RocksDB基本架构与原理详解
Rocksdb
Flink提供基于流的有状态计算,除了提供实时数据流的处理能力,还需要将计算产生的状态存储起来。
为了满足状态存取需求,提供了memory、flie system、rocksdb三种类型的状态存储机制。
memory存取高效单空间有限,且可用性低;
file system提供状态持久化能力但存取性能较低;
rocksdb提供数据快速写入以及数据持久化的能力。
本文介绍了Rocksdb设计的基本架构。
RocksDB介绍
Rocksdb 是基于Google LevelDB研发的高性能kv持久化存储引擎,以库组件形式嵌入程序中,为大规模分布式应用在ssd上运行提供优化。RocksDB不提供高层级的操作,例如备份、负载均衡、快照等,而是选择提供工具支持将实现交给上层应用。正是这种高度可定制化能力,允许RocksDB对广泛的需求和工作负载场景进行定制。
RocksDB 架构
RocksDB使用Log-Structured Merge(LSM)trees做为基本的数据存储结构。
RocksDB主要组成 & 读、写和压缩操作流程图解

Writes
当数据写入RocksDB的时候,首先写入到内存中的写缓存MemTable和磁盘上的Write-Ahead-Log(WAL)。
每当MemTable缓存数据量达到预设值,MemTable与WAL将会转为不可变状态,同时分配新的MemTable与WAL用于后续写入,接着对不可变MemTable中相同key进行merge合并,
flush到磁盘上的Sorted String Table(ssTable)文件中,并丢弃关联的MemTable与WAL数据。
1、为了保证数据的有序性,数据插入搜索的高效性(O(log n)),MemTable基于skipList实现。
2、WAL用于故障发生时的数据恢复,可选择关闭。
3、每个ssTable除了包含数据块(DataBlock)外,还有一个索引块(IndexBlock)用于二分查找
Compaction
LSM tree有多个层级,每个层级由多个ssTable组成,最新的ssTable都会放置在level-0(最顶层),下层的ssTable通过
Compaction(压缩)操作创建。每层的ssTable总大小由配置参数决定,当L层数据大小超出预设值,会选择L层的SSTable与L+1层的SSTable重叠部分合并,
通过这一过程将写入数据从Level-0逐渐推到最后一层。基于这些操作完成了数据的删除与覆盖,同时优化了数据空间与读性能。
Compaction操作对于I/O是高效的,因为压缩是可以并行执行,并且对数据文件的读写是批量的。
Level-0中单个ssTable中的key是有序的,不同的ssTable存在key重叠。下层的key是整体有序的。
RocksDB支持多种压缩类型:
- Leveled Compaction: 从LevelDB迁移改进过来的,每一层的大小由上至下指数增长,数据量达到指定大小开始压缩。
- Tiered Compaction: 也叫Universal Compaction,与Apache Cassandra/ HBase使用的延迟压缩类似,当某层的runs/ssTables个数超出预设值 或者 数据库大小与最大一层的大小比值超过预设系数
- 时才开始压缩。
- FIFO Compaction 一旦数据量达到预设值,将会丢弃旧数据并执行轻量级压缩,主要应用于内存缓存的场景。
压缩模式的选择,让RocksDB适用于广泛的场景。通过调整压缩策略,能将RocksDB配置成读友好、写友好、或者针对特殊缓存工作的极度写友好模式。
开发者需要根据使用场景权衡指标配置。延迟压缩算法能够减少写放大、写吞吐,但是读性能会收到影响;而积极的压缩策略会影响写性能,但读效率会更高。
日志与流处理服务可以使用侧重写,而数据库服务需要在读写之间做好平衡,
三种主要的压缩策略对各项指标的影响对比

