python操作MySQL、SQL注入问题、视图、触发器、事务、存储过程、函数、流程控制、索引(重点)
python操作MySQL(重要)
SQL的由来:
MySQL本身就是一款C/S架构,有服务端、有客户端,自身带了有客户端:mysql.exe
python这门语言成为了MySQL的客户端(对于一个服务端来说,客户端可以有很多)
操作步骤:
1. 先链接MySQL
host、port、username、password、charset、库等
2. 在Python中书写SQL语句
3. 开始执行SQL语句,拿到结果
4. 在Python中做处理(进一步对数据做处理)
# 需要使用第三方一个模块: pymysql mysqldb mysqlclient
1. 先链接MySQL
conn=pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='1234',
db='db10',
charset='utf8',
autocommit=True
)
2. 获取游标
cur=conn.cursor(cursor=pymysql.cursors.DictCursor)
3. 写SQL语句
sql='select * from student'
sql='insert into teacher(tid, tname) values (7, "ly1")'
4. 开始执行SQL语句
affect_rows=cur.execute(sql) # 16 是影响的行数
需要执行二次确认: 除了查询之外都要二次确认提交
conn.commit()
print(affect_rows)
5. 想获取到结果:
res=cur.fetchone()
res=cur.fetchall()
res=cur.fetchmany(5)
{'sid': 1, 'gender': '男', 'class_id': 1, 'sname': '理解'}
print(res) # (1, '男', 1, '理解') 元组类型for i in res:
print(i.get("sid"))
SQL注入问题
import pymysql
# 连接MySQL服务端
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='db8_3',
charset='utf8',
autocommit=True # 针对增 改 删自动二次确认
)
# 产生一个游标对象
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 编写SQL语句
username = input('username>>>:').strip()
password = input('password>>>:').strip()
sql = "select * from userinfo where name='%s' and pwd='%s'" % (name,pwd)
sql = "select * from userinfo where name=%s and pwd=%s"
cursor.execute(sql,(username,password))
data = cursor.fetchall()
if data:
print(data)
print('登录成功')
else:
print('用户名或密码错误')
# 1.只需要用户名也可以登录
username:>>> kevin111 " -- ddasfdfsdfdsfsdfsdfsdfdsfsdfsd
username:>>> xxx " or 1=1
# 2.不需要用户名和密码也可以登录
SQL注入的原因 是由于特殊符号的组合会产生特殊的效果
实际生活中 尤其是在注册用户名的时候 会非常明显的提示你很多特殊符号不能用
原因也是一样的
结论:设计到敏感数据部分 不要自己拼接 交给现成的方法拼接即可
sql = 'insert into userinfo(name,pwd) values("jason","123"),("kevin","321")'
res = cursor.execute(sql)print(res)
在使用代码进行数据操作的时候 不同操作的级别是不一样的
针对查无所谓
针对增 改 删都需要二次确认
conn.commit()
视图
什么是视图
视图就是通过查询得到一张虚拟表,然后保存下来,下次直接使用即可
为什么要用视图
如果要频繁使用一张虚拟表,可以不用重复查询
如何用视图
create view teacher2course as
select * from teacher inner join course on teacher.tid = course.teacher_id;
创建好了之后 验证它的存在navicat验证 cmd终端验证
最后文件验证 得出下面的结论 视图只有表结构数据还是来源于之前的表
delete from teacher2course where id=1;
强调
1、在硬盘中,视图只有表结构文件,没有表数据文件
2、视图通常是用于查询,尽量不要修改视图中的数据
drop view teacher2course;
思考:开发过程中会不会去使用视图?
不会!视图是mysql的功能,如果你的项目里面大量的使用到了视图,那意味着你后期想要扩张某个功能的时候这个功能恰巧又需要对视图进行修改,意味着你需要先在mysql这边将视图先修改一下,然后再去应用程序中修改对应的sql语句,这就涉及到跨部门沟通的问题,所以通常不会使用视图,而是通过重新修改sql语句来扩展功能
触发器
在满足对某张表数据的增、删、改的情况下,自动触发的功能称之为触发器
为何要用触发器
触发器专门针对我们对某一张表数据增insert、删delete、改update的行为,这类行为一旦执行
就会触发触发器的执行,即自动运行另外一段sql代码
创建触发器语法
语法结构
create trigger 触发器的名字 before/after insert/update/delete on 表名 for each row
