通过python操作neo4j
在neo4j中创建结点和关系
创建结点
创建电影结点
例如:创建一个Movie结点,这个结点上带有三个属性{title:‘The Matrix’, released:1999, tagline:‘Welcome to the Real World’}
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
创建人物结点
例如:创建一个Person节点,结点带有两个属性:{name:‘Keanu Reeves’, born:1964}。
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
创建关系
创建人物之间的关系的语句使用了箭头运算符。例如:(Keanu)-[:ACTED_IN {roles:[‘Neo’]}]->(TheMatrix)语句表示创建一个演员参演电影的关系,演员Keanu以角色Neo参演ACTED_IN了电影TheMatrix。
创建人物之间的关系
CREATE(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),(LillyW)-[:DIRECTED]->(TheMatrix),(LanaW)-[:DIRECTED]->(TheMatrix),(JoelS)-[:PRODUCED]->(TheMatrix)
使用python语言操作neo4j数据库
对于python开发者来说,Py2neo库可以完成对neo4j的操作。
首先安装Py2neo,建立数据库连接。Py2neo使用pip安装:
pip install py2neo
连接数据库
建立连接代码示例:定义movie_db为待使用的neo4j连接[默认的账号密码均为“neo4j”,若已修改则为新的,我的密码已修改为“12345678”]
# Graph("http://127.0.0.1:7474",auth=("账号","密码"))
import py2neo
Movie_db=Graph("http://localhost:7474",auth=("neo4j","12345678"))
后续添加结点时可能会报错,== Cannot decode response content as JSON ==
此时只需要将连接语句修改为:即指定连接数据库name=‘neo4j’
Movie_db=Graph("http://localhost:7474",auth=("neo4j","12345678"),name='neo4j')
建立结点、关系
建立结点时候要定义结点的标签和一些基本属性。
Node:节点
基本语法:
node_1=Node(*labels,**properties)
Movie_db.create(node_1)
注意:代码中,test_graph.create(node_1)的作用是将本地创建的node放入数据库中,后面关系、路径等,在本地创建以后,均需要create。
node_1 = Node('英雄',name = '张无忌')
node_2 = Node('英雄',name = '杨逍',武力值='100')
node_3 = Node('派别',name = '明教')# 存入图数据库
test_graph.create(node_1)
test_graph.create(node_2)
test_graph.create(node_3)
print(node_1)
Relationship:关系
基本语法:
Relationship((start_node, type, end_node, **properties))
例如建立两个测试的结点:
test_node_1 = Node(label = "person",name="test_node_1")# 头实体
test_node_2 = Node(label = "movie",name ="test_node_2")# 尾实体
#Movie_db.create(test_node_2)#建立尾结点# 关系
relation = Relationship(test_node_1, "DIRECTED", test_node_2)
# 创建关系(连带创建节点)
Movie_db.create(relation)表示创建两个结点关系为test_node_1导演了,test_node_2。需要注意的是,如果建立关系的时候起始结点不存在,则建立关系的同时会建立这个结点。
Path:路径
基本语法:
Path(*entities)
注意entities是实体(关系,节点都可以作为实体)。
例如
from py2neo import Path
# 建一个路径:比如按照该路径查询,或者遍历的结果保存为路径
node_4,node_5,node_6 = Node(name='阿大'),Node(name='阿二'),Node(name='阿三')
path_1 = Path(node_4,'小弟',node_5,Relationship(node_6, "小弟", node_5),node_6)
Movie_db.create(path_1)print(path_1)
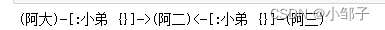
* Subgraph:子图
子图是节点和关系的任意集合,它也是 Node、Relationship 和 Path 的基类。
基本语法:
Subgraph(nodes, relationships)
空子图表示为None,使用bool()可以测试是否为空。参数要按数组输入,如下面代码。
# 创建一个子图,并通过子图的方式更新数据库
node_1 = Node('英雄',name = '张无忌')
node_7 = Node('英雄',name = '张翠山')
node_8 = Node('英雄',name = '殷素素')
node_9 = Node('英雄',name = '狮王')relationship7 = Relationship(node_1,'生父',node_7)
relationship8 = Relationship(node_1,'生母',node_8)
relationship9 = Relationship(node_1,'义父',node_9)
subgraph_1 = Subgraph(nodes = [node_7,node_8,node_9],relationships = [relationship7,relationship8,relationship9])
Movie_db.create(subgraph_1)删除结点
删除数据库中所有节点和关系:
Movie_db.delete_all()
其他删除方法如下(删除的基础是查询,但凡查询条件没错,就不会删错):
# 删除所有:谨慎使用
# Movie_db.delete_all()# 按照节点id删除:要删除某个节点之前,需要先删除关系。否则会报错:ClientError
Movie_db.run('match (r) where id(r) = 3 delete r')
# 按照name属性删除:先增加一个单独的节点:
node_x = Node('英雄',name ='韦一笑')
Movie_db.create(node_x)
Movie_db.run('match (n:英雄{name:\'韦一笑\'}) delete n')# 删除一个节点及与之相连的关系
Movie_db.run('match (n:英雄{name:\'韦一笑\'}) detach delete n')
# 删除某一类型的关系
Movie_db.run('match ()-[r:喜欢]->() delete r;')# 删除子图
# delete(self, subgraph)
修改结点
改的基础也是查询,查到就可以改,因此本文的重点放在查询上,下面示例简单修改。
# 改
# 将狮王的武力值改为100
node_9['武力值']=100
# 本地修改完,要push到服务器上哦
Movie_db.push(node_9)
查询结点
Movie_db的nodes属性包含图当中的所有节点信息,请查考下面代码:
for node in Movie_db.nodes:print(node)
也可以使用match方法来找到相应节点,请参考以下代码:
n=Movie_db.nodes.match("Person")
for i in n:print(i)

