【机器学习合集】人脸表情分类任务Pytorch实现TensorBoardX的使用 ->(个人学习记录笔记)
人脸表情分类任务
- 注意:整个项目来自阿里云天池,下面是开发人员的联系方式,本人仅作为学习记录!!!
- 该文章原因,学习该项目,完善注释内容,针对新版本的Pytorch进行部分代码调整
- 本文章采用pytorch2.0.1版本,python3.10版本
源码链接
这是一个使用pytorch实现的简单的2分类任务
项目结构:- net.py: 网络定义脚本- train.py:模型训练脚本- inference.py:模型推理脚本- run_train.sh 训练可执行文件- run_inference.sh 推理可执行文件# Copyright 2019 longpeng2008. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# If you find any problem,please contact us longpeng2008to2012@gmail.com
1. 网络结构
# coding:utf8import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np# 3层卷积神经网络simpleconv3定义
# 包括3个卷积层,3个BN层,3个ReLU激活层,3个全连接层class simpleconv3(nn.Module):# 初始化函数def __init__(self, nclass):# 继承父类super(simpleconv3, self).__init__()# 3通道 输入图片大小为3*48*48,输出特征图大小为12*23*23,卷积核大小为3*3,步长为2'''输出特征图大小 = [(输入大小 - 卷积核大小) / 步长] + 1输入大小是 48x48卷积核大小是 3x3步长是 2将这些值代入公式,您将得到输出特征图的大小:输出特征图大小 = [(48 - 3) / 2] + 1 = (45 / 2) + 1 = 22.5 + 1 = 23'''self.conv1 = nn.Conv2d(3, 12, 3, 2)# 批量标准化操作 12个特征通道self.bn1 = nn.BatchNorm2d(12)# 输入图片大小为12*23*23,输出特征图大小为24*11*11,卷积核大小为3*3,步长为2'''输出特征图大小 = [(输入大小 - 卷积核大小) / 步长] + 1输入大小是 23x23卷积核大小是 3x3步长是 2将这些值代入公式,您将得到输出特征图的大小:输出特征图大小 = [(23 - 3) / 2] + 1 = (20 / 2) + 1 = 10 + 1 = 11'''self.conv2 = nn.Conv2d(12, 24, 3, 2)# 批量标准化操作 24个特征通道self.bn2 = nn.BatchNorm2d(24)# 输入图片大小为24*11*11,输出特征图大小为48*5*5,卷积核大小为3*3,步长为2'''输出特征图大小 = [(输入大小 - 卷积核大小) / 步长] + 1输入大小是 11x11卷积核大小是 3x3步长是 2将这些值代入公式,您将得到输出特征图的大小:输出特征图大小 = [(11 - 3) / 2] + 1 = (8 / 2) + 1 = 4 + 1 = 5'''self.conv3 = nn.Conv2d(24, 48, 3, 2)# 批量标准化操作 48个特征通道self.bn3 = nn.BatchNorm2d(48)# 输入向量长为48*5*5=1200,输出向量长为1200 展平self.fc1 = nn.Linear(48 * 5 * 5, 1200)# 1200 -> 128self.fc2 = nn.Linear(1200, 128) # 输入向量长为1200,输出向量长为128# 128 -> 类别数self.fc3 = nn.Linear(128, nclass) # 输入向量长为128,输出向量长为nclass,等于类别数# 前向函数def forward(self, x):# relu函数,不需要进行实例化,直接进行调用# conv,fc层需要调用nn.Module进行实例化# 先卷积后标准化再激活x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = F.relu(self.bn3(self.conv3(x)))# 更改形状 改为1维x = x.view(-1, 48 * 5 * 5)# 全连接再激活x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xif __name__ == '__main__':import torchx = torch.randn(1, 3, 48, 48)model = simpleconv3(2)y = model(x)print(model)'''simpleconv3((conv1): Conv2d(3, 12, kernel_size=(3, 3), stride=(2, 2))(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(12, 24, kernel_size=(3, 3), stride=(2, 2))(bn2): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(24, 48, kernel_size=(3, 3), stride=(2, 2))(bn3): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(fc1): Linear(in_features=1200, out_features=1200, bias=True)(fc2): Linear(in_features=1200, out_features=128, bias=True)(fc3): Linear(in_features=128, out_features=2, bias=True))'''
2. 训练函数
