Pytorch从零开始实战07
Pytorch从零开始实战——咖啡豆识别
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——咖啡豆识别
- 环境准备
- 数据集
- 模型选择
- 训练
- 模型可视化
- 模型预测
- 其他问题
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的是手写VGG,并且测试多GPU。
第一步,导入常用包
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn.functional as F
import random
from time import time
import numpy as np
import pandas as pd
import datetime
import gc
import os
import copy
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
创建设备对象,并且查看GPU数量
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device, torch.cuda.device_count()
数据集
本次使用的数据集是咖啡豆图片,它分为四个类别,Dark、Green、Light、Medium,一共有1200张图片,不同的类别存放在不同的文件夹中,文件夹名是类别名。
使用pathlib查看类别
import pathlib
data_dir = './data/beans'
data_dir = pathlib.Path(data_dir) # 转成pathlib.Path对象
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("/")[2] for path in data_paths]
classNames # ['Dark', 'Green', 'Medium', 'Light']
使用transforms对数据集进行统一处理,并且根据文件夹名映射对应标签
train_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])total_data = datasets.ImageFolder("./data/beans/", transform=train_transforms)
total_data.class_to_idx # {'Dark': 0, 'Green': 1, 'Light': 2, 'Medium': 3}
随机查看5张图片
def plotsample(data):fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图for i in range(5):num = random.randint(0, len(data) - 1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签 #将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0))) axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴plotsample(total_data)

根据8比2划分数据集和测试集,并且利用DataLoader划分批次和随机打乱
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size, test_size])batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,batch_size=batch_size,shuffle=True,)
test_dl = torch.utils.data.DataLoader(test_ds,batch_size=batch_size,shuffle=True,)len(train_dl.dataset), len(test_dl.dataset) # (960, 240)
模型选择
本次实验使用VGG16,模型如下
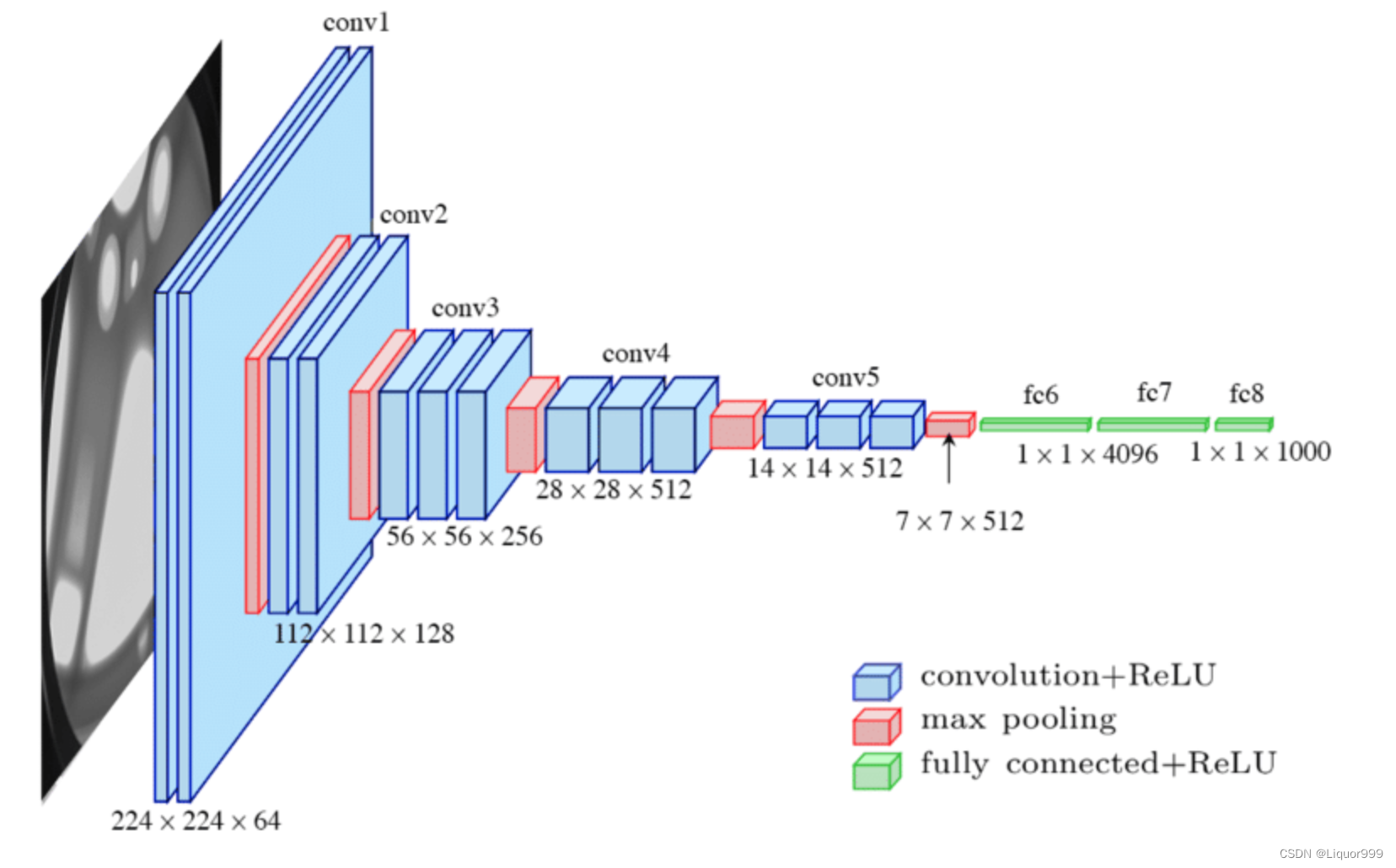
class Model(nn.Module):def __init__(self):super().__init__()self.block1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2))self.block2 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2))self.block3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2))self.block4 = nn.Sequential(nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2))self.block5 = nn.Sequential(nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2))self.fc = nn.Sequential(nn.Linear(7 * 7 * 512, 4096),nn.ReLU(),nn.Linear(4096, 4096),nn.ReLU(),nn.Linear(4096, len(classNames)))def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.block4(x)x = self.block5(x)x = x.view(-1, 7 * 7 * 512)x = self.fc(x)return x
使用summary查看模型结构,并且将模型转成多GPU并行运算的模型
from torchsummary import summary
# 将模型转移到GPU中
model = Model()
model = model.to(device)
if torch.cuda.device_count() > 1: # 检查电脑是否有多块GPUprint(f"Let's use {torch.cuda.device_count()} GPUs!")model = nn.DataParallel(model) # 将模型对象转变为多GPU并行运算的模型summary(model, input_size=(3, 224, 224))