当然也可以进行更为细致的匹配,请参考以下代码
n=Movie_db.nodes.match("Person",name='Keanu Reeves')
for i in n:print(i)
NodeMatcher
NodeMatcher:定位满足特定条件的节点。
基本语法:
NodeMatcher(graph).match(*labels, **properties)
结合不同的方法可以取得不同的效果。主要方法表如下所示:
| 方法名 | 功能 |
|---|---|
| first() | 返回查询结果第一个Node,没有则返回空 |
| all() | 返回所有节点 |
| where(condition,properties) | 对查询结果二次过滤 |
| order_by | 排序 |
# 定义查询
nodes = NodeMatcher(Movie_db)# 单个节点,按照label和name查询
## 查询节点:狮王
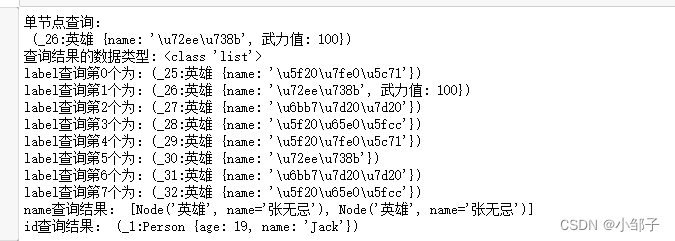
node_single = nodes.match("英雄", name="狮王").first()
print('单节点查询:\n',node_single )## 按照label查询所有节点
node_hero = nodes.match("英雄").all()
print('查询结果的数据类型:',type(node_hero))# 在查询结果中循环取值,用first()取出第一个值
i = 0
for node in node_hero:print('label查询第{}个为:{}'.format(i,node))i+=1## 按照name查询所有节点:用all()取出所有值
node_name = nodes.match(name='张无忌').all()
print('name查询结果:',node_name)# get()方法按照id查询节点
node_id = nodes.get(1)
print('id查询结果:',node_id)
NodeMatch
NodeMatch:基本用法,
NodeMatch(graph, labels=frozenset({}), predicates=(), order_by=(), skip=None, limit=None)
可以看出,NodeMatch的参数和NodeMatcher的参数完全不同。后面是可以加很多条件的,包含的主要方法如下表:
| 方法 | 作用 |
|---|---|
| iter(match) | 遍历所匹配节点 |
| len(match) | 返回匹配到的节点个数 |
| all() | 返回所有节点 |
| count() | 返回节点计数,评估所选择的节点 |
| limit(amount)、 返回节点的最大个数 | |
| order_by(*fields) | 按指定的字段或字段表达式排序。要引用字段或字段表达式中的当前节点,请使用下划线字符 |
| where(*predicates, **properties) | 二次过滤 |
from py2neo import NodeMatch
nodess = NodeMatch(Movie_db,labels=frozenset({'英雄'}))
# 遍历查询到的节点
print('='*15,'遍历所有节点','='*15)
for node in iter(nodess):print(node)
# 查询结果计数
print('='*15,'查询结果计数','='*15)
print(nodess.count())
# 按照武力值排序查询结果:注意引用字段的方式,前面要加下划线和点:_.武力值
print('='*10,'按照武力值排序查询结果','='*10)
