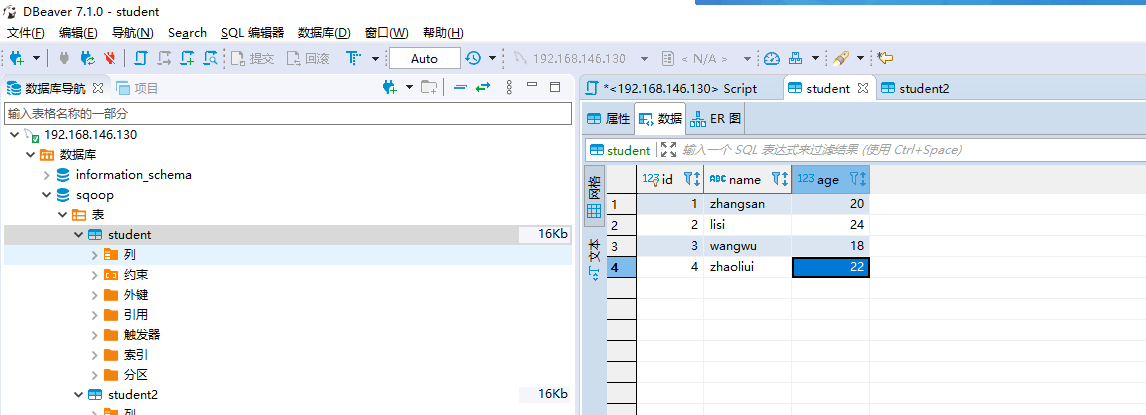
- student2表:
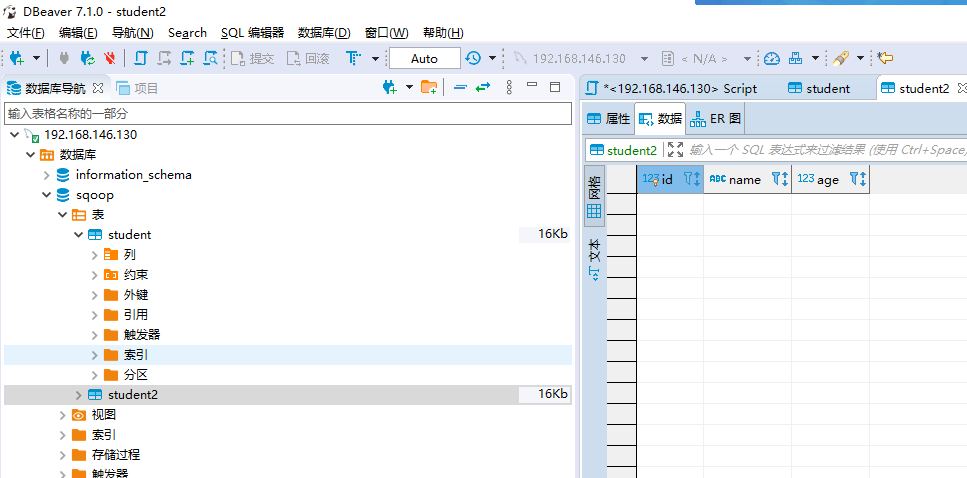
1.3.4.2 Hive的准备(也在dbeaver中执行):
--(1) 启动hive,使用以下命令:
hiveserver2
--(2) 打开DBeaver连接Hive--(3) 创建sqoop数据库,使用以下命令:
CREATE DATABASE sqoop;--(4) 使用sqoop数据库,使用以下命令:
USE sqoop;--(5) 创建student表用于装载MySQL导入的数据,使用以下命令:
CREATE TABLE IF NOT EXISTS student(id INT COMMENT '编号',name STRING COMMENT '名字',age INT COMMENT '年龄'
) COMMENT '学生表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' ';
- 如果搭建完HadoopHA后在启动Hive报错
hive启动时,提示java.net.UnknownHostException:ns
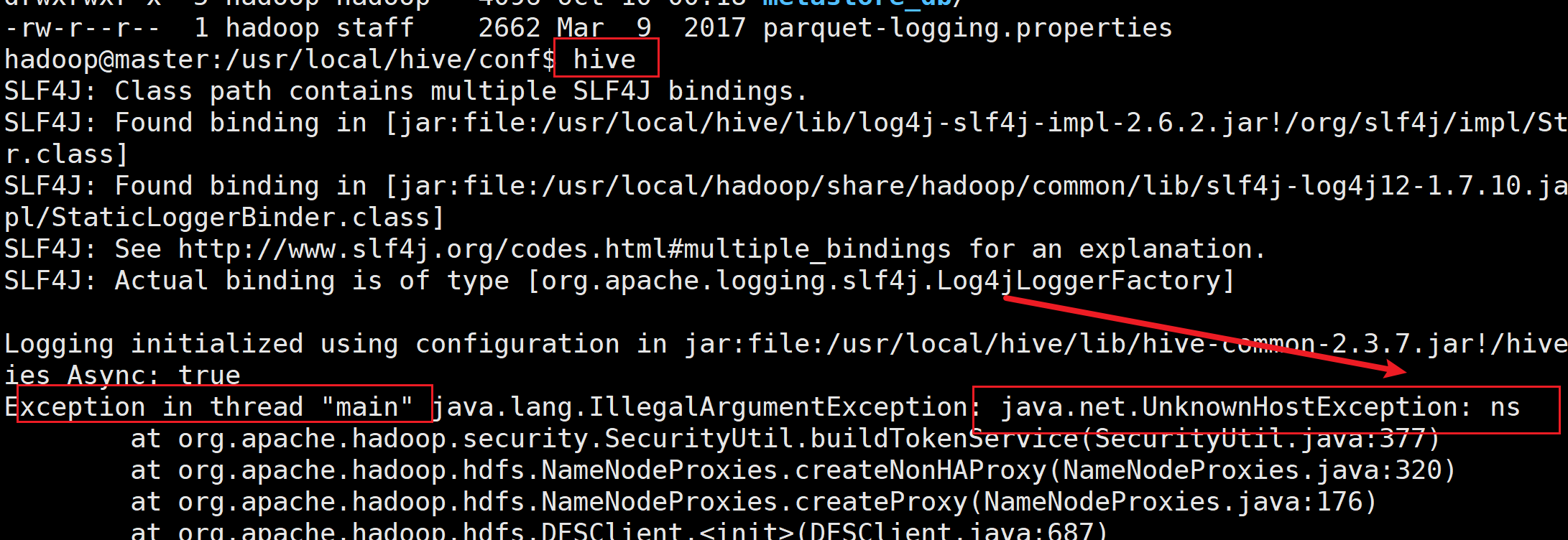
注意复制HDFS的core-site.xml和hdfs-site.xml到hive目录的conf下面
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hive/conf
cp /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hive/conf
1.5 Sqoop命令
Sqoop 的常用命令
| 命令 | 说明 |
|---|---|
| list-databases | 列出所有数据库名 |
| list-tables | 列出某个数据库下所有表 |
| import | 将数据导入到 HDFS 集群,hive,hbase,hdfs本身等等 |
| export | 将 HDFS 集群数据导出 |
| help | 打印 sqoop 帮助信息 |
| version | 打印 sqoop 版本信息 |
Sqoop 的公共参数
| 命令 | 说明 |
|---|---|
| –connect | 连接关系型数据库的URL |
| –username | 连接数据库的用户名 |
| –password | 连接数据库的密码 |
Sqoop的 import 命令参数
| 参数 | 说明 |
|---|---|
| –fields-terminated-by | Hive中的列分隔符,默认是逗号 |
| –lines-terminated-by | Hive中的行分隔符,默认是\n |
| –append | 将数据追加到HDFS中已经存在的DataSet中,如果使用该参数,sqoop会把数据先导入到临时文件目录,再合并。 |
| –columns | 指定要导入的字段 |
| –m或–num-mappers | 启动N个map来并行导入数据,默认4个。 |
| –query或**–e** | 将查询结果的数据导入,使用时必须伴随参–target-dir,–hive-table,如果查询中有where条件,则条件后必须加上$CONDITIONS关键字 |
