Kafka入门05——基础知识
目录
副本数据同步原理
HW和LEO的更新流程
第一种情况
第二种情况
数据丢失的情况
解决方案
Leader副本的选举过程
日志清除策略和压缩策略
日志清除策略
日志压缩策略
Kafka存储手段
零拷贝(Zero-Copy)
页缓存(Page Cache)
Kafka的消息可靠性

在ISR中,只要有一个Follower存活就能确保Commit的数据不会丢失。那如果分区所有副本都失效了,会发生什么?
无法确保Commit数据不丢失,会出现可用性和一致性问题。需要采取折中方案:
-
等待ISR中第一个“活”过来的副本,选举它为Leader。
-
选择第一个“活”过来的副本,但它不一定是Leader。
第一种方案的问题就是不可用的时间会相对较长。第二种方案的问题是不保证包含所有Commit的消息。所以往往采取的是第一种方案。
副本数据同步原理
Kafka 的数据副本同步原理是确保消息的高可用性和数据冗余的关键机制。在 Kafka 中,每个分区通常都有多个副本,其中一个是领导副本(Leader Replication)负责读写操作,其他是追随者副本(Follower Replication)用于数据备份和容错。
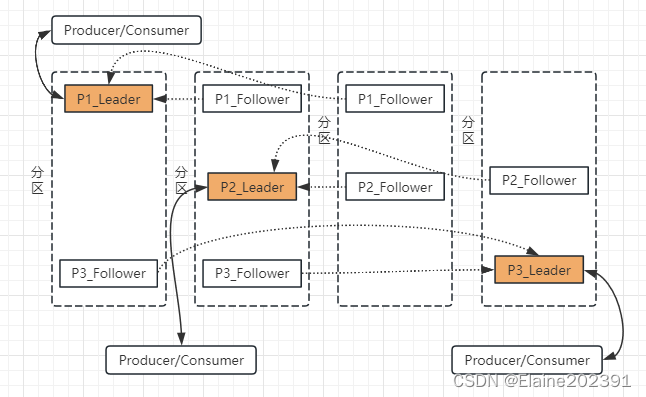
以其中一个分区的副本同步通信举例,当producer将消息发布到某个partition时:

-
通过zookeeper找到分区的leader,将消息发送给leader(无论多少个副本,生产者只将消息发送给leader)。
-
leader将消息写入本地log。每个follower从leader拉取数据,follower存储顺序与leader一致。
-
follower在收到消息并写入自身log后,向leader发送Ack。
-
leader收到ISR中所有的副本的Ack后,消息被认为commit成功,leader更新HW并向生产者发送Ack。
HW(High Water): 水位线。代表的是小于等于HW值的所有消息是已备份的。
LEO(Log End Offset):日志末端位移。代表的是下一条消息的位移,如LEO=10,表示已有[0,9]共10条消息。
HW和LEO的更新流程
初始状态的HW和LEO都是0。Leader中存放了一个表示follower的LEO值 remote leo也为0。
当前生产者没有发送消息,但是Follower会不断地向leader发送fetch请求,因为leader没有接收到消息,follower的fetch会阻塞。参数配置replicas.fetch.wait.,ax.ms决定阻塞时间。时间内,生产者发送消息给leader的话,fetch请求会被唤醒,让leader继续处理。

