learning rate
这里写目录标题
- learning rate
- 单一固定(one-size-fits-all)的学习率Model训练到驻点很困难(学习率太大不能收敛,学习率太小收敛太慢)
- 如何客制化学习率?- 引入参数σ
- σ常见的计算方式 - Root mean square(均方根)
- Adagrad - 不同参数不同学习率
- RMSProp - 不同参数不同学习率+同一参数不同学习率
- Adam:RMSProp + Momentum
- 小梯度累加导致learning rate 暴增
- 如何让时间影响学习率? - 方式一:Learning Rate Decay(学习速率衰减)
- 如何让时间影响学习率? - 方式二:Warm Up(预热)
learning rate
loss下降到走不下去的时候,gradient真的很小吗?不一定噢,不一定卡在local minimal还是saddle point
思考训练卡住的原因是,
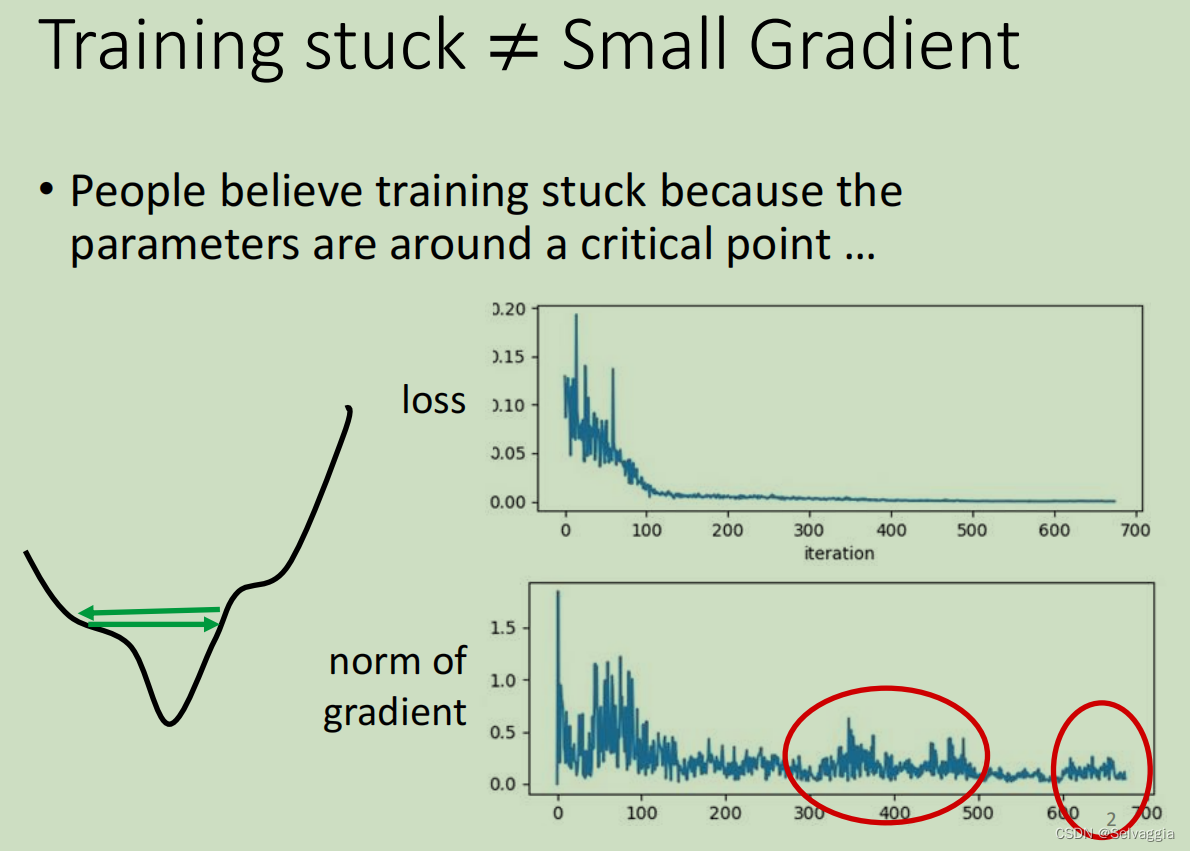
通过观察norm(向量) of gradient
loss几乎没动了,gradient还是有上升下降的波动的痕迹
梯度下降可能会发生锯齿现象
用一般的gradient decent往往做不到如图(由于遇到minimal point或者是saddle point,loss无法继续下降)的效果,往往在gradient decent还很大的时候,loss就下不去了
多数training在还没走到critical point的时候就已经停止了
当loss不再下降时,并不一定是gradient很小的情况(saddle point 或者 local minima),也有可能是gradient在error surface山谷的两个谷壁间不断的来回的震荡导致loss不能再下降。
