基于LSTM encoder-decoder模型实现英文转中文的翻译机器
前言
神经网络机器翻译(NMT, neuro machine tranlation)是AIGC发展道路上的一个重要应用。正是对这个应用的研究,发展出了注意力机制,在此基础上产生了AIGC领域的霸主transformer。我们今天先把注意力机制这些东西放一边,介绍一个对机器翻译起到重要里程碑作用的模型:LSTM encoder-decoder模型(sutskever et al. 2014)。根据这篇文章的描述,这个模型不需要特别的优化,就可以取得超过其他NMT模型的效果,所以我们也来动手实现一下,看看是不是真的有这么厉害。
模型
原文作者采用了4层LSTM模型,每层有1000个单元(每个单元有输入门,输出门,遗忘门和细胞状态更新共计4组状态),采用1000维单词向量,纯RNN部分,就有64M参数。同时,在encoder的输出,和decoder的输出后放一个长度为80000的softmax层(因为论文的输出字典长80000),用于softmax的参数量为320M。整个模型共计320M + 64M = 384M。该模型用了8GPU的服务器训练了10天。
模型大概长这样:

按照现在的算力价格,用8张4090的主机训练每小时要花20多块钱,训练一轮下来需要花费小5000,笔者当然没有这么土豪,所以我们会使用一个参数量小得多的模型,主要为了记录整个搭建过程使用到的工具链和技术。另外,由于笔者使用了一个预训练的词向量库,包含了中英文单词共计128万多条,其中中文90多万,英文30多万,要像论文中一样用一个超大的softmax来预测每个词的概率并不现实,因此先使用一个linear层再加上relu来简化,加快训练过程,只求能看到收敛。
笔者的模型看起来像这样:

该模型的主要参数如下:
词向量维度:300
LSTM隐藏层个数:600
LSTM层数:4
linear层输入:600
linear层输出:300
模型参数个数如下为:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Seq2Seq [1, 11, 300] --
├─Encoder: 1-1 [1, 300] --
│ └─LSTM: 2-1 [1, 10, 600] 10,819,200
│ └─Linear: 2-2 [1, 300] 180,300
│ └─ReLU: 2-3 [1, 300] --
├─Decoder: 1-2 [1, 11, 300] --
│ └─LSTM: 2-4 [1, 11, 600] 10,819,200
│ └─Linear: 2-5 [1, 11, 300] 180,300
│ └─ReLU: 2-6 [1, 11, 300] --
==========================================================================================
Total params: 21,999,000
Trainable params: 21,999,000
Non-trainable params: 0
Total mult-adds (M): 227.56
==========================================================================================
Input size (MB): 0.02
Forward/backward pass size (MB): 0.13
Params size (MB): 88.00
Estimated Total Size (MB): 88.15
==========================================================================================
如果大家希望了解LSTM层的10,819,200个参数如何计算出来,可以参考pytorch源码 pytorch/torch/csrc/api/src/nn/modules/rnn.cpp中方法void RNNImplBase::reset()的实现。笔者如果日后有空也可能会写一写。
3 单词向量及语料
3.1 语料
先说语料,NMT需要大量的平行语料,语料可以从这里获取。另外有个语料天涯网站大全分享给大家。
3.2 词向量
首先需要对句子进行分词,中英文都需要做分词。中文分词工具本例采用jieba,可直接安装。
$ pip install jieba
...
$ python
Python 3.11.6 (tags/v3.11.6:8b6ee5b, Oct 2 2023, 14:57:12) [MSC v.1935 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> for token in jieba.cut("我爱踢足球!", cut_all=False):
... print(token)
...
我
爱
踢足球
!
英文分词采用nltk,安装之后,需要下载一个分词模型。
$ pip install nltk
...
$ python
Python 3.11.6 (tags/v3.11.6:8b6ee5b, Oct 2 2023, 14:57:12) [MSC v.1935 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>> nltk.download("punkt")
...
>>> from nltk import word_tokenize
>>> word_tokenize('i love you')
['i', 'love', 'you']
国内有墙,一般下载不了,所以可以到这里找到punkt文件并下载,解压到~/nltk_data/tokenizers/下边。
3.3 加载语料代码
import xml.etree.ElementTree as ETclass TmxHandler():def __init__(self):self.tag=Noneself.lang=Noneself.corpus={}def handleStartTu(self, tag):self.tag=tagself.lang=Noneself.corpus={}def handleStartTuv(self, tag, attributes):if self.tag == 'tu':if attributes['{http://www.w3.org/XML/1998/namespace}lang']:self.lang=attributes['{http://www.w3.org/XML/1998/namespace}lang']else:raise Exception('tuv element must has a xml:lang attribute')self.tag = tagelse:raise Exception('tuv element must go under tu, not ' + tag)def handleStartSeg(self, tag, elem):if self.tag == 'tuv':self.tag = tagif self.lang:if elem.text:self.corpus[self.lang]=elem.textelse:raise Exception('lang must not be none')else:raise Exception('seg element must go under tuv, not ' + tag)def startElement(self, tag, attributes, elem):if tag== 'tu':self.handleStartTu(tag)elif tag == 'tuv':self.handleStartTuv(tag, attributes)elif tag == 'seg':self.handleStartSeg(tag, elem)def endElem(self, tag):if self.tag and self.tag != tag:raise Exception(self.tag + ' could not end with ' + tag)if tag == 'tu':self.tag=Noneself.lang=Noneself.corpus={}elif tag == 'tuv':self.tag='tu'self.lang=Noneelif tag == 'seg':self.tag='tuv'def parse(self, filename):for event, elem in ET.iterparse(filename, events=('start','end')):if event == 'start':self.startElement(elem.tag, elem.attrib, elem)elif event == 'end':if elem.tag=='tu':yield self.corpusself.endElem(elem.tag)
3.4 句子转词向量代码
from gensim.models import KeyedVectors
import torch
import jieba
from nltk import word_tokenize
