39 深度学习(三):tensorflow.data模块的使用(基础,可跳)
文章目录
- data模块的使用
- 基础api的介绍
- csv文件
- tfrecord
data模块的使用
在训练的过程中,当数据量一大的时候,我们纯读取一个文件,然后每次训练都调用相同的文件,然后进行处理是很不科学的,或者说,当我们需要进行多次训练的时候,我们实际上可以将数据先切分,打乱到对应的位置,然后存储到文件夹当中,下次读取然后进行训练。这样子也可以避免一下子加载太多的数据。(这对于大数据的图像切割领域尤其重要)
基础api的介绍
import numpy as np
import pandas as pd
import tensorflow as tf# 经过下面的使用得到的dataset可以当作是迭代器 或者 就是数据提取器# from_tensor_slices数据切片 返回的是一个迭代器 需要for去取
dataset = tf.data.Dataset.from_tensor_slices(np.arange(3))
for item in dataset:print(item)
print('-'*50)# from_tensors 不对数据进行处理 就是一个长数据 但是一样得用for去取数据
dataset = tf.data.Dataset.from_tensors(np.arange(3))
for item in dataset:print(item)
print('-'*50)# batch(2)一次性取多少数据
dataset = tf.data.Dataset.from_tensor_slices(np.arange(10)).batch(4)
for item in dataset:print(item)
print('-'*50)# repeat把数据进行复制处理
dataset = tf.data.Dataset.from_tensor_slices(np.arange(2)).repeat(2)
for item in dataset:print(item)
print('-'*50)# interleave 就是提取数据的方式 和下面进行对比
dataset = tf.data.Dataset.from_tensor_slices(np.arange(10)).batch(2)
dataset2 = dataset.interleave(lambda v: tf.data.Dataset.from_tensors(v).repeat(3), # map_fncycle_length = 3, # cycle_length,每一个cycle提取的个数block_length = 2, # block_length
)
for item in dataset2:print(item)# interleave 就是提取数据的方式
dataset = tf.data.Dataset.from_tensor_slices(np.arange(10)).batch(2)
dataset2 = dataset.interleave(lambda v: tf.data.Dataset.from_tensor_slices(v).repeat(3), # map_fncycle_length = 3, # cycle_length,竖选3个为一个cycleblock_length = 2, # block_length,横选2个
)
for item in dataset2:print(item)
print('-'*50)x = np.array([[1, 2], [3, 4], [5, 6]])
y = np.array(['cat', 'dog', 'fox'])
#输入的参数是元祖的情况下
dataset3 = tf.data.Dataset.from_tensor_slices((x, y))
print(dataset3)for item_x, item_y in dataset3:print(item_x, item_y)
#输入的参数是字典的情况下
dataset4 = tf.data.Dataset.from_tensor_slices({"feature1": x,"label": y})
print(dataset4)
for item in dataset4:print(item["feature1"], item["label"])
输出:
tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64)
--------------------------------------------------
tf.Tensor([0 1 2], shape=(3,), dtype=int64)
--------------------------------------------------
tf.Tensor([0 1 2 3], shape=(4,), dtype=int64)
tf.Tensor([4 5 6 7], shape=(4,), dtype=int64)
tf.Tensor([8 9], shape=(2,), dtype=int64)
--------------------------------------------------
tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64)
--------------------------------------------------
tf.Tensor([0 1], shape=(2,), dtype=int64)
tf.Tensor([0 1], shape=(2,), dtype=int64)
tf.Tensor([2 3], shape=(2,), dtype=int64)
tf.Tensor([2 3], shape=(2,), dtype=int64)
tf.Tensor([4 5], shape=(2,), dtype=int64)
tf.Tensor([4 5], shape=(2,), dtype=int64)
tf.Tensor([0 1], shape=(2,), dtype=int64)
tf.Tensor([2 3], shape=(2,), dtype=int64)
tf.Tensor([4 5], shape=(2,), dtype=int64)
tf.Tensor([6 7], shape=(2,), dtype=int64)
tf.Tensor([6 7], shape=(2,), dtype=int64)
tf.Tensor([8 9], shape=(2,), dtype=int64)
tf.Tensor([8 9], shape=(2,), dtype=int64)
tf.Tensor([6 7], shape=(2,), dtype=int64)
tf.Tensor([8 9], shape=(2,), dtype=int64)
tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64)
tf.Tensor(5, shape=(), dtype=int64)
tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64)
tf.Tensor(5, shape=(), dtype=int64)
tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64)
tf.Tensor(5, shape=(), dtype=int64)
tf.Tensor(6, shape=(), dtype=int64)
tf.Tensor(7, shape=(), dtype=int64)
tf.Tensor(8, shape=(), dtype=int64)
tf.Tensor(9, shape=(), dtype=int64)
tf.Tensor(6, shape=(), dtype=int64)
