Spring三级缓存解决循环依赖问题
文章目录
- 1. 三级缓存解决的问题场景
- 2. 三级缓存的差异性
- 3. 循环依赖时的处理流程
- 4. 源码验证
1. 三级缓存解决的问题场景
循环依赖指的是在对象之间存在相互依赖关系,形成一个闭环,导致无法准确地完成对象的创建和初始化;当两个或多个对象彼此之间相互引用,而这种相互引用形成一个循环时,就可能出现循环依赖问题。
在早期的 Spring 版本中是可以自动解决的循环依赖的问题的,
public class A {@Autowiredprivate B b;
}public class B {@Autowiredprivate A a;
}
但要注意,Spring 解决循环依赖是有前提条件的,
🍂第一,要求互相依赖的 Bean 必须要是单例的 Bean。
- 这是因为对于原型范围的 Bean(prototype scope),每次请求都会创建一个新的 Bean 实例,这样每次尝试解析循环依赖时,都会产生新的 Bean 实例,导致无限循环,由于没有全局的、持续的单例实例的缓存来引用,因此循环依赖无法得到解决。
🍂第二,依赖注入的方式不能都是构造函数注入的方式。
- 当使用构造函数注入时,一个 Bean 的实例在构造函数被完全调用之前是不会被创建的;如果 Bean A 的构造函数依赖于 Bean B,而 Bean B 的构造函数又依赖于 Bean A,那么就会产生一个死锁的情况,因为两者都不能在对方初始化之前完成初始化。
public class C {private D d;@Autowiredpublic C(D d) {this.dService = dService;}
}public class D {private C c;@Autowiredpublic D(C c) {this.c = c;}
}
Spring 源码中关于三级缓存的定义如下:
// 一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
// 三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
所以说,所谓的“三级缓存”就是是指三个 Map 数据结构,分别用于存储不同状态的 Bean。
2. 三级缓存的差异性
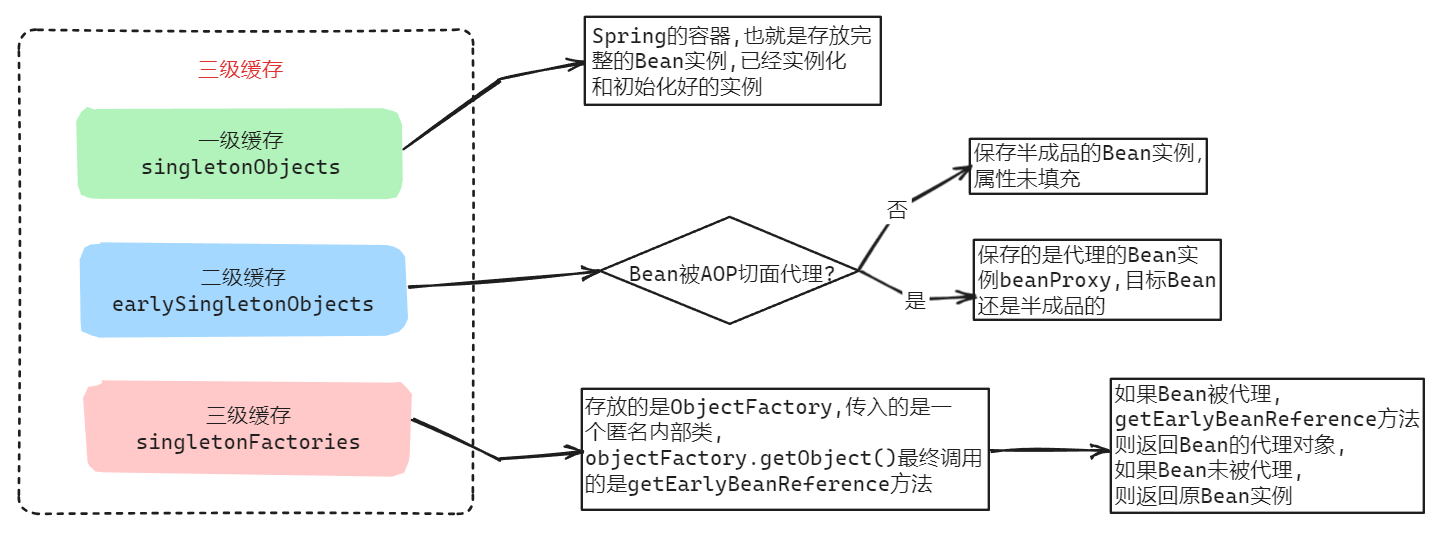
🎯一级缓存:
一级缓存保存的是已经完全初始化和实例化的 Bean 对象,在程序中使用的 Bean 通常就是从这个缓存中获取的;这个缓存的目的是确保 Bean 只初始化一次(是单例的),避免多次实例化相同的Bean对象,提高性能。
🎯二级缓存:
二级缓存用来解决 Bean 创建过程中的循环依赖问题,它存储的是尚未完成属性注入和初始化的“半成品”Bean 对象;当 Spring容器发现两个或多个 Bean 之间存在循环依赖时,也就是当一个 Bean 创建过程中需要引用另一个正在创建的 Bean,Spring 将创建需要的这些未完全初始化的对象提前暴露在二级缓存中,以便其他 Bean 进行引用,确保它们之间的依赖能够被满足。
🎯三级缓存:
三级缓存中存储的是 ObjectFactory<?> 类型的代理工厂对象,主要用于处理存在 AOP 时的循环依赖问题;每个 Bean 都对应一个 ObjectFactory 对象,通过调用该对象的 getObject 方法,可以获取到早期暴露出去的 Bean;在该 Bean 要被其他 Bean 引用时,Spring 就会用工厂对象创建出该 Bean 的实例对象,最终当该 Bean 完成构造的所有步骤后就会将该 Bean 放入到一级缓存中。
3. 循环依赖时的处理流程
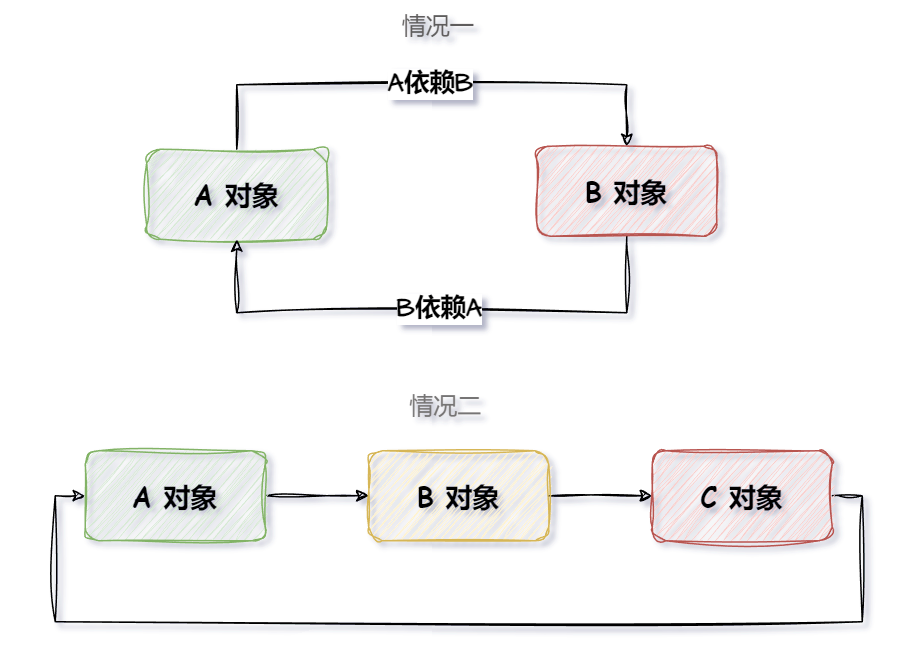
当 Spring 发生循环依赖时(以最开始介绍的场景为例,A B 两个 Bean 相互依赖),以下是完善的执行流程:
- 遍历待创建的所有 beanName:在容器启动时,Spring 会遍历所有需要创建的 Bean 名称,在第一次遍历到 A 时,就开始获取 Bean A;如果 Bean A 的实例不在一级、二级缓存中(缓存中没有值),Spring 会开始正常的 Bean 创建流程。
- Bean A 的创建:Bean A 的创建过程开始,然后 Spring 会检查是否 A 是单例(Singleton),同时 A 是否已经创建完成;如果 A 是单例且尚未创建完成,将 A 的 BeanFactory 存入三级缓存。
- 处理依赖注入:A 开始处理 @Autowired 注解,尝试注入 B 属性;Spring 会在一级、二级缓存中来查找 Bean B,如果找不到,则开始正常创建 Bean B 的流程。
- Bean B 的创建:Bean B 的创建过程类似于 A,首先判断B是否是单例,且是否已创建完成,如果否,B 的BeanFactory 也会被存入三级缓存。
- B 注入 A 属性:B 开始注入 A 属性,尝试从一级、二级缓存中查找 A;如果在缓存中找不到 A,B 会尝试从三级缓存获取 A 的 BeanFactory,并通过 BeanFactory的
getObject()方法获取 A 的属性,此时,A 被存入二级缓存,同时清除三级缓存;因此,B 能够成功注入 A 属性,B 接着执行初始化,处于实例化和初始化都已完成的完全状态。 - B 存入一级缓存:B执行
addSingleton(),将完全状态的 B 存入一级缓存,并清空二级,三级缓存。 - A 继续注入 B 属性:A 继续注入 B 属性,调用
beanFactory.getBean()方法获取 B,由于第六步已经将 B 存入一级缓存,A 可以直接获取 B,成功注入 B 属性, A 接着执行初始化,得到一个完全状态的 A。 - A 存入一级缓存:A 执行
addSingleton(),将完全状态的 A 存入一级缓存,并清空二级缓存。
此时,A 和 B 都被实例化和初始化完成,解决了循环依赖的问题;这个流程确保了每个Bean在需要时都能够获取到已完全初始化的依赖项。
🚀常见疑问解答
问题一:为什么在 Bean B 被注入 Bean A 之前,需要将 Bean A 存入二级缓存?
- 主要原因是,如果存在其他循环依赖需要用到 A,从二级缓存中直接取出早期的 Bean A 对象会更加高效。
