Elasticsearch中使用join来进行父子关联
在使用关系数据库进行开发的过程中,你可能会经常使用外键来表示父表和子表之间的关联关系,在Elasticsearch中,有哪些方法可以用来让开发者解决索引之间一对多和多对多的关联关系的问题呢
1 使用对象数组存在的问题
你可以很方便地把一个对象以数组的形式放在索引的字段中。下面的请求将建立一个订单索引,里面包含对象字段“goods”,它用来存放订单包含的多个商品的数据,从而在订单和商品之间建立起一对多的关联。
PUT order-obj-array
{"mappings": {"properties": {"orderid": {"type": "integer"},"buyer": {"type": "keyword"},"order_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"goods": {"properties": {"goodsid": {"type": "integer"},"goods_name": {"type": "keyword"},"price": {"type": "double"},"produce_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"}}}}}
}
现在,向这个索引中添加一条订单数据,里面包含两个商品的数据。
PUT order-obj-array/_doc/1
{"orderid": "1","buyer": "tom","order_time": "2020-11-04 00:00:00","goods": [{"goodsid": "1","goods_name": "milk","price": 5.2,"produce_time": "2020-10-04 00:00:00"},{"goodsid": "2","goods_name": "juice","price": 8.2,"produce_time": "2020-10-12 00:00:00"}]
}
这样做虽然可以把商品数据关联到订单数据中,但是在做多条件搜索的时候会出现问题,比如下面的布尔查询相关代码,其中包含两个简单的match搜索条件。
POST order-obj-array/_search
{"query": {"bool": {"must": [{"match": {"goods.goods_name": "juice"}},{"match": {"goods.produce_time": "2020-10-04 00:00:00"}}]}}
}
从业务的角度讲,由于“juice”的生产日期是“2020-10-12 00:00:00”,所以这一搜索不应该搜到订单数据,然而实际上却能搜到,代码如下。
"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.3616575,"hits" : [{"_index" : "order-obj-array","_type" : "_doc","_id" : "1","_score" : 1.3616575,"_source" : {"orderid" : "1","buyer" : "tom","order_time" : "2020-11-04 00:00:00","goods" : [{"goodsid" : "1","goods_name" : "milk","price" : 5.2,"produce_time" : "2020-10-04 00:00:00"},{"goodsid" : "2","goods_name" : "juice","price" : 8.2,"produce_time" : "2020-10-12 00:00:00"}]}}]}
之所以会产生这种效果,是因为Elasticsearch在保存对象数组的时候会把数据展平,产生类似下面代码的效果。
"goods.goods_name" : [ "milk", "juice" ],"goods.produce_time" : [ "2020-10-04 00:00:00", "2020-10-12 00:00:00" ]
这导致的直接后果是你无法将每个商品的数据以独立整体的形式进行检索,使得检索结果存在错误。
2、在索引中使用join字段
PUT order-join
{"settings": {"number_of_shards": "5","number_of_replicas": "1"},"mappings": {"properties": {"orderid": {"type": "integer"},"buyer": {"type": "keyword"},"order_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"goodsid": {"type": "integer"},"goods_name": {"type": "keyword"},"price": {"type": "double"},"produce_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"my_join_field": {"type": "join","relations": {"order": "goods"}}}}
}
可以看出这个映射包含订单父文档和商品子文档的全部字段,并且在末尾添加了一个名为my_join_field的join字段。在relations属性中,定义了一对父子关系:order是父关系的名称,goods是子关系的名称。
由于父文档和子文档被写进了同一个索引,在添加索引数据的时候,需要指明是在为哪个关系添加文档。先添加一个父文档,它是一条订单数据,在这条数据中把join字段的关系名称指定为order,表明它是一个父文档。
PUT order-join/_doc/1
{"orderid": "1","buyer": "tom","order_time": "2020-11-04 00:00:00","my_join_field": {"name":"order"}
}
然后,为该订单数据添加两个子文档,也就是商品数据。
PUT order-join/_doc/2?routing=1
{"goodsid": "1","goods_name": "milk","price": 5.2,"produce_time": "2020-10-04 00:00:00","my_join_field": {"name": "goods","parent": "1"}
}
PUT order-join/_doc/3?routing=1
{"goodsid": "2","goods_name": "juice","price": 8.2,"produce_time": "2020-10-12 00:00:00","my_join_field": {"name": "goods","parent": "1"}
}
