零资源的大语言模型幻觉预防
零资源的大语言模型幻觉预防
- 摘要
- 1 引言
- 2 相关工作
- 2.1 幻觉检测和纠正方法
- 2.2 幻觉检测数据集
- 3 方法论
- 3.1 概念提取
- 3.2 概念猜测
- 3.2.1 概念解释
- 3.2.2 概念推理
- 3.3 聚合
- 3.3.1 概念频率分数
- 3.3.2 加权聚合
- 4 实验
- 5 总结

摘要
大语言模型(LLMs)在各个领域的广泛应用引起了人们对“幻觉”问题的关注,即LLMs生成事实不准确或无依据的信息。现有的语言助手中的幻觉检测技术依赖于复杂的不确定性、特定的自由语言思维链(CoT)技术或 基于参数的方法,存在解释性问题。此外,针对生成后识别幻觉的方法无法防止其发生,并且由于指令格式和模型风格的影响,性能不一致。本文介绍了一种新颖的 预检测自我评估技术 ,称为SELF-FAMILIARITY,重点评估模型对输入指令中存在的概念的熟悉程度,并在遇到不熟悉的概念时不生成响应。这种方法模拟了人类在面对不熟悉的话题时避免回应的能力,从而减少幻觉。
基于参数的方法是指在幻觉检测中使用参数化模型或算法的技术。这些方法通常会将语言助手的行为、输出或其他相关特征表示为参数,并使用这些参数来进行幻觉检测。
预检测的自我评估技术是指在自然语言处理任务中,通过对模型输出进行评估和分析来评估模型性能的技术。模型生成翻译结果后,并不立即输出给用户或系统。相反,生成的结果会经过一系列评估步骤来估计其质量和准确性。
在四个不同的大语言模型上验证了SELF-FAMILIARITY,并表现出与现有技术相比始终优越的性能。研究结果为LLM助手中的幻觉缓解提供了重要的先发性策略转变,有望提高可靠性、适用性和解释性。
1 引言
大语言模型(LLMs)的广泛应用引发了人们对其在各种用例中的应用的兴趣,例如医疗和药学。然而,阻碍它们充分发挥潜力的一个主要挑战是幻觉问题,即模型产生不准确或编造的信息,导致其可靠性和可信度存在重大差距。图6展示了一个示例,演示了当用户向ChatGPT查询有关治疗由内源性生长激素分泌不足引起的矮小症的药物“Skytrofa”时,幻觉问题的存在。可以观察到ChatGPT在这种药物的关键因素上生成了不准确的回答。