tf.Tensor(7, shape=(), dtype=int64)
tf.Tensor(8, shape=(), dtype=int64)
tf.Tensor(9, shape=(), dtype=int64)
tf.Tensor(6, shape=(), dtype=int64)
tf.Tensor(7, shape=(), dtype=int64)
tf.Tensor(8, shape=(), dtype=int64)
tf.Tensor(9, shape=(), dtype=int64)
--------------------------------------------------
<_TensorSliceDataset element_spec=(TensorSpec(shape=(2,), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
tf.Tensor([1 2], shape=(2,), dtype=int64) tf.Tensor(b'cat', shape=(), dtype=string)
tf.Tensor([3 4], shape=(2,), dtype=int64) tf.Tensor(b'dog', shape=(), dtype=string)
tf.Tensor([5 6], shape=(2,), dtype=int64) tf.Tensor(b'fox', shape=(), dtype=string)
<_TensorSliceDataset element_spec={'feature1': TensorSpec(shape=(2,), dtype=tf.int64, name=None), 'label': TensorSpec(shape=(), dtype=tf.string, name=None)}>
tf.Tensor([1 2], shape=(2,), dtype=int64) tf.Tensor(b'cat', shape=(), dtype=string)
tf.Tensor([3 4], shape=(2,), dtype=int64) tf.Tensor(b'dog', shape=(), dtype=string)
tf.Tensor([5 6], shape=(2,), dtype=int64) tf.Tensor(b'fox', shape=(), dtype=string)
csv文件
执行流程:
!rm -rf generate_csv
存数据
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
import os# 数据准备
# -----------------------------------------------------------------------------
housing = fetch_california_housing()
x_train_all, x_test, y_train_all, y_test = train_test_split(housing.data, housing.target, random_state = 7)
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all, random_state = 11)
print(x_train.shape, y_train.shape)
print(x_valid.shape, y_valid.shape)
print(x_test.shape, y_test.shape)
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)
# -----------------------------------------------------------------------------# 下面要把特征工程后的数据存为csv文件
output_dir = "generate_csv"
if not os.path.exists(output_dir):os.mkdir(output_dir)def save_to_csv(output_dir, data, name_prefix, header=None, n_parts=10):#生成文件名path_format = os.path.join(output_dir, "{}_{:02d}.csv")#把数据分为n_parts部分,写到文件中去 enumerate就是多一个i从0开始,不断加上去的for file_idx, row_indices in enumerate(np.array_split(np.arange(len(data)), n_parts)):#生成子文件名part_csv = path_format.format(name_prefix, file_idx)with open(part_csv, "wt", encoding="utf-8") as f:#先写头部if header is not None:f.write(header + "\n")for row_index in row_indices:#把字符串化后的每个字符串用逗号拼接起来f.write(",".join([repr(col) for col in data[row_index]]))f.write('\n')#np.c_把x和y合并起来
train_data = np.c_[x_train_scaled, y_train]
valid_data = np.c_[x_valid_scaled, y_valid]
test_data = np.c_[x_test_scaled, y_test]
#头部,特征,也有目标
header_cols = housing.feature_names + ["MidianHouseValue"]
#把列表变为字符串
header_str = ",".join(header_cols)
print(header_str)
save_to_csv(output_dir, train_data, "train",header_str, n_parts=20)
save_to_csv(output_dir, valid_data, "valid",header_str, n_parts=10)
save_to_csv(output_dir, test_data, "test",header_str, n_parts=10)
输出:
(11610, 8) (11610,)
(3870, 8) (3870,)
(5160, 8) (5160,)
MedInc,HouseAge,AveRooms,AveBedrms,Population,AveOccup,Latitude,Longitude,MidianHouseValue
!cd generate_csv;ls
输出:
test_00.csv test_06.csv train_02.csv train_08.csv train_14.csv valid_00.csv valid_06.csv
test_01.csv test_07.csv train_03.csv train_09.csv train_15.csv valid_01.csv valid_07.csv
test_02.csv test_08.csv train_04.csv train_10.csv train_16.csv valid_02.csv valid_08.csv
test_03.csv test_09.csv train_05.csv train_11.csv train_17.csv valid_03.csv valid_09.csv
test_04.csv train_00.csv train_06.csv train_12.csv train_18.csv valid_04.csv
