ch3_6多线程举例
作者丨billom
来源丨投稿
编辑丨GiantPandaCV
云端深度学习的服务的性能加速通常需要算法和工程的协同加速,需要模型推理和计算节点的融合,并保证整个“木桶”没有太明显的短板。
如何在满足时延前提下让算法工程师的服务的吞吐尽可能高,尽可能简便成了性能优化的关键一环。为了解决这些问题,TorchPipe通过深入PyTorch的C++计算后端和CUDA流管理,以及针对多节点的领域特定语言建模,对外提供面向PyTorch前端的线程安全函数接口,对内提供面向用户的细粒度后端扩展。
开源地址:https://github.com/torchpipe/torchpipe
文档:https://torchpipe.github.io/zh/docs/introduction
背景
深度学习的Serving面临多个难题:
-
一是GIL锁带来的多线程使用受限
-
二是cpu-gpu异构设备开销和复杂性
-
三是复杂流程
业界有一些实践,如triton inference server, 阿里妈妈high_service, 美团视觉GPU推理服务部署架构优化实践。总体上,有以下方向去做这些事情:
-
全流程gpu化
-
DAG的并行化
-
对于cpu计算后端,去克服GIL锁
通常用户对于trinton inference server的一个抱怨是,在多个节点交织的系统中,有大量业务逻辑在客户端完成,通过RPC调用服务端,很麻烦;而为了性能考虑,不得不考虑共享显存,ensemble,BLS[5]等非常规手段。
一. 问题定义
对于我们自己来说,面临的第一个问题是,pytorch 中如何并发调用resnet18模型。本项目开始于一个简单的需求,即我们需要求得一个 X,能够实现模型推理并满足:
-
前向接口需要是线程安全的。
-
在主要硬件平台(如 NVIDIA GPU)以及主要通用加速引擎(如 TensorRT/Libtorch)上实现了此 X。
import torch, X
resnet18 = X(model="resnet18_-1x3x224x224.onnx", precision="fp16",max=4, instance_num=4, batching_timeout=5)
data = torch.from_numpy(data)
net_output: torch.Tensor = resnet18(data=data) # 线程安全调用
以此为起点,我们扩展到了对以下场景的支持:
-
包含前处理在内的通用计算后端X的细粒度泛型扩展
-
多节点组成的有向无环图(DAG)的流水线并行,多级结构化
-
条件控制流

二. 背景知识
首先,我们介绍一些背景知识。您也可以跳过这一部分。
2.1 CUDA: 流和并发
CUDA提供了一致的抽象,来控制并发访问,以便用户最大化、完整地利用单块GPU设备的资源能力。为了最有效的使用GPU设备,我们希望:
- 单位硬件资源能承载更多的业务请求量
- GPU尽可能满载(前提:关联资源使用量小,时延达标)
为了达到此目的,我们简单分析下CUDA的编程模型。
硬件
Cuda Core是显卡主要的运算单元。 采用Pascal及以上架构的显卡拥有上千的CUDA核心,对应着多组SM(Streaming Multiprocessor),可共用于一个任务,也可承载不同的运算任务。从volta架构开始,NVIDIA引入了专为深度学习设计的Tensor Core. 在Turing架构的 Tesla T4中,一共有40个SM, 共享6MB的L2缓存。一个SM由64个FP32 算数单元,和8个Tensor Core组成。对于模型的算子级优化,需要关注较为底层的优化。而对于业务使用场景,既需要算子级优化(选取针对性的计算后端负责),也需要整体视角的分析。
参考链接: GPU Architecture.
CUDA流
CUDA流表示一个GPU操作队列,所有提交给GPU的任务,均指定了执行流。存在一个默认流,也就是`stream 0`, 作为默认的队列。提交任务这个操作本身可以是异步的,对流进行同步化,则意味着需要阻塞cpu线程,直至所有已经提交至该队列中的任务执行完毕。不同流之间的任务可以借助硬件的不同单元并行执行或者时分并发执行。
CUDA上下文(CUDA Context)
CUDA-Stream/CUDA-Context可以类比于线程/进程:多线程分配调用的GPU资源同属一个CUDA Context下,有自己的隔离的地址空间,资源不能跨Context共享。 默认情况下,一个进程中,在初次调用CUDA runtime软件库中的任何一个API时,会自动初始化当前进程中唯一的一个CUDA上下文。GPU在同一时刻只能切换到一个context,而默认情况下一个进程有一个上下文,故多个进程使用GPU,无法同时利用硬件。
虚拟化
由于GPU无法同时执行跨CUDA context的任务,导致硬件利用率可能不高,此时可采用一些虚拟化手段。典型的如NVIDIA官方的MPS(Multi Process Service),它实际上启动了一个独立进程去转发所有的任务。采用此方法的坏处是隔离性收到了一定破坏:一旦此进程失效,所有关联任务都将受到影响。
为了充分利用GPU的性能,可以采取一些措施:
- GPU任务合理分配到多个流,并只在恰当时机同步;
- 将单个显卡的任务限制在单个进程中,去克服CUDA上下文分时特性带来的资源利用率可能不足的问题。
2.2 PyTorch CUDA 语义
PyTorch 以易用性为核心,按照一致的原则组织了对GPU资源的访问。
当前流
在PyTorch内,当前流(current stream)指的是当前线程绑定的CUDA流。PyTorch通过以下API提供了绑定CUDA流到当前线程,以及获取当前线程绑定的CUDA流的功能:
torch.cuda.set_stream(stream)
torch.cuda.current_stream(device=None)
默认情况下,所有线程都绑定到默认流(stream 0)上. PyTorch的GPU运算均提交到当前线程绑定的当前流上。PyTorch尽量让用户感知不到这点:
- 通常来说,当前流是都是默认流,而在同一个流上提交的任务会按提交时间串行执行;
- 对于涉及到将GPU数据拷贝到CPU或者另外一块GPU设备的操作, PyTorch默认地在操作中插入当前流的同步操作 .
为了在多线程环境使得PyTorch充分利用GPU资源,我们需要打破以上惯例:
-
计算后端线程绑定到独立的CUDA流;
-
在线程转换时进行流同步
参考资料: asynchronous execution
更多信息,可参考https://torchpipe.github.io/zh/docs/preliminaries
三. 单节点的并行化