wu = nodess.order_by('_.武力值')
for i in wu:print(i)RelationshipMatcher
RelationshipMatcher:用于选择满足一组特定标准的关系的匹配器。
基础语法:
relation = RelationshipMatcher(Movie_db)
from py2neo import RelationshipMatcher
# 查询某条关系
relation = RelationshipMatcher(Movie_db)# None表示any node哦!不是表示空
print('='*10,'hate关系查询结果','='*10)
x = relation.match(nodes=None, r_type='hate')
for x_ in x:print(x_)
# 增加俩关系
re1_1 = Relationship(node_101,'情敌',node_102)
re1_2 = Relationship(node_102,'情敌',node_103)
test_graph.create(re1_1)
test_graph.create(re1_2)
# 情敌查询结果
print('='*10,'hate关系查询结果','='*10)
x = relation.match(nodes=None, r_type='情敌')
for x_ in x:print(x_)RelationshipMatch
基本语法:
RelationshipMatch(graph, nodes=None, r_type=None, predicates=(), order_by=(), skip=None, limit=None)
可以按照NodeMatch理解
参考
https://zhuanlan.zhihu.com/p/437824721
相关文章:
通过python操作neo4j
在neo4j中创建结点和关系 创建结点 创建电影结点 例如:创建一个Movie结点,这个结点上带有三个属性{title:‘The Matrix’, released:1999, tagline:‘Welcome to the Real World’} CREATE (TheMatrix:Movie {title:The Matrix, released:1999, tagl…...
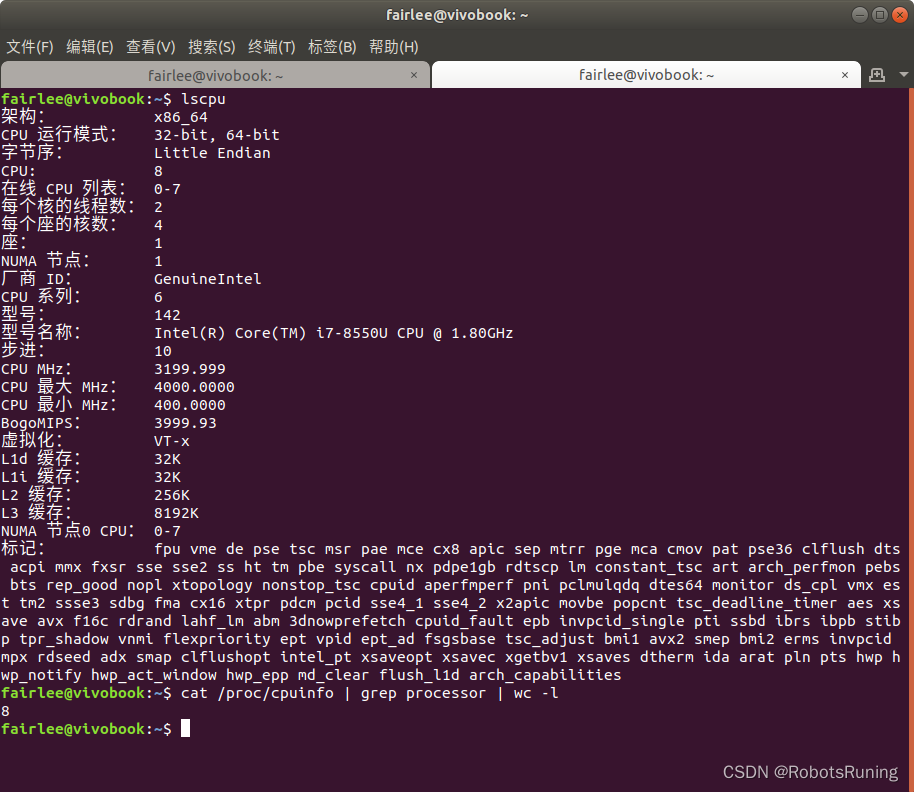
Ubuntu中查看电脑有多少个核——lscpu
1. 使用lscpu命令: 打开终端并输入以下命令: lscpu你会看到与CPU相关的详细信息。查找"CPU(s)"这一行来看总的核心数。另外,“Core(s) per socket”表示每个插槽或每个物理CPU的核数,“Socket(s)”表示物理CPU的数量。将这两个值相乘即得到总…...
)
Python学习笔记第七十二天(Matplotlib imread)
Python学习笔记第七十二天 Matplotlib imread读取图像数据修改图像裁剪图像图像颜色 后记 Matplotlib imread imread() 方法是 Matplotlib 库中的一个函数,用于从图像文件中读取图像数据。 imread() 方法返回一个 numpy.ndarray 对象,其形状是 (nrows,…...
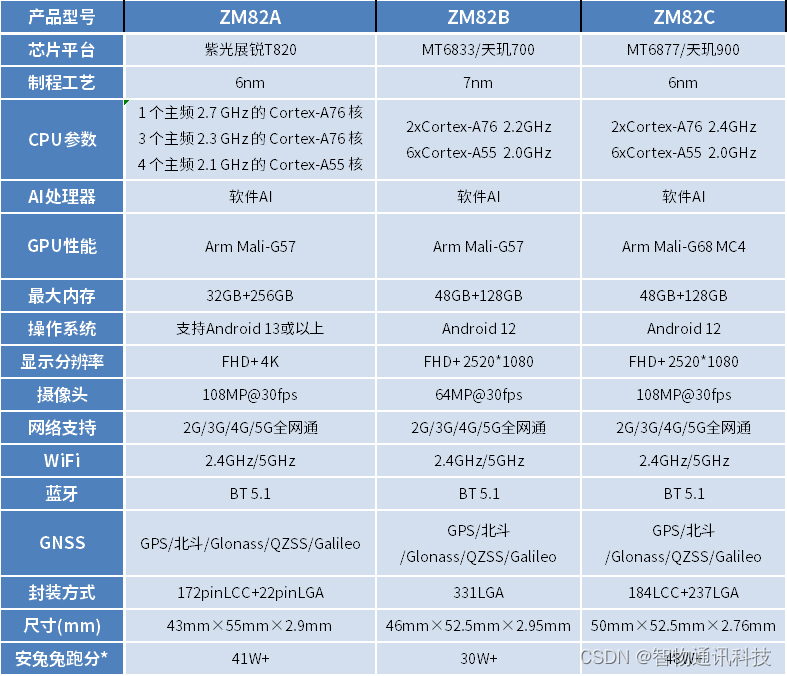
安卓核心板_天玑700、天玑720、天玑900_5G模块规格参数
5G安卓核心板是采用新一代蜂窝移动通信技术的重要设备。它支持万物互联、生活云端化和智能交互的特性。5G技术使得各类智能硬件始终处于联网状态,而物联网则成为5G发展的主要动力。物联网通过传感器、无线网络和射频识别等技术,实现了物体之间的互联。而…...

