yo!这里是进程间通信
目录
前言
进程间通信简介
目的
分类
匿名通道
介绍
举例(进程池)
命名管道
介绍
举例
共享内存
介绍
共享内存函数
1.shmget
2.shmat
3.shmdt
4.shmctl
举例
1.框架
2.通信逻辑
消息队列
信号量
同步与互斥
理解信号量
后记
前言
之前介绍到进程说过,进程具有独立性,也就是说两个进程之间没有相交的部分,没有共享的部分,那如何实现标题所说的通信呢?我们一定能先想到,一方将信息放到某个地方,然后另一方去拿,这不就实现了所谓的通信了,实际也是这样,进程间通信就是让两个或多个进程看到同一块资源(空间),对应的实现也是有很多种。其中,在本文我们详细介绍匿名管道、命名管道、共享内存,简单介绍消息队列、信号量,快往下看看吧!
进程间通信简介
-
目的
进程间通信的目的,包括数据传输、共享资源、通知、进程控制。其中,
数据传输:一个进程需要发送给另一个进程一些数据;
共享资源:多个进程之间共享同一份资源;
通知:一个进程需要通知另一个或多个进程发生了某个事件(如进程终止时要通知父进程);
进程控制:有些进程可以控制另一个进程的执行(如Debug进程),此时控制进程能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
-
分类
进程间通信的方法分类大致可以分为三类,包括管道、System V IPC(进程间通信InterProcess Communication)、POSIX IPC。
其中,
管道:
匿名管道
命名管道
System V IPC:
System V 消息队列
System V 共享内存
System V 信号量
POSIX IPC:
消息队列
共享内存
信号量
互斥量
条件变量
读写锁
对于System V IPC,侧重于本地通信,也就是一台机器上的多个进程进行通信;对于POSIX IPC,其将网络通信纳入到进程间通信,既能本地通信,又能远程通信。下面我们将详细介绍管道、System V 共享内存,简单介绍System V 消息队列、System V 信号量。
匿名通道
-
介绍
首先,我们把一个进程连接到两一个进程的一个数据流叫做管道,匿名管道就是之前所用的【 | 】,比如将当前路径信息输入到draft.txt文件中,如下图:
但这是指令实现的管道,代码如何实现呢?如下:
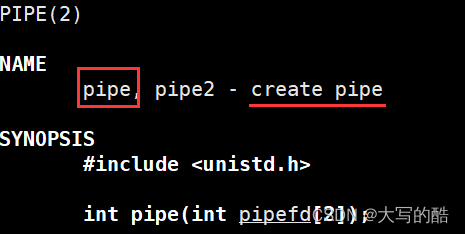
其中,pipefd是一个文件描述符数组,里面可以放两个文件描述符,pipefd[0]表示读端,pipefd[1]表示写端;返回值:成功返回0,否则返回-1,且设置errno。
注意:
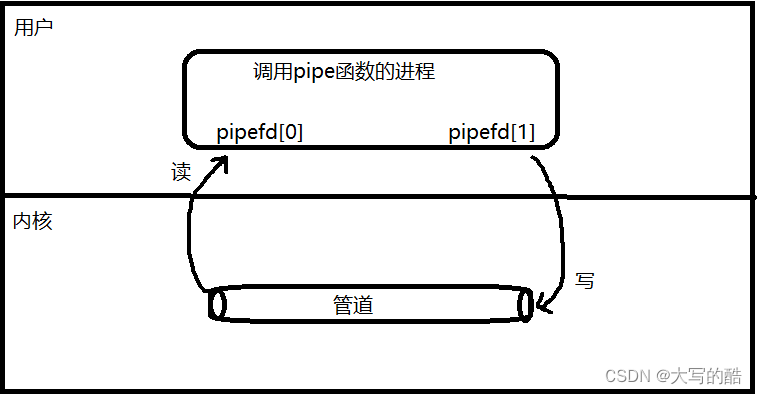
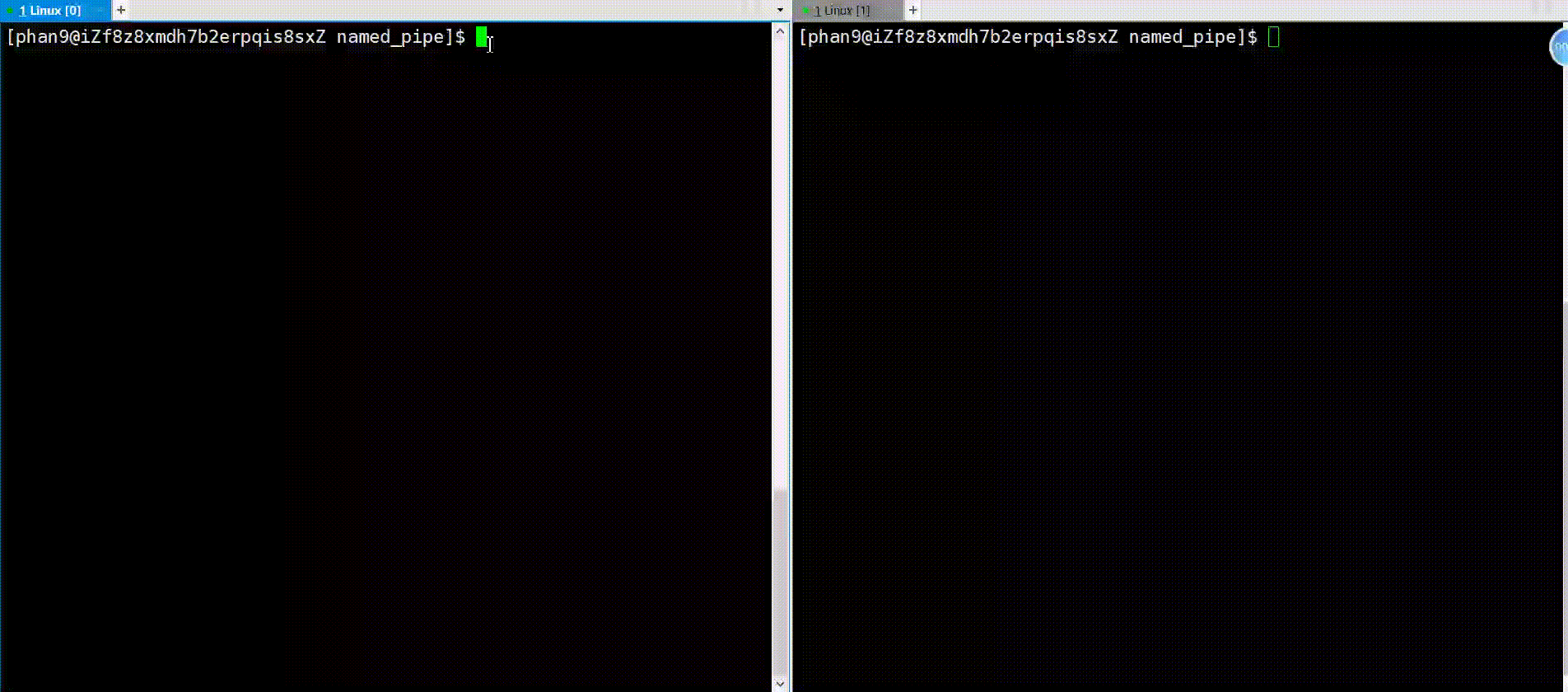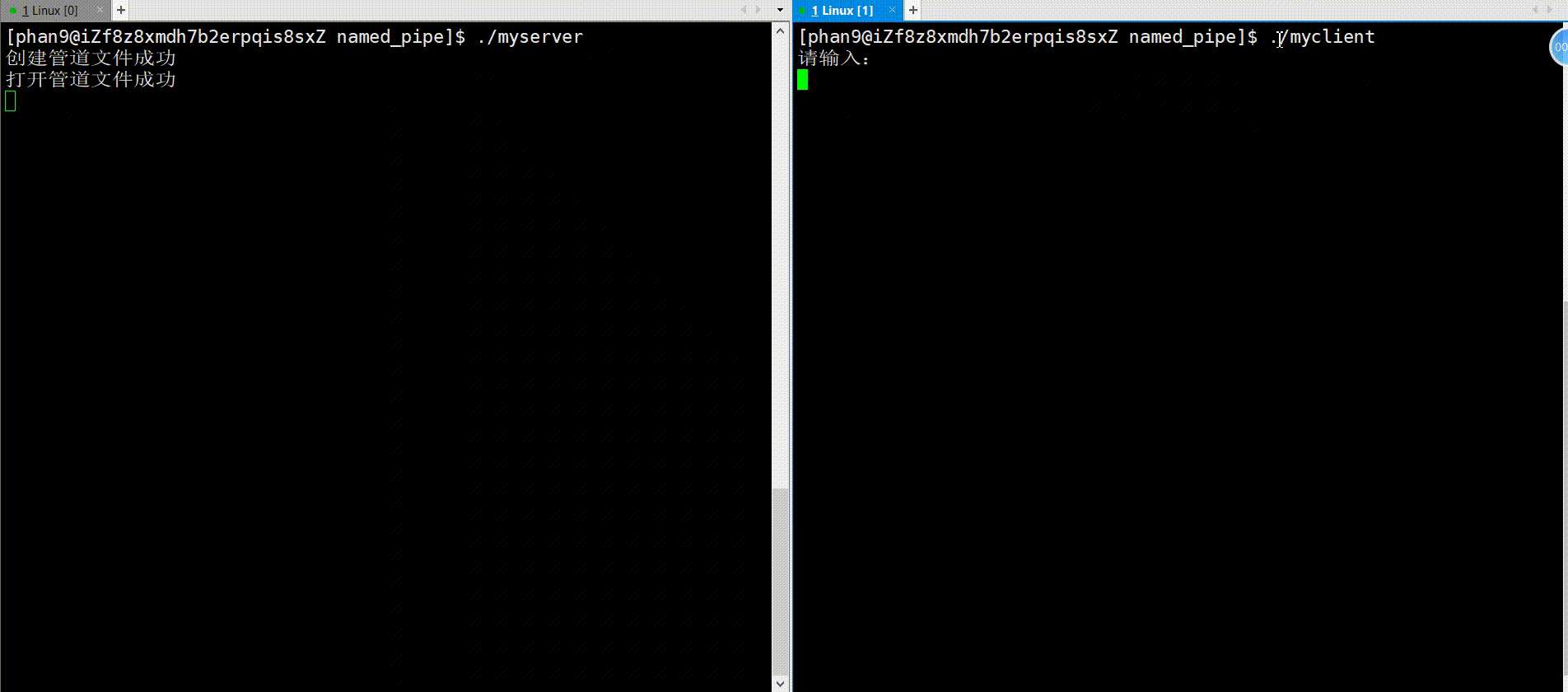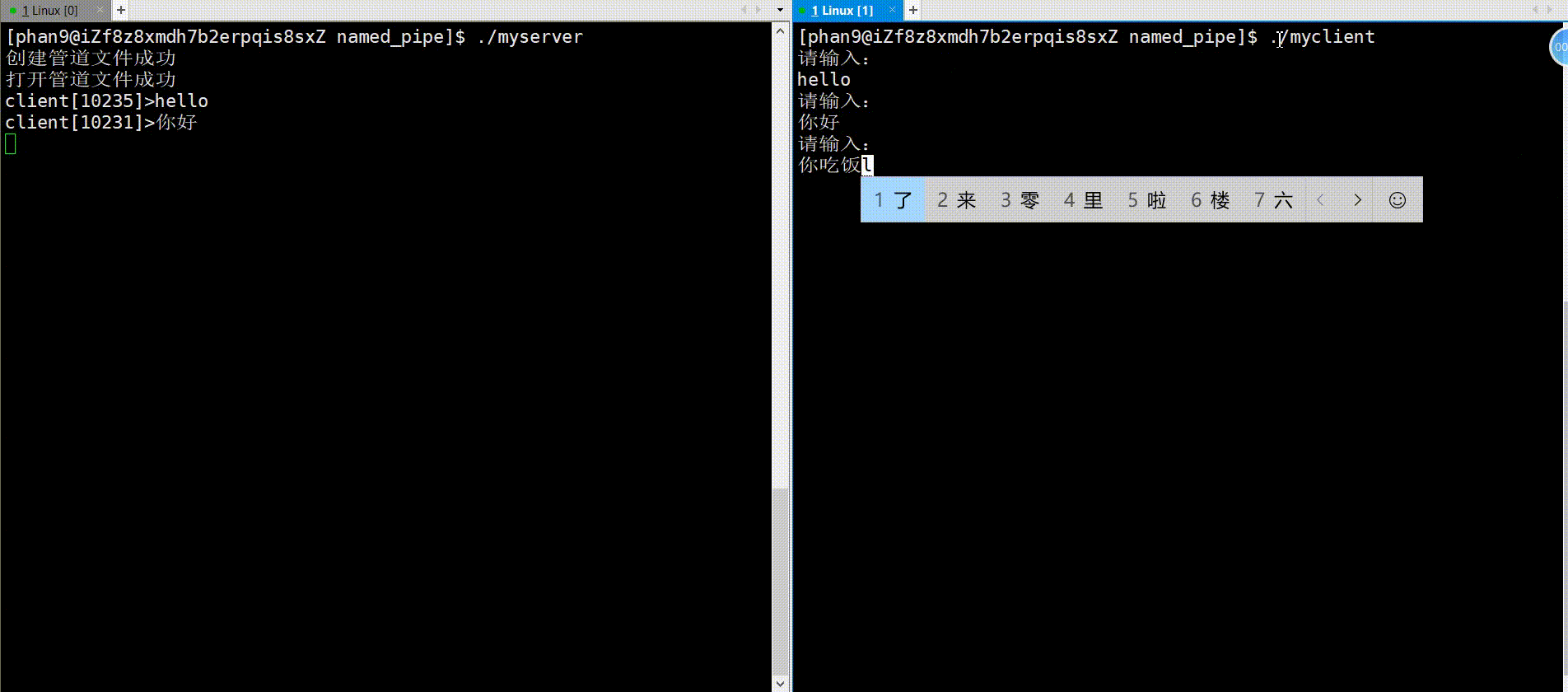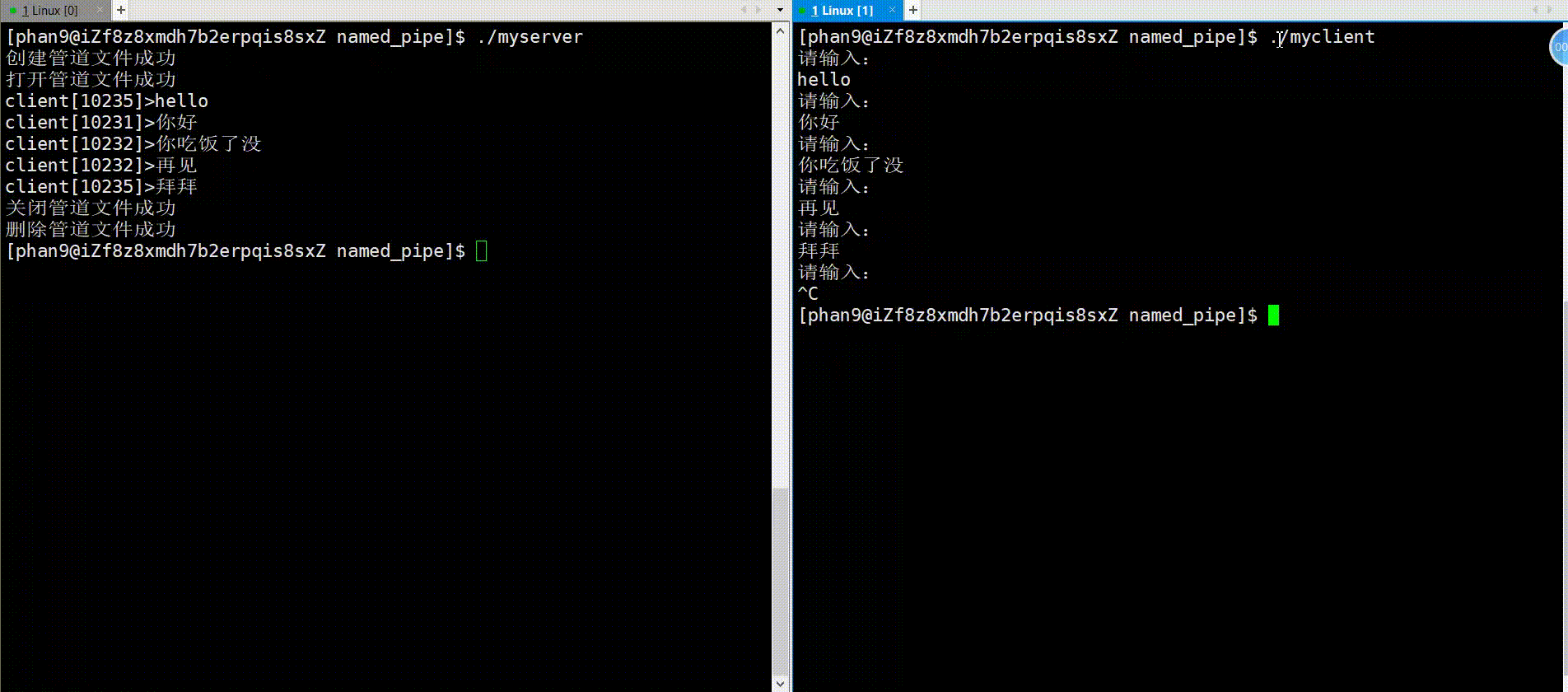
pipefd数组是一个输出型参数,我们传入一个空数组,函数内会将打开的读写fd对应放入数组内带出,函数外就可以通过pipefd[0]、pipefd[1]从写端向读端传输数据,如下图可方便理解:

-
举例(进程池)
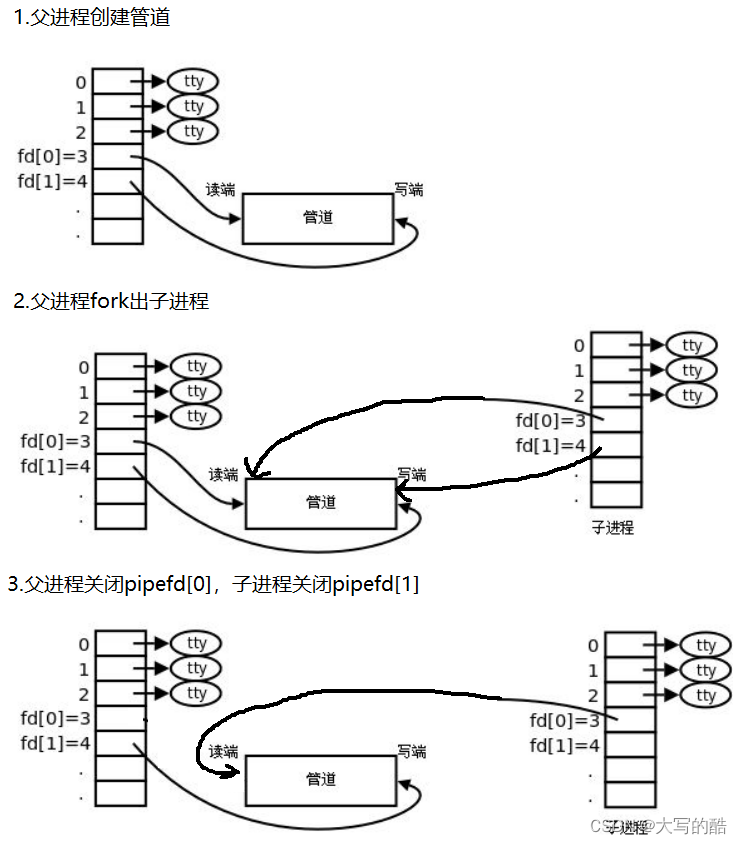
进程池就是父进程fork出多个子进程,使用进程间通信的方法父进程向子进程发送任务,子进程完成任务返回给父进程。对于父进程fork出来的一个子进程,父进程使用管道文件与子进程进行通信的原理如下:
对于进程池中父进程通信多个子进程的原理亦是如此,看如下代码实现。
主函数框架:
进程池首先需要一个vector记录创建的所有子进程,父进程发送任务可随机选择子进程执行任务,接下来就是创建多个子进程和对应管道,将每个子进程的写端关闭,然后子进程就是等待父进程派发任务;对于父进程,在关闭读端之后,开始派发任务,依旧是面向用户的一个菜单,框架与以前写的游戏菜单一样,用户可以选择菜单上的选项进行操作,用户操作结束以后,紧接着关闭所有的fd以及父进程等待接收子进程,以免子进程成为僵尸进程。
代码:
#include <iostream>
#include <vector>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <assert.h>
#include "Task.hpp"#define PROCESS_NUM 5int main()
{vector<pair<pid_t, int>> process_vec;// 创建多个子进程for (int i = 0; i < PROCESS_NUM; i++){// 创建管道 //注意:管道创建要在循环里面int pipefd[2] = {0};int res = pipe(pipefd);assert(res == 0);pid_t id = fork();if (id == 0){// 子进程:读,关闭写close(pipefd[1]);while (true){//接收任务}exit(1);}// 父进程:写,关闭读close(pipefd[0]);process_vec.push_back(make_pair(id, pipefd[1])); //记录进程}// 派发任务int select;srand((unsigned int)time(nullptr));do{usleep(100000);printf("**************************************************\n");printf("*** 0.quit 1.show tasks 2.execute task ***\n");printf("**************************************************\n");printf("请输入:\n");cin >> select;if (select == 0){printf("退出成功\n");}else if (select == 1){//显示任务}else if (select == 2){//发送任务}else{printf("输入有误\n");}} while (select);//关闭所有fd//接受收进程return 0;
}任务(Task.hpp):
首先将所有任务实现在这个头文件中,这里仅有task0、1、2、3四个任务,创建一个vector存储这些任务,此外,再创建一个map存储这些任务的序号和对应介绍(这里只显示名称),以便于主函数菜单中的任务显示(ShowTask()函数),而TaskLoad()函数是在完成vector和map的填充。
代码:
#pragma once#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
#include <unistd.h>
#include <functional>
#include <map>
using namespace std;typedef function<void()> task; //c++11中提出,作为函数指针的平替
vector<task> task_vec;
map<int,string> task_info;void task0()
{printf("进程[%d]正在执行任务0\n");
}
void task1()
{printf("进程[%d]正在执行任务1\n");
}
void task2()
{printf("进程[%d]正在执行任务2\n");
}
void task3()
{printf("进程[%d]正在执行任务3\n");
}void TaskLoad()
{task_info.insert(make_pair(task_vec.size(),"task0"));task_vec.push_back(task0);task_info.insert(make_pair(task_vec.size(),"task1"));task_vec.push_back(task1);task_info.insert(make_pair(task_vec.size(),"task2"));task_vec.push_back(task2);task_info.insert(make_pair(task_vec.size(),"task3"));task_vec.push_back(task3);
}void ShowTasks()
{for(auto i:task_info){cout<<i.first<<":"<<i.second<<endl;}
}主函数细节:
首先就是要主函数中上传任务(TaskLoad());对于父进程的执行任务模块,随机采用子进程将任务序号write到管道中,对于子进程的接收任务模块,则是封装了一个函数,以实现如果父进程不发送任务,就堵塞的情形,在函数中,子进程去read管道中的数据,接收任务序号,再调用对应任务即可;对于最后的收尾工作,包括关闭所有fd、接收子进程,很简单,如代码所示。
代码:
#include <iostream>
#include <vector>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <assert.h>
#include "Task.hpp"#define PROCESS_NUM 5bool ReceiveTask(int fd,int& task_no)
{ssize_t n=read(fd,&task_no,sizeof(task_no));if(n!=sizeof(int)) //保证接收的数据是int大小的字节数return false;return true;
}int main()
{vector<pair<pid_t, int>> process_vec;TaskLoad();// 创建多个子进程for (int i = 0; i < PROCESS_NUM; i++){// 创建管道 //注意:管道创建要在循环里面int pipefd[2] = {0};int res = pipe(pipefd);assert(res == 0);pid_t id = fork();if (id == 0){// 子进程:读,关闭写close(pipefd[1]);while (true){//接收任务int task_no=0;bool res=ReceiveTask(pipefd[0], task_no);//封装函数意义:如果父进程不发,就堵塞if(!res)break;if(task_no<0||task_no>=task_vec.size())printf("输入有误\n");elsetask_vec[task_no]();}exit(1);}// 父进程:写,关闭读close(pipefd[0]);process_vec.push_back(make_pair(id, pipefd[1]));}// 派发任务int select;srand((unsigned int)time(nullptr));do{usleep(100000);printf("**************************************************\n");printf("*** 0.quit 1.show tasks 2.execute task ***\n");printf("**************************************************\n");printf("请输入:\n");cin >> select;if (select == 0){printf("退出成功\n");}else if (select == 1){ShowTasks();}else if (select == 2){int task_no;int i = rand() % task_vec.size();printf("请输入:");cin >> task_no;write(process_vec[i].second, &task_no, sizeof(task_no));}else{printf("输入有误\n");}} while (select);//关闭所有fdfor(auto i:process_vec){close(i.second);}//接受收进程for(auto i:process_vec){int ret=waitpid(i.first,nullptr,0);}return 0;