在添加子文档时,有两个地方需要注意。一是必须使用父文档的主键作为路由值,由于订单数据的主键是1,因此这里使用1作为路由值,这能确保子文档被分发到父文档所在的分片上。如果路由值设置错误,搜索的时候就会出现问题。
二是在join字段my_join_field中,要把name设置为goods,表示它是一个子文档,parent要设置为父文档的主键,类似于一个外键。由于join字段中每个子文档是独立添加的,你可以对某个父文档添加、删除、修改某个子文档,嵌套对象则无法实现这一点。由于写入数据时带有路由值,如果要修改主键为3的子文档,修改时也需要携带路由值,代码如下。
POST order-join/_update/3?routing=1
{"doc": {"price": 18.2}
}
2.2 join字段的搜索
由于join类型把父、子文档都写入了同一个索引,因此如果你需要单独检索父文档或者子文档,只需要用简单的term查询就可以筛选出它们。
POST order-join/_search
{"query": {"term": {"my_join_field": "goods"}}
}
可见,整个搜索过程与普通的索引过程没有什么区别。但是包含join字段的索引支持一些用于检索父子关联的特殊搜索方式。例如,以父搜子允许你使用父文档的搜索条件查出子文档,以子搜父允许你使用子文档的搜索条件查出父文档,父文档主键搜索允许使用父文档的主键值查出与其存在关联的所有子文档。接下来逐个说明。
2.3.以父搜子
以父搜子指的是使用父文档的条件搜索子文档,例如,你可以用订单的购买者数据作为条件搜索相关的商品数据。
POST order-join/_search
{"query": {"has_parent": {"parent_type": "order","query": {"term": {"buyer": {"value": "tom"}}}}}
}
在这个请求体中,把搜索类型设置为has_parent,表示这是一个以父搜子的请求,参数parent_type用于设置父关系的名称,在查询条件中使用term query检索了购买者tom的订单,但是返回的结果是tom的与订单关联的商品列表,如下所示。
"hits" : [{"_index" : "order-join","_type" : "_doc","_id" : "2","_score" : 1.0,"_routing" : "1","_source" : {"goodsid" : "1","goods_name" : "milk","price" : 5.2,"produce_time" : "2020-10-04 00:00:00","my_join_field" : {"name" : "goods","parent" : "1"}}},{"_index" : "order-join","_type" : "_doc","_id" : "3","_score" : 1.0,"_routing" : "1","_source" : {"goodsid" : "2","goods_name" : "juice","price" : 18.2,"produce_time" : "2020-10-12 00:00:00","my_join_field" : {"name" : "goods","parent" : "1"}}}]
需要记住,以父搜子的时候提供的查询条件用于筛选父文档,返回的结果是对应的子文档。如果需要在搜索结果中把父文档也一起返回,则需要加上inner_hits参数。
POST order-join/_search
{"query": {"has_parent": {"parent_type": "order","query": {"term": {"buyer": {"value": "tom"}}},"inner_hits": {}}}
}
2.4以子搜父
以子搜父跟以父搜子相反,提供子文档的查询条件会返回父文档的数据。例如:
POST order-join/_search
{"query": {"has_child": {"type": "goods","query": {"match_all": {}}}}
}
上面的请求把搜索类型设置为has_child,在参数type中指明子关系的名称,它会返回所有子文档对应的父文档。但是如果一个父文档没有子文档,则其不会出现在搜索结果中。相关代码如下。
"hits" : [{"_index" : "order-join","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"orderid" : "1","buyer" : "tom","order_time" : "2020-11-04 00:00:00","my_join_field" : {"name" : "order"}}}]
你还可以根据子文档匹配搜索结果的数目来限制返回结果,例如:
POST order-join/_search
{"query": {"has_child": {"type": "goods","query": {"match_all": {}},"max_children": 1}}
}
上述代码表示,如果子文档在query参数中指定的搜索结果数量大于1,就不返回它对应的父文档。你还可以使用min_children参数限制子文档匹配数目的下限。
3.5父文档主键搜索
父文档主键搜索只需要提供父文档的主键就能返回该父文档所有的子文档。例如,你可以提供订单的主键返回该订单所有的子文档。
POST order-join/_search
{"query": {"parent_id": {"type": "goods","id": "1"}}
}
其中,type用于指定子文档的关系名称,id表示父文档的主键,该查询请求会搜出订单号为1的所有商品的数据,如下所示。
3 join字段的聚集
join字段有两种专门的聚集方式,一种是children聚集,它可用于统计每个父文档的子文档数据;另一种是parent聚集,它可用于统计每个子文档的父文档数据。
3.1. children聚集
你可以在一个父文档的聚集中嵌套一个children聚集,这样就可以在父文档的统计结果中加入子文档的统计结果。为了演示效果,下面再添加两条测试数据。
POST order-join/_doc/4
{"orderid": "4","buyer": "mike","order_time": "2020-12-04 00:00:00","my_join_field": {"name":"order"}
}
POST order-join/_doc/5?routing=4
{"goodsid": "5","goods_name": "milk","price": 3.6,"produce_time": "2020-11-04 00:00:00","my_join_field": {"name": "goods","parent": "4"}
}
然后发起一个聚集请求,统计出每个购买者购买的商品名称和数量。
POST order-join/_search