问题二:为什么创建完 Bean 后要清空二、三级缓存?
- 清空是为了节省存储空间,一旦 Bean 完全初始化并存储在一级缓存中,其在二、三级缓存中的记录就不再需要了。
问题三:三级缓存为什么不能解决构造器引起的循环依赖?
- 这是因为构造器引起的循环依赖发生在 Bean 的实例化阶段,这个阶段比二、三级缓存处理的阶段还要早,无法创建出早期的半成品对象。
问题四:如果不使用三级缓存,只使用二级缓存,能否解决循环依赖?
肯定是不能的,二级缓存存储的 Bean 可能是两种类型,一种是实例化阶段创建出来的对象,另一种是实例化阶段创建出来的对象的代理对象;是否需要代理对象取决于你的配置需要,如是否添加了事务注解或自定义 AOP 切面;如果放弃使用三级缓存,即没有 ObjectFactory,那么就需要将早期的 Bean 放入二级缓存;但问题是,应该将未被代理的 Bean 还是代理的 Bean 放入二级缓存,这只能在属性注入阶段,处理注解时才能分辨。
- 如果直接往二级缓存添加没有被代理的 Bean,那么此时注入给其它对象的 Bean 可能跟最后完全生成的 Bean 是不一样的,因为最后生成使用的是可能代理对象,此时注入的是原始对象,这这种情况是不允许发生的。
- 如果直接往二级缓存添加一个代理 Bean,在不确定是否要使用代理对象的情况下,就有提前暴露代理对象的可能;正常的代理的对象都是初始化后期调用生成的,是基于后置处理器的,若提早的代理就违背了 Bean 定义的生命周期。
Spring 在一个三级缓存放置一个工厂,如果产生循环依赖 ,这个工厂的作用就是判断这个对象是否需要代理,如果否则直接返回,如果是则返回代理对像。
4. 源码验证
在项目中双击 Shift,全局查找文件:AbstractAutowireCapableBeanFactory,找到 550 行左右的 doCreateBean 方法,重点看一下 580 行到 600 行这20行代码就行,包含了三级缓存、属性注入、初始化,精华都在这20行,下面在源码中给出了关键注释。
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)throws BeanCreationException {// Instantiate the bean.BeanWrapper instanceWrapper = null;if (mbd.isSingleton()) {instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);}// 通过BeanDefinition实例化对象if (instanceWrapper == null) {instanceWrapper = createBeanInstance(beanName, mbd, args);}Object bean = instanceWrapper.getWrappedInstance();Class<?> beanType = instanceWrapper.getWrappedClass();if (beanType != NullBean.class) {mbd.resolvedTargetType = beanType;}// Allow post-processors to modify the merged bean definition.synchronized (mbd.postProcessingLock) {if (!mbd.postProcessed) {try {applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);}catch (Throwable ex) {throw new BeanCreationException(mbd.getResourceDescription(), beanName,"Post-processing of merged bean definition failed", ex);}mbd.postProcessed = true;}}// Eagerly cache singletons to be able to resolve circular references// even when triggered by lifecycle interfaces like BeanFactoryAware.// 对象是否单例、是否未创建完成boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&isSingletonCurrentlyInCreation(beanName));if (earlySingletonExposure) {if (logger.isTraceEnabled()) {logger.trace("Eagerly caching bean '" + beanName +"' to allow for resolving potential circular references");}// 将对象的工厂加入到三级缓存addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));}// Initialize the bean instance.Object exposedObject = bean;try {// 属性注入 (在这里解析@Autowired注解时,触发循环依赖)populateBean(beanName, mbd, instanceWrapper);// 初始化exposedObject = initializeBean(beanName, exposedObject, mbd);}catch (Throwable ex) {if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {throw (BeanCreationException) ex;}else {throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);}}if (earlySingletonExposure) {// 从缓存中获取 BeanObject earlySingletonReference = getSingleton(beanName, false);if (earlySingletonReference != null) {if (exposedObject == bean) {exposedObject = earlySingletonReference;}else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {String[] dependentBeans = getDependentBeans(beanName);Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);for (String dependentBean : dependentBeans) {if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {actualDependentBeans.add(dependentBean);}}if (!actualDependentBeans.isEmpty()) {throw new BeanCurrentlyInCreationException(beanName,"Bean with name '" + beanName + "' has been injected into other beans [" +StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +"] in its raw version as part of a circular reference, but has eventually been " +"wrapped. This means that said other beans do not use the final version of the " +"bean. This is often the result of over-eager type matching - consider using " +"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");}}}}// Register bean as disposable.try {registerDisposableBeanIfNecessary(beanName, bean, mbd);}catch (BeanDefinitionValidationException ex) {throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);}return exposedObject;
}
从缓存中获取 Bean 的源码
protected Object getSingleton(String beanName, boolean allowEarlyReference) {// Quick check for existing instance without full singleton lockObject singletonObject = this.singletonObjects.get(beanName);// 从一级缓存中获取// 如果一级缓存里没有,且 Bean 正在创建中// 就从二级缓存里获取if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {singletonObject = this.earlySingletonObjects.get(beanName);// 二级缓存没有,就从三级缓存获取一个工厂if (singletonObject == null && allowEarlyReference) {synchronized (this.singletonObjects) {// Consistent creation of early reference within full sinsingletonObject = this.singletonObjects.get(beanName);if (singletonObject == null) {singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null) {ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {// 能获取到工厂则创建 BeansingletonObject = singletonFactory.getObject();// 把实例存入二级缓存this.earlySingletonObjects.put(beanName, singletonObject);// 把工厂从三级缓存移除this.singletonFactories.remove(beanName);}}}}}}return singletonObject;
}
总之,Spring 的三级缓存机制是一个巧妙的设计,它解决了在 Bean 初始化过程中可能出现的循环依赖问题;对于 Spring 的用户来说,这意味着更加稳定和可靠的 Bean 管理和依赖注入机制。
相关文章:
Spring三级缓存解决循环依赖问题
文章目录 1. 三级缓存解决的问题场景2. 三级缓存的差异性3. 循环依赖时的处理流程4. 源码验证 1. 三级缓存解决的问题场景 循环依赖指的是在对象之间存在相互依赖关系,形成一个闭环,导致无法准确地完成对象的创建和初始化;当两个或多个对象彼…...
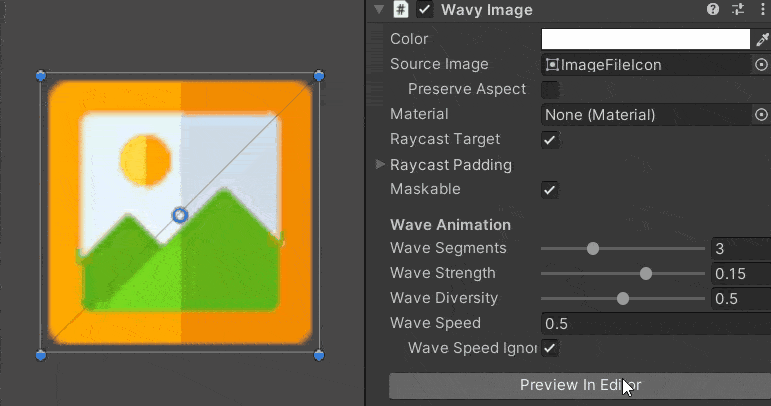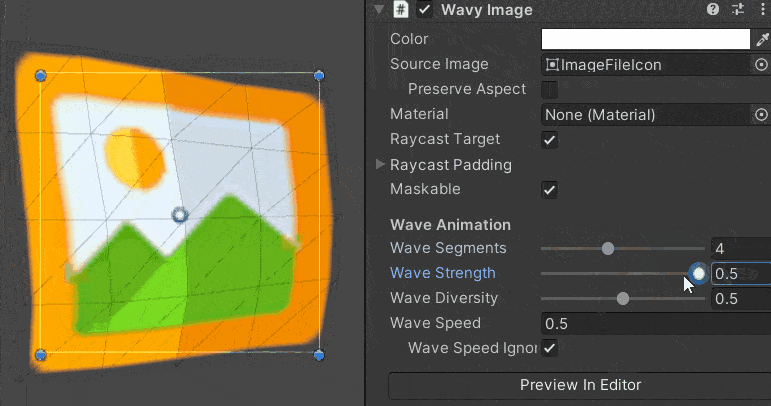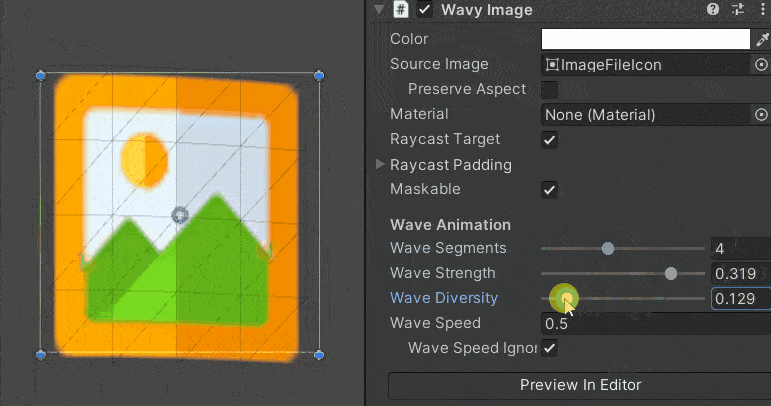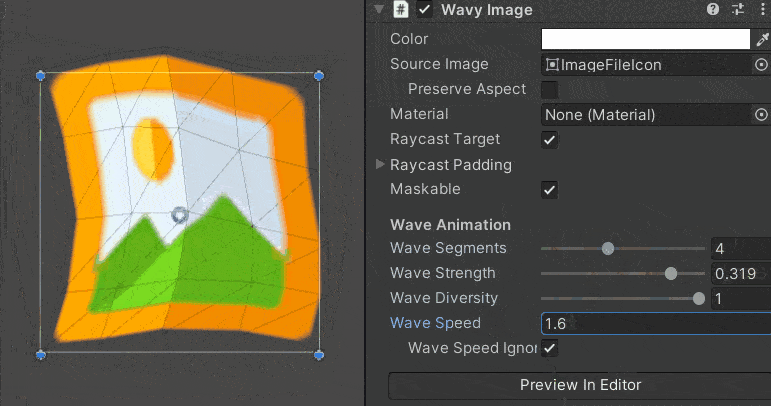
Unity 中使用波浪动画创建 UI 图像
如何使用 只需将此组件添加到画布中的空对象即可。强烈建议您将此对象放入其自己的画布/嵌套画布中,因为它会弄脏每一帧的画布并导致重新生成整个网格。 注意:不支持切片图像。 using System.Collections.Generic; using UnityEngine; using UnityEng…...