begin
sql语句
end
针对插入
create trigger tri_after_insert_t1 after insert on 表名 for each row
begin
sql代码。。。
end
create trigger tri_after_insert_t2 before insert on 表名 for each row
begin
sql代码。。。
end
针对删除
create trigger tri_after_delete_t1 after delete on 表名 for each row
begin
sql代码。。。
end
create trigger tri_after_delete_t2 before delete on 表名 for each row
begin
sql代码。。。
end
针对修改
create trigger tri_after_update_t1 after update on 表名 for each row
begin
sql代码。。。
end
create trigger tri_after_update_t2 before update on 表名 for each row
begin
sql代码。。。
end
需要注意 在书写sql代码的时候结束符是; 而整个触发器的结束也需要分号;
这就会出现语法冲突 需要我们临时修改结束符号
delimiter $$
delimiter ;
该语法只在当前窗口有效
案例
CREATE TABLE cmd (
id INT PRIMARY KEY auto_increment,
USER CHAR (32),
priv CHAR (10),
cmd CHAR (64),
sub_time datetime, #提交时间
success enum ('yes', 'no') #0代表执行失败
);CREATE TABLE errlog (
id INT PRIMARY KEY auto_increment,
err_cmd CHAR (64),
err_time datetime
);delimiter $$ # 将mysql默认的结束符由;换成$$
create trigger tri_after_insert_cmd after insert on cmd for each row
begin
if NEW.success = 'no' then # 新记录都会被MySQL封装成NEW对象
insert into errlog(err_cmd,err_time) values(NEW.cmd,NEW.sub_time);
end if;
end $$delimiter ; # 结束之后记得再改回来,不然后面结束符就都是$$了
#往表cmd中插入记录,触发触发器,根据IF的条件决定是否插入错误日志
INSERT INTO cmd (
USER,
priv,
cmd,
sub_time,
success
)
VALUES
('egon','0755','ls -l /etc',NOW(),'yes'),
('egon','0755','cat /etc/passwd',NOW(),'no'),
('egon','0755','useradd xxx',NOW(),'no'),
('egon','0755','ps aux',NOW(),'yes');查询errlog表记录
select * from errlog;
删除触发器
drop trigger tri_after_insert_cmd;
事务(掌握重点)
什么是事务
开启一个事务可以包含一些sql语句,这些sql语句要么同时成功
要么一个都别想成功,称之为事务的原子性
事务的作用
保证了对数据操作的数据安全性
案例:用交行的卡操作建行ATM机给工商的账户转钱
事务的4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性
原子性(atomicity)一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
一致性(consistency)事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation)一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability)持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
怎么使用
# 先介绍事务的三个关键字 再去用表实际展示效果
start transaction;
commit;
rollback;create table user(
id int primary key auto_increment,
name char(32),
balance int
);insert into user(name,balance)
values
('jason',1000),
('egon',1000),
('tank',1000);# 修改数据之前先开启事务操作
start transaction;# 修改操作
update user set balance=900 where name='jason'; #买支付100元
update user set balance=1010 where name='egon'; #中介拿走10元
update user set balance=1090 where name='tank'; #卖家拿到90元# 回滚到上一个状态
rollback;# 开启事务之后,只要没有执行commit操作,数据其实都没有真正刷新到硬盘
commit;
"""开启事务检测操作是否完整,不完整主动回滚到上一个状态,如果完整就应该执行commit操作"""# 站在python代码的角度,应该实现的伪代码逻辑,
try:
# 少了开事务...
update user set balance=900 where name='jason'; #买支付100元