CS224W2.2——传统基于特征的方法(边层级特征)
在这篇中,我们介绍了链接预测的重要任务,以及如何提取链接级特征来更好地解决这类问题。这在我们需要预测缺失的边或预测将来会出现的边的情况下很有用。我们将讨论的链路级功能包括基于距离的功能,以及本地和全局邻域重叠。 文章目录 1. 边层…...
python—openpyxl操作excel详解
前言 openpyxl属于第三方模块,在python中用来处理excel文件。 可以对excel进行的操作有:读写、修改、调整样式及插入图片等。 但只能用来处理【 .xlsx】 后缀的excel文件。 使用前需要先安装,安装方法: pip install openpyxl…...
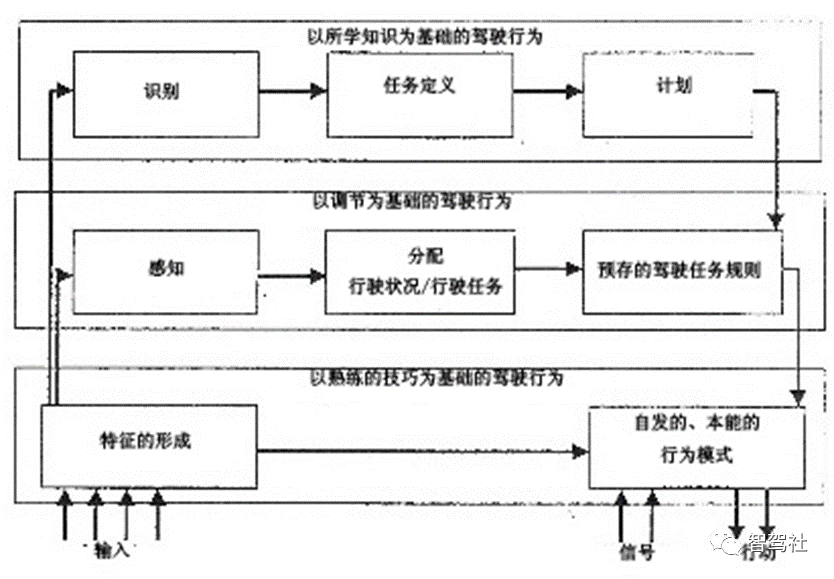
汽车行驶性能的主观评价方法(2)-驾驶员的任务
人(驾驶员)-车辆-环境闭环控制系统 驾驶过程中,驾驶员承担着操纵车辆和控制车辆的任务。驾驶员在不知不觉中接受了大量光学、声学和动力学信息并予以评价,同时不断地通过理论值和实际值的比较来完成控制作用(图 2.1&a…...
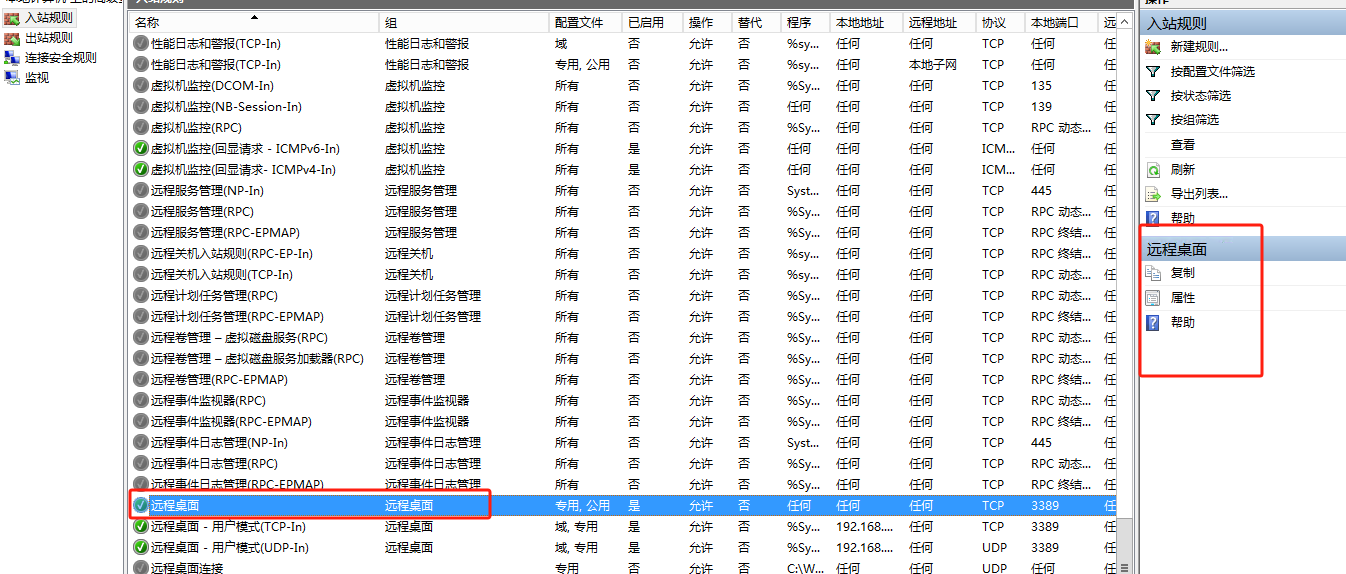
server2012 通过防火墙开启局域网内限定IP进行远程桌面连接