部分代码内容与作者不同
- scheduler.step()与optimizer.step()修改前后顺序
- RandomSizedCrop改为RandomCrop
- transforms.Scale修改为transforms.Resize
# coding:utf8
from __future__ import print_function, division
import os
import torch
import torch.nn as nn
import torch.optim as optim
# 使用tensorboardX进行可视化
from tensorboardX import SummaryWriter
from torch.optim import lr_scheduler
from torchvision import datasets, transformsfrom net import simpleconv3writer = SummaryWriter('logs') # 创建一个SummaryWriter的示例,默认目录名字为runs# 训练主函数
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):"""训练模型Args:model: 模型criterion: loss函数optimizer: 优化器scheduler: 学习率调度器num_epochs: 训练轮次Returns:"""# 开始训练for epoch in range(num_epochs):# 打印训练轮次print(f'Epoch {epoch+1}/{num_epochs}')for phase in ['train', 'val']:if phase == 'train':# 设置为训练模式model.train(True)else:# 设置为验证模式model.train(False)# 损失变量running_loss = 0.0# 精度变量running_accs = 0.0number_batch = 0# 从dataloaders中获得数据for data in dataloaders[phase]:inputs, labels = dataif use_gpu:inputs = inputs.cuda()labels = labels.cuda()# 清空梯度optimizer.zero_grad()# 前向运行outputs = model(inputs)# 使用max()函数对输出值进行操作,得到预测值索引_, preds = torch.max(outputs.data, 1)# 计算损失loss = criterion(outputs, labels)if phase == 'train':# 误差反向传播loss.backward()# 参数更新optimizer.step()running_loss += loss.data.item()running_accs += torch.sum(preds == labels).item()number_batch += 1# 调整学习率scheduler.step()# 得到每一个epoch的平均损失与精度epoch_loss = running_loss / number_batchepoch_acc = running_accs / dataset_sizes[phase]# 收集精度和损失用于可视化if phase == 'train':writer.add_scalar('data/trainloss', epoch_loss, epoch)writer.add_scalar('data/trainacc', epoch_acc, epoch)else:writer.add_scalar('data/valloss', epoch_loss, epoch)writer.add_scalar('data/valacc', epoch_acc, epoch)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))writer.close()return modelif __name__ == '__main__':# 图像统一缩放大小image_size = 60# 图像裁剪大小,即训练输入大小crop_size = 48# 分类类别数nclass = 2# 创建模型model = simpleconv3(nclass)# 数据目录data_dir = './data'# 模型缓存接口if not os.path.exists('models'):os.mkdir('models')# 检查GPU是否可用,如果是使用GPU,否使用CPUuse_gpu = torch.cuda.is_available()if use_gpu:model = model.cuda()print(model)# 创建数据预处理函数,训练预处理包括随机裁剪缩放、随机翻转、归一化,验证预处理包括中心裁剪,归一化data_transforms = {'train': transforms.Compose([transforms.RandomCrop(48), # 随机大小、长宽比裁剪图片size=48 RandomSizedCrop改为RandomCroptransforms.RandomHorizontalFlip(), # 随机水平翻转 默认概率p=0.5transforms.ToTensor(), # 