单一固定(one-size-fits-all)的学习率Model训练到驻点很困难(学习率太大不能收敛,学习率太小收敛太慢)
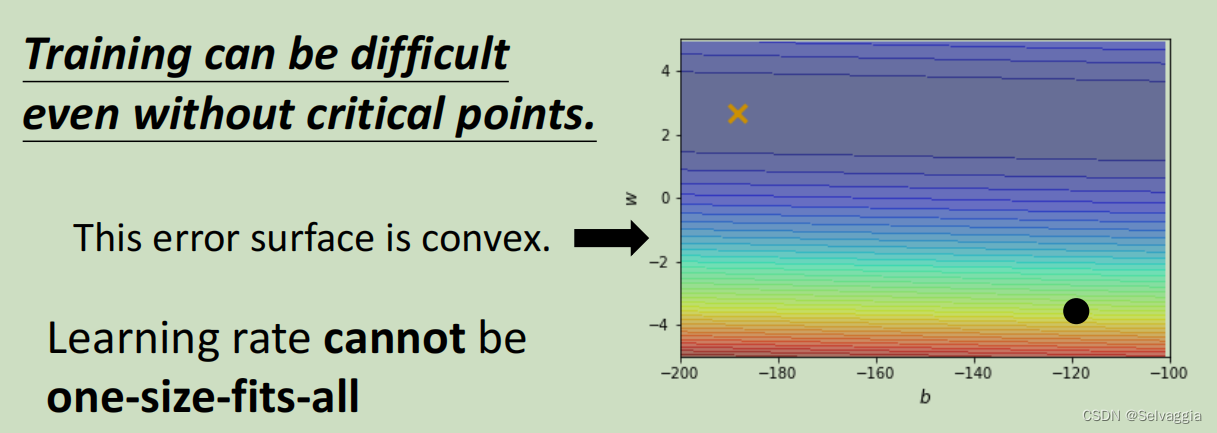
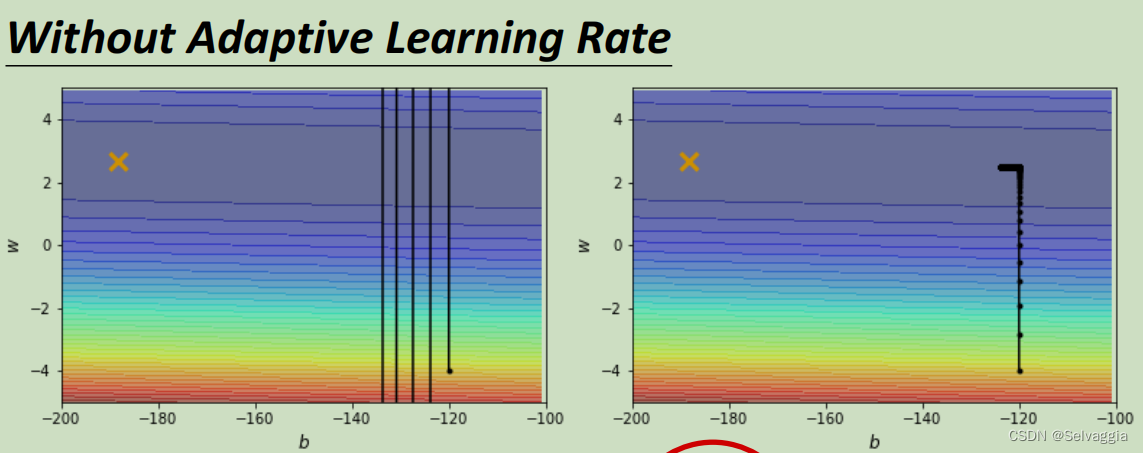
以上图为例子,只有两个参数,这两个参数值不一样的时候Loss的值不一样,画出了error surface,这个error surface的最低点在上图黄色X的地方。事实上,这个error surface是convex的形状(可以理解为凸的或者凹的,convex optimization常翻译为“凸优化”)。
这个非常简单的error surface ,在纵向的变化特别密集((gradient非常的大,它的坡度的变化非常的大、非常的陡峭)),在横向的变化特别平滑(gradient非常的小,它的坡度的变化非常的小、非常的平滑),可以理解成上面的“等高线”是一个长轴特别长,短轴特别短的椭圆。我们现在要从黑点这个地方当作初始点,目标的最佳点是×所在的位置。
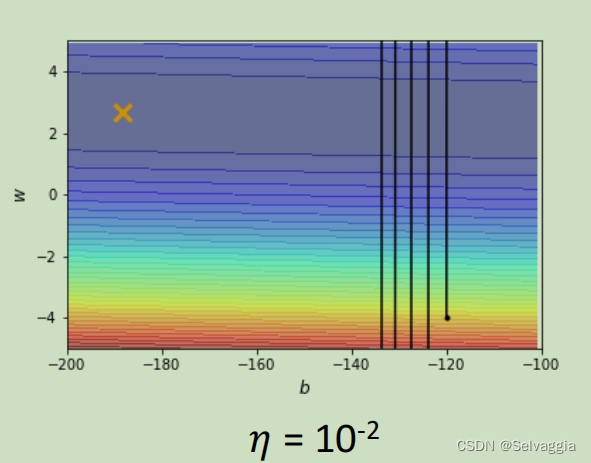
当learning rate设为 1 0 − 2 10^{-2} 10−2 的时候,这个参数在峡谷的两端不断的震荡从而导致loss掉不下去,但此时的gradient仍然很大。
那你可能说是因为learning rate设太大了,learning rate决定了我们update参数的时候步伐有多大,learning rate步伐太大,没办法慢慢地滑到山谷里面,只要把learning rate设小一点不就可以解决这个问题了吗? 调这个learning rate从10⁻²一直调到10⁻⁷终于不再震荡。