}运行:
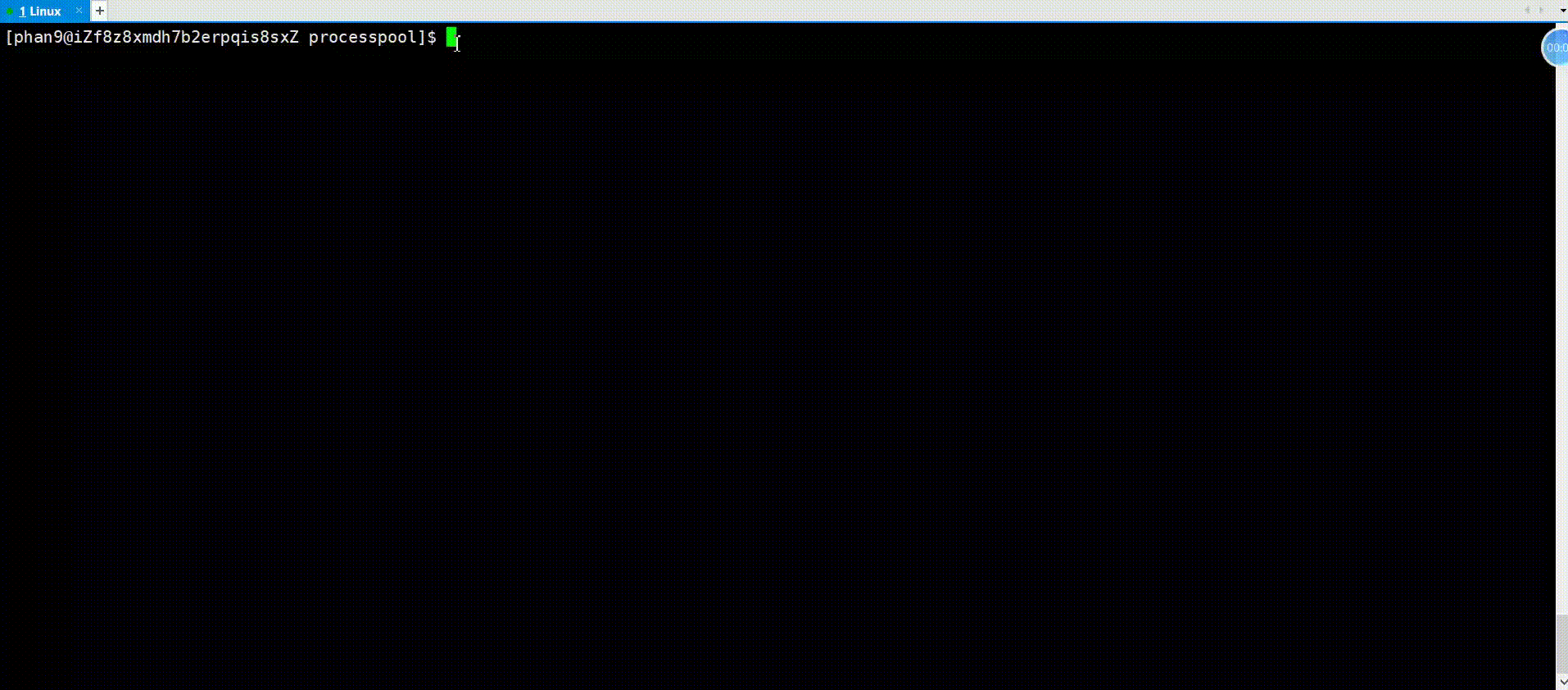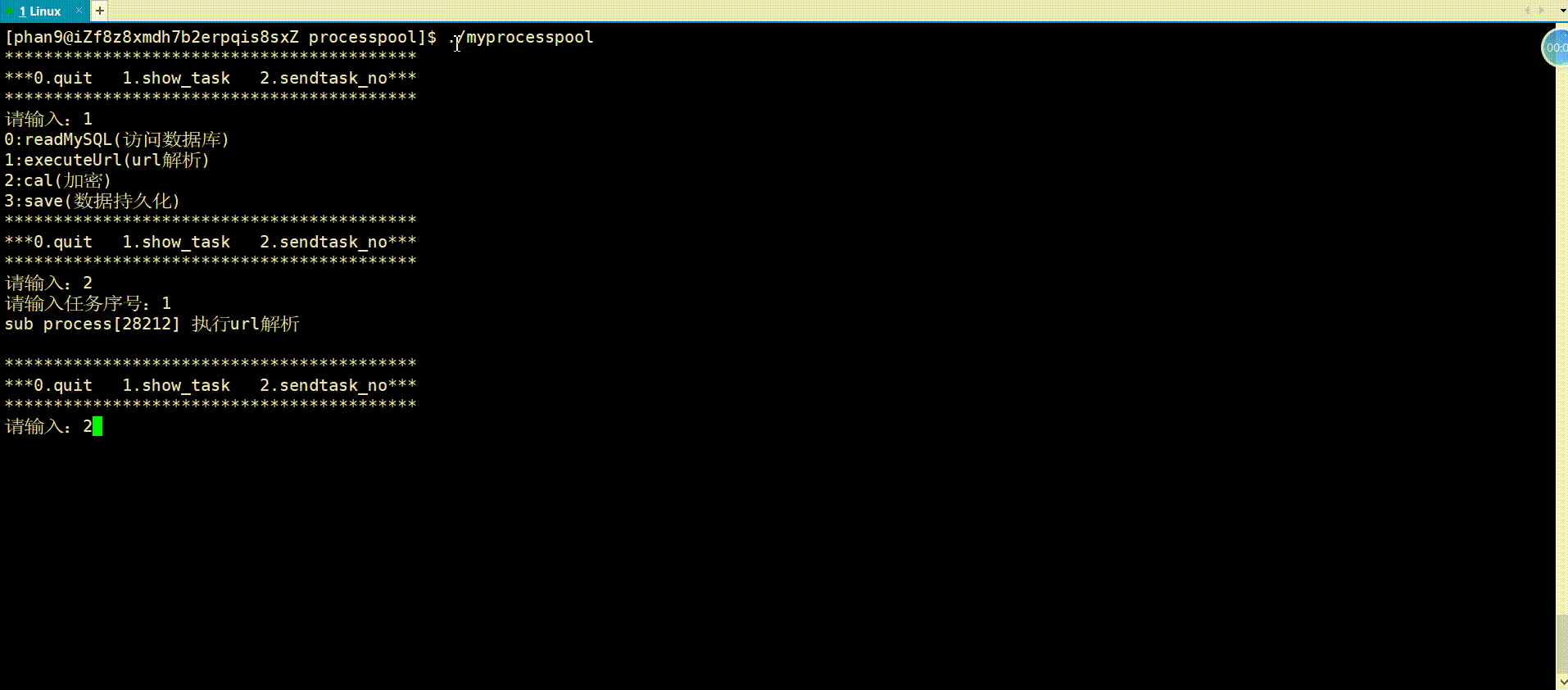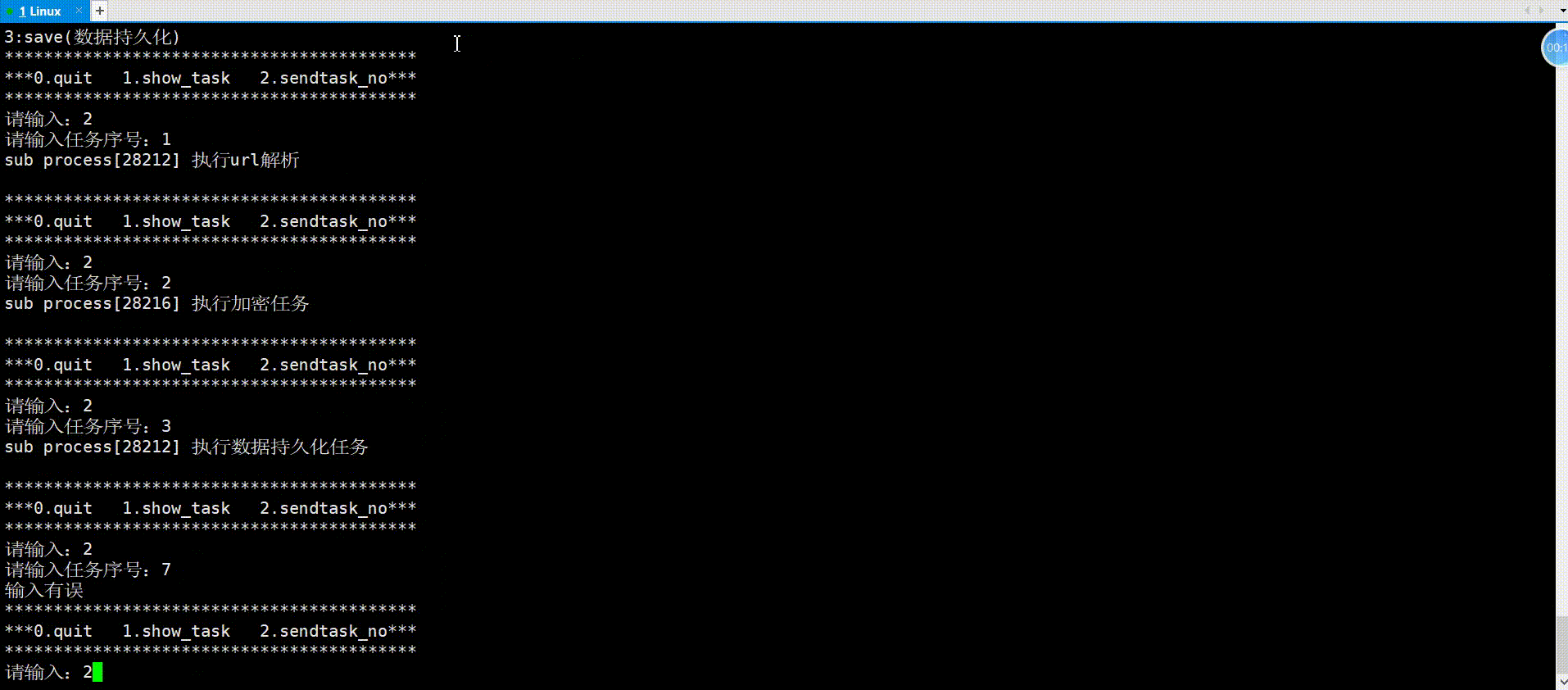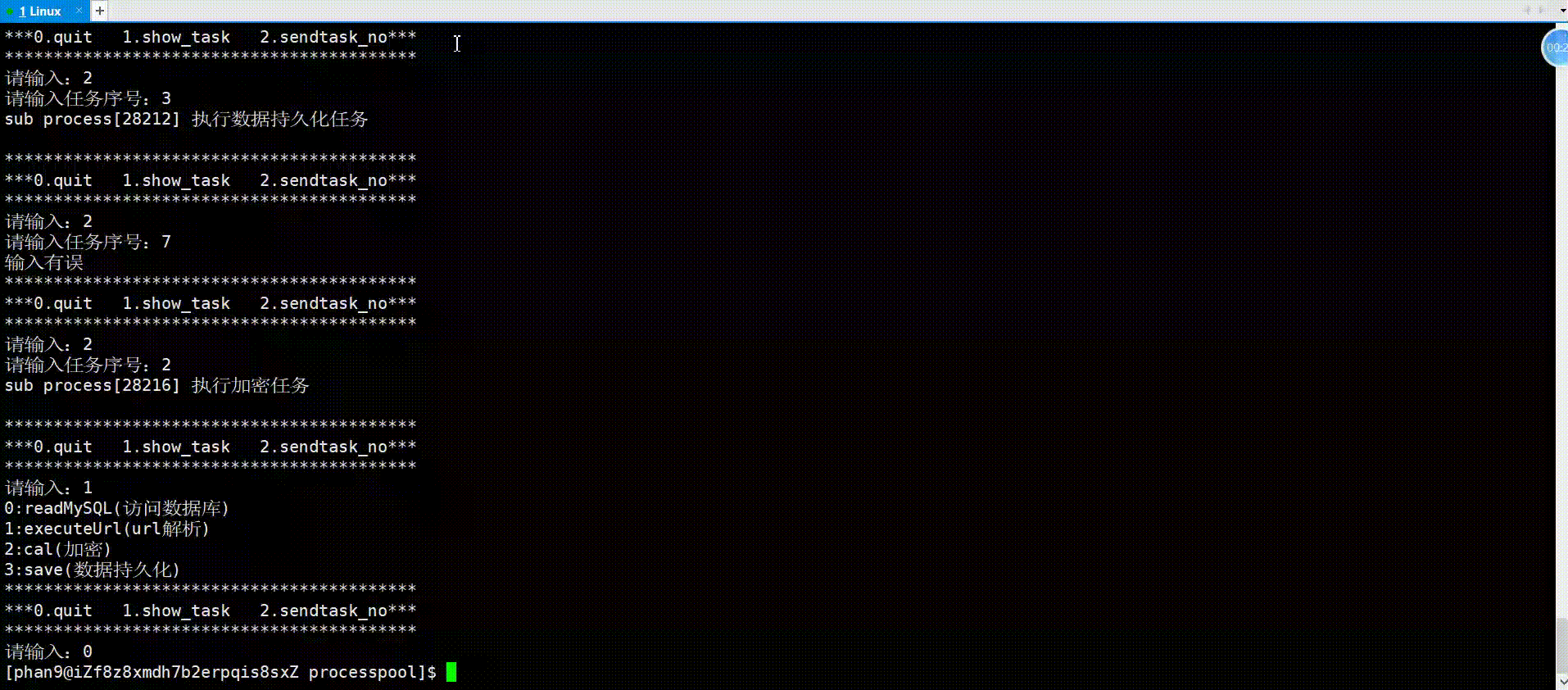
通过以上对匿名管道的理解,我们可以发现,管道是具有访问控制的,以下就是其读写规则,即
①当没有数据可以读时,即写的慢,读的快,read调用阻塞,即进程暂停执行,一直等到有数据来到为止;
②当管道满了时,即写的快,读的慢,write调用阻塞,直到有进程读走数据;
③如果所有管道写端对应的文件描述符被关闭,则read返回0,表示读到了管道文件末尾;
④如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出。
我们也可以总结出匿名管道的特点,如下:
① 只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;通常,一个管道由一个进程创建,然后该进程调用fork,此后父子进程之间就可应用该管道;
②管道提供流式服务,这与协议有关,后面再说;
③一般而言,进程退出,管道释放,所以管道的生命周期随进程;
④一般而言,内核会对管道操作进行同步与互斥,即提供了访问控制;
⑤管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道。
命名管道
-
介绍
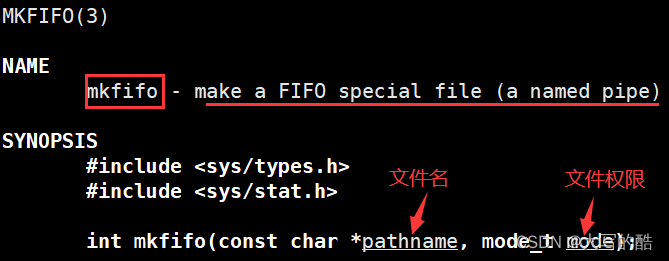
对于匿名管道,很大的一个缺点就是只能在具有公共祖先(如父子进程)的进程间通信,若想要在不相关的进程间通信,下面要讲到的命名管道(FIFO文件)就是方法之一。命令行实现:mkfifo filename,举例如下图:
代码实现:
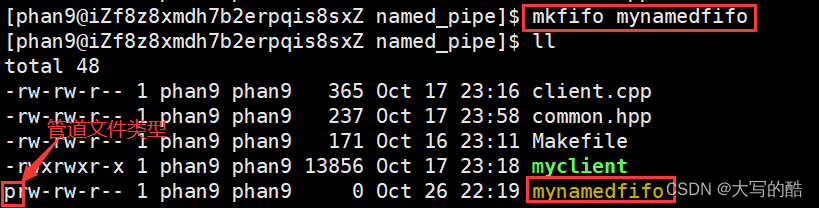
-
举例
对于服务端,首先是通过mkfifo函数创建命名管道(fifo文件),接着使用open系统调用打开此文件,下面就可以接收用户端的信息了,这里将接收信息封装成了一个函数getMessage(),而且创建了多个子进程来随机接收任务,最后就是收尾工作,包括父进程接收子进程的、关闭管道文件以及删除管道文件;对于getMessage函数,首先创建一个缓冲区存放用户端发送的信息,接着下面是个循环接收信息的过程,通过read系统调用将信息存放至缓冲区内,这里注意对read的返回值分情况讨论,当读到文件末尾时将不再继续读取,break退出。
代码(server):
#include <iostream>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <assert.h>
#include <string.h>
using namespace std;#define FIFONAME "mypipe"
#define FIFOMODE 0666void getMessage(int fd)
{char buffer[1024];while (true){memset(buffer, '\0', sizeof(buffer));ssize_t n = read(fd, buffer, sizeof(buffer) - 1);//后续对n的分情况处理较为重要if(n>0){printf("client[%d]>%s\n", getpid(),buffer);}else if(n==0)//读到了文件结尾{break;}else{perror("read");break;}}
}int main()
{// 创建命名管道int res = mkfifo(FIFONAME, FIFOMODE);if (res < 0){perror("mkfifo");exit(1);}printf("创建管道文件成功\n");// 打开管道文件int fd = open(FIFONAME, O_RDONLY);if (fd < 0){perror("open");exit(2);}printf("打开管道文件成功\n");// 正常操作(读)int process_nums=5;for(int i=0;i<process_nums;i++){pid_t id=fork();if(id==0){getMessage(fd);exit(3);}}// 接收子进程for(int i = 0; i < process_nums; i++){waitpid(-1, nullptr, 0);}//关闭文件close(fd);printf("关闭管道文件成功\n");//删除管道文件int ret=unlink(FIFONAME);assert(res!=-1);printf("删除管道文件成功\n");return 0;
}在服务端创建了管道文件之后,用户端也通过系统调用open打开此文件,接下来循环去发送文件,使用系统调用write将信息写进管道文件中,最后收尾工作,将文件fd关闭。
代码(client):
#include <iostream>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <assert.h>
#include <string.h>
using namespace std;#define FIFONAME "mypipe"
#define FIFOMODE 0666int main()
{// 打开通道文件int fd = open(FIFONAME, O_WRONLY);assert(fd > 0);// 开始操作(写)string message;while (true){cout << "请输入:\n";cin >> message;write(fd, message.c_str(), strlen(message.c_str()));}//关闭文件close(fd);return 0;
}运行:
以上就是管道的两种类型的全部介绍,我们可以来总结一下两者的区别:
①匿名管道由pipe函数创建并打开,命名管道由mkfifo函数创建,用系统接口open打开;
②匿名管道只能在具有公共祖先(如父子进程)的进程间使用,而命名管道可以在不相关的进程间使用,
除此之外,二者具有相同的功能。
共享内存
-
介绍
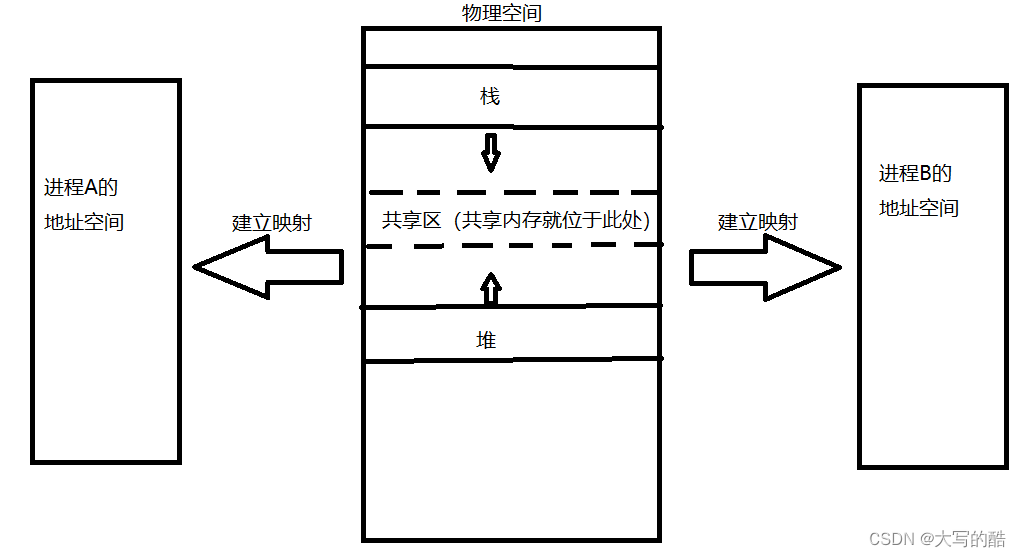
共享内存可以说是最快的IPC(进程间通信)方式,因为其属于内存级的数据传输,且不需要过多的拷贝,当这块资源(内存)映射到涉及的两个进程的地址空间,那么数据传输不需要再输入输出内核空间(只在用户空间中),即不需要再使用read、write等系统调用接口传输数据,与此相对应的是pipe、fifo文件均是件,属于内核空间,需要用read、write等系统调用接口传输数据以致通信。示意图如下:
-
共享内存函数
1.shmget
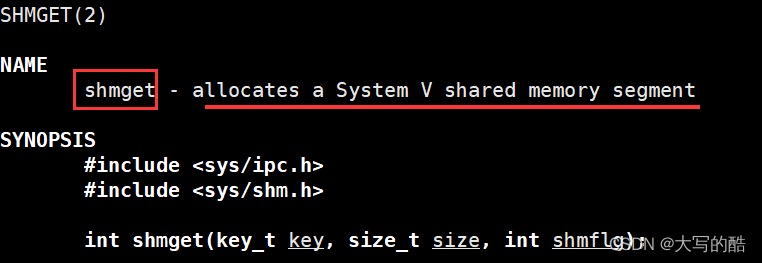
功能:创建共享内存;
参数:
key是关键字,是对于os而言的共享内存标识符,这个值调用ftok函数(下面介绍)由os创建,两个进程创建共享内存时使用同一个key值即是共享了这一块内存;
size是共享内存的大小,建议设置成页大小(4096)的整数倍;
shmflg是权限标志,填IPC_CREAT,表示若底层已存在key标识的共享内存,则获取之并返回,若不存在则创建之并返回;填IPC_CREAT | IPC_EXCL,表示若底层不存在则创建并返回,若存在则出错返回,注意后面还可以再或上八进制权限表示法,设置共享内存的权限;
返回值:成功返回一个非负整数,称为shmid,是对于用户而言的共享内存标识符,失败返回-1。
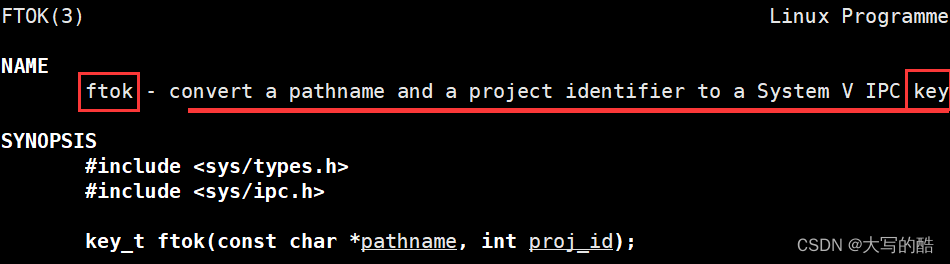
功能:把一个已存在的路径名和一个整数标识符转换成key;
参数:pathname是路径名,由用户指定,此路径必须存在且可存取;proj_id也是由用户指定,该值必须是一个至少有8个比特位的非零值;