| –table | 关系数据库的表名 |
| –target-dir | 指定导入数据存储的HDFS路径 |
| –null-string | string类型的列如果null,替换为指定字符串 |
| –null-non-string | 非string类型的列如果null,替换为指定字符串 |
| –check-column | 作为增量导入判断的列名 |
| –incremental | mode:append或lastmodified |
| –last-value | 指定某一个值,用于标记增量导入的位置 |
Sqoop 的 export 命令参数
| 参数 | 说明 |
|---|---|
| –input-fields-terminated-by | Hive中的列分隔符,默认是逗号 |
| –input-lines-terminated-by | Hive中的行分隔符,默认是\n |
| –export-dir | 存放数据的HDFS的源目录 |
| -m或–num-mappers | 启动N个map来并行导出数据,默认4个 |
| –table | 指定导出到哪个RDBMS中的表 |
| –update-key | 对某一列的字段进行更新操作 |
| –update-mode | updateonly或allowinsert(默认) |
Sqoop 的命令案例
- 导入到HDFS
#查看MySQL中已有的数据库名称
sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username sqoop --password 123456#查看MySQL中Sqoop数据库中的表,使用以下命令
sqoop list-tables --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456#导入全部MySQL数据到HDFS,执行以下命令
sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --table student --target-dir /user/student --delete-target-dir -m 1#执行完成后,去HDFS查看数据是否导入成功,使用以下命令:
hdfs dfs -cat /user/student/part-m-00000#导入部分mysql数据到HDFS(导入时筛选)
#-- query不与--table同时使用
#必须在where后面加上$CONDITIONS
sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --target-dir /user/student --delete-target-dir -m 1 --query 'select * from student where age <20 and $CONDITIONS'
查看–target-dir指定的路径
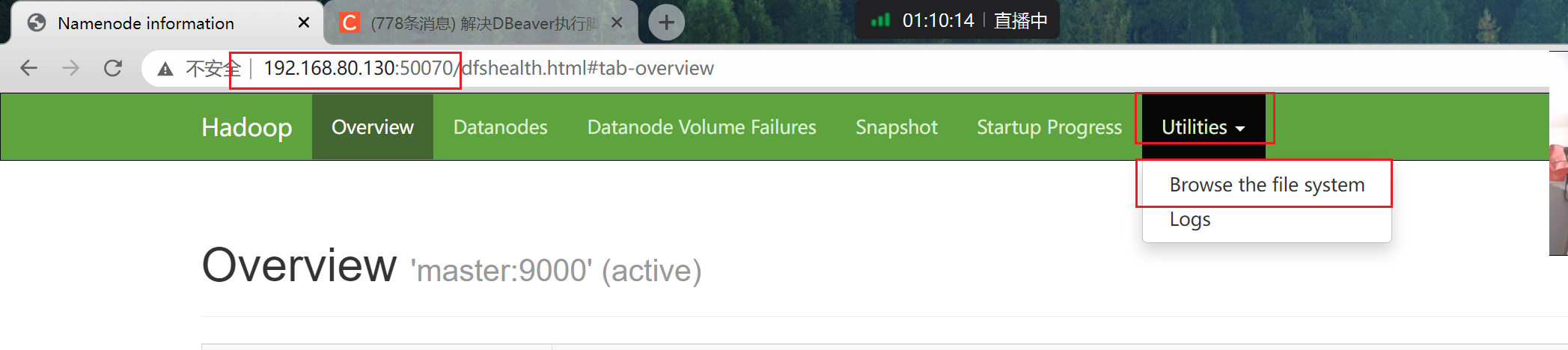
-
导入到Hive