Reads
从MemTables开始搜索,接着从Level-0依次往下层搜索,直至查到指定的key,若查无则不存在。
在LSM的每一层上搜索都使用二分查找搜索目标ssTables,接着利用Bloom filter过滤掉非必要搜索的sssTable,
最后在ssTable中二分查找出指定key的value。
核心结构
MemTable
MemTable 是一种内存数据结构,用于保留刚写入的数据直至刷新到SST文件中。
它同时服务于读和写:新的写入总是将数据插入到 memtable 中;而读取流程最先查询 memtable,因为 memtable 中的数据较新。
一旦一个 memtable 满了,它就会变得不可变并被一个新的 memtable 取代。后台线程会将内存表的内容刷新到 SST 文件中,然后销毁已经落盘的内存表。
memtable 默认使用SkipList实现。还可以选择HashLinkList、HashSkipList、Vector用来加速某些查询。
- SkipList MemTable
读写、随机访问和顺序扫描提供了总体良好的性能,还提供了其他 memtable 实现目前不支持的一些其他有用功能,例如并发插入和带Hit插入
- HashSkipList MemTable
HashSkipList将数据组织在哈希表中,每一个哈希桶都是一个有序的SkipList,key是原始key通过Options.prefix_extractor截取的前缀key。主要用于减少查询时的比较次数。一般与PlainTable SST格式配合使用将数据存储在 RAMFS 中。
基于哈希的 memtables 的最大限制是跨多个前缀进行扫描需要复制和排序,非常慢且内存成本高。
触发 Memtable 刷新落盘的场景:
- 写入后 Memtable 大小超过ColumnFamilyOptions::write_buffer_size
- 所有列族的Memtable用量超过 DBOptions::db_write_buffer_size 或者 write_buffer_manager发出刷新信号。最大的MemTable将会flushed
- WAL文件大小超过 DBOptions::max_total_wal_size
Block Cache
RocksDB 在内存中缓存数据以供读取的地方。一个Cache对象可以被同一个进程中的多个RocksDB实例共享,用户可以控制整体的缓存容量。
块缓存存储未压缩的块。用户可以选择设置存储压缩块的二级块缓存。读取将首先从未压缩的块缓存中获取数据块,然后是压缩的块缓存。如果使用 Direct-IO,压缩块缓存可以替代 OS 页面缓存。
- Block Cache有两种缓存实现,分别是 LRUCache 和 ClockCache。两种类型的缓存都使用分片以减轻锁争用。容量平均分配给每个分片,分片不共享容量。默认情况下,每个缓存最多会被分成 64 个分片,每个分片的容量不小于 512k 字节。
LRUCache: 默认的缓存实现。使用容量为8MB的基于LRU的缓存。缓存的每个分片都维护自己的LRU列表和自己的哈希表以供查找。通过每个分片的互斥锁实现同步,查找与插入都需要对分片加锁。
极少数情况下,在块上进行读或迭代的,并且固定的块总大小超过限制,缓存的大小可能会大于容量。如果主机没有足够的内存,这可能会导致意外的 OOM 错误,从而导致数据库崩溃
- ClockCache: ClockCache 实现了 CLOCK 算法。时钟缓存的每个分片都维护一个缓存条目的循环列表。时钟句柄在循环列表上运行,寻找要驱逐的未固定条目,但如果自上次扫描以来已使用过,也给每个条目第二次机会留在缓存中。
ClockCache 还不稳定,不建议使用
Write Buffer Manager
Write Buffer Manager 用于控制多个列族或者多个数据库实例的内存表总使用量。
使用方式:用户创建一个write buffer manager对象,并将对象传递到需要控制内存的列族或数据库实例中。
有两种限制方式:
1、限制 memtables 的总内存用量
触发其中一个条件将会在实例的列族上触发flush操作:
- 如果活跃的 memtables 使用超过阈值的90%
- 总内存超过限制,活跃的 mamtables 使用也超过阈值的 50% 时。
2、memtable 的内存占用转移到 block cache
大多数情况下,block cache中实际使用的block远小于block cache中缓存的,所以当用户启用该功能时,block cache容量将覆盖block cache和memtable两者的内存使用量。
如果用户同时开启 cache_index_and_filter_blocks,那么RocksDB的三大内存区域(index and filter cache, memtables, block cache)内存占用都在block cache中。
SST文件格式
BlockBasedTable 是 SSTable 的默认表格式。
<beginning_of_file>
[data block 1]
[data block 2]
...
[data block N]