3.1 res****net18 计算加速
对于onnx格式的 resnet18的模型resnet18_-1x3x224x224.onnx, 通常有以下手段进行推理加速:
-
使用tensorrt等框架进行模型针对性加速
-
避免频繁显存申请
-
多实例,batching,分别用来提高资源使用量和使用效率
-
优化数据传输
线程安全的本地推理
为了方便,假设将tensorrt推理功能封装为名称为 TensorrtTensor 的计算后端。由于计算发生在gpu设备上,我们加上SyncTensor 表示gpu上的流同步操作。
| 配置项
| 参数
| 说明
|
| backend | “SyncTensor[TensorrtTensor]” | 计算后端和tensorrt推理本身一样,不是线程安全的。 |
| max
| 4 | 模型支持的最大batchsize,用于模型转换(onnx->tensorrt) |
torchpipe默认会在此计算后端上包裹一层可扩展的单节点调度后端,实现以下三个基本能力:
-
前向接口线程安全性
-
多实例并行
| 配置项
| 默认值
| 说明 |
| instance_num | 1 | 多个模型实例并行执行推理任务。 |
- Batching
对于resnet18, 模型本身输入为-1x3x224x224, batchsize越大,单位硬件资源所完成的任务越多。batchsize 从计算后端(TensorrtTensor)读取。
| 配置项
| 默认值
| 说明 |
| batching_timeout | 0
| 单位为毫秒,在此时间内如果没有接收到 batchsize 个数目的请求,则放弃等待。 |
性能调优技巧
汇总以上步骤,我们获得推理resnet18在torchpipe下的必要参数:
import torchpipe as tp
import torch
config = {
# 单节点调度器参数:
"instance_num":2,
"batching_timeout":5,
# 计算后端:
"backend":"SyncTensor[TensorrtTensor]",
# 计算后端参数:
"model":"resnet18_-1x3x224x224.onnx",
"max":4
}# 初始化
models = tp.pipe(config)
data = torch.ones(1,3,224,224).cuda()## 前向
input = {"data":data}
models(input) # <== 可多线程调用
result: torch.Tensor = input["result"] # 失败则 "result" 不存在
假设我们想要支持最多10路的客户端/并发请求, instance_num 一般设置2,以便最多有处理 instance_num*max = 8 路的能力。
性能取舍
请注意,我们的加速做了如下假设:
同设备上的数据拷贝(如cpu-cpu数据拷贝,gpu-gpu同一显卡内部显存拷贝)速度快,消耗资源少,整体上可忽略不计。
相对于cpu-gpu数据拷贝以及其他的计算,这条假设是没问题的。后面我们将看到,在一些特殊场景,这条假设可能不成立,需要相应的规避手段。
3.2 计算后端
在深度学习的服务中,如果仅支持模型加速远远不够。为此,我们内置了一些常用的细粒度后端。
内置后端举例:
|
名称
|
说明
|
|
DecodeMat
|
jpg解码
|
|
cvtColorMat
|
颜色空间转换
|
|
ResizeMat
|
resize
|
|
PillowResizeMat
|
严格保持和pillow的结果一致的resize
|
|
更多…
|
|
|
名称
|
说明
|
|
DecodeTensor
|
GPU上jpg解码
|
|
cvtColorTensor
|
颜色空间转换
|
|
ResizeTensor
|
resize
|
|
PillowResizeTensor
|
严格保持和pillow的结果一致的resize
|
|
更多…
|
|
3.3 Sequential
Sequential 能串联多个后端。也就是说,Sequential[DecodeTensor,ResizeTensor,cvtColorTensor,SyncTensor] 和 Sequential[DecodeMat,ResizeMat] 是有效后端。
在 Sequential[DecodeMat,ResizeMat] 的前向执行中,数据(dict)会依次经过下列流程:
-
执行 DecodeMat:DecodeMat读取data, 并将结果赋值给result和color
-
条件控制流:尝试将数据中的result的值赋值给data 并删除result
-
执行 ResizeMat :ResizeMat读取data, 并将结果赋值给result键值