{"query": {"match_all": {}},"aggs": {"orders": {"terms": {"field": "buyer","size": 10},"aggs": {"goods_data": {"children": {"type": "goods"},"aggs": {"goods_name": {"terms": {"field": "goods_name","size": 10}}}}}}}
}
可以看到,这个请求首先对buyer做了词条聚集,它会得到每个购买者的订单统计数据,为了获取每个购买者购买的商品详情,在词条聚集中嵌套了一个children聚集,在其中指定了子文档的关系名,然后继续嵌套一个词条聚集统计每个商品的数据,得到每个购买者的商品列表。结果如下。
"aggregations" : {"orders" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "mike","doc_count" : 1,"goods_data" : {"doc_count" : 1,"goods_name" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "milk","doc_count" : 1}]}}},{"key" : "tom","doc_count" : 1,"goods_data" : {"doc_count" : 2,"goods_name" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "juice","doc_count" : 1},{"key" : "milk","doc_count" : 1}]}}}]}}
3.2. parent聚集
parent聚集跟children聚集相反,你可以在子文档的聚集中嵌套一个parent聚集,就能得到每个子文档数据对应的父文档统计数据。例如:
POST order-join/_search
{"aggs": {"goods": {"terms": {"field": "goods_name","size": 10},"aggs": {"goods_data": {"parent": {"type": "goods"},"aggs": {"orders": {"terms": {"field": "buyer","size": 10}}}}}}}
}
上面的请求首先在goods_name字段上对子文档做了词条聚集,会得到每个商品的统计数据,为了查看每个商品的购买者统计数据,在词条聚集中嵌套了一个parent聚集,需注意该聚集需要指定子关系的名称,而不是父关系的名称。最后在parent聚集中,又嵌套了一个词条聚集,以获得每种商品的购买者统计数据,结果如下。
"aggregations" : {"goods" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "milk","doc_count" : 2,"goods_data" : {"doc_count" : 2,"orders" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "mike","doc_count" : 1},{"key" : "tom","doc_count" : 1}]}}},{"key" : "juice","doc_count" : 1,"goods_data" : {"doc_count" : 1,"orders" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "tom","doc_count" : 1}]}}}]}
最后来总结一下join字段在解决父子关联时的优缺点。它允许单独更新或删除子文档,嵌套对象则做不到;建索引时需要先写入父文档的数据,然后携带路由值写入子文档的数据,由于父、子文档在同一个分片上,join关联查询的过程没有网络开销,可以快速地返回查询结果。但是由于join字段会带来一定的额外内存开销,建议使用它时父子关联的层级数不要大于2,它在子文档的数量远超过父文档的时比较适用。
3.3 在应用层关联数据
所谓在应用层关联数据,实际上并不使用任何特别的字段,直接像关系数据库一样在建模时使用外键字段做父子关联,做关联查询和统计时需要多次发送请求。这里还是以订单和商品为例,需要为它们各建立一个索引,然后在商品索引中添加一个外键字段orderid来指向订单索引,代码如下。
PUT orders
{"mappings": {"properties": {"orderid": {"type": "integer"},"buyer": {"type": "keyword"},"order_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"}}}
}
PUT goods
{"mappings": {"properties": {"goodsid": {"type": "integer"},"goods_name": {"type": "keyword"},"price": {"type": "double"},"produce_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"orderid": {"type": "integer"}}}
}
然后向两个索引中添加数据。
PUT orders/_doc/1
{"orderid": "1","buyer": "tom","order_time": "2020-11-04 00:00:00"
}
PUT goods/_bulk
{"index":{"_id":"1"}}
{"goodsid":"1","goods_name":"milk","price":5.2,"produce_time":"2020-10-04 00:00:00","orderid":1}
{"index":{"_id":"2"}}
{"goodsid":"2","goods_name":"juice","price":8.2,"produce_time":"2020-10-12 00:00:00","orderid":1}
此时,如果你想获得以父搜子的效果,就得发送两次请求,例如搜索tom的所有订单以及它们包含的商品,先使用term查询tom的所有订单数据。
POST orders/_search
{"query": {"term": {"buyer": {"value": "tom"}}}
}
然后使用搜索结果返回的orderid去搜索商品索引。
POST goods/_search
{"query": {"terms": {"orderid": ["1"]}}
}
可以看到,这样做也能达到目的,但是如果第一次搜索返回的orderid太多就会引起性能下降甚至出错。总之,在应用层关联数据的优点是操作比较简单,缺点是请求次数会变多,如果用于二次查询的条件过多也会引起性能下降,在实际使用时需要根据业务逻辑来进行权衡。
相关文章:

Elasticsearch中使用join来进行父子关联
在使用关系数据库进行开发的过程中,你可能会经常使用外键来表示父表和子表之间的关联关系,在Elasticsearch中,有哪些方法可以用来让开发者解决索引之间一对多和多对多的关联关系的问题呢 1 使用对象数组存在的问题 你可以很方便地把一个对象…...

提供一个springboot使用h2数据库是无法使用脚本并报错的处理方案
环境描述 springboot 2.6.2 mybatis-plus-boot-starter 3.5.1 mysql-connector-java 8.0.11 查阅了很多博客,说是使用spring.datasource.schema或者spring.sql.init.schema-locations指定脚本也均无效。不使用启动脚本,启动后在h2控制台ÿ…...

【组合计数】CF1866 H
Problem - H - Codeforces 题意 思路 不知道这种trick叫什么,昨天VP刚遇到过 设 f[x] 为恰好有一个最大值为 x 的方案数,我们要求这个,那就设 g[x] 为 至少有一个最大值为 x 的方案数,那么答案就是 f[x] g[x] - g[x - 1] 这里…...
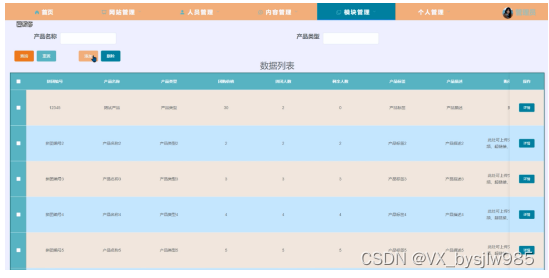
JavaSpringbootmysql农产品销售管理系统47627-计算机毕业设计项目选题推荐(附源码)
摘 要 随着互联网趋势的到来,各行各业都在考虑利用互联网将自己推广出去,最好方式就是建立自己的互联网系统,并对其进行维护和管理。在现实运用中,应用软件的工作规则和开发步骤,采用Java技术建设农产品销售管理系统。…...
一文5000字从0到1使用Jmeter实现轻量级的接口自动化测试(图文并茂)
接口测试虽然作为版本的一环,但是也是有一套完整的体系,有接口的功能测试、性能测试、安全测试;同时,由于接口的特性,接口的自动化低成本高收益的,使用一些开源工具或一些轻量级的方法,在测试用…...

