【Python】Numpy数组的切片、索引详解:取数组的特定行列
【Python】Numpy数组的切片、索引详解:取数组的特定行列
文章目录
- 【Python】Numpy数组的切片、索引详解:取数组的特定行列
- 1. 介绍
- 2. 切片索引
- 2.1 切片索引先验知识
- 2.1 一维数组的切片索引
- 2.3 多维数组的切片索引
- 3. 数组索引(副本)
- 3.1 一维数组的数组索引
- 3.2 多维数组的数组索引
- 3.2.1 对于索引数组数量小于被索引数组维度的情况
- 3.2.2 红色标记的元素为待索引元素,对应结果数组分别为一维和二维数组c, d:
- 3.2.3 需索引数组的指定行列(红色标记位置),对应结果数组为二维数组e:(这个比较重要感觉)
- 3.2.4 通过扩展可知,对于三维数组
- 3.3 如何选取数组的特定行列
- 3.3.1 函数ix_()快速索引指定行列
- 4. 切片和数组的组合索引(副本)
- 5. 布尔数组索引
- 6. 结构化索引工具
- 7. 利用索引给数组赋值
- 8. 参考
1. 介绍
Numpy的数组除了可使用内置序列的索引方式之外,提供了更多的索引能力。
- 如通过切片、整数数组和布尔数组等方式进行索引。
这使得Numpy索引功能很强大,但同时也带来了一些复杂性和混乱性,尤其是多维索引数组。
- Numpy数组的切片索引,不会复制内部数组数据,仅创建原始数据的新视图,以引用方式访问数据。
- 而使用数组索引进行索引时,返回数据副本,而不是创建视图。索引可避免在数组中循环各元素,从而大大提高了性能。
2. 切片索引
Numpy数组的切片索引,不会复制内部数组数据,仅创建原始数据的新视图,以引用方式访问数据。
- 切片索引适用于有规律的查找指定位置的元素(元素位置位于等差序列);
- 当切片的数量少于数组维度时,缺失的维度索引被认为是一个完整切片,省略、“:”、“…”三者等价;
2.1 切片索引先验知识
对于一维数组来说,python原生的list和numpy的array的切片操作都是相同的,记住一个规则
arr[start: end: step]
下面是几个特殊的例子:
- [:] 表示复制源列表。
- 负的index表示,从后往前。-1表示最后一个元素。
import numpy as np
data = np.arange(20).reshape(4,5)#array([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]])data[1,:] #data[i,:] 获取第i行元素 同理data[:,i] 获取第i列元素
#array([5, 6, 7, 8, 9])data[:,-3:] #获取所有的行中倒数第三个到最后的元素
#array([[ 2, 3, 4],
# [ 7, 8, 9],
# [12, 13, 14],
# [17, 18, 19]])
data[:,:3] #获取所有的行中从0到2的元素(注意时左闭右开)
#array([[ 0, 1, 2],
# [ 5, 6, 7],
# [10, 11, 12],
# [15, 16, 17]])#取一个数据块
data[0:2,0:3] # 注意,时左闭右开原则
#array([[0, 1, 2],
# [5, 6, 7]])
2.1 一维数组的切片索引
>>> a = np.arange(16)
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
>>> a[::-1] # 逆序
array([15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
>>> a[...] # 索引全部元素,与a[:]等价
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
>>> a[2:6:2] # 索引位置2,4的两个元素, 从2到6(不包括6),步长为2
array([2, 4])
2.3 多维数组的切片索引
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]])>>> b[:, ::-1] # 轴2逆序,即列逆序
array([[ 3, 2, 1, 0],[ 7, 6, 5, 4],[11, 10, 9, 8],[15, 14, 13, 12]])
>>> b[1:3] # 轴1位置0,1,即第1,2行
array([[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
>>> b[1:3, :4:2] # 第1,2行,第0,2列
array([[ 4, 6],[ 8, 10]])
>>> c = np.arange(24).reshape(2,3,4)
>>> c
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])
>>> c[:, 0, :2]
array([[ 0, 1],[12, 13]])
3. 数组索引(副本)
Numpy的数组索引,返回数据副本,而不是创建视图。相比切片索引,整数数组的索引更具有通用性,因为其不要求索引值具有特定规律。
- 对于索引数组中未建立索引的维度(索引数组中的索引集数目小于被索引数组维度),默认被全部索引;
- 索引结果数组的形状由索引数组的形状与被索引数组中所有未索引的维的形状串联组成,也就是说,若对数组的所有维度建立索引,则索引数组的形状等于结果数组的形状;
- 若索引数组具有匹配的形状,即索引数组个数(索引集数)等于被索引数组的维度,此时结果数组与索引数组具有相同形状,且这些结果值对应于各维索引集的索引在索引数组中的位置;
3.1 一维数组的数组索引
>>> a = np.arange(16)
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
>>>a[[0,1]] # 第0,1位置的元素,结果数组维度为1,与a[[[0,1]]]等价
array([0, 1])
>>> a[np.array([[0,1]])] # 第0,1位置的元素,结果数组1*2,与a[[[[0,1]]]]等价
array([[0, 1]])