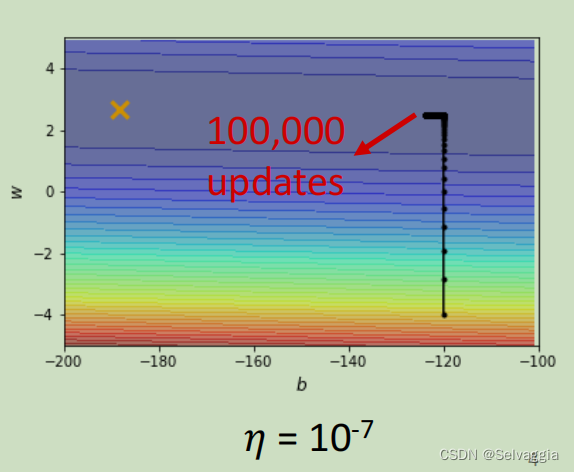
但是这个训练此时永远走不到终点,因为learning rate已经太小了,上图中垂直竖线,因为坡度很陡、gradient的值很大,所以还能够前进一点;左拐以后在横短黑线这个地方坡度已经非常平滑了,非常小的gradient 和 这么小的learning rate根本没有办法再让训练前进 ( θ i + 1 = θ i − η g ) ( \theta _{i + 1} = θ_ i − η g ) (θi+1=θi−ηg)
事实上在左拐这个地方,这一大堆黑点有十万个,所以显然就算是一个convex的error surface,你用gradient descend也很难train。
在之前的gradient descend中,所有的参数都是设同样的learning rate,这显然不太合适,learning rate它应该要根据不同的参数进行定制,也就是客制化。
如何客制化学习率?- 引入参数σ
Different parameters needs different learning rate(不同的参数需要不同的学习率)
那客制化学习率的方法是什么? 从刚才的例子中,其实可以看到一个大原则,如果在某一个方向上的gradient的值很小,非常的平坦,那我们会希望learning rate调大一点;如果在某一个方向上非常的陡峭,坡度很大,那我们其实期待learning rate可以设得小一点。 也就是说希望学习率可以根据梯度的情况进行调整
接下来看σ常见的计算方式。
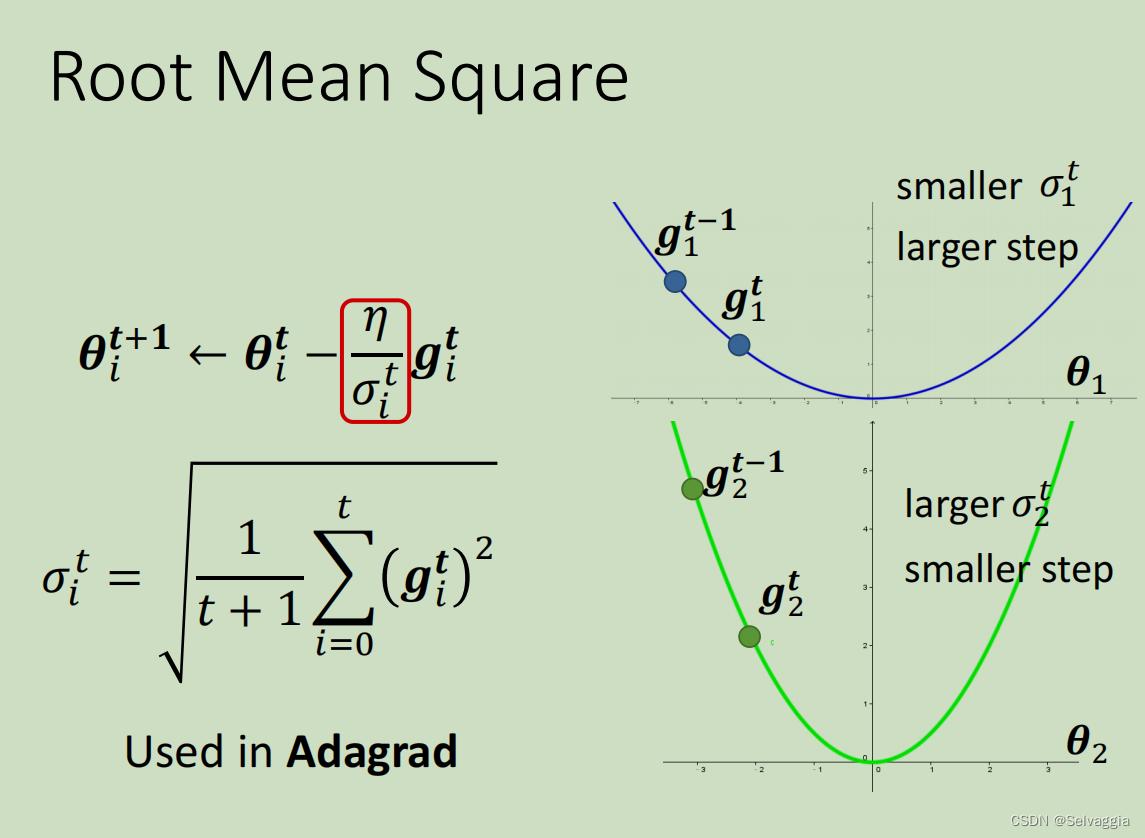
σ常见的计算方式 - Root mean square(均方根)
Adagrad - 不同参数不同学习率
