高级深入--day38
阳光热线问政平台
http://wz.sun0769.com/index.php/question/questionType?type=4
爬取投诉帖子的编号、帖子的url、帖子的标题,和帖子里的内容。
items.py
import scrapyclass DongguanItem(scrapy.Item):# 每个帖子的标题title = scrapy.Field()# 每个帖子的编号number = scrapy.Field()# 每个帖子的文字内容content = scrapy.Field()# 每个帖子的urlurl = scrapy.Field()
spiders/sunwz.py
Spider 版本
# -*- coding: utf-8 -*-import scrapy
from dongguan.items import DongguanItemclass SunSpider(CrawlSpider):name = 'sun'allowed_domains = ['wz.sun0769.com']url = 'http://wz.sun0769.com/index.php/question/questionType?type=4&page='offset = 0start_urls = [url + str(offset)]def parse(self, response):# 取出每个页面里帖子链接列表links = response.xpath("//div[@class='greyframe']/table//td/a[@class='news14']/@href").extract()# 迭代发送每个帖子的请求,调用parse_item方法处理for link in links:yield scrapy.Request(link, callback = self.parse_item)# 设置页码终止条件,并且每次发送新的页面请求调用parse方法处理if self.offset <= 71130:self.offset += 30yield scrapy.Request(self.url + str(self.offset), callback = self.parse)# 处理每个帖子里def parse_item(self, response):item = DongguanItem()# 标题item['title'] = response.xpath('//div[contains(@class, "pagecenter p3")]//strong/text()').extract()[0]# 编号item['number'] = item['title'].split(' ')[-1].split(":")[-1]# 文字内容,默认先取出有图片情况下的文字内容列表content = response.xpath('//div[@class="contentext"]/text()').extract()# 如果没有内容,则取出没有图片情况下的文字内容列表if len(content) == 0:content = response.xpath('//div[@class="c1 text14_2"]/text()').extract()# content为列表,通过join方法拼接为字符串,并去除首尾空格item['content'] = "".join(content).strip()else:item['content'] = "".join(content).strip()# 链接item['url'] = response.urlyield item
CrawlSpider 版本
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from dongguan.items import DongguanItem
import timeclass SunSpider(CrawlSpider):name = 'sun'allowed_domains = ['wz.sun0769.com']start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4&page=']# 每一页的匹配规则pagelink = LinkExtractor(allow=('type=4'))# 每个帖子的匹配规则contentlink = LinkExtractor(allow=r'/html/question/\d+/\d+.shtml')rules = [# 本案例为特殊情况,需要调用deal_links方法处理每个页面里的链接Rule(pagelink, process_links = "deal_links", follow = True),Rule(contentlink, callback = 'parse_item')]# 需要重新处理每个页面里的链接,将链接里的‘Type&type=4?page=xxx’替换为‘Type?type=4&page=xxx’(或者是Type&page=xxx?type=4’替换为‘Type?page=xxx&type=4’),否则无法发送这个链接def deal_links(self, links):for link in links:link.url = link.url.replace("?","&").replace("Type&", "Type?")print link.urlreturn linksdef parse_item(self, response):print response.urlitem = DongguanItem()# 标题item['title'] = response.xpath('//div[contains(@class, "pagecenter p3")]//strong/text()').extract()[0]# 编号item['number'] = item['title'].split(' ')[-1].split(":")[-1]# 文字内容,默认先取出有图片情况下的文字内容列表content = response.xpath('//div[@class="contentext"]/text()').extract()# 如果没有内容,则取出没有图片情况下的文字内容列表if len(content) == 0:content = response.xpath('//div[@class="c1 text14_2"]/text()').extract()# content为列表,通过join方法拼接为字符串,并去除首尾空格item['content'] = "".join(content).strip()else:item['content'] = "".join(content).strip()# 链接item['url'] = response.urlyield item
pipelines.py
# -*- coding: utf-8 -*-# 文件处理类库,可以指定编码格式
import codecs
import jsonclass JsonWriterPipeline(object):def __init__(self):# 创建一个只写文件,指定文本编码格式为utf-8self.filename = codecs.open('sunwz.json', 'w', encoding='utf-8')def process_item(self, item, spider):content = json.dumps(dict(item), ensure_ascii=False) + "\n"self.filename.write(content)return itemdef spider_closed(self, spider):self.file.close()
settings.py
ITEM_PIPELINES = {'dongguan.pipelines.DongguanPipeline': 300,
}# 日志文件名和处理等级
LOG_FILE = "dg.log"
LOG_LEVEL = "DEBUG"
在项目根目录下新建main.py文件,用于调试
from scrapy import cmdline
cmdline.execute('scrapy crawl sunwz'.split())
执行程序
py2 main.py相关文章:

高级深入--day38
阳光热线问政平台 http://wz.sun0769.com/index.php/question/questionType?type4 爬取投诉帖子的编号、帖子的url、帖子的标题,和帖子里的内容。 items.py import scrapyclass DongguanItem(scrapy.Item):# 每个帖子的标题title scrapy.Field()# 每个帖子的编…...
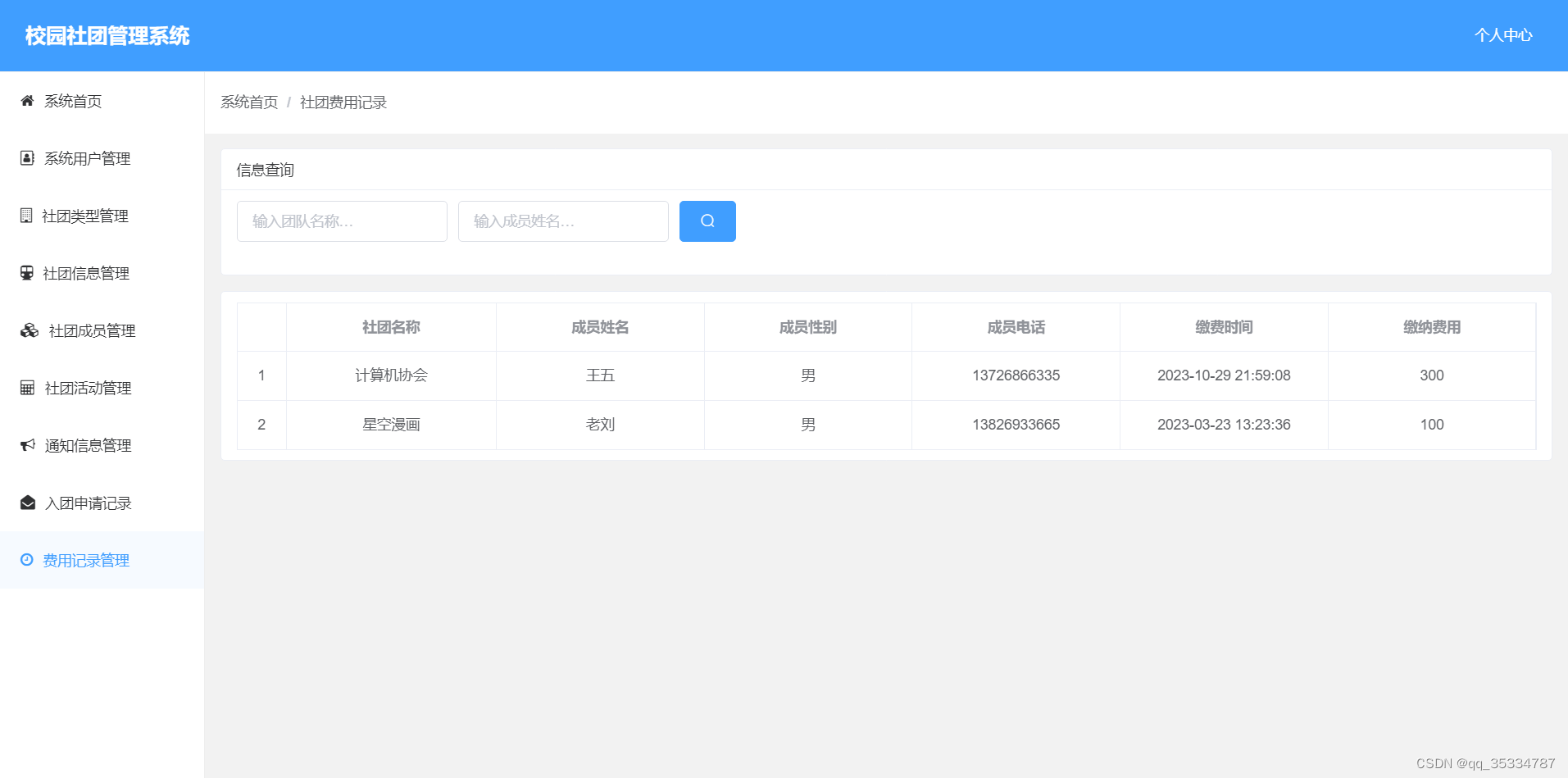
基于springboot,vue校园社团管理系统
开发工具:IDEA 服务器:Tomcat9.0, jdk1.8 项目构建:maven 数据库:mysql5.7 系统分前后台,项目采用前后端分离 前端技术:vueelementUI 服务端技术:springbootmybatis-plus 本系…...