update user set balance=1010 where name='egon'; #中介拿走10元
update user set balance=1090 where name='tank'; #卖家拿到90元
except 异常:
rollback;
else:
commit;
存储过程
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql,类似于python中的自定义函数
基本使用
delimiter $$
create procedure p1()
begin
select * from user;
end $$
delimiter ;# 调用
call p1()
三种开发模型
第一种
应用程序:只需要开发应用程序的逻辑
mysql:编写好存储过程,以供应用程序调用
优点:开发效率,执行效率都高
缺点:考虑到人为因素、跨部门沟通等问题,会导致扩展性差
第二种
应用程序:除了开发应用程序的逻辑,还需要编写原生sql
优点:比方式1,扩展性高(非技术性的)
缺点:
1、开发效率,执行效率都不如方式1
2、编写原生sql太过于复杂,而且需要考虑到sql语句的优化问题
第三种
应用程序:开发应用程序的逻辑,不需要编写原生sql,基于别人编写好的框架来处理数据,ORM
优点:不用再编写纯生sql,这意味着开发效率比方式2高,同时兼容方式2扩展性高的好处
缺点:执行效率连方式2都比不过
创建存储过程
# 介绍形参特点 再写具体功能
delimiter $$
create procedure p2(
in m int, # in表示这个参数必须只能是传入不能被返回出去
in n int,
out res int # out表示这个参数可以被返回出去
)
begin
select tname from teacher where tid > m and tid < n;
set res=0; # 用来标志存储过程是否执行
end $$
delimiter ;
# 针对res需要先提前定义
set @res=10; 定义
select @res; 查看
call p1(1,5,@res) 调用
select @res 查看
如何用存储过程
大前提:存储过程在哪个库下面创建的只能在对应的库下面才能使用
1、直接在mysql中调用
set @res=10 # res的值是用来判断存储过程是否被执行成功的依据,所以需要先定义一个变量@res存储10
call p1(2,4,10); # 报错
call p1(2,4,@res);# 查看结果
select @res; # 执行成功,@res变量值发生了变化
2、在python程序中调用
pymysql链接mysql
产生的游表cursor.callproc('p1',(2,4,10)) # 内部原理:@_p1_0=2,@_p1_1=4,@_p1_2=10;
cursor.execute('select @_p1_2;')
3、存储过程与事务使用举例(了解)
delimiter //
create PROCEDURE p5(
OUT p_return_code tinyint
)
BEGIN
DECLARE exit handler for sqlexception
BEGIN
-- ERROR
set p_return_code = 1;
rollback;
END;
DECLARE exit handler for sqlwarning
BEGIN
-- WARNING
set p_return_code = 2;
rollback;
END;START TRANSACTION;
update user set balance=900 where id =1;
update user123 set balance=1010 where id = 2;
update user set balance=1090 where id =3;
COMMIT;-- SUCCESS
set p_return_code = 0; #0代表执行成功
END //
delimiter ;
函数
注意与存储过程的区别,mysql内置的函数只能在sql语句中使用!
CREATE TABLE blog (
id INT PRIMARY KEY auto_increment,
NAME CHAR (32),
sub_time datetime
);INSERT INTO blog (NAME, sub_time)
VALUES
('第1篇','2015-03-01 11:31:21'),
('第2篇','2015-03-11 16:31:21'),
('第3篇','2016-07-01 10:21:31'),
('第4篇','2016-07-22 09:23:21'),
('第5篇','2016-07-23 10:11:11'),
('第6篇','2016-07-25 11:21:31'),
('第7篇','2017-03-01 15:33:21'),
('第8篇','2017-03-01 17:32:21'),
('第9篇','2017-03-01 18:31:21');
+----+--------------------------------------+---------------------+
| id | NAME | sub_time | month
+----+--------------------------------------+---------------------+
| 1 | 第1篇 | 2015-03-01 11:31:21 | 2015-03
| 2 | 第2篇 | 2015-03-11 16:31:21 | 2015-03
| 3 | 第3篇 | 2016-07-01 10:21:31 | 2016-07
| 4 | 第4篇 | 2016-07-22 09:23:21 | 2016-07
| 5 | 第5篇 | 2016-07-23 10:11:11 | 2016-07
| 6 | 第6篇 | 2016-07-25 11:21:31 | 2016-07