最近,已提出了几种方法来检测(甚至纠正)LLMs在开放对话中生成的幻觉回答,这些方法可以大致分为两类:
- 第一类方法依赖第三方知识库,结合思维链(CoT)技术,识别和纠正潜在的幻觉回答。
- 另一个研究方向侧重于设计基于参数的方法,主要利用困惑度等特定指标评估回答的正确性。
在这种方法中,模型会根据输入的问题或任务,生成一个回答。然后,通过计算回答的困惑度或其他特定指标来评估回答的正确性。困惑度是一种衡量语言模型预测能力和不确定性的指标,它表示模型在选择正确答案时的困惑程度,即模型对不同答案的选择难度。
通过使用困惑度等特定指标,可以量化回答的质量和准确性。较低的困惑度通常表示回答更准确和可靠。这些指标可以用于评估模型在特定任务或数据集上的表现,并进行模型选择、调优或比较。
所有上述方法主要集中在 幻觉回应的后检测 上。这些方法只能确定回答是否为幻觉,无法阻止未来产生此类回答,从而降低可靠性。此外,现有方法的性能深受指令和模型风格的影响,在维持开放对话场景的鲁棒性方面存在挑战。这种复杂性使得很难建立一个明确的阈值来区分幻觉回答。例如,二进制查询通常会导致简短的响应序列,使得与更长的响应序列导出的指标相比,指标差异显著。因此,对于人工智能(AI)语言助手的实际和高效应用,一种积极的、预防性的幻觉回答策略是必不可少的。
“Post-detection of hallucination responses”(幻觉回应的后检测)是指在生成型模型或对话系统中,对于生成的回答或响应进行后续的幻觉检测。为了解决幻觉回应的问题,可以采用后检测的方法。后检测是指在生成结果之后,对其进行进一步的分析和评估,以确定其中是否存在幻觉回应。
设计这样一种有效的预防方法面临着几个挑战。
- 首先,所提出的方法必须在零资源的环境中进行导航,不能依赖于从搜索引擎中获取的外部知识。忽视这一要求会损害方法的通用性和适用性,使其不适用于预算有限或无法访问外部环境的情况。因此,深入了解语言模型的内在知识变得至关重要。
- 此外,确保鲁棒性的任务非常重要。设想的系统必须对不同类型的指令、上下文变化和模型风格表现出韧性。鉴于人类语言的开放性和动态性质,要在各种场景中实现一致的性能和坚定的韧性,面临着无疑的巨大挑战。
为了同时应对这些挑战,本文提出了一种新颖的零资源预检测方法,称为SELF-FAMILIARITY,如图2所示。该方法通过避免讨论模型不熟悉的概念来模拟人类的自我评估能力,从而减少产生幻觉信息的风险。这种方法使其与传统的后检测技术有所区别。
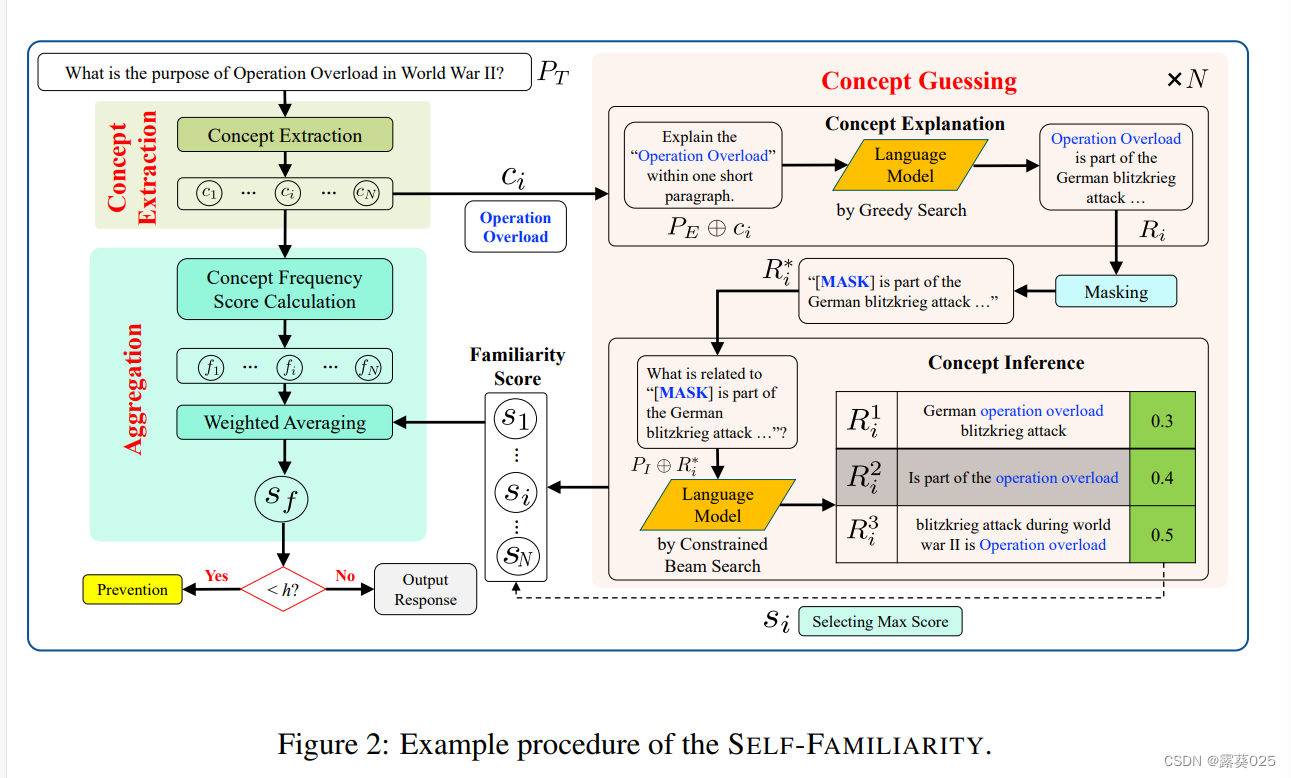
首先,本方法在概念提取阶段从指令中提取和处理概念实体。
然后,在概念猜测阶段,通过提示工程分别检查提取的概念,以获得每个概念的熟悉程度分数。
最后,在聚合阶段,将不同概念的熟悉程度分数组合起来生成最终的指令级熟悉程度分数。
与现有方法相比,本文的算法具有以下优点。
- 首先,SELF-FAMILIARITY集成了思维链技术和基于参数的方法的优势。与思维链方法类似,本文的算法可以通过识别模型不熟悉的概念提供有建设性的回答。然而,本文的算法仅使用提示工程,不需要模型具备强大的推理能力,并避免了它们的缺点,同时结合了它们的优点。
- 此外,本文的算法不受指令风格和类型的影响,具有积极性和预防性,从而提高了其可靠性和鲁棒性。
- 最后,它不需要任何外部知识。
使用一种新提出的预检测幻觉指令分类数据集Concept-7,在四个大语言模型上评估了我们的方法。实验结果表明,所提出的SELF-FAMILIARITY方法在所有模型上始终优于其他方法,显示出其巨大的应用价值。
2 相关工作
目前,没有现有的工作专注于在零资源环境下通过分析指令本身来防止开放对话中的幻觉回答。因此,所讨论的上下文与先前研究的上下文有所不同。
2.1 幻觉检测和纠正方法
以前的幻觉检测和纠正研究主要集中在特定任务的条件文本生成上,例如摘要概括、图像字幕、对话生成、机器翻译和表格到文本生成。由于这些工作非常特定于任务,它们无法解决开放对话中的幻觉问题。
对于开放对话设置,根据采用的策略,方法通常分为两组。
-
第一类利用思维链(CoT)或提示编程来评估和修正回答。一个值得注意的例子是CRITIC,其中使用思维链过程,并从外部搜索引擎获得补充输入,以提高响应质量。某些方法不需要外部知识,通常直接要求模型评估输出的准确性。然而,这些方法在特定回答方面有一定的局限性,并且在很大程度上依赖于模型的内在推理能力。另一个挑战在于算法输出通常是自由文本,这可能使得实际的分类阈值模糊不清。
-
第二类方法强调使用语言模型参数(例如token概率序列)来确定幻觉程度。这些方法通常具有出色的泛化能力,并且可以提供精确的输出分数。Self-check GPT是使用基于参数的方法进行开放式文本生成的先驱。Self-check GPT使用困惑度、采样和无条件概率共同估计幻觉程度。然而,该工作仅评估与传记相关的问题,并且与思维链技术相比,模型的可解释性显著降低。
2.2 幻觉检测数据集
目前在开放对话中的幻觉检测数据集主要集中在后检测情景中。在这些数据集中,任务涉及选择正确的回答或确定回答是否不正确。然而,这些数据集受到一定限制。首先,这些数据集通常源自单个任务,如传记撰写,没有考虑不同语言模型之间的差异。每个模型可能具有不同的背景知识,使得一个模型可以识别另一个模型可能忽略的幻觉回答。此外,即使模型能够准确地对特定的幻觉回答进行分类,也不能保证模型将在将来避免生成不同的幻觉回答。因此,重要的是创建一个新的数据集,用于验证预检测设置。
3 方法论
本算法的目标是通过检查语言模型对指令 P T P_T PT中存在的概念的熟悉程度,评估目标指令 P T P_T PT是否是潜在的幻觉指令,这在零资源环境下进行。方法如图2所示,包括三个主要步骤:
(1)概念提取,
(2)概念猜测,
(3)聚合。
每个步骤的详细信息将在下面的章节中阐述。
3.1 概念提取
为了评估熟悉程度,首先需要从自由文本指令中提取概念实体,否则评分将受到指令中的“噪音”的很大影响,即指令的风格和格式化元素,这些元素对其理解没有贡献。例如,将问题“声音能在真空中传播吗?”转化为陈述句“声音能在真空中传播。请判断该陈述的真实性。”不会改变所需的知识,但会大幅修改后续回答的风格。此外,如果指令中包含多个概念,将会极大增加后续提示工程的难度。通过独立评估这些概念,可以减少这种风格影响,从而增强后续程序的鲁棒性。通过使用命名实体识别(NER)模型对给定指令进行概念提取来实现这一点:

这些提取的实体 [c1, · · · , cN ] 是指令的关键概念。N代表提取的概念数。然而,NER模型经常产生额外的噪音并且无法完全捕捉到一些概念。因此,引入后续的处理步骤来改进这些提取的概念,如下所述。
概念分组 提取的概念经常具有一定的不完整性。例如,“2023年美国债务上限危机”这个术语可能被无意地分割成[“2023年”, “美国”, “债务上限危机”]。为了解决这个问题,提出按照它们在 P T ( 语言模型对指令 ) P_T(语言模型对指令) PT(语言模型对指令)中的位置 对概念进行排序,并尝试将一个概念与相邻的概念合并,如果新合并的概念在原始 P T P_T PT中找到,就将合并的概念对合并为一个扩展的、统一的概念。
概念过滤 在合并概念之后,下一步是排除不需要检查的简单概念,以提高效率。这些包括常见的概念,如“年份”和“年龄”,通常被模型很好地理解。为了解决这个问题,识别Wiktionary4中使用频率最高的单词,并将其指定为“常见概念”。任何包含在这些常见词汇中的概念都将被排除。
3.2 概念猜测
下一个任务是在零资源环境中检查语言模型对提取的概念的熟悉程度。在零资源环境中进行这项任务会增加其复杂性,因为它不能依赖外部概念知识。因此,将模型的理解能力与已建立的金标准定义进行比较以得出结果的方法变得不可行。同时,引入了一种新颖的自我评估技术,称为概念猜测。本方法开始时,提示模型为给定的概念生成一个解释。随后,通过提示工程,要求模型基于这个解释重新创建原始概念。如果模型成功生成了初始概念,响应序列的概率分数可以解释为概念与解释之间的连接强度,作为熟悉度分数。整个过程可以类比为专门的Charades或Pictionary游戏。如果语言模型能够从生成的解释中熟练地推导出原始概念,这不仅表明解释的充分性,也反映了模型对概念的熟练程度。重要的是,这一方法不需要获得概念的金标准定义。概述以下步骤,将这个概念方法转化为一个标准化的度量方式:
3.2.1 概念解释
在概念解释步骤中,使用标准的解释提示( P E P_E PE)和目标概念( c i c_i ci)来查询语言模型(LM)。这个查询促使语言模型通过贪婪搜索(Greedy Search)为每个概念生成解释。贪婪搜索选择下一个具有最高概率的单词来生成响应。这个过程会一直持续,直到遇到句子的结束标记,或达到预定义的最大长度(记为 l F l_F lF):
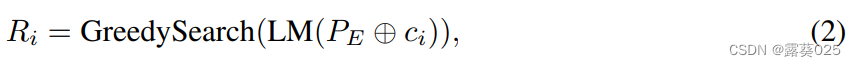
其中,⊕表示将 c i c_i ci插入到 P E P_E PE的预定义位置。在许多情况下,原始概念可能直接并入生成的解释中,如图2所示。因此,模型可以简单地“复制”原始概念以“作弊”。为了防止这种情况发生,在 R i R_i Ri中对 c i c_i ci的单词进行屏蔽处理:

3.2.2 概念推理
给定屏蔽的解释 R i ∗ R^∗_i Ri∗和由 P I P_I PI表示的概念推理提示,可以要求模型生成原始概念 c i c_i ci。然而,模型的响应是以开放式的自由文本形式生成的,这在尝试将其转化为标准分数时会带来挑战。考虑这样一个情况,模型可能以“可口可乐的最大竞争对手”而不是“百事可乐”的形式正确生成原始概念。这种差异使得确定原始概念是否成功重现变得复杂。为了解决这个问题,采用了**约束束搜索(ConsBeamSearch)**的方法,指导模型通过束搜索寻找包含原始概念的响应,并同时提供响应的概率分数:
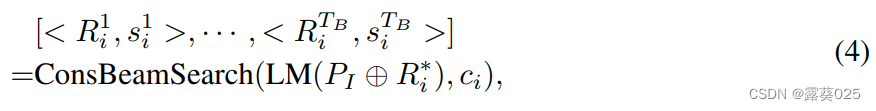
其中,每个 < R i j , s i j R^j_i, s^j_i Rij,sij> 对应于包含概念实体 c i c_i ci的响应 R i j R^j_i Rij,其中 s i j s^j_i sij表示相应的响应概率分数。 T B T_B TB是ConsBeamSearch算法的束搜索大小。将停止准则设置为达到句子结束标记或达到最大长度 l B l_B lB。束搜索将返回多个结果,但是模型的理解仅与最高分相关。因此,从[ s i 1 , ⋅ ⋅ ⋅ , s i T B s^1_i, · · · , s^{T_B}_i si1,⋅⋅⋅,siTB]中选择最高的响应分数 s i s_i si作为概念 c i c_i ci的熟悉度分数。

