DeepSpeed: 大模型训练框架 | 京东云技术团队
背景:
目前,大模型的发展已经非常火热,关于大模型的训练、微调也是各个公司重点关注方向。但是大模型训练的痛点是模型参数过大,动辄上百亿,如果单靠单个GPU来完成训练基本不可能。所以需要多卡或者分布式训练来完成这项工作。
一、分布式训练
1.1 目前主流的大模型分布式训练主要包括两种:
- 数据并行训练
- 模型并行训练
二、DeepSpeed
DeepSpeed是由Microsoft提供的分布式训练工具,旨在支持更大规模的模型和提供更多的优化策略和工具。对于更大模型的训练来说,DeepSpeed提供了更多策略,例如:Zero、Offload等。
2.1 基础组件
分布式训练需要掌握分布式环境中的基础配置,包括节点变化、全局进程编号、局部进程编号、全局总进程数、主节点等。这些组件都跟分布式训练紧密相关,同时组件之间也有非常大的联系,例如通信联系等。
2.2 通信策略
既然是分布式训练,那机器之间必须要保持通信,这样才可以传输模型参数,梯度参数等信息。
DeepSpeed提供了mpi、gioo、nccl等通信策略
| 通信策略 | 通信作用 |
|---|---|
| mpi | 它是一种跨界点的通信库,经常用于CPU集群的分布式训练 |
| gloo | 它是一种高性能的分布式训练框架,可以支持CPU或者GPU的分布式训练 |
| nccl | 它是nvidia提供的GPU专用通信库,广泛用于GPU上的分布式训练 |
我们在使用DeepSpeed进行分布式训练的时候,可以根据自身的情况选择合适的通信库,通常情况下,如果是GPU进行分布式训练,可以选择nccl。
2.3 Zero(零冗余优化器)
Microsoft开发的Zero可以解决分布式训练过程中数据并行和模型并行的限制。比如: Zero通过在数据并行过程中划分模型状态(优化器、梯度、参数),来解决数据并行成可能出现内存冗余的情况(正常数据并行训练,模型全部参数是复制在各个机器上的);同时可以在训练期间使用动态通信计划,在分布式设备之间共享重要的状态变量,这样保持计算粒度和数据并行的通信量。
Zero是用于大规模模型训练优化的技术,它的主要目的是减少模型的内存占用,让模型可以在显卡上训练,内存占用主要分为Model States和Activation两个部分,Zero主要解决的是Model States的内存占用问题。
Zero将模型参数分成三个部分:
| 状态 | 作用 |
|---|---|
| Optimizer States | 优化器在进行梯度更新的时候需要用到的数据 |
| Gradient | 在反向转播过程中产生的数据,其决定参数的更新方向 |
| Model Parameter | 模型参数,在模型训练过程中通过数据“学习”的信息 |
Zero的级别如下:
| 级别 | 作用 |
|---|---|
| Zero-0 | 不使用所有类型的分片,仅使用DeepSpeed作为DDP |
| Zero-1 | 分割Optimizer States, 减少4倍内存,通信容量和数据并行性相同 |
| Zero-2 | 分割Optimizer States和Gradients,减少8倍内存,通信容量和数据并行性相同 |
| Zero-3 | 分割Optimizer States、gradients、Parametes,内存减少与数据并行度呈线性关系。例如,在64个GPU(Nd=64)之间进行拆分将产生64倍的内存缩减。通信量有50%的适度增长 |
| Zero-Infinity | Zero-Infinity是Zero-3的扩展,它允许通过使用 NVMe 固态硬盘扩展 GPU 和 CPU 内存来训练大型模型 |
2.4 Zero-Offload:
相比GPU,CPU就相对比较廉价,所以Zero-Offload思想是将训练阶段的某些模型状态放(offload)到内存以及CPU计算。