| 7 | 第7篇 | 2017-03-01 15:33:21 | 2017-03
| 8 | 第8篇 | 2017-03-01 17:32:21 | 2017-03
| 9 | 第9篇 | 2017-03-01 18:31:21 | 2017-03
+----+--------------------------------------+---------------------+select count(*) from blog group by month;
select date_format(sub_time,'%Y-%m'),count(id) from blog group by date_format(sub_time,'%Y-%m');
https://blog.csdn.net/GG_Bruse/article/details/131484538
流程控制
# if条件语句
delimiter //
CREATE PROCEDURE proc_if ()
BEGIN
declare i int default 0;
if i = 1 THEN
SELECT 1;
ELSEIF i = 2 THEN
SELECT 2;
ELSE
SELECT 7;
END IF;END //
delimiter ;
# while循环
delimiter //
CREATE PROCEDURE proc_while ()
BEGINDECLARE num INT ;
SET num = 0 ;
WHILE num < 10 DO
SELECT
num ;
SET num = num + 1 ;
END WHILE ;END //
delimiter ;
索引(重点)
索引就是一种数据结构,类似于书的目录。意味着以后再查数据应该先找目录再找数据,而不是用翻页的方式查询数据
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。
-
primary key
-
unique key
-
index key
注意:上面三种key前两种除了有加速查询的效果之外还有额外的约束条件(primary key:非空且唯一,unique key:唯一),而index key没有任何约束功能只会帮你加速查询
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
索引的影响:
在表中有大量数据的前提下,创建索引速度会很慢(建表的时候,如果明显需要索引,就提前加上)
# 以后实际添加索引的时候,尽量在空表的时候添加,在创建表的时候就添加索引,此时添加索引是最快的
# 如果表中数据已经有了,还需要添加索引,也可以,只不过创建索引的速度会很慢,不建议这样做
在索引创建完毕后,对表的查询性能会大幅度提升,但是写的性能会降低
# 但是,写的性能影响不是很大,因为在实际中,写的频率很少,大部分操作都是查询
# 如何添加索引?到底给哪些字段加索引呢?
'''没有固定答案,具体给哪个字段加索引,要看你实际的查询条件'''
select * from user where name='' and password='';
# 索引的使用其实是需要大量的工作经验,才能正确的判断出
'''不要一创建表就加索引,在一张表中,最多最多不要超过15个索引,索引越多,性能就会下降'''
# 如何数据量比较小,不需要加索引,100w一下一般不用加,mysql针对于1000w一下的数据,性能不会下降太多.
b+树
树------>二叉树 平衡树 b树 b+树 b-树...
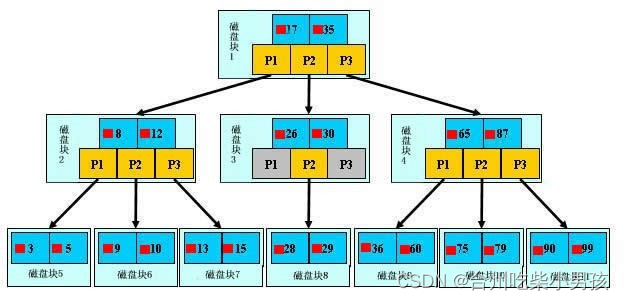
只有叶子结点存放真实数据,根和树枝节点存的仅仅是虚拟数据
查询次数由树的层级决定,层级越低次数越少
一个磁盘块儿的大小是一定的,那也就意味着能存的数据量是一定的。如何保证树的层级最低呢?一个磁盘块儿存放占用空间比较小的数据项
# 以后加索引的时候,尽量给字段中存的是数字的列加,我们使用主键查询速度很快
select * from user where name = ''
select * from user where id = '' # 主键查询的更快一些
思考我们应该给我们一张表里面的什么字段字段建立索引能够降低树的层级高度>>> 主键id字段
聚集索引(primary key)
聚集索引其实指的就是表的主键,innodb引擎规定一张表中必须要有主键。先来回顾一下存储引擎。
myisam在建表的时候对应到硬盘有几个文件(三个)?
innodb在建表的时候对应到硬盘有几个文件(两个)?frm文件只存放表结构,不可能放索引,也就意味着innodb的索引跟数据都放在idb表数据文件中。
特点:叶子结点放的一条条完整的记录
辅助索引(unique,index)
辅助索引:查询数据的时候不可能都是用id作为筛选条件,也可能会用name,password等字段信息,那么这个时候就无法利用到聚集索引的加速查询效果。就需要给其他字段建立索引,这些索引就叫辅助索引
特点:叶子结点存放的是辅助索引字段对应的那条记录的主键的值(比如:按照name字段创建索引,那么叶子节点存放的是:{name对应的值:name所在的那条记录的主键值})
select name from user where name='jack';
上述语句叫覆盖索引:只在辅助索引的叶子节点中就已经找到了所有我们想要的数据
select age from user where name='jack';
上述语句叫非覆盖索引,虽然查询的时候命中了索引字段name,但是要查的是age字段,所以还需要利用主键才去查找
相关文章:
python操作MySQL、SQL注入问题、视图、触发器、事务、存储过程、函数、流程控制、索引(重点)
python操作MySQL(重要) SQL的由来: MySQL本身就是一款C/S架构,有服务端、有客户端,自身带了有客户端:mysql.exe python这门语言成为了MySQL的客户端(对于一个服务端来说,客户端可以有很多) 操作步骤: …...