训练
定义训练函数
def train(dataloader, model, loss_fn, opt):size = len(dataloader.dataset)num_batches = len(dataloader)train_acc, train_loss = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)opt.zero_grad()loss.backward()opt.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
定义损失函数、优化算法、学习率,本次使用的是Adam优化算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.0001
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
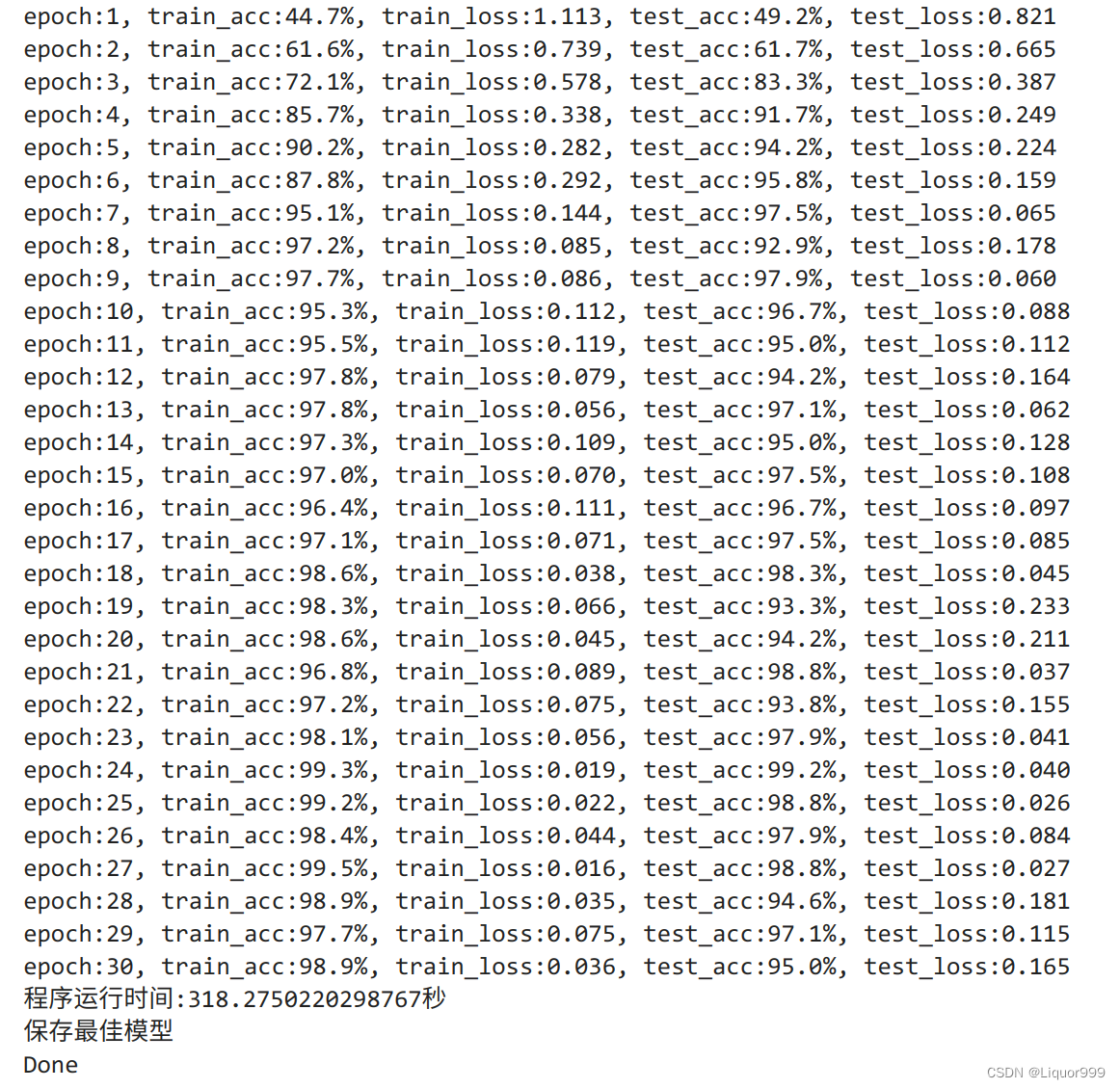
开始训练,准确率还是非常高的
import time
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []T1 = time.time()best_acc = 0
best_model = 0for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)if epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))T2 = time.time()
print('程序运行时间:%s秒' % (T2 - T1))PATH = './best_model.pth' # 保存的参数文件名