将原始的PILImage格式或者numpy.array格式的数据格式化为可被pytorch快速处理的张量类型transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 数据标准化 要将图像三个通道的数据 整理到 [-1,1] 之间 ,可以加快模型的收敛]),'val': transforms.Compose([transforms.Resize(64), # Scale用于调整图像的大小,现在采用transforms.Resize()代替transforms.CenterCrop(48), # 从图像中心裁剪图片尺寸size=48transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),}# 使用torchvision的dataset ImageFolder接口读取数据image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}# 创建数据指针,设置batch大小,shuffle,多进程数量dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x],batch_size=16, # 每个小批次包含16个样本shuffle=True, # 是否随机打乱数据num_workers=4) # 加载数据的子进程数for x in ['train', 'val']}# 获得数据集大小dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}# 优化目标使用交叉熵,优化方法使用带动量项的SGD,学习率迭代策略为step,每隔100个epoch,变为原来的0.1倍criterion = nn.CrossEntropyLoss()# 优化器 传入权重阈值,学习率0.1 动量(momentum)是一个控制梯度下降方向的超参数。# 它有助于加速训练,特别是在存在平坦区域或局部极小值时。动量的值通常在0到1之间。较大的动量值会使参数更新更平滑。在这里,动量设置为0.9。optimizer_ft = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)'''lr_scheduler.StepLR 是PyTorch中的学习率调度器(learning rate scheduler),用于在训练神经网络时动态调整学习率。lr_scheduler.StepLR 允许您在训练的不同阶段逐步减小学习率,以帮助优化过程。optimizer_ft:这是您用于优化模型参数的优化器,通常是 optim.SGD 或其他PyTorch优化器的实例。学习率调度器将监控这个优化器的状态,并根据其规则更新学习率。step_size=100:这是学习率更新的周期,也称为学习率下降步数。在每个 step_size 个训练周期之后,学习率将减小。gamma=0.1:这是学习率减小的因子。在每个 step_size 个训练周期之后,学习率将乘以 gamma。这意味着学习率将以 gamma 的倍数逐步减小。'''exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=100, gamma=0.1)model = train_model(model=model,criterion=criterion,optimizer=optimizer_ft,scheduler=exp_lr_scheduler,num_epochs=10)torch.save(model.state_dict(), 'models/model.pt')
3. 预测
执行以下内容,或者自行安排数据集
## 使用方法 python3 inference.py 模型路径 图片路径
python3 inference.py models/model.pt data/train/0/1neutral.jpg
python3 inference.py models/model.pt data/train/1/1smile.jpg
# coding:utf8import sys
import numpy as np
import torch
from PIL import Image
from torchvision import transforms# 全局变量
# sys.argv[1] 权重文件
# sys.argv[2] 图像文件夹testsize = 48 # 测试图大小
from net import simpleconv3# 定义模型
net = simpleconv3(2)
# 设置推理模式,使得dropout和batchnorm等网络层在train和val模式间切换
net.eval()
# 停止autograd模块的工作,以起到加速和节省显存
torch.no_grad()# 载入模型权重
modelpath = sys.argv[1]
net.load_state_dict(torch.load(modelpath, map_location=lambda storage, loc: storage))# 定义预处理函数
data_transforms = transforms.Compose([transforms.Resize(48),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])# 读取3通道图片,并扩充为4通道tensor
imagepath = sys.argv[2]
image = Image.open(imagepath)
imgblob = data_transforms(image).unsqueeze(0)# 获得预测结果predict,得到预测的标签值label