[meta block 1: filter block] (see section: "filter" Meta Block)
[meta block 2: index block]
[meta block 3: compression dictionary block] (see section: "compression dictionary" Meta Block)
[meta block 4: range deletion block] (see section: "range deletion" Meta Block)
[meta block 5: stats block] (see section: "properties" Meta Block)
...
[meta block K: future extended block] (we may add more meta blocks in the future)
[metaindex block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
<end_of_file>
数据块 DataBlock:键值对序列按照根据排序规则顺序排列,划分为一系列数据块(data block)。这些块在文件开头一个接一个排列,每个数据块可选择性压缩。
元数据块 MetaBlock:紧接着数据块的是一堆元数据块(meta block),元数据块包括:过滤块(filter block)、索引块(index block)、压缩字典块(compression dictionary block)、范围删除块(range deletion block)、属性块(properties block)。
元索引3块 MetaIndexBlock: 元索引块包含一个映射表指向每个meta block,key是meta block的名称,value是指向该meta block的指针,指针通过offset、size指向数据块。
页脚 Footer:文件末尾是固定长度的页脚。包括指向metaindex block的指针,指向index block的指针,以及一个magic number。
Meta Block的具体种类:
索引块 Index Block
索引块用于查找包含指定key的数据块。是一种基于二分搜索的数据结构。一个文件可能包含一个索引块,也可能包含一组分区索引块,这取决于使用配置。即存在全局索引与分区索引两种索引方式。
过滤器块 Filter Block
全局过滤器、分区过滤器,都是通过用布隆过滤器实现
- 全局过滤器 Full Filter: 在此过滤器中,整个 SST 文件只有一个过滤器块。
- 分区过滤器 Partitioned Filter: Full Filter 被分成多个子过滤器块,在这些块的顶层有一个索引块用于将key映射到相应的子过滤器块。
压缩字典块 Compression Dictionary Block
包含用于在压缩/解压缩每个块之前准备压缩库的字典。
范围删除块 Range Deletion Block
范围删除块包含文件中key与序列号中的删除范围。在读请求下发到sst的时候能够从sst中的指定区域判断key是否在deleterange 的范围内部,存在则直接返回NotFound。memtable中也有一块区域实现同样的功能。
compaction或者flush的时候会清除掉过时的tombstone数据。
属性块 Properties Block
包含属性信息。
统计块格式:
[prop1] 每个property都是一个键值对 [prop2]...[propN]
属性信息保证顺序且没有重复,默认情况下包含了以下信息:
data size // data block总大小index size // index block总大小filter size // filter block总大小raw key size // 所有key的原始大小raw value size // 所有value的原始大小number of entriesnumber of data blocks
优化
RocksDB优化的演变进程:
- 优化写放大: Log-Structure Merge Tree
- 空间放大: compaction操作
- 减少compaction带来的cpu负载:优化lsm,控制压缩频率粒度
- cpu、ssd资源平衡:拆分存储,使用远程存储(hdfs、s3、oss)
写放大
RocksDB早起专注于通过节省闪存的擦除周期来减小写入放大。写放大主要出现在两个层面:
1、SSD本身引入的写入放大,放大范围在1.1~3;
2、存储和数据库软件也会产生写放大,有时会高达100(eg:当100bytes的变更导致4kB/8KB/16KB的page被写出)
Leveled Compaction通常会带来10-30之间的写入放大,在大多数情况下比B-trees要低,但对于写敏感的应用来说还是太高。
所以有了Tiered Compaction,牺牲了读性能将写放大减小到4-10之间。数据写入速率高的场景使用Tiered Compaction这类压缩策略减少写入放大,
写入速率偏低的场景使用Leveled Compaction这类策略减少空间使用和提高读取效率。
写放大对写入速率的影响

