python pandas.DataFrame 直接写入Clickhouse
import pandas as pd
import sqlalchemy
from clickhouse_sqlalchemy import Table, engines
from sqlalchemy import create_engine, MetaData, Column
import urllib.parsehost = '1.1.1.1'
user = 'default'
password = 'default'
db = 'test'
port = 8123 # http连接端口
engine = create_engine('clickhouse://{user}:{password}@{host}:{port}/{db}'.format(user = user,host = host,password = urllib.parse.quote_plus(password),db = db,port = port),pool_size = 30,max_overflow = 0,pool_pre_ping=True , pool_recycle= 3600)
port = 9000 # Tcp/Ip连接端口
engine1 = create_engine('clickhouse+native://{user}:{password}@{host}:{port}/{db}'.format(user = user,host = host,password = urllib.parse.quote_plus(password),db = db,port = port),pool_size = 30,max_overflow = 0,pool_pre_ping=True , pool_recycle=3600)# https://github.com/xzkostyan/clickhouse-sqlalchemy/issues/129
# 参考文档https://github.com/xzkostyan/clickhouse-sqlalchemy
# pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install clickhouse-sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simpleclass ClickhouseDf(object):def __init__(self, **kwargs):self.engines_dict = {"MergeTree": engines.MergeTree,"AggregatingMergeTree": engines.AggregatingMergeTree,"GraphiteMergeTree": engines.GraphiteMergeTree,"CollapsingMergeTree": engines.CollapsingMergeTree,"VersionedCollapsingMergeTree": engines.VersionedCollapsingMergeTree,"SummingMergeTree": engines.SummingMergeTree,"ReplacingMergeTree": engines.ReplacingMergeTree,"Distributed": engines.Distributed,"ReplicatedMergeTree": engines.ReplicatedMergeTree,"ReplicatedAggregatingMergeTree": engines.ReplicatedAggregatingMergeTree,"ReplicatedCollapsingMergeTree": engines.ReplicatedCollapsingMergeTree,"ReplicatedVersionedCollapsingMergeTree": engines.ReplicatedVersionedCollapsingMergeTree,"ReplicatedReplacingMergeTree": engines.ReplicatedReplacingMergeTree,"ReplicatedSummingMergeTree": engines.ReplicatedSummingMergeTree,"View": engines.View,"MaterializedView": engines.MaterializedView,"Buffer": engines.Buffer,"TinyLog": engines.TinyLog,"Log": engines.Log,"Memory": engines.Memory,"Null": engines.Null,"File": engines.File}self.table_engine = kwargs.get("table_engine", "MergeTree") # 默认引擎选择if self.table_engine not in self.engines_dict.keys():raise ValueError("No engine for this table")def _createORMTable(self, df, name, con, schema, **kwargs):col_dtype_dict = {"object": sqlalchemy.Text,"int64": sqlalchemy.Integer,"int32": sqlalchemy.Integer,"int16": sqlalchemy.Integer,"int8": sqlalchemy.Integer,"int": sqlalchemy.Integer,"float64": sqlalchemy.Float,"float32": sqlalchemy.Float,"float16": sqlalchemy.Float,"float8": sqlalchemy.Float,"float": sqlalchemy.Float,}primary_key = kwargs.get("primary_key", [])df_col = df.columns.tolist()metadata = MetaData(bind=con, schema=schema)_table_check_col = []for col in df_col:col_dtype = str(df.dtypes[col])if col_dtype not in col_dtype_dict.keys():if col in primary_key:_table_check_col.append(Column(col, col_dtype_dict["object"], primary_key=True))else:_table_check_col.append(Column(col, col_dtype_dict["object"]))else:if col in primary_key:_table_check_col.append(Column(col, col_dtype_dict[col_dtype], primary_key=True))else:_table_check_col.append(Column(col, col_dtype_dict[col_dtype]))_table_check = Table(name, metadata,*_table_check_col,self.engines_dict[self.table_engine](primary_key=primary_key))return _table_checkdef _checkTable(self, name, con, schema):sql_str = f"EXISTS {schema}.{name}"if con.execute(sql_str).fetchall() == [(0,)]:return 0else:return 1def to_sql(self, df, name: str, con, schema=None, if_exists="fail",**kwargs):'''将DataFrame格式数据插入Clickhouse中{'fail', 'replace', 'append'}, default 'fail''''if self.table_engine in ["MergeTree"]: # 表格必须有主键的引擎列表-暂时只用这种,其他未测试self.primary_key = kwargs.get("primary_key", [df.columns.tolist()[0]])else:self.primary_key = kwargs.get("primary_key", [])orm_table = self._createORMTable(df, name, con, schema, primary_key=self.primary_key)tanle_exeit = self._checkTable(name, con, schema)# 创建表if if_exists == "fail":if tanle_exeit:raise ValueError(f"table already exists :{name} ")else:orm_table.create()if if_exists == "replace":if tanle_exeit:orm_table.drop()orm_table.create()else:orm_table.create()if if_exists == "append":if not tanle_exeit:orm_table.create()# http连接下会自动将None填充为空字符串以入库,tcp/ip模式下则不会,会导致引擎报错,需要手动填充。df_dict = df.to_dict(orient="records")con.execute(orm_table.insert(), df_dict)# df.to_sql(name, con, schema, index=False, if_exists="append")if __name__ == '__main__':# 使用方法cdf = ClickhouseDf()df = pd.DataFrame({'column1': [1, 2, 3],'column2': ['A', 'B', 'C']})db = 'default'password = ''user = 'default'port = 9090host = '192.168.76.136'engine = create_engine('clickhouse+native://{user}:{password}@{host}:{port}/{db}'.format(user=user,host=host,password=urllib.parse.quote_plus(password),db=db,port=port),pool_size=30, max_overflow=0,pool_pre_ping=True, pool_recycle=3600)with engine.connect() as conn:cdf.to_sql(df, "table_name", conn, schema='default', if_exists="replace")list = engine.connect().execute("SELECT * FROM table_name").fetchall()print(list)1) 运行需要安装包
# pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install clickhouse-sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
2)cdf.to_sql(df, "table_name", conn, schema='default', if_exists="replace")
这里的 schema 一定要写,判断表是否存在 是用
if con.execute('EXISTS default.table_name') == [(0,)]: 来判断表是否存在的
参考链接: SQLAlchemy_clickhouse_sqlalchemy-CSDN博客
https://github.com/xzkostyan/clickhouse-sqlalchemy
相关文章:

python pandas.DataFrame 直接写入Clickhouse
import pandas as pd import sqlalchemy from clickhouse_sqlalchemy import Table, engines from sqlalchemy import create_engine, MetaData, Column import urllib.parsehost 1.1.1.1 user default password default db test port 8123 # http连接端口 engine create…...

德语中第二虚拟式在主动态的形式,柯桥哪里可以学德语
德语中第二虚拟式在主动态的形式 1. 对于大多数的动词,一般使用这样的一般现在时时态: wrde 动词原形 例句:Wenn es nicht so viel kosten wrde, wrde ich mir ein Haus am Meer kaufen. 如果不花这么多钱,我会在海边买一栋房…...
[Python进阶] 消息框、弹窗:tkinter库
6.16 消息框、弹窗:tkinter 6.16.1 前言 应用程序中的提示信息处理程序是非常重要的部分,用户要知道他输入的资料到底正不正确,或者是应用程序有一些提示信息要告诉用户,都必须通过提示信息处理程序来显示适当的信息,…...
(免费领源码)java#Springboot#mysql装修选购网站99192-计算机毕业设计项目选题推荐
摘 要 随着科学技术,计算机迅速的发展。在如今的社会中,市场上涌现出越来越多的新型的产品,人们有了不同种类的选择拥有产品的方式,而电子商务就是随着人们的需求和网络的发展涌动出的产物,电子商务网站是建立在企业与…...
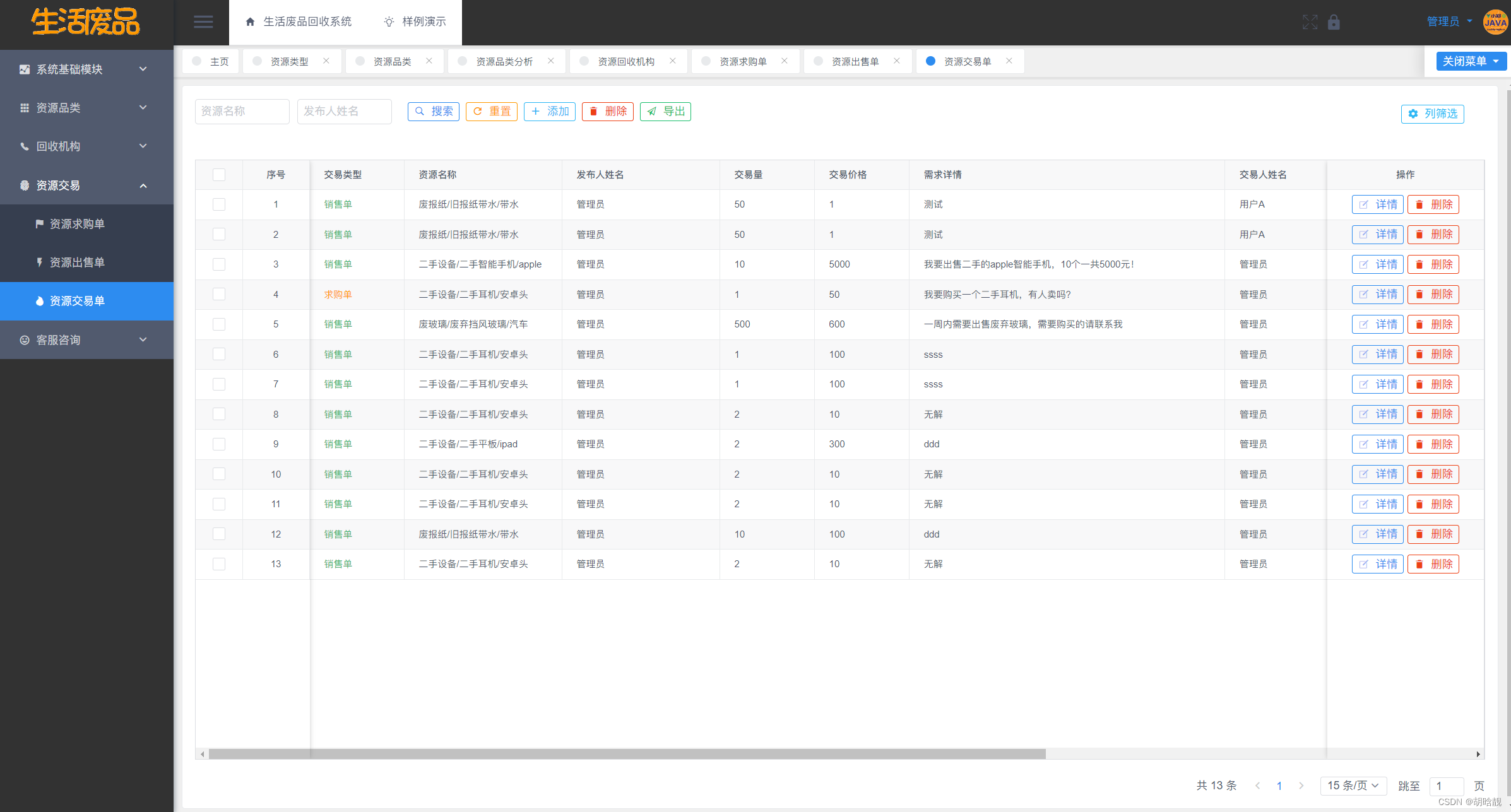
生活废品回收系统 JAVA语言设计和实现
目录 一、系统介绍 二、系统下载 三、系统截图 一、系统介绍 基于VueSpringBootMySQL的生活废品回收系统包含资源类型模块、资源品类模块、回收机构模块、回收机构模块、资源销售单模块、资源交易单模块、资源交易单模块,还包含系统自带的用户管理、部门管理、角…...