predict = net(imgblob)
index = np.argmax(predict.detach().numpy())
# print(predict)
# print(index)if index == 0:print('the predict of ' + sys.argv[2] + ' is ' + str('none'))
else:print('the predict of ' + sys.argv[2] + ' is ' + str('smile'))
4. TensorBoardX的使用
TensorBoardX 是一个用于在 PyTorch 中可视化训练过程和结果的工具。它是 TensorBoard 的 Python 版本,用于创建交互式、实时的训练和评估图表。以下是一些使用 TensorBoardX 的一般步骤:
-
安装 TensorBoardX:首先,您需要安装 TensorBoardX 库。您可以使用以下命令安装它:
pip install tensorboardX -
导入库:在您的 PyTorch 代码中,导入 TensorBoardX 库:
from tensorboardX import SummaryWriter -
创建 SummaryWriter:创建一个
SummaryWriter对象,以将日志数据写入 TensorBoard 日志目录。writer = SummaryWriter() -
记录数据:在训练循环中,使用
writer.add_*方法来记录各种数据,例如标量、图像、直方图等。以下是一些示例:-
记录标量数据:
writer.add_scalar('loss', loss, global_step) -
记录图像数据:
writer.add_image('image', image, global_step) -
记录直方图数据:
writer.add_histogram('weights', model.conv1.weight, global_step) -
记录文本数据:
writer.add_text('description', 'This is a description.', global_step)
-
-
启动 TensorBoard 服务器:在命令行中,使用以下命令启动 TensorBoard 服务器:
tensorboard --logdir=/path/to/log/directory其中
/path/to/log/directory是存储 TensorBoardX 日志的目录。 -
查看可视化结果:在浏览器中打开 TensorBoard 的 Web 界面,通常位于
http://localhost:6006,您可以在该界面上查看可视化结果。
请注意,您可以根据需要记录不同类型的数据,并根据训练过程的不同阶段定期记录数据。TensorBoardX 提供了丰富的可视化工具,以帮助您监视和分析模型的训练过程。
确保在训练循环中适时记录数据,并使用 TensorBoardX 查看结果,以更好地理解和改进您的深度学习模型。
这是 TensorBoard 启动时的一般信息,表明TensorBoard运行在本地主机(localhost)。如果您想使 TensorBoard 可以在网络上访问,可以采取以下几种方法:
-
使用代理:您可以使用代理服务器来将 TensorBoard 的端口暴露到网络上。这通常需要在代理服务器上进行一些配置,以便外部用户可以访问 TensorBoard。代理服务器可以是诸如 Nginx 或 Apache 之类的 Web 服务器。
-
使用 --bind_all 参数:在启动 TensorBoard 时,您可以使用
--bind_all参数,以将 TensorBoard 绑定到所有网络接口。这样,TensorBoard 将可以在本地网络上的任何 IP 地址上访问,而不仅仅是本地主机。例如:tensorboard --logdir=/path/to/log/directory --bind_all -
使用 --host 参数:您还可以使用
--host参数来指定 TensorBoard 的主机名(hostname),以使其在指定的主机上可用。例如:tensorboard --logdir=/path/to/log/directory --host=0.0.0.0这将允许 TensorBoard 在所有网络接口上运行,从而在网络上的任何 IP 地址上访问。
请根据您的需求和网络设置选择适当的方法。如果只需要在本地访问 TensorBoard,无需进行任何更改。如果需要在网络上访问,可以使用上述选项之一。不过,请注意,为了安全起见,最好将 TensorBoard 限制在受信任的网络上,或者使用身份验证和授权来保护访问。
效果展示
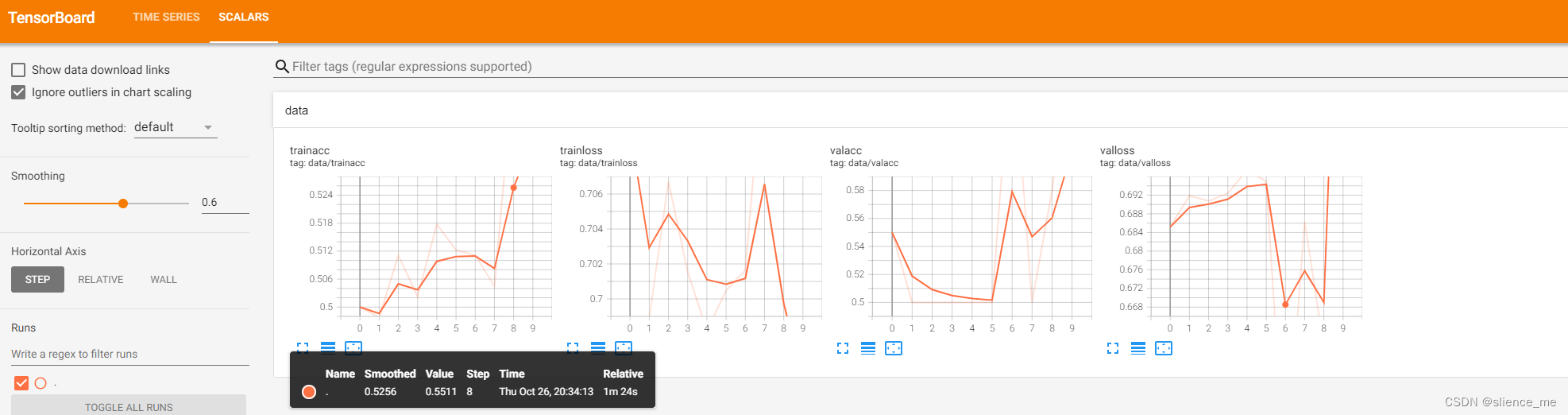
相关文章:
【机器学习合集】人脸表情分类任务Pytorch实现TensorBoardX的使用 ->(个人学习记录笔记)
人脸表情分类任务 注意:整个项目来自阿里云天池,下面是开发人员的联系方式,本人仅作为学习记录!!!该文章原因,学习该项目,完善注释内容,针对新版本的Pytorch进行部分代码…...
)
Maven - 国内 Maven 镜像仓库(加速包,冲冲冲~)
<?xml version"1.0" encoding"UTF-8" ?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding…...
【Solidity】智能合约案例——③版权保护合约
目录 一、合约源码分析: 二、合约整体流程: 1.部署合约: 2.添加实体: 3.查询实体 4.审核版权: 5.版权转让 一、合约源码分析: Copyright.sol:主合约,定义了版权局的实体ÿ…...