约束束搜索(ConsBeamSearch)是一种搜索算法,用于在生成式模型中进行序列生成任务,如机器翻译或文本生成。与贪婪搜索(Greedy Search)只选择每个步骤上最可能的单词不同,束搜索考虑了多个备选单词,并根据概率进行排序。
束搜索使用一个参数称为束宽(beam width),该参数指定在每个时间步中要保留的备选单词数量。在每个时间步,束搜索会根据预测的概率选择前K个可能性最高的备选单词(K为束宽),并保留这些备选路径。然后,针对每个备选路径,继续预测下一个单词,并再次选择最有可能的K个备选单词。
这个过程会一直持续,直到生成的序列达到预定的结束标记或达到最大长度。最终,束搜索会返回具有最高总体概率的生成序列作为最终的输出。

3.3 聚合
在许多情况下,最终提取的概念数量可能大于1。因此,需要对每个概念的重要性进行排名,并根据其重要性合并概念的熟悉度分数,以生成最终的指令级结果。
3.3.1 概念频率分数
为了评估概念的重要性,提出了一种基于概念中包含的单词频率排名计算分数的方法。期望具有更不常见单词的概念对应的分数 f i f_i fi较低。为此,从Wiktionary中获取概念 c i c_i ci的第 j j j个单词的频率排名 p i j p^j_i pij。如果单词不在词典中或者是大写的,则将索引设置为词典的长度。考虑到单词分布往往遵循长尾分布,使用指数函数将频率排名转换回频率分数,并将它们相乘得到概念级别的频率分数:

在这里, M i M_i Mi是概念 c i c_i ci中的单词数。术语 H H H被引入作为一个归一化因子,以确保结果分数在一个合理的范围内。
3.3.2 加权聚合
接下来,通过加权平均值基于频率分数对熟悉度分数进行平均。与仅选择单个分数作为最终值相比,这种方法在多实体情况下提供了稳健性。为了使重要部分比不重要的尾部部分更有贡献,我们建立了一个几何递减的加权方案,比率为1/r。

在这里,θ(fi)表示 f i f_i fi在按fi的大小排序的[ f 1 , ⋅ ⋅ ⋅ , f N f_1, · · · , f_N f1,⋅⋅⋅,fN]中的排名位置。使用得到的 s f s_f sf来表示指令的臆想程度,并在分数低于预定阈值h时终止响应过程。
4 实验
5 总结
相关文章:
零资源的大语言模型幻觉预防
零资源的大语言模型幻觉预防 摘要1 引言2 相关工作2.1 幻觉检测和纠正方法2.2 幻觉检测数据集 3 方法论3.1 概念提取3.2 概念猜测3.2.1 概念解释3.2.2 概念推理 3.3 聚合3.3.1 概念频率分数3.3.2 加权聚合 4 实验5 总结 摘要 大语言模型(LLMs)在各个领域…...

