nlp与知识图谱代码解读
词嵌入
简单原理
我们要给一群14岁的孩子讲解词嵌入。可以使用一些比喻和生活中的例子:
老师: 你们还记得玩乐高积木的时候,每个积木块代表了一个特定的事物或形状吗?现在,想象一下,每个词都像是一个乐高积木。我们要做的是为每个积木找到一个特殊的地方,这样它们就可以和其他积木在某种方式上连接起来。
词嵌入就像是为每个词找一个特定的地方或位置,但这个“地方”不是在房间里,而是在一个叫做“嵌入空间”的地方。
学生A: “嵌入空间”是什么?
老师: 好问题!嵌入空间就像一个大大的游乐场。每个词都有自己的一个小小的位置,这个位置由一些数字决定。比如,“猫”可能在游乐场的旋转木马旁边,而“狗”可能在滑梯旁边。这些位置是用数字来表示的,所以“猫”可能是[0.5, 2.3],而“狗”可能是[0.6, 2.1]。
这些位置不是随机选择的。词之间的关系决定了它们在游乐场中的位置。例如,因为“猫”和“狗”都是宠物,所以它们的位置会很接近。但“猫”和“汽车”可能就相距很远,因为它们是不同类别的事物。
学生B: 那我们是怎么知道每个词的位置的呢?
老师: 很好的问题!我们使用计算机和特殊的算法。我们把很多句子和文本输入到计算机中,计算机会查看哪些词经常一起出现,然后根据这些信息决定它们在游乐场中的位置。
比如,“奶”和“饼干”在很多句子中都一起出现,所以计算机会认为它们应该在游乐场的同一个地方或附近。
学生C: 那为什么我们要做这个呢?
老师: 好问题!当我们给计算机很多文本时,我们希望它能理解这些文本的意思。但计算机不懂“猫”或“狗”的真正意思,它只懂数字。所以,我们把每个词转换成数字,这样计算机就可以理解它们了。通过这种方式,计算机可以帮助我们回答问题、写文章或者做其他有趣的事情!
既然计算机不懂什么是“猫”和“狗”,那计算机如何将“猫”和“狗”的数字设置的近一些呢?
很好的问题!确实,计算机本身并不知道“猫”和“狗”的具体含义,但它可以通过分析大量的文本数据来识别这两个词语之间的关联。下面我会用一个简单的例子来解释这个过程。
老师: 让我们想象一个游戏:你在读很多的故事书,但是每次你只看两个连在一起的词。比如:“猫在”, “在睡觉”, “狗在”, “在追”。你可能会注意到,“猫”和“狗”经常都跟“在”这个词后面。
现在,假设我们有一个大篮子,里面放着很多词的卡片。开始时,这些卡片都随机地放在篮子里。每次你读到两个连在一起的词,你就把这两张卡片放得更近一些。
经过很多次这样的操作后,你会发现那些经常在故事里连在一起的词卡片会聚集在一起。所以,“猫”和“狗”可能会因为它们经常与相似的词语连在一起,而被放得很近。
计算机在进行词嵌入的时候,也是做了类似的事情。它看了大量的句子,每次只注意那些靠近的词。然后,它会调整每个词的数字位置,使得经常在一起出现的词更加接近。
通过这种方式,即使计算机不知道“猫”和“狗”的真实含义,它也能知道这两个词在很多情境中是相似或有关的,所以应该放得近一些。
希望这个解释能帮助你理解计算机是如何决定词嵌入中词的位置的!
代码案例+解读
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding # 词嵌入model = Sequential()
model.add(Embedding(input_dim=7, output_dim=3, )) # 输入、输出
model.compile() # 全部参数使用默认
x = np.array([[0, 1, 0, 1, 1, 0, 0],[1, 1, 1, 1, 1, 1, 1]])
print('input shape data: \n', x, x.shape)
result = model.predict(x)
print('Embedding:', result, 'shape:', result.shape)
这段代码使用TensorFlow的Keras API来创建一个简单的词嵌入(Embedding)模型。我们来逐行解读代码内容:
-
import numpy as np
导入NumPy库,并使用别名np引用它。NumPy是一个常用的Python科学计算库,用于进行数值计算。 -
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding
这两行从TensorFlow库中导入必要的模块。Sequential模型是Keras中一个线性堆叠的层次结构,而Embedding是Keras中用于词嵌入的层。 -
model = Sequential()
创建一个Sequential模型的实例。 -
model.add(Embedding(input_dim=7, output_dim=3, ))
向模型中添加一个Embedding层。其中,input_dim=7表示输入数据的词汇表大小为7,也即我们有7个不同的单词/标记。output_dim=3表示每个单词要被嵌入到3维的向量空间中。 -
model.compile()
编译模型。这里没有为compile函数提供任何参数,所以它使用默认设置。由于这只是一个简单的演示,并没有进行真实的训练,所以这一步的设置不是很关键。 -