空间放大
后续对大多数程序的观察可知,闪存的写入周期与写入开销都没有受到约束,IO负载远低于SSD能提供的能力。
空间的利用率变得比写放大更重要,因此开始对磁盘空间进行优化。
得益于LSM-trees结构的非碎片化数据布局,其对于磁盘空间优化也能起到有效作用。可以通过减少LSM-trees中的脏数据(delete/overwrite)来优化Leveled-Compaction。
因此有了新的数据压缩策略:
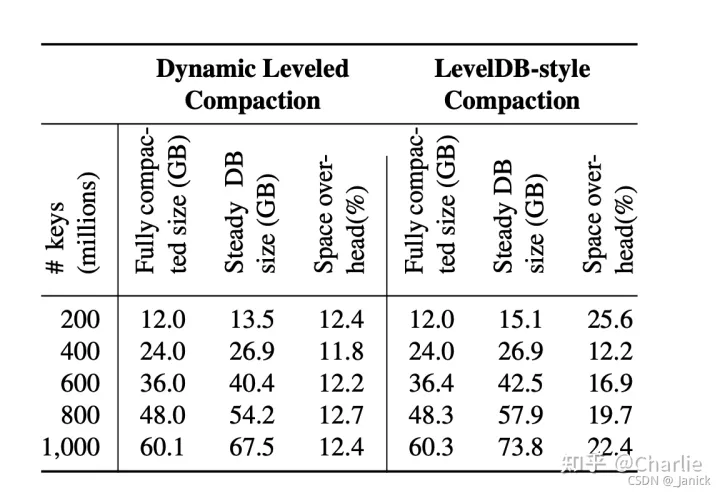
Dynamic Leveled Compaction:每一层的数据大小根据上一层的实际大小动态调整,实现比Leveled Compaction更好更稳定的空间效率
右下图测试数据所示,Leveled Compaction使用25.6%的空间,而Dynamic Leveled Compaction策略只需要12.4%。
极端情况下Leveled Compaction的磁盘使用会高达90%,而Dynamic Leveled Compaction依旧能保持在相对稳定的范围。
恒定2MB/s写入速率下两种压缩策略的空间使用与数据大小
CPU利用率
减少CPU负载可以提高少数受CPU限制的应用性能。更重要的是减少CPU开销能够节省硬件成本。
早期降低CPU开销的方式包括:引入前缀布隆过滤器、在索引查询之前应用布隆过滤器、优化布隆过滤器
适应新的硬件技术
SSD:与SSD相关的架构改进可能会影响RocksDB。例如open-channel SSDs,multi-stream和SSDZNS都承诺改善查询延迟并节省闪存擦除周期。
由于大部分使用RocksDB的软件受限于磁盘空间而不是擦除周期和延迟,这种新技术变更只会对小部分使用RocksDB的软件有性能提升。
让RocksDB直接适应新的硬件技术将会对RocksDB的一致性体验带来挑战。目前社区对存储计算这方面还没有研究与优化规划。
Disaggregated (remote) storag: 远程存储是目前的优先事项。目前的优化都是预设闪存在本机环境,然而现在的网络已经允许支撑更多的远程I/。
因此对越来越多的程序来说,支持远程存储的RocksDB性能变得越来越重要。使用远程存储可以按需配置,能更容易重复利用CPU与SSD资源。
目前针对分离存储的优化有:整合&并行化I/O来优化I/O延迟、将QoS需求传递到底层系统、报告分析信息
Storage Class Memory(SCM:存储级内存,即既具有memory的优势,又兼顾了storage的特点。目前有几种应用设想:
- SCM做为内存拓展,涉及到如何设计贴合两种存储的数据结构
- SCM做为db主要存储
- 将SCM应用于WAL
Rocksdb在大型系统上的使用优化
键-值接口
几乎所有存储工作负载都可以由具有KV API的数据存储提供服务。KV 接口是通用的。
键和值都是由可变长的字节数组构成,应用程序负责解析和解释键和值,可以自由选择将哪些信息打包到key value中,包括编码方案。
KV 接口的另一个好处就是便携性,键值系统之间的数据迁移更为容易。
然而KV 接口会限制某些程序的性能。例如,在RocksDB之外构建并发控制很难有高效的性能,特别是需要支持两阶段提交的场景,在提交事务之前需要持久化一些数据,因此RocksDB提供了事务支持。
版本与时间戳
数据的版本控制非常重要。版本信息是RocksDB中的第一物件,以便正确支持多版本并发控制(MVCC)、时间点读取等特性。
RocksDB也需要支持对不同版本的高效访问。
目前,RocksDB内部使用56位序列号识别不同版本的键值对。序列号由RocksDB生成,每次客户端写入时递增,因此所有数据都按逻辑顺序排列。
RocksDB允许应用程序对数据库进行快照,RocksDB保证快照时存在的所有键值对将持续存在,直至程序明确释放快照,因此具有相同key的多个键值对可以共存,由它们的序列号区分。
这种版本控制方式也有局限性,无法满足许多程序的要求。
- 因为没有API指定时间点,RocksDB不支持创建过去的快照。并且,支持时间点读取效率低下
- 每个RocksDB实例维护自己的序列号,也只能在每个实例的基础上获取快照。导致多数据分片的程序版本控制复杂度增高。提供跨分片一致性读取的数据版本基本上是不可能的。
应用程序可以通过在key/value中编码写入时间错解决局限性。不过这种方式会导致性能下降,key中编码会牺牲 点查寻的性能(key变大);