上面这个方法被应用在Adagrad算法中,Adagrad解决不同参数应该使用不同的更新速率的问题。Adagrad是自适应地为各个参数分配不同学习率的算法。
以上版本绝非最终版本
Root Mean Square中,每一个gradient都有同等的重要性,
但在RMS Prop中,你可以自己调整gradient的重要性或权重。
通过参数设置来决定,是当前的gradient更具有决定性还是之前的gradient更具有决定性
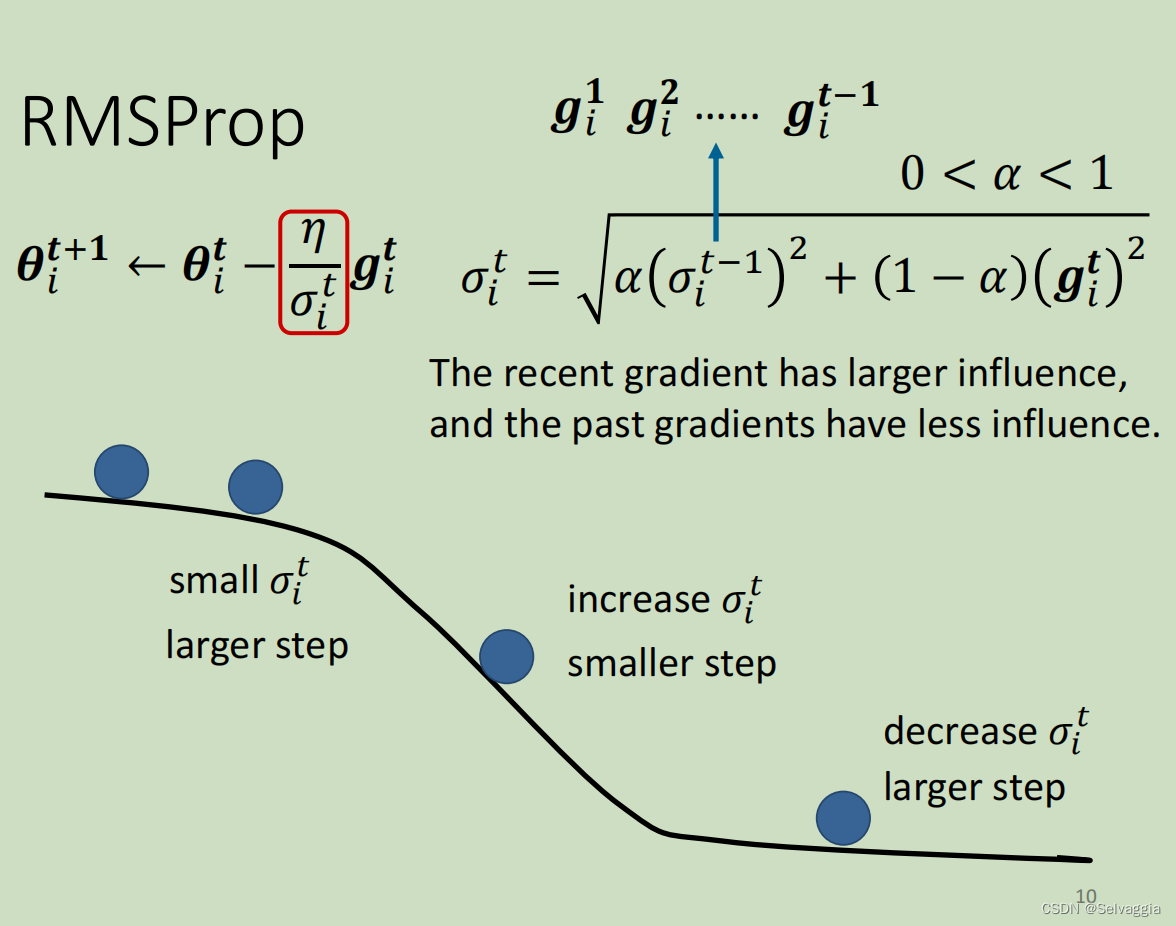
RMSProp - 不同参数不同学习率+同一参数不同学习率
root mean square prop:均方根传递
我们期望:就算是同一个参数,它需要的learning rate也会随著时间而改变。
上面的方法中我们假设,同一个参数,其gradient的大小差不多。
但事实上并不是这样,比如下图这个例子,心月形的error surface
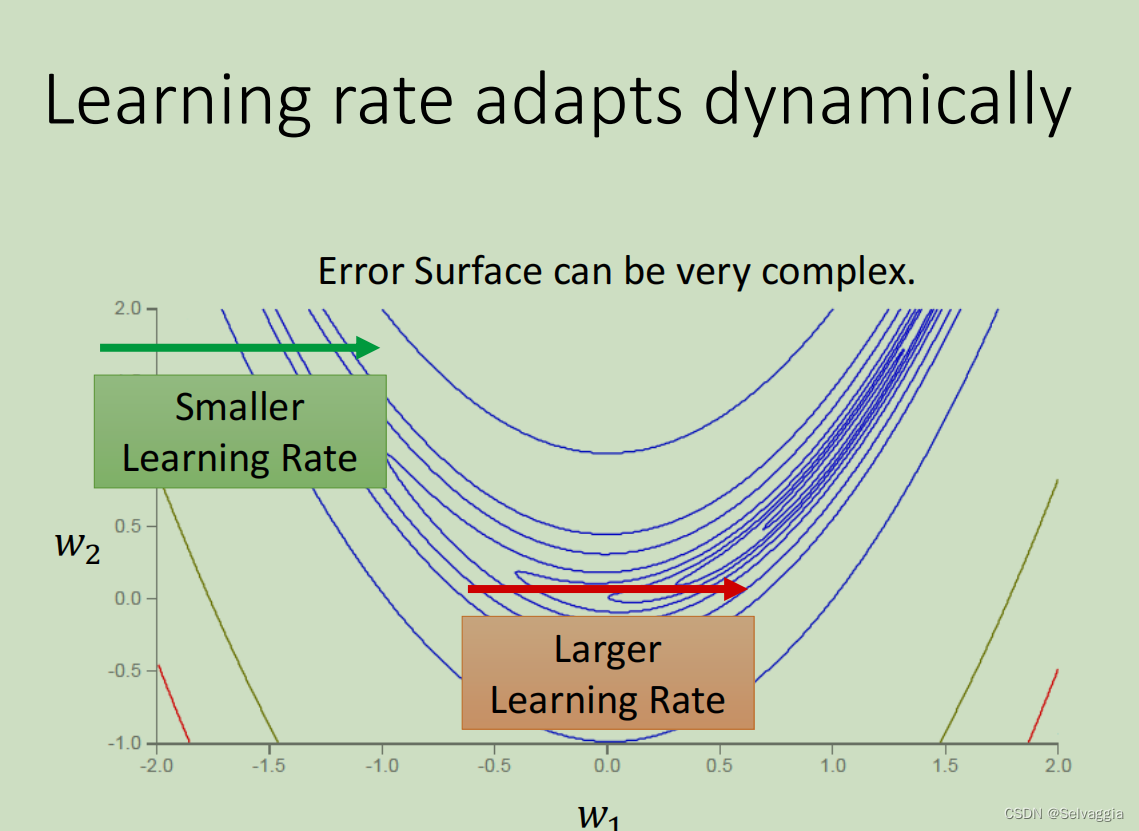
【 红色箭头处相比于绿色箭头处的gradient是比较平缓的,下面那个穿过很多相同的等高线,等于穿过一个平滑的小谷地
maybe need some knowledge about 自然地理??】
红色和绿色线的方向,可以看做同一个参数w2的同一个方向,所以就算是同一个参数的同一个方向,也需要learning rate可以动态的调整。于是就有了RMS Prop。
RMS Prop 不是出自论文,只是Hinton在自己的deep learning课程中提出的。
Adam:RMSProp + Momentum
Adam是现在最常用的optimization的策略。
Adam就是RMS Prop加上Momentum,Adam的演算法跟原始的论文