import numpy as npclass WordEmbeddingLoader():def __init__(self):passdef load(self, fname):self.model = KeyedVectors.load_word2vec_format(fname)def get_embeddings(self, word:str):if self.model:try:return self.model.get_vector(word)except(KeyError):return Noneelse:return Nonedef get_scentence_embeddings(self, scent:str, lang:str):embeddings = []ws = []if(lang == 'zh'):ws = jieba.cut(scent, cut_all=False)elif lang == 'en':ws = word_tokenize(scent)else:raise Exception('Unsupported language ' + lang)for w in ws:embedding = self.get_embeddings(w.lower())if embedding is None:embedding = np.zeros(self.model.vector_size)embedding = torch.from_numpy(embedding).float()embeddings.append(embedding.unsqueeze(0))return torch.cat(embeddings, dim=0)
4 模型代码实现
4.1 encoder
import torch.nn as nnclass Encoder(nn.Module):def __init__(self, device, embeddings=300, hidden_size=600, num_layers=4):super().__init__()self.device = deviceself.hidden_layer_size = hidden_sizeself.n_layers = num_layersself.embedding_size = embeddingsself.lstm = nn.LSTM(embeddings, hidden_size, num_layers, batch_first=True)self.linear = nn.Linear(hidden_size, embeddings)self.relu = nn.ReLU()def forward(self, x):# x: [batch size, seq length, embeddings]# lstm_out: [batch size, x length, hidden size]lstm_out, (hidden, cell) = self.lstm(x)# linear input is the lstm output of the last wordlineared = self.linear(lstm_out[:,-1,:].squeeze(1))out = self.relu(lineared)# hidden: [n_layer, batch size, hidden size]# cell: [n_layer, batch size, hidden size]return out, hidden, cell
4.2 decoder
import torch.nn as nnclass Decoder(nn.Module):def __init__(self, device, embedding_size=300, hidden_size=900, num_layers=4):super().__init__()self.device = deviceself.hidden_layer_size = hidden_sizeself.n_layers = num_layersself.embedding_size = embedding_sizeself.lstm = nn.LSTM(embedding_size, hidden_size, num_layers, batch_first=True)self.linear = nn.Linear(hidden_size, embedding_size)self.relu = nn.ReLU()def forward(self, x, hidden_in, cell_in):# x: [batch_size, x length, embeddings]# hidden: [n_layers, batch size, hidden size]# cell: [n_layers, batch size, hidden size]# lstm_out: [seq length, batch size, hidden size]lstm_out, (hidden,cell) = self.lstm(x, (hidden_in, cell_in))# prediction: [seq length, batch size, embeddings]prediction=self.relu(self.linear(lstm_out))return prediction, hidden, cell
4.3 encoder-decoder
接下来把encoder和decoder串联起来。
import torch
import encoder as enc
import decoder as dec
import torch.nn as nn
import timeclass Seq2Seq(nn.Module):def __init__(self, device, embeddings, hiddens, n_layers):super().__init__()self.device = deviceself.encoder = enc.Encoder(device, embeddings, hiddens, n_layers)self.decoder= dec.Decoder(device, embeddings, hiddens, n_layers)self.embeddings = self.encoder.embedding_sizeassert self.encoder.n_layers == self.decoder.n_layers, "Number of layers of encoder and decoder must be equal!"assert self.decoder.hidden_layer_size==self.decoder.hidden_layer_size, "Hidden layer size of encoder and decoder must be equal!"# x: [batches, x length, embeddings]# x is the source scentences# y: [batches, y length, embeddings]# y is the target scentencesdef forward(self, x, y):# encoder_out: [batches, n_layers, embeddings]# hidden, cell: [n layers, batch size, embeddings]encoder_out, hidden, cell = self.encoder(x)# use encoder output as the first word of the decode sequencedecoder_input = torch.cat((encoder_out.unsqueeze(0), y), dim=1)# predicted: [batches, y length, embeddings]predicted, hidden, cell = self.decoder(decoder_input, hidden, cell)return predicted
5 模型训练
5.1 训练代码
