Flume 快速入门【概述、安装、拦截器】
文章目录
- 什么是 Flume?
- Flume 组成
- Flume 安装
- Flume 配置任务文件
- 应用示例
- 启动 Flume 采集任务
- Flume 拦截器
- 编写 Flume 拦截器
- 拦截器应用
什么是 Flume?
Flume 是一个开源的数据采集工具,最初由 Apache 软件基金会开发和维护。它的主要目的是帮助用户将大规模数据从各种数据源(如日志文件、网络数据源、消息队列等)采集、传输和加载到数据存储系统(如 Hadoop HDFS、Apache HBase、Apache Hive 等)。
Flume 旨在处理大规模数据流,以便进行数据分析和处理。
Flume 组成
Flume (配置)主要由以下 4 个部分组成:
1. 数据源(Source): Flume 可以从多种数据源收集数据,例如日志文件、网络流、消息队列等。
2. 通道(Channel): 采集的数据被存储在通道中,等待传输到目标数据存储系统。Flume 支持多种不同类型的通道,如内存通道、文件通道和 Kafka 通道。
3. 拦截器(Interceptor): 拦截器允许用户对采集的数据进行预处理和转换,以满足特定需求。
4. 接收器(Sink): 接收器将数据传输到目标数据存储系统,如 Hadoop HDFS、HBase、Kafka 等。
Flume 通过灵活的配置,允许用户根据其数据采集需求来定义数据流的整个流程,包括数据源、通道、拦截器和接收器。
这使得 Flume 成为处理大规模数据采集和传输任务的强有力工具,构建数据管道,将分散的数据整合到中心存储或处理系统中,用于实时或者离线数据分析和报告。
Flume 安装
官方安装包下载地址:http://archive.apache.org/dist/flume
本篇博客使用的版本为:Flume-1.10.1
1. 解压
tar -zxvf apache-flume-1.10.1-bin.tar.gz -C /opt/
2. 配置环境变量
vim /etc/profile
文件末尾添加:
#FLUME_HOME
export FLUME_HOME=/opt/flume-1.10.1
export PATH=$PATH:$FLUME_HOME/bin
刷新环境变量:source /etc/profile
其实到这里,Flume 算是安装完了,但是为了后期使用方便,这里再调整一下配置参数。
修改日志存储与输出:
cd $FLUME_HOMEvim conf/log4j2.xml
在该文件中修改日志文件的存储目录(正文第 3 行)
<Property name="LOG_DIR">/opt/flume-1.10.1/logs</Property>
在该文件中添加日志控制台输出方式(正文末尾)
<AppenderRef ref="Console" />
默认只有 LogFile 日志文件的输出方式。