这一年的资源
#线性代数 https://textbooks.math.gatech.edu/ila/one-to-one-onto.html行业规范https://xlinux.nist.gov/dads/https://www.dhs.gov/publications产业群链基金会 https://www.cncf.io/谷歌 https://opensource.google/projects网飞 高德纳 https://www.gartne…...

从【臀部监控】到【电脑监控软件】,企业如何在隐私权与管理权博弈中找到平衡
【臀部监控】 依稀记得在2021年初某个高科技产品的爆火,惹得各大媒体网站争相报道。 起因是一位杭州网友在论坛上发帖,不久前公司给员工发放了一批高科技坐垫。 这个坐垫能自动感应心跳、呼吸在内的诸多人体数据,还能提醒人保持正确坐姿以及…...
数据库简介和sqlite3安装
数据库就是存储数据的仓库,其本质是一个文件系统,数据按照特定的格式将数据存储起来,用户可以对数据库中的数据进行增加,修改,删除及查询操作。 严格意义上来说,"数据库"不能被称之为"数据库",而…...
颈肩肌筋膜炎做什么检查
颈肩肌筋膜炎症状 颈肩背部广泛疼痛酸胀沉重感、麻木感,僵硬、活动受限,可向后头部及上臂放散。疼痛呈持续性,可因感染、疲劳、受凉、受潮等因素而加重。查体见颈部肌紧张,压痛点常在棘突及棘突旁斜方肌、菱形肌等,压…...
django建站过程(3)定义模型与管理页
定义模型与管理页 定义模型[models.py]迁移模型向管理注册模型[admin.py]注册模型使用Admin.site.register(模型名)修改Django后台管理的名称定义管理列表页面应用名称修改管理列表添加查询功能 django shell交互式shell会话 认证和授权 定义模型[models.py] 模仿博客形式&…...
node开发微信群聊机器人第⑤章
▍PART 序 看本文时,请确保前4章都已经看过,不然本章你看着看着思维容易跳脱!再一个机器人教程只在公众号:“程序员野区”首发。csdn会跟着发一份,未经博主同意,请勿转载!欢迎分享到自己的微信…...