#导入MySQL数据到hive sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --table student --target-dir /user/student2 --delete-target-dir --hive-import --fields-terminated-by " " --columns id,name,age --hive-overwrite --hive-table sqoop.student -m 1#导入部分MySQL数据到hive(覆盖导入) sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --target-dir /user/student2 --delete-target-dir -m 1 --query 'select * from student where age <20 and $CONDITIONS' --hive-import --fields-terminated-by " " --columns id,name,age --hive-overwrite --hive-table sqoop.student2 #增量导入部分MySQL数据到hive #--incremental append不能和--delete-target-dir一起用 sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --table student --target-dir /user/student2 --hive-import --fields-terminated-by " " --columns id,name,age --hive-table sqoop.student2 --check-column id --incremental append --last-value 3 -m 1-
问题:导入数据权限不足,导入hive失败
-
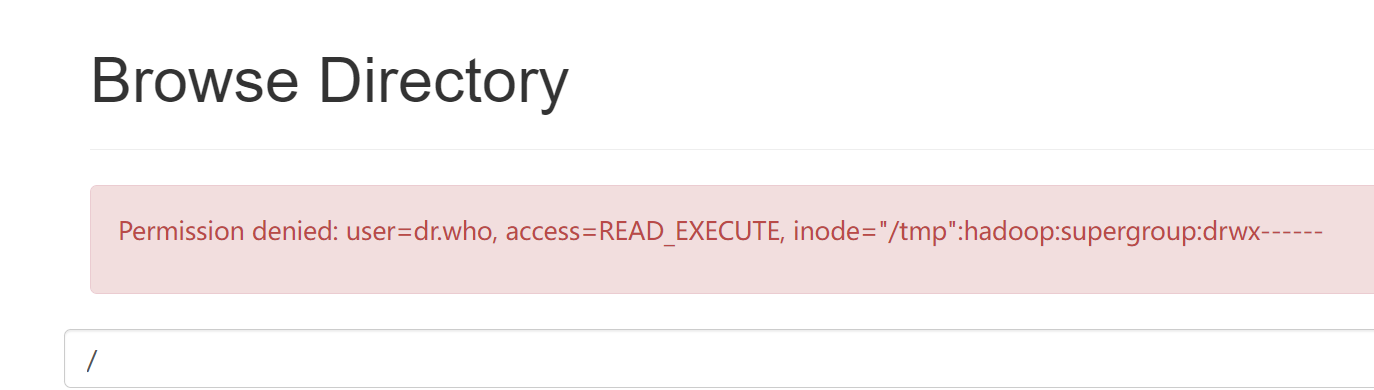
-
Hdfs页面操作文件出现 Permission denied: user=dr.who,
-
#在xshell hdfs dfs -chmod -R 755 /
-
-
-
-
导入到HBase
#导入数据到HBase,需要提前创建对应的表student
#导入数据之前
hbase shell
create 'student','info'#开始执行导入命令
sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 -table student -hbase-table "student" --hbase-row-key "id" --column-family "info" --columns "id,name,age" --split-by id -m -1
- Hive导出到MySQL
#Sqoop 的导出命令案例
sqoop export --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --table student2 --export-dir /usr/local/hive/warehouse/sqoop.db/student --input-fields-terminated-by " " -m 1