蓝桥杯每日一题0223.10.23
第几天 - 蓝桥云课 (lanqiao.cn) 题目描述 题目分析 简单枚举(用k来记录经过的天数) #include<bits/stdc.h> using namespace std; bool is_ren(int n) {if(n % 400 0 || (n % 4 0 && n % 100 ! 0))return true;return false; } int …...

php危险函数及rce漏洞
php代码执行语句 eval() eval()语句 eval() 会将符合PHP 语法规范字符串当作php 代码执行。 <meta charset"UTF-8"> <pre><?php$dd$_REQUEST[dd];eval($dd);?>可以执行php代码 也可以套一层system执行系统操作指令 assert()函数 assert() …...

4. 寻找两个正序数组的中位数
1. 题目 见 寻找两个正序数组的中位数 2. 解题思路 首先一看到题目说是正序数组,且时间复杂度要求在对数级别,所以自然想到了双指针中的二分法。 首先来看一下,假设输入是这两个数组,那么将其逻辑合并成一个大数组的话&#x…...

Stable Diffusion AI绘图
提示词: masterpiece, best quality, 1girl, (anime), (manga), (2D), half body, perfect eyes, both eyes are the same, Global illumination, soft light, dream light, digital painting, extremely detailed CGI anime, hd, 2k, 4k background 反向提示词&…...

MR混合现实情景实训教学系统在旅游管理专业中的应用
在旅游管理专业中,MR混合现实情景实训教学系统的主要应用包括但不限于以下几个方面: 1. 实地考察的替代:对于一些无法实地考察的景点或设施,学生可以通过MR系统进行虚拟参观,从而了解其实际情况。这不仅可以减少时间和…...

CentOS 使用线程库Pthread 库
1、Pthread 库说明 pthread 库是Linux系统默认线程库。 在Linux 系统环境中,编辑C/C程序使用pthread 库,需要添加对应的头文件,并链接pthread库。 #include<pthread.h> 2、Pthread 库核心方法 pthread_create 函数定义࿱…...

#力扣:LCP 01. 猜数字@FDDLC
LCP 01. 猜数字 - 力扣(LeetCode) 一、Java class Solution {public int game(int[] guess, int[] answer) {int cnt0;for(int i0;i<3;i){if(guess[i]answer[i])cnt;}return cnt;} }...

kafka丢数据的原因
目录 背景kafkaClient代码消息丢失的可能原因broker is downRD_KAFKA_MSG_SIZE_TOO_LARGE分区问题Kafka Broker的处理能力无法跟上,可能会出现以下情况 Some基础知识补充 背景 采用的client是librdkafka,在producerClient Send的数据时候发现会有数据丢…...

音视频编解码技术学习笔记
音视频编解码技术是音视频处理领域的重要部分,涉及到对原始音视频数据的压缩、编码和解码。以下是音视频编解码技术的一些要点和难点: 要点: 压缩技术 音视频编解码的核心是对原始音视频数据进行压缩,以减小文件大小和传输带宽…...

[C#基础训练]FoodRobot食品管理部分代码-1
代码参考: using System;namespace FoodRobotDemo { public class FoodRobot{private int[] foodCountArr;private string[] foodNameArr;public FoodRobot(){foodCountArr new int[3];foodNameArr new string[3] {"航天","航空","宇航" };}…...