>>> a[np.array([[0,1], [2,3]])] # 第0,1,2,3位置的4个元素,结果数组2*2
array([[0, 1],[2, 3]])
3.2 多维数组的数组索引
由于二维数组的整数索引用途广泛,在此做详细介绍。被索引的二维数组/矩阵b,如下:
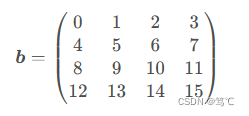
3.2.1 对于索引数组数量小于被索引数组维度的情况
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]])
>>> b[[1,3]] # 轴2缺省(长度为4),被索引全部,索引数组一维长度为2,结果数组二维2*4
array([[ 4, 5, 6, 7],[12, 13, 14, 15]])
>>> b[np.array([[0,1], [0,2]])] # 轴2缺省(长度为4),被索引全部,索引数组二维2*2,结果数组三维2*2*4
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7]],[[ 0, 1, 2, 3],[ 8, 9, 10, 11]]])
3.2.2 红色标记的元素为待索引元素,对应结果数组分别为一维和二维数组c, d:
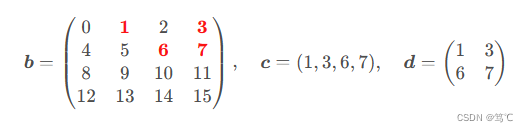
>>> c = b[[0,0,1,1], [1,3,2,3]] # 与结果数组同形,长度为4的一维数组
>>> c
array([1, 3, 6, 7])
>>> d = b[[[0,0],[1,1]], [[1,3],[2,3]]] # 与结果数组同形,2*2,等价于b[[[0],[1]], [[1,3],[2,3]]](广播)
>>> d
array([[1, 3],[6, 7]])
3.2.3 需索引数组的指定行列(红色标记位置),对应结果数组为二维数组e:(这个比较重要感觉)
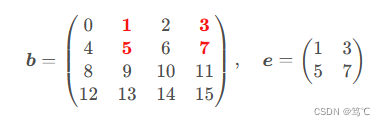
>>> i = [[0], [1]]
>>> j = [[1,3]]
>>> b[i, j] # b[[[0],[1]], [[1,3]]],等价于b[[[0,0], [1,1]], [[1,3], [1,3]]]
array([[1, 3],[5, 7]])
上述结果反映了整数数组索引同样具有广播性质,即b[[[0,1], [0,3]], [[1,1], [1,3]]] 可简写为b[[[0], [1]], [[1,3]]]。
显然,用切片索引b[:2, 1::2]更容易实现上述结果,但切片索引要求被索引的行列顺序符合等差分布,不适用于无序的行列索引。
假设需要索引数组b bb的第0,2,3行的第0,1,3列,一种简单的想法是行列分开索引,即b[[0,2,3]][:, [0,1,3]]。显然结果正确。但此种索引方式效率低下,因为第一步索引创建了临时数组,第二步索引在新的临时数组中执行。
效率更高的实现是使用整数数组索引,即b[[[0],[2],[3]], [[0,1,3]]]:
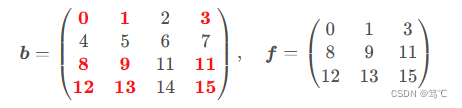
>>> b[[0,2,3]][:, [0,1,3]]
array([[ 0, 1, 3],[ 8, 9, 11],[12, 13, 15]])
>>> f = b[[[0],[2],[3]], [[0,1,3]]]
>>> f
array([[ 0, 1, 3],[ 8, 9, 11],[12, 13, 15]])
3.2.4 通过扩展可知,对于三维数组
>>> c = np.arange(24).reshape(2,3,4)
>>> c
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])
>>> c[[0]]
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]]])
>>> c[[0],[0,1]]
array([[0, 1, 2, 3],[4, 5, 6, 7]])
>>> c[[0],[0,2],[2,3]]
array([ 2, 11])
>>> c[[[[0,0], [0,0]]], [[[0,0],[1,1]]], [[[0,1],[0,1]]]]
array([[[0, 1],[4, 5]]])
>>> c[[[[0]]], [[[0],[1]]], [[[0,1]]]]
array([[[0, 1],[4, 5]]])
>>> c[0, [[0],[1]], [0,1]] # 形状 1-2*1-1*2 -> 2*2
array([[0, 1],[4, 5]])
3.3 如何选取数组的特定行列
通过上述例子发现,对于二维数组b,若索引数组的第0,1行的第1,3列,完整形式记作:b[[[0,1], [0,3]], [[1,1], [1,3]]],但通过利用整数数组索引的广播性质,简写为b[[[0],[1]], [[1,3]]]。
因此,若给定行号列表x=[0,2,3]和列号列表y=[0,13],建立二维数组索引的方法如下:
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]])
>>> x = [0,2,3]
>>> y = [0,1,3]
>>> b[np.array([x]).T, [y]] # 等价于b[np.array([x]).T, y]
array([[ 0, 1, 3],[ 8, 9, 11],[12, 13, 15]])
3.3.1 函数ix_()快速索引指定行列
Numpy提供的函数ix_()可帮助我们更快地实现索引指定行列,如下:
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]])
>>> i,j = np.ix_([0,2,3],[0,1,3])
>>> i
array([[0],[2],[3]])
>>> j
array([[0, 1, 3]])
>>> b[i,j]
array([[ 0, 1, 3],[ 8, 9, 11],[12, 13, 15]])
>>> c = np.arange(24).reshape(2,3,4)
>>> c