在初始状态下,会出现两种情况:
-
leader处理完生产者请求后,follower发送一个fetch请求。
-
follower的fetch请求阻塞时间内,leader收到生产者发送的请求
第一种情况
生产者发送一条消息,leader处理后,消息追加到本地log,更新LEO为1。
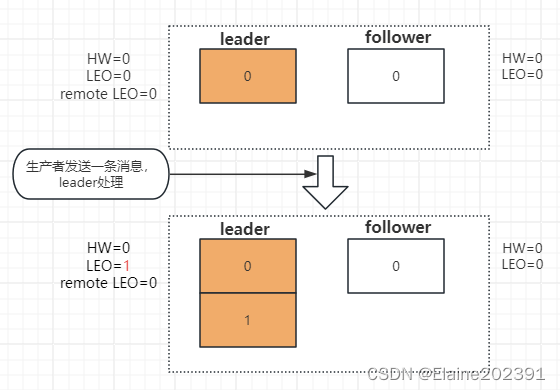
follower第一次发起fetch请求,offset=0;
leader收到后确认remote LEO为0,
HW由LEO和remote LEO的最小值决定,HW = 0,
leader回复response,包含消息和HW=0。
follower收到response,追加消息到本地log,更新LEO=1。
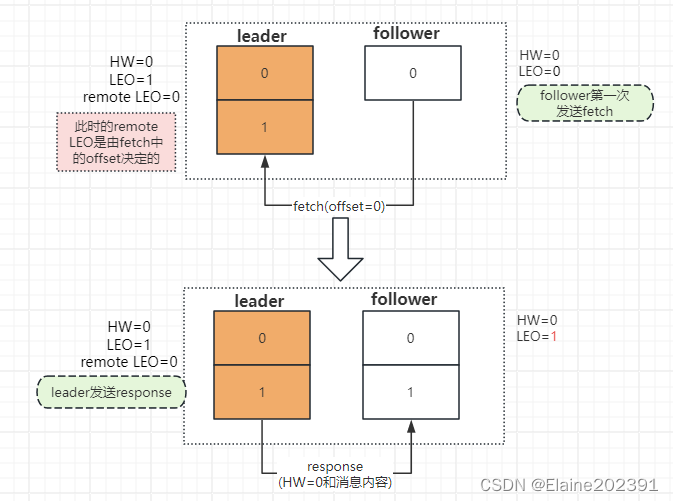
follower第二次发起fetch请求,offset=1;
leader收到后确认remote LEO为1,
HW由LEO和remote LEO的最小值决定,HW = 1,
leader回复response,包含消息(没有数据就返回空)和HW=1。
follower收到response,追加消息到本地log(有就写入本地日志),更新HW=1。
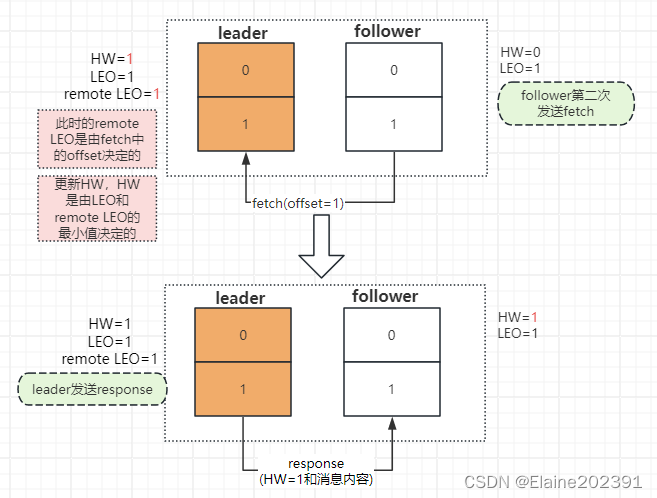
第一种情况到此就完成了数据同步,消费者就可以消费offset=1的这条消息了。
第二种情况
fetch在阻塞的过程中leader收到了生产者发送的消息,就会唤醒fetch请求,后面和第一种情况一致。
-
leader将消息写入本地日志,更新leader的LEO
-
唤醒follower的fetch请求
-
更新HW
数据丢失的情况
Kafka中min.insync.replicas=1默认设定ISR中的最小副本数为1,并且acks设置为-1(需要所有副本确认)才生效。
意思就是需要至少1个副本同步才能表示消息时提交的,当min.insync.replicas=1时,只要leader将消息写入log就认为是“已提交”,而延迟一轮fetch rpc更新HW值的设计使得follower HW的值是异步延迟更新的。
假设这个过程中,leader发生变更,那新leader中的HW值就有可能是过期的,使得“已提交” 的消息被删除。
acks表示生产者发送消息到broker上以后的确认之。
-
0:表示不需要确认。时延小风险大(server宕机,数据就会丢失)
-
1:表示只需要leader确认。时延小同时确保leader接收成功
-
all(-1):需要ISR所有replicas确认。速度慢,安全性最高,但ISR会缩小到只有一个replicas,也不一定能避免数据丢失。
解决方案
Kafka的0.11版本引入了leader epoch解决数据丢失问题。 leader epoch是一对值(epoch,offset),epoch从0递增,当leader变更会epoch+1,offset是对应的leader写入第一条消息的offset。
Epoch 的作用:
-
数据丢失恢复:Epoch 机制用于解决因为领导副本故障而导致的数据丢失问题。当一个新的领导副本被选定时,Kafka 会使用 Epoch 来确定哪些追随者副本具有相同的数据,并将数据从这些追随者副本中恢复。
-
数据冲突解决:Epoch 也用于解决数据冲突问题,确保只有具有最新数据的副本成为新的领导副本。