Cisco IOS XE Web UI 命令执行漏洞
Cisco IOS XE Web UI 命令执行漏洞 受影响版本 Cisco IOS XE全版本 漏洞描述 Cisco IOS XE Web UI 是一种基于GUI的嵌入式系统管理工具,能够提供系统配置、简化系统部署和可管理性以及增强用户体验。它带有默认映像,因此无需在系统上启用任何内容或安…...

qwen大模型,推理速度慢,单卡/双卡速度慢,flash-attention安装,解决方案
场景 阿里的通义千问qwen大模型,推理速度慢,单卡/双卡速度慢。 详细: 1、今日在使用qwen-14b的float16版本进行推理(BF16/FP16) 1.1 在qwen-14b-int4也会有同样的现象 2、使用3090 24G显卡两张 3、模型加载的device是auto&#x…...

3.SpringSecurity基于数据库的认证与授权
文章目录 SpringSecurity基于数据库的认证与授权一、自定义用户信息UserDetails1.1 新建用户信息类UserDetails1.2 UserDetailsService 二、基于数据库的认证2.1 连接数据库2.2 获取用户信息2.2.1 获取用户实体类2.2.2 Mapper2.2.3 Service 2.3 认证2.3.1 实现UserDetails接口2…...
【软件测试】自动化测试selenium
目录 一、什么是自动化测试 二、Selenium介绍 1、Selenium是什么 2、Selenium的原理 三、了解Selenium的常用API 1、webDriver API 1.1、元素定位 1.1.1、CSS选择器 1.1.2、Xpath元素定位 1.1.3、面试题 1.2、操作测试对象 1.3、添加等待 1.4、打印信息 1.5、浏…...
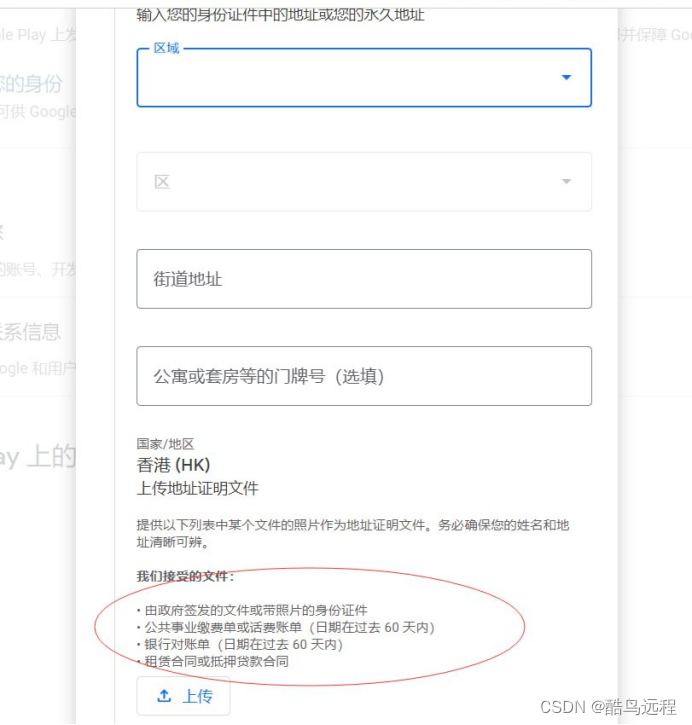
如何解决Google play开发者新注册账号,身份验证的地址证明问题?
我们知道,Google Play应用市场的发展速度惊人,但这两年,为了防止恶意软件的传播,谷歌要求开发者账号需要进行身份验证才能发布应用。 而今年越来越严格,不仅在提审时需要进行电话验证(链接)&am…...