修改堆内存大小:
cd $FLUME_HOMEvim conf/flume-env.sh
如果是本地学习或者测试环境建议调小一点:
export JAVA_OPTS="-Xms512m -Xmx2048m -Dcom.sun.management.jmxremote"
我这里调整最小为 512MB,最大 2048MB,也可以将最大和最小调整为一样的,避免进行内存交换。
Flume 配置任务文件
Flume 最主要的内容就是配置任务文件了,在文章开头提到过,主要由四部分组成:
-
数据源(Source)
-
通道(Channel)
-
拦截器(Interceptor)
-
接收器(Sink)
我们可以根据需求,进入 Flume 的官方网站,查阅各项参数如何进行配置,按照要求配置即可。
配置查阅网站:Flume 1.10.1 User Guide
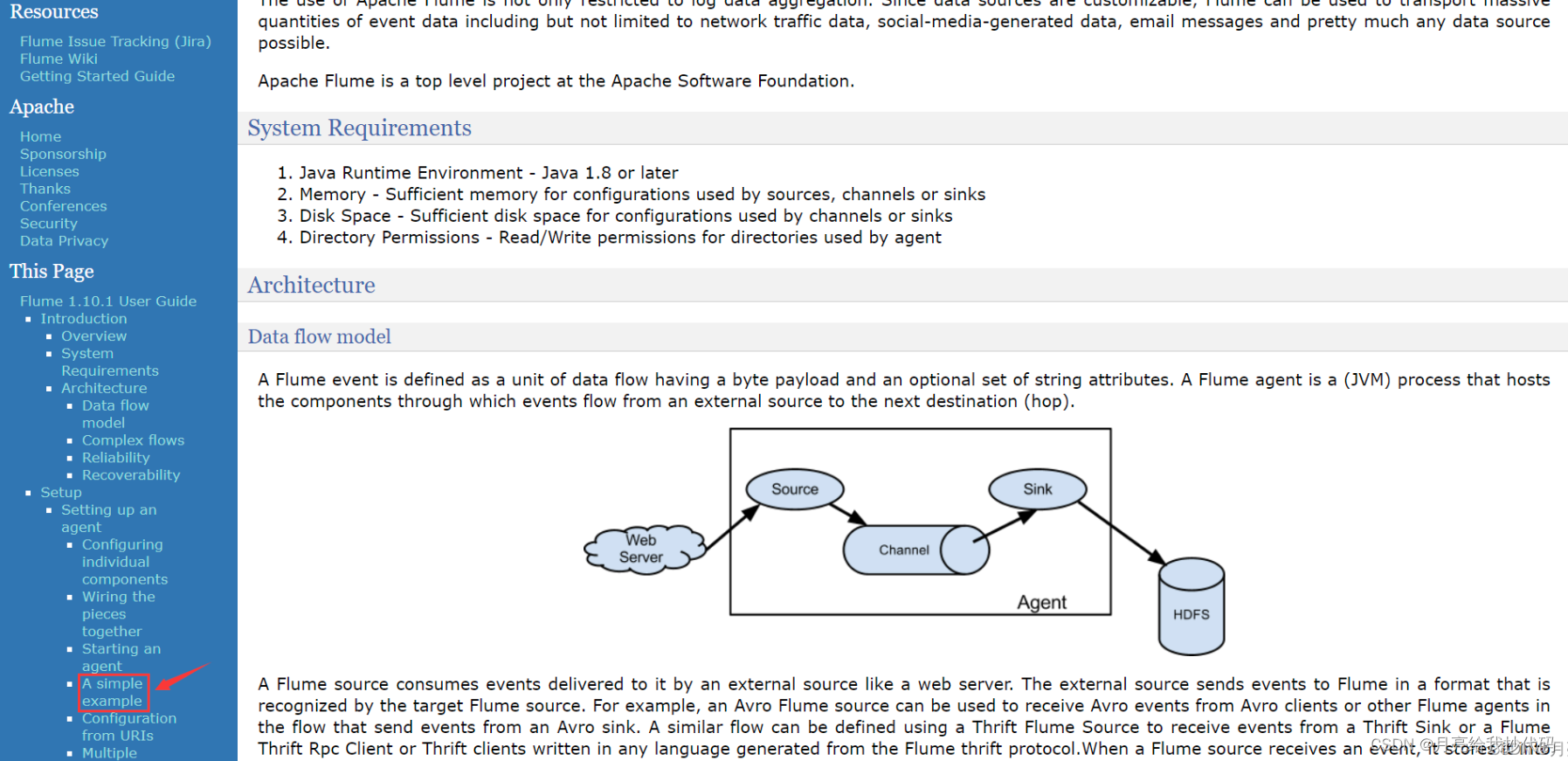
其中给出了一个模板文件,内容如下所示:
# example.conf: A single-node Flume configuration# Name the components on this agent 声明变量名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1# Describe/configure the source 配置数据源
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444# Describe the sink 配置接收器(存储源)
a1.sinks.k1.type = logger# Use a channel which buffers events in memory 配置管道参数
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel 组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
根据该模板文件就可以来快速构建一个数据采集的配置文件啦。
应用示例
将 Maxwell 发送到 Kafka 消息队列中的数据采集到 HDFS 上。
# --------- 声明变量名称 ---------
a1.sources = r1
a1.sinks = k1
a1.channels = c1# --------- 配置数据源 ---------
# 指定数据源类型
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
# 指定连接地址
a1.sources.r1.kafka.bootstrap.servers = hadoop120:9092,hadoop121:9092,hadoop122:9092
# 指定消费者组别,防止多个消费者之间引发数据冲突
a1.sources.r1.kafka.consumer.group.id = flume1
# 指定主题名称,这里需要和 MaxWell 指定发送的主题保持一致,否则会采集不到数据
a1.sources.r1.kafka.topics = topic_db# --------- 配置接收器 ---------
# 指定存储源类型
a1.sinks.k1.type = hdfs
# 动态规划 HDFS 写入路径
a1.sinks.k1.hdfs.path = /test/%{tableName}_inc/%Y/%m/%d/# 当以下值中的其中一个满足时,触发滚动操作,将数据写入到新的文件中(避免小文件过多)
# 根据运行时间判定(s),测试环境调小,开发环境30m-1h
a1.sinks.k1.hdfs.rollInterval = 10
# 根据数据量大小判定(B),128 MB
a1.sinks.k1.hdfs.rollSize = 134217728
# 根据文件的条数判断,为 0 时表示不依据该参数
a1.sinks.k1.hdfs.rollCount = 0# 压缩文件
# 指定文件类型为压缩流
a1.sinks.k1.hdfs.fileType = CompressedStream
# 指定数据压缩格式
a1.sinks.k1.hdfs.codeC = gzip# --------- 配置通道 ---------
# 通道类型
a1.channels.c1.type = file
# 检查点存储路径
a1.channels.c1.checkpointDir = /opt/module/flume-1.10.1/file-channel/checkpoint1
# 用于存储日志文件的目录,多个路径用逗号分隔
a1.channels.c1.dataDirs = /opt/module/flume-1.10.1/file-channel/data1
# 指定允许等待的时间
a1.channels.c1.keep-alive = 6# --------- 组装 ---------
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动 Flume 采集任务
cd $FLUME_HOME./bin/flume-ng agent -c conf/ -f job_file -n a1
参数解析:
./bin/flume-ng:flume-ng是 Flume 的执行脚本,它用于启动 Flume 的agent实例。
-
agent:这告诉 Flume-ng 启动一个代理实例,也就是一个数据采集和传输任务的执行单元。 -
-c conf/:指定 Flume 配置文件的目录。 -
-f job_file:指定 Flume 任务配置文件的参数,其中配置文件包含了数据源、通道、接收器以及数据处理的详细信息。 -
-n a1:指定代理实例的名称,与配置文件中的对应。
Flume 拦截器
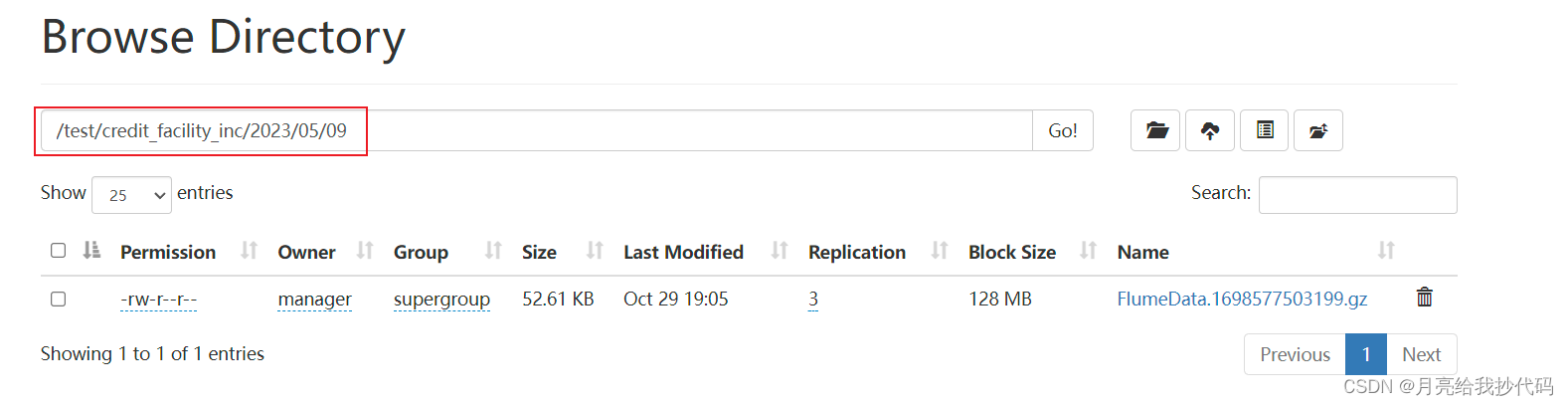
当我们在配置文件中定义了动态参数时,例如上方示例中接收器的配置语句:
a1.sinks.k1.hdfs.path = /test/%{tableName}_inc/%Y/%m/%d/
我们设想的是将表名称和年月日进行动态规划,但在未设置拦截器时,这些动态参数值都会被默认为空,如果是系统预定义的参数则为系统设定值。
如下所示:

其中 tableName 是自定义的值,Flume 系统并没有对其进行预定义,所以为空,但 %Y %m %d 这三个值系统默认为当前的日期值,所以不为空。
如果想将上述值设定为希望出现的值,此时便引出了拦截器的概念。通过对拦截器的配置,将采集的数据进行预处理和转换,以满足特定需求。
编写 Flume 拦截器
在 IDEA 中编写拦截器代码,然后打包上传,使用依赖如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.work</groupId><artifactId>intercepted</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><!-- JSON 解析包--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.32</version></dependency><!-- flume 包,不打包该 Jar 包--><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.10.1</version><scope>provided</scope></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>
注意,JDK 版本与平台保持一致。
拦截器实现,用于设定表头与写入日期:
package com.work.flume.interceptor;import com.alibaba.fastjson.JSONException;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;/*** @author Moon_coder* @version 1.0* @date 2023/10/29 17:32*/
public class TableNameAndTimestamp implements Interceptor {/*** 初始化方法*/@Overridepublic void initialize() {}/**** 处理单条数据* @param event* @return*/@Overridepublic Event intercept(Event event) {try{// 1.获取头数据Map<String, String> headers = event.getHeaders();// 2.获取数据内容,将字节数据转换为字符串String log = new String(event.getBody(), StandardCharsets.UTF_8);// 3.将字符串转换为 JSON 对象JSONObject jsonObject = JSONObject.parseObject(log);// 4.获取表名String table = jsonObject.getString("table");// 5.获取时间,我的数据是经 Maxwell 采集的,Maxwell 中的数据是 10 位时间戳,不含毫秒,将数据存入 HDFS 时 *1000String ts = jsonObject.getString("ts") + "000";// 6.更新头数据信息headers.put("tableName",table);headers.put("timestamp",ts);}catch (JSONException e){// 如果不是 JSON 数据,则将该数据定义为脏数据return null;}return event;}/**** 批量数据处理方法* @param events* @return*/@Overridepublic List<Event> intercept(List<Event> events) {// 批量处理 event 同时实现过滤功能events.removeIf(next -> intercept(next) == null);return events;}/*** 关闭方法*/@Overridepublic void close() {}// TODO 返回拦截器类public static class Builder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new TableNameAndTimestamp();}@Overridepublic void configure(Context context) {}}}
类名或 Jar 包名称都没有特别要求,自定义即可。
注意: 当我们在往头信息里面放东西时,需要与键名一一对应。
// 6.更新头数据信息headers.put("tableName",table);headers.put("timestamp",ts);
如果是自定义的值,名称与 Flume 配置文件设定的必须对应:

如果是系统预定义的值,则需要在官方网站中查询其对应的键名。例如这里出现的 %Y %m %d 这三个值,在接收器的参数定义那里即可查询到(HDFS Sink¶),如下所示:

这里官方给出了提示,说 对于所有与时间相关的转义序列,事件的标头中必须存在一个关键字为 “timestamp” 的标头,所以在拦截器中对头信息的时间进行操作时,对应的键名为 timestamp。
拦截器应用
将打包好的拦截器 Jar 包上传到 Flume 中的 lib 目录下,然后在 Flume 任务配置文件中添加拦截器配置,如下所示:
# --------- 拦截器 ---------
# 拦截器名称
a1.sources.r1.interceptors = i1
# 编写的拦截器全类名 + $Builder 标识符
a1.sources.r1.interceptors.i1.type = com.work.flume.interceptor.TableNameAndTimestamp$Builder
再次执行上方的示例任务,可以看到配置完拦截器后,头信息已经达到了我们预期的结果。
相关文章:
Flume 快速入门【概述、安装、拦截器】
文章目录 什么是 Flume?Flume 组成Flume 安装Flume 配置任务文件应用示例启动 Flume 采集任务 Flume 拦截器编写 Flume 拦截器拦截器应用 什么是 Flume? Flume 是一个开源的数据采集工具,最初由 Apache 软件基金会开发和维护。它的主要目的是…...
【pandas技巧】group by+agg+transform函数
目录 1. group by单个字段单个聚合 2. group by单个字段多个聚合 3. group by多个字段单个聚合 4. group by多个字段多个聚合 5. transform函数 studentsgradesexscoremoney0小狗小学部female958441小猫小学部male938362小鸭初中部male838543小兔小学部female909314小花小…...
一文解读WordPress网站的各类缓存-老白博客
缓存是一种重要的WordPress优化手段,用于提高网站的性能和加载速度。减少计算量,有效提升响应速度,让有限的资源服务更多的用户。本文老白博客便从自己的使用简单给大家介绍下WordPress的缓存,包括 站点缓存(Page Cach…...