举个例子:
在分区的本地磁盘上持久化了一个/tmp/kafkalog/topic/leader-epoch-checkpoint的文件,文件的内容类似于[0,50],[1,89],[2,100]...leader broker会保存这样一个缓存,定期写入文件中。
当leader写log时,会尝试更新整个缓存。
-
如果leader首次写,缓存中新加一条数据。
-
如果leader不是首次写,那就不更新。
副本每次成为loader时都会查询这部分缓存,获取对应的leader版本的offset。
针对数据丢失的场景,就有了对应的解决办法:
-
follower宕机恢复后
-
leader没有发生改变:发送OffsetForLeaderEpochRequest请求给leader,leader返回LEO
-
leader发生改变:follower发送的Request中的epoch和leader不同,leader会去查找follower的epoch+1对应的StartOffset,也就是新leader的LEO,返回给follower。
-
-
leader宕机了,重新选举了leader:原本的follower就变成了leader,epoch从0变为了1,原本follower中的LEO值得到了保留。
Leader副本的选举过程
KafkaController会监听Zookeeper的/broker/ids节点路径,有broker挂了的时候,对应broker中分区的leader副本就需要重新选举。
选举策略:
-
优先从ISR列表中选取第一个作为leader副本,叫优先副本。
-
如果ISR列表为空,查看topic的unclean.leader.election.enable配置。
-
true:允许选择非ISR列表的副本作为leader,有可能数据丢失
-
false:不允许选择非ISR列表的副本作为leader,抛出异常,选举失败
-
-
在2的配置为true的基础上,选出一个leader副本,并且ISR列表只包含该leader副本。选举成功后,将leader和ISR其他副本信息写入该分区对应的Zookeeper路径上。
日志清除策略和压缩策略
日志清除策略
kafka的日志使用的分段存储,一方面能减少文件内容的大小,另一方面方便kafka日志清理。日志清理策略有两个:
-
根据消息的保留时间,超过指定时间的消息会被清理
-
根据存储的数据大小,当日志文件大于一定的阈值就删除最旧的消息。
kafka有一个后台线程,定期检查是否存在可以删除的消息。对应的两个参数配置:log.retention.bytes和log.retention.hours。消息默认保留时间是7天。
日志压缩策略
消息的保存方式是key-value的形式,消费者只关心相同的key最新的value,kafka的压缩原理就是后台启动Cleaner线程,定期将相同的key进行合并,保存最新的value。
Kafka存储手段
零拷贝(Zero-Copy)
零拷贝是一种技术,通过它可以将数据从一个缓冲区(如内存)传输到另一个缓冲区,而不需要在中间进行数据的复制。这可以提高数据传输的效率和降低CPU和内存的开销。在 Kafka 中,零拷贝技术用于以下几个方面:
-
生产者:Kafka 生产者使用零拷贝来将消息从内存传输到网络套接字,从而提高发送性能。
-
消费者:Kafka 消费者使用零拷贝来将消息从网络套接字传输到内存,从而提高接收性能。