Sequential可简写为S.
3.4 单节点调度系统
输入数据经由默认的单节点调度系统BaselineSchedule分发给计算后端执行。在此过程中主要经历了凑batch和多实例的调度。
凑batch/多实例
对于TensorrtTensor等模型推理引擎,输入范围一般是[1, max_batch_size], 此时调度系统可将输入数据打包送入。BaselineSchedule单节点调度后端实现了如下的调度功能:
-
根据instance_num参数启动多个计算后端实例
-
从计算后端读取max_batch_size=max(), 如果大于1,启动凑batch功能
-
从输入队列获取数据,在batching_timeout的时间内,如果获得了max_batch_size个数据,那么将其送往Batch队列, 如果时间到了仍然没有获得足够数据,那么将已有数据送入Batch队列
-
将任务从Batch队列中分发到空闲的计算实例中。
以上是主干的大致流程,细节部分会有差别,如BaselineSchedule也实现了基础的自适应流量功能,根据多实例计算引擎的状态决定batch状态的功能,以及组合调度的功能。
单节点组合调度
有些计算后端的输入范围最小值大于1, 导致无法作为正常的后端进行调度(可能导致有些数据永远没有办法进行处理)。BaselineSchedule通过&符号提供了组合的能力。
举例来讲,对于TensorrtTensor后端,一些模型不方便转为动态模型, 此时可以用一个 batchsize=1 的模型和几个 batchsize=N 的模拟动态batch.
[model]
model="batch1.onnx&batch4.onnx&batch8.onnx"
backend="SyncTensor[TensorrtTensor]" # or 'SyncTensor[TensorrtTensor]&SyncTensor[TensorrtTensor]'
instance_num = 2 # auto extend to '2&2&2'
min="1&4&8"
max="1&4&8"
此时,将共有6个实例,前两个实例输入范围均是[1, 1],中间两个均是[4, 4],最后两个均是[8, 8]。对BaselineSchedule来说,这六个实例组成了两个虚拟实例,每个虚拟实例占用了三个实例,虚拟实例的输入范围是[1, 8].
更多信息,可参考https://torchpipe.github.io/zh/docs/Intra-node
四. 多节点调度
针对多节点,主要考虑了**:**
多个节点的链接,
filter: 有向无环图中的条件控制流,
context: 自动map语法糖,
图的跳转,
逻辑节点。
限于篇幅,暂时不再展开。可参考https://torchpipe.github.io/zh/docs/Inter-node
五. RoadMap
torchpie目前处于一个快速迭代阶段,我们非常需要你的帮助。欢迎通过issues或者反馈等方式帮助我们。
我们的最终目标是让服务端高吞吐部署尽可能简单。为了实现这一目标,我们将积极自我迭代,也愿意参与有相近目标的其他项目。
2023年度和2024年度 RoadMap
-
大模型方面的示例
-
公开的基础镜像和pypi(manylinux)
-
优化编译系统,分为core,pplcv,model/tensorrt,opencv等模块
-
基础结构优化。包含python与c++交互,异常,日志系统,跨进程后端的优化;
-
技术报告
潜在未完成的研究方向
-
单节点调度和多节点调度后端,他们与计算后端无本质差异,需要更多面向用户进行解耦,我们想要将这部分优化为用户API的一部分;
-
针对多节点的调试工具。由于在多节点调度中,使用了模拟栈设计,比较容易设计节点级别的调试工具;
-
负载均衡
六. 意见和建议
欢迎大家提出意见,微信:billom,备注torchpipe
参考链接
-
[1] PyTorch’s Philosophy.
-
[2] GPU Architecture
-
[3] PyTorch’s Asynchronous Execution
-
[4] triton inference server
-
[5] Business Logic Scripting
-
[6] Walle: An End-to-End, General-Purpose, and Large-Scale Production System for Device-Cloud Collaborative Machine Learning | PDF, Github
-
[7] Using Python for Model Inference in Deep Learning. Zachary DeVito et al. (2021)
ref
原文出自;
GiantPandaCV