支付功能测试用例测试点?
支付功能测试用例测试点是指在测试支付功能时,需要关注和验证的各个方面。根据不同的支付场景和需求,支付功能测试用例测试点可能有所不同,但一般可以分为以下几类: 功能测试:主要检查支付功能是否符合设计和业务需求…...
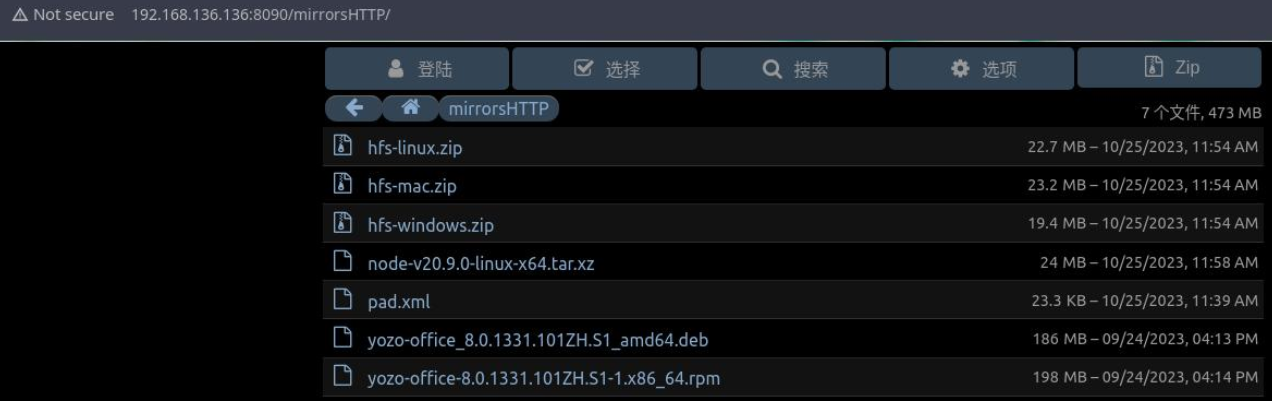
HFS 快速搭建 http 服务器
HFS 是一个轻量级的HTTP 服务工具,3.0版本前进提供Windows平台安装包,3.0版本开提供Linux和macOS平台的安装包。 HFS更适合在局域网环境中搭建文件共享服务或者安装配置源服务器。 甲 非守护进程的方式运行 HFS (Ubuntu 22.04) 一…...