Zero-Offload不希望为了最小化显存占用而让系统计算效率下降,但如果使用CPU也需要考虑通信和计算的问题(通信:GPU和CPU的通信;计算:CPU占用过多计算就会导致效率降低)。
Zero-Offload想做的是把计算节点和数据节点分布在GPU和CPU上,计算节点落到哪个设备上,哪个设备就执行计算,数据节点落到哪个设备上,哪个设备就负责存储。
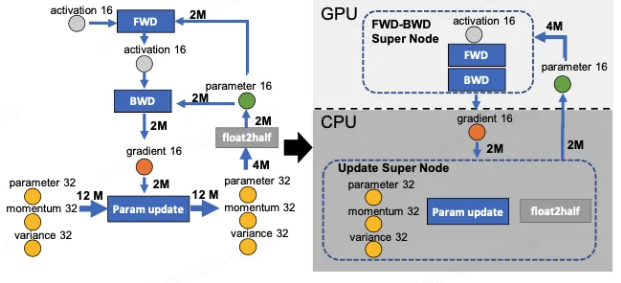
Zero-Offload切分思路:
下图中有四个计算类节点:FWD、BWD、Param update和float2half,前两个计算复杂度大致是 O(MB), B是batch size,后两个计算复杂度是 O(M)。为了不降低计算效率,将前两个节点放在GPU,后两个节点不但计算量小还需要和Adam状态打交道,所以放在CPU上,Adam状态自然也放在内存中,为了简化数据图,将前两个节点融合成一个节点FWD-BWD Super Node,将后两个节点融合成一个节点Update Super Node。如下图右边所示,沿着gradient 16和parameter 16两条边切分。
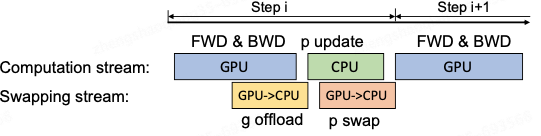
Zero-Offload计算思路:
在GPU上面进行前向和后向计算,将梯度传给CPU,进行参数更新,再将更新后的参数传给GPU。为了提高效率,可以将计算和通信并行起来,GPU在反向传播阶段,可以待梯度值填满bucket后,一遍计算新的梯度一遍将bucket传输给CPU,当反向传播结束,CPU基本上已经有最新的梯度值了,同样的,CPU在参数更新时也同步将已经计算好的参数传给GPU,如下图所示。
2.5 混合精度:
混合精度训练是指在训练过程中同时使用FP16(半精度浮点数)和FP32(单精度浮点数)两种精度的技术。使用FP16可以大大减少内存占用,从而可以训练更大规模的模型。但是,由于FP16的精度较低,训练过程中可能会出现梯度消失和模型坍塌等问题。
DeepSpeed支持混合精度的训练,可以在config.json配置文件中设置来启动混合精度(“fp16.enabled”:true)。在训练的过程中,DeepSpeed会自动将一部分操作转化为FP16格式,并根据需要动态调整精度缩放因子,来保证训练的稳定性和精度。
在使用混合精度训练时,需要注意一些问题,例如梯度裁剪(Gradient Clipping)和学习率调整(Learning Rate Schedule)等。梯度裁剪可以防止梯度爆炸,学习率调整可以帮助模型更好地收敛。
三、总结
DeepSpeed方便了我们在机器有限的情况下来训练、微调大模型,同时它也有很多优秀的性能来使用,后期可以继续挖掘。
目前主流的达模型训练方式: GPU + PyTorch + Megatron-LM + DeepSpeed
优势
- 存储效率:DeepSpeed提供了一种Zero的新型解决方案来减少训练显存的占用,它与传统的数据并行不同,它将模型状态和梯度进行分区来节省大量的显存;
- 可扩展性:DeepSpeed支持高效的数据并行、模型并行、pipeline并行以及它们的组合,这里也称3D并行;
- 易用性: 在训练阶段,只需要修改几行代码就可以使pytorch模型使用DeepSpeed和Zero。
参考:
1. http://wed.xjx100.cn/news/204072.html?action=onClick
2. https://zhuanlan.zhihu.com/p/513571706
作者:京东物流 郑少强
来源:京东云开发者社区 转载请注明来源
相关文章:
DeepSpeed: 大模型训练框架 | 京东云技术团队
背景: 目前,大模型的发展已经非常火热,关于大模型的训练、微调也是各个公司重点关注方向。但是大模型训练的痛点是模型参数过大,动辄上百亿,如果单靠单个GPU来完成训练基本不可能。所以需要多卡或者分布式训练来完成这…...