相关文章:
ch3_6多线程举例
作者丨billom 来源丨投稿 编辑丨GiantPandaCV 云端深度学习的服务的性能加速通常需要算法和工程的协同加速,需要模型推理和计算节点的融合,并保证整个“木桶”没有太明显的短板。 如何在满足时延前提下让算法工程师的服务的吞吐尽可能高,尽…...

javaEE -7(网络原理初识 --- 7000字)
一:网络初识 计算机的独立模式是指多台计算机在网络中相互独立运行,彼此之间不共享资源或信息。在早期,计算机主要采用独立模式,每台计算机都拥有自己的操作系统、应用程序和数据,它们之间没有直接的连接或通信。 在…...

新生儿弱视:原因、科普和注意事项
引言: 新生儿弱视,也被称为婴儿弱视或婴儿屈光不正,是一个在婴儿和幼儿时期非常重要的视觉问题。虽然它是一种潜在的视觉障碍,但早期的诊断和干预可以显著改善儿童的视觉发育。本文将科普新生儿弱视的原因,提供相关信…...
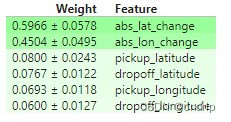
【机器学习可解释性】2.特征重要性排列
机器学习可解释性 1.模型洞察的价值2.特征重要性排列3.偏依赖图 ( partial dependence plots )4.SHAP Value5.SHAP Value 高级使用 正文 前言 你的模型认为哪些特征最重要? 介绍 我们可能会对模型提出的最基本的问题之一是:哪…...

机器学习之朴素贝叶斯
朴素贝叶斯: 也叫贝叶算法推断,建立在主管判断的基础上,不断地进行地修正。需要大量的计算。1、主观性强2、大量计算 贝叶斯定理:有先验概率和后验概率区别:假如出门堵车有两个因素:车太多与交通事故先验概…...
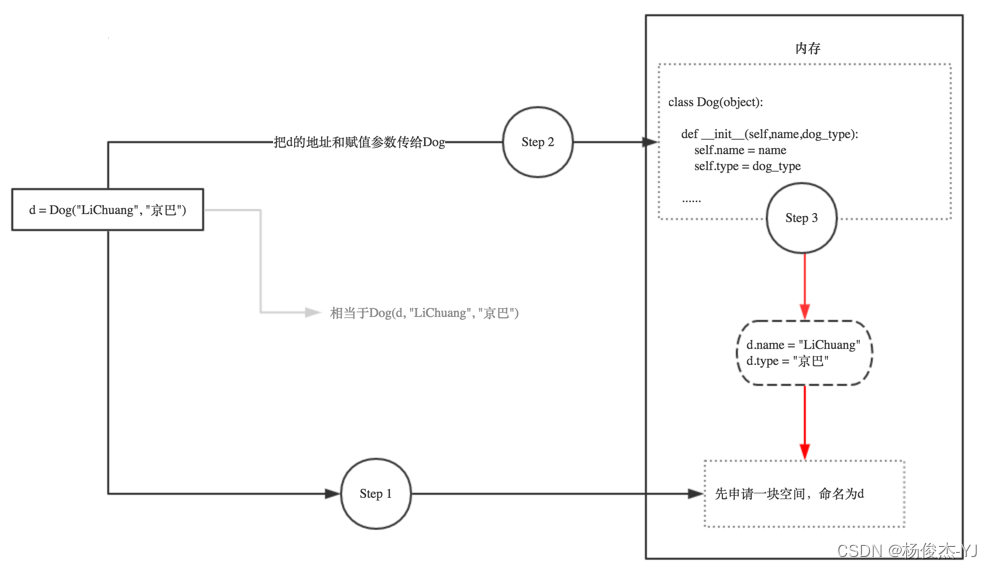
Python中if __name__ == ‘__main__‘,__init__和self 的解析
一、 if __name__ __main__ if __name__ __main__的意思是: 当.py文件被直接运行时,if __name__ __main__之下的代码块将被运行; 当.py文件以模块形式被导入时,if __name__ __main__之下的代码块不被运行。 1.1、一个 xxx.p…...