从零开始:开发直播商城APP的技术指南
时下,直播商城APP已经成了线上购物、电子商务的核心组成,本文将为您提供一个全面的技术指南,帮助您从零开始开发一个直播商城APP。我们将涵盖所有关键方面,包括技术堆栈、功能模块、用户体验和安全性。 第一部分:技术…...
GZ035 5G组网与运维赛题第6套
2023年全国职业院校技能大赛 GZ035 5G组网与运维赛项(高职组) 赛题第6套 一、竞赛须知 1.竞赛内容分布 竞赛模块1--5G公共网络规划部署与开通(35分) 子任务1:5G公共网络部署与调试(15分) …...

分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)
分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制) 目录 分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matla…...

【Qt】QString怎么转成int
2023年10月29日,周日晚上 第一种方法 这种方法会尝试将 QString 对象转换为 int 类型。如果转换成功,将返回转换后的 int 值;如果转换失败(例如,字符串中包含非数字字符),则返回 0。 QString…...

ubuntu 22.04 安装python-pcl
ubuntu 22.04 安装python-pcl 安装python-pcl修复bug 由于python-pcl库基本已经停止维护,所以Ubuntu22.04 在使用pip install python-pcl安装的时候会出现版本不适配的原因 安装python-pcl 使用Ubuntu22系统自带python3安装python-pcl,随后将下载的包拷…...

【题解】[GenshinOI Round 3 ]P9817 lmxcslD
题目传送门 分析 看到这道题我一开始是有点懵的,但是看了看数据范围,发现有几个点有 n 为质数 的特殊性质,结论先行,大胆猜测是不是可以贪心,所以先打了一个最傻的代码上去试试. void solve(){cin >> n >&…...
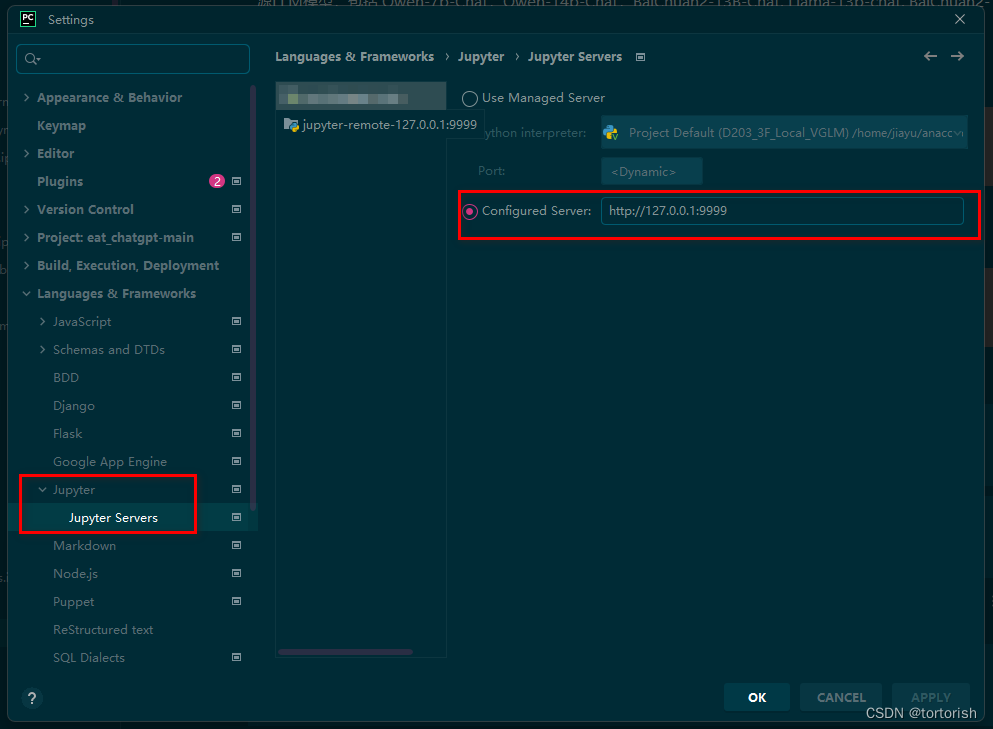
在pycharm中,远程操作服务器上的jupyter notebook
一、使用场景 现在我们有两台电脑,一台是拥有高算力的服务器,另一台是普通的轻薄笔记本电脑。如何在服务器上运行jupyter notebook,同时映射到笔记本电脑上的pycharm客户端中进行操作呢? 二、软件 pycharm专业版,jupy…...