x = np.array([[0, 1, 0, 1, 1, 0, 0], [1, 1, 1, 1, 1, 1, 1]])
使用NumPy创建一个形状为(2, 7)的数组。可以看作是两个句子,每个句子由7个单词/标记组成。这里的数字代表词汇表中的索引。 -
print('input shape data: \n', x, x.shape)
打印输入数据和它的形状。 -
result = model.predict(x)
使用Embedding模型对输入数据x进行预测。实际上,这一步将输入数据的每个单词索引转换为对应的嵌入向量。 -
print('Embedding:', result, 'shape:', result.shape)
打印嵌入的结果和它的形状。
总结:此代码创建了一个简单的词嵌入模型,然后用这个模型将两个句子中的单词索引转换为对应的嵌入向量。这个模型没有经过训练,所以得到的嵌入向量是随机的。
专业原理介绍
词嵌入简介:
词嵌入(Word Embedding)是NLP和深度学习中的一个关键技术,它的核心思想是将自然语言中的单词或短语转换成固定大小的向量。这些向量可以捕获单词之间的语义关系、相似性和其他多种语言属性。
为什么需要词嵌入?
计算机本身不能理解文本或单词,它只能理解数字。因此,我们需要一种方法将单词转化为数值或向量形式。初学者可能会首先想到“独热编码”,但这种方法在大词汇表中是不切实际的,因为它产生的向量非常稀疏,且不能捕获单词间的关系。
词嵌入提供了一种更紧凑、高效的表示方法,其中相似的单词在向量空间中彼此靠近。
如何获得词嵌入?
-
预训练模型:例如Word2Vec、GloVe和FastText,这些模型在大量文本数据上训练,可以为每个单词提供预训练的向量。你可以直接使用这些预训练向量或在特定任务上进行进一步的微调。
-
自行训练:例如,在一个深度学习模型(如RNN、CNN)中使用嵌入层,这个层在模型训练过程中学习合适的单词向量。
Word2Vec简介:
Word2Vec是最受欢迎的词嵌入方法之一。它的核心思想是“一个单词的含义可以由它周围的单词定义”。Word2Vec有两种主要的训练方法:
- CBOW(Continuous Bag of Words):给定上下文,预测当前单词。
- Skip-Gram:给定当前单词,预测它的上下文。
词嵌入的优点:
- 捕获语义信息:例如,“king” - “man” + “woman” 接近 “queen”。
- 降维:将高维的独热向量转化为低维的密集向量。
- 可转移:预训练的词向量可以用于多种不同的任务。
总结:
词嵌入为单词提供了一种密集、低维的向量表示形式,这些向量捕获了单词的语义属性和关系。使用词嵌入,我们可以在深度学习模型中更高效地处理文本数据。
场景
当然可以!让我们使用一个简单的例子来进一步理解词嵌入。
场景: 设想你有以下四个句子:
- The cat sat on the mat.
- The dog sat on the rug.
- Cats and dogs are pets.
- Pets make great companions.
如果我们从这些句子中提取出所有的唯一单词,我们得到一个词汇表:[The, cat, sat, on, the, mat, dog, rug, cats, dogs, are, pets, make, great, companions]。我们忽略大小写和标点符号。
独热编码:
让我们先看独热编码。对于词汇表中的每一个单词,独热编码将会为其分配一个向量,其中只有一个元素是1,其余都是0。
例如:
- cat: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- dog: [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
但是这种表示方式有两个问题:向量很大并且稀疏(大部分为0),且这种编码方式无法表示单词间的关系(如“cat”和“dog”都是宠物,有语义上的相似性)。
词嵌入:
相对于独热编码,词嵌入将每个单词表示为一个更小的、密集的向量。例如,我们可以有一个3维的嵌入空间(实际应用中通常更高维)。
在这个简化的例子中,向量可能如下:
- cat: [0.9, 0.5, 0.3]
- dog: [0.8, 0.6, 0.4]
- mat: [0.1, 0.2, 0.3]
- rug: [0.15, 0.21, 0.31]
在这个嵌入空间中,“cat”和“dog”的向量很接近,这意味着它们在语义上相似。而“mat”和“rug”也很接近,因为它们都是可以坐或躺的物体。
词嵌入的美妙之处在于,当它们被训练在大量的文本数据上时,它们能够捕获更多的复杂语义和语法关系。例如,“king”和“queen”的向量之间的关系可能类似于“man”和“woman”的向量之间的关系。
这个简化的例子展示了词嵌入如何提供一种更紧凑、更有表现力的方式来表示单词,从而能够捕获单词之间的关系和语义含义。
相关文章:

nlp与知识图谱代码解读
词嵌入 简单原理 我们要给一群14岁的孩子讲解词嵌入。可以使用一些比喻和生活中的例子: 老师: 你们还记得玩乐高积木的时候,每个积木块代表了一个特定的事物或形状吗?现在,想象一下,每个词都像是一个乐高…...
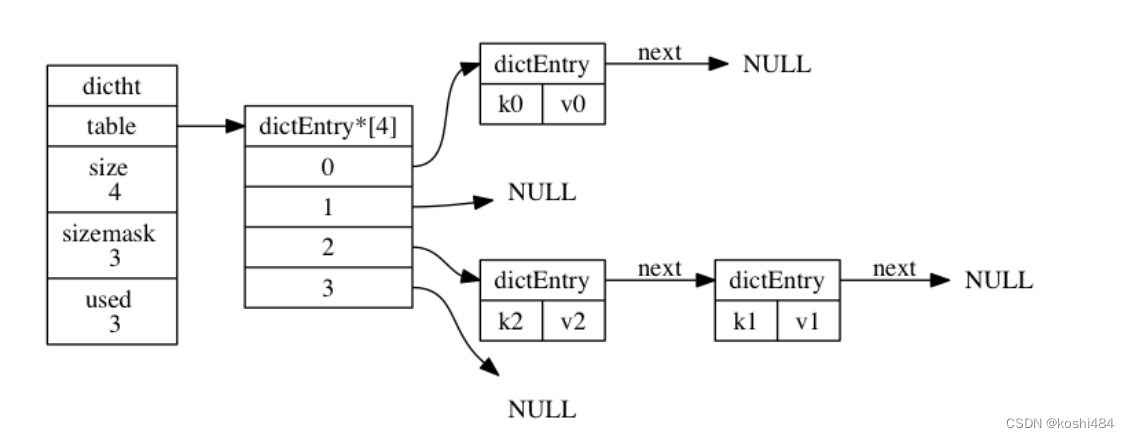
Redis设计与实现(3)字典
Redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每一个哈希表节点就保存了字典中的一个键值对 redis字典所使用的哈希表由dict.h/dictht typedef struct dictht{//哈希表数组dictEntry **table;//哈希表大小unsigned long si…...
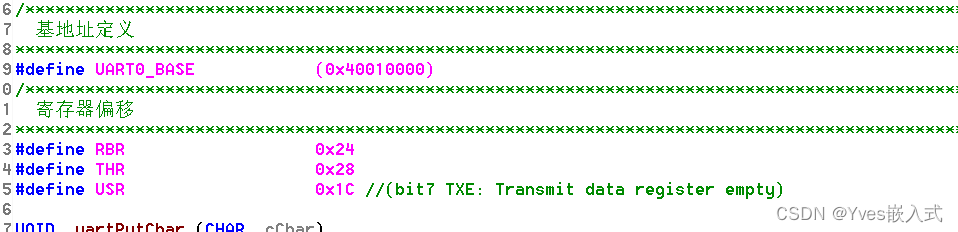
STM32MP157D BSP
一,全志R16、IMX6ULL和STM32MP157D启动相关 1,IMX6ULL是EMMC启动后,通过uboot fat命令的load进内存进行启动测试 2,openedv应该也是参考的官方的板子,类似调试口等均应该是一致的,所以目前就是用正点原子…...