if best_model is not None:torch.save(best_model.state_dict(), PATH)print('保存最佳模型')
print("Done")
模型可视化
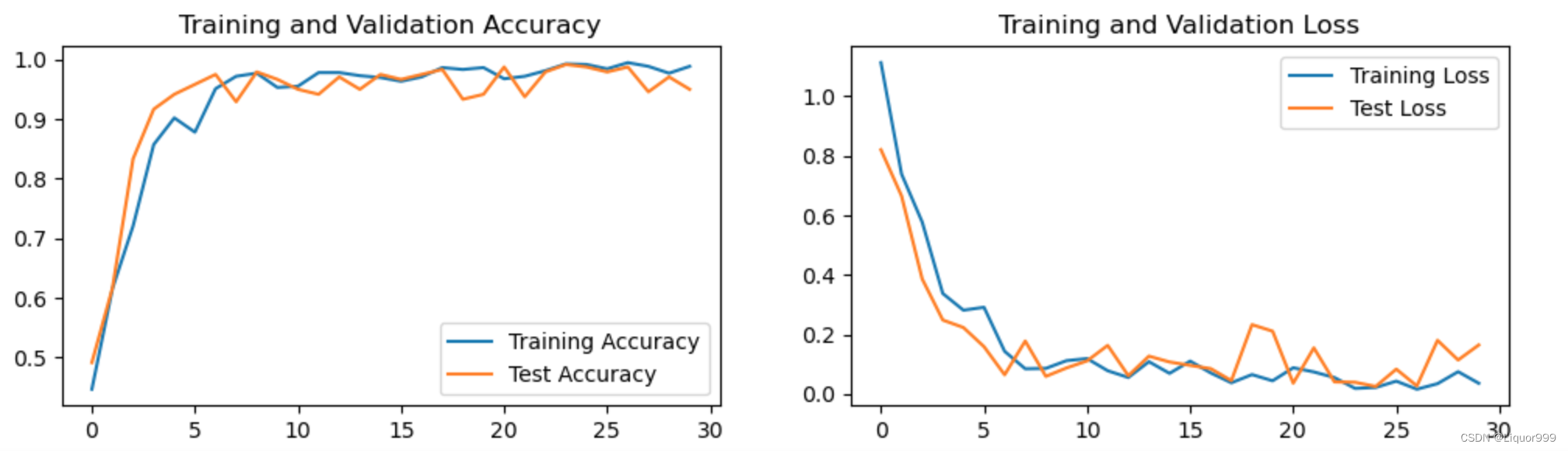
使用matplotlib可视化训练、测试过程
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
模型预测
定义模型预测函数
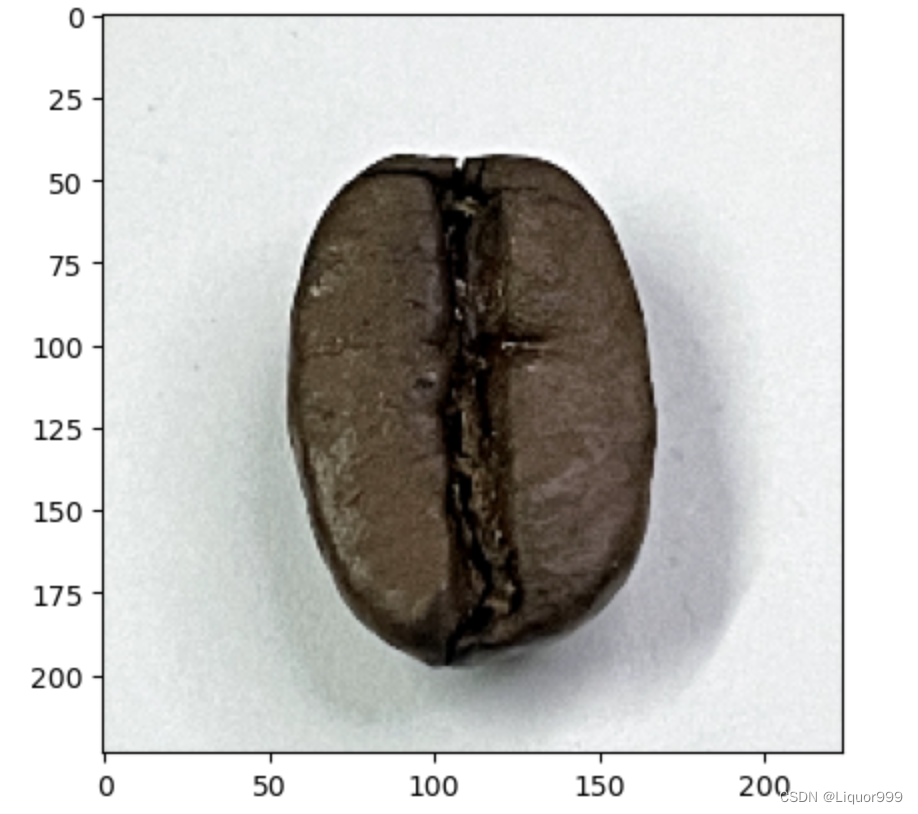
from PIL import Image classes = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
开始单张图片预测
predict_one_image(image_path='./data/beans/Dark/dark (1).png', model=model, transform=train_transforms, classes=classes) # 预测结果是:Dark
查看最优的模型的准确率和损失
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss # (0.9916666666666667, 0.0399394309388299)
其他问题
本次实验又使用了单GPU,进行训练
# 单GPU
from torchsummary import summary
# 将模型转移到GPU中
model = Model()
model = model.to(device)
结果如下