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])
>>> i,j,z = np.ix_([0], [0,1], [0, 1])
>>> i
array([[[0]]])
>>> j
array([[[0],[1]]])
>>> z
array([[[0, 1]]])
>>> c[i,j,z]
array([[[0, 1],[4, 5]]])
4. 切片和数组的组合索引(副本)
整数数组索引可以和切片索引组合使用,实际上切片是被转换为索引数组,该数组与索引数组一起广播以产生结果数组。因此易知,使用组合索引,返回的是原数组数据的副本。
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]])
>>> d = b[[0,1],:2]
>>> d
array([[0, 1],[4, 5]])
>>> d[0,0] = 100 # 非引用,不改变被索引数组的数据
>>> d
array([[100, 1],[ 4, 5]])
>>> b
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]])
5. 布尔数组索引
当我们使用整数数组索引时,我们提供了要选择的索引列表。
- 而使用布尔值作为索引时,我们明确地选择数组中需要的元素。
布尔数组用途十分广泛,如元素筛选、元素赋值等,如下:
>>> a = np.arange(8)
>>> a > 4
array([False, False, False, False, False, True, True, True])
>>> a[a>4]
array([5, 6, 7])
>>> (a > 4) & (a < 7)
array([False, False, False, False, False, True, True, False])
>>> a[(a > 4) & (a < 7)]
array([5, 6])
>>> a[(a > 4) & (a < 7)] += 10
>>> a
array([ 0, 1, 2, 3, 4, 15, 16, 7])
>>> b = np.arange(6).reshape(2,3)
>>> b
array([[0, 1, 2],[3, 4, 5]])
>>> b > 2
array([[False, False, False],[ True, True, True]])
>>> b[b>2]
array([3, 4, 5])
>>> np.where(b>2)
(array([1, 1, 1], dtype=int64), array([0, 1, 2], dtype=int64))
6. 结构化索引工具
为了便于将数组形状与表达式和赋值相匹配,可在数组索引中使用newaxis对象来添加大小为1的新维度。可以参考:np.newaxis函数详解
>>> x = np.arange(5)
>>> x
array([0, 1, 2, 3, 4])
>>> x[:,np.newaxis]
array([[0],[1],[2],[3],[4]])
>>> x[np.newaxis,:]
array([[0, 1, 2, 3, 4]])
>>> x + x[:, np.newaxis]
array([[0, 1, 2, 3, 4],[1, 2, 3, 4, 5],[2, 3, 4, 5, 6],[3, 4, 5, 6, 7],[4, 5, 6, 7, 8]])
7. 利用索引给数组赋值
如前所述,可以使用单个索引、切片索引、整数数组索引以及布尔数组索引来选择数组的子集。若通过这些索引修改原数组数据,需要注意以下几点:
- 分配给索引数组的值必须与索引数组的维度一致(可实现广播规则的除外);
- 不能将较高精度的数据赋值给较低精度的数组元素,因为数组中元素占用内存已固定;
- 可通过切片索引得到的子数组修改原数组数据,但不能通过整数数组索引得到的子数组修改原数组数据;
- 当索引列表包含重复时,赋值完成多次,但仅保留最后一次的赋值结果;
>>> a = np.arange(5)
>>> a
array([0, 1, 2, 3, 4])
>>> a[:2] += 4
>>> a
array([4, 5, 2, 3, 4])
>>> a[:2] -= [4,4]
>>> a
array([0, 1, 2, 3, 4])>>> a[:2] += 1.0
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: Cannot cast ufunc add output from dtype('float64') to dtype('int32') with casting rule 'same_kind'>>> a[[0,0,1]] += 1 # 仅保留最后依次结果,未执行两次
>>> a
array([1, 2, 2, 3, 4])
>>> a[[0,0,1]] -= [2,1,1]
>>> a
array([0, 1, 2, 3, 4])>>> a[a >2] += 10
>>> a
array([ 0, 1, 2, 13, 14])>>> b = a[-2:]
>>> b
array([13, 14])
>>> b -= 10 # 切片索引得到的结果数组为原数组的视图
>>> a
array([0, 1, 2, 3, 4])>>> b = a[[-2,-1]]
>>> b
array([3, 4])
>>> b += 100 # 整数数组索引得到的结果数组为原数组的副本
>>> b
array([103, 104])
>>> a
array([0, 1, 2, 3, 4])
8. 参考
【1】https://blog.csdn.net/sinat_34072381/article/details/84448307
相关文章:
【Python】Numpy数组的切片、索引详解:取数组的特定行列
【Python】Numpy数组的切片、索引详解:取数组的特定行列 文章目录【Python】Numpy数组的切片、索引详解:取数组的特定行列1. 介绍2. 切片索引2.1 切片索引先验知识2.1 一维数组的切片索引2.3 多维数组的切片索引3. 数组索引(副本)…...