在pytorch中都帮你把算法写好了,所以不用担心这种optimization的问题。optimizer的deep learning套件往往都做好,然后这个optimizer里面也有一些hyperparameter需要人工决定,但是你往往用预设的那一种参数就可以了,自己调有时候会调到比较差的。
小梯度累加导致learning rate 暴增
小梯度累加导致learning rate 暴增
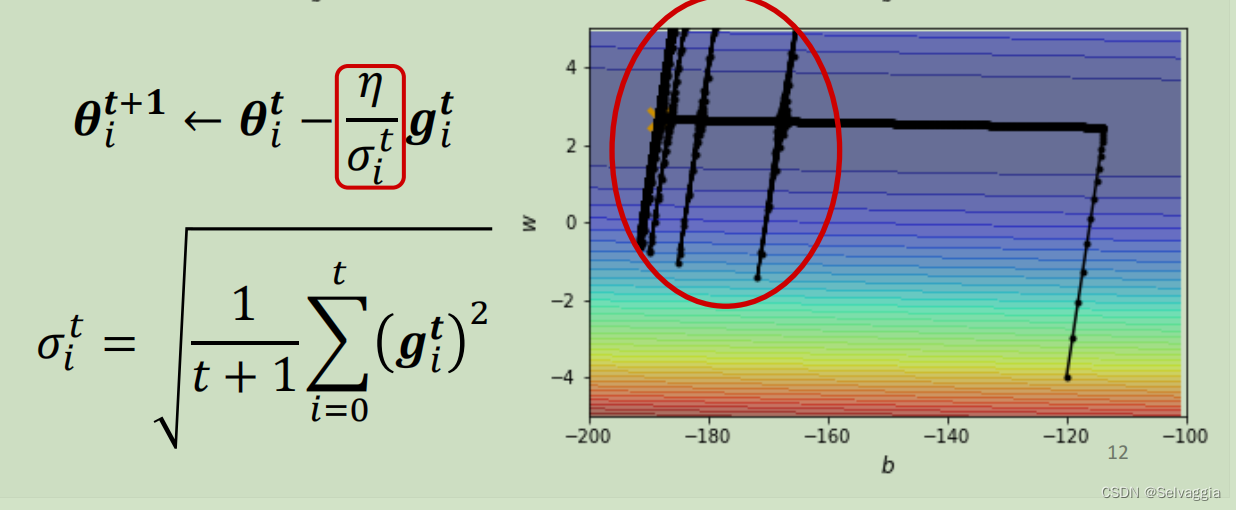
如何处理梯度爆炸?- 让时间影响学习率
如何处理这种“爆发”问题,有一个方法叫做learning rate scheduling可以解决。
如何让时间影响学习率? - 方式一:Learning Rate Decay(学习速率衰减)
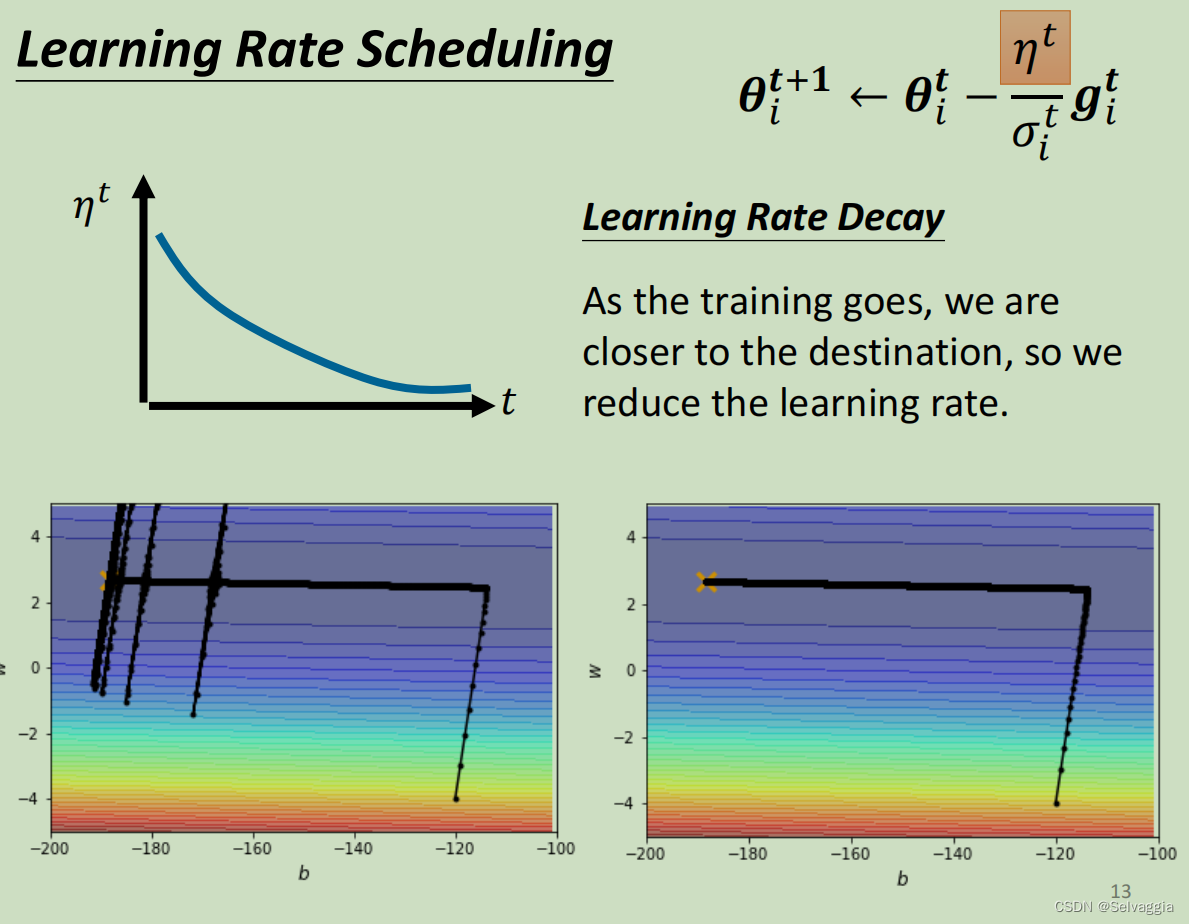
最常见的方法叫做Learning Rate Decay(学习速率衰减),也就是说随着时间的不断地前进、随着参数不断的update,让η越来越小。
如何让时间影响学习率? - 方式二:Warm Up(预热)
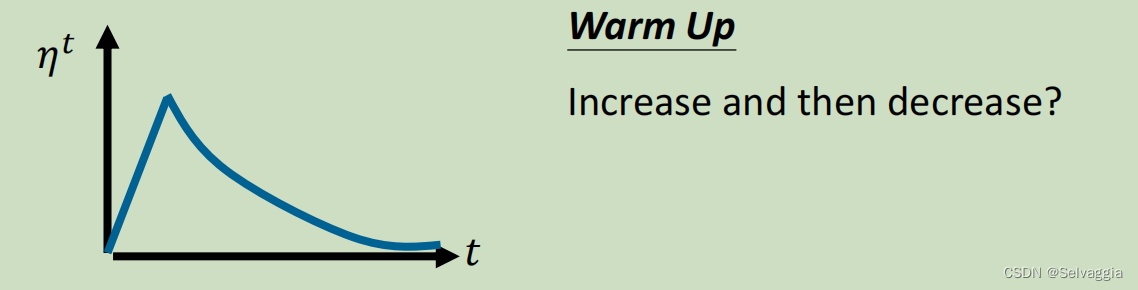
为什么warm up会起作用?- 待研究
一个可能的解释:σ是一个统计量,刚开始时,因为σ没有收集到足够的数据,先让η很小,学习率很小,步子很小,让σ有足够的时间收集更多的error surface的情况,等到σ收集到足够的情况可以做出很好的统计。
博主造福后辈!!!
相关文章:
learning rate
这里写目录标题 learning rate单一固定(one-size-fits-all)的学习率Model训练到驻点很困难(学习率太大不能收敛,学习率太小收敛太慢) 如何客制化学习率?- 引入参数σσ常见的计算方式 - Root mean square&a…...