广州华锐互动:VR虚拟现实物理学习平台,开启数字化教学新格局
随着虚拟现实(VR)技术的不断发展,越来越多的领域开始应用这一技术。广州华锐互动开发的VR虚拟现实物理学习平台就得到了广泛应用,平台涉及力学、光学、热学等初中物理知识,还包含了物理名人、实验器具、物理现象的还原和学习,相比…...

【tio-websocket】8、T-IO对半包和粘包的处理
介绍 t-io对数据的解码是在DecodeRunnable中完成的,一个TCP连接对应一个DecodeRunnable半包粘包的处理也都在DecodeRunnable中完成的关于DecodeRunnable 先贴上 DecodeRunnable 的源代码: import java.nio.BufferUnderflowException; import java.nio.ByteBuffer; import j…...

【Linux】安装与配置虚拟机及虚拟机服务器坏境配置与连接
目录 操作系统介绍 什么是操作系统 常见操作系统 UNIX操作系统 linux操作系统 mac操作系统 嵌入式操作系统 个人版本和服务器版本的区别 安装VMWare虚拟机 VMWare虚拟网卡 编辑 配置虚拟网络编辑器 编辑 安装配置Windows Server 2012 R2 安装Windows Server 2…...

Redis常识
文章目录 缓存的三个风险数据结构淘汰策略 和 过期删除策略过期删除淘汰 如何理解单线程redis特性复制gossip协议事务(和mysql不同,是不严格的事务 )集群(高可用)管道持久化 缓存的三个风险 缓存雪崩(缓存…...

Instant,LocalDate,LocalTime,LocalDateTime和ZonedDateTime
Instant 封装了从 1970-01-01T00:00:00Z 开始的秒数,相当于时间戳。 主要有两个属性: private final long seconds; private final int nanos;LocalDate 用于表示日期,包括年、月、日,例如 2017-12-03。 主要有三个属性&…...

Web入门笔记
Web入门笔记 HTTP协议 超文本传输协议 规定了浏览器和服务器之间数据传输的规则,请问数据和响应数据的格式 基于TCP请求-响应模式一次请求对应一次响应无状态的协议 请问数据格式 浏览器版本:解决浏览器兼容问题。GET请求体:存放请求参数…...

Linux网络编程二(TCP三次握手、四次挥手、TCP滑动窗口、MSS、TCP状态转换、多进程/多线程服务器实现)
TCP三次握手 TCP三次握手(TCP three-way handshake)是TCP协议建立可靠连接的过程,确保客户端和服务器之间可以进行可靠的通信。下面是TCP三次握手的详细过程: 假设客户端为A,服务器为B 1、第一次握手(SYN1,seq500&…...
C#和.NET Framework)
C#核心笔记——(一)C#和.NET Framework
C#是一种通用的,类型安全的面向对象编程语言。其目标是提高程序员生产力。 一.面向对象 C#实现了丰富的面向对象范式,包括封装、继承、多态。 C#面向对象特性包括: 统一的类型系统 类与接口 属性、方法、事件 C#支持纯函数模式 二、类型安…...

【2023年冬季】华为OD统一考试(B卷)题库清单(已收录345题),又快又全的 B 卷题库大整理
目录 专栏导读华为OD机试算法题太多了,知识点繁杂,如何刷题更有效率呢? 一、逻辑分析二、数据结构1、线性表① 数组② 双指针 2、map与list3、队列4、滑动窗口5、二叉树6、并查集7、栈 三、算法1、基础算法① 贪心算法② 二分查找③ 分治递归…...