2023年全国最新交安安全员精选真题及答案6
百分百题库提供交安安全员考试试题、交安安全员考试预测题、交安安全员考试真题、交安安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 51.安全生产资金保障制度建立后关键在于落实,各施工企业在落实安全生…...
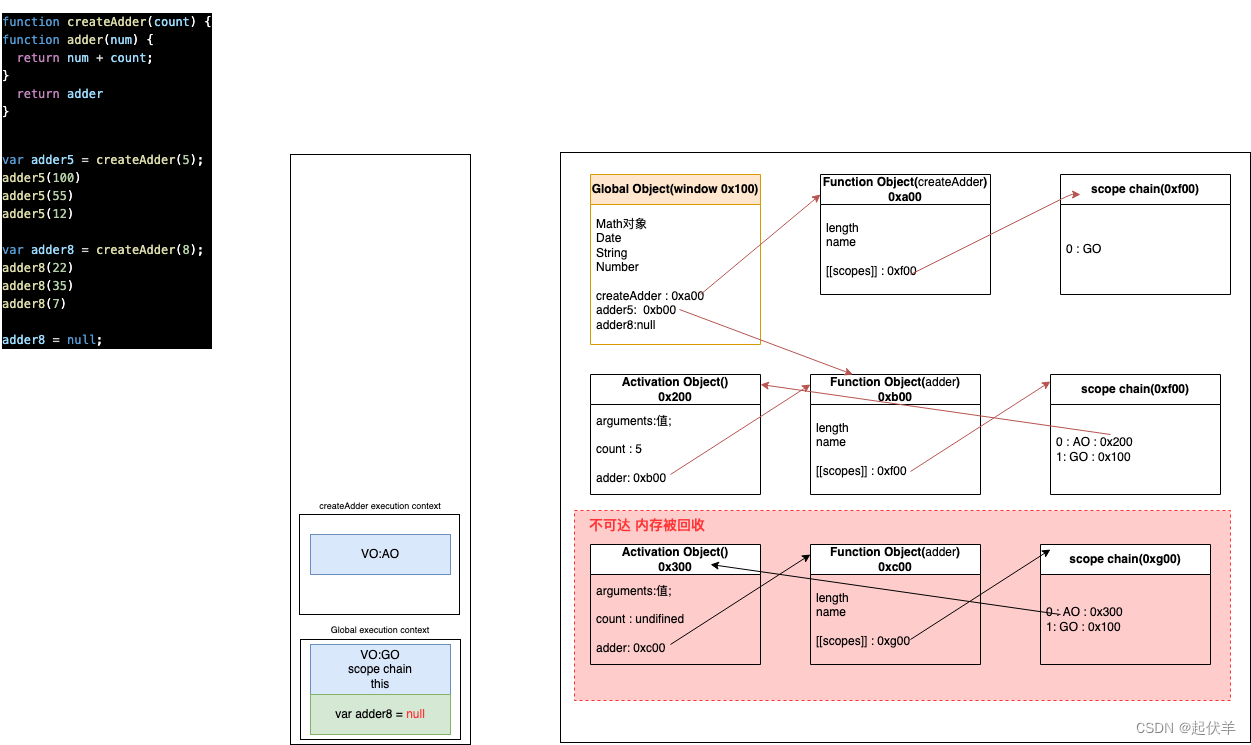
JavaScript 闭包【自留】
闭包的概念理解 闭包的定义 ✅ 这里先来看一下闭包的定义,分成两个:在计算机科学中和在JavaScript中。 ✅ 在计算机科学中对闭包的定义(维基百科): 闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures);是在支持头等函数…...
【MySQL】什么是意向锁 IS IX 及值得学习的思想
文章目录前言行锁和表锁使用意向锁意向锁的算法意向锁的思想JDK 中相似的思想前言 之前看 MySQL 都刻意忽略掉了 IS 和 IX 锁,今天看 《MySQL 是怎样运行的》,把意向锁讲的很通透,本篇博文提炼一下思想。 I: Intention Lock(意向…...