小型气象站数据采集网关准确监测雨量和风速
随着科技的发展,人们对天气信息的需求也愈发增加。天气是每个人生活中不可或缺的一部分,了解准确的天气信息有助于我们做出合理的决策和安排。在小型气象站数据采集中,一个关键的环节是监测雨量和风速。而小型气象站数据采集网关的出现&#…...

C++常见容器实现原理
引言 如果有一天!你骄傲离去!(抱歉搞错了)如果有一天,你在简历上写下了这段话: 那么你不得不在面试前实现一下STL常见的容器了。C的常用容器有:vector、string、deque、stack、queue、list、se…...
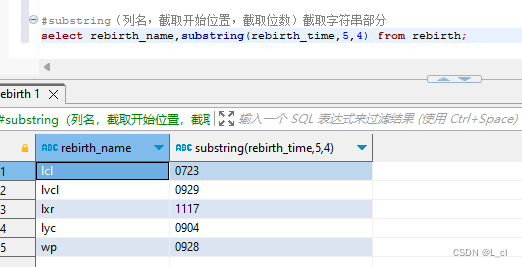
Mysql数据库 5.SQL语言聚合函数 语言日期-字符串函数
一、聚合函数 SQL中提供了一些可以对查询的记录的列进行计算的函数——聚合函数 1.count() 统计函数,统计满足条件的指定字符的值的个数 统计表中rebirth_mood个数 select count(列名) from 表名; #统计表中rebirth_namelcl的个数 select …...
使用Linux JumpServer 堡垒机进行远程访问
文章目录 前言1. 安装Jump server2. 本地访问jump server3. 安装 cpolar内网穿透软件4. 配置Jump server公网访问地址5. 公网远程访问Jump server6. 固定Jump server公网地址 前言 JumpServer 是广受欢迎的开源堡垒机,是符合 4A 规范的专业运维安全审计系统。JumpS…...
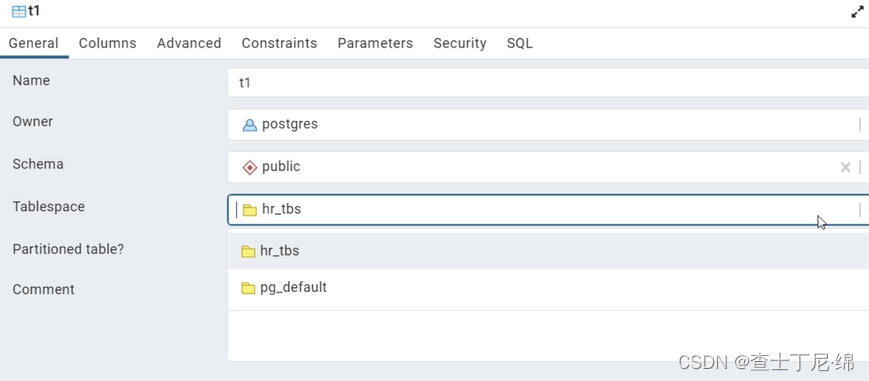
postgresql14管理(五)-tablespace
基本概念 表空间tablespace在postgresql中,表示数据库对象(比如表或索引)的存放目录。当表被访问时,系统通过表空间定位到对应数据文件所在的位置。 优势: 1、如果数据库集群所在的初始磁盘分区或磁盘卷的空间不足&a…...