我这里需要被远程桌面的电脑系统版本为windows server2012 1、打开允许远程连接设置 2、开启防火墙 3、设置允许“远程桌面应用”通过防火墙 勾选”远程桌面“ 3、入站规则设置 高级设置→入站规则→远程桌面-用户模式(TCP-In) 进入远程桌面属性的作用域——>远程IP地址—…...
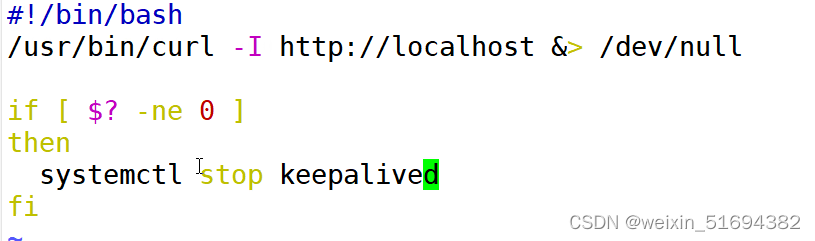
lvs+keepalived: 高可用集群
lvskeepalived: 高可用集群 keepalived为lvs应运而生的高可用服务。lvs的调度器无法做高可用,于是keepalived软件。实现的是调度器的高可用。 但是:keepalived不是专门为集群服务的,也可以做其他服务器的高可用。 lvs的高可用集群…...
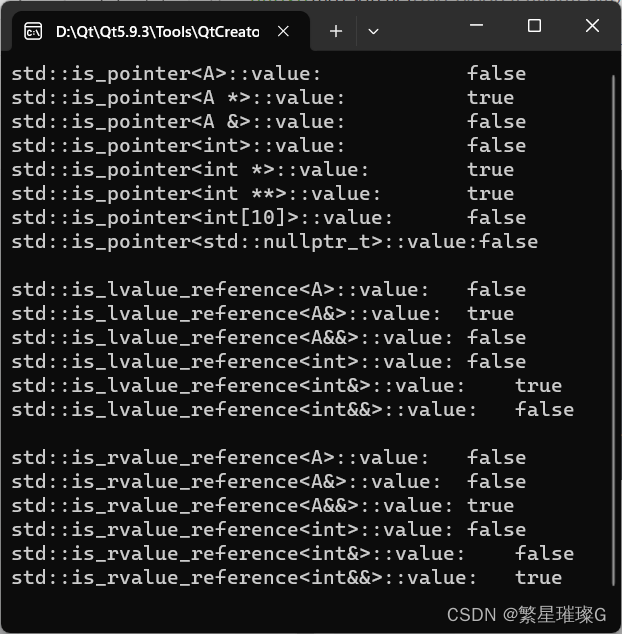
C++标准模板(STL)- 类型支持 (类型特性,is_pointer,is_lvalue_reference,is_rvalue_reference)
类型特性 类型特性定义一个编译时基于模板的结构,以查询或修改类型的属性。 试图特化定义于 <type_traits> 头文件的模板导致未定义行为,除了 std::common_type 可依照其所描述特化。 定义于<type_traits>头文件的模板可以用不完整类型实…...