总结
本次实验主要手写了经典网络架构VGG16,并且使用两张GPU和一张GPU进行实验,但惊奇的发现,一张GPU运行时间是164秒,两张GPU运行时间是318秒,明明算力提高了,反而训练时间更加慢了,经过资料的查询,大概原因是数据量很小,GPU之间传递数据占用时间相对大于加速运算时间,所以训练时间反而变长了。
相关文章:
Pytorch从零开始实战07
Pytorch从零开始实战——咖啡豆识别 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——咖啡豆识别环境准备数据集模型选择训练模型可视化模型预测其他问题总结 环境准备 本文基于Jupyter notebook,使用Python3.8,Pytor…...

大数据知识扫盲
MapReudece作业启动和运行机制 MapReduce是一种分布式计算框架,最初由Google开发,用于处理大规模数据集的批处理任务。其核心思想是将数据划分为小的块,然后并行处理这些块,最后将结果合并。以下是MapReduce作业的启动和运行机制…...

使用Ubuntu虚拟机离线部署RKE2高可用集群
环境说明 宿主机和虚拟机的OS与内核相同,如下 $ cat /etc/issue Ubuntu 22.04.3 LTS \n \l$ uname -sr Linux 6.2.0-34-generic虚拟化软件版本 $ kvm --version QEMU emulator version 6.2.0 (Debian 1:6.2dfsg-2ubuntu6.14) Copyright (c) 2003-2021 Fabrice Be…...
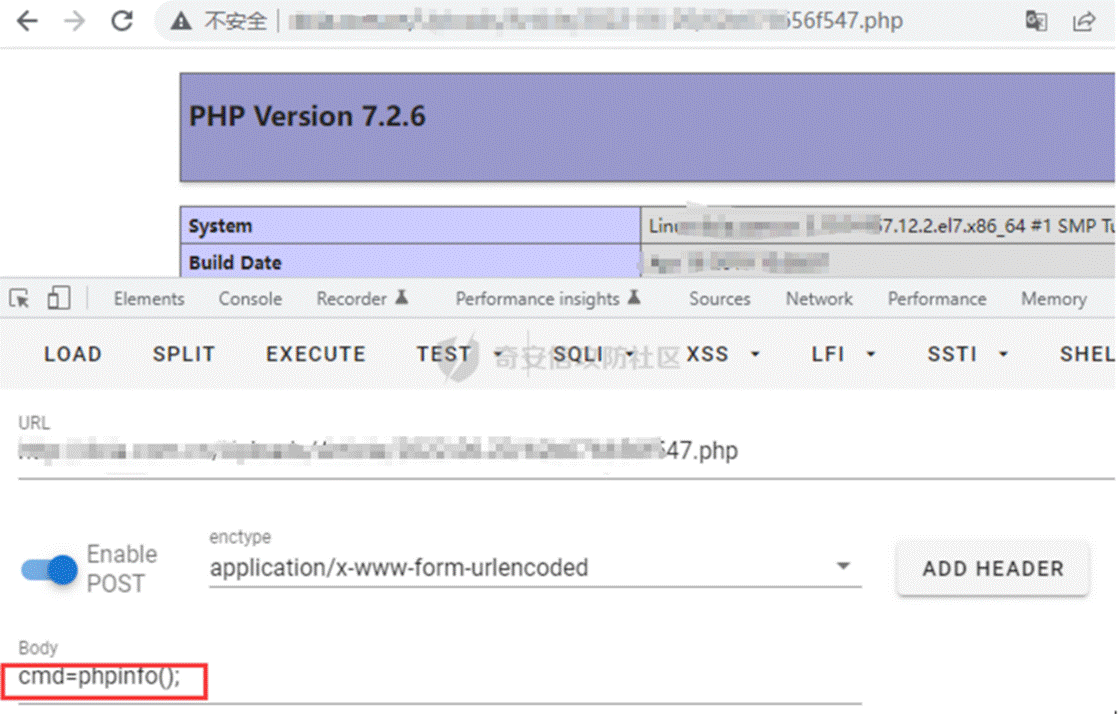
记一次任意文件下载到Getshell
任意文件下载(Arbitrary File Download)是一种常见的 Web 攻击技术,用于窃取服务器上任意文件的内容。攻击者利用应用程序中的漏洞,通过构造恶意请求,使应用程序将任意文件(如配置文件、敏感数据等…...
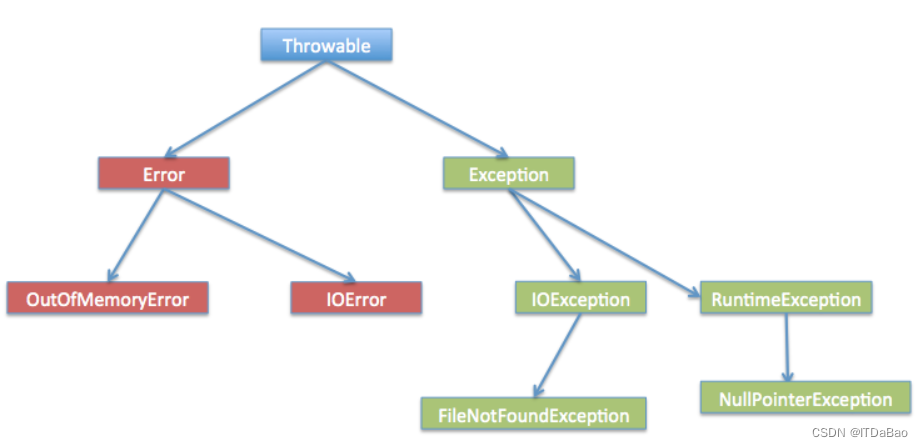
java异常处理
异常处理分为三类: 检查性异常 用户错误或问题引起的异常,这是程序员无法预见的。例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略。 运行时异常 运行时异常是可能被程序员避免的异常…...