test_05.csv train_01.csv train_07.csv train_13.csv train_19.csv valid_05.csv
提取数据:
import pprint# 提取数据的流程
# 获取文件名称
filenames = os.listdir('./generate_csv')
train_filenames = []
test_filenames = []
valid_filenames = []
for filename in filenames:if filename[0] == 'v':valid_filenames.append('generate_csv/'+filename)elif filename[1] == 'e':test_filenames.append('generate_csv/'+filename)else:train_filenames.append('generate_csv/'+filename)def parse_csv_line(line, n_fields = 9):#先写一个默认的格式,就是9个nan,如果从csv中读取缺失数据,就会变为nandefs = [tf.constant(np.nan)] * n_fields#使用decode_csv解析parsed_fields = tf.io.decode_csv(line, record_defaults=defs)#前8个是x,最后一个是yx = tf.stack(parsed_fields[0:-1])y = tf.stack(parsed_fields[-1:])return x, ydef csv_reader_dataset(filenames, n_readers=5,batch_size=32, n_parse_threads=5,shuffle_buffer_size=10000):# 将数据集放入这个dataset当中,他会默认进行shuffledataset = tf.data.Dataset.list_files(filenames)#变为repeat dataset可以让读到最后一个样本时,从新去读第一个样本dataset = dataset.repeat()dataset = dataset.interleave(#skip(1)是因为每个文件存了特征名字,target名字lambda filename: tf.data.TextLineDataset(filename).skip(1),cycle_length = n_readers)dataset.shuffle(shuffle_buffer_size) #对数据进行洗牌,混乱#map,通过parse_csv_line对数据集进行映射,map只会给函数传递一个参数dataset = dataset.map(parse_csv_line,num_parallel_calls=n_parse_threads)dataset = dataset.batch(batch_size)return dataset# 得到dataset类
train_set = csv_reader_dataset(train_filenames, batch_size=4)print(train_set)
#是csv_reader_dataset处理后的结果,
for x_batch, y_batch in train_set.take(2):print("x:")pprint.pprint(x_batch)print("y:")pprint.pprint(y_batch)
输出:
<_BatchDataset element_spec=(TensorSpec(shape=(None, 8), dtype=tf.float32, name=None), TensorSpec(shape=(None, 1), dtype=tf.float32, name=None))>
x:
<tf.Tensor: shape=(4, 8), dtype=float32, numpy=
array([[-1.1199750e+00, -1.3298433e+00, 1.4190045e-01, 4.6581370e-01,-1.0301778e-01, -1.0744184e-01, -7.9505241e-01, 1.5304717e+00],[ 4.9710345e-02, -8.4924191e-01, -6.2146995e-02, 1.7878747e-01,-8.0253541e-01, 5.0660671e-04, 6.4664572e-01, -1.1060793e+00],[-6.6722274e-01, -4.8239522e-02, 3.4529406e-01, 5.3826684e-01,1.8521839e+00, -6.1125383e-02, -8.4170932e-01, 1.5204847e+00],[-3.2652634e-01, 4.3236190e-01, -9.3454592e-02, -8.4029920e-02,8.4600359e-01, -2.6631648e-02, -5.6176794e-01, 1.4228760e-01]],dtype=float32)>
y:
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.66 ],[2.286],[1.59 ],[2.431]], dtype=float32)>
x:
<tf.Tensor: shape=(4, 8), dtype=float32, numpy=
array([[-1.0775077 , -0.4487407 , -0.5680568 , -0.14269263, -0.09666677,0.12326469, -0.31448638, -0.4818959 ],[-0.9490939 , 0.6726626 , 0.28370556, 0.1065553 , -0.65464777,-0.06239493, 0.21273656, 0.0024705 ],[-1.453851 , 1.8741661 , -1.1315714 , 0.36112761, -0.3978858 ,-0.03273859, -0.73906416, 0.64662784],[ 1.5180511 , -0.52884096, 0.81024706, -0.1921417 , 0.44135395,0.02733506, -0.81838083, 0.8563535 ]], dtype=float32)>
y:
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.978],[0.607],[1.875],[2.898]], dtype=float32)>
tfrecord
Tfrecord是TensorFlow独有的数据格式,有读取速度快的优势,正常情况下我们训练文件数据集经常会生成 train, test 或者val文件夹,这些文件夹内部往往会存着成千上万的图片或文本等文件,这些文件被散列存着,这样不仅占用磁盘空间,并且再被一个个读取的时候会非常慢,繁琐。占用大量内存空间(有的大型数据不足以一次性加载)。此时我们TFRecord格式的文件存储形式会很合理的帮我们存储数据。TFRecord内部使用了“Protocol Buffer”二进制数据编码方案,它只占用一个内存块,只需要一次性加载一个二进制文件的方式即可,简单,快速,尤其对大型训练数据很友好。而且当我们的训练数据量比较大的时候,可以将数据分成多个TFRecord文件,来提高处理效率。
之后补,这边采用csv也可以,方法类似,这边先跳,之后补充。
相关文章:
:tensorflow.data模块的使用(基础,可跳))
39 深度学习(三):tensorflow.data模块的使用(基础,可跳)
文章目录 data模块的使用基础api的介绍csv文件tfrecord data模块的使用 在训练的过程中,当数据量一大的时候,我们纯读取一个文件,然后每次训练都调用相同的文件,然后进行处理是很不科学的,或者说,当我们需…...