redhat/centos 配置本地yum源
- 详细步骤(首先需要将iso文件上传到服务器): 1. mkdir /media/cdrom #新建镜像文件挂载目录2. cd /usr/local/src #进入系统镜像文件存放目录3. ls #列出目录文件,可以看到刚刚上传的系统镜像文件4. mount -t iso9660 -o loop /usr/local/src/rhel-s…...
FLStudio2024汉化破解版在哪可以下载?
水果音乐制作软件FLStudio是一款功能强大的音乐创作软件,全名:Fruity Loops Studio。水果音乐制作软件FLStudio内含教程、软件、素材,是一个完整的软件音乐制作环境或数字音频工作站... FL Studio21简称FL 21,全称 Fruity Loops Studio 21,因此国人习惯叫…...

Java 音频处理,音频流转音频文件,获取音频播放时长
1.背景 最近对接了一款智能手表,手环,可以应用与老人与儿童监控,环卫工人监控,农场畜牧业监控,宠物监控等,其中用到了音频传输,通过平台下发语音包,发送远程命令录制当前设备音频并…...

Spring Boot发送邮件
在现代的互联网应用中,发送电子邮件是一项常见的功能需求。Spring Boot提供了简单且强大的邮件发送功能,使得在应用中集成邮件发送变得非常容易。本文将介绍如何在Spring Boot中发送电子邮件,并提供一个完整的示例。 1. 准备工作 在开始之前…...

智慧矿山:AI算法助力!刮板机监测,生产效率和安全性提升!
工作面刮板机在煤矿等采矿场景中起着重要作用。为了提高其生产效率和安全性,研究人员开发了一种基于 AI 算法的刮板机监测技术。 在传统的刮板机监测中,通常需要人工观察和判断刮板机的状态。这种方法存在许多问题,如主观性、耗时和易出错等。…...

Qt跨平台(统信UOS)各种坑解决办法
记录Qt跨平台的坑,方便日后翻阅。 一、环境安装 本人用的是qt 5.14.2.直接在官网下载即可。地址:Index of /archive/qt/5.14/5.14.2 下载linux版本。 下载之后 添加可执行权限。 chmod 777 qt-opensource-linux-x64-5.14.2.run 然后执行。 出现坑1…...

ORB-SLAM3算法1之Ubuntu18.04+ROS-melodic安装ORB-SLAM3及各种问题解决
文章目录 0 引言1 安装依赖1.1 opencv安装1.2 Eigen3安装1.3 Pangolin安装1.4 其他2 编译安装ORB-SLAM32.1 build.sh2.2 build_ros.sh0 引言 ORB-SLAM3,在之前ORB-SLAM和ORB-SLAM2的基础上,新增了IMU多传感器融合SLAM,这是第一个能够使用针孔和鱼眼镜头模型通过单目、立体和…...

git学习笔记之用命令行解决冲突
背景 一般来说,当使用git检测到源分支和目标分支发生冲突时,我们习惯用IDE在本地进行冲突的解决,再合并、push。 但如果冲突文件不多,我们大可以直接用命令行去解决冲突。 方法 第一种方法: 找到所有的>>>…...