2. Flume
2.1Flume简介
-
Flume是一个分布式的、高可靠的、高可用的将大批量的不同数据源的日志数据收集、聚合、移动**到数据中心(**HDFS)进行存储的系统
-
1、可以高速采集数据,采集的数据能够以想要的文件格式及压缩方式存储在hdfs上;
-
2、事务功能保证了数据在采集的过程中数据不丢失;
- 原子性
-
3、部分Source保证了Flume挂了以后重启依旧能够继续在上一次采集点采集数据,真正做到数据零丢失。
-
2.2Flume架构
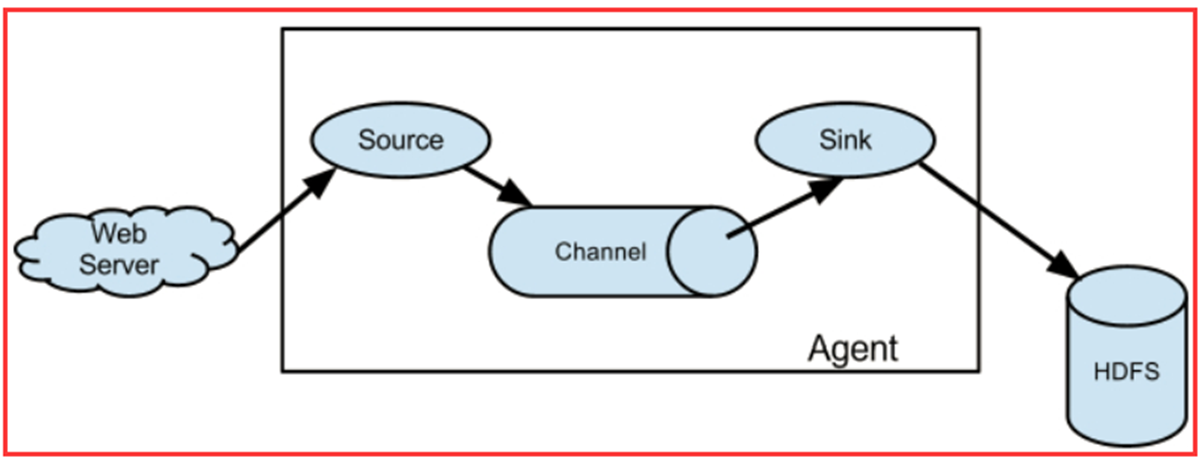
- Agent 是 Flume 中最小的独立运行单位,一个 agent 就是一个 JVM(java虚拟机)
- 含有三个核心组件,分别是 source、channel 和 sink
2.3 Flume安装
#下载、上传、解压、重命名和授权
https://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz#上传到 /home/hadoop 目录
sudo tar -xvf apache-flume-1.9.0-bin.tar.gz -C /usr/localsudo mv /usr/local/apache-flume-1.9.0-bin/ /usr/local/flumesudo chown -R hadoop /usr/local/flume
2.4 Flume配置
配置环境变量
#编辑环境变量
vim /home/hadoop/.bashrc#在环境变量最后添加以下内容
export FLUME_HOME=/usr/local/flume
export PATH=$PATH:$FLUME_HOME/bin#刷新环境变量
source /home/hadoop/.bashrc
配置 Agent
# 为 agent 起个名字叫做 a1
# 设置 a1 的 sources 叫做 r1
a1.sources = r1# 设置 a1 的 sinks 叫做 k1
a1.sinks = k1# 设置 a1 的 channels 叫做 c1
a1.channels = c1
配置Source
# 设置 r1 的类型是 exec,用于采集命令产生的数据
a1.sources.r1.type = exec# 设置 r1 采集 tail -F 命令产生的数据
a1.sources.r1.command = tail -F /home/hadoop/tail-test.txt
配置 Channel
- 两种常见类型:MemoryChannel和FileChannel
# 设置 c1 的类型是 memory
a1.channels.c1.type = memory# 设置 c1 的缓冲区容量
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
配置 Sink
# 设置 k1 的类型是 hdfs
a1.sinks.k1.type = hdfs
# 设置 k1 输出路径,按照时间在 hdfs 上创建相应的目录
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
# 设置 k1 输出的数据保存为文本
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
# 把时间戳放入数据的头中
a1.sinks.k1.hdfs.useLocalTimeStamp = true
组装 Source、Channel 和 Sink
# 设置 r1 连接 c1
a1.sources.r1.channels = c1# 设置 k1 连接 c1
a1.sinks.k1.channel = c1
2.5 Flume使用
了解tail -F的命令
#(1)进入/home/hadoop目录,使用以下命令:
cd /home/hadoop/
#(2)创建touch tail-test.txt文件,使用以下命令:
touch tail-test.txt
#(3)向tail-test.txt文件中追加一些内容,使用以下命令:
echo 'hello 11111' >> tail-test.txt
echo 'hello 22222'>> tail-test.txt
echo 'hello 33333'>> tail-test.txt
#(4)查看tail-test.txt文件中的内容,使用以下命令:
cat tail-test.txt
#(5)复制(新开)一个xshell窗口监控tail-test.txt文件内容的变化,使用以下命令:
tail -F tail-test.txt
#(6)回到上一个xshell窗口,继续向tail-test.txt文件中追加一些内容,使用以下命令:
echo 'hello 44444' >> tail-test.txt
echo 'hello 55555'>> tail-test.txt
echo 'hello 66666'>> tail-test.txt
#查看tail -F命令是否监控到内容的变化
使用flume
目标:把tail-test.txt文件中新增的内容给采集到HDFS
#搭配着Flume把tail-test.txt文件中新增的内容给采集到HDFS上。
#(1)新开一个xshell窗口,创建exec-memory-hdfs.properties文件,使用以下命令:
touch exec-memory-hdfs.properties
#(2)编辑touch exec-memory-hdfs.properties文件,填写以下内容:
sudo vim exec-memory-hdfs.properties
# 单节点的 flume 配置文件
# 为 agent 起个名字叫做 a1
# 设置 a1 的 sources 叫做 r1
a1.sources = r1# 设置 a1 的 sinks 叫做 k1
a1.sinks = k1# 设置 a1 的 channels 叫做 c1
a1.channels = c1# 设置 r1 的类型是 exec,用于采集命令产生的数据
a1.sources.r1.type = exec# 设置 r1 采集 tail -F 命令产生的数据
a1.sources.r1.command = tail -F /home/hadoop/tail-test.txt# 设置 c1 的类型是 memory
a1.channels.c1.type = memory# 设置 c1 的缓冲区容量
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 设置 k1 的类型是 hdfs
a1.sinks.k1.type = hdfs# 设置 k1 输出路径,按照时间在 hdfs 上创建相应的目录
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-# 设置 k1 输出的数据保存为文本
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text# 把时间戳放入数据的头中
a1.sinks.k1.hdfs.useLocalTimeStamp = true# 设置 r1 连接 c1
a1.sources.r1.channels = c1# 设置 k1 连接 c1
a1.sinks.k1.channel = c1
启动 Flume
- 启动三个节点zookeeper
zkServer.sh start
- 先启动hdfs和yarn
start-dfs.sh
start-yarn.sh
- 启动 Flume
#启动 Flume
flume-ng agent -n a1 -c conf -f /home/hadoop/exec-memory-hdfs.properties
验证flume
#(4)在第一个xshell窗口大量的向tail-test.txt文件中追加数据
echo 'hello 44444' >> tail-test.txt
echo 'hello 55555' >> tail-test.txt
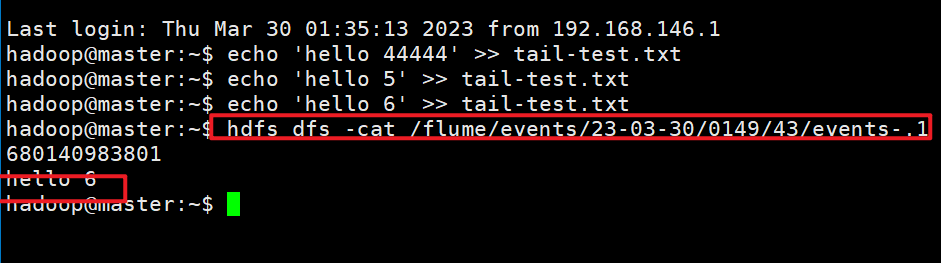
echo 'hello 6666' >> tail-test.txt#2. 在xshell里,使用命令
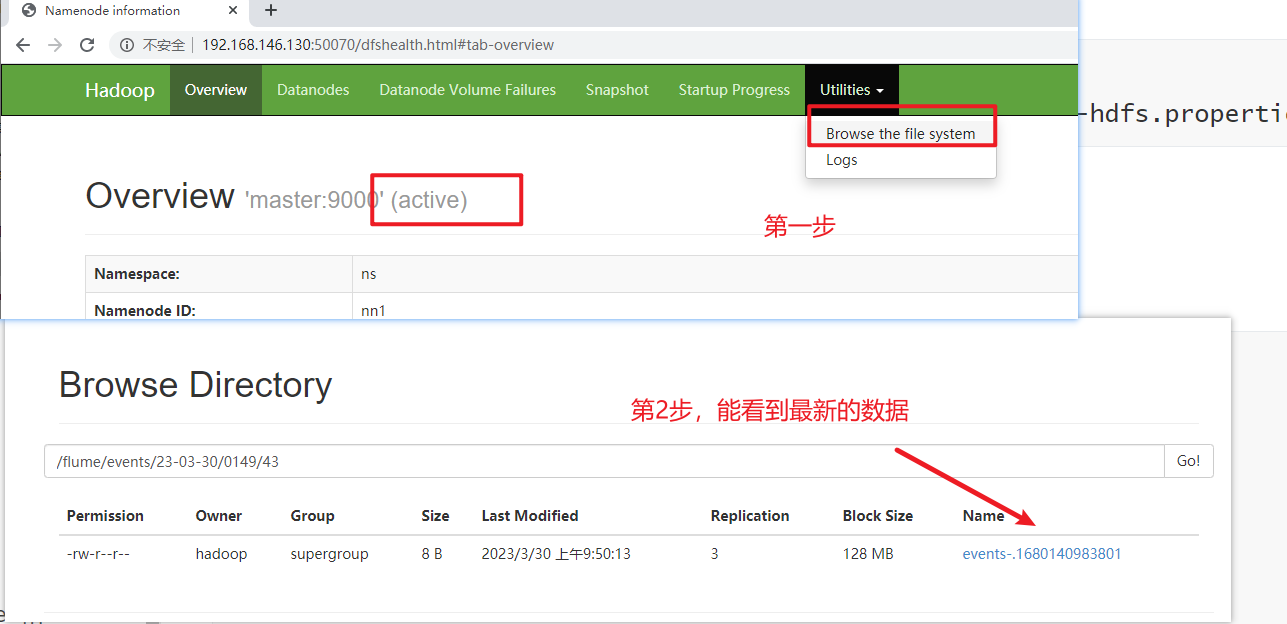
hdfs dfs -cat /flume/events/目录的名称/文件名,可以看到数据
- 去HDFS的web监控页面查看是否采集到数据
- 能看到有新生成的目录
-
在xshell里,使用命令
hdfs dfs -cat /flume/events/目录的名称/文件名,可以看到数据
相关文章:
sqoop和flume简单安装配置使用
1. Sqoop 1.1 Sqoop介绍 Sqoop 是一个在结构化数据和 Hadoop 之间进行批量数据迁移的工具 结构化数据可以是MySQL、Oracle等关系型数据库 把关系型数据库的数据导入到 Hadoop 与其相关的系统 把数据从 Hadoop 系统里抽取并导出到关系型数据库里 底层用 MapReduce 实现数据 …...