css四种导入方式
1 行内样式 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title> </head> <body> <h1 style"color: blue">我是标题</h1> </body> </htm…...
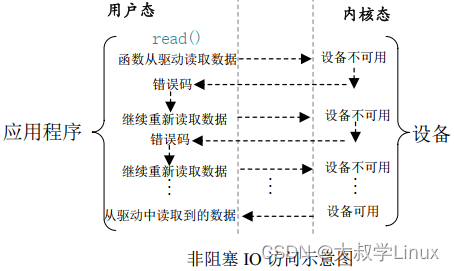
Linux学习第24天:Linux 阻塞和非阻塞 IO 实验(一): 挂起
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 在正式开始今天的笔记之前谈一下工作中遇见的一个问题。 本篇笔记主要学习Linux 阻塞和非阻塞 IO 实验,主要包括阻塞和非阻塞简介、等待队列、轮询、…...

037-第三代软件开发-系统音量设置
第三代软件开发-系统音量设置 文章目录 第三代软件开发-系统音量设置项目介绍系统音量设置QML 实现C 实现 总结一下 关键字: Qt、 Qml、 volume、 声音、 GPT 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML(Qt Meta-Obj…...
Python 自动化详解(pyautogui)
文章目录 1 概述1.1 第三方库:pyautogui1.2 坐标说明 2 操作对象2.1 鼠标2.1.1 定位2.1.2 移动2.1.3 拖动2.1.4 滚动2.1.5 点击 2.2 键盘2.2.1 输入2.2.2 按键2.2.3 快捷键 2.3 屏幕2.3.1 截图2.3.2 分辨率 2.4 信息提示2.4.1 提示框2.4.2 选择框2.4.3 密码输入2.4.…...
【Linux】第四站:Linux基本指令(三)
文章目录 一、时间相关的指令1.指令简介2.使用 二、cal指令三、find指令 -name1.介绍2.使用 四、grep指令1.介绍2.使用 五、zip/unzip指令1.介绍2.zip的安装3.使用 六、tar指令:打包解包,不打开它、直接看内容1.介绍2.使用 七、bc指令八、uname -r指令1.…...