Echarts-3D柱状图
通过Echarts的echarts.graphic.extendShape实现真正的3D柱状图 思路就是通过调整顶部面(CubeTop)、左侧面(CubeLeft)、右侧面(CubeRight)来决定柱状图的宽窄 建议优先调整顶部面,一般c1不需要动 // echarts-3D-bar-config.js import Vue from "vue";cons…...

vue中组件传值 引用页面与组件页面绑定参数 vue省市地区街道级联选择组件
在做后台的时候需要用到地区级联选择器 然后就自己封装了一个 其中 组件页面中 export default {props: { //使用value接收引用页面的绑定值value: [String]},watch: {value: {handler(val) {//val 以及 this.value 都可以获取到引用页面的绑定值},deep: true,immediate: tr…...

componentDidMount只执行一次的解决方法
一、前言 最近写react antd前端项目,需要页面加载时调用下查询列表的接口。 于是在componentDidMount方法里这样写了: componentDidMount() {const {dispatch,MyJS: { queryPara },} this.props;//这个调用接口查询列表dispatch({ type: MyJS/fetch, …...
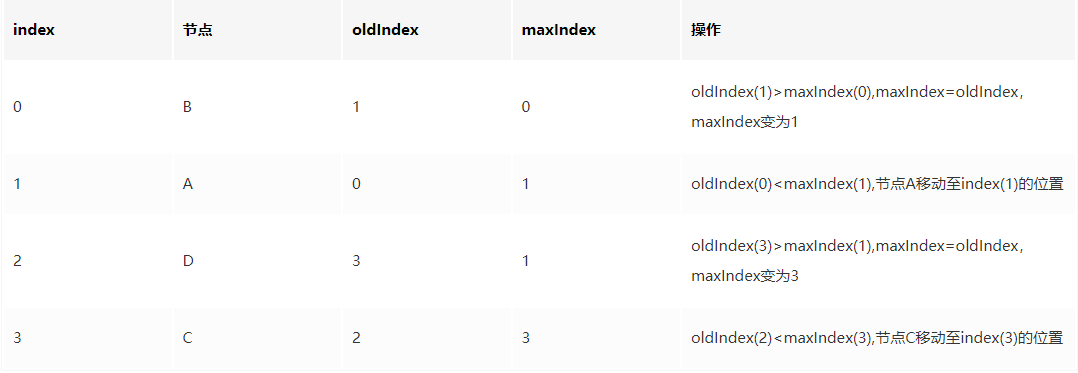
React之diff原理
一、是什么 跟Vue一致,React通过引入Virtual DOM的概念,极大地避免无效的Dom操作,使我们的页面的构建效率提到了极大的提升 而diff算法就是更高效地通过对比新旧Virtual DOM来找出真正的Dom变化之处 传统diff算法通过循环递归对节点进行依…...
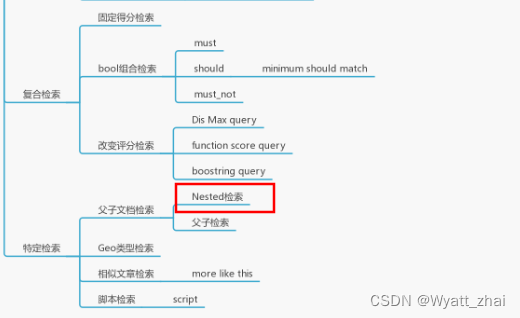
ElasticSearch中关于Nasted嵌套查询的介绍:生动案例,通俗易懂,彻底吸收
题注:随着对ES接触的越来越深入,发现此前了解的ES知识点有点单薄,特此寻来ES知识点汇总成的一个思维导图,全面了解自己掌握了哪些,未掌握哪些。此外,作者斌并没有足够的精力学习ES全部的知识点,…...