如何助力企业出海?未来发展趋势是什么?尽在「云通信」Tech专场
2023杭州云栖大会 倒计时4天! 阿里云云通信 2大并行Session 6场话题演讲 今日「云通信」Tech 议程内容抢先知晓 01 「云通信」Tech • 国内企业出海,如何更高地提升市场营销的ROI,提升客户的转化率? • 面对海外存量客户&a…...
安装虚拟机(VMware)保姆级教程及配置虚拟网络编辑器和安装WindowsServer以及本地访问虚拟机和配置服务器环境
目录 一、操作系统 1.1.什么是操作系统 1.2.常见操作系统 1.3.个人版本和服务器版本的区别 1.4.Linux的各个版本 二、VMware Wworkstation Pro虚拟机的安装 1.下载与安装 注意:VMWare虚拟网卡 2.配置虚拟网络编辑器 三、安装配置 WindowsServer 1.创建虚拟…...
使用Typecho搭建个人博客网站,并内网穿透实现公网访问
使用Typecho搭建个人博客网站,并内网穿透实现公网访问 文章目录 使用Typecho搭建个人博客网站,并内网穿透实现公网访问前言1. 安装环境2. 下载Typecho3. 创建站点4. 访问Typecho5. 安装cpolar6. 远程访问Typecho7. 固定远程访问地址8. 配置typecho 前言 …...
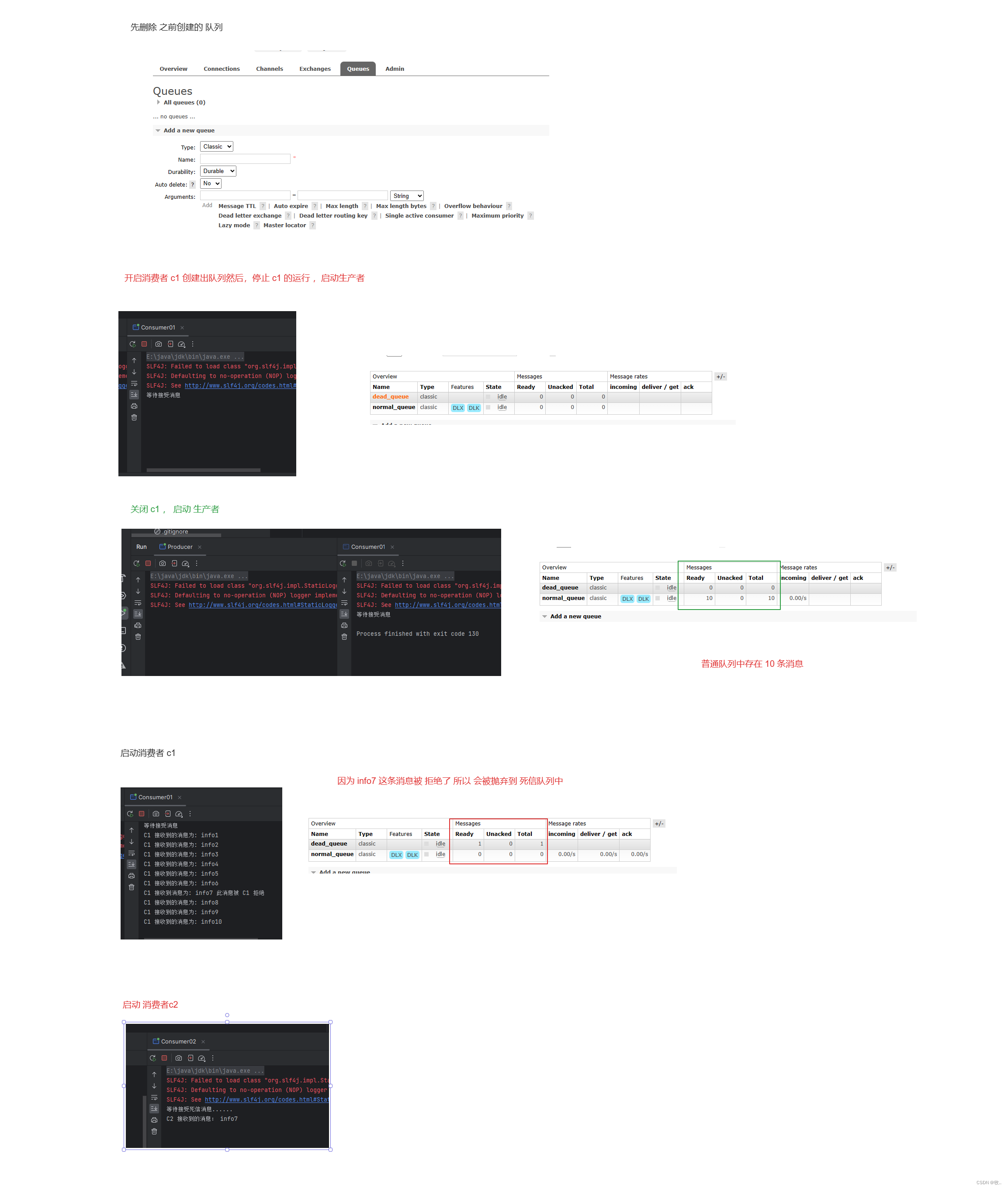
RabbitMQ (4)
RabbitMQ (4) 文章目录 1. 死信的概念2. 死信的来源3. 死信代码案例3.1 TTL 过期时间3.2 超过队列最大长度3.3 拒绝消息 前言 上文我们已经学习完 交换机 ,知道了几个交换机的使用 ,下面我们来学习一下 死信队列 1. 死信的概念 先从概念解释上搞清楚这…...