SQL 运算符
SQL 运算符 运算符是保留字或主要用于 SQL 语句的 WHERE 子句中的字符,用于执行操作,例如:比较和算术运算。 这些运算符用于指定 SQL 语句中的条件,并用作语句中多个条件的连词。 常见运算符有以下几种: 算术运算符比…...

中间件安全-CVE 复现K8sDockerJettyWebsphere漏洞复现
目录 服务攻防-中间件安全&CVE 复现&K8s&Docker&Jetty&Websphere中间件-K8s中间件-Jetty漏洞复现CVE-2021-28164-路径信息泄露漏洞CVE-2021-28169双重解码信息泄露漏洞CVE-2021-34429路径信息泄露漏洞 中间件-Docker漏洞复现守护程序 API 未经授权访问漏洞…...

系列九、什么是Spring bean
一、什么是Spring bean 一句话,被Spring容器管理的bean就是Spring bean。...

轻量封装WebGPU渲染系统示例<4>-CubeMap/天空盒(源码)
当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/version-1.01/src/voxgpu/sample/ImgCubeMap.ts 此示例渲染系统实现的特性: 1. 用户态与系统态隔离。 2. 高频调用与低频调用隔离。 3. 面向用户的易用性封装。 4. 渲染数据和渲染机制分离。 5. 用户…...