系列二、Spring的优缺点是什么
一、Spring的优缺点是什么 1.1、优点 集中管理对象,降低对象和对象之间的耦合性,方便维护对象;在不修改代码的情况下可以对业务代码进行增强,减少重复代码,提高开发效率,方便维护;提高开发效率…...

ESP32网络开发实例-HTTP-GET请求
HTTP-GET请求 文章目录 HTTP-GET请求1、HTTP GET请求2、软件准备3、硬件准备4、代码实现4.1 向OpenWeatherMap请求天气数据4.2 ThingSpeak 中的 ESP32 HTTP GET(更新值)在本文中,我们将介绍如使用ESP32向 ThingSpeak 和 openweathermap.org 等常用 API 发出 HTTP GET 请求。…...

PHP:json_encode和json_decode用法
json_encode 函数用于将 PHP 数据结构转换为 JSON 字符串。json_decode 函数用于将 JSON 字符串转换为 PHP 数据结构。 // 将 PHP 数据结构转换为 JSON 字符串 $data ["name" > "John","age" > 25,"city" > "New York&…...

Kafka-Java二:Spring配置kafka消息发送端的缓冲区
一、涉及到的组件概念 1.1、缓冲区 1.2、本地线程 1.3.本地线程消息推送策略 二、各组件的解释参见代码注释 // 配置消息的缓冲区/** 设置消息发送者端的缓冲区大小,如果设置了缓冲区,消息会先发送到缓冲区,可以提供发送性能* 默认大小是32…...

【ArcGIS模型构建器】05:批量为多个矢量数据添加相同的字段
本文实现借助arcgis模型构建器,实现批量为多个土地利用矢量数据添加相同的字段,例如DLMC,DLTB等。 文章目录 问题分析模型构建问题分析 有多个土地利用数据矢量图层,每个图层中有很多个图斑,现在需要给每个图层添加一个或者多个字段,如DLCM,DLBM等。 属性表如下所示: …...

坤坤的悲伤生活
描述 坤坤,这几个月来都非常悲伤,因为自己事发了,有一些问题找上了门,这个时候,有个人进献了一个阿拉丁神灯,有个灯神能够解决掉这个问题,但是有前提,必须回答出它的问题,…...
职业技术认证:《研发效能(DevOps)工程师》——开启职业发展新篇章
在互联网行业中,资质认证可以证明在该领域内的专业能力和知识水平。各种技术水平认证也是层出不穷,而考取具有公信力和权威性的认证是从业者的首选。同时,随着国内企业技术实力的提升和国家对于自主可控的重视程度不断提高,国产证…...

gin 框架出现runtime error: index out of range [0] with length 0
之前是这样的: category : c.Request.Form["type"][0] 加上这一句就变成了 fmt.Println(c.Request.FormFile("type")) category : c.Request.Form["type"][0]...
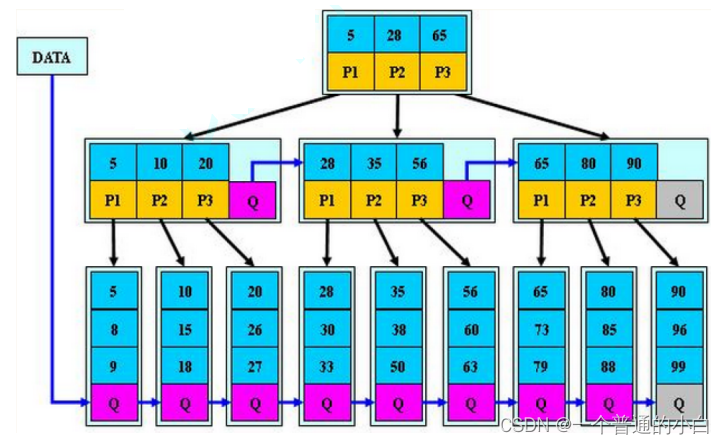
【高阶数据结构】B树
目录 1.B树 2.B树和B树的不同 3.B*树 B树较于哈希红黑树的优势:外查找:读取磁盘数据 ; B树的高度更低,对磁盘的进行I/O操作的次数更少(磁盘的性能比内存差得多); 1.B树 1.1.B树的概念&am…...

突破存储限制:群晖DSM7下Synology Photos自定义文件夹挂载实战
1. 为什么需要自定义文件夹挂载 很多群晖用户升级到DSM7后都会遇到一个头疼的问题:Synology Photos默认把所有个人照片都存放在/home/Photos目录下,而这个目录实际上位于/homes共享文件夹中。随着照片数量不断增加,/homes所在存储空间很快就会…...

将HermesAgent项目接入Taotoken的详细配置步骤与注意事项
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将HermesAgent项目接入Taotoken的详细配置步骤与注意事项 本文旨在为开发者提供一份清晰的指南,帮助你将HermesAgent项…...

如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南
如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否厌倦了每次启动Minecraft都要手动配…...

等压雨幕原理在铝合金窗的应用
等压雨幕原理在铝合金窗的应用 摘要: 针对常见的样窗水密气密不达标,首先概述等压雨幕的作用原理,然后介绍其在铝合金门窗应用中的代表性细节。可以看出,控制框扇搭接处的间隙很重要,以及密封胶条合理设计选用的重要性。而且日系推拉采用等压设计的方式很值得借鉴。 关键…...

终极FGO自动化助手:告别枯燥刷本,每天节省3小时游戏时间
终极FGO自动化助手:告别枯燥刷本,每天节省3小时游戏时间 【免费下载链接】FGA Auto-battle app for F/GO Android 项目地址: https://gitcode.com/gh_mirrors/fg/FGA Fate/Grand Automata(简称FGA)是一款专为Fate/Grand Or…...

怎么判断一家工厂还在不在正常生产?6 类活跃度信号,从纸面到现场
跑工厂的销售员都遇到过这种事:手机里存着一份名单,导航开两小时,到门口才发现卷帘门焊死、车间长草、保安说"厂子去年就搬了"。 问题出在哪?大多数人判断"这家工厂在不在",靠的是工商登记——执照…...

m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕
m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容日益丰富的今天…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...

量子控制中的动态校正门与SCQC几何方法
1. 量子控制中的噪声挑战与动态校正门在超导量子处理器上实现高保真度的量子门操作,最大的障碍来自环境噪声。这些噪声主要分为两类:失谐噪声(δz)和幅度噪声(ϵ)。失谐噪声源于量子比特频率的漂移…...

BiscuitLang:专为Web业务逻辑设计的轻量级脚本语言
1. 项目概述:一个为现代Web开发而生的轻量级语言如果你和我一样,长期在Web前端和全栈开发的泥潭里摸爬滚打,那你一定对JavaScript生态的“臃肿”与“复杂”深有体会。一个简单的项目动辄node_modules文件夹体积惊人,工具链配置繁琐…...