什么是React Router?它的作用是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...
界面控件DevExtreme v23.1 - UI组件 UI模板库增强
DevExtreme拥有高性能的HTML5 / JavaScript小部件集合,使您可以利用现代Web开发堆栈(包括React,Angular,ASP.NET Core,jQuery,Knockout等)构建交互式的Web应用程序。从Angular和Reac,…...

Fedora Linux 38下Mariadb数据库设置utf8mb4字符编码
Fedora操作系统之下最好使用开源免费的MySQL替代品Mariadb来学习MySQL的知识,一点也不会耽搁。 连接上互联网后,打开shell命令行界面,Sudo dnf install mariadb-server mariadb -y就可以安装好 mariadb-server和 mariadb࿰…...
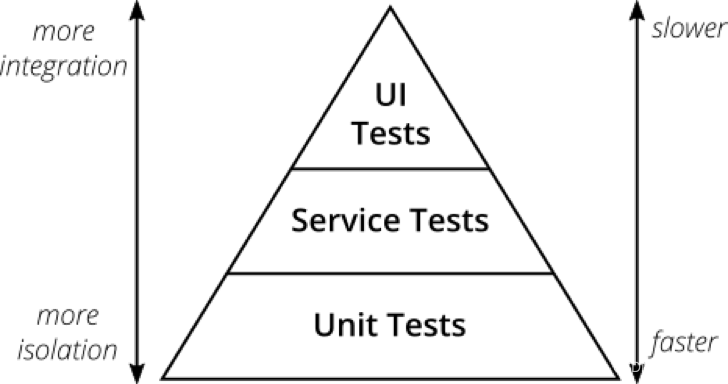
【单元测试】--高级主题
一、模拟与存根深入 在单元测试中,模拟(Mock)和存根(Stub)是两种常用的测试替代品,用于模拟外部依赖或模拟特定行为,以便测试能够独立运行。以下是深入了解模拟与存根的概念,以NUni…...
)
面向对象程序设计(2023年10月)
设计模式:参考下文 23 种设计模式详解(全23种)-CSDN博客...