最新SQL注入漏洞修复建议
点击星标,即时接收最新推文 本文选自《web安全攻防渗透测试实战指南(第2版)》 点击图片五折购书 SQL注入漏洞修复建议 常用的SQL注入漏洞的修复方法有两种。 1.过滤危险字符 多数CMS都采用过滤危险字符的方式,例如&…...

新人FPGA验证书籍推荐
1、FPGA之道 推荐理由:FPGA基础知识讲解全面,可以作为参考书时常翻阅; 2、Verilog数字系统设计教程 推荐理由:FPGA语法详细的介绍,案例比较有代表性; 工具类书籍推荐: 3、ModelSim电子系统…...
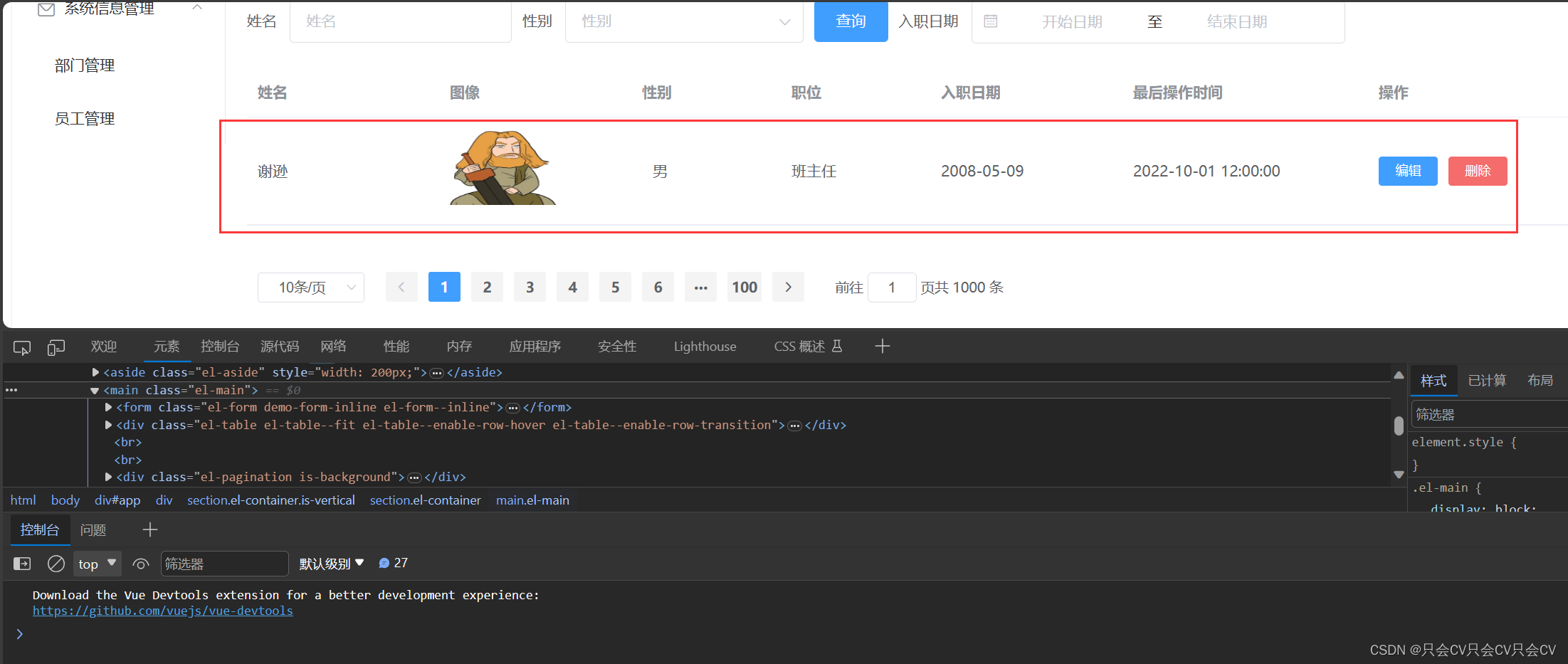
TypeError: data.reduce is not a function:数据类型不匹配
错误展示: 错误分析: 首先来看看前端代码:我表格绑定的数据模型是tableData,而我tableData定义的是一个数组 其次看看后端给的数据: 传递的是一个对象,而不是一个数组! 这样原因就找出了&…...
出租屋智能视频监控系统方案:全面保卫租客安全
除了我们常见的家庭、社区、园区等智能监控,出租房作为很多人的暂住所也极易发生盗窃等事件,为保障大众租户的财产安全,旭帆科技特地针对出租屋制定了智能监控系统方案。 1、安装智能安防摄像头 高清晰度、夜视功能良好的智能摄像头…...