def do_train(model:Seq2Seq, train_set, optimizer, loss_function):step = 0model.train()# seq: [seq length, embeddings]# labels: [label length, embeddings]for seq, labels in train_set:step = step + 1# ignore the last word of the label scentence# because it is to be predictedlabel_input = labels[:-1].unsqueeze(0)# seq_input: [1, seq length, embeddings]seq_input = seq.unsqueeze(0)# y_pred: [1, seq length + 1, embeddings]y_pred = model(seq_input, label_input)# single_loss = loss_function(y_pred.squeeze(0), labels.to(self.device))single_loss = loss_function(y_pred.squeeze(0), labels)optimizer.zero_grad()single_loss.backward()optimizer.step()print_steps = 100if print_steps != 0 and step%print_steps==1:print(f'[step: {step} - {time.asctime(time.localtime(time.time()))}] - loss:{single_loss.item():10.8f}')def train(device, model, embedding_loader, corpus_fname, batch_size:int, batches: int):reader = corpus_reader.TmxHandler()loss = torch.nn.MSELoss()# summary(model, input_size=[(1, 10, 300),(1,10,300)])optimizer = torch.optim.SGD(model.parameters(), lr=0.01)generator = reader.parse(corpus_fname)for _b in range(batches):batch = []try:for _c in range(batch_size):try:corpus = next(generator)if 'en' in corpus and 'zh' in corpus:en = embedding_loader.get_scentence_embeddings(corpus['en'], 'en').to(device)zh = embedding_loader.get_scentence_embeddings(corpus['zh'], 'zh').to(device)batch.append((en,zh))except (StopIteration):breakfinally:print(time.localtime())print("batch: " + str(_b))do_train(model, batch, optimizer, loss)torch.save(model, "./models/seq2seq_" + str(time.time()))if __name__=="__main__":# device = torch.device('cuda')device = torch.device('cpu')embeddings = 300hiddens = 600n_layers = 4embedding_loader = word2vec.WordEmbeddingLoader()print("loading embedding")# a full vocabulary takes too long to load, a baby vocabulary is used for demo purposeembedding_loader.load("../sgns.merge.word.toy")print("load embedding finished")# if there is an existing model, load the existing model from file# model_fname = "./models/_seq2seq_1698000846.3281412"model_fname = Nonemodel = Noneif not model_fname is None:print('loading model from ' + model_fname)model = torch.load(model_fname, map_location=device)print('model loaded')else:model = Seq2Seq(device, embeddings, hiddens, n_layers).to(device)train(device, model, embedding_loader, "../News-Commentary_v16.tmx", 1000, 100)
5.2 使用CPU进行训练
让我们先来体验一下CPU的龟速训练。下图是每100句话的训练输出。每次打印的间隔大约为2-3分钟。
[step: 1 - Thu Oct 26 05:14:13 2023] - loss:0.00952744
[step: 101 - Thu Oct 26 05:17:11 2023] - loss:0.00855174
[step: 201 - Thu Oct 26 05:20:07 2023] - loss:0.00831730
[step: 301 - Thu Oct 26 05:23:09 2023] - loss:0.00032693
[step: 401 - Thu Oct 26 05:25:55 2023] - loss:0.00907284
[step: 501 - Thu Oct 26 05:28:55 2023] - loss:0.00937218
[step: 601 - Thu Oct 26 05:32:00 2023] - loss:0.00823146
5.3 使用GPU进行训练
如果把main函数的第一行中的"cpu"改成“cuda”,则可以使用显卡进行训练。笔者使用的是一张GTX1660显卡,打印间隔缩短为15秒。
[step: 1 - Thu Oct 26 06:38:45 2023] - loss:0.00955237
[step: 101 - Thu Oct 26 06:38:50 2023] - loss:0.00844441
[step: 201 - Thu Oct 26 06:38:56 2023] - loss:0.00820994
[step: 301 - Thu Oct 26 06:39:01 2023] - loss:0.00030389
[step: 401 - Thu Oct 26 06:39:06 2023] - loss:0.00896622
[step: 501 - Thu Oct 26 06:39:11 2023] - loss:0.00929985
[step: 601 - Thu Oct 26 06:39:17 2023] - loss:0.00813591
相关文章:
基于LSTM encoder-decoder模型实现英文转中文的翻译机器
前言 神经网络机器翻译(NMT, neuro machine tranlation)是AIGC发展道路上的一个重要应用。正是对这个应用的研究,发展出了注意力机制,在此基础上产生了AIGC领域的霸主transformer。我们今天先把注意力机制这些东西放一边,介绍一个对机器翻译…...