常用正在表达式
function isIP(s) //by zergling { var patrn/^[0-9.]{1,20}$/; if (!patrn.exec(s)) return false return true } //校验密码:只能输入6-20个字母、数字、下划线 function isPasswd(s) { var patrn/^(\w){6,20}$/; if (!patrn.exec(s)) return false return true …...

ES6初步了解Map对象(含十种方法)
ES6提供了 Map数据结构。它类似于对象,也是键值对的集合。但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。 创建方法 let m new Map()console.log(m)Map的方法 1.set( ) 添加元素 接收两个参数,…...
推荐一款可以识别m3u8格式ts流批量下载并且合成mp4视频的chrome插件——猫抓
https://chrome.google.com/webstore/detail/%E7%8C%AB%E6%8A%93/jfedfbgedapdagkghmgibemcoggfppbb?utm_sourceext_app_menuhttps://chrome.google.com/webstore/detail/%E7%8C%AB%E6%8A%93/jfedfbgedapdagkghmgibemcoggfppbb?utm_sourceext_app_menu 网页媒体嗅探工具 一…...

文本处理方法及其在NLP中的应用
文本处理方法及其在NLP中的应用 了解 在自然语言处理(NLP)领域,文本处理是一个至关重要的环节。 本篇博文将介绍几种常用的文本处理方法,并重点讨论了其中两种:One-Hot编码和停用词过滤。这些方法对于将文本转化为计…...

html文字一行时靠右,多行时靠左
html文字一行时靠右,多行时靠左 元素居中 display: block; margin: auto; 文字居中 text-align: center; 文字下划线 text-decoration: underline; 边框线 border: 1px #1D6AF8 double; 圆弧角 border-radius: 10px; <!DOCTYPE html> <html><hea…...

Stable-diffusion-webui
AI 画图,之前整理的 AI换脸 CSDN不给通过,说是换脸之类的不给通过,只能自己看了。 GitHub:https://github.com/AUTOMATIC1111/stable-diffusion-webuihttps://github.com/AUTOMATIC1111/stable-diffusion-webui 安装完毕跑起来大概…...

Python中的文件操作和异常处理
在Python编程中,文件操作和异常处理是非常重要的概念。本文将介绍如何使用Python进行文件读写操作,并展示如何处理可能出现的错误和异常情况。 文件读写操作 Python提供了简单而强大的文件读写功能,让我们能够轻松地处理各种文件类型。下面…...

KF-GINS 和 OB-GINS 的 Earth类 和 Rotation 类
原始 Markdown文档、Visio流程图、XMind思维导图见:https://github.com/LiZhengXiao99/Navigation-Learning 文章目录 一、Earth 类:地球参数和坐标转换1、gravity():正常重力计算2、meridianPrimeVerticalRadius():计算子午圈半径…...

2017年亚太杯APMCM数学建模大赛B题喷雾轨迹规划问题求解全过程文档及程序
2017年亚太杯APMCM数学建模大赛 B题 喷雾轨迹规划问题 原题再现 喷釉工艺用喷釉枪或喷釉机在压缩空气下将釉喷入雾中,使釉附着在泥体上。这是陶瓷生产过程中一个容易实现自动化的过程。由于不均匀的釉料在烧制过程中会产生裂纹,导致工件报废࿰…...

柏拉图式爱情是同性之爱,绘画是理念世界的二次模仿
公元前427年,柏拉图出生在雅典。 柏拉图20岁成为苏格拉底的弟子。 有一次,柏拉图问苏格拉底:“什么是爱情?”苏格拉底说:“请穿越麦田,摘一株最大最金黄的麦穗回来。不走回头路,只能摘一次。”…...