Gin vs Beego: Golang的Web框架之争
前言 Golang作为一门高效且简洁的语言,已经在Web开发领域得到了广泛的应用。Gin和Beego是Golang中两个著名的Web框架,它们都提供了一系列强大的功能,帮助开发者构建高性能的Web应用。本文将对Gin和Beego进行全面的对比,帮助开发者…...

javascript IP地址正则表达式
/^(1[0-9]{2}|2[0-4][0-9]|25[0-5]|(\d){1,2})\.(1[0-9]{2}|2[0-4][0-9]|25[0-5]|(\d){1,2}|0)\.(1[0-9]{2}|2[0-4][0-9]|25[0-5]|(\d){1,2}|0)\.(1[0-9]{2}|2[0-4][0-9]|25[0-5]|(\d){1,2}|0)$/g.test(10.2.35.8) 注: 一定不要把表达式赋值给变量,直接…...

【Bash】记录一个长命令换行的BUG
假设现在我要在terminal执行如下命令跑模型: CUDA_VISIBLE_DEVICES6 python finetune.py -c configs/quantized/resnet32_cifar100_finetune.yml --model resnet32 --data-dir ~/datasets --apex-amp --initial-checkpoint /home/zwx/projects/hawq/resnet32.pth.t…...

【.net core】yisha框架imageupload组件多图上传修改
框架\wwwroot\lib\imageupload\1.0\js路径下imgup.js文件,参照旧版本代码和修改代码修改 (function ($) {"use strict";var deleteParent;var deleteDisplay none;var defaults {fileType: ["jpg", "png", "bmp", "…...

vscode markdown 使用技巧 -- 如何快速打出一个Tab 或多个空格
背景描述: 我在使用VSCode,这玩意很好用,但是,有一个缺点是,我想使用Tab来做一些对齐,但是我发现在VSCode中,无论是Tab还是多个空格,最终显示出来的都是一个空格 使用代码可以实现打…...
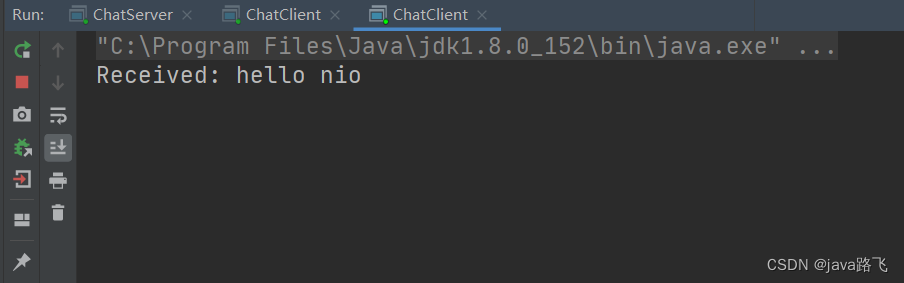
I/O 模型学习笔记【全面理解BIO/NIO/AIO】
文章目录 I/O 模型什么是 I/O 模型Java支持3种I/O模型BIO(Blocking I/O)NIO(Non-blocking I/O)AIO(Asynchronous I/O) BIO、NIO、AIO适用场景分析 java BIOJava BIO 基本介绍Java BIO 编程流程一个栗子实现…...

【Python学习笔记】字符编码
1. 字符串编码 Python3语言里面的字符串对象是unicode字符串,在内存中实际存储时,使用的是 UTF16 编码。但通常不会将UTF16编码的内容写到磁盘或者在网络进行传输, 因为utf16编码比较浪费空间。特别是如果文字信息基本都是英文符号的情况下&…...
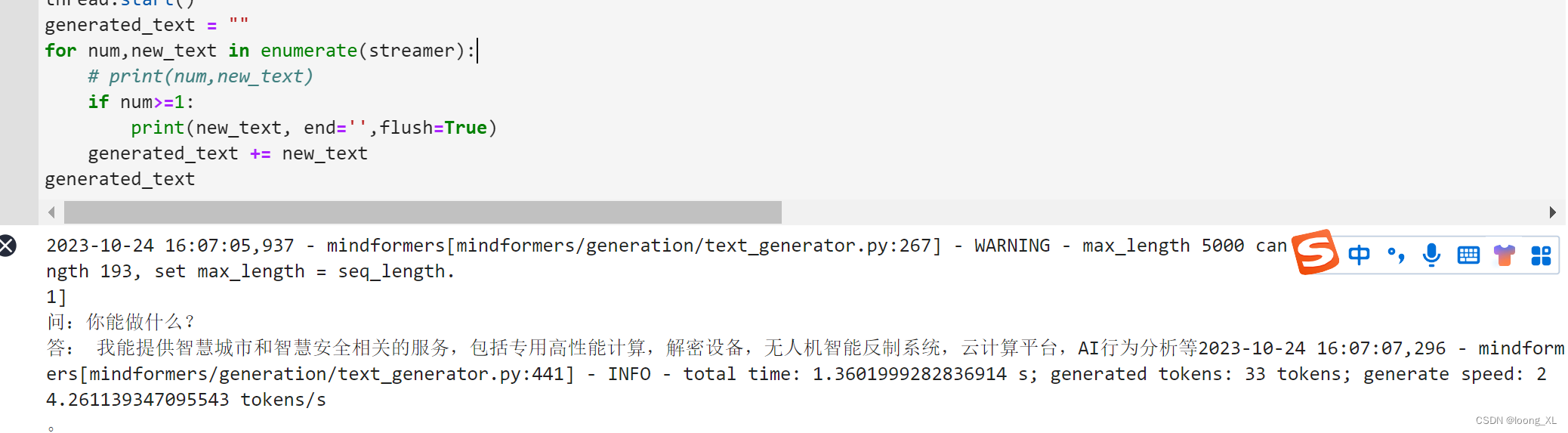
华为昇腾NPU卡 大模型LLM ChatGLM2模型推理使用
参考:https://gitee.com/mindspore/mindformers/blob/dev/docs/model_cards/glm2.md#chatglm2-6b 1、安装环境: 昇腾NPU卡对应英伟达GPU卡,CANN对应CUDA底层; mindspore对应pytorch;mindformers对应transformers 本…...