python多线程实现
用于线程实现的Python模块 Python线程有时称为轻量级进程,因为线程比进程占用的内存少得多。 线程允许一次执行多个任务。 在Python中,以下两个模块在一个程序中实现线程 - _thread模块threading模块 这两个模块之间的主要区别在于_thread模块将线程视…...
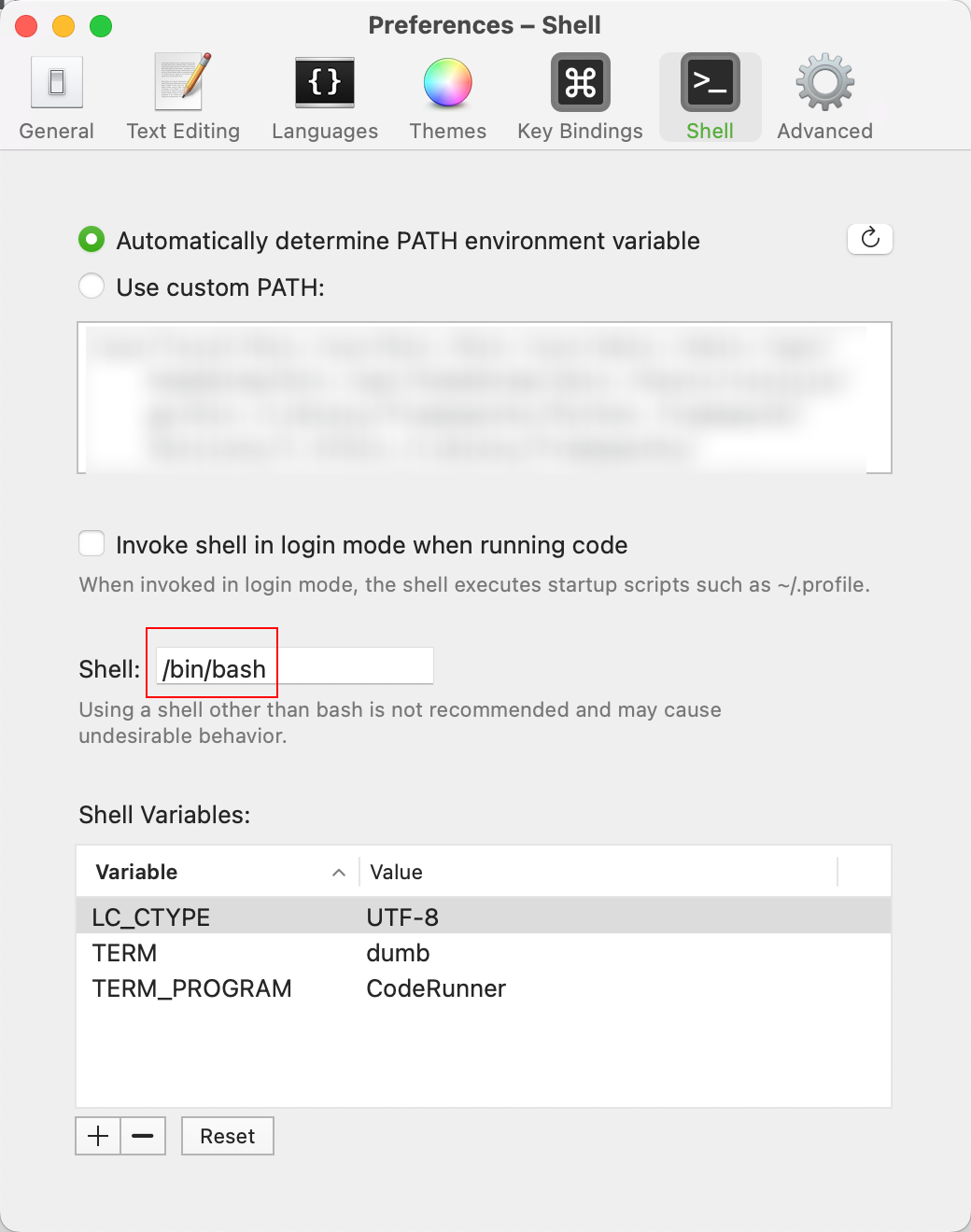
macOS使用CodeRunner快速配置fortran环境
个人网站:xzajyjs.cn 由于一些项目的缘故,需要有fortran的需求,但由于是M1 mac的缘故,不能像windows那样直接使用vsivf这种经典配置。搜了一下网上主流的跨平台方案,主要是gfortran,最近用Coderunner(主要…...
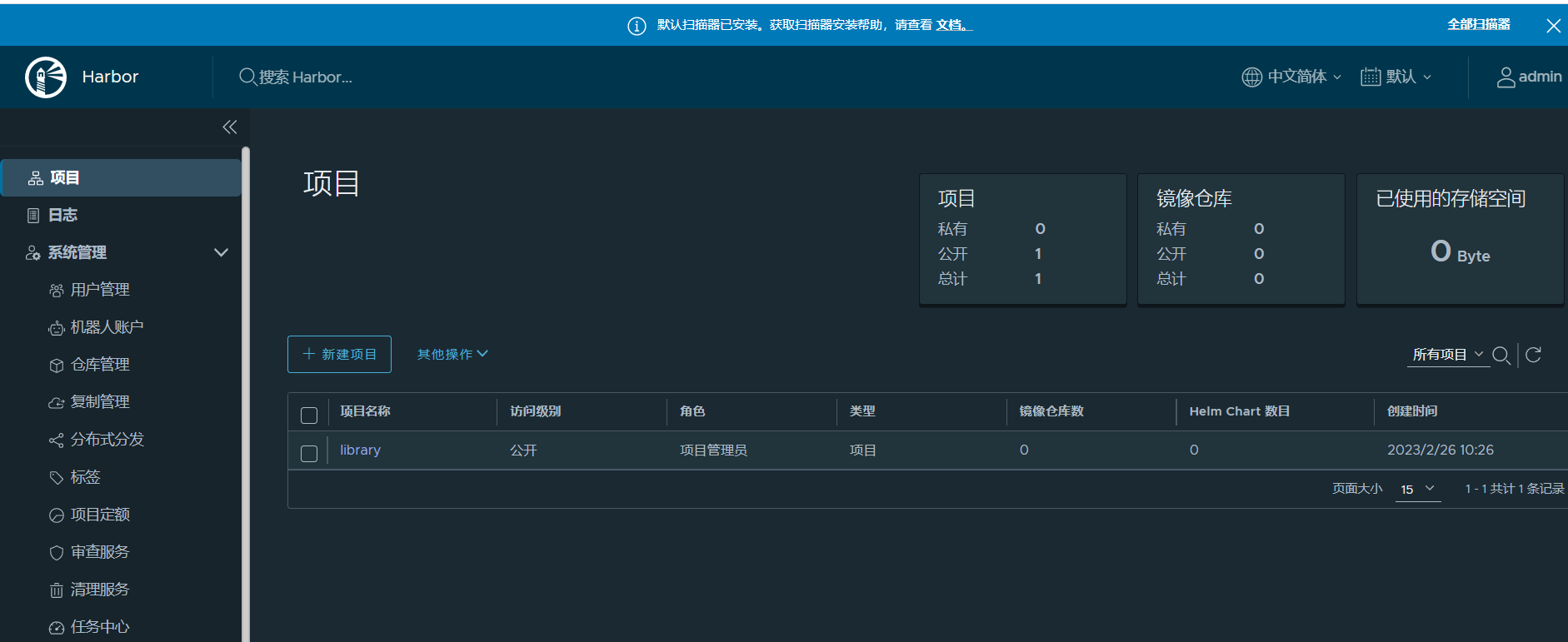
【云原生】k8s 离线部署讲解和实战操作
文章目录一、概述二、前期准备1)节点信息2)修改主机名和配置hosts3)配置ssh互信4)时间同步5)关闭防火墙6)关闭 swap7)禁用SELinux8)允许 iptables 检查桥接流量三、开始部署1&#x…...