【滴滴出行安全应急响应平台DSRC2倍积分卡】
1、使用方法 2、券(记得点个关注,做一下数据)...

HashMap 元素添加流程
在Java 1.8中,HashMap的元素添加流程: 计算键的哈希值:当调用put(key, value)方法时,首先会计算键(key)的哈希值,这个哈希值用来确定元素在内部数组中的位置。确定位置:通过哈希值&…...

甲亢_甲状腺功能亢进_Methimazole甲巯基咪唑
美国医生 Methimazole甲巯基咪唑 is used to treat hyperthyroidism, a condition where the thyroid gland produces too much thyroid hormone. It is also used before thyroid surgery or radioactive iodine treatment. Methimazole is an antithyroid medicine. It wor…...
【Maven】VSCode Java+Maven 环境配置
0x00 前言 没写过 Java,得配个带 Maven 的编码环境,不太明白,试试看顺便记录一下 0x01 配置过程 安装 jdk1.8 后,找到安装位置: (base) dianCD-Ali doraemon % /usr/libexec/java_home -V Matching Java Virtual Ma…...

检索模型cross-encoder笔记
文章目录计算句子对相似度搜索结果的“重排序”cross-encoder一种检索模型,和双路召回机制不一样,各有优缺点。cross-encoder最大的特点就是会将query(问题)和document(候选文本)一起分析。一般的流程是,双路召回先粗排,cross-enc…...
)
从电赛真题到产品原型:深入解析单相全桥逆变三种SPWM调制策略(含效率与波形对比)
单相全桥逆变SPWM调制策略实战:从电赛到工业应用的深度解析 在电力电子领域,逆变技术作为直流-交流转换的核心环节,其性能优劣直接影响着整个系统的效率与可靠性。单相全桥逆变器凭借其结构简单、控制灵活的特点,成为电子设计竞赛…...

【 MySQL 】第三节 - 约束实战全攻略
🌟【深度剖析】MySQL 约束实战全攻略:从建表到外键行为管理(附避坑指南) 前言 在数据库设计中,约束(Constraint) 是保障数据一致性、完整性和业务逻辑性的“安全锁”。日前我系统学习了 MySQL…...

VR视频转换:让3D内容在普通设备焕发新生的开源方案
VR视频转换:让3D内容在普通设备焕发新生的开源方案 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.com/gh_mirro…...
)
保姆级教程:用C++和Eigen库手搓一个URDF机器人正解器(以Franka Panda为例)
从零实现URDF机器人正解器:C与Eigen实战指南(Franka Panda案例) 机械臂末端执行器的精准定位是机器人控制的基础。本文将带你用C和Eigen库,不依赖ROS等框架,从零构建一个完整的URDF解析与正运动学计算系统。我们会以F…...
)
为什么你的视觉检测准确率卡在92.7%?(揭秘工业现场3类未标注异常数据导致的模型过拟合代码根源)
第一章:视觉检测准确率瓶颈的工业现场真相在实际产线部署中,视觉检测模型在实验室达到99.2%的mAP,落地后却频繁出现漏检与误报——这不是算法缺陷,而是工业现场多维干扰叠加的真实映射。光照波动、工件表面反光、传送带抖动、镜头…...

QQ空间历史说说备份终极攻略:3步实现数据永久保存
QQ空间历史说说备份终极攻略:3步实现数据永久保存 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory GetQzonehistory是一款专为QQ空间用户设计的开源数据备份工具,…...
)
手把手教你用STM32驱动ADS1292R心电模块(附完整代码与SPI避坑指南)
手把手教你用STM32驱动ADS1292R心电模块(附完整代码与SPI避坑指南) 在医疗电子和可穿戴设备领域,生物电信号采集一直是核心技术难点之一。TI的ADS1292R作为一款高集成度、低功耗的生物电信号前端芯片,能够同时采集心电(…...

Harness Engineering: 为 AI 搭建可持续迭代环境的实践
在公司内部一个 AIGC页面 Verify 项目(下面代号 HelixVerify )中,我们经历了 114 次版本迭代, 将相对benchmark 的风险样本召回率从 最初的 8% 提升至 98.86%,无风险样本通过率从 36.11% 提升至 54.93%。 **整个 114 次迭代中,基本没有代码是我手写的。**从第一个版本开始,所有…...

别再为电赛E题发愁了!用OpenMV+舵机云台搞定运动目标追踪的保姆级避坑指南
OpenMV舵机云台运动目标追踪实战:从硬件搭建到代码调试的全流程避坑指南 刚拿到电赛E题任务书时,看着"运动目标控制与自动追踪系统"这个标题,我和队友面面相觑——既要处理图像识别,又要协调舵机运动,这对毫…...