Git 拉取远程更新报错
报错内容如下: cannot lock ref refs/remotes/origin/bugfix/bug: refs/remotes/origin/bugfix 已存在,无法创建 refs/remotes/origin/bugfix/bug 来自 gitlab.zhangyue-inc.com:dejian_ios/iReaderDejian! [新分支] bugfix/bug -> ori…...

腾讯云国际站服务器端口开放失败怎么办?
腾讯云服务器是腾讯公司推出的一种云服务,用户能够经过这种方式在互联网上进行数据存储和计算。然而,用户在运用腾讯云服务器时或许会遇到各种问题,其间端口敞开失利是一个常见问题。本文将具体介绍如何解决腾讯云服务器端口敞开失利的问题。…...
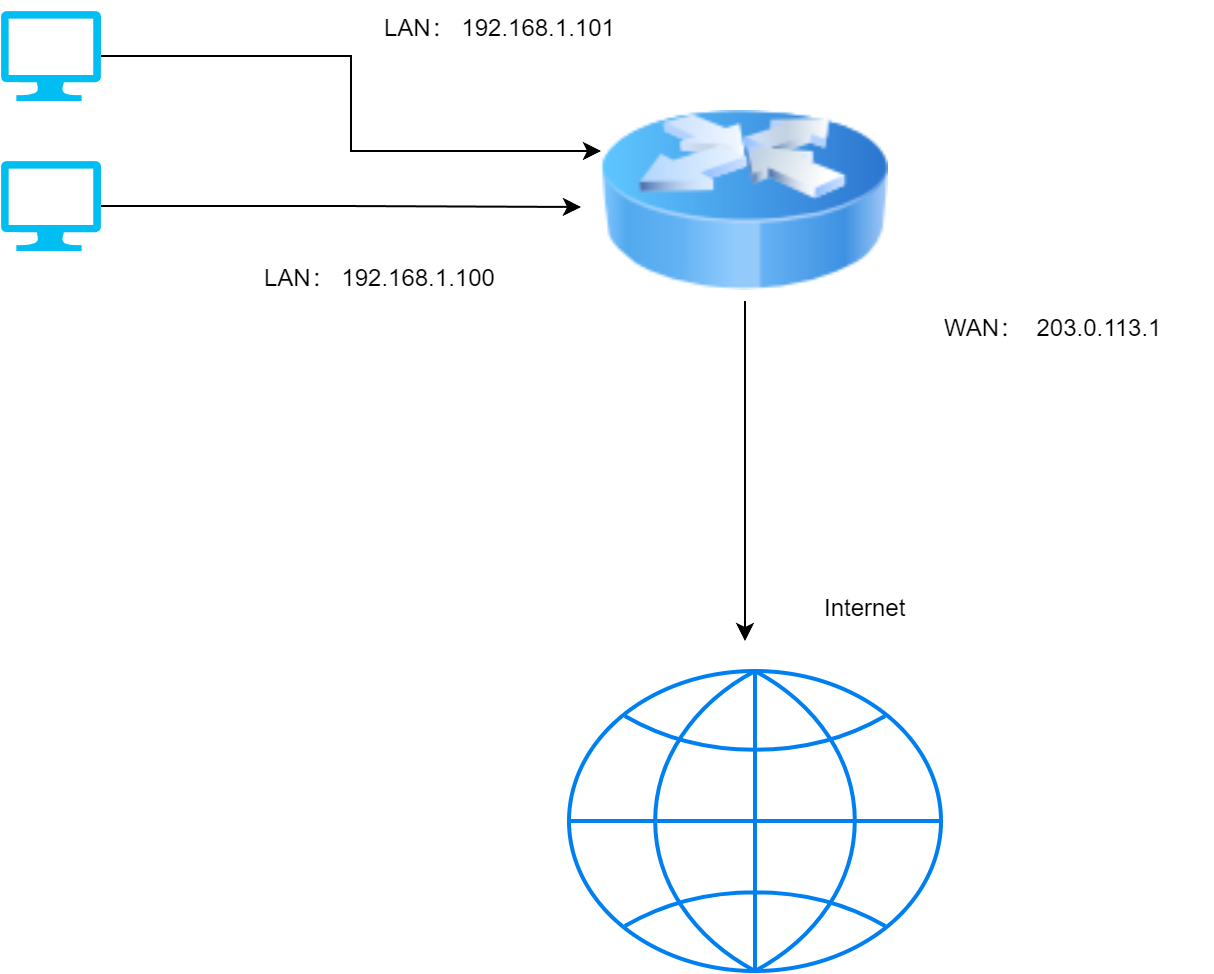
一句话解释什么是出口IP
出口 IP 是指从本地网络连接到公共互联网时所使用的 IP 地址。这个 IP 地址是由 Internet 服务提供商(ISP)分配给你的,它可以用来标识你的网络流量的来源。如果你使用的是 NAT(网络地址转换)技术,则在 NAT 设备内部会进行地址转换,使得多个设备可以共享同一个公共 IP 地…...