-
磁盘写入:Kafka 使用零拷贝来将数据从内存缓冲区写入到磁盘,这可以提高磁盘写入的效率。
页缓存(Page Cache)
Kafka 使用操作系统的页缓存来管理磁盘上的数据。Page Cache 是操作系统的一部分,它将磁盘上的数据缓存在内存中,以便快速读取和写入。Kafka 利用了页缓存来加速磁盘的读写操作,提高了消息的持久性和性能。
具体来说,Kafka 将消息写入到磁盘时,首先将消息写入到操作系统的页缓存中,然后异步刷写到磁盘上。这样,Kafka 可以将多个小的写操作合并成更大的写操作,减少磁盘 I/O 操作的次数,提高写入性能。
另外,当 Kafka 消费者读取消息时,它可以从页缓存中读取消息,而不必每次都直接访问磁盘,这降低了读取的延迟。
Kafka的消息可靠性
消息的可靠性很难达到百分百完全可靠的地步,常常会用几个9作为衡量标准。kafka保证消息可靠性的手段:
-
分区和副本:Kafka 的消息被分布到多个分区中,每个分区通常有多个副本。这样即使其中一个节点或分区发生故障,消息仍然可以从其他节点或副本中获取,从而提高可用性和可靠性。
-
Leader-Follower 架构:每个分区都有一个领导副本(Leader)和多个追随者副本(Followers)。生产者写入消息到领导副本,然后领导副本负责将消息复制到追随者副本,确保数据冗余。
-
消息持久性:Kafka 使用文件系统和操作系统的缓存来提高消息的持久性。消息首先写入到文件系统缓存,然后异步刷写到磁盘,以避免写入性能的下降。
-
复制同步:Kafka 使用复制同步机制来确保数据同步。只有当追随者副本确认已成功复制数据后,生产者才会收到确认。
-
消息确认:生产者和消费者可以配置确认机制,确保消息的可靠性。生产者可以等待所有副本都确认成功后才发送确认,而消费者可以等待消息处理成功后才发送确认。
-
数据冗余:消息在多个副本之间进行冗余,如果一个副本出现故障,仍然可以从其他副本获取数据。
-
再均衡(Rebalance):在消费者组中,Kafka 使用再均衡机制来确保分区的重新分配,以提供高可用性和数据冗余。
-
持久性日志:Kafka 的日志文件具有持久性,即使 Kafka 服务重启,数据也不会丢失。
相关文章:
Kafka入门05——基础知识
目录 副本数据同步原理 HW和LEO的更新流程 第一种情况 第二种情况 数据丢失的情况 解决方案 Leader副本的选举过程 日志清除策略和压缩策略 日志清除策略 日志压缩策略 Kafka存储手段 零拷贝(Zero-Copy) 页缓存(Page Cache&…...
配置邮箱发送功能)
WordPress(7)配置邮箱发送功能
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、注册登陆163邮箱1. 配置SMTP二、开启smtp1.添加授权码二.在网站中配置smtp服务1.在主题的Boxmoe主题设置中开启邮箱设置三.安装所需要的插件1.安装完毕开启插件即可四.SMTP邮箱服务测试总结…...
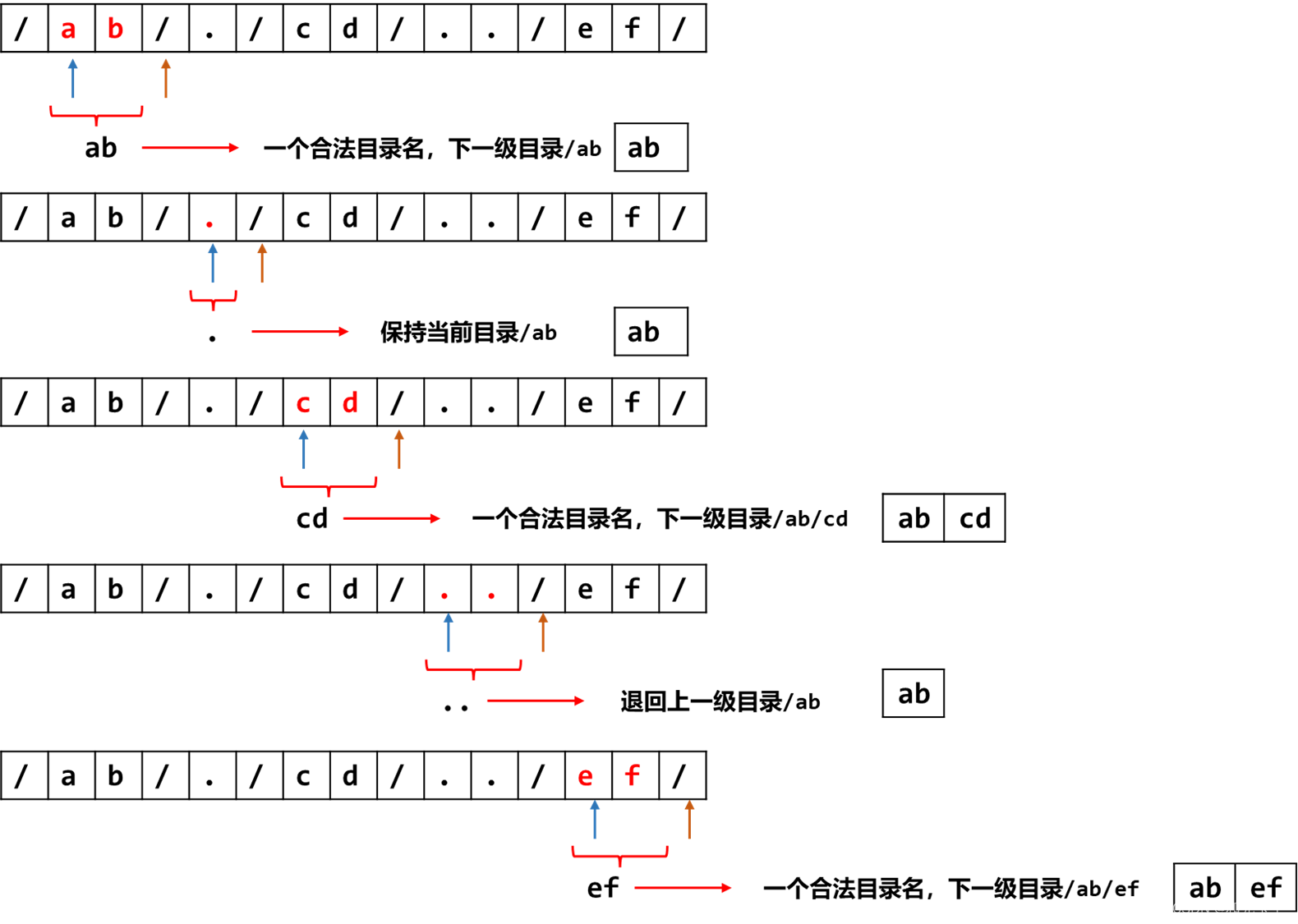
简化路径(C++解法)
题目 给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 / 开头),请你将其转化为更加简洁的规范路径。 在 Unix 风格的文件系统中,一个点(.)表示当前目录本身࿱…...