暄桐推荐|学书法的必读书目
在暄桐教室,写字之外,读书、静坐也是桐学们修习的功课。今天,便向你推荐,关于学习书法,暄桐教室的那些必读书目: 暄桐推荐学书法必读书之初阶书目: 对零基础的小白同学或刚入门…...

2023年赋能更多的人
最近接触到一些新人,是真正的网络新人,慢慢理解了新人的困惑。 对于新人,每天获取的信息五花八门,这是好的也是极其不好的。因为他们不知道如何筛选,到底适不适合自己去做。 我一直在劝大家去做一些内容创造性的事情…...
量子计算与量子密码(入门级)
量子计算与量子密码 写在最前面一些可能带来的有趣的知识和潜在的收获 1、Introduction导言四个特性不确定性(自由意志论)Indeterminism不确定性Uncertainty叠加原理(线性)superposition (linearity)纠缠entanglement 虚数的常见基本运算欧拉公式&#x…...
将安全作为首要目标 — Venus 的现状和前景展望
DeFi 的全面爆发将上一轮牛市推向巅峰。在不断的演化中,DeFi 领域也产生了很多新兴的细分领域,比如收益聚合器、合成资产、各种 DeFi 收益工具,以及最近整个市场都在讨论的 RWA 等。 DeFi 在不断进化,不变的是,DEX 和借…...

『第七章』翩翩起舞的雨燕:顺序与并发执行
在本篇博文中,您将学到如下内容: 1. 顺序执行2. 主线程 Main Thread 的秘密3. 并发执行:GCD 与分发队列(DispatchQueue)4. 延时执行5. 数据竞争(Data Race)6. 线程间的同步7. 避免线程爆炸8. RunLoop 与定时器总结楚客自相送,沾裳春水边。 晚来风信好,并发上江船。 花映…...

c语言进制的转换10进制转换16进制
c语言进制的转换10进制转换16进制 c语言的进制的转换 c语言进制的转换10进制转换16进制一、16进制的介绍二、10进制转换16进制的方法 一、16进制的介绍 十六进制: 十六进制逢十六进一,所有的数组是0到9和A到F组成,其中A代表10,B代…...
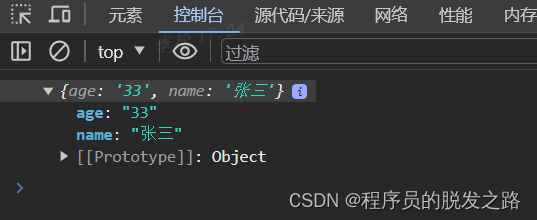
js中的Formdata数据结构
这里写目录标题 一、基本概念二、常用方法1.append(name, value)、set(name, value)2.get()、getAll()3.has(name)4.delete(name)5.keys(),values(),entries() 三、其他细节1.for of遍历2.转为对象3.结合 URLSearchParams 转为queryString 一、基本概念 FormData 提供了一种表…...
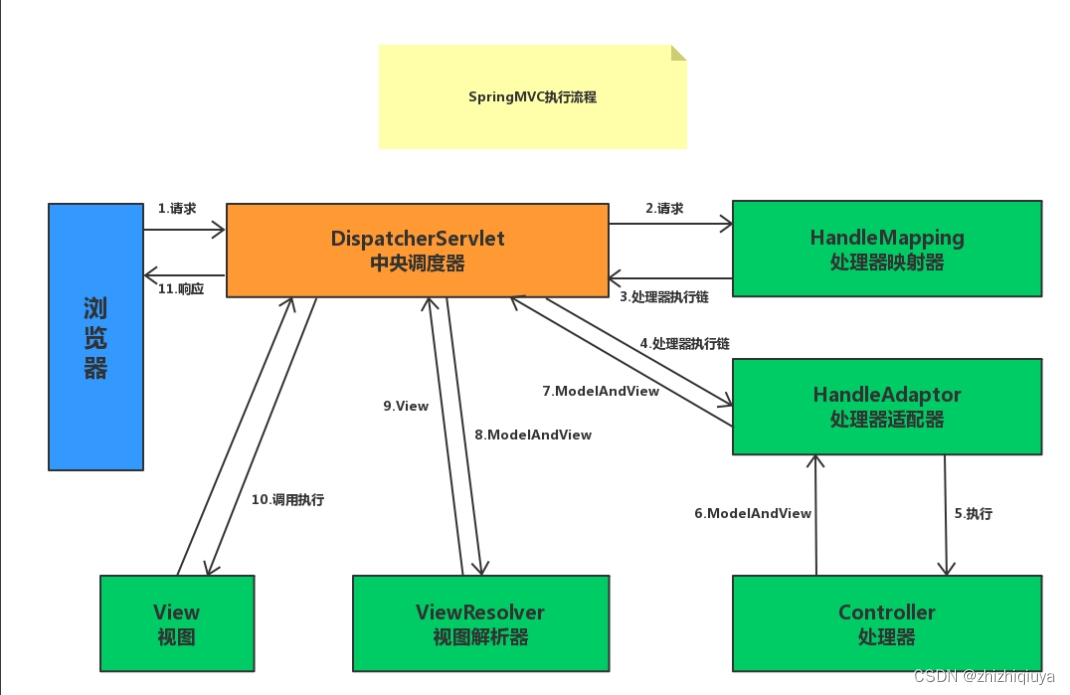
Spring MVC 执行流程
前言 Spring MVC 是一个非常强大的框架,它能够帮助开发人员快速构建高效的 Web 应用程序。然而,要理解 Spring MVC 的执行流程并不容易,因为它涉及到多个组件和模块。在本文中,我们将介绍 Spring MVC 的执行流程,帮助…...