智能终端界面自动化测试操作工具 - Appium常见用法
1. Appium 是什么可以做什么? Appium 是一款开源的移动应用自动化测试框架,用于测试移动应用程序的功能和用户界面。它支持多种移动平台,包括 Android 和 iOS,可以使用多种编程语言进行脚本编写,如 Python、Java、Jav…...
结构体数组经典运用---选票系统
结构体的引入 1、概念:结构体和其他类型基础数据类型一样,例如int类型,char类型,float类型等。整型数,浮点型数,字符串是分散的数据表示,有时候我们需要用很多类型的数据来表示一个整体&#x…...

code too large
描述:比较尴尬,一个方法的代码接近10000行了,部署服务器的时候提示(java :code[255,21] too large),提示代码过长,无法运行。 查看了一下百度:解决的思路 JVM规范:「类或接口可以声明的字段数量限制在 655…...

vue中把弹出层.vue文件注册成组件供其他.vue文件调用的写法
背景:因弹出层多个页面的详情都是一样的,因此把弹出层定义成组件,多次调用 定义组件的过程中出现很多问题,因此再次记录最终成功的写法 一、 简单实现页面调用弹出层组件的打开弹出层方法: 1. 弹出层组件 (in…...
mac 查看GPU使用
首先搜索活动监视器 然后 点击窗口->gpu历史记录 记住不是立马出结果,而是 需要等半分钟左右的...
工业4.0的安全挑战与解决方案
在当今数字化时代,工业4.0已经成为制造业的核心趋势。工业4.0的兴起为生产企业带来了前所未有的效率和灵活性,但与之伴随而来的是一系列的安全挑战。本文将深入探讨工业4.0的安全挑战,并提供一些解决方案,以确保制造业的数字化转型…...
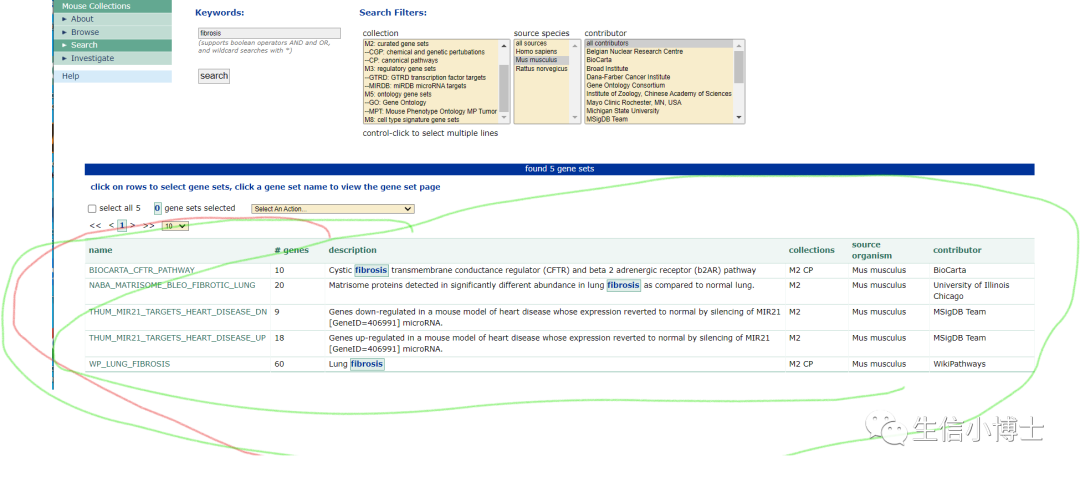
如何查找特定基因集合免疫基因集 炎症基因集
温故而知新,再次看下Msigdb数据库。它更新了很多内容。给我们提供了一个查询基因集的地方。 关注微信:生信小博士 比如纤维化基因集: 打开网址:https://www.gsea-msigdb.org/gsea/msigdb/index.jsp 2.点击search 3.比如我对纤维…...

轮转数组(Java)
大家好我是苏麟 , 这篇文章是凑数的 ... 轮转数组 描述 : 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 题目 : 牛客 NC110 旋转数组: 这里牛客给出了数组长度我们直接用就可以了 . LeetCode 189.轮转数组 : 189. 轮…...

Spring体系结构
Spring体系结构 核心容器 核心容器由 spring-core,spring-beans,spring-context,spring-context-support和spring-expression(SpEL,Spring 表达式语言,Spring Expression Language)等模块组成&…...

PostgreSQL basebackup备份和恢复
一、概述 备份和恢复分为逻辑和物理,这里指物理备份和恢复。 PG的物理备份依赖basebackup,这差不多就是数据目录的拷贝,还依赖归档日志。 恢复分为完全恢复和PITR恢复,它们都需要归档日志,它们关键的差别是…...