深入理解强化学习——强化学习的历史:试错学习
分类目录:《深入理解强化学习》总目录 让我们现在回到另一条通向现代强化学习领域的主线上,它的核心则是试错学习思想。我们在这里只对要点做概述,《深入理解强化学习》系列后面的文章会更详细地讨论这个主题。根据美国心理学家R.S.woodworth…...

Go输入输出格式化技巧大全,深入理解操作系统中的线程。
Go基础:输入与输出格式化详解 标准输入与输出 Go语言通过fmt包提供丰富的输入输出功能。标准输出常用Print、Println和Printf函数。Print直接输出内容,Println自动添加换行符,Printf支持格式化输出。 fmt.Print("Hello") // …...

电机速度计算
1. M法计算速度值详解:原理、公式与应用 概述 M法,也称为频率测量法,是一种通过在固定时间内统计脉冲数量来计算速度的常用方法。这种方法特别适用于中高速运动的测量场景,在电机控制、编码器测速等领域有着广泛的应用。 …...

基于metaRTC的H264/H265嵌入式高清直播系统开发指南
1. 为什么选择metaRTC开发嵌入式直播系统 第一次接触metaRTC是在一个教育录播项目里,客户要求系统必须支持H265编码,还得能在ARM架构的嵌入式设备上稳定运行。当时试了好几个开源方案,不是编解码性能跟不上,就是内存占用太高。直到…...

告别英雄联盟繁琐操作:3大核心功能让你轻松掌控游戏节奏
告别英雄联盟繁琐操作:3大核心功能让你轻松掌控游戏节奏 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 在快节奏的英雄联盟对局中…...
)
ParaView实战:5分钟搞定热流图单元格体积计算(附Python脚本)
ParaView热流分析实战:从单元格体积计算到三维可视化全流程指南 在计算流体力学和热传导分析中,准确获取网格单元的体积数据是后续量化分析的基础。许多工程师在处理复杂几何体的热流分布时,常常陷入繁琐的手动计算或复杂的编程工作中。实际上…...

利用快马平台快速原型:五分钟构建你的第一个multisim风格电路仿真器
最近在尝试电路设计时,发现从构思到实际验证往往需要花费大量时间搭建仿真环境。传统方式需要安装专业软件、配置参数,整个过程相当繁琐。直到尝试了InsCode(快马)平台,发现它特别适合用来做电路设计的快速原型验证。下面分享如何用五分钟构建…...

N_m3u8DL-RE终极指南:跨平台流媒体下载与加密视频处理完全解决方案
N_m3u8DL-RE终极指南:跨平台流媒体下载与加密视频处理完全解决方案 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_…...
,帮你避坑收藏这篇就够了!)
Agent落地方法论入门到精通(非常详细),帮你避坑收藏这篇就够了!
涉及到智能体应用的开发时,agent相关知识不可能绕过,不管是基于langchain还是autogen,都要系统性了解agent,才能对agent开发有全面充分的理解。 Agent 到底是什么 如果从工程角度定义: Agent 以大模型为核心决策器&a…...

智慧机场三维空间智能中枢系统白皮书——构建“全域感知 × 空间认知 × 智能调度”的下一代机场操作平台
智慧机场三维空间智能中枢系统白皮书——构建“全域感知 空间认知 智能调度”的下一代机场操作平台(镜像视界(浙江)科技有限公司空间计算技术体系支撑)一、项目背景:机场正在进入“复杂系统时代”现代机场已从单一交…...

保姆级教程:用Python调用DashScope灵积模型API,5分钟搞定你的第一个AI菜谱
5分钟实战:用Python调用DashScope打造智能菜谱生成器 第一次接触AI模型API调用时,很多人会被各种术语和配置步骤吓退。但事实上,借助像DashScope这样的平台,即使是编程新手也能快速实现有趣的应用。今天我们就从一个生活化场景出…...