导入Embassy库进行爬虫
Embassy是一个基于Lua的轻量级爬虫框架,可以方便地进行网页抓取和数据提取。它提供了简单易用的接口和丰富的功能,可以帮助开发者快速构建爬虫应用。 要使用Embassy进行爬虫,首先需要安装Embassy库。可以通过Lua的包管理工具luarocks来安装E…...

GoLong的学习之路(十三)语法之标准库 log(日志包)的使用
上回书说到,flag的问题。这回说到日志。无论是软件开发的调试阶段还是软件上线之后的运行阶段,日志一直都是非常重要的一个环节,我们也应该养成在程序中记录日志的好习惯。 文章目录 log配置logger配置日志前缀配置日志输出位置自定义logger …...
别处拿来的VUE项目 npm run serve报错
问题现象: 从别处拷贝来的VUE项目,根据说明通过npm install 加载了项目依赖 ,但是运行npm run serve里报错: npm ERR! Missing script: "serve" npm ERR! npm ERR! To see a list of scripts, run: npm ERR! npm ru…...

Istio 运行错误 failed to update resource with server-side apply for obj 问题解决
Istio 环境 kubernetes version: v1.18.2 istio version: v1.10.0运行之后 istio-operator 的日志就抛出下面错误,而且会一直重启 # kubectl get iop -A NAMESPACE NAME REVISION STATUS AGE istio-system iop-pro-cluster…...
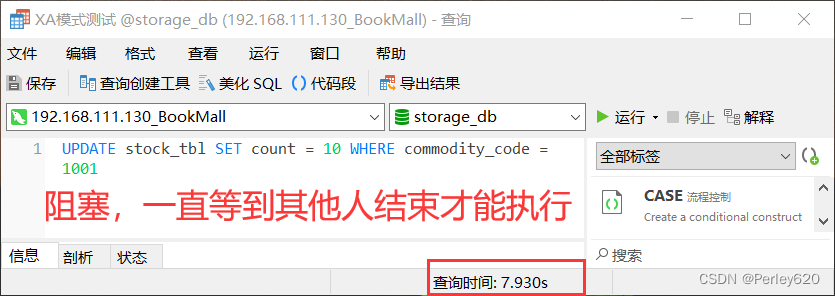
分布式事务(Seata)——Seata分布式事务XA模式、AT模式、TCC模式的介绍和对比 结合案例分析AT模式和XA模式【源码】
前言 事务(TRANSACTION)是一个不可分割的逻辑单元,包含了一组数据库操作命令,并且把所有的命令作为一个整体向系统提交,要么都执行、要么都不执行。 事务作为系统中必须考虑的问题,无论是在单体项目还是在分布式项目中都需要进行…...

GMT 格式 转 标准日期格式
需求:有一个时间格式:TUE NOV 14 08:00:00 GMT08:00 2000 我需要将这种格式的时间转换为标准日期格式,并且只修改这种时间格式的时间,不影响其他的 思路:我想到的是用正则来判断,SimpleDateFormat来进行转换…...

【蓝桥杯选拔赛真题01】C++参赛建议 青少年组蓝桥杯C++选拔赛真题 STEMA比赛真题解析
目录 C/C++参赛建议 一、题目要求 1、编程实现 2、输入输出 二、算法分析 <...