CS224W1.1——图机器学习介绍
文章目录 1. 介绍2. 主要问题3. 深度学习如何应用在图结构中4. 课程大纲 学习一下斯坦福CS224W的图机器学习(2021年),并做一下学习笔记,主要是研究方向与图神经网络相关。这次是第一次笔记,图片很多都是从斯坦福的PPT里…...
docker搭建waline评论系统
我这里是给博客网站嵌入评论系统的 1.登录LeanCloud 国际版,没有账号可以注册个 链接:点击跳转 2.新建应用,选择开发版(免费),商用版每个月最低消费5美刀。 3.在设置-应用凭证里面将AppID、AppKey、Maste…...

sql server 生成连续日期和数字
在sqlserver里,可以利用系统表master..spt_values里面存储的连续数字0到2047,结合dateadd()函数生成连续的日期 select convert (varchar(10),dateadd(d, number, getdate()),23) as workday from master..spt_values where type…...
太极v14.0.4 免ROOT用Xposed
一个帮助你免 Root、免解锁免刷机使用 Xposed 模块的 APP 框架。 模块通过它改变系统和应用的行为,既能以传统的 Root/ 刷机方式运作, 也能免 Root/ 免刷机运行;并且它支持 Android 5.0 ~ 11。 简单来说,太极就是个 Xposed 框架…...