世界前沿技术发展报告2023《世界航空技术发展报告》(四)无人机技术
(四)无人机技术 1.无人作战飞机1.1 美国空军披露可与下一代战斗机编组作战的协同式无人作战飞机项目1.2 俄罗斯无人作战飞机取得重要进展 2.支援保障无人机2.1 欧洲无人机项目通过首个里程碑2.2 美国海军继续开展MQ-25无人加油机测试工作 3.微小型无人机…...

【JAVA学习笔记】48 - 八大常用Wrapper类(包装类)
一、包装类 1.针对八种基本定义相应的引用类型一包装类 2.有了类的特点,就可以调用类中的方法。 黄色背景的表示父类是Number 二、包装类和基本数据的转换 演示包装类和基本数据类型的相互转换,这里以int和Integer演示。 1.jdk5前的手动装箱和拆箱方…...

学习笔记:Splay
Splay 定义 Splay 树, 或 伸展树,是一种平衡二叉查找树,它通过 Splay/伸展操作 不断将某个节点旋转到根节点,使得整棵树仍然满足二叉查找树的性质,能够在均摊 O ( log n ) O(\log n) O(logn) 时间内完成插入,查…...
JAVA中的垃圾回收器(1)
一)垃圾回收器概述: 1.1)按照线程数来区分: 串行回收指的是在同一时间端内只允许有一个CPU用于执行垃圾回收操作,此时工作线程被暂停,直至垃圾回收工作结束,在诸如单CPU处理器或者较小的应用内存等硬件平台不是特别优越的场合,出行…...
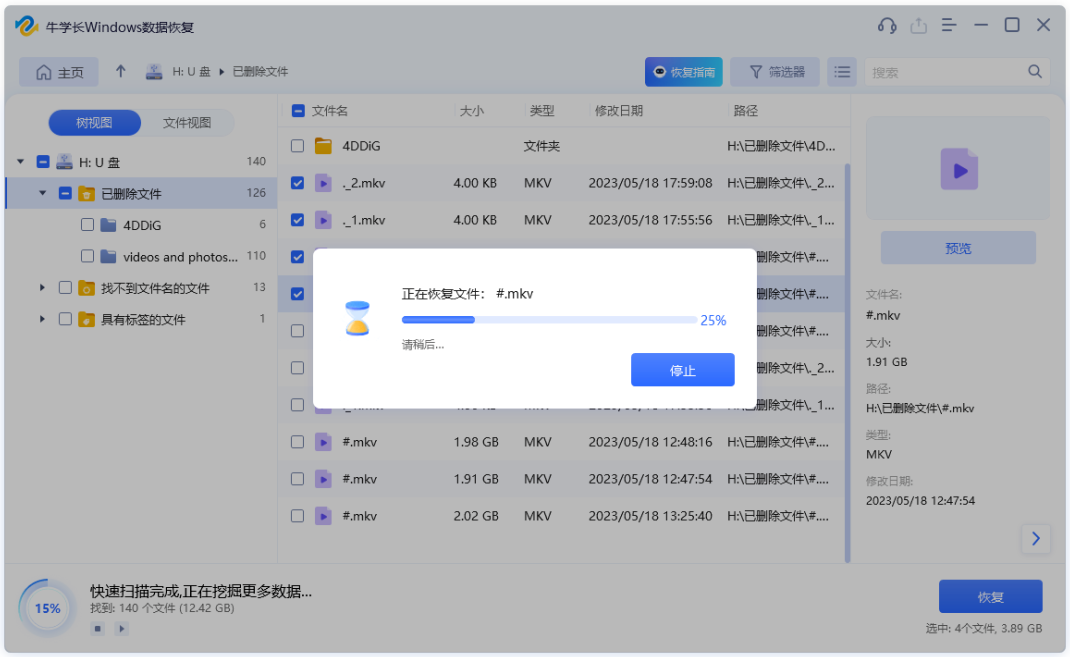
Windows 10/11如何恢复永久删除的文件?
数据丢失在我们的工作生活中经常发生。当你决定清理硬盘或U盘时,你会删除一些文件夹或文件。如果你通过右键单击删除文件,则可以很容易从回收站恢复已删除的文件。但是,如果你按Shift Delete键、清空回收站或删除大于8998MB的大文件夹&#…...
)
【Shell 系列教程】shell介绍(一)
文章目录 前言Shell 脚本Shell 环境第一个shell脚本运行 Shell 脚本有两种方法:1、作为可执行程序2、作为解释器参数 前言 Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。 Sh…...

考研数学中放缩法和无穷项求和
考研数学放缩法和无穷项求和 放缩法专题例子1例子2例子3例子4例子5 放缩法专题 本文以例子为切入,对一些常用的放缩方法进行总结归纳,以期让读者对相关问题有一定的应对手段。 例子1 问题:2020年高数甲,选择题第1题。 lim …...

计算机网络常识
文章目录 1、HTTP2、HTTP状态码1xx(信息性状态码):2xx(成功状态码):3xx(重定向状态码):4xx(客户端错误状态码):5xx(服务器…...
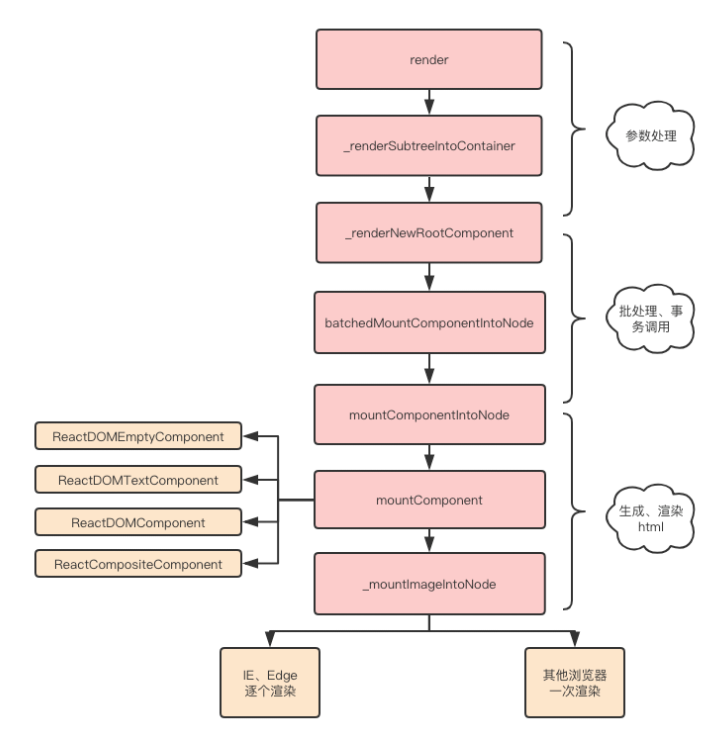
React之Jsx如何转换成真实DOM
一、是什么 react通过将组件编写的JSX映射到屏幕,以及组件中的状态发生了变化之后 React会将这些「变化」更新到屏幕上 在前面文章了解中,JSX通过babel最终转化成React.createElement这种形式,例如: <div>< img src&q…...