云服务器的先驱,亚马逊云科技海外云服务器领军者
随着第三次工业革命的发展,移动互联网技术带来的信息技术革命为我们的生活带来了极大的便捷。其中,不少优秀的云服务器产品发挥了不可低估的作用,你或许听说过亚马逊云科技、谷歌GCP、IBM Cloud等优秀的海外云服务器。那么云服务器有哪些&…...
QT webengine显示HTML简单示例
文章目录 参考示例1TestWebenqine.promainwindow.hmainwindow.cppmain.cpp效果 示例2 (使用setDevToolsPage函数)main.cpp效果 参考 QT webengine显示HTML简单示例 示例1 编译器 : Desktop Qt 5.15.2 MSVC2019 64bit编辑器: QtCreator代码: TestWebenqine.pro # TestWeben…...
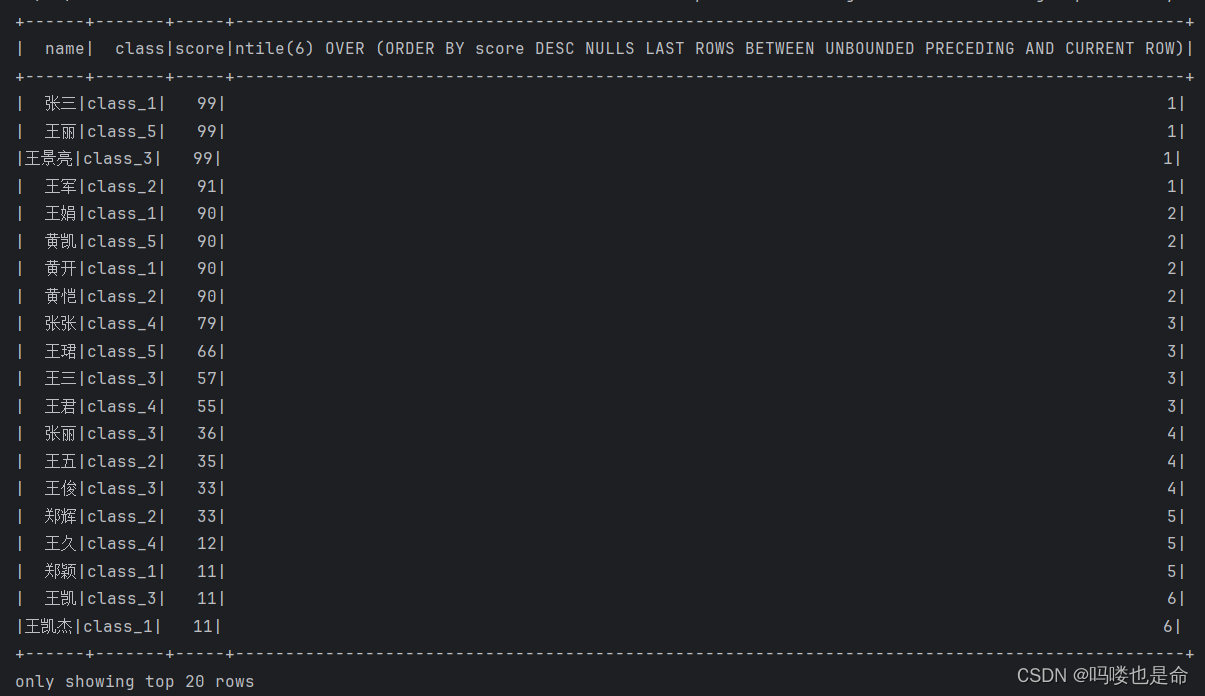
Spark_SQL函数定义(定义UDF函数、使用窗口函数)
一、UDF函数定义 (1)函数定义 (2)Spark支持定义函数 (3)定义UDF函数 (4)定义返回Array类型的UDF (5)定义返回字典类型的UDF 二、窗口函数 (1&…...

【Leetcode】【每日一题】【中等】274. H 指数
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer。https://leetcode.cn/problems/h-index/description/?envTyped…...

MySQL读写分离技术及实现方案
MySQL读写分离技术及实现方案 本文主要介绍了MySQL读写分离技术的原理、实现方案以及示例。通过使用读写分离技术,可以提高数据库的性能,降低服务器的压力。 一、MySQL读写分离技术简介 读写分离是指将数据库的读操作和写操作分别分配到不同的服务器上…...
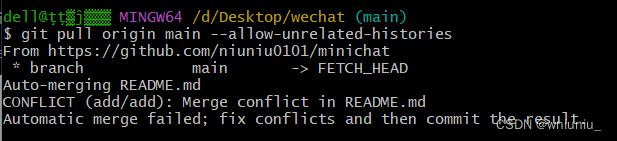
git 推送到github远程仓库细节处理(全网最良心)
我查看了很多网上的教程都不是很好 我们先在github创建一个仓库,且初始化 readme 我们到本地文件初始化仓库 添加远程仓库 这时候我们就 git add . , git commit ,再准备git push 的时候 显示没有指定远程的分支 我们按照提示操作 提示我们要先git pull 提示我…...