【Kubernetes】第十一篇 - 滚动发布的介绍与实现
一,前言 上一篇,介绍了灰度发布和流量切分的集中方式,以及如何实现 k8s 的灰度发布; 本篇,介绍滚动发布的实现; 二,滚动发布简介 滚动发布 滚动发布,则是我们一般所说的无宕机发…...

【尊享版】如何系统构建你的思维认知模型?
超友们,早上好,国庆节快乐~ 今天为你带来的分享是《如何系统构建你的思维认知模型?》,主要分为三个部分: 第一部分:【实现爆发式成长的 10 个思维模型】 第二部分:【6 个不可不知的…...

urho3D编码约定
缩进样式类似于Allman(BSD),即在控制语句的下一行使用大括号,在同一级别缩进。在switch-case语句中,case与switch语句处于相同的缩进级别。 缩进使用4个空格而不是制表符。不应保留空行上的缩进。 类和结构名称以大写…...

Overleaf推广奖励:增加合作者的数量、解锁Dropbox同步和项目修改历史
Overleaf推广奖励 Overleaf是一个LaTeX\LaTeXLATEX在线编译器,它可以让你与合作者共同在线编辑文档。但是默认的免费账号仅能邀请一个合作者。那么如何增加合作者的数量呢? Overleaf推出了一个奖励计划,你邀请其他人注册Overleaf…...