OpenCV学习(六)——图像算术运算(加法、融合与按位运算)
图像算术运算 6. 图像算术运算6.1 图像加法6.2 图像融合6.3 按位运算 6. 图像算术运算 6.1 图像加法 OpenCV加法是饱和运算Numpy加法是模运算 import cv2 import numpy as npx np.uint8([250]) y np.uint8([10])# OpenCV加法 print(cv2.add(x, y)) # 25010 260 > 255…...

如何做好一次代码审查,什么样是一次优秀的代码审查,静态代码分析工具有哪些
代码审查是确保代码质量、提升团队协作效率、分享知识和技能的重要过程。以下是进行优秀代码审查的一些指南: 如何做好代码审查: 理解代码的背景和目的: 在开始审查前,确保你了解这次提交的背景和目的,这有助于更准确…...

【Android】一个contentResolver引起的内存泄漏问题分析
长时间的压力测试后,系统发生了重启,报错log如下 JNI ERROR (app bug): global reference table overflow (max51200) global reference table overflow的log 08-08 04:11:53.052912 973 3243 F zygote64: indirect_reference_table.cc:256] JNI ER…...
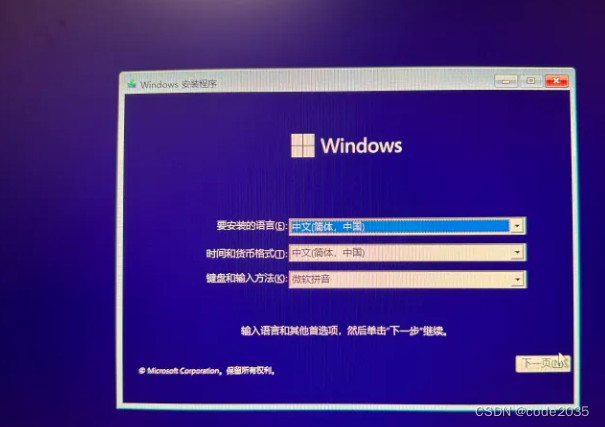
2023年正版win10/win11系统安装教学(纯净版)
第一步:准备一个8G容量以上的U盘。 注意,在制作系统盘时会格式化U盘,所以最好准备个空U盘,防止资料丢失。 第二步:制作系统盘。 安装win10 进入windows官网 官网win10下载地址:https://www.microsoft.c…...

系统架构设计师-第11章-未来信息综合技术-软考学习笔记
未来信息综合技术是指近年来新技术发展而提出的一些新概念、新知识、新产品 信息物理系统(CPS ) ,人工智能( A l) ,机器人、边缘计算、数字孪生、云计算和大数据等技术 信息物理系统技术概述 信息物理系统的概念 信息物理系统是控制系统、嵌入式系统…...
方法详解)
Python __new__()方法详解
__new__() 是一种负责创建类实例的静态方法,它无需使用 staticmethod 装饰器修饰,且该方法会优先 __init__() 初始化方法被调用。 一般情况下,覆写 __new__() 的实现将会使用合适的参数调用其超类的 super().__new__(),并在返回之…...

虹科 | 解决方案 | 汽车示波器 索赔管理方案
索赔管理 Pico汽车示波器应用于主机厂/供应商与服务店/4S店的协作,实现产品索赔工作的高效管理;同时收集的故障波形数据,便于日后的产品优化和改进 故障记录 在索赔申请过程中,Pico汽车示波器的数据记录功能可以用于捕捉故障时的…...

详解Jmeter中的BeanShell脚本
BeanShell是一种完全符合Java语法规范的脚本语言,并且又拥有自己的一些语法和方法,所以它和java是可以无缝衔接的,学了Java的一些基本语法后,就可以来在Jmeter中写写BeanShell脚本了 在利用jmeter进行接口测试或者性能测试的时候,…...