Linux 环境变量 二
目录 获取环境变量的后两种方法 环境变量具有全局属性 内建命令 和环境变量相关的命令 c语言访问地址 重新理解地址 地址空间 获取环境变量的后两种方法 main函数的第三个参数 :char* env[ ] 也是一个指针数组,我们可以把它的内容打印出来看看。 …...
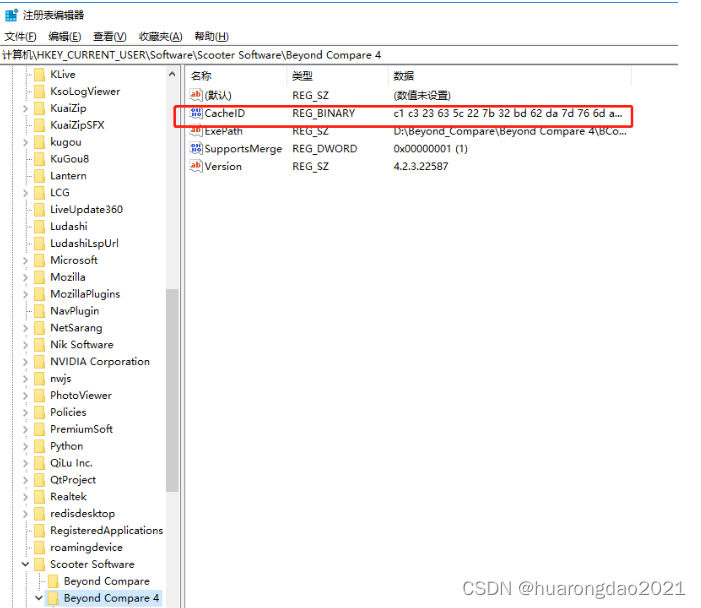
Beyond Compare4 30天试用到期的解决办法
相信很多小伙伴都有在使用Beyond Compare 4软件,如果我们没有激活该软件,就只有30天的评估使用期,那么过了这30天后我们怎么继续使用呢?下面小编就来为大家介绍方法。 打开Beyond Compare4,提示已经超出30天试用期限制…...
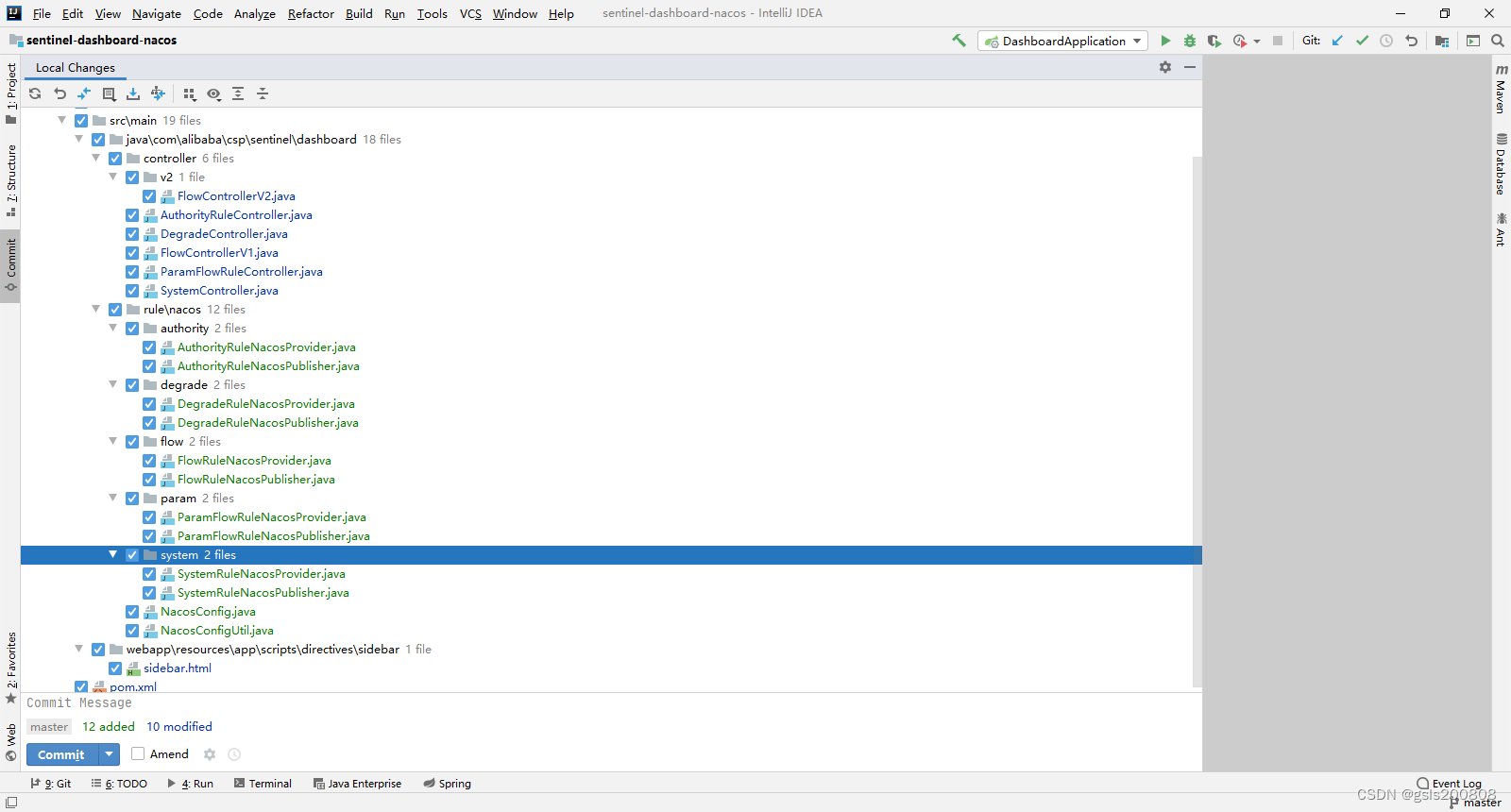
sentinel规则持久化-规则同步nacos-最标准配置
官方参考文档: 动态规则扩展 alibaba/Sentinel Wiki GitHub 需要修改的代码如下: 为了便于后续版本集成nacos,简单讲一下集成思路 1.更改pom 修改sentinel-datasource-nacos的范围 将 <dependency><groupId>com.alibaba.c…...

【Linux】tail命令使用
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。 语法 tail [参数] [文件] tail命令 -Linux手册页 著者 由保罗鲁宾、大卫麦肯齐、伊恩兰斯泰勒和吉姆梅耶林撰写。 命令选项及作用 执行令 tail --help 执行命令结果 参…...