返回值:返回一个key值。
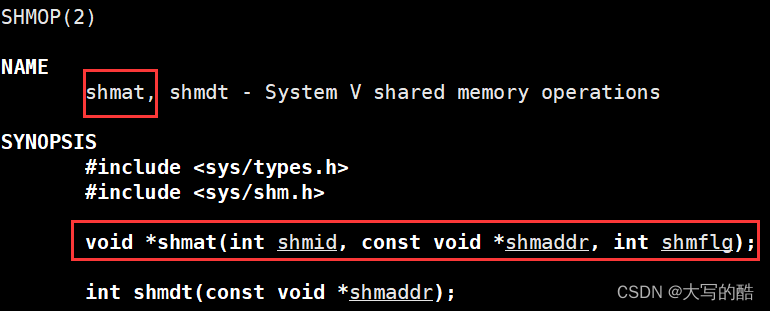
2.shmat
功能:将共享内存挂接(映射)到进程地址空间;
参数:
shmid就是shmget的返回值,是对于用户而言的共享内存标识符;
shmaddr是指定连接的地址,可设置为nullptr成为默认值;
shmflg可设置为0成为默认值;
返回值:成功返回一个指针指向共享内存的第一个字节,失败返回空,用法类似malloc。
3.shmdt
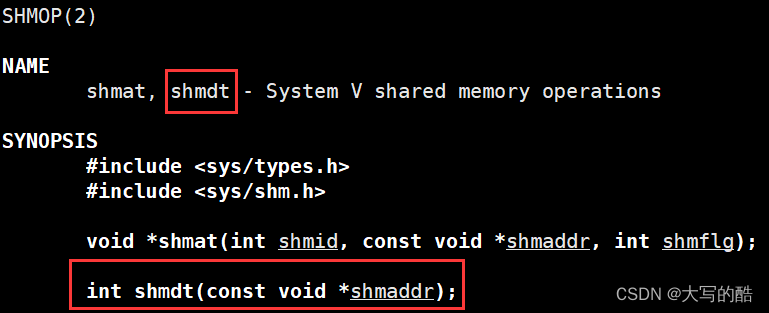
功能:将共享内存脱离当前进程;
参数:指向共享内存的指针shmaddr;
返回值:成功返回0,失败返回-1。
4.shmctl
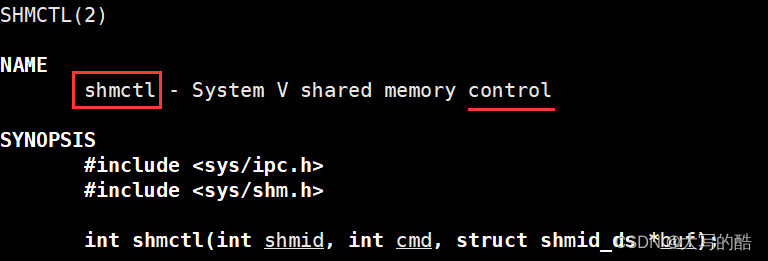
功能:控制共享内存,常用于删除共享内存;
参数:
shmid是共享内存标识符;
cmd可填入IPC_RMID,表示删除共享内存;
buf可填nullptr表示设置默认值;
返回值:成功返回0,失败返回-1。
注意:system V IPC资源的生命周期随内核,即需要手动(指令)删除或者代码删除,逼向管道资源,生命周期随进程,进程结束资源也就被删除了。
-
举例
1.框架
1).common.hpp
代码:
#pragma once#include <iostream>
#include <cstdio>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/wait.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <assert.h>
#include <string.h>
using namespace std;#define PATHNAME "/home/phan9" //具有访问权限
#define PROJ_ID 0x66 //自定
#define SHM_SIZE 4096 //共享内存的大小,最好是页(PAGE: 4096)的整数倍2).server.cpp
先通过ftok函数创建key值,再通过此key值使用shmget函数创建共享内存,client也是通过此方法创建(识别到)这同一块共享内存,紧接着,将此共享内存通过shmat函数挂接到当前进程上,之后就可以使用shmaddr指针使用此共享内存,这里可以将共享内存当作成一个shmaddr指向的大字符串,通信结束后,先是使用shmdt函数将此共享内存与此进程相脱离,再用shmctl函数删除此共享内存。
代码:
#include "common.hpp"int main()
{int res;//与client通过ftok内部算法创建相同的keykey_t key=ftok(PATHNAME,PROJ_ID);if(key==-1){perror("ftok");exit(1);}printf("server创建key成功,key:%d\n",key); //创建shm,服务器是通信的发起者---要创建一个全新的共享内存,所以要使用IPC_CREAT|IPC_EXCLint shmid=shmget(key,SHM_SIZE,IPC_CREAT|IPC_EXCL|0666);if(shmid==-1){perror("shmget");exit(2);}printf("server创建共享内存成功,shmid:%d\n",shmid);//关联共享内存,shmat用法与malloc一样char* shmaddr=(char*)shmat(shmid,nullptr,0); //最后一个参数设为0,是默认只读的形式关联if(shmaddr==nullptr){perror("shmat");exit(3);}printf("server关联共享内存成功,shmid:%d\n",shmid);sleep(5);//通信//*****************************************************//...//*****************************************************//共享内存去关联res=shmdt(shmaddr);if(res==-1){perror("shmdt");exit(4);}printf("server共享内存去关联成功,shmid:%d\n",shmid);sleep(5);//删除共享内存res=shmctl(shmid,IPC_RMID,nullptr);if(res==-1){perror("shmctl");exit(5);}printf("server删除共享内存成功,shmid:%d\n",shmid);return 0;
}3).client.cpp
框架部分,client大部分代码是与server一样的,唯一不同的就是client不需要删除共享内存,因为client不是该共享内存的发起者,应当是server来删除。
代码:
#include "common.hpp"int main()
{int res;//创建keykey_t key=ftok(PATHNAME,PROJ_ID);if(key==-1){perror("ftok");exit(1);}printf("client创建key成功,key:%d\n",key);//创建共享内存int shmid=shmget(key,SHM_SIZE,IPC_CREAT);if(shmid==-1){perror("shmget");exit(2);}printf("client创建共享内存成功,shmid:%d\n",shmid); //关联共享内存,shmat用法与malloc一样char* shmaddr=(char*)shmat(shmid,nullptr,0);if(shmaddr==nullptr){perror("shmat");exit(3);}printf("client关联共享内存成功,shmid:%d\n",shmid);sleep(5);//通信//*****************************************************//...//*****************************************************//共享内存去关联res=shmdt(shmaddr);if(res==-1){perror("shmdt");exit(3);}printf("client共享内存去关联成功,shmid:%d\n",shmid);sleep(5);//client不需要删除shmreturn 0;
}
4).运行
ipcs -m:查看共享内存
while :; do ipcs -m; sleep 1; done:一秒显示一次共享内存
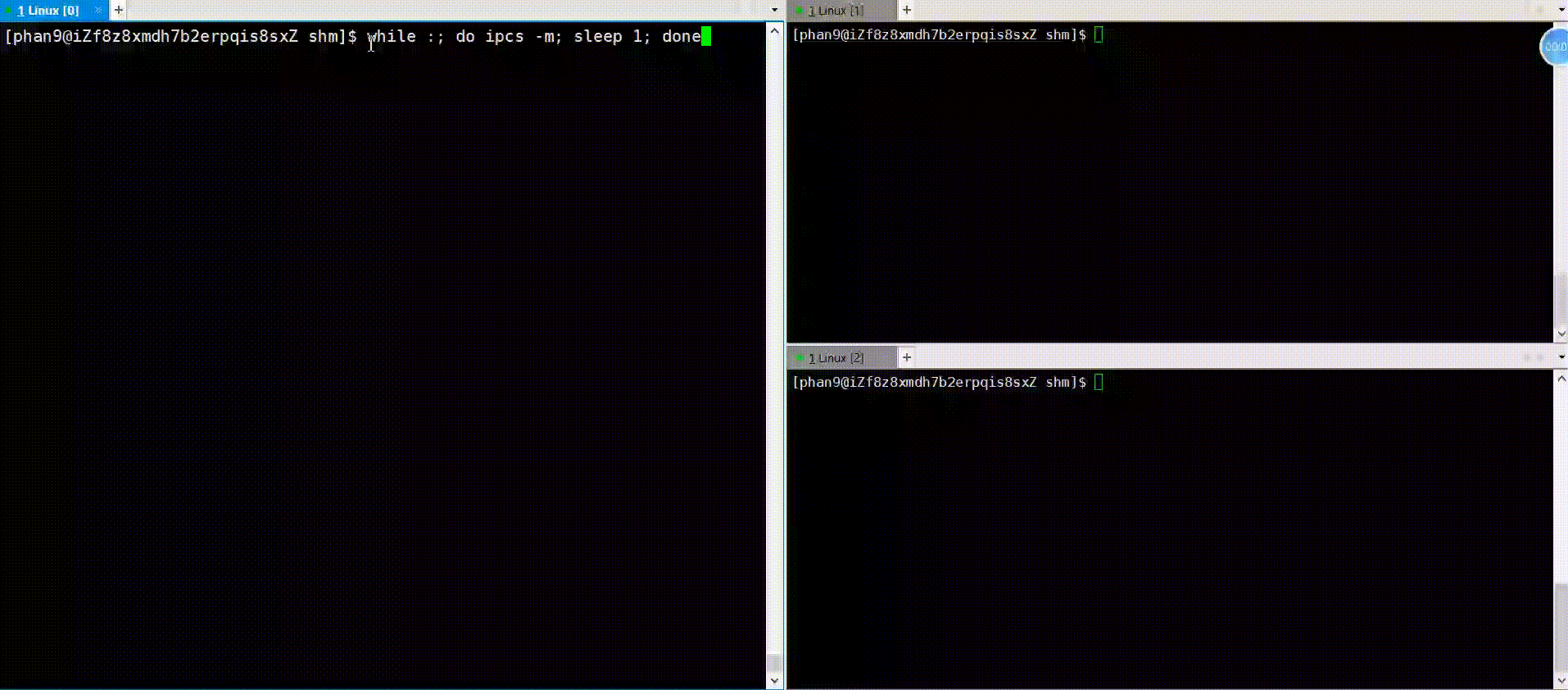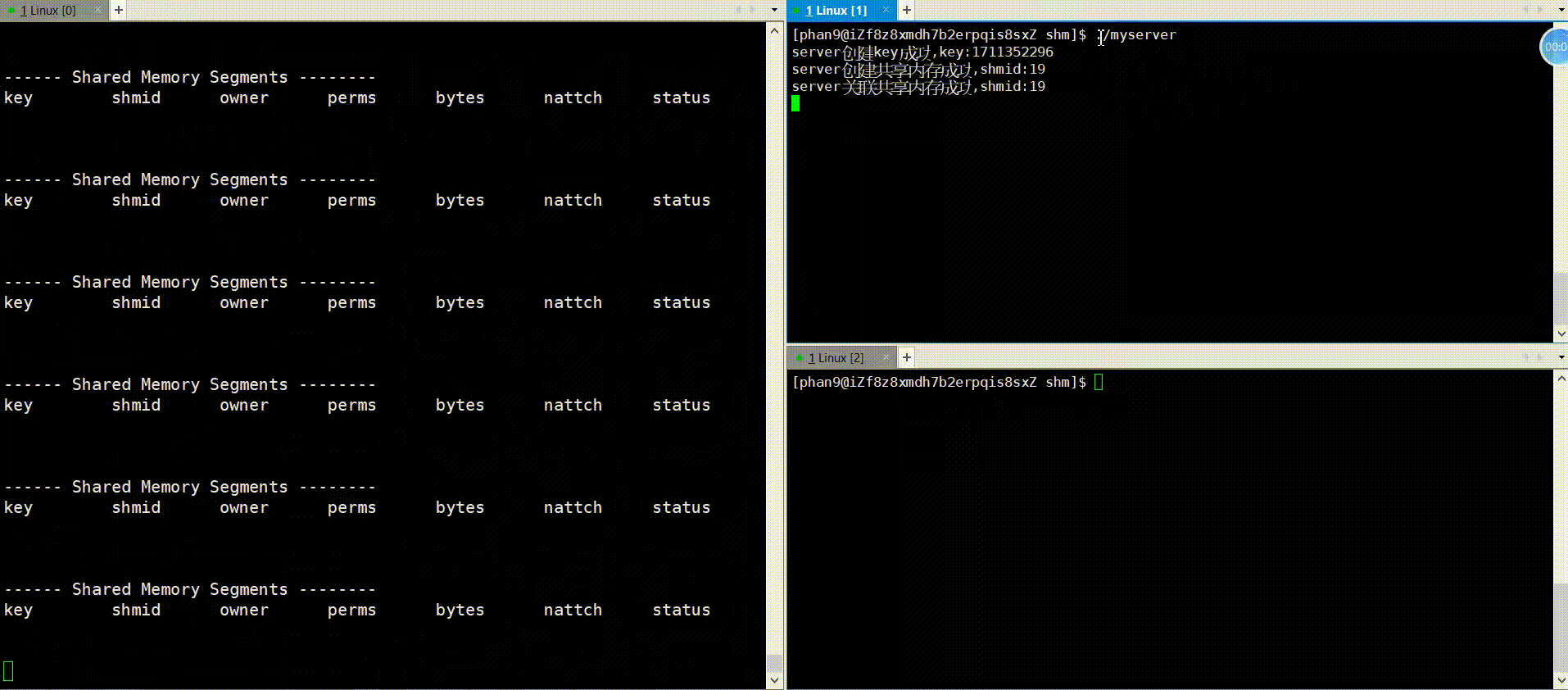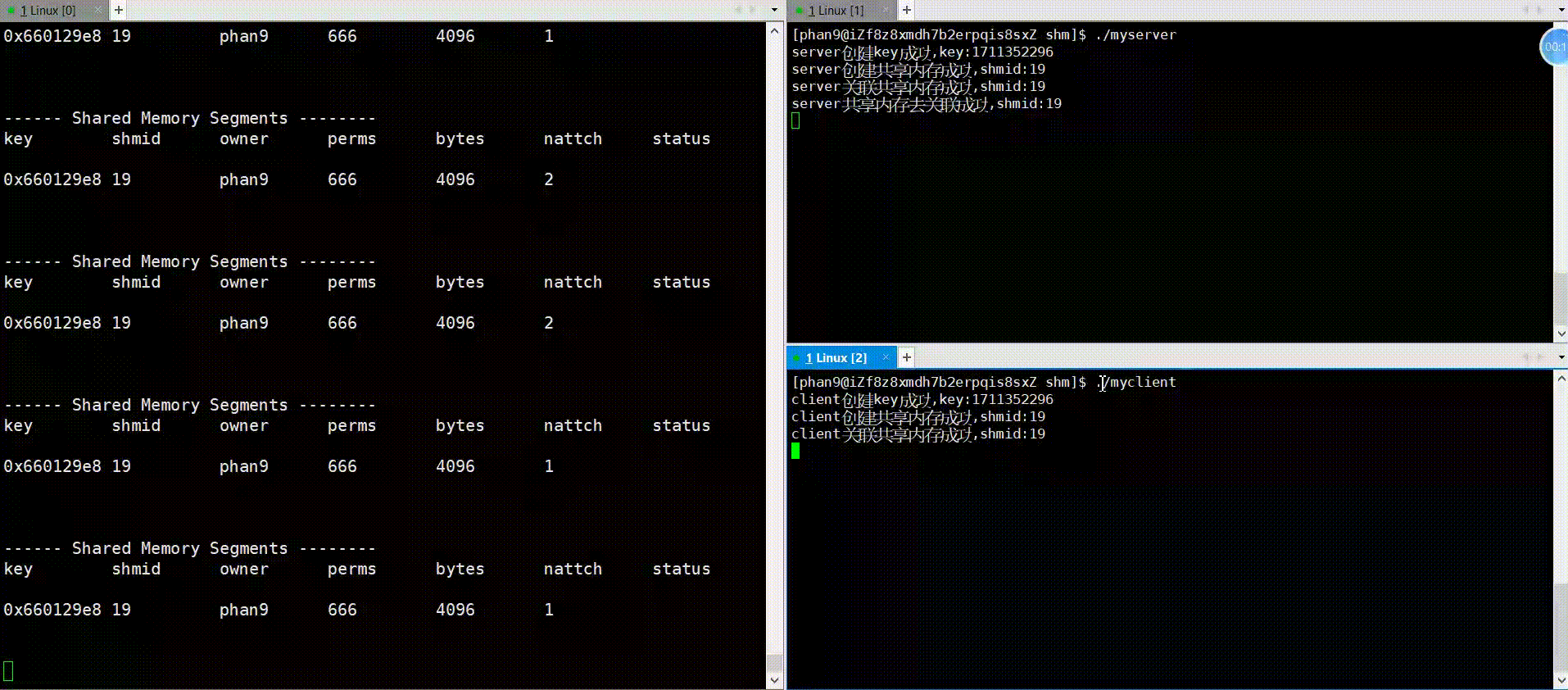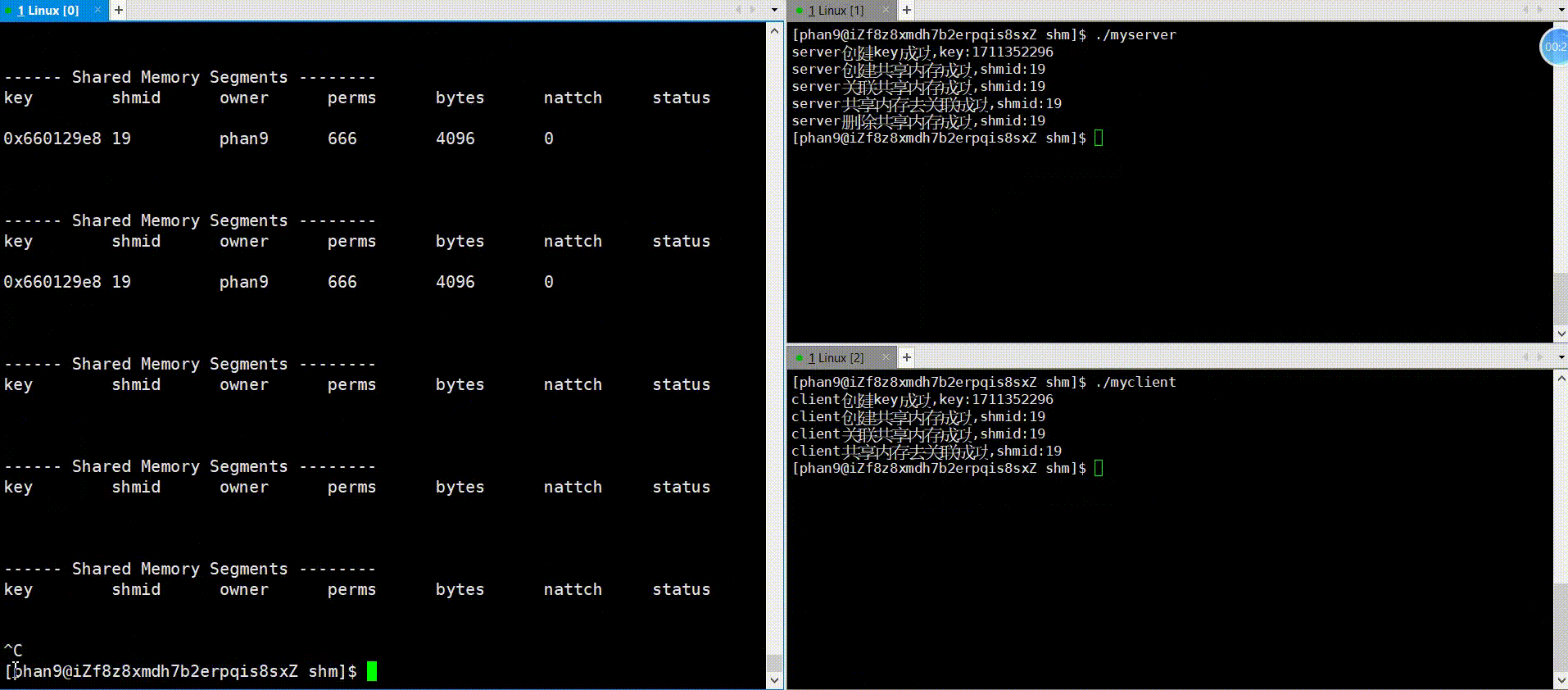
代码中会用sleep函数模拟通信逻辑部分,先运行server,再运行client可看到如下图情况,运行server,nattach变成1,三秒之后,运行client,nattach变成了2,紧接着server中对共享内存去关联,随即nattach变成了1,在client也去关联之后,nattach变成了0,可见,框架的运行逻辑是没错的,下面看一下通信逻辑的实现。
运行:
2.通信逻辑
1).server.cpp
server将共享内存当成一个字符串,即将shmaddr当成字符串的首地址,举例让server反复去检查共享内存有无信息可以读取,有的话立马读出来,当遇到quit字符串时就退出读取。
代码:
//通信(读)//server将共享内存当成一个字符串,即将shmaddr当成字符串的首地址while(true){printf("%s\n",shmaddr);if(strcmp(shmaddr,"quit")==0)break;sleep(1);}2).client.cpp
client将共享内存当成一个char类型的缓存区,这里我们举例让client反复去写信息,当写到quit字符串时就停止写入。
代码:
//通信(写)//client将共享内存当成一个char类型的缓存区while(true){cin>>shmaddr;if(strcmp(shmaddr,"quit")==0)break;}运行:

上图中可见,无论client运不运行,server都在一直从共享内存读消息,当client写进消息时,server能立马读出来,要知道共享内存是内存级的读写,是IPC中最快的,因为不需要过多的拷贝工作,但是共享内存缺乏访问控制,这样会带来并发问题,即client还没将信息写完整,server就已经读到了,这会产生不可控的影响。
那如何做到一定的访问控制呢?
我们知道,管道文件是自带访问控制的,那我们不妨借助管道文件来实现共享内存的访问控制,如下common.hpp代码中,我们首先实现了一个类,来创建和删除管道文件,只要在server中我们定义一个全局变量的该类的对象,那么在运行server时都会自动创建管道文件,运行结束就会自动删除管道文件,紧接着就是为打开和删除管道文件封装的函数,而Wait函数就是实现server读取共享内存中的信息前进行等待的功能,Wake函数就是实现client将消息输入到共享内存后提醒server可以读取消息的功能,其中tmp是通过管道的临时信息,具体使用如代码2、3。
1).common.hpp
#define FIFONAME "./myfifo"class Init
{
public:Init(){umask(0);int ret=mkfifo(FIFONAME,0666);assert(ret==0);}~Init(){unlink(FIFONAME);}
};int OpenFifo(const char* FifoName,int flags)
{int fd=open(FIFONAME,flags);assert(fd>=0);return fd;
}
void CloseFifo(int fd)
{close(fd);
}void Wait(int fd)
{printf("等待中\n");int tmp=0;read(fd,&tmp,sizeof(int));
}void Wake(int fd)
{int tmp=1;write(fd,&tmp,sizeof(tmp));
}2).server.cpp
在server读取共享内存的消息之前,先进行等待,当client向共享内存输入了信息(即将tmp输入到管道后),就算是等待到了信息,随后即可读取共享内存的信息,值得注意的是,在读取前后,要打开和关闭管道文件。
代码:
//通信(读)//server将共享内存当成一个字符串,即将shmaddr当成字符串的首地址int fd=OpenFifo(FIFONAME,O_RDONLY);while(true){Wait(fd);printf("%s\n",shmaddr);if(strcmp(shmaddr,"quit")==0)break;}CloseFifo(fd);3).client.cpp
在client向共享内存写入了信息之后,提醒server可以读取了(即将管道的内容读到了tmp中),也要注意,写入信息前后别忘了打开和关闭管道文件。
代码:
//通信(写)//client将共享内存当成一个char类型的缓存区int fd=OpenFifo(FIFONAME,O_WRONLY);while(true){cin>>shmaddr;if(strcmp(shmaddr,"quit")==0)break;Wake(fd);}CloseFifo(fd);运行:

消息队列
消息队列是一个可以存储消息的缓冲区,它有一个唯一的标识符来区分不同的消息队列。进程可以通过调用消息队列相关的API来创建、发送、接收和删除消息队列。
System V消息队列提供了一些优点,如异步通信、灵活的消息长度、高效的消息传递和顺序保证,使得它成为一种常见的IPC机制。但是,它也存在一些缺点,如消息队列的大小受限于系统内存、没有提供消息确认机制和没有提供消息过期机制。
在Linux系统中,类似共享内存一样,消息队列也可以使用类似函数,比如msgget()、msgsnd()、msgrcv()和msgctl()等函数来操作System V消息队列。
查看消息队列:ipcs -q
删除消息队列:ipcrm -q msqid
信号量
system V信号量是一种用于进程间同步和通信的机制。它是UNIX系统中用于进程间同步和互斥的一种机制,常被用于进程间共享资源的同步和互斥(下面介绍)。
system V信号量由3部分组成:一个计数器,一个等待队列和一些函数。计数器用于记录可用资源数量,等待队列用于保存等待该资源的进程列表,函数用于对信号量进行操作,例如增加、减少、初始化等操作。
当一个进程需要访问共享资源时,它必须先申请信号量。如果信号量的计数器值大于0,那么进程可以使用该资源,并将信号量计数器减1。如果计数器值为0,则表明该资源已经被占用,申请进程将被阻塞,直到该资源被释放。释放资源的进程将会增加信号量计数器的值,同时唤醒等待队列中的一个或多个进程来获取资源。
system V信号量提供了一种可靠的机制来防止多个进程同时访问共享资源。它是一种重要的进程间通信和同步机制,在多进程编程中应用广泛。
查看信号量:ipcs -s
删除信号量:ipcrm -s semid
-
同步与互斥
进程的同步是指在多个进程同时运行的情况下,为了避免出现不合预期的结果而采取的措施。由于各进程要求共享资源,而且有些资源需要互斥使用,因此各进程间竞争使用这些资源,进程的这种关系为进程的互斥。
其中,多个进程(执行流)访问公共的同一份资源,这一份资源称为临界资源;涉及临界资源的代码称为临界区。
注意:
一般地,多个执行流一起运行时互相干扰,主要是因为在不加保护的情况下在临界区访问了临界资源,但在非临界区多个执行流是互不影响的。
-
理解信号量
如同想在电影院看电影,就要先买票一样,进程访问临界资源就要先申请信号量;如同卖掉一张电影票,电影院的座位就少一个一样,一个进程申请信号量成功,信号量计数器就--,就能成功预定想要的资源,当执行完自己的临界区代码(访问完临界资源),信号量就会释放,计数器就会++。
其中买票是对座位的预定,而申请信号量就是对临界资源的预定。
后记
进程间通信的方法很多,涉及到的知识点不是很难,但实操起来是是有一点困难,难的是一些细节的处理,虽然这些并不是目前主流的通信方式,但是都是一些较为经典的、会在面试当中被问到的知识点,希望可以通过此文章了解一部分,有问题的可以在评论中提出哦,拜拜!
相关文章:
yo!这里是进程间通信
目录 前言 进程间通信简介 目的 分类 匿名通道 介绍 举例(进程池) 命名管道 介绍 举例 共享内存 介绍 共享内存函数 1.shmget 2.shmat 3.shmdt 4.shmctl 举例 1.框架 2.通信逻辑 消息队列 信号量 同步与互斥 理解信号量 后记…...