代码解读-自然语言处理
目录 demo3文本转为向量代码解读给出每一步的输出 demo3文本转为向量 代码 from tensorflow.keras.preprocessing.text import Tokenizer # 标记器(每一个词,以我们的数值做映射,)words [LaoWang has a Wechat account., He is not a nice person., …...

docker指令
镜像操作: # 搜索镜像 docker search image_name # 搜索结果过滤:是否是官方 docker search --filter --filter is-official image_name # 搜索结果过滤:是否是自动化构建 docker search --filter --filter is-automated image_name # 搜索结…...
【MySql】9- 实践篇(七)
文章目录 1. 一主多从的主备切换1.1 基于位点的主备切换1.2 GTID1.3 基于 GTID 的主备切换1.4 GTID 和在线 DDL 2. 读写分离问题2.1 强制走主库方案2.2 Sleep 方案2.3 判断主备无延迟方案2.4 配合 semi-sync方案2.5 等主库位点方案2.6 GTID 方案 3. 如何判断数据库是否出问题了…...

Maven compile时报错 系统资源不足,出现OOM:GC overhead limit exceeded
今天在对项目进行Maven clean compile的时候,报出了如下的错误, 系统资源不足。 有关详细信息,请参阅一下堆栈跟踪。 java.lang.OutOfMemoryError: GC overhead limit exceededat java.util.EnumSet.noneOf(EnumSet.java:115)at com.sun.too…...

启动内核ip转发和其他优化
1.临时修改 echo 1 > /proc/sys/net/ipv4/ip_forward echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse 2.配置文件修改 vim /etc/sysctl.conf net.ipv4.ip_forward 1 net.ipv4.tcp_tw_reuse 1 vm.swappiness 0 kernel.sysrq 1 net.ipv4.neigh.default.gc_stale_t…...
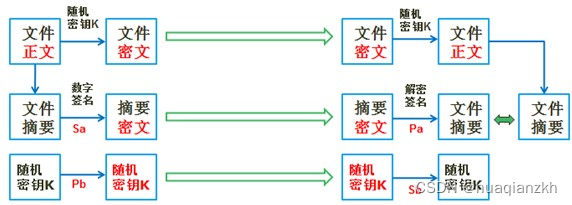
信息安全技术
1.与区块链相关的技术 区块链技术的核心是一系列的信息安全技术,其体系结构为: 区块链技术核心相关技术:A..非对称加密 B.时间戳 C.哈希函数 D.智能合约 E.POS 2.哈希函数 哈希算法 MD5SHA 哈希算法作用 用于保障信息完…...

SQL 选择数据库 USE语句
SQL 选择数据库 USE语句 当SQL Schema中有多个数据库时,在开始操作之前,需要选择一个执行所有操作的数据库。 SQL USE语句用于选择SQL架构中的任何现有数据库。 句法 USE语句的基本语法如下所示 : USE DatabaseName;数据库名称在RDBMS中必须是唯一的。…...
FL Studio21版无限破解版下载 软件内置破解补丁
FL Studio是一款非常好用方便的音频媒体制作工具,它的功能是非常的强大全面的,想必那些喜欢音乐创作的朋友们应该都知道这款软件是多么的好用吧,它还能够给用户们带来更多的创作灵感,进一步加强提升我们的音乐制作能力。该软件还有…...
【代码随想录】算法训练计划02
1、977. 有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 输入:nums [-4,-1,0,3,10] 输出:[0,1,9,16,100] 思路: 这题思路在于——双指针…...

hive针对带有特殊字符非法json数据解析
一、背景 有的时候前端或者后端进行埋点日志,会把json里面的数据再加上双引号,或者特殊字符,在落日志的时候,组装的格式就不是正常的json数据了,我们就需要将带有特殊字符的json数据解析成正常的json数据。 二、正则…...