ChatGPT的互补工具Perplexity的详细使用方法(持续更新)
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,科大讯飞比赛第三名,CCF比赛第四名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…...
【Linux驱动开发100问】如何编译Linux内核?
🥇今日学习目标:如何编译Linux内核? 🤵♂️ 创作者:JamesBin ⏰预计时间:10分钟 🎉个人主页:嵌入式悦翔园个人主页 🍁专栏介绍:Linux驱动开发100问 如何编译…...
15、条件概率、全概率公式、贝叶斯公式、马尔科夫链
条件概率定义:设A、B是两个事件,且,P(A) > 0 则称 为事件A发生的条件下事件B的条件概率对这个式子进行变形,即可得到概率的乘法公式:P(A) > 0 时,则P(B) > 0 时,则乍一看,…...
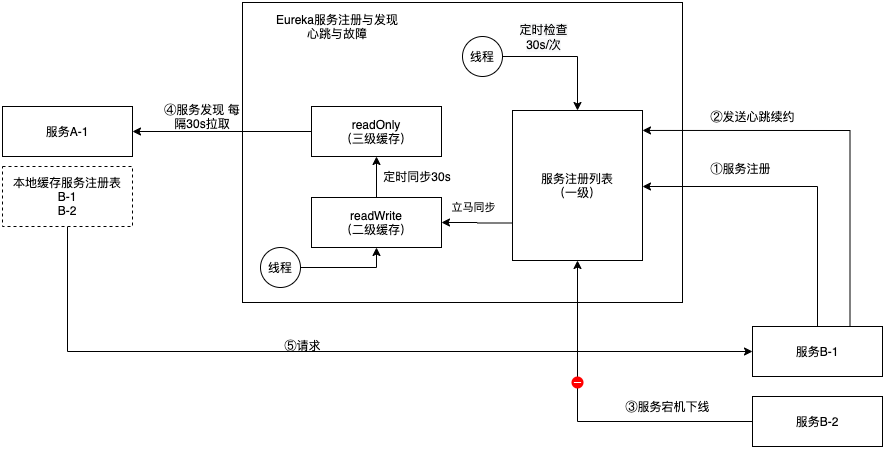
Eureka服务注册与发现
注册中心是分布式开发的核心组件之一,而Eureka是spring cloud推荐的注册中心实现。简单分析一下Eureka的原理。Eureka基础概念与流程1、服务注册在微服务架构中,一个服务提供者本质上也是一个Eureka客户端。启动时,会调用Eureka所提供的服务注…...

20230226 引用类型和指针类型的区别 - chatGPT
绝了,把chatGPT当百度之后真爽! 引用类型和指针类型都是C语言中的重要概念,它们都提供了访问和操作内存的方法,但它们之间有几个关键的区别。 1. 定义和初始化方式不同 指针类型的变量定义和初始化的方式是通过使用*符号来声明…...
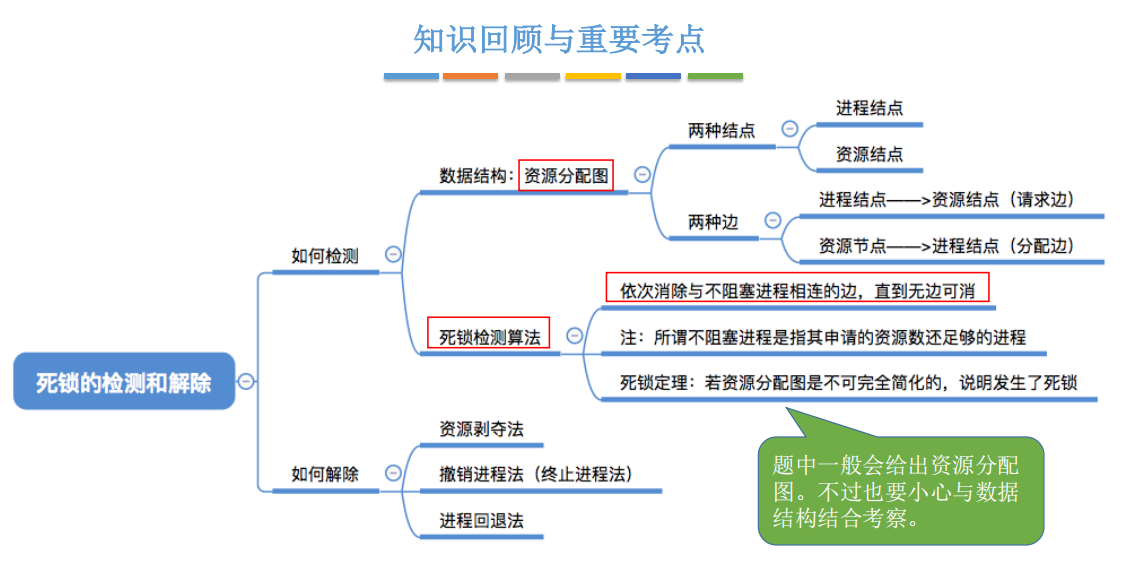
《操作系统》——第二章 进程与线程
目录 2.1.1进程的概念、组成、特征 2.1.2进程的状态与转换、进程的组织 2.1.3进程控制 2.1.4进程通信 2.1.5线程的概念 2.1.6线程的实现方式和多线程模型 2.2.1调度的概念、层次 2.2.2进程调度的时机、切换与过程、方式 2.2.4调度算法的评价指标 2.2.5调度算法(1) 2…...