【Superset】自定义授权认证,接入内部系统二次开发
想要将内部系统认证与superset打通,必须要了解superset的认证体系。 Superset的认证体系 Superset的认证体系可以通过以下几种方式进行配置: 基于LDAP认证:Superset可以集成LDAP以验证用户身份。在这种情况下,Superset将根据LDAP…...

私有云:【1】ESXI的安装
私有云:【1】ESXI的安装 1、使用VMware Workstation创建虚拟机2、启动配置虚拟机3、登录ESXI管理台 1、使用VMware Workstation创建虚拟机 新建虚拟机 选择典型安装 稍后安装操作系统 选择VMware ESXI 选择虚拟机安装路径 硬盘设置300G或者更多 自定义硬件 内存和处…...

Mac怎么删除文件和软件?苹果电脑删除第三方软件方法
Mac删除程序这个话题为什么一直重复说或者太多人讨论呢?因为如果操作不当,可能会导致某些不好的影响。因为Mac电脑如果有太多无用的应用程序,很有可能会拖垮Mac系统的运行速度。或者如果因为删除不干净,导致残留文件积累在Mac电脑…...

【开题报告】基于微信小程序的旅游攻略分享平台的设计与实现
1.研究背景及意义 旅游已经成为现代人生活中重要的组成部分,人们越来越热衷于探索新的目的地和体验不同的文化。然而,对于旅游者来说,获取准确、可靠的旅游攻略信息并不容易。传统的旅游攻略书籍或网站往往无法提供实时、个性化的建议。因此…...

布隆过滤器(Bloom Filter)初学习
目录 1、布隆过滤器是什么 2、布隆过滤器的优缺点 3、使用场景 4、⭐基于Redis的布隆过滤器插件安装 4.1 下载布隆过滤器 4.2 创建文件夹并上传文件 4.3 安装gcc 4.4 解压RedisBloom压缩包 4.5 在解压好的文件夹下输入make 4.6 将编译的好的插件拷贝到docker redis容…...
“深入探讨操作系统和虚拟化技术“
目录 引言1.操作系统1.1.什么是操作系统1.2.常见操作系统1.3.个人版本和服务器版本的区别1.4.Linux的各个版本 2.安装VMWare虚拟机1.VMWare虚拟机介绍2.VMWare虚拟机安装3.VMWare虚拟机配置 3.安装配置Windows Server 2012 R24.完成电脑远程访问电脑5.服务器环境搭建配置jdk配置…...