【C++进阶之路】第三篇:二叉搜索树 kv模型
文章目录 一、二叉搜索树1.二叉搜索树概念2.二叉搜索树操作3.二叉搜索树的实现 二、二叉搜索树的应用1.kv模型2.kv模型的实现 三、 二叉搜索树的性能分析 一、二叉搜索树 1.二叉搜索树概念 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性…...
【Oracle】Navicat Premium 连接 Oracle的两种方式
Navicat Premium 使用版本说明 Navicat Premium 版本 11.2.16 (64-bit) 一、配置OCI 1.1 配置OCI环境变量 1.1.2 设置\高级系统设置 1.1.2 系统属性\高级\环境变量(N) 1.1.3 修改/添加系统变量 ORACLE_HOME ORACLE_HOME D:\app\root\product\12.1.0\dbhome_11.1.4 添加系…...

在python里如何实现switch函数的功能
在许多编程语言中,包括Python,都提供了switch语句或类似的功能来根据不同的条件执行不同的代码块。然而,Python本身并没有内置的switch语句,但是您可以使用其他方式来实现类似的功能。下面是一种常见的方法: 使用if-e…...

开源显示控制新纪元:ColorControl打破设备壁垒的技术实践
开源显示控制新纪元:ColorControl打破设备壁垒的技术实践 【免费下载链接】ColorControl Easily change NVIDIA display settings and/or control LG TVs 项目地址: https://gitcode.com/gh_mirrors/co/ColorControl 在数字内容消费多元化的今天,…...

打造你的专属数字伙伴:BongoCat虚拟桌宠完全指南 [特殊字符]
打造你的专属数字伙伴:BongoCat虚拟桌宠完全指南 🐱 【免费下载链接】BongoCat 🐱 跨平台互动桌宠 BongoCat,为桌面增添乐趣! 项目地址: https://gitcode.com/gh_mirrors/bong/BongoCat 你是否曾幻想过在单调的…...

新手福音:通过快马生成wsl2入门项目,轻松迈出linux开发第一步
作为一个刚接触Linux开发的新手,我最近在尝试使用WSL2搭建开发环境时遇到了不少麻烦。从安装配置到基础命令学习,每一步都让我这个Windows用户感到手足无措。直到发现了InsCode(快马)平台,它帮我生成了一套完整的WSL2入门项目,让我…...
Pixel Couplet Gen 保姆级部署教程:VSCode远程开发环境搭建
Pixel Couplet Gen 保姆级部署教程:VSCode远程开发环境搭建 1. 前言:为什么选择VSCode远程开发 如果你正在使用星图GPU平台上的Pixel Couplet Gen服务,可能会遇到一个常见问题:如何在本地高效地开发和调试对联生成项目ÿ…...

第八章:实战项目案例
第八章:实战项目案例 8.1 项目一:Todo 应用(Vue 3 Pinia) 项目初始化 npm create vitelatest todo-app -- --template vue cd todo-app npm install pinia npm install -D vitejs/plugin-vue项目结构 todo-app/ ├── src/ …...

TCC-G15散热控制实战指南:释放Dell游戏本性能潜力
TCC-G15散热控制实战指南:释放Dell游戏本性能潜力 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 一、问题发现:游戏本散热困境的技术根…...

Natron Rotoscoping与跟踪技术:专业影视特效制作终极指南
Natron Rotoscoping与跟踪技术:专业影视特效制作终极指南 【免费下载链接】Natron Open-source video compositing software. Node-graph based. Similar in functionalities to Adobe After Effects and Nuke by The Foundry. 项目地址: https://gitcode.com/gh_…...

wan2.1-vae高性能部署:TensorRT优化+FP16量化提速与显存占用实测
wan2.1-vae高性能部署:TensorRT优化FP16量化提速与显存占用实测 1. 项目背景与价值 wan2.1-vae是基于Qwen-Image-2512模型构建的高性能图像生成平台,在实际应用中面临两个核心挑战: 生成高分辨率图像时推理速度慢(单张2048x204…...

如何将Rust二进制文件大小减少70%:min-sized-rust与主流优化方案全对比
如何将Rust二进制文件大小减少70%:min-sized-rust与主流优化方案全对比 【免费下载链接】min-sized-rust 🦀 How to minimize Rust binary size 📦 https://github.com/johnthagen/min-sized-rust 项目地址: https://gitcode.com/gh_mirror…...

黑丝空姐-造相Z-Turbo构建AI编程助手:自动生成前端组件配图
黑丝空姐-造相Z-Turbo构建AI编程助手:自动生成前端组件配图 想象一下这个场景:你正在为一个航空公司的内部管理系统编写前端代码,需要创建一个“机组人员资料卡”组件。你已经写好了HTML结构和CSS样式,但卡在了头像占位符上——是…...