递归为什么这么难?一篇文章带你了解递归
递归为什么这么难?一篇文章带你了解递归 美国计算机科学家——彼得多伊奇(L Peter Deutsch)在《程序员修炼之道》(The Pragmatic Programmer)一书中提到“To Iterate is Human, to Recurse, Divine”——我理解的这句话为:人理解迭代,神理解…...
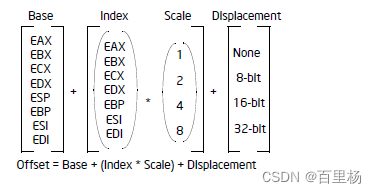
X86(32位)汇编指令与机器码转换原理
X86(32位)汇编指令与机器码转换原理 1 32位寻址形式下的ModR/M字节2 汇编指令转机器码2.1 mov ecx,[eaxebx*2]2.1.1 查Opcode和ModR/M2.1.2 查SIB 2.2 mov ecx,[eaxebx*210h]2.3 mov ecx,[eaxebx*200000100h] 本文属于《 X86指令基础系列教程》之一&…...
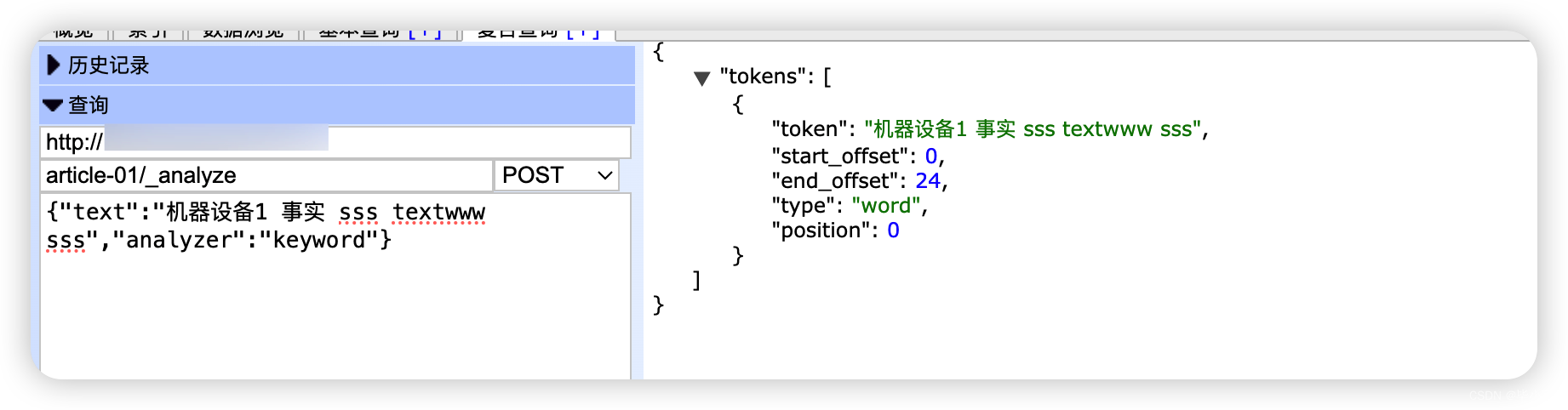
ES 全字段模糊检索时分词方式对检索结果的影响
文章目录 背景创建索引指定 _all 分词为空格创建索引插入索引数据全字段的模糊检索 创建索引指定 _all 分词为 keyword索引创建插入数据模糊检索 创建索引不配置 _all不同分词的结果启示录 背景 2018年参与使用 ES 和 Kafka 项目的开发,当时主要是做前端开发&#…...
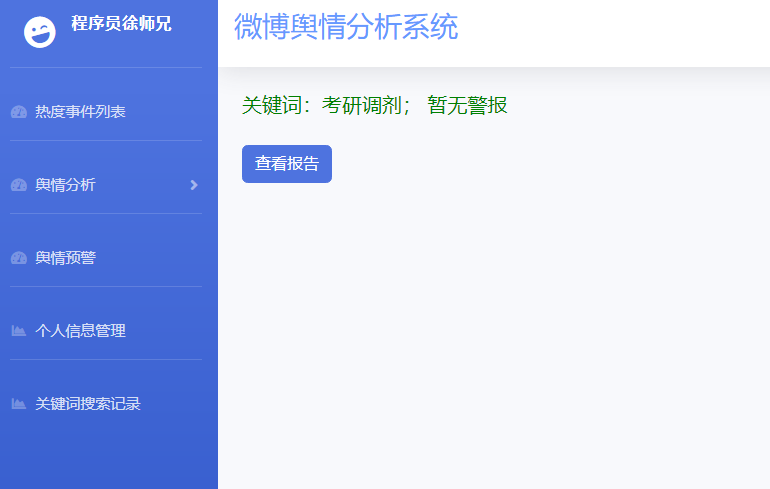
基于Python Django 的微博舆论、微博情感分析可视化系统(V2.0)
文章目录 1 简介2 意义3 技术栈Django 4 效果图微博首页情感分析关键词分析热门评论舆情预测 5 推荐阅读 1 简介 基于Python的微博舆论分析,微博情感分析可视化系统,项目后端分爬虫模块、数据分析模块、数据存储模块、业务逻辑模块组成。 Python基于微博…...

python读取Excel到mysql
常见问题: 1.数据库密码有特殊字符 使用urllib.parse.quote_plus 编译密码 mysql_engine create_engine((f"mysqlpymysql://root:%s10.0.0.2:3306/mydb")%urllib.parse.quote_plus("passaaaa")) 2.设置字段类型 设置特定类型,和指…...

C++八股文面经
1.介绍一下你对面向对象的理解, 面向对象编程(Object-Oriented Programming,简称OOP)是一种编程范式,它将数据和操作数据的方法组合成一个对象,以此来描述现实世界中的事物和概念。在面向对象编程中&#…...