value中编码会牺牲会牺牲同一key乱序写入的性能,并使旧版本key读取复杂化(解码value比较时间戳)。让应用程序指定时间戳的方式可以更好解决这些限制,应用程序可以在key/value之外用全局时间戳标记数据。
资源管理
对于大型的分布式数据服务,常常将数据划为多个分片分布在多个节点存储。一个单独的 RocksDB 实例用于为每个分片提供服务。
这意味着主机上将运行许多 RocksDB 实例。这些实例可以全部运行在一个单一的地址空间中,也可以每个都运行在自己的地址空间中。
一、RocksDB需要对资源进行有效管理,以保证它们被有效应用。在单进程模式下运行时,需要具备全局资源限制能力,资源包括:
- 内存,用于write buffer、block cache
- 压缩I/O带宽
- 线程,用于压缩
- 磁盘资源
- 文件删除率
- RocksDB 允许应用程序为每种类型的资源创建一个或多个资源控制器,支持RocksDB实例之间的优先级排序,以确保资源优先用于最需要它的实例。
二、多实例的使用方式下,不限制地使用非线程池化的线程会出现问题。线程过多会增加CPU负载的概率,导致过多的上下文切换开销,并使调试变得极其困难,并且会增加I/O负载。RocksDB最好使用可以轻松限制大小和资源使用量的线程池。
三、每个分片只有本地信息,当 RocksDB 实例在单独的进程中运行时,全局资源管理更具挑战性,有两种应对策略:
使用保守的资源策略:例如降低压缩频率,这种策略的缺点是全局资源可能没有被充分利用;
实例之间共享资源使用信息并相应地进行调整以尝试更全局地优化资源使用。这种需要做更多的工作来改进 RocksDB 中主机范围的资源管理
WAL处理
传统数据库倾向于在每次写入操作时强制写入预写日志 (WAL) 以确保持久性。而大规模分布式存储系统通常为了性能和可用性而复制数据,并且它们具有各种一致性保证。
因此提供选项来调整WAL同步行为以满足不同应用程序的需求是很有帮助的。
具体来说,RocksDB引入了差异化的 WAL 操作模式:(1) 同步 WAL 写入 (2) 缓冲 WAL 写入 (3) 无 WAL 写入。对于缓冲的 WAL 处理,WAL 会在后台以低优先级定期写入磁盘,以免影响 RocksDB 的流量延迟
限制文件删除速度
RocksDB 通常通过文件系统与底层存储设备交互,文件系统对是闪存(SSD)是有感知的。ssd上文件的删除可能会触发SSD的内部垃圾收集,导致大量数据移动,并对 IO 延迟产生负面影响。
引入了文件删除速率限制,以防止同时删除多个文件(压缩过程中)
数据格式兼容
磁盘上的数据在不同软件版本之间保持向后和向前兼容非常重要。
配置管理
RocksDB 是高度可配置的,因此应用程序可以针对其工作负载进行优化。然而,配置管理是一个挑战:
早期的配置继承自LevelD,大量配置与代码耦合。RocksDB对其配置方式进行了调整与更新。
QA
Q: MemTable为什么用跳表不用平衡树?
A: 1. 跳表实现比树简洁; 2. 空间占用小,除了数据外其他都是指针; 3. 数据有序,利于范围查询。
Q: MySQL 为什么用B+ trees不用跳表?
A: 1、B+树的页天生就与磁盘块对应,对磁盘更友好;而跳表基于链表实现,数据物理分布比较分散,对I/O不友好;
2、跳表无法实现聚集索引和覆盖索引; 3、数据分散无法利用磁盘预读,对磁盘缓存不友好
。总之就是跳表设计简单,不贴合磁盘特性,适合内存使用。
参考文档
Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience
RocksDB Wiki
相关文章:
RocksDB基本架构与原理详解
Rocksdb Flink提供基于流的有状态计算,除了提供实时数据流的处理能力,还需要将计算产生的状态存储起来。 为了满足状态存取需求,提供了memory、flie system、rocksdb三种类型的状态存储机制。 memory存取高效单空间有限,且可用…...
ArcGIS笔记12_ArcGIS搜索工具没法用?ArcGIS运行很慢很卡?
本文目录 前言Step 1 ArcGIS搜索工具没法用Step 2 ArcGIS运行很慢很卡 前言 这是笔者最近遇到的两个小问题,新换了台式机,安装上ArcGIS后发现搜索工具没法用,而且感觉还不如原来笔记本运行的流畅,加载图层很慢,编辑要…...