学生专用台灯怎么选?双十一专业学生护眼台灯推荐
台灯应该是很多家庭都会备上一盏的家用灯具,很多大人平时间看书、用电脑都会用上它,不过更多的可能还是给家中的小孩学习、阅读使用的。而且现在的孩子近视率如此之高,这让家长们不得不重视孩子的视力健康问题。那么孩子学习使用的台灯应该怎…...

Go 常用标准库之 fmt 介绍与基本使用
Go 常用标准库之 fmt 介绍与基本使用 文章目录 Go 常用标准库之 fmt 介绍与基本使用一、介绍二、向外输出2.1 Print 系列2.2 Fprint 系列2.3 Sprint 系列2.4 Errorf 系列 三、格式化占位符3.1 通用占位符3.2 布尔型3.3 整型3.4 浮点数与复数3.5 字符串和[]byte3.6 指针3.7 宽度…...

antv/x6 导出图片方法exportPNG
antv/x6 导出图片方法exportPNG antv/x6 版本如下: "antv/x6": "2.14.1","antv/x6-plugin-export": "2.1.6",在文件中导入 import { Graph, Shape, StringExt } from antv/x6 import { Export } from antv/x6-plugin-exp…...
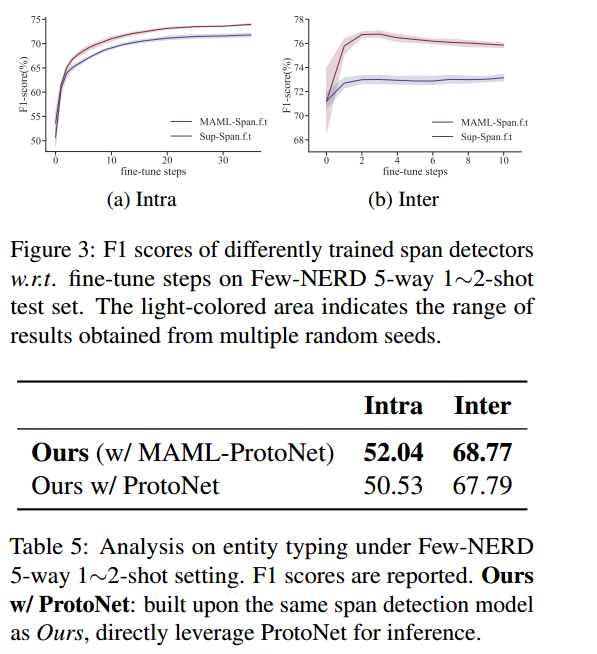
Decomposed Meta-Learning for Few-Shot Named Entity Recognition
原文链接: https://aclanthology.org/2022.findings-acl.124.pdf ACL 2022 介绍 问题 目前基于span的跨度量学习(metric learning)的方法存在一些问题: 1)由于是通过枚举来生成span,因此在解码的时候需要额…...