XTU-OJ 1248-Alice and Bob
Alice和Bob在玩骰子游戏,他们用三颗六面的骰子,游戏规则如下: 点数的优先级是1点最大,其次是6,5,4,3,2。三个骰子点数相同,称为"豹子",豹子之间按点数优先级比较大小。如果只有两个骰子点数相同&…...
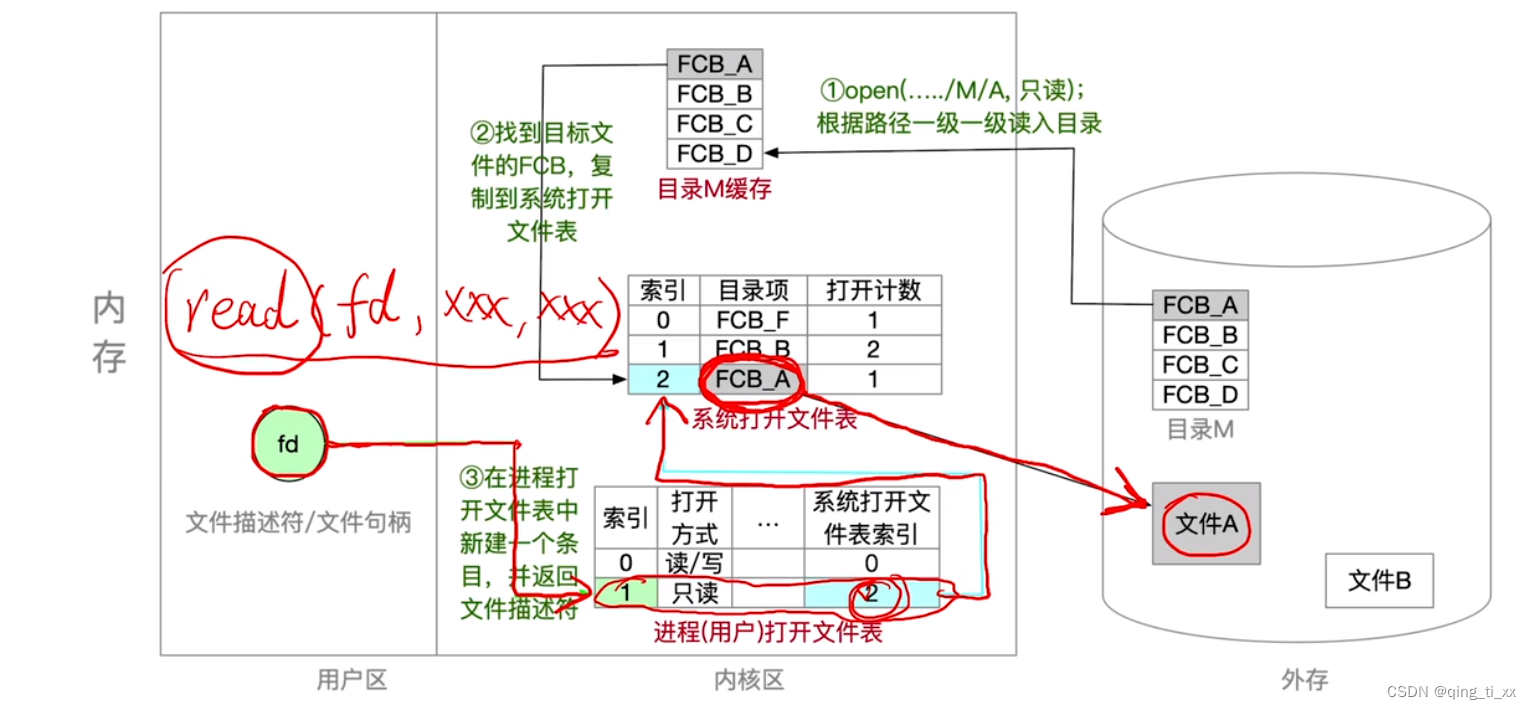
第四章 文件管理 十、文件系统的全局结构
目录 一、文件系统的建立 1、原始磁盘 2、物理格式化后 3、逻辑格式化后 二、文件系统在内存中的结构 三、系统调用背后的过程 一、文件系统的建立 1、原始磁盘 2、物理格式化后 物理格式化,即低级格式化――划分扇区,检测坏扇区,并用…...