【VictoriaMetrics】单机版配置
为方便查看,释义都已翻译成中文,本文配置基于VictoriaMetrics 1.87.1版本 bigMergeConcurrencyint用于大合并的最大 CPU 核数。设置为 0 时使用默认值cacheExpireDuration30m0s...
【C语言】strcpy()函数
🦄个人主页:修修修也 🎏所属专栏:C语言 ⚙️操作环境:Visual Studio 2022 目录 一.strcpy()函数简介 1.函数功能 2.函数参数 1>.char * destination 2>.const char * source 3.函数返回值 4.函数头文件 二.strcpy()函数的具体使用 1.使用s…...

C++基础算法⑦——信奥一本通递归算法(放苹果、求最大公约数问题、2的幂次方表示、分数求和、因子分解、判断元素是否存在)
递归算法 1206:放苹果1207:求最大公约数问题1208:2的幂次方表示1209:分数求和1210:因子分解1211:判断元素是否存在 1206:放苹果 这道题还是有些难度的,我们要考虑几种放苹果的情况。…...
uni-app医院智能导诊系统源码
随着科技的迅速发展,人工智能已经逐渐渗透到我们生活的各个领域。在医疗行业中,智能导诊系统成为了一个备受关注的应用。本文将详细介绍智能导诊系统的概念、技术原理以及在医疗领域中的应用,分析其优势和未来发展趋势。 智能导诊系统通过人工…...