C++经典面试题:内存泄露是什么?如何排查?
1.内存泄露的定义:内存泄漏简单的说就是申请了⼀块内存空间,使⽤完毕后没有释放掉。 它的⼀般表现⽅式是程序运⾏时间越⻓,占⽤内存越多,最终⽤尽全部内存,整个系统崩溃。由程序申请的⼀块内存,且没有任何⼀…...
Hadoop+Hive+Spark+Hbase开发环境练习
1.练习一 1.数据准备 在hdfs上创建文件夹,上传csv文件 [rootkb129 ~]# hdfs dfs -mkdir -p /app/data/exam 查看csv文件行数 [rootkb129 ~]# hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l 2.分别使用 RDD和 Spark SQL 完成以下分析…...
使用Spring Boot限制在一分钟内某个IP只能访问10次
有些时候,为了防止我们上线的网站被攻击,或者被刷取流量,我们会对某一个ip进行限制处理,这篇文章,我们将通过Spring Boot编写一个小案例,来实现在一分钟内同一个IP只能访问10次,当然具体数值&am…...
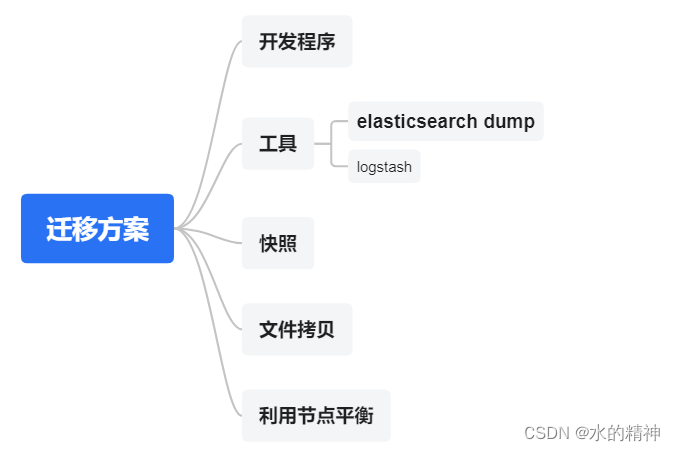
ES 数据迁移最佳实践
ES 数据迁移最佳实践与讲解 数据迁移是 Elasticsearch 运维管理和业务需求中常见的操作之一。以下是不同数据迁移方法的最佳实践和讲解: 一、数据迁移需求梳理 二、数据迁移方法梳理 三、各方案对比 方案 优点 缺点(限制) 适用场景 是否有…...