JAVA毕业设计104—基于Java+Springboot+Vue的医院预约挂号小程序(源码+数据库)
基于JavaSpringbootVue的医院预约挂号小程序(源码数据库)104 一、系统介绍 本系统前后端分离带小程序 小程序(用户端),后台管理系统(管理员,医生) 小程序: 预约挂号,就诊充值&…...

一文了解独立站黑科技:clock斗篷技术
FP产品作为高利润高回报的产品,它热度在出海商品中是一直居高不下的。但这类产品在独立站的运营中往往会遇到很多问题,例如最让商家头疼的投流问题,FP产品的推广营销很容易遭到平台的管控封禁,这时候往往会用到市面上现在很火的黑…...
Java IDEA controller导出CSV,excel
Java IDEA controller导出CSV,excel 导出excel/csv,亲测可共用一个方法,代码逻辑里判断设置不同的表头及contentType;导出excel导出csv 优化:有数据时才可以导出参考 导出excel/csv,亲测可共用一个方法&…...

FFmpeg编译安装(windows环境)以及在vs2022中调用
文章目录 下载源码环境准备下载msys换源下载依赖源码位置 开始编译编译x264编译ffmpeg 在VS2022写cpp调用ffmpeg 下载源码 直接在官网下载压缩包 这个应该是目前(2023/10/24)最新的一个版本。下载之后是这个样子: 我打算添加外部依赖x264&a…...

gRPC之gateway集成swagger
1、gateway集成swagger 1、为了简化实战过程,gRPC-Gateway暴露的服务并未使用https,而是http,但是swagger-ui提供的调用服 务却是https的,因此要在proto文件中指定swagger以http调用服务,指定的时候会用到文件 prot…...

Pytorch从零开始实战07
Pytorch从零开始实战——咖啡豆识别 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——咖啡豆识别环境准备数据集模型选择训练模型可视化模型预测其他问题总结 环境准备 本文基于Jupyter notebook,使用Python3.8,Pytor…...

大数据知识扫盲
MapReudece作业启动和运行机制 MapReduce是一种分布式计算框架,最初由Google开发,用于处理大规模数据集的批处理任务。其核心思想是将数据划分为小的块,然后并行处理这些块,最后将结果合并。以下是MapReduce作业的启动和运行机制…...