启动jar时指定nacos配置
背景 由于需要在不同服务上部署应用,避免频繁打包,需要在jar启动时灵活配置naocs配置 启动命令 java -Xms256m -Xmx512m -Dfile.encodingutf-8 -jar mes-gateway-1.0.1.jar --spring.cloud.nacos.discovery.server-addrhttp://127.0.0.1:8848 --spri…...
linux安装vscode vscode使用 创建项目并运行
下载 https://code.visualstudio.com/ 下载.deb文件 安装 假如文件被下载到了 /opt目录下 进入Opt目录,右键从当前目录打开终端。 输入下面的安装命令。 sudo apt-get install ./code_1.83.1-1696982868_amd64.deb 安装成功。 安装插件 使用c,必…...

如何解决数据倾斜
星光下的赶路人star的个人主页 臣书刷字墨淋漓,舒卷烟云势最奇 文章目录 1、数据倾斜的现象2、解决办法2.1 单表聚合(group bysum())2.2 多表关联(join) 3、倾斜原因 1、数据倾斜的现象 部分Reduce一直运行࿰…...
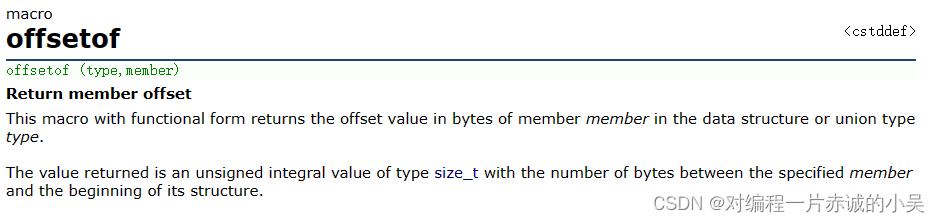
宏定义实现offsetof
在C语言中,有这样一个特殊的宏,叫offsetof,它的功能是啥呢? 我们来看看它的介绍 它的功能是:返回一个结构体的成员的大小(相较于起始地址的偏移量) 引用代码:http://t.csdnimg.cn…...

YOLOv5— Fruit Detection
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营-第7周:咖啡豆识别(训练营内部成员可读) 🍖 原作者:[K同学啊 | 接辅导、项目定制](https…...

(PyTorch)PyTorch中的常见运算(*、@、Mul、Matmul)
1. 矩阵与标量 矩阵(张量)每一个元素与标量进行操作。 import torch a torch.tensor([1,2]) print(a1) >>> tensor([2, 3]) 2. 哈达玛积(Mul) 两个相同尺寸的张量相乘,然后对应元素的相乘就是这个哈达玛…...

cmd 命令关闭占用端口
工作中还是偶尔会遇到端口号被占用的情况,之前也有写过另一种关闭方式,但是发现没有命令方便,所以记录一下。 1、 查看 8081 端口占用的 pid 。 命令:netstat -ano |findstr 8081 由上图可知,占用 8081 端口的进程 id…...

PG14启动报错“max_stack_depth“ must not exceed 7680kB
问题描述 PG14编译安装后启动报错"max_stack_depth" must not exceed 7680kB [roottop132:/pgdb/data]$ systemctl start postgres Job for postgres.service failed because the control process exited with error code. See "systemctl status postgres.se…...

BES2700 蓝牙协议之RFCOMM通道使用方法
是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务 BES2700 RFCOMM通道使用方法 RFCOMM_CHANNEL_NUM 枚举定义了一系列的通道号码,并为每个通道号码指定了一个具体的名称。以下是其中一些通道的中文含义: RFCOMM_CHAN…...

简单介绍一下迁移学习
迁移学习是一种机器学习技术,旨在利用从一个任务或领域学习到的知识来改善另一个任务或领域的学习性能。在传统的机器学习方法中,通常假设训练数据和测试数据是从相同的分布中独立同分布采样的。然而,在现实世界中,这个假设并不总…...

PHP 同城服务共享茶室小程序系统是如何实现的?
随着互联网的快速发展和共享经济的兴起,同城服务共享茶室作为一种新型的商业模式,越来越受到人们的关注。通过开发一款基于PHP的同城服务共享茶室小程序系统,可以提供更加便捷、高效、个性化的服务体验。本文将详细介绍PHP同城服务共享茶室小…...

JavaScript对象与原型
目录 对象的创建 原型与原型链 原型继承 总结 在JavaScript中,对象是非常重要的概念之一。它们允许我们以一种结构化的方式存储和组织数据,并提供了一种方便的方式来操作和访问这些数据。而对象的行为和属性则通过原型来定义。 对象的创建 在JavaS…...

论文解读:《DataPype:用于计算机辅助药物设计的全自动统一软件平台》
论文解读:《DataPype: A Fully Automated Unified Software Platform for Computer-Aided Drug Design》 1.文章概述2.背景2.方法2.1 DataPype概述2.2 数据2.3 分子和蛋白质数据的处理2.3.1 配体处理2.3.2 蛋白质加工 2.4 CADD方法2.5 基准研究2.5.1 单个 CADD 制备…...