YModem协议总结
《YModem协议总结》 目录 第1章 YModem协议简介 4 1.1 基本介绍 4 1.2 YModem基本介绍 4 第2章 YModem传输协议 5 2.1 起始帧的数据格式 5 2.2 数据帧的数据格式 5 2.3 结束帧数据结构 6 2.4 文件传输过程 6 2.5 CRC的计算 7 附录A 附录 8 A.1 附录 8 第1章 YModem协议简…...
ElasticSearch(ES)8.1及Kibana在docker环境下如何安装
ES基本信息介绍 Elasticsearch(简称ES)是一个开源的分布式搜索和分析引擎,最初由Elastic公司创建。它属于Elastic Stack(ELK Stack)的核心组件之一,用于实时地存储、检索和分析大量数据。 以下是Elastics…...
常用Win32 API的简单介绍
目录 前言: 控制控制台程序窗口的指令: system函数: COORD函数: GetStdHandle函数: GetConsoleCursorInfo函数: CONSOLE_CURSOR_INFO函数: SetConsoleCursorInfo函数: SetC…...
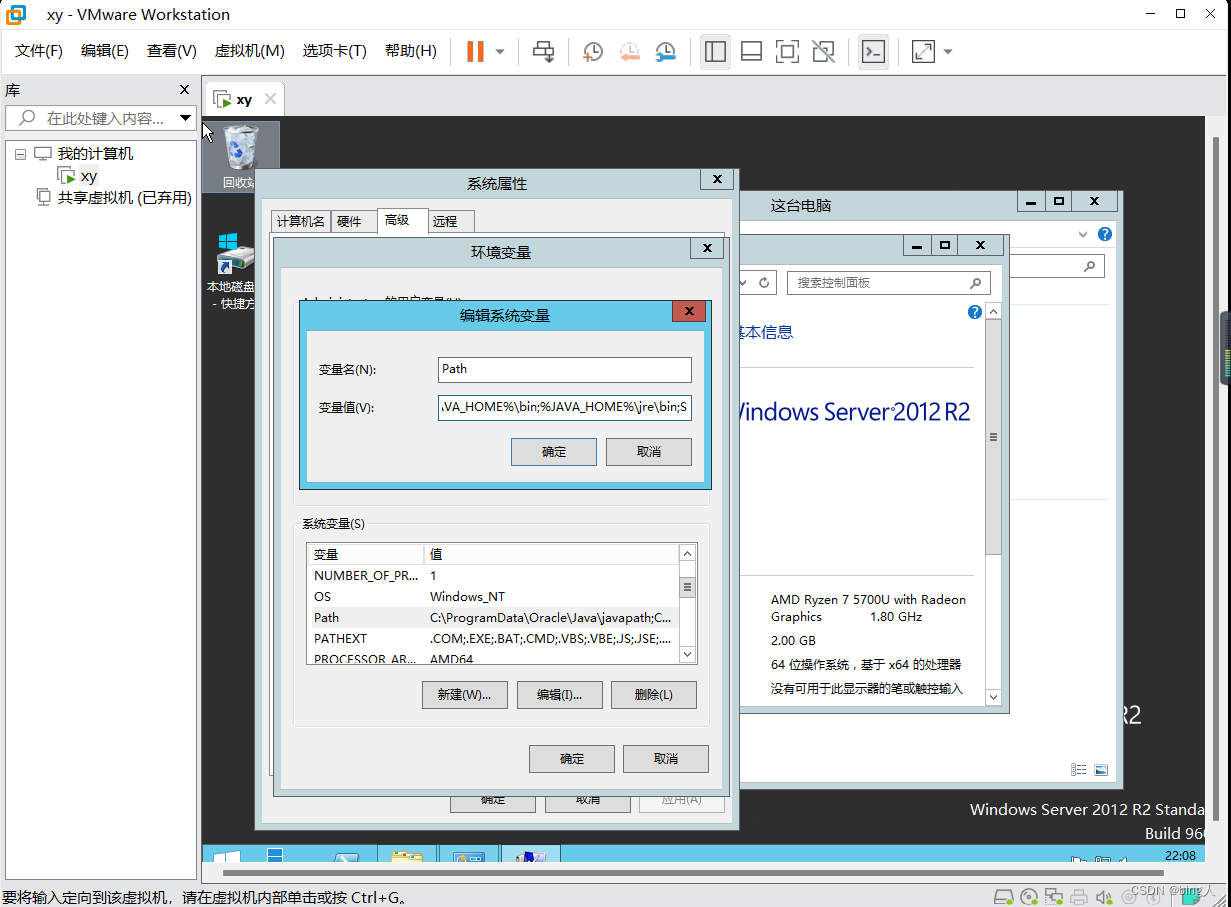
VM及WindowsServer安装
目录 一.操作系统的简介及常用的操作系统 二.windows的安装 安装VMWare虚拟机 注意点一 编辑 注意点二 三.安装配置Windows Server 2012 R2 四、虚拟机的环境配置及连接 1. 主机连接虚拟机 2. 虚拟机环境配置及共享 3. 环境配置 一.操作系统的简介及常用的操作系…...