使用Ubuntu虚拟机离线部署RKE2高可用集群
环境说明 宿主机和虚拟机的OS与内核相同,如下 $ cat /etc/issue Ubuntu 22.04.3 LTS \n \l$ uname -sr Linux 6.2.0-34-generic虚拟化软件版本 $ kvm --version QEMU emulator version 6.2.0 (Debian 1:6.2dfsg-2ubuntu6.14) Copyright (c) 2003-2021 Fabrice Be…...
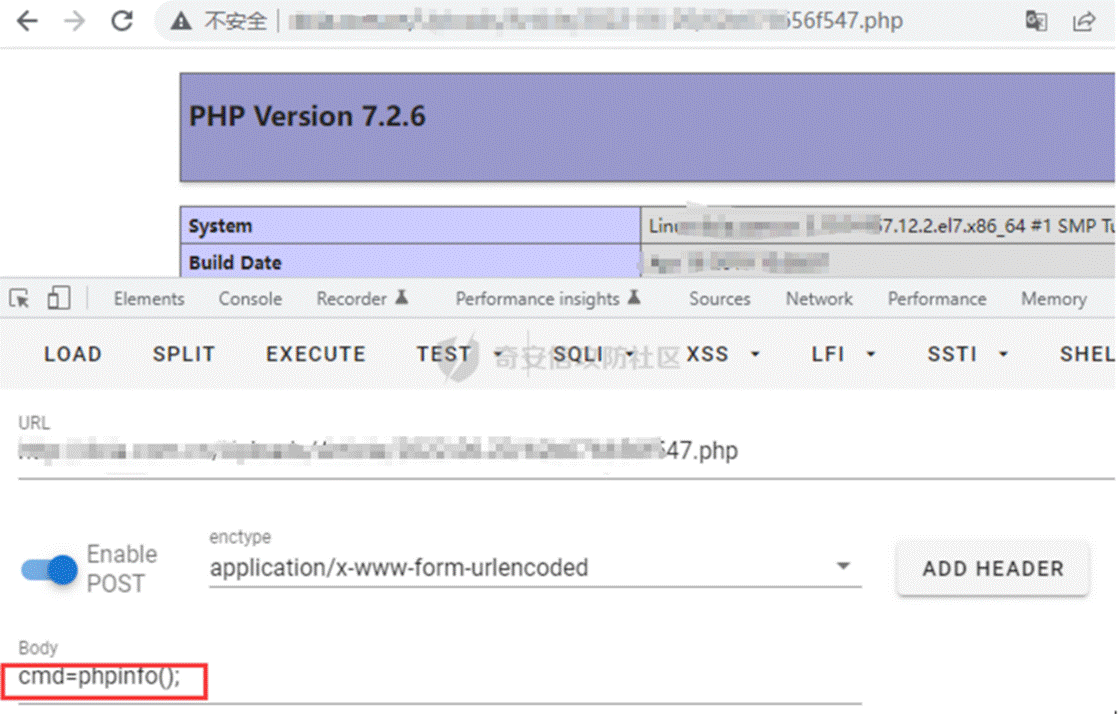
记一次任意文件下载到Getshell
任意文件下载(Arbitrary File Download)是一种常见的 Web 攻击技术,用于窃取服务器上任意文件的内容。攻击者利用应用程序中的漏洞,通过构造恶意请求,使应用程序将任意文件(如配置文件、敏感数据等…...
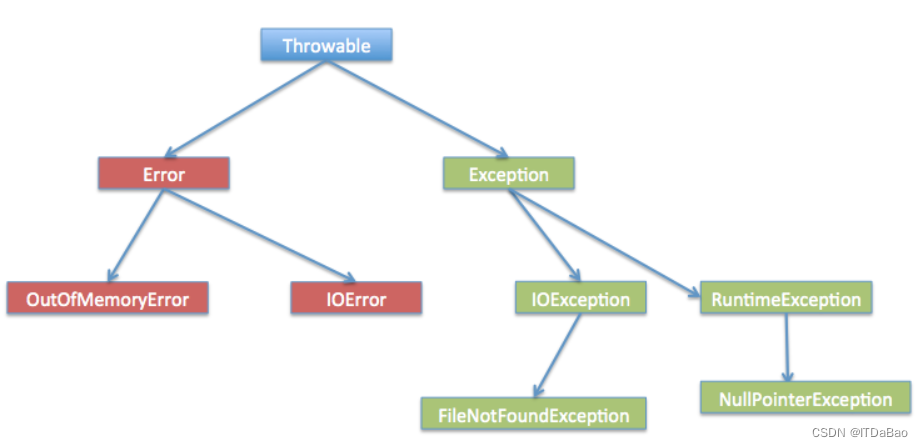
java异常处理
异常处理分为三类: 检查性异常 用户错误或问题引起的异常,这是程序员无法预见的。例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略。 运行时异常 运行时异常是可能被程序员避免的异常…...