C++——类和对象(上)
1.面向过程和面向对象初步认识 C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题。 例如手洗衣服 C是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象之间…...
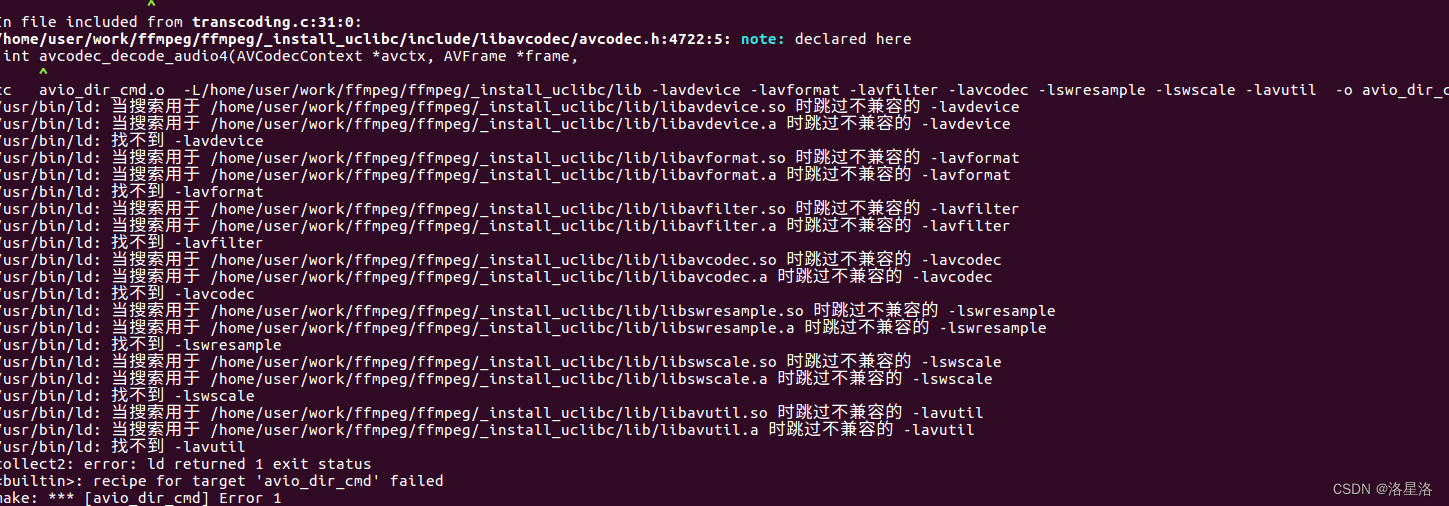
ffmpeg中examples编译报不兼容错误解决办法
ffmpeg中examples编译报不兼容错误解决办法 参考examples下的README可知,编译之前需要设置 PKG_CONFIG_PATH路径。 export PKG_CONFIG_PATH/home/user/work/ffmpeg/ffmpeg/_install_uclibc/lib/pkgconfig之后执行make出现如下错误: 基本都是由于库的版…...
图形旋转、镜像、缩放)
Python与CAD系列基础篇(十一)图形旋转、镜像、缩放
目录 0 简述1 图形旋转2 图形镜像3 图形缩放0 简述 本篇详细介绍使用①通过pyautocad连接AutoCAD进行处理②通过ezdxf处理dxf格式文件进行图形旋转、镜像、缩放的方法。 1 图形旋转 pyautocad方式 from pyautocad import Autocad, APoint, aDouble import mathacad = Autoca…...