【Linux】静态库和共享库一分钟快速上手
Linux 前言对比创建静态库动态库 前言 程序库,对于程序原来说是非常重要的。但不少人对其不太了解,接下来一起学习其中的奥秘吧! 简单来说,程序库可以分为静态库和共享库。它们包含了数据和执行代码的文件。其不能单独执行&#…...

C++继承总结(下)——菱形继承
一.什么是菱形继承 菱形继承是多继承的一种特殊情况,一个类有多个父类,这些父类又有相同的父类或者祖先类,那么该类就会有多份重复的成员,从而造成调用二义性和数据冗余。 class Person {public:Person(){cout << "P…...

CCF CCSP2023参赛记 + 算法题题解
大家好啊,时隔多年,作为大四老年人,再次来到这个地方记录算法竞赛相关,可能也是最后一次参加这种算法赛事了,我觉得还是很有纪念意义的。虽然我高中搞OI被强基背刺,以至于到了大学有点躲着竞赛,…...
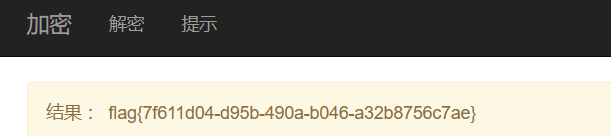
buuctf_练[GYCTF2020]FlaskApp
[GYCTF2020]FlaskApp 文章目录 [GYCTF2020]FlaskApp常用绕过方法掌握知识解题思路解题一 -- 计算pin码解题二 -- 拼接绕过 执行命令 关键paylaod 常用绕过方法 ssti详解与例题以及绕过payload大全_ssti绕过空格_HoAd’s blog的博客-CSDN博客 CTF 对SSTI的一些总结 - FreeBuf网…...

针对element-plus,跳转jump(快速翻页)
待补充 const goToPage () > {const inputElement document.querySelector(.el-pagination .el-input__inner);console.log(inputElement, inputElement); } 打印之后可以看到分页跳转的数字输入框,是有进行处理的,max"102",是我自己的…...
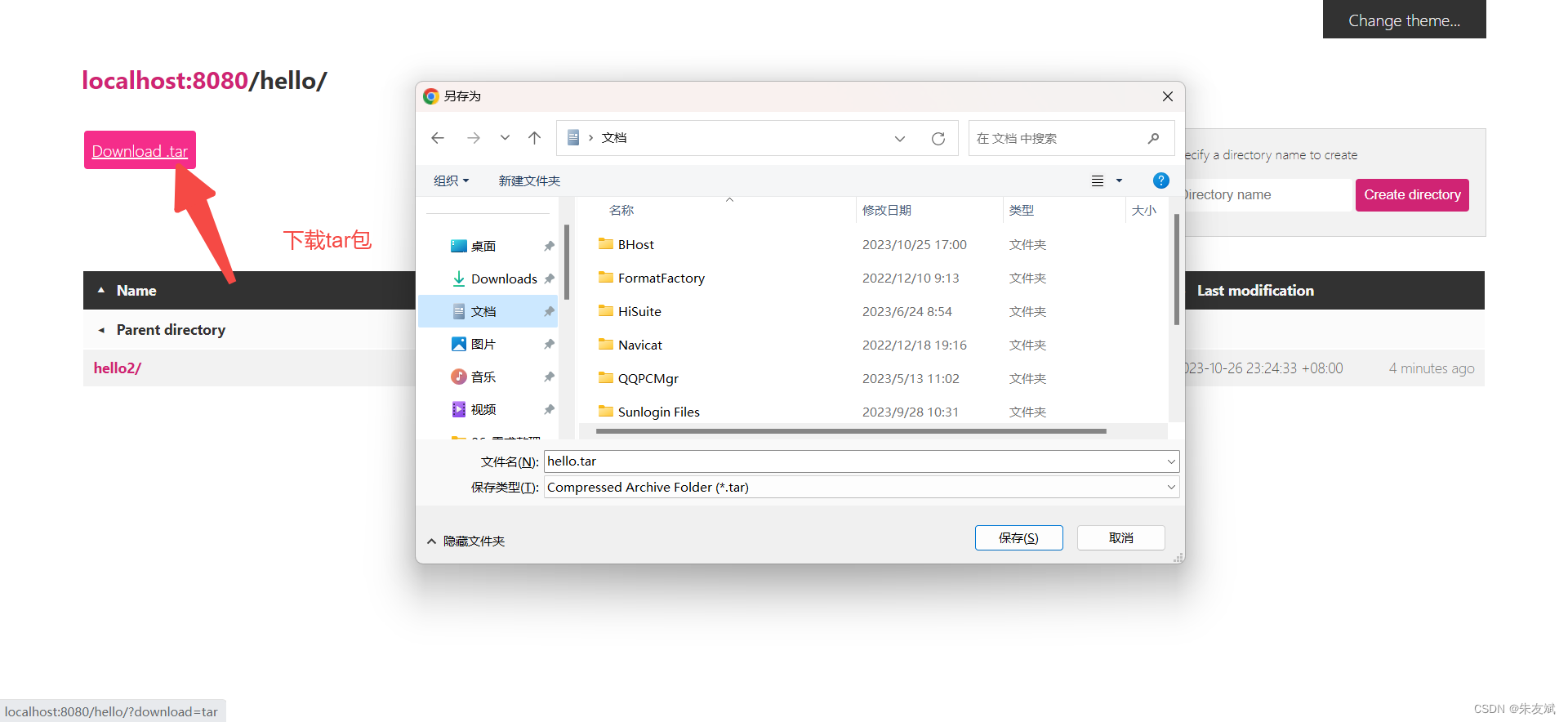
【软件安装】Windows系统中使用miniserve搭建一个文件服务器
这篇文章,主要介绍如何在Windows系统中使用miniserve搭建一个文件服务器。 目录 一、搭建文件服务器 1.1、下载miniserve 1.2、启动miniserve服务 1.3、指定根目录 1.4、开启访问日志 1.5、指定启动端口 1.6、设置用户认证 1.7、设置界面主题 (…...