远程连接异地主机可能遇到的问题及处理
0.现状 公司的一套系统内部有多个节点的内网,要把数据上传至客户的办公网环境中的服务器。客户办公网为我们提供了一台类似路由的设备,办公网无法让内网地址的数据包透传至服务器。现场条件所限,只有有限数量的技术服务人员可以维持…...
的分类)
使用 PointNet 进行3D点集(即点云)的分类
点云分类 介绍 无序3D点集(即点云)的分类、检测和分割是计算机视觉中的核心问题。此示例实现了开创性的点云深度学习论文PointNet(Qi 等人,2017)。 设置 如果使用 colab 首先安装 trimesh !pip install trimesh。 import os import glob import trimesh import numpy as…...
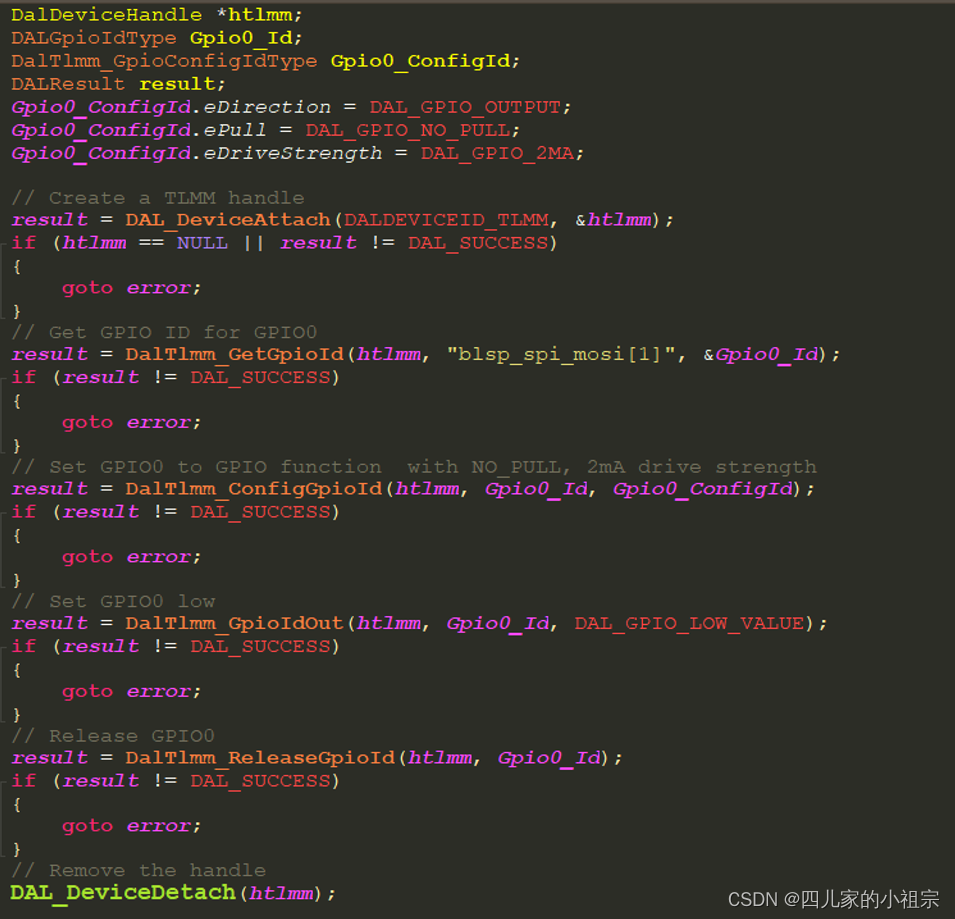
高通平台GPIO引脚复用指导
高通平台GPIO引脚复用指导 1. 概述1.1 平台有多少个GPIO?1.2 这些GPIO都有哪些可复用的功能? 2. 软件配置2.1 TZ侧GPIO配置2.2 SBL侧GPIO配置2.3 AP侧GPIO配置2.3.1 Linux DTS机制与设备驱动模型概述2.3.2高通平台的pinctrl控制器2.3.2.1 SDX12 CPU pinc…...

华为机试题:HJ5 进制转换
目录 第一章、算法题1.1)题目描述1.2)解题思路与答案1.3)派仔的解题思路与答案1.3)牛客链接 友情提醒: 先看文章目录,大致了解文章知识点结构,点击文章目录可直接跳转到文章指定位置。 第一章、算法题 1.…...

面试算法37:小行星碰撞
题目 输入一个表示小行星的数组,数组中每个数字的绝对值表示小行星的大小,数字的正负号表示小行星运动的方向,正号表示向右飞行,负号表示向左飞行。如果两颗小行星相撞,那么体积较小的小行星将会爆炸最终消失…...

ROS学习记录2018.7.10
ROS学习记录2018.7.10 1.ROS基础了解 开源机器人操作系统ROS(robot operation system) 分级: 1.计算图集(一种网络结构) 1.节点:执行运算的进程(做基础处理的单元)2.消息&#x…...
OPC UA:工业领域的“HTML”
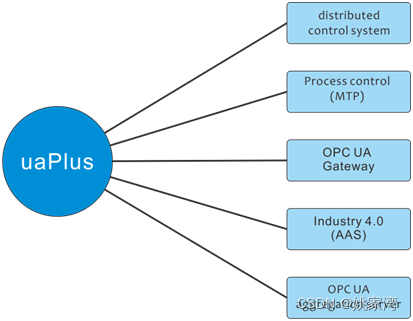
OPC UA是工业自动化领域的一项重要的通信协议。它的特点是包括了信息模型构建方法。能够建立工业领域各种事物的信息模型。在工业自动化行业,OPCUA 类似互联网行业的HTTP协议和“HTML”语言。能够准确,可靠地描述复杂系统中各个元素,并且实现…...
【golang】Windows环境下Gin框架安装和配置
Windows环境下Gin框架安装和配置 我终于搞定了Gin框架的安装,花了两三个小时,只能说道阻且长,所以写下这篇记录文章 先需要修改一些变量,这就需要打开终端,为了一次奏效,我们直接设置全局的: …...