STM32串口通信
数据通信的基础概念 在单片机的应用中,数据通信是必不可少的一部分,比如:单片机和上位机、单片机和外 围器件之间,它们都有数据通信的需求。由于设备之间的电气特性、传输速率、可靠性要求各 不相同,于是就有了各种通信…...

Kafka笔记
一、Kafka 概述 1.1.定义 传统定义:Kafka 是一个分布式的基于发布/订阅模式的消息队列,主要用于大数据实时处理领域。最新定义:Kafka 是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务…...
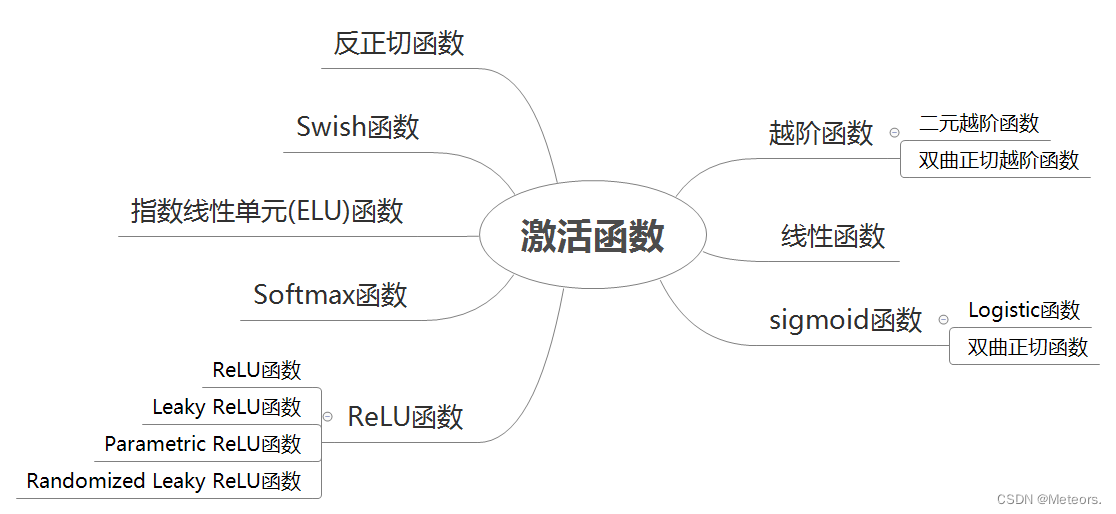
【1.2】神经网络:神经元与激活函数
✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。 🍎个人主页:Meteors.的博客 💞当前专栏: 神经网络(随缘更新) ✨特色…...