python DevOps
在云原生中,python扮演的角色是什么? 在云原生环境中,Python 作为一种高级编程语言,在多个方面扮演着重要角色。云原生是指利用云计算的各种优势(如弹性、可扩展性和自动化),构建和运行应用程序…...
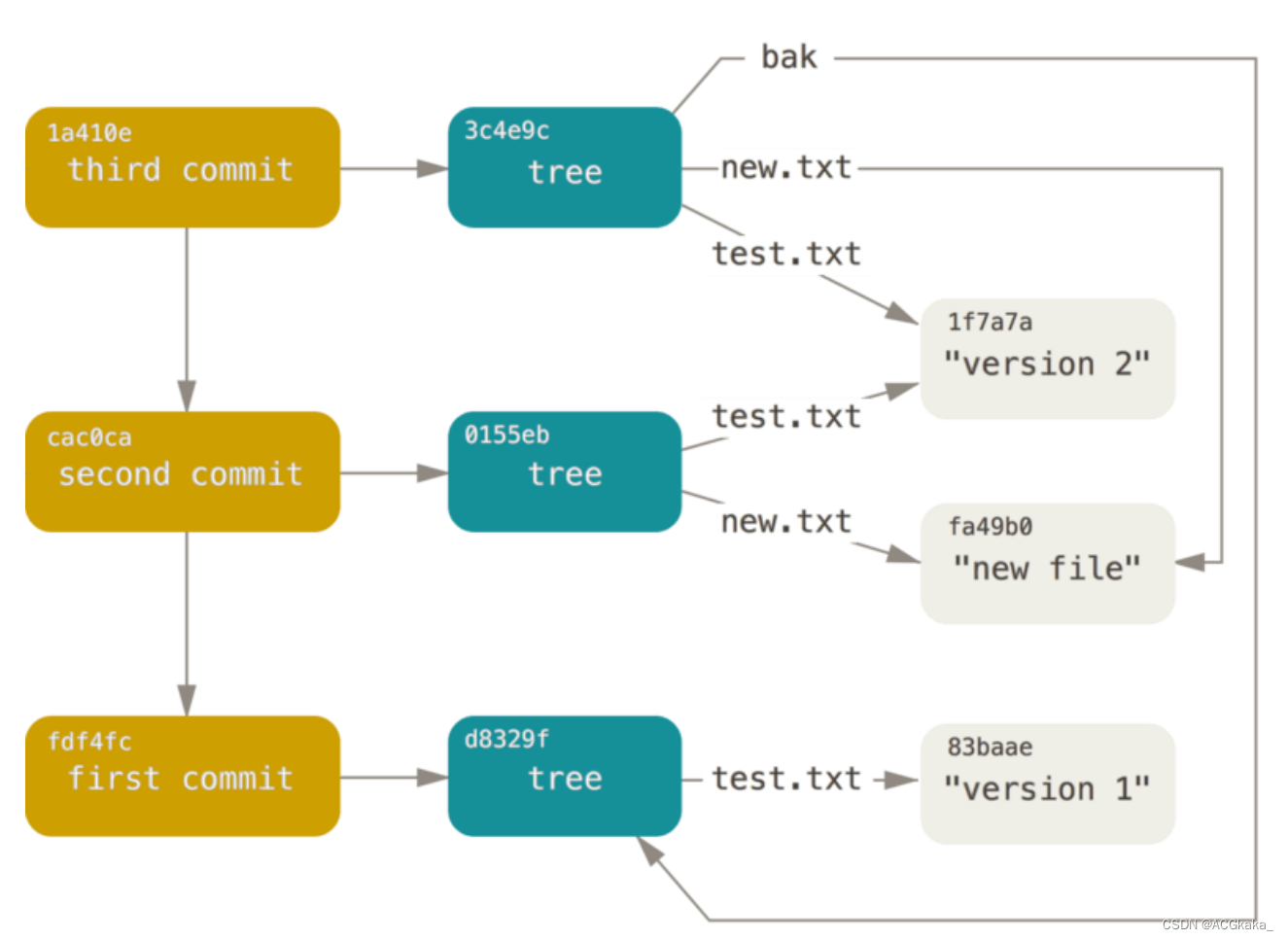
Git(四)底层命令:git对象、树对象、提交对象
目录 一、知识回顾1.1 Linux 基础命令1.2 .git 文件夹解析 二、git 对象(数据对象)2.1 hash-object 存储对象2.2 cat-file 查看对象 三、树对象3.1 ls-files 查看暂存区3.2 update-index 创建暂存区3.3 write-tree 生成树对象3.4 更新暂存区,…...
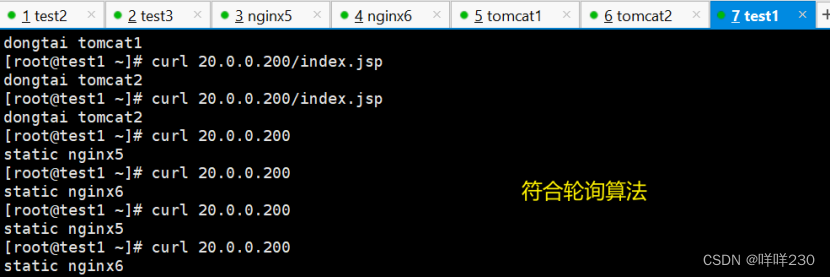
LVS-DR模式+keepalived+nginx+tomcat实现动静分离、负载均衡、高可用实验
实验条件: test2——20.0.0.20——主服务器——ipvsadm、keepalived服务 test3——20.0.0.30——备服务器——ipvsadm、keepalived服务 nginx5——20.0.0.51——后端真实服务器1(tomcat的代理服务器)——nginx服务 nginx6——20.0.0.61—…...
canvas 状态管理
本文简介 带尬猴,我是德育处主任 canvas 绘图时会根据当前状态来绘制。很多的 canvas 库都利用到这一特性。比如 p5.js 利用了 canvas 状态特性衍生出 push 和 pop 函数实现状态隔离(既然提到了,下一篇就讲这个)。 有兴趣了解 p…...
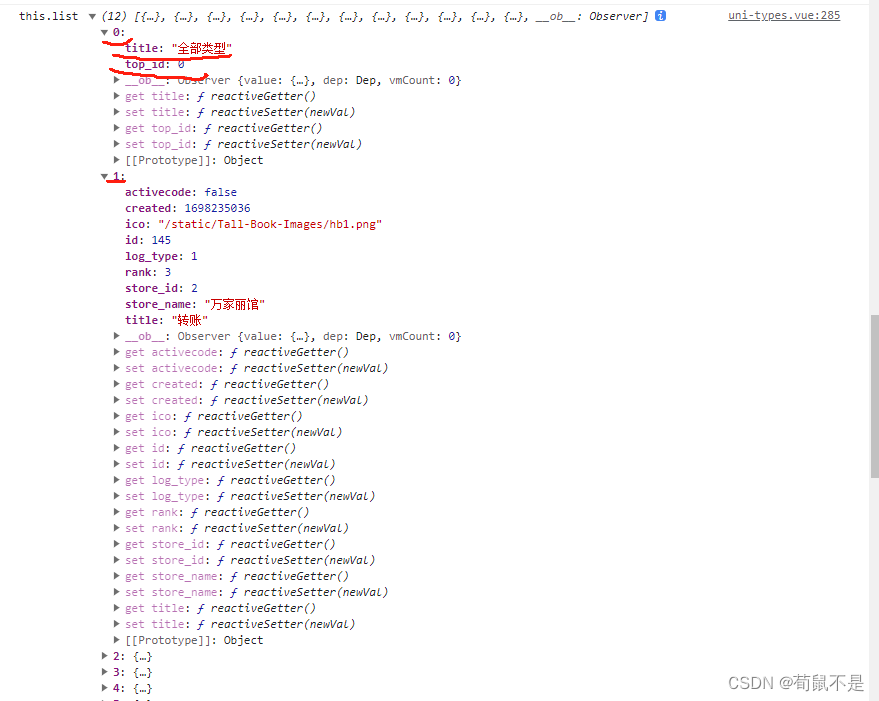
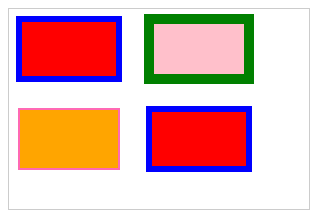
vue中如何给后端过来的数组中每一个对象加一个新的属性和新的对象(不影响后端的原始数据)
方法: 先看后端的原数据 1、给数组中每一个对象加一个新的属性: 输出查看数组list的值: 2、给数组list加入新的对象: 输出结果: 3、总结: 如果是数组中每个对象新增属性就用map遍历每个对象加入新增的属性…...
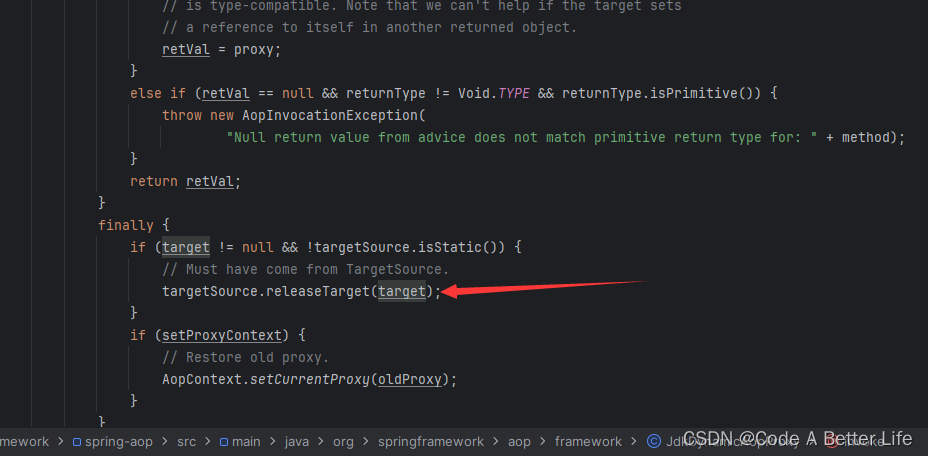
SpringAOP源码解析之TargetSource(四)
前言 在Spring框架中,TargetSource是一个接口,用于封装获取目标对象(也就是被代理的对象)的逻辑。它的主要作用是提供代理对象使用的目标对象,并且允许在运行时动态地切换目标对象。TargetSource在Spring的AOP&#x…...