C语言中的内联汇编是什么?如何使用内联汇编进行底层编程?
C语言中的内联汇编是一种高级编程技术,允许开发者在C代码中嵌入汇编代码,以实现对特定处理器指令的直接控制和优化。内联汇编通常用于底层编程,例如操作系统开发、嵌入式系统编程和性能关键的应用程序。本文将详细介绍内联汇编的概念、语法和…...
react笔记基础部分(组件生命周期路由)
注意点: class是一个关键字, 类。 所以react 写class, 用classname ,会自动编译替换class 点击方法: <button onClick {this.sendData}>给父元素传值</button>常用的插件: 需要引入才能使用的…...
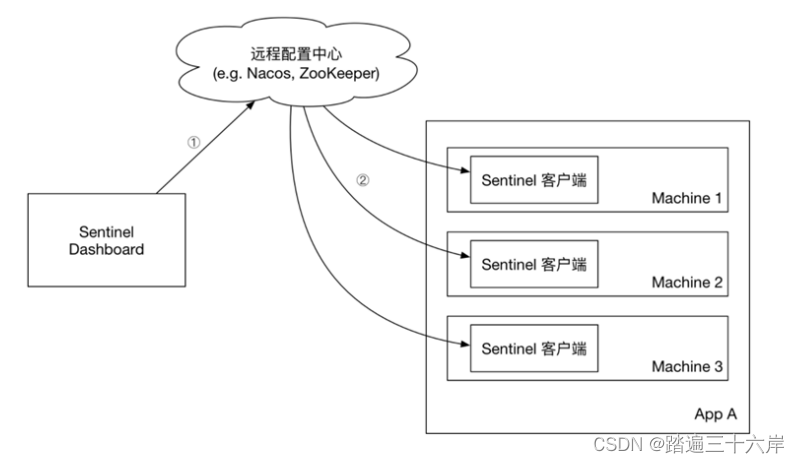
Sentinel授权规则和规则持久化
大家好我是苏麟 , 今天说说Sentinel规则持久化. 授权规则 授权规则可以对请求方来源做判断和控制。 授权规则 基本规则 授权规则可以对调用方的来源做控制,有白名单和黑名单两种方式。 白名单:来源(origin)在白名单内的调用…...
 垃圾回收)
JVM(三) 垃圾回收
一、自动垃圾回收 1.1 C/C++的内存管理 在C/C++这类没有自动垃圾回收机制的语言中,一个对象如果不再使用,需要手动释放,否则就会出现内存泄漏。我们称这种释放对象的过程为垃圾回收,而需要程序员编写代码进行回收的方式为手动回收。 内存泄漏指的是不再使用的对象在系统中…...

vue3中使用svg并封装成组件
打包svg地图 安装插件 yarn add vite-plugin-svg-icons -D # or npm i vite-plugin-svg-icons -D # or pnpm install vite-plugin-svg-icons -D使用插件 vite.config.ts import { VantResolver } from unplugin-vue-components/resolvers import { createSvgIconsPlugin } from…...
实验六:DHCP、DNS、Apache、FTP服务器的安装和配置
1. (其它) 掌握Linux下DHCP、DNS、Apache、FTP服务器的安装和配置,在Linux服务器上部署JavaWeb应用 完成单元八的实训内容。 1、安装 JDK 2、安装 MySQL 3、部署JavaWeb应用 安装jdk 教程连接:linux安装jdk8详细步骤-CSDN博客 Jdk来源:linu…...
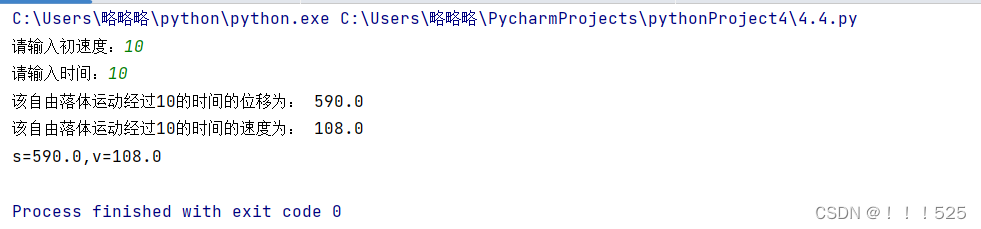
Python实验项目4 :面对对象程序设计
1:运行下面的程序,回答问题。 (1)说明程序的执行过程; (2)程序运行结果是什么? # (1)说明程序的执行过程; # (2)程序运行…...