2023年Flutter教程_Flutter+Getx仿小米商城项目实战视频教程-V3版
Flutter是谷歌公司开发的一款开源、免费的UI框架,可以让我们快速的在Android和iOS上构建高质量App。它最大的特点就是跨平台、以及高性能。 目前 Flutter 已经支持 iOS、Android、Web、Windows、macOS、Linux 的跨平台开发。 GetX 是 Flutter 上的一个轻量且强大的解…...

ChromeDriver vs GeckoDriver终极选择指南:如何为php-webdriver项目挑选最佳浏览器驱动
ChromeDriver vs GeckoDriver终极选择指南:如何为php-webdriver项目挑选最佳浏览器驱动 【免费下载链接】php-webdriver PHP client for Selenium/WebDriver protocol. Previously facebook/php-webdriver 项目地址: https://gitcode.com/gh_mirrors/ph/php-webdr…...

超详细|2026年OpenClaw4月京东云部署、配置大模型APIkey、接入skill教程,保姆级教学
超详细|2026年OpenClaw4月京东云部署、配置大模型APIkey、接入skill教程,保姆级教学。OpenClaw作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI在企业群聊、个人工作…...

蒙特卡洛模拟的颠覆性突破:OpenMC如何通过多源采样与方差缩减技术解决计算效率瓶颈
蒙特卡洛模拟的颠覆性突破:OpenMC如何通过多源采样与方差缩减技术解决计算效率瓶颈 【免费下载链接】openmc OpenMC Monte Carlo Code 项目地址: https://gitcode.com/gh_mirrors/op/openmc 在核工程、粒子物理和辐射屏蔽等领域,蒙特卡洛模拟一直…...

Qwen3-ForcedAligner-0.6B语音强制对齐实战:基于LLM的时间戳预测
Qwen3-ForcedAligner-0.6B语音强制对齐实战:基于LLM的时间戳预测 1. 引言 你有没有遇到过这样的情况:手里有一段音频和对应的文字稿,想要知道每个词在音频中的具体位置?比如给视频加字幕时,需要精确到每个字的出现时…...

Path of Building 全面指南:从零开始的流放之路角色构建工具精通教程
Path of Building 全面指南:从零开始的流放之路角色构建工具精通教程 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding Path of Building 是《流放之路》玩家不…...

RTKLIB数据处理避坑大全:从SPP/PPP精度对比到LAPACK库调用疑难解析
RTKLIB数据处理避坑大全:从SPP/PPP精度对比到LAPACK库调用疑难解析 当你在处理GNSS数据时,是否遇到过这样的困扰:明明按照教程一步步操作,结果却出现大量"飞点",精度远不如预期?或者当你想要启用…...

Atmosphere-stable功能解析与实践指南:开源Switch自定义固件解决方案
Atmosphere-stable功能解析与实践指南:开源Switch自定义固件解决方案 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 传统Switch破解方案常面临系统稳定性差、原始系统安全风险…...
)
别光记公式!用Python+OpenCV手把手带你标定相机内参外参(附完整代码)
别光记公式!用PythonOpenCV手把手带你标定相机内参外参(附完整代码) 在计算机视觉项目中,相机标定是构建三维感知系统的第一步。很多开发者能背诵内参矩阵的数学形式,却对如何用代码实际获取这些参数一头雾水。本文将用…...

DeepSeek-Coder-V2完全指南:从环境搭建到代码生成实战
DeepSeek-Coder-V2完全指南:从环境搭建到代码生成实战 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Coder-V2 D…...

WiseFlow部署避坑指南:从Docker到PowerShell权限问题的完整解决方案
WiseFlow部署实战手册:从零到一的系统化避坑指南 引言 当你第一次接触WiseFlow这个开源项目时,可能会被它强大的功能所吸引——从自动化任务处理到智能数据分析,这个工具正在改变许多开发者的工作方式。然而,就像大多数技术栈的初…...