Centos7 安装nvidia显卡驱动
参考一:https://blog.csdn.net/awen19921106/article/details/131331450 参考二:https://www.cnblogs.com/lishanyang/p/17326021.html 报错一: ERROR: Unable to find the kernel source tree for the currently running kernel. Please …...

22 行为型模式-状态模式
1 状态模式介绍 2 状态模式结构 3 状态模式实现 代码示例 //抽象状态接口 public interface State {//声明抽象方法,不同具体状态类可以有不同实现void handle(Context context); }...

Jetpack:018-Jetpack中的导航一
文章目录 1. 概念介绍2. 使用方法2.1 基本概念2.2 传统用法2.3 新的用法 3. 示例代码4. 内容总结 我们在上一章回中介绍了Jetpack库中对话框相关的内容,本章回中主要介绍 导航。闲话休提,让我们一起Talk Android Jetpack吧! 1. 概念介绍 我…...

Linux常见问题解决操作(yum被占用、lsb无此命令、Linux开机进入命令界面等)
Linux常见问题解决操作(yum被占用、lsb无此命令、Linux开机进入命令界面等) 问题一、新安装的Linux使用命令lsb_release提示无此命令,需先安装再使用 Linux安装lsb命令 lsb是Linux Standard Base的缩写(Linux基本标准ÿ…...
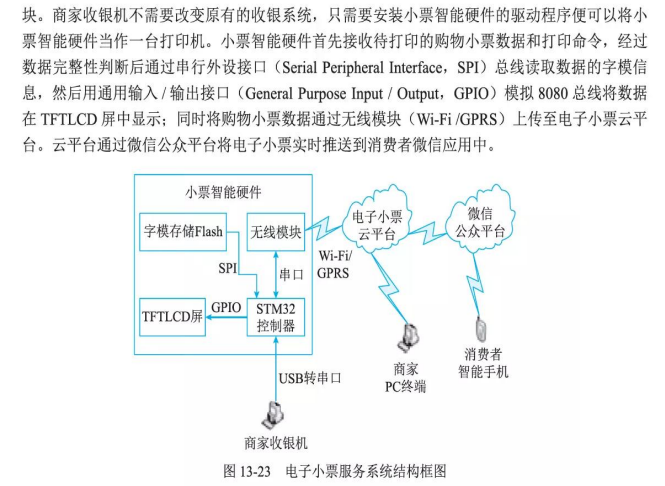
层次式架构的设计理论与实践
层次式架构的设计理论与实践 层次式架构概述 层次式架构的定义和特性 定义 特性 层次式架构的一般组成(表现层、中间层、数据访问层和数据层) 表现层框架设计 设计模式 MVC MVP MVVM XML技术 UIP设计思想 表现层动态生成设计思想(基于XML界面管理技术) 中间层架构设计 业务…...