使用docker安装MySQL,Redis,Nacos,Consul教程
文章目录 安装MySQL安装Redis安装Nacos安装Consul 如未安装docker,参考教程: https://blog.csdn.net/m0_63230155/article/details/134090090 安装MySQL #拉取镜像 sudo docker pull mysql:latestsudo docker run --name mysql \-p 3306:3306 \-e MYSQ…...

python和Springboot如何交互?
Python和Spring Boot可以通过RESTful API进行交互。Spring Boot通常用于后端开发,提供了快速构建RESTful API的工具,而Python则可以用于编写前端或与后端交互的代码。 要实现Python和Spring Boot的交互,可以按照以下步骤进行: 在…...

Qt实现json解析
前提要点 json文件,可通过键值的方式存储你所需要的数据,斌且支持多种类型存储,类似于一种结构化的数据库,在读取json文件时可通过相对应的关键字精准获取。他是一种树状结构,我们可以自己设定叶子的数量以及他所代表…...

Ajax、Json深入浅出,及原生Ajax及简化版Ajax
Ajax 1.路径介绍 1.1 JavaWeb中的路径 在JavaWeb中,路径分为相对路径和绝对路径两种: 相对路径: ./ 表示当前目录(可省略) ../ 表示当前文件所在目录的上一级目录 绝对路径: http://ip:port/工程名/资源路径 2.2 在JavaWeb中…...