C++中低级内存操作
C中低级内存操作 C相较于C有一个巨大的优势,那就是你不需要过多地担心内存管理。如果你使用面向对象的编程方式,你只需要确保每个独立的类都能妥善地管理自己的内存。通过构造和析构,编译器会帮助你管理内存,告诉你什么时候需要进…...
)
Linux硬盘大小查看命令全解析 (linux查看硬盘大小命令)
Linux操作系统是一款广泛应用于服务器和嵌入式设备的操作系统,相比于Windows等其他操作系统,Linux的优点之一就是支持强大的命令行操作。在日常操作中,了解和掌握一些简单但实用的命令可以提高工作效率。比如硬盘大小查看命令,在L…...

什么是供应链金融?
一、供应链金融产生背景 供应链金融兴起的起源来自于供应链管理一个产品生产过程分为三个阶段:原材料 - 中间产品 - 成产品。由于技术进步需求升级,生产过程从以前的企业内分工,转变为企业间分工。那么整个过程演变了如今的供应链管理流程&a…...
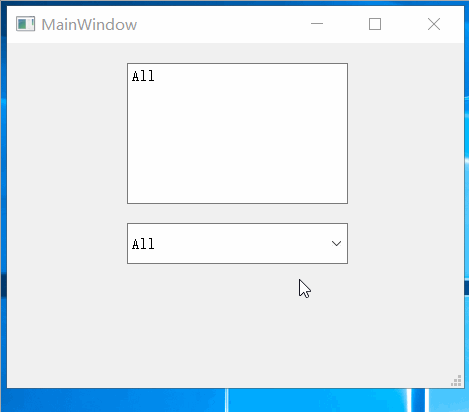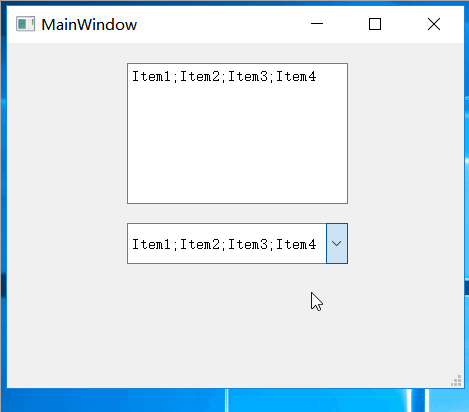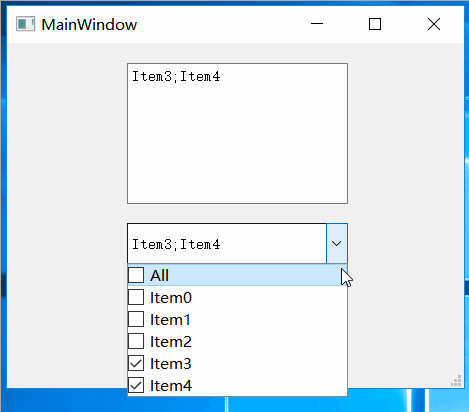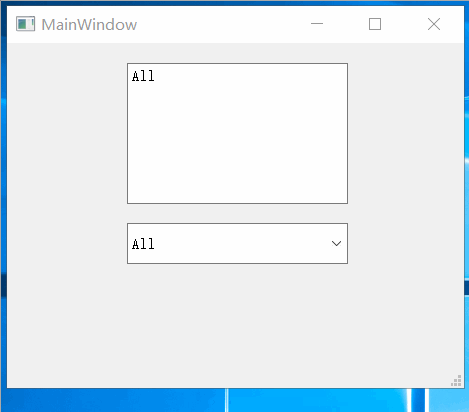
Qt之实现支持多选的QCombobox
一.效果 1.点击下拉列表的复选框区域 2.点击下拉列表的非复选框区域 二.实现 QHCustomComboBox.h #ifndef QHCUSTOMCOMBOBOX_H #define QHCUSTOMCOMBOBOX_H#include <QLineEdit> #include <QListWidget> #include <QCheckBox> #include <QComboBox>…...

【UI设计】Figma_“全面”快捷键
目录 1.快捷键与键位(mac与windows)2.基础快捷键3.操作区快捷键3.1视图3.2文字3.3选项3.4图层3.5组件 4.特殊技巧 Figma 是一个 基于浏览器 的协作式 UI 设计工具。【https://www.figma.com/】 Figma Sketch(UI 设计) InVision&a…...