递归为什么这么难?一篇文章带你了解递归
递归为什么这么难?一篇文章带你了解递归 美国计算机科学家——彼得多伊奇(L Peter Deutsch)在《程序员修炼之道》(The Pragmatic Programmer)一书中提到“To Iterate is Human, to Recurse, Divine”——我理解的这句话为:人理解迭代,神理解…...

Arm Neoverse CMN-700互连架构与协议寄存器配置指南
1. Arm Neoverse CMN-700一致性互连架构解析在现代多核处理器设计中,一致性互连网络如同城市交通系统般重要。Arm Neoverse CMN-700作为第二代Coherent Mesh Network解决方案,其架构设计充分考虑了数据中心和边缘计算的严苛需求。与传统的总线或环形拓扑…...

ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准
ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准 当你把ADXL335加速度计接入Arduino,兴奋地跑起第一个测试程序时,那些跳动的数字可能很快会浇灭你的热情。原始读数像得了疟疾般颤抖,静止时本该稳定的1g重力加速…...

从零构建情感大语言模型:基于EmoLLM的实践指南
1. 项目概述:当大语言模型学会“察言观色”最近在折腾一个挺有意思的开源项目,叫SmartFlowAI/EmoLLM。光看名字你可能就猜到了,这玩意儿跟“情绪”和“大语言模型”有关。没错,它的核心目标就是让冷冰冰的LLM(Large La…...

符号链接批量管理工具 linko:声明式配置与自动化实践
1. 项目概述与核心价值最近在折腾一些自动化脚本和工具链,发现一个挺有意思的仓库:monsterxx03/linko。乍一看这个名字,你可能会有点懵,这到底是干嘛的?是链接管理工具,还是某种网络代理的客户端࿱…...

数据流编排与异步任务调度中间件kelivo部署与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫“Chevey339/kelivo”。乍一看这个标题,可能有点摸不着头脑,它不像那些直接告诉你“XX管理系统”或“XX工具库”的项目名那么直白。但恰恰是这种看似神秘的命名,背后往往隐藏…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...

【STC8H】GPIO模式深度解析:从准双向到推挽,如何精准控制外设
1. STC8H的GPIO模式全景解析 第一次接触STC8H的GPIO配置时,我被那个神秘的PxM0和PxM1寄存器搞得晕头转向。直到有一次调试I2C通讯失败,才发现是开漏模式配置错误。这次教训让我明白,理解GPIO的四种工作模式,就像掌握不同武器的使用…...

Arm Neoverse CMN-700多芯片架构与一致性哈希解析
1. Arm Neoverse CMN-700多芯片架构解析在现代高性能计算领域,多芯片系统架构已成为突破单芯片性能瓶颈的关键技术路径。Arm Neoverse CMN-700作为第二代一致性网状网络控制器,其设计哲学体现在三个维度:首先是通过模块化设计实现计算单元的可…...

OCT-X算法:早期胃癌AI检测的技术突破与应用
1. OCT-X算法:早期胃癌AI检测的技术突破在医疗影像分析领域,胃癌早期检测一直面临着巨大挑战。传统内窥镜检查依赖医生经验判断,存在主观性强、漏诊率高等问题。我们团队开发的OCT-X(One Class Twin Cross Learning)算…...

AI原生代码库OpenCode:从代码生成到项目级协同的开发新范式
1. 项目概述:一个面向开发者的AI原生代码库最近在GitHub上看到一个挺有意思的项目,叫opencode-ai/opencode。光看名字,你可能会觉得这又是一个“AI写代码”的工具,或者是一个AI模型的代码仓库。但如果你点进去仔细研究一下&#x…...