SpringBoot内置工具类之断言Assert的使用与部分解析
先例举一个service的demo中用来验证参数对象的封装方法,使用了Assert工具类后是不是比普通的 if(xxx) { throw new RuntimeException(msg) } 看上去要简洁多了? 断言Assert工具类简介 断言是一个判断逻辑,用来检查不该发生的情况ÿ…...

如何检测租用的香港服务器是不是CN2线路呢?
CN2,是中国电信新一代融合承载网络,是为电信自身关键业务和具有QoS保证的SLA业务服务的,可以提供高性能的网络指 标,平均单向时延、最大单向时延、单向丢包率等均属于顶尖水平。简单地说,CN2和普通网络,就像…...

Spring Boot进阶(94):从入门到精通:Spring Boot和Prometheus监控系统的完美结合
📣前言 随着云原生技术的发展,监控和度量也成为了不可或缺的一部分。Prometheus 是一款最近比较流行的开源时间序列数据库,同时也是一种监控方案。它具有极其灵活的查询语言、自身的数据采集和存储机制以及易于集成的特点。而 Spring Boot 是…...

Redis(02)| 数据结构-SDS
一、键值对数据库是怎么实现的? 在开始讲数据结构之前,先给介绍下 Redis 是怎样实现键值对(key-value)数据库的。 Redis 的键值对中的 key 就是字符串对象,而 value 可以是字符串对象,也可以是集合数据类型…...

HackTheBox-Starting Point--Tier 0---Preignition
文章目录 一 题目二 实验过程 一 题目 Tags Web、Custom Applications、Apache、Reconnaissance、Web Site Structure Discovery、Default Credentials译文:Web、定制应用程序、Apache、侦察、网站结构发现、默认凭证Connect To attack the target machine, you …...
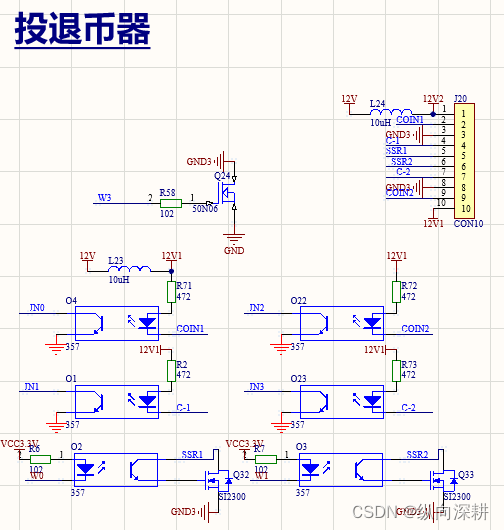
售货机相关的电路
一、货道选通矩阵电路,类似扫描电路,驱动哪个电机,就打开相应的行线与列线输出 二、MDB纸币器,虽然现在国内都是手机支付,但如果机器还是外销国外还是有用 三、硬币器电路,投币与退币,脉冲信号…...

软考高项(十四)项目沟通管理 ★重点集萃★
👑 个人主页 👑 :😜😜😜Fish_Vast😜😜😜 🐝 个人格言 🐝 :🧐🧐🧐说到做到,言出必行&am…...

Linux多线程服务端编程:使用muduo C++网络库 学习笔记 第五章 高效的多线程日志
“日志(logging)”有两个意思: 1.诊断日志(diagnostic log)。即log4j、logback、slf4j、glog、g2log、log4cxx、log4cpp、log4cplus、Pantheios、ezlogger等常用日志库提供的日志功能。 2.交易日志(trasac…...

利用Pholcus框架提取小红书数据的案例分析
前言 在当今互联网时代,数据的获取和分析变得越来越重要。爬虫技术作为一种数据采集的方法,被广泛涉及各个领域。在本文中,我们将介绍如何使用Python Spark语言和Pholcus框架来实现一本小红书数据爬虫的案例分析。 开发简述 Go语言作为一种…...
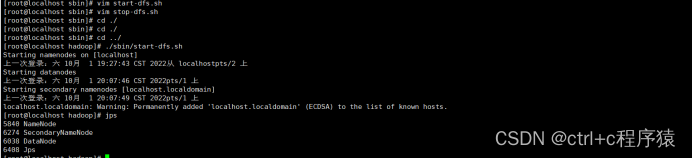
超详细Hadoop安装教程(单机版、伪分布式)
超详细Hadoop安装教程(单机版、伪分布式) 1.Hadoop分布式系统基础架构介绍1.1.Hadoop核心 2.Hadoop安装教程2.1.环境准备2.2.配置用户ssh 免密登录2.3.JAVA环境的安装和配置2.4.Hadoop安装2.5.单机版Hadoop配置2.6.伪分布式Hadoop配置2.7Hadoop初始化 1.…...