计算机网络(谢希仁)第八版课后题答案(第一章)
1.计算机网络可以向用户提供哪些服务 连通性:计算机网络使上网用户之间可以交换信息,好像这些用户的计算机都可以彼此直接连通一样。 共享:指资源共享。可以是信息、软件,也可以是硬件共享。 2.试简述分组交换的要点 采用了存储转发技术。把报文(要发…...

argparse模块介绍
argparse是一个Python模块:命令行选项、参数和子命令解析器。argparse 模块可以让人轻松编写用户友好的命令行接口。程序定义了所需的参数,而 argparse 将找出如何从 sys.argv (命令行)中解析这些参数。argparse 模块还会自动生成…...

分布式、集群、微服务
分布式是以缩短单个任务的执行时间来提升效率的;而集群则是通过提高单位时间内执行的任务数来提升效率。 分布式是指将不同的业务分布在不同的地方。 集群指的是将几台服务器集中在一起,实现同一业务。 分布式中的每一个节点,都可以做集群…...
—— 原理详解、代码实现与性能验证)
超越极限:YOLOv8融合Dynamic Head(统一尺度-空间-任务感知注意力)—— 原理详解、代码实现与性能验证
引言 在目标检测领域,YOLO系列模型凭借其出色的速度与精度平衡,始终占据着举足轻重的地位。YOLOv8作为Ultralytics团队的最新力作,在架构设计、训练策略和部署便捷性上均达到了新的高度。然而,随着应用场景的日益复杂,如何让模型在多尺度变化、空间遮挡、任务干扰等挑战下…...

NaViL-9B效果展示:电商主图自动提取卖点文案+竞品对比分析
NaViL-9B效果展示:电商主图自动提取卖点文案竞品对比分析 1. 多模态大模型惊艳登场 想象一下,当你上传一张商品图片,AI不仅能准确识别图片内容,还能自动生成吸引人的卖点文案——这就是NaViL-9B带来的革命性体验。作为原生多模态…...

如何安全高效地管理Cookie:Get cookies.txt LOCALLY本地处理终极实践指南
如何安全高效地管理Cookie:Get cookies.txt LOCALLY本地处理终极实践指南 【免费下载链接】Get-cookies.txt-LOCALLY Get cookies.txt, NEVER send information outside. 项目地址: https://gitcode.com/gh_mirrors/ge/Get-cookies.txt-LOCALLY 在数字时代&a…...

维普AIGC检测降AI率全流程攻略:从70%降到10%以下实操分享
维普AIGC检测降AI率全流程攻略:从70%降到10%以下实操分享 说一个最近碰到的真事。我们实验室一个师弟,论文用维普查了AIGC检测,结果出来AI率72.4%。他当场就懵了——因为他确实有用AI辅助写了一些段落,但自认为改了挺多的…...

League Akari:英雄联盟玩家的智能效率工具集,从自动秒选到战绩分析的全能助手
League Akari:英雄联盟玩家的智能效率工具集,从自动秒选到战绩分析的全能助手 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/L…...

Python开发环境快速搭建:Miniconda-Python3.9镜像实战体验
Python开发环境快速搭建:Miniconda-Python3.9镜像实战体验 1. 为什么选择Miniconda-Python3.9 Python作为当今最流行的编程语言之一,在数据科学、机器学习、Web开发等领域有着广泛应用。然而,Python环境管理一直是开发者面临的挑战之一。Mi…...

告别混乱:我是如何用Hugo + GitHub Actions实现博客自动化构建与发布的
告别混乱:我是如何用Hugo GitHub Actions实现博客自动化构建与发布的 去年我的博客还处于"石器时代"——每次写完文章都要手动执行hugo build,再把public文件夹里的文件拖到服务器。直到某天连续三次忘记更新CNAME文件导致域名解析失败&#…...

RWKV7-1.5B-g1a镜像优势解析:离线加载兼容+软链修复+日志分级排查设计
RWKV7-1.5B-g1a镜像优势解析:离线加载兼容软链修复日志分级排查设计 1. 平台简介与核心能力 rwkv7-1.5B-g1a是基于新一代RWKV-7架构的多语言文本生成模型,专为轻量级应用场景优化设计。该镜像经过工程化改造,在保持原模型优秀生成能力的同时…...

基于springboot框架个性化旅游线路推荐系统 景区门票 酒店 预订88u7sgf 有论文-idea maven vue
目录系统架构设计技术选型与工具数据库设计核心功能实现论文研究要点开发计划安排项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作系统架构设计 采用前后端分离架构,后端基于SpringBoot框架,前端使用Vue…...

手把手教你用STM32CubeMX配置LCD1602显示:HAL库驱动移植+Proteus 8.12仿真
STM32CubeMX与Proteus联合开发:LCD1602显示实战指南 在嵌入式开发领域,STM32CubeMX和Proteus的组合为开发者提供了从硬件配置到软件仿真的完整解决方案。本文将深入探讨如何利用这两个工具链实现LCD1602液晶显示屏的驱动与显示功能,特别针对从…...