【数据结构】面试OJ题——时间复杂度2
目录 一:移除元素 思路: 二:删除有序数组中的重复项 思路: 三:合并两个有序数组 思路1: 什么?你不知道qsort() 思路2: 一:移除元素 27. 移…...
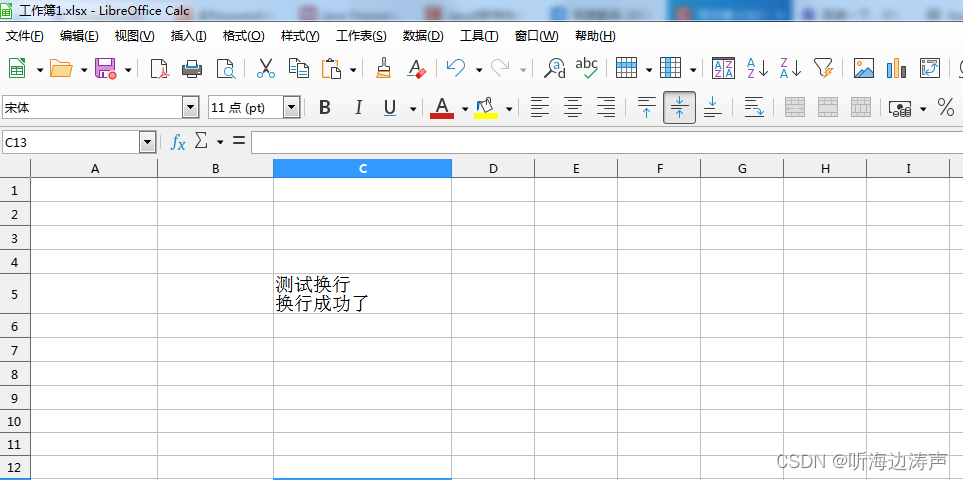
LibreOffice编辑excel文档如何在单元格中输入手动换行符
用WPS编辑excel文档的时候,要在单元格中输入手动换行符,可以先按住Alt键,然后回车。 而用LibreOffice编辑excel文档,要在单元格中输入手动换行符,可以先按住Ctrl键,然后回车。例如:...

Raw Accel深度解析:从零掌握Windows内核级鼠标加速的终极指南
Raw Accel深度解析:从零掌握Windows内核级鼠标加速的终极指南 【免费下载链接】rawaccel kernel mode mouse accel 项目地址: https://gitcode.com/gh_mirrors/ra/rawaccel 你是否厌倦了Windows默认鼠标加速的不稳定表现?是否在游戏中苦苦寻找更精…...

终极M3U8视频下载指南:5个技巧轻松掌握开源工具
终极M3U8视频下载指南:5个技巧轻松掌握开源工具 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 想要下载在线视频却总是失败?面对M3U8格式束手无策&#x…...

HoRain云--AI 底层架构
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

3个高效窗口管理技巧:用AlwaysOnTop重新定义你的多任务工作流
3个高效窗口管理技巧:用AlwaysOnTop重新定义你的多任务工作流 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否曾在编写代码时,为了查看API文档而反…...

C++lambda表达式深入解析
Clambda表达式深入解析lambda表达式是C11引入的匿名函数特性,它提供了一种简洁的方式来定义内联函数对象,特别适合用于STL算法和回调函数。lambda表达式的基本语法包括捕获列表、参数列表、返回类型和函数体。#include #include #include #includevoid b…...

巴别鸟vs坚果云:企业云盘同步机制踩坑与实战配置
干企业网盘这行,最怕听到用户说"同步慢"。我们2019年上线第一版云盘时,同步1GB的CAD图纸包要40分钟,用户骂完就跑。踩了三年坑才知道,"能同步"和"同步好用"根本是两回事。 本文从踩坑实录加配置实战…...

JMeter接口测试实战:从登录闭环到分布式压测
1. 为什么接口测试不能只靠“点点点”——从一个被忽略的500错误说起我第一次在客户现场接手一个电商后台系统时,开发说“所有接口都测过了,Postman跑了一遍,没问题”。上线前夜,支付回调接口突然返回500,日志里只有一…...

蒙古语AI语音落地难?ElevenLabs最新v3.2模型支持率提升至98.7%,但90%开发者忽略这5个编码陷阱
更多请点击: https://intelliparadigm.com 第一章:蒙古语AI语音落地的现实困境与技术拐点 蒙古语作为中国少数民族语言中使用人口较多、语法高度黏着、音系复杂的阿尔泰语系代表,其AI语音技术长期受限于低资源特性——标准语音数据集不足50小…...

第九届蓝桥杯国赛b组--备战国赛版h
第一题:0换零钞 - 蓝桥云课 模拟 #include <bits/stdc.h> using namespace std; int main() {int a,b,c0;for(a1;a<200;a)//一元钞票{for(b1;b<100;b)//两元钞票{for(c1;c<40;c)//五元钞票{if(ba*10&&(ab*2c*5)200){cout<<abc<&l…...

别再乱加“impressionism”!Midjourney印象派风格生效的3个前置条件,90%新手忽略第2条
更多请点击: https://codechina.net 第一章:印象派风格在Midjourney中的本质误读与认知纠偏 当用户在 Midjourney 中输入 --style raw --s 750 并附加诸如 “impressionist painting” 或 “Monet style” 等提示词时,模型实际响应的并非印…...