【shell】read -t -n1
if read -t 5 -p "Please enter your name:" name thenecho "Hello, $name, welcome to my script" else#起到换行的作用echo#输入计数 -n1read -n1 -p "Do you want to continue [Y/N]?" answercase $answer inY | y) echoecho "Fine, co…...
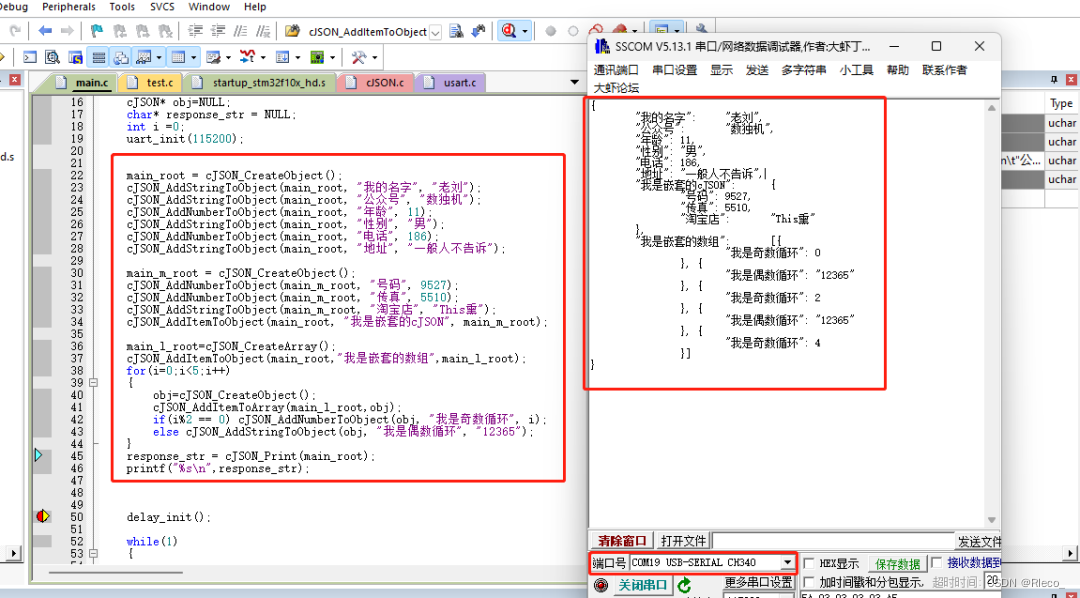
【嵌入式项目应用】__cJSON在单片机的使用
目录 前言 一、JSON和cJson 二、cJSON是如何表示JSON数据的 三、如何封装完整的JSON数据 1. 先将串口打通,方便电脑查看log日志。 2. 增加cjson.c文件,已经在main.c中 3. 准备打包如下的JSON包 4. 代码部分,先将几个部分初始化指针 …...

猫抓:网页资源提取工具的全场景应用指南
猫抓:网页资源提取工具的全场景应用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾遇到这样的困境:精心策划的…...

8大核心功能解决网盘下载难题:Online-disk-direct-link-download-assistant完全指南
8大核心功能解决网盘下载难题:Online-disk-direct-link-download-assistant完全指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿…...

5分钟让老旧打印机变身AirPrint无线打印神器:cups-avahi-airprint完全指南
5分钟让老旧打印机变身AirPrint无线打印神器:cups-avahi-airprint完全指南 【免费下载链接】cups-avahi-airprint Docker image for CUPS intended as an AirPrint relay 项目地址: https://gitcode.com/gh_mirrors/cu/cups-avahi-airprint 在苹果生态日益普…...

告别漫长ps软件下载等待,用快马ai即刻生成你的高效修图工作台
作为一个经常需要处理图片的创作者,我深知传统PS软件下载安装的痛点:动辄几个G的安装包、漫长的等待时间、复杂的配置过程。直到发现了InsCode(快马)平台,才真正体会到什么叫"即开即用"的高效修图体验。 批量处理革命 以前要给几十…...

新手福音,用快马平台可视化学习apifox接口调用与测试
作为一个刚接触API开发的新手,第一次看到各种接口文档时完全摸不着头脑。直到发现了Apifox这个工具,配合InsCode(快马)平台的智能生成功能,终于找到了最适合新手的可视化学习路径。下面分享我的学习心得: 为什么选择Apifox作为入门…...

RexUniNLU效果实测:对比传统方法,零样本在垂直领域信息抽取的准确率表现
RexUniNLU效果实测:对比传统方法,零样本在垂直领域信息抽取的准确率表现 1. 测试背景与方法论 1.1 为什么需要零样本信息抽取? 在传统NLP项目中,构建一个可用的信息抽取系统通常需要经历数据收集、标注、训练、调优等复杂流程。…...

Sambert语音合成镜像新手教程:Web界面操作,简单易上手
Sambert语音合成镜像新手教程:Web界面操作,简单易上手 1. 为什么选择Sambert语音合成镜像 语音合成技术正在改变我们与数字世界的交互方式。Sambert多情感中文语音合成镜像是一个开箱即用的解决方案,特别适合没有深度学习背景但需要快速实现…...

ShortURL MCP 集成指南
在今天的数字时代,短链接的生成和管理变得越来越重要。Ace Data Cloud 提供的 ShortURL MCP 服务器,利用 MCP (模型上下文协议),允许 AI 模型(如 Claude、GPT 等)通过标准化接口调用外部工具,从而更加便利地…...

Agent在供应链场景能降低多少出错率?2026年智能体企业供应链应用深度解析
站在2026年的技术深水区回望,供应链管理已完成从“信息化、自动化”向“智能化、人机共生”的范式转移。在复杂的全球贸易与工业协同背景下,AI Agent(智能体)已正式跨越对话式助手的初级阶段,演进为具备自主执行能力的…...

Gemini 2.0与Gemma混搭开发:手把手教你构建低成本AI代理系统
Gemini 2.0与Gemma混搭开发:构建低成本AI代理系统的实战指南 1. 双轨战略的技术架构设计 谷歌的闭源Gemini与开源Gemma组合为开发者提供了独特的混合部署可能。这种架构设计的核心在于分层处理:将计算密集型任务交给云端Gemini处理,而设备端则…...