【PythonGIS】基于高德Api实现批量地址查询经纬度
之前因为同事需要几千个小区的经纬度信息,所以就帮同事写了一段Python代码,通过调取高德地图的api实现地址查询经纬度这个功能。对于如何使用经纬度查询地址的方法,我之前分享过博文:【Python入门教程】获取图片可视化精准定位&am…...

vue数组中的变更方法和替换方法
变更方法: Vue 能够侦听响应式数组的变更方法,并在它们被调用时触发相关的更新。这些变更方法包括: push():在数组末尾添加一个或者多个元素,返回新的长度。 var arr [1, 2, 3, 4, 5]; // 定义一个数组 arr.push(6…...

Java - 工具类参数初始化
在做第三方接口调用时,经常需要根据不同的环境指定初始化的参数。以下做一个简单的记录。 一、使用static初始化 使用static初始化,仅会初始化一次,但无法从配置文件中获取参数。并且如果写了多个初始化工具类,会互相覆盖。 /**…...
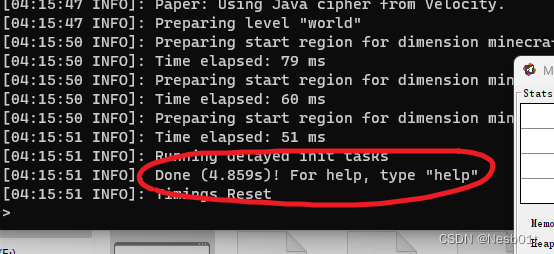
一文搞懂 MineCraft 服务器启动操作和常见问题 2023年10月
文章目录 前言1. 新建文件夹2. 创建 bat 文件3. 编辑 bat 文件4. 启动服务器5. 恭喜完成 文章持续更新中,如果你有问题可以通过 qq 1317699264 获取免费协助,解决的问题将会被更新到本文章中 前言 无论你是使用服务端整合包,还是从上一篇我的…...

第2篇 机器学习基础 —(2)分类和回归
前言:Hello大家好,我是小哥谈。机器学习中的分类和回归都是监督学习的问题。分类问题的目标是将输入数据分为不同的类别,而回归问题的目标是预测一个连续的数值。分类问题输出的是物体所属的类别,而回归问题输出的是数值。本节课就…...
Java游戏修炼手册:2023 最新学习线路图
前言 有没有一种令人兴奋的学习方法?当然有!绝对有!而且我要告诉你,学习的快乐可以媲美游戏的刺激。 小学时代,我曾深陷于一款名为"八百万勇士的梦"的游戏。每当放学,我总是迫不及待地打开电脑&a…...

前端访问geoserver服务发生跨域的解决办法,以及利用html2canvas下载绘制的地图
我的业务场景: 需要利用html2canvas下载Openlayers绘制的地图。 预期:可以下载成图片甚至其他格式(svg)文件。 结果:下载下来是个空白图片。 排查错误:请求数据正常回显到页面上,利用html2canvas截取的时候会发生跨域,导致无法绘制。 首先处理tomcat跨域问题 第一步…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

USB数据隔离器DIY:物理切断数据线,防范充电攻击
1. 移动设备充电安全:一个被忽视的“物理后门”你可能每天都在做这件事:手机或平板电脑电量告急,随手拿起一根数据线,插在办公室的公共电脑、机场的充电站,甚至是朋友提供的充电宝上。这看起来再平常不过了,…...

如何快速掌握ncmdumpGUI:Windows平台网易云音乐NCM文件转换完整教程
如何快速掌握ncmdumpGUI:Windows平台网易云音乐NCM文件转换完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

安卓逆向实战:Frida内存砸壳提取DEX原理与技巧
1. 这不是“脱壳”,是逆向工程中一次精准的内存手术你打开一个加固过的安卓App,用常规工具解包,发现classes.dex只有几KB,里面全是混淆到面目全非的壳代码;用dex2jar反编译,报错“Not a valid dex file”&a…...