操作系统【OS】调度算法对比图
FCFS SJF 高响应比 时间片轮转 多级反馈队列 可抢占? √ √ √ 队列内算法不一定 不可抢占? √ √ √ 队列内算法不一定 特点&优点 公平实现简单有利于长作业不利于短作业有利于CPU繁忙作业不利于IO繁忙作业 因为CPU繁忙型进程即…...

Mac NTFS读写完整解决方案:技术深度解析与高效部署指南
Mac NTFS读写完整解决方案:技术深度解析与高效部署指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management f…...

如何十分钟掌握Diablo Edit2:暗黑破坏神II角色编辑器的完整指南
如何十分钟掌握Diablo Edit2:暗黑破坏神II角色编辑器的完整指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾为暗黑破坏神II中属性点分配错误而烦恼?是否厌倦了…...

Hunyuan-MT-7B功能体验:少数民族语言翻译效果实测与对比
Hunyuan-MT-7B功能体验:少数民族语言翻译效果实测与对比 1. 引言:少数民族语言翻译的技术挑战 在全球化与数字化浪潮中,语言障碍始终是跨文化交流的重要壁垒。对于主流语言如英语、汉语等,机器翻译技术已相对成熟。然而…...

Qwen3-ForcedAligner-0.6B模型量化实战:减小部署体积
Qwen3-ForcedAligner-0.6B模型量化实战:减小部署体积 语音处理中的强制对齐技术,能够精确匹配文本与语音的时间戳,是语音识别、字幕生成等应用的关键环节。Qwen3-ForcedAligner-0.6B作为一款基于大语言模型的强制对齐工具,支持11种…...

S2-Pro跨语言编程能力评测:根据中文注释生成多国语言代码
S2-Pro跨语言编程能力评测:根据中文注释生成多国语言代码 1. 评测背景与目标 在软件开发领域,跨语言编程能力正变得越来越重要。开发者经常需要在不同技术栈间切换,或者将一个语言的算法实现迁移到另一个语言。传统方式下,这需要…...

简单的kail中使用docker搭建vulhub靶场
我这里kali版本是6.12.38 一,安装docker 提权:sudo su 更新一手软件资源 命令:apt-get update ┌──(root㉿kali)-[/home/kali/Desktop] └─# apt-get update 获取:1 http://mirrors.ustc.edu.cn/kali kali-rolling InRelease [34.0 kB]…...

【机器人】ROS2配置solidworks模型转换的URDF文件
🙇♀ 安装solidworks_urdf插件 地址 在添加过点和坐标系后,点击工具->tools(在最下面) 如何转为URDF请看这个视频点击 ☕ 为ROS2配置 安装相关依赖 sudo apt install ros-humble-joint-state-publisher-gui sudo apt install ros-humble-xacro…...

React Native Interactable终极指南:TouchesInside与静态交互对比详解
React Native Interactable终极指南:TouchesInside与静态交互对比详解 【免费下载链接】react-native-interactable Experimental implementation of high performance interactable views in React Native 项目地址: https://gitcode.com/gh_mirrors/re/react-na…...

gallery用户留存技巧:提高本地AI平台用户的活跃度
gallery用户留存技巧:提高本地AI平台用户的活跃度 【免费下载链接】gallery A gallery that showcases on-device ML/GenAI use cases and allows people to try and use models locally. 项目地址: https://gitcode.com/GitHub_Trending/gallery44/gallery …...

ADXL345嵌入式驱动开发:I²C/SPI寄存器配置与FreeRTOS中断集成
1. ADXL345加速度传感器库深度解析:面向嵌入式工程师的底层驱动开发指南ADXL345是Analog Devices公司推出的超低功耗、高分辨率(13位)、数字输出三轴加速度传感器,广泛应用于姿态检测、振动监测、跌倒报警、工业预测性维护及可穿戴…...