网络原理之初识
目录 一. 网络互连 1. 局域网 2. 广域网 二. 网络通信基础 1. IP 地址 2. 端口号 3. 网络协议 4. 协议分层 5. TCP/IP 五层网络模型 (简述) 6. 网络数据传输的基本流程 一. 网络互连 随着时代的发展,越来越需要计算机之间互相通信&am…...
CAN总线开发一本全(4) - FlexCAN的驱动程序
CAN总线开发一本全(4) - FlexCAN的驱动程序 苏勇,2023年2月 文章目录CAN总线开发一本全(4) - FlexCAN的驱动程序引言从MindSDK获取FlexCAN驱动程序数据结构配置通信引擎的结构体类型访问MB的结构体类型配置ID过滤器的…...

如何分析linux tcp/ip 丢包问题
引用手把手教你用Dropwatch诊断问题通过dropwatch定位系统内核丢包Finding out if/why a server is dropping packetsgithub source coed: pavel-odintsov/drop_watchHow to drop a packet in Linux in more ways than one试试Linux下的ip命令,ifconfig已经过时了Ho…...

Unity资源提取技术解密:AssetRipper效能革命与实战指南
Unity资源提取技术解密:AssetRipper效能革命与实战指南 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper 在游戏开发迭代加速…...

Phi-3-mini-4k-instruct-gguf开发者案例:为微信小程序后端提供的轻量API服务
Phi-3-mini-4k-instruct-gguf开发者案例:为微信小程序后端提供的轻量API服务 1. 项目背景与需求 在开发微信小程序时,我们经常需要为前端提供智能文本处理能力,比如自动生成商品描述、智能客服回复、内容摘要等。传统方案要么需要调用第三方…...
:微服务架构详解与微服务部署,及同步问题总览(第一篇,总共三篇))
【Oracle篇】基于OGG 21c全程图形化实现9TB数据从Oracle 11g到19c的不停机迁移(上):微服务架构详解与微服务部署,及同步问题总览(第一篇,总共三篇)
💫《博主主页》: 🔎 CSDN主页: 奈斯DB 🔎 IF Club社区主页: 奈斯、 🔎 微信公众号: 奈斯DB 🔥《擅长领域》: 🗃️ 数据库…...
)
避坑指南:MoE训练中AllToAll通信的配置与性能调优(以DeepSpeed为例)
MoE训练实战:AllToAll通信性能调优与DeepSpeed配置避坑指南 当你在500张GPU的集群上启动MoE模型训练时,控制台突然刷出"AllToAll timeout"的红色警告——这不是假设场景,而是去年我们在训练千亿参数模型时真实遭遇的噩梦。AllToAll…...

为什么92%的Java团队TCC失败?阿里P8级专家复盘6大反模式与可立即上线的加固模板
第一章:为什么92%的Java团队TCC失败?阿里P8级专家复盘6大反模式与可立即上线的加固模板TCC(Try-Confirm-Cancel)作为分布式事务的经典模式,在高并发、多服务协同场景中本应提供强一致性保障,但阿里内部审计…...

Qt 实时数据可视化工程实践:环形缓冲区实践
目录 前言 一、架构设计 1.1 分层架构图 1.2 数据写入流 1.3 数据刷新流 (定时器驱动 → 视图更新) 1.4 核心设计思想 二、核心实现详解 2.1 RingBuffer:环形缓冲区实现 2.1.1 append函数(线程安全写入) 函数主体实现: …...

百川2-13B-4bits模型调优:OpenClaw任务响应速度提升50%的3个技巧
百川2-13B-4bits模型调优:OpenClaw任务响应速度提升50%的3个技巧 1. 问题背景与优化动机 去年冬天,当我第一次将百川2-13B-4bits模型接入OpenClaw时,发现一个奇怪现象:同样的自动化任务,在本地测试时响应飞快&#x…...

【SLAM实战解析】卡方检验在ORB-SLAM2外点剔除中的关键作用
1. 卡方检验在SLAM中的核心价值 第一次在ORB-SLAM2的代码里看到卡方检验时,我盯着那行chi2测试代码愣了半天。这个在统计学课本里见过的概念,怎么突然出现在视觉SLAM系统中?后来才发现,这简直是SLAM开发者处理异常值的"瑞士军…...
)
逆向实战:用Smali语法修改APK逻辑,实现一个简单的功能破解(附工具与源码)
逆向工程实战:用Smali语法解锁APK功能的全流程指南 在Android逆向工程领域,掌握Smali语法就像获得了一把打开APK内部逻辑的万能钥匙。不同于那些停留在理论层面的教程,本文将带你深入一个真实的逆向场景——如何通过修改Smali代码来解锁某个演…...
)
Java函数计算部署实战:从本地调试到生产环境上线的7个关键步骤(含阿里云/华为云/AWS对比)
第一章:Java函数计算部署全景概览Java函数计算是云原生场景下轻量级、事件驱动型服务的重要实现方式。它将传统Java应用的部署范式从虚拟机/容器迁移至按需执行、自动扩缩的无服务器架构,显著降低运维复杂度与资源闲置成本。开发者只需聚焦业务逻辑&…...