前端和后端 优化
1.前端资源优化 1.1 html结构优化 保证简洁、清晰的html结构,减少或避免多余的html标签 使用HTML5的web语义化标签,结构清晰且利于seo css文件在head中引入,js文件放在body底部引入,这样做可以防止阻塞。另外如果有需要提前加载的…...

C++编译与运行:其二、编译期和运行期的区别
C的编译分为四步,最终生成一个可执行文件。 C的运行,就是将可执行文件交给操作系统,按照机器码逐步执行,运行功能。 先看一个非常非常有趣的例子: class Father{ public:virtual void f(){cout<<"I am fat…...

《彻底搞懂RAG技术:解决大模型幻觉,落地企业AI应用的核心方案》
随着大模型技术快速普及,众多企业纷纷入局AI落地,但绝大多数通用大模型在实际业务场景中都会面临两大致命难题:知识滞后与幻觉问题。通用大模型的训练数据存在固定时间截止点,无法获取最新行业数据、企业私有业务数据,…...

为什么91%的DeepSeek部署在第7轮后开始“失忆”?揭秘KV Cache碎片率超阈值的实时熔断策略
更多请点击: https://codechina.net 第一章:DeepSeek多轮对话优化 DeepSeek系列大模型在多轮对话场景中面临上下文衰减、指代歧义与意图漂移等典型挑战。为提升长程一致性与角色连贯性,需从提示工程、状态管理与响应重校准三个维度协同优化。…...

条件矩约束模型中的局部稳健推断与正交工具变量应用
1. 条件矩约束模型:从核心挑战到稳健推断的桥梁在实证研究的工具箱里,条件矩约束模型(Conditional Moment Restrictions, CMRs)无疑是一把瑞士军刀。无论是评估一项政策对经济产出的影响,还是分析用户特征如何影响其购…...

ODM终极指南:5步快速上手免费开源无人机影像处理,生成专业三维模型与正射影像
ODM终极指南:5步快速上手免费开源无人机影像处理,生成专业三维模型与正射影像 【免费下载链接】ODM A command line toolkit to generate maps, point clouds, 3D models and DEMs from drone, balloon or kite images. 📷 项目地址: https…...

kkFileView在Linux服务器上安装踩坑全记录:从字体乱码到Office组件报错的保姆级排错指南
kkFileView部署实战:Linux服务器疑难问题深度排查手册当你在凌晨两点收到服务器告警,发现刚部署的kkFileView服务又崩溃了——这已经是本周第三次。日志里那些晦涩的报错信息像是一道道密码,而生产环境的文件预览功能明天早上就要交付。这不是…...

MD-Editor-V3 编辑器查找替换功能深度解析与实现原理
MD-Editor-V3 编辑器查找替换功能深度解析与实现原理 【免费下载链接】md-editor-v3 Markdown editor for vue3, developed in jsx and typescript, dark theme、beautify content by prettier、render articles directly、paste or clip the picture and upload it... 项目地…...

长期使用Taotoken Token Plan套餐在项目开发中的成本节省体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐在项目开发中的成本节省体感 1. 项目背景与成本挑战 我们团队负责一个中型AI应用项目的开发&…...

BiliDownloader:三分钟掌握B站视频下载的终极指南
BiliDownloader:三分钟掌握B站视频下载的终极指南 【免费下载链接】BiliDownloader BiliDownloader是一款界面精简,操作简单且高速下载的b站下载器 项目地址: https://gitcode.com/gh_mirrors/bi/BiliDownloader BiliDownloader是一款专为Bilibil…...

CAXA工艺图表中文版全流程下载与安装教程实录
如大家所熟悉的,CAXA工艺图表是一款功能强大且十分专业的计算机辅助工艺设计(CAPP)软件工具,专为制造业企业打造,集2D/3D图形编辑、图文混排、工艺知识库、典型工艺重用与结构化工艺数据管理于一体,用于高效…...

机器遗忘:从合规需求到技术实现,ROEL-TID框架如何平衡效率与精度
1. 项目概述:当机器学习模型需要“忘记”时在过去的十年里,我亲眼见证了机器学习如何从一个学术概念,演变为驱动商业决策、优化用户体验乃至重塑行业格局的核心引擎。从电商平台的“猜你喜欢”,到金融系统的欺诈交易拦截ÿ…...