持续集成部署-k8s-服务发现-Ingress
持续集成部署-k8s-服务发现-Ingress 1. Ingress 是什么2. Ingress 控制器3. 安装 Ingress-Nginx3.1 添加 Helm 仓库3.2 更新 Helm 仓库3.3 下载 Ingress-Nginx 安装包3.4 配置 Ingress-Nginx 配置文件参数3.5 安装 Ingress-Nginx1. Ingress 是什么 Ingress是 Kubernetes 中的一…...

从零开始搭建Prometheus+grafana服务器组件监控系统
服务器及相关组件监控 本文档主要记录了常用企业级服务器及各种组件的监控手段和监控部署方案,使企业可以实时感知服务器组件的健康状态,并在服务器或组件出现异常时及时做出反应。 本方案采用的Prometheusgrafana的方式实现对服务器及各种组件的监控&am…...

智能水厂运行与调控3D模拟仿真在线展示提高整个系统的协同效应
水厂在生活中的重要性不可忽视。它们提供清洁、安全的水源,满足人们饮用、洗浴、烹饪等基本需求,保障公共卫生,预防疾病传播;同时,水厂也促进经济发展,为工业生产和农业灌溉提供保障,吸引和支持企业的投资和…...
ts声明文件
1 背景 对于为第三方模块/库写声明文件之前,我们需要知道第三方模块/库,是否需要声明文件,或者是否已有声明文件。 若第三方模块/库,是ts编写且无声明文件, 可以使用--declaration配置选项来生成;可以在命…...

如何快速解密网易云音乐NCM文件:Windows用户的完整解决方案
如何快速解密网易云音乐NCM文件:Windows用户的完整解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的NCM格式文件无法…...

OpenMemories-Tweak:嵌入式系统配置管理的逆向工程实践
OpenMemories-Tweak:嵌入式系统配置管理的逆向工程实践 【免费下载链接】OpenMemories-Tweak Unlock your Sony cameras settings 项目地址: https://gitcode.com/gh_mirrors/op/OpenMemories-Tweak 问题导向:破解封闭式嵌入式系统的配置限制 在…...

免费开源AMD Ryzen调试工具:5步快速掌握SMUDebugTool处理器控制技巧
免费开源AMD Ryzen调试工具:5步快速掌握SMUDebugTool处理器控制技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...

工作总“救火”还费力不讨好?《易经》这一卦告诉你:别瞎忙
你有没有遇到过这样的同事或领导?哪里出问题,他就冲向哪里,整天忙得脚不沾地,可最后不但没解决问题,反而把局面弄得更糟,自己也落得个“吃力不讨好”。或者,你自己就是那个“救火队员”。项目出…...

WarcraftHelper魔兽争霸3兼容性解决方案:让经典游戏在现代电脑上重获新生
WarcraftHelper魔兽争霸3兼容性解决方案:让经典游戏在现代电脑上重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为心爱的魔兽…...

RePKG:终极Wallpaper Engine资源提取与TEX转换完全指南
RePKG:终极Wallpaper Engine资源提取与TEX转换完全指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经想提取Wallpaper Engine壁纸中的精美音乐,…...

去偏机器学习在左截断右删失数据因果生存分析中的应用
1. 项目概述:当生存分析遇上复杂数据与因果推断在生物医学、流行病学乃至社会科学研究中,我们常常关心一个关键事件发生的时间:从接受某种治疗到疾病复发,从开始暴露于某种风险因素到出现特定结局,或者从产品发布到用户…...

机器学习模型虚假相关性识别与应对:四大评估框架与实战指南
1. 项目概述:当模型学会了“走捷径”在机器学习项目里摸爬滚打这么多年,我越来越觉得,模型训练最让人头疼的,不是调不出更高的准确率,而是你永远不知道它到底“学会”了什么。很多时候,模型在测试集上表现优…...

企业级MCP Server OAuth授权接入的七层防御实践
1. 这不是又一篇“OAuth流程图”——企业级MCP Server为什么必须自己实现授权接入你有没有遇到过这样的场景:公司新上线的内部运维平台(我们暂且叫它MCP,即Monitoring & Control Platform)需要对接钉钉、飞书或企业微信的组织…...

基于密度距离度量构建高质量科学仿真训练集:从原理到工程实践
1. 项目概述:从仿真数据到高质量训练集的桥梁在计算物理、流体力学或者天体物理模拟这类科学计算项目中,我们常常会生成海量的仿真数据。这些数据,比如一个随时间演化的等离子体密度场,其本身是复杂且高维的。直接把这些“原始矿石…...