小红书为什么流量不好,小红书笔记质量评判标准有哪些?
我们都知道小红书平台强大的种草力与传播力,需要依靠优质笔记的输出来达成。但是很多时候,我们撰写了笔记,却无法被收录,获得流量,这都是因为笔记质量出现了问题。那么小红书为什么流量不好,小红书笔记质量…...

优化改进 | YOLOv2算法超详细解析(包括诞生背景+论文解析+技术原理等)
前言:Hello大家好,我是小哥谈。YOLOv2是YOLO(You Only Look Once)目标检测算法的第二个版本,它在YOLOv1的基础上做了很多改进,包括使用更深的卷积神经网络Darknet-19作为特征提取器、使用Batch Normalizati…...

hsjdvfjfgdhdydh
一、OpenAI 1.OpenAI是什么简单来说,OpenAI 大模型 是由美国人工智能公司 OpenAI 开发的一系列大型语言模型(LLMs) 。你可以把它们想象成拥有巨大“知识储备”和“学习能力”的超级大脑,它们被训练用来理解和生成人类语言…...

读硕士是否有必要?
一、研究方法说明 数据来源 本报告数据来源于以下公开渠道(2024-2025年),所有结论均有真实数据支撑:来源说明麦可思研究院《2025年中国本科生就业报告》权威第三方教育研究机构猎聘《2025人才供需洞察》《2025上半年人才供需洞察报…...

兼容FX3U源码的增强版:支持以太网与串口下载,集成MODBUS-TCP协议,实现相对定位与绝...
18650锂电池高温热失控一、模块概述 FX3U系列PLC CAN网络通信模块是基于STM32F10x系列微控制器开发的专用通信组件,旨在实现多节点PLC设备间的可靠数据交互。该模块采用STM32F10x CAN外设硬件资源,结合自定义应用层协议,支持主从式网络架构&a…...

APM基础概念普及:应用性能管理的全面解析
在当今数字化时代,企业应用的性能直接影响着用户体验和商业成功。应用性能管理(Application Performance Management,APM)作为保障应用稳定运行的关键技术,已成为现代IT运维不可或缺的工具。本文将全面解析APM的基础概…...

Go语言的分布式事务处理
Go语言的分布式事务处理 1. 分布式事务简介 在分布式系统中,事务处理变得更加复杂。传统的单机事务可以通过数据库的ACID特性来保证一致性,但在分布式环境中,由于网络延迟、节点故障等因素,确保多个服务之间的数据一致性成为一个挑…...
)
如何彻底关闭Elasticsearch 7.x的安全警告提示(内网开发必备)
彻底关闭Elasticsearch 7.x安全警告的实战指南 每次启动Elasticsearch时,控制台不断刷新的安全警告是否让你感到烦躁?特别是在内网开发环境中,这些红色警告既不影响功能又无法忽略。本文将带你深入理解警告产生的机制,并提供三种不…...

番茄小说下载创新工具:一站式EPUB转换与离线阅读解决方案
番茄小说下载创新工具:一站式EPUB转换与离线阅读解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读日益普及的今天,小说爱好者常面临三…...

OpCore Simplify终极指南:30分钟完成黑苹果智能配置的完整解决方案
OpCore Simplify终极指南:30分钟完成黑苹果智能配置的完整解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 对于想要体验macOS系统…...

OpCore-Simplify:颠覆性重构开源系统硬件适配流程,从8小时到30分钟的效率革命
OpCore-Simplify:颠覆性重构开源系统硬件适配流程,从8小时到30分钟的效率革命 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify …...

周末限免别浪费!手把手教你用Node.js和Gemini API玩转Nano Banana开源项目
周末限免别浪费!手把手教你用Node.js和Gemini API玩转Nano Banana开源项目 周末的闲暇时光,正是技术爱好者探索新工具的最佳时机。最近Google AI Studio推出的Gemini API周末限免活动,为开发者们提供了一个零成本体验前沿AI技术的绝佳机会。…...