AI时代的程序员应该如何就业突击找工作?编程语言该如何选择才不会被时代所淘汰?
AI时代的程序员应该如何就业突击找工作?编程语言该如何选择才不会被时代所淘汰? AI时代程序员就业突击与编程语言选择指南 一、就业突击策略 核心能力强化 算法与数据结构:掌握基础算法(排序/搜索)和高级结构&#x…...

KMS_VL_ALL_AIO:Windows与Office授权管理全场景解决方案
KMS_VL_ALL_AIO:Windows与Office授权管理全场景解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾在重要会议前遭遇Office突然提示"未授权"导致文件无法编辑…...
工具箱的使用)
MES(The Measures of Effect Size )工具箱的使用
MES(The Measures of Effect Size )效应量计算工具的使用 The Measures of Effect Size (MES) Toolbox is a set of Matlab functions which compute a wide range of effect size statistics. The four main toolbox functions cover common analysis d…...
验证服务**在Web3.0时代,用户不再依赖中心化的身份提供商()
**发散创新:用Rust构建Web3.0去中心化身份(DID)验证服务**在Web3.0时代,用户不再依赖中心化的身份提供商(
发散创新:用Rust构建Web3.0去中心化身份(DID)验证服务 在Web3.0时代,用户不再依赖中心化的身份提供商(如Google、微信登录),而是通过去中心化身份(Decentralized Identity, DID&…...
)
Mac用户必看:Homebrew换源提速全攻略(附清华镜像最新配置)
Mac开发者必备:Homebrew国内镜像加速终极指南 每次打开终端准备用Homebrew安装新工具时,那个缓慢的下载进度条是否让你抓狂?作为Mac生态中最受欢迎的包管理工具,Homebrew的默认服务器位于海外,国内用户常遭遇下载速度以…...

告别黑苹果配置噩梦:5大核心优势让开源工具OpCore-Simplify成为新手救星
告别黑苹果配置噩梦:5大核心优势让开源工具OpCore-Simplify成为新手救星 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 黑苹果配置一直是…...

VLP-16数据包解析实战:从原始字节到三维点云
1. VLP-16数据包解析入门指南 第一次拿到VLP-16激光雷达的原始UDP数据流时,我完全被那一串串十六进制数字搞懵了。这就像收到一封用密码写成的信,明明知道里面藏着宝贵的三维环境信息,却不知道如何破译。经过几个项目的实战积累,我…...

Z-Image-GGUF小程序开发:微信小程序前端调用云端AI绘画API
Z-Image-GGUF小程序开发:微信小程序前端调用云端AI绘画API 最近在折腾AI绘画,发现一个挺有意思的事儿:很多厉害的模型都部署在云端服务器上,但咱们平时用手机的时间可比用电脑多多了。要是能在微信里随手打开一个小程序ÿ…...

Face Analysis WebUI体验:智能人脸检测的简单方法
Face Analysis WebUI体验:智能人脸检测的简单方法 1. 开箱即用的人脸分析工具 你是否曾经需要快速分析一张照片中的人脸信息,却被复杂的安装步骤和命令行操作劝退?Face Analysis WebUI正是为解决这个问题而生。这个基于InsightFace模型的可…...

构建自主海上防御系统:Mirai Robotics融资420万美元
Mirai Robotics已筹集420万美元的Pre-Seed轮资金,旨在构建自主和智能的海上系统。本轮融资由Primo Ventures、Techshop和40Jemz Ventures领投,并有来自意大利和国际的天使投资人参与。 海洋是地球上最关键的基础设施之一。全球超过80%的贸易通过海路运输…...