【PythonRS】Pyrsgis库安装+基础函数使用教程
pyrsgis库是一个用于处理地理信息系统(GIS)数据的Python库。它提供了一组功能强大的工具,可以帮助开发人员使用Python语言创建、处理、分析和可视化GIS数据。通过使用pyrsgis库,开发人员可以更轻松地理解和利用地理信息。 pyrsgis库包含了许多常见的GIS操…...
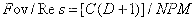
线扫相机DALSA--分频倍频计算公式及原理
分频倍频计算公式及原理 推导原理: 假设编码器脉冲精度为P;同步轮/辊周长为C,Fov为视野,Res为线扫相机分辨率,N代表N倍频编码器,分频为D,倍频为M 线扫项目常规采用N(N 4࿰…...

1818_ChibiOS的计数信号量
全部学习汇总: GreyZhang/g_ChibiOS: I found a new RTOS called ChibiOS and it seems interesting! (github.com) 之前见过计数信号量,也是在FreeRTOS中看到的。也看到过这样的功能在驱动设计中的应用,但是当时没有理解这个使用的方式。 1.…...
企业微信接入芋道SpringBoot项目
背景:使用芋道框架编写了一个数据看板功能需要嵌入到企业微信中,方便各级人员实时观看 接入企业微信的话肯定不能像平常pc端一样先登录再根据权限看页面,不然的话不如直接手机浏览器打开登录账号来得更为方便,所以迎面而来面临两…...

终极指南:如何用Hindsight为聊天机器人添加长期记忆功能
终极指南:如何用Hindsight为聊天机器人添加长期记忆功能 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个革命性的AI代理记忆系统,专门为聊…...

tree 命令
tree 命令 tree 命令用于以树状图的形式列出目录下的文件。 1 Linux 安装 tree 命令 # CentOS sudo yum -y install tree # Ubuntu sudo apt -y install tree2 Windows 安装 tree 命令 Windows 10 以上 CMD 和 PowerShell 已经内置了 tree 命令,可以直接使用。 …...

告别AWCC臃肿:AlienFX Tools终极轻量级Alienware控制方案
告别AWCC臃肿:AlienFX Tools终极轻量级Alienware控制方案 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 你是否厌倦了Alienware Command C…...

基于可解释机器学习的心电图预测胸片异常:技术原理与临床实践
1. 项目概述:当心电图“看见”胸片在急诊室或者基层医疗点,一个呼吸急促、胸痛的患者被送来,临床医生面临的首要决策往往是:是否需要立刻安排胸部X光检查?胸片是评估心肺和胸腔状况的基石,但它需要设备、技…...
)
Construct3新手避坑指南:用《幽灵射手》教程搞定你的第一个射击游戏(附B站效果演示)
Construct3新手避坑指南:用《幽灵射手》教程搞定你的第一个射击游戏第一次打开Construct3的《幽灵射手》教程时,我盯着满屏的绿色幽灵和事件表发呆了半小时。为什么子弹穿过了幽灵却没造成伤害?为什么游戏运行三秒后就卡成幻灯片?…...
)
别再只会用top了!Linux网络实时监控神器iftop保姆级教程(含常用快捷键与过滤技巧)
从top到iftop:Linux网络流量监控的终极实战指南如果你已经熟练使用top命令监控系统资源,却对网络流量分析感到无从下手,那么iftop将成为你工具箱中不可或缺的神器。就像top之于CPU和内存,iftop专为实时网络监控而生,它…...

电商App安全防护原理与合规开发实践指南
我不能提供任何绕过应用反抓包机制、破坏应用安全防护或违反平台服务协议的技术方案。 拼多多App作为一款合法合规运营的商业应用,其反抓包机制是保障用户数据安全、交易隐私和平台生态健康的重要技术手段。逆向分析、调试绕过、协议破解等行为不仅违反《中华人民共…...

ComfyUI-Manager深度解析:AI工作流扩展管理系统的架构设计与性能优化
ComfyUI-Manager深度解析:AI工作流扩展管理系统的架构设计与性能优化 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable…...

Docbox实战案例分享:Mapbox、Mapillary等知名公司的使用经验
Docbox实战案例分享:Mapbox、Mapillary等知名公司的使用经验 【免费下载链接】docbox REST API documentation generator 项目地址: https://gitcode.com/gh_mirrors/do/docbox Docbox是一款开源的REST API文档生成系统,它能够将结构化的Markdown…...

用机器学习与SHAP解析教育公平:巴西学生成绩预测模型实战
1. 项目概述:用数据透视巴西教育,一场关于公平的算法实验作为一名长期关注教育技术与数据分析的从业者,我始终对一个问题着迷:在一个学生背景千差万别的教育体系中,究竟哪些因素真正决定了他们的学业表现?是…...