算法训练|数据流中的中位数
LCR 160. 数据流中的中位数 - 力扣(LeetCode) 总结:这题自己最开始的想法是直接使用vector容器,每次取中位数的时候就进行一次排序,超时。题解很巧妙的利用大根堆和小根堆来解决问题,大根堆和小根堆各存一…...

LeetCode 2558. 从数量最多的堆取走礼物【模拟,堆或原地堆化】简单
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
windows服务器环境下使用php调用com组件
Office设置 安装 office2013 且通过正版激活码激活 在组件服务 计算机 我的电脑 DOM 中找到 Microsoft Word 97 - 2003 文档 服务,右键属性 身份验证调整为 无 在 标识中 调整为 交互式用户 php环境设置 开启com组件扩展 在php.ini中设置 extensionphp_com_dotn…...

机器学习赋能多共振生物传感:从多维光学数据中挖掘精准检测新范式
1. 项目概述与核心思路在生物传感和医疗诊断领域,我们一直在追求更高的检测精度和更低的检测限。传统的光学折射率传感器,比如基于表面等离子体共振(SPR)或法布里-珀罗腔的传感器,其工作原理大多依赖于监测单个光学共振…...

C++lambda表达式深入解析
Clambda表达式深入解析lambda表达式是C11引入的匿名函数特性,它提供了一种简洁的方式来定义内联函数对象,特别适合用于STL算法和回调函数。lambda表达式的基本语法包括捕获列表、参数列表、返回类型和函数体。#include #include #include #includevoid b…...

1.2 struct page 与 PFN:VMA 背后的物理存储
本篇目标:理解 Linux 如何为每个物理页帧维护元数据(struct page),以及虚拟地址最终如何落实到物理内存。HMM 的关键创新之一,是让设备内存(GPU VRAM)也拥有 struct page,从而被内核…...

如何快速上手Balena Etcher:新手必学的3种安装方法和实用技巧
如何快速上手Balena Etcher:新手必学的3种安装方法和实用技巧 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher Balena Etcher是一款开源的镜像烧录工具…...

React动画革命:react-tween-state 完全指南 - 10分钟掌握React平滑过渡动画
React动画革命:react-tween-state 完全指南 - 10分钟掌握React平滑过渡动画 【免费下载链接】react-tween-state React animation. 项目地址: https://gitcode.com/gh_mirrors/re/react-tween-state react-tween-state 是一款轻量级的 React 动画库ÿ…...

AssetStudio v0.16.5深度解析:Unity资源解包原理与工程化实践
1. 为什么你还在手动解包Unity游戏资源?AssetStudio不是“点开即用”的万能钥匙AssetStudio这个名字,听上去像某个高端建模插件,或者Unity官方出的资源管理器——其实它既不是Unity原生工具,也不带任何图形化向导。它是个开源、无…...

JMeter断言实战:从误配到分层校验的避坑指南
1. 为什么断言不是“加个检查框”就完事了?很多人第一次在 JMeter 里点开“添加 → 断言 → 响应断言”,填上“包含文本:success”,跑完看绿色小勾就以为接口测试闭环了。我带过三届测试团队,新同事交来的脚本里&#…...

BetterCodable高级用法:自定义策略和属性包装器的深度解析
BetterCodable高级用法:自定义策略和属性包装器的深度解析 【免费下载链接】BetterCodable Better Codable through Property Wrappers 项目地址: https://gitcode.com/gh_mirrors/be/BetterCodable BetterCodable是一个通过属性包装器(Property Wrapper)增强…...

上海AI实验室发布WildClawBench:AI智能体究竟能走多远?
这项由上海人工智能实验室联合香港中文大学、复旦大学、中国科学技术大学、上海交通大学、清华大学、浙江大学及南洋理工大学等多所顶尖机构共同完成的研究,于2026年5月11日以预印本形式发布,论文编号为arXiv:2605.10912v1。感兴趣的读者可通过该编号在a…...

抖音批量下载器终极指南:3步轻松搞定无水印视频下载
抖音批量下载器终极指南:3步轻松搞定无水印视频下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...