iOS .a类型静态库使用终端进行拆解和合并生成
项目中会用到许多第三方的.a类型的静态库,有时候会有一些静态库回包含相同文件而产生冲突,我们就需要对这个库进行去重的一个操作。一般有哪些文件冲突了,xcode报错都会有详细的提示。我们可以将这两个库合并,也可以其中一方中的文…...

react-组件间的通讯
一、父传子 父组件在使用子组件时,提供要传递的数据子组件通过props接收数据 class Parent extends React.Component {render() {return (<div><div>我是父组件</div><Child name"张" age{16} /></div>)} }const Child …...

【广州华锐互动】VR公司工厂消防逃生演练带来沉浸式的互动体验
在工业生产过程中,安全问题始终是我们不能忽视的重要环节。特别是火灾事故,不仅会造成重大的经济损失,更会威胁到员工的生命安全。传统的消防安全训练方法,如讲座、实地演练等,虽然具有一定的效果,但是无法…...

163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具
163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量歌词而烦恼吗?163MusicLy…...

迪拜塔幕墙设计
迪拜塔幕墙设计 【作 者】:罗永增 【关键词】:迪拜塔,幕墙,设计,系统。 前言:...

Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南
Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirro…...

番茄小说下载器:打造属于你的个人数字图书馆终极指南
番茄小说下载器:打造属于你的个人数字图书馆终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经遇到过这样的场景?深夜追更小说时网络突然断线&…...

Vim-ai插件深度指南:在Vim中无缝集成AI提升开发效率
1. 项目概述:当Vim遇上AI,一场编辑器生产力的革命如果你和我一样,是个在终端里泡了十多年的老Vim用户,那你一定经历过这样的场景:面对一个复杂的函数重构,手指在键盘上飞舞,:s、%s、宏录制轮番上…...

Python数据聚合抓取工具:从配置化引擎到实战避坑指南
1. 项目概述:一个多功能的“聚合爪”工具最近在GitHub上闲逛,发现了一个名字挺有意思的项目:al1enjesus/polyclawster。这个名字拆开看,“poly”代表多,“clawster”听起来像是“claw”(爪子)和…...

AI量化交易实战:从机器学习模型到加密货币对冲基金系统构建
1. 项目概述:一个面向加密货币的AI对冲基金框架最近几年,AI在量化交易领域的应用已经从实验室走向了实战,尤其是在波动性极高的加密货币市场。如果你对量化交易和机器学习感兴趣,并且想找一个能直接上手、结构清晰的实战项目来学习…...

从肌电信号到Arduino控制:MyoWare传感器实战指南
1. 项目概述:当肌肉“说话”,我们如何“倾听”?如果你玩过一些体感游戏,或者看过科幻电影里用意念控制机械臂的场景,心里大概会闪过一个念头:这玩意儿到底是怎么做到的?其实,很多酷炫…...

基于Python与Playwright的招聘信息自动化聚合与智能筛选工具实践
1. 项目概述:一个面向求职者的自动化信息聚合与投递工具最近在和一些做开发的朋友聊天,发现大家普遍有个痛点:找工作太费时间了。每天要在几个招聘App之间来回切换,重复筛选岗位、刷新列表、投递简历,机械性的操作占据…...
)
计算机毕业设计OpenCV多特征融合的疲劳驾驶检测系统 图像处理 深度学习 大数据毕业设计(源码+LW+PPT+讲解)
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台…...