Oracle里的MINUS是什么
在 Oracle 中,MINUS 是 SQL 中的一个集合操作符,它用于比较两个查询的结果集,并返回第一个查询中有而第二个查询中没有的不重复记录。 核心概念 MINUS 执行的是集合的“差集”操作。你可以把它想象成数学中的减法:结果集A - 结果集…...

打造纯净浏览环境:AdGuard浏览器扩展全方位部署与优化指南
打造纯净浏览环境:AdGuard浏览器扩展全方位部署与优化指南 【免费下载链接】AdguardBrowserExtension AdGuard browser extension 项目地址: https://gitcode.com/gh_mirrors/ad/AdguardBrowserExtension 一、核心优势解析:重新定义广告拦截技术标…...

5MB轻量级中文字体:WenQuanYi Micro Hei完全指南
5MB轻量级中文字体:WenQuanYi Micro Hei完全指南 【免费下载链接】fonts-wqy-microhei Debian package for WenQuanYi Micro Hei (mirror of https://anonscm.debian.org/git/pkg-fonts/fonts-wqy-microhei.git) 项目地址: https://gitcode.com/gh_mirrors/fo/fon…...

RexUniNLU零样本实战:智能家居指令解析,5分钟快速上手
RexUniNLU零样本实战:智能家居指令解析,5分钟快速上手 1. 为什么选择RexUniNLU处理智能家居指令? 1.1 智能家居场景的特殊挑战 智能家居领域面临两大核心难题:指令多样性和用户表达随意性。同一操作可能有数十种表达方式&#…...

终极指南:3个简单步骤免费下载B站4K大会员视频
终极指南:3个简单步骤免费下载B站4K大会员视频 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 你是否曾遇到过这样的场景&…...

3步诊断显存故障:memtest_vulkan如何帮你精准定位显卡问题?
3步诊断显存故障:memtest_vulkan如何帮你精准定位显卡问题? 【免费下载链接】memtest_vulkan Vulkan compute tool for testing video memory stability 项目地址: https://gitcode.com/gh_mirrors/me/memtest_vulkan 在显卡稳定性测试领域&#…...

OpenClaw+Qwen3.5-9B低成本方案:自建接口替代OpenAI API
OpenClawQwen3.5-9B低成本方案:自建接口替代OpenAI API 1. 为什么选择Qwen3.5-9B作为OpenClaw的本地大脑 去年冬天,当我第一次尝试用OpenClaw自动化处理周报时,被OpenAI API的账单吓了一跳——简单的文件整理和摘要生成,一周竟消…...

告别复杂操作!Wan2.2-I2V-A14B一键生成480P高清视频
告别复杂操作!Wan2.2-I2V-A14B一键生成480P高清视频 1. 视频创作新体验:简单三步生成专业级视频 你是否曾经为制作一段简单的视频而头疼?传统视频制作需要学习复杂的剪辑软件,花费大量时间调整参数,甚至需要专业的拍…...

如何精准定制鼠单克隆抗体?
一、为何鼠单克隆抗体仍是定制研发的主流选择?鼠单克隆抗体作为生物医学研究的重要工具,在定制开发领域占据着不可替代的地位。这主要源于其技术体系的成熟性、标准化的操作流程以及广泛的应用验证基础。自杂交瘤技术问世以来,小鼠作为免疫动…...

实测有效!Yi-Coder-1.5B生成高质量代码案例分享
实测有效!Yi-Coder-1.5B生成高质量代码案例分享 1. 引言:一个轻量级但强大的编程伙伴 最近在尝试各种代码生成模型时,我发现了Yi-Coder-1.5B这个宝藏。说实话,一开始看到“1.5B”这个参数规模,我并没有抱太高期望——…...