前端第一阶段测试
前端第一阶段测试 选择问答 如果觉得有用请给我点个赞⑧~ 选择 1、【单选】下列哪个是子代选择器 A A、p>b B、p b C、pb D、p.b 2、【单选】下述有关css属性position的属性值的描述,说法错误的是?B A、static:没有定位,元素出…...

openlayers+vue的bug
使用addInteraction添加交互draw绘制,预期removeInteraction删除交互draw绘制时不再绘制,但是删除绘制不起作用,各种找原因,结果把data中的map变量注释掉即可,原因未知。 <template><div><div id"…...
实时数仓-Hologres介绍与架构
本文是向大家介绍Hologres是一款实时HSAP产品,隶属阿里自研大数据品牌MaxCompute,兼容 PostgreSQL 生态、支持MaxCompute数据直接查询,支持实时写入实时查询,实时离线联邦分析,低成本、高时效、快速构筑企业实时数据仓…...
asp.net教务管理信息系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio计算机毕业设计
一、源码特点 asp.net 教务管理信息系统是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c#语言 开发 asp.net教务管理系统 应用技术&a…...

爬虫、数据清洗和分析
爬虫、数据清洗和分析是在数据科学、数据挖掘和网络爬虫开发领域中常见的概念。 爬虫(Web Scraping):爬虫是一种自动化程序或脚本,用于从互联网上的网站上提取信息。这些信息可以是文本、图像、视频或其他类型的数据。爬虫通常会…...

SpringBoot | SpringBoot中实现“微信支付“
SpringBoot中实现"微信支付": 1.“微信支付”产品2."微信支付"接入流程3.“微信小程序支付”时序图:3.1 “商家端JSAPI下单” 接口3.2 “微信小程序端调起支付” 接口 4.微信支付准备工作:4.1 获得微信支付平台证书、商户私钥文件4…...
基于SSM和VUE的留守儿童信息管理系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
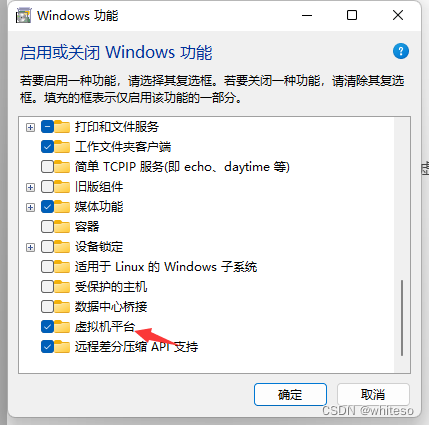
VMware 16开启虚拟机电脑就蓝屏W11解决方法
问题现象 解决方法 控制面板->程序->启用或关闭windows功能->勾选虚拟机平台->重启...
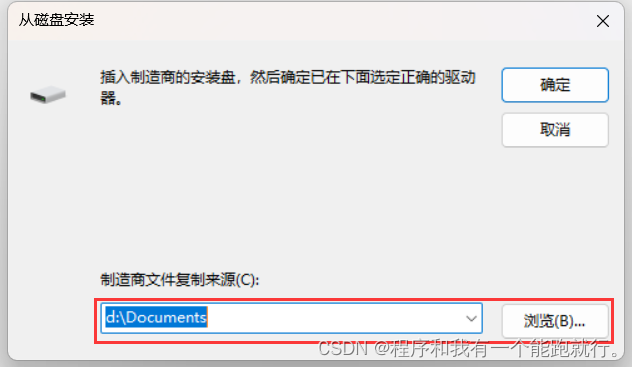
【Bug——VMware Workstation】虚拟机桥接网络没有 VMnet0
此时 没有VMnet0用来桥接网络。 接下来进行解决 1.找到安装VM的路径,在安装的目录里面找到如图所示的三个文件: 2.依次点击鼠标右键 将这三个文件依次安装如图所示: 二.windows下的操作 1.首先 找到电脑的控制面板->网络和internet->…...

centos中安装Mysql8.0
其实和mysql5.7的安装差不多 1.root用户 2.更新密钥 rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 3.安装mysql yum库 rpm -Uvh https://dev.mysql.com/ get/mysql80-community-release-el7-2.noarch.rpm 4.通过上两步,我们就可以使用yum去安装…...

简化对象和函数写法
简化对象写法: 传统写法: var x 10, y 20; var obj {x: x, y: y};简化写法: var x 10, y 20; var obj {x, y};简化函数写法: 传统写法: function add(x, y) {return x y; }简化写法: var add …...
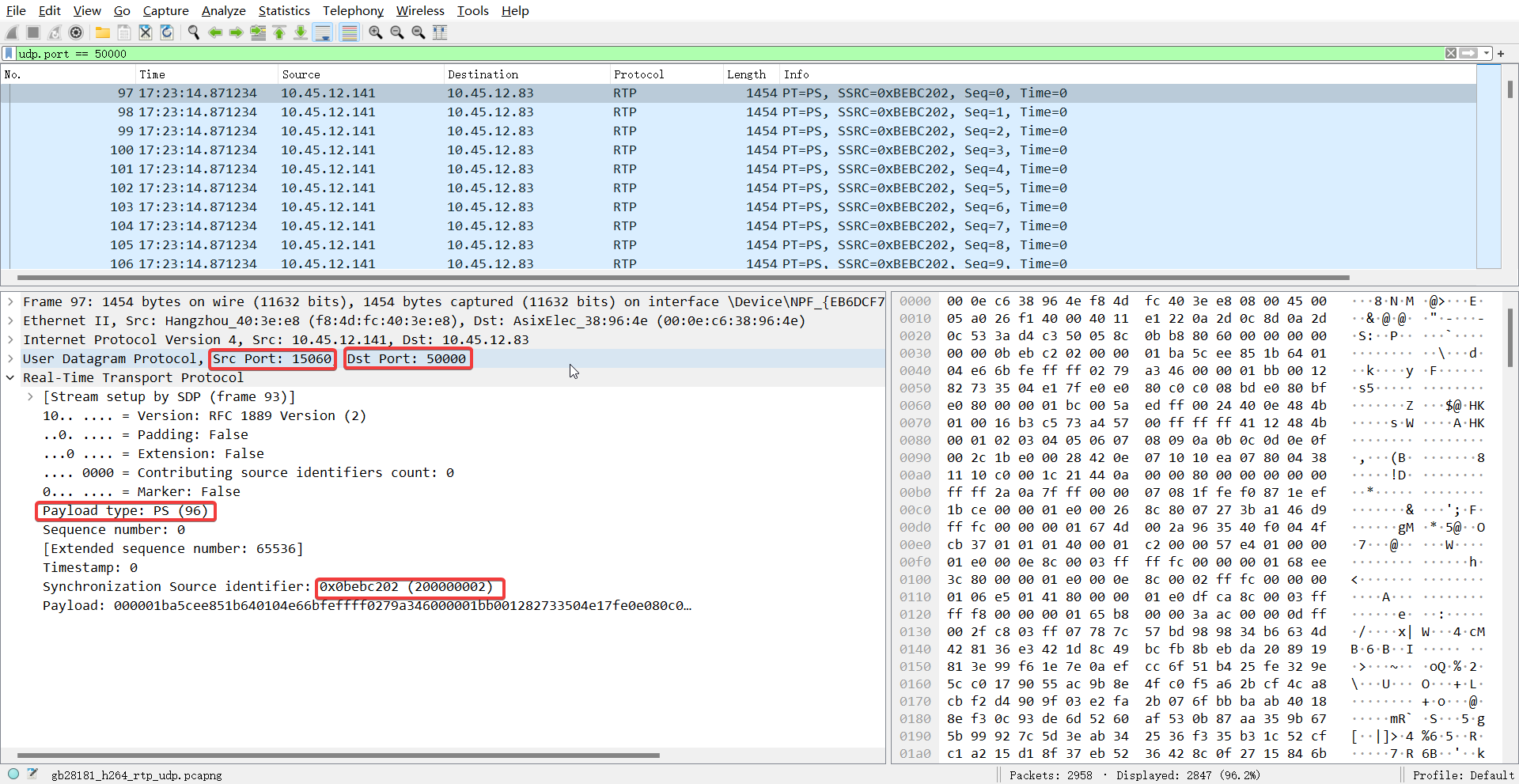
GB/T28181流媒体相关协议详解
GB/T28181流媒体相关协议详解 文章目录 GB/T28181流媒体相关协议详解1 GB/T28181协议中使用的应用层协议介绍2 实时视频点播协议交互流程2.1 设备注册2.2 设备保活2.3 视频播放 总结 本文主要主要针对28181协议中视频流的部分,来阐述视频流通过28181协议如何进行视频…...

十进制转二进制的算法代码 ← Python
【算法分析】 本算法需要用到的Python知识点: 1.求余%,整除 //。例如,7%21,7//23,而7/23.5。 2.Python列表的 append 及 pop 函数。 • append(x) 函数用于将 x 添加到现有列表中。 • pop() 函数默认移除列表中…...
智慧垃圾站:AI视频智能识别技术助力智慧环保项目,以“智”替人强监管
一、背景分析 建设“技术先进、架构合理、开放智能、安全可靠”的智慧环保平台,整合环境相关的数据,对接已建业务系统,将环境相关数据进行统一管理,结合GIS技术进行监测、监控信息的展现和挖掘分析,实现业务数据的快速…...

LeetCode 面试题 16.07. 最大数值
文章目录 一、题目二、C# 题解 一、题目 编写一个方法,找出两个数字a和b中最大的那一个。不得使用if-else或其他比较运算符。 示例: 输入: a 1, b 2 输出: 2 点击此处跳转题目。 二、C# 题解 找出最大的数,本质还是…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...

别再把大模型当搜索框了:一文讲透 LLM 的基本原理、能力边界与局限性
写在前面很多人把大语言模型当成“会聊天的搜索引擎”,结果一上线就遇到幻觉、口径不稳、上下文丢失、成本失控。真正理解 LLM,要先抓住一句话:它是基于 Transformer 的概率生成模型,核心能力来自海量预训练、上下文学习与后训练对…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...

告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境
告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境 当现代Linux系统已全面拥抱Python3的时代,突然需要维护一个仅支持Python2.7的遗留项目,这种场景对开发者而言无异于一场噩梦。本文将带你用工程化的思维,在Deb…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...

基于Shapley值与随机森林的印度CPI通胀预测与特征重要性分析
1. 项目概述与核心价值在宏观经济预测领域,通胀预测的准确性直接关系到货币政策制定、市场预期管理乃至社会民生稳定。传统的计量经济学模型,如基于菲利普斯曲线的线性回归,虽然具有良好的可解释性,但在捕捉现实世界中复杂、非线性…...

D3KeyHelper终极指南:5分钟掌握暗黑3最强自动化工具
D3KeyHelper终极指南:5分钟掌握暗黑3最强自动化工具 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为《暗黑破坏神3…...

ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 [特殊字符]
ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 🚀 【免费下载链接】clojuredocs clojuredocs.org web app 项目地址: https://gitcode.com/gh_mirrors/cl/clojuredocs ClojureDocs作为社区驱动的Clojure文档网站,其性能优…...

免费岛屿设计终极指南:5分钟快速掌握Happy Island Designer
免费岛屿设计终极指南:5分钟快速掌握Happy Island Designer 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Animal Cros…...

别再只会用strlen了!CAPL脚本字符串处理实战:从CAN报文解析到日志生成
CAPL脚本字符串处理实战:从CAN报文解析到日志生成在汽车电子测试领域,CAPL脚本是工程师们不可或缺的利器。面对复杂的CAN总线数据流,字符串处理能力往往决定了脚本的效率和可靠性。本文将带您超越基础API的简单调用,探索如何组合运…...