pandas 中如何按行或列的值对数据排序?
在处理表格型数据时,常会用到排序,比如,按某一行或列的值对表格排序,要怎么做呢?
这就要用到 pandas 中的 sort_values() 函数。
一、 按列的值对数据排序
先来看最常见的情况。
1.按某一列的值对数据排序
以下面的数据为例。
import pandas as pd
df_col = pd.DataFrame({'Name':['Paul','Richard', 'Betty', 'Philip','Anna'],'course1':[85,83,90,84,85],'course2':[90,82,79,71,86],'sport':['basketball', 'Volleyball', 'football', 'Basketball','baseball']},index=[1,2,3,4,5])df_col
| Name | course1 | course2 | sport | |
|---|---|---|---|---|
| 1 | Paul | 85 | 90 | basketball |
| 2 | Richard | 83 | 82 | Volleyball |
| 3 | Betty | 90 | 79 | football |
| 4 | Philip | 84 | 71 | Basketball |
| 5 | Anna | 85 | 86 | baseball |
在 sort_values() 函数中设置 by='列名',即可以按这一列值的顺序重新排列行。
df_sort=df_col.sort_values(by='course2')
df_sort
| Name | course1 | course2 | sport | |
|---|---|---|---|---|
| 4 | Philip | 84 | 71 | Basketball |
| 3 | Betty | 90 | 79 | football |
| 2 | Richard | 83 | 82 | Volleyball |
| 5 | Anna | 85 | 86 | baseball |
| 1 | Paul | 85 | 90 | basketball |
如以上结果所示,默认是升序排列。还可以做降序排列,在 sort_values() 函数中设置 ascending=False 即可。例如:
df_sort=df_col.sort_values(by='course2',ascending=False)
df_sort
| Name | course1 | course2 | sport | |
|---|---|---|---|---|
| 1 | Paul | 85 | 90 | basketball |
| 5 | Anna | 85 | 86 | baseball |
| 2 | Richard | 83 | 82 | Volleyball |
| 3 | Betty | 90 | 79 | football |
| 4 | Philip | 84 | 71 | Basketball |
2. 按多列的值对数据排序
您是否遇到过这种情况:要排序的某一列数据有相同的值,此时结果会怎么样呢?我们来看下面的例子。
df_sort=df_col.sort_values(by='course1')
df_sort
| Name | course1 | course2 | sport | |
|---|---|---|---|---|
| 2 | Richard | 83 | 82 | Volleyball |
| 4 | Philip | 84 | 71 | Basketball |
| 1 | Paul | 85 | 90 | basketball |
| 5 | Anna | 85 | 86 | baseball |
| 3 | Betty | 90 | 79 | football |
从结果看到,“course1” 有两个相同的值 85,此时会依据 index 的先后顺序排列。
那如果不想按 index 顺序,想要自己设定相同值的排序方式,应该怎么做呢?
可以设置第二列,对于第一列的相同值,参照第二列的值排序。例如:
df_sort=df_col.sort_values(by=['course1','course2'])
df_sort
| Name | course1 | course2 | sport | |
|---|---|---|---|---|
| 2 | Richard | 83 | 82 | Volleyball |
| 4 | Philip | 84 | 71 | Basketball |
| 5 | Anna | 85 | 86 | baseball |
| 1 | Paul | 85 | 90 | basketball |
| 3 | Betty | 90 | 79 | football |
可以看到,by 参数中的第二列 “course2” 只在第一列 “course1” 中有相同值时起作用,因此只有 “Anna” 和 “Paul” 所在的这两行数据位置互换,其它行位置不变。
3. key 参数:设置排序时的数据变换函数
在实际中还可能会遇到这种情况,数据中大小写都有,比如例子数据的 “sport” 列。按这一列对数据排序,结果如下:
df_sort=df_col.sort_values(by=['sport'])
df_sort
| Name | course1 | course2 | sport | |
|---|---|---|---|---|
| 4 | Philip | 84 | 71 | Basketball |
| 2 | Richard | 83 | 82 | Volleyball |
| 5 | Anna | 85 | 86 | baseball |
| 1 | Paul | 85 | 90 | basketball |
| 3 | Betty | 90 | 79 | football |
看结果发现,大写字母排在小写字母前面,因此 “Volleyball” 所在行排在 “baseball” 所在行前面,但这并不是我们想要的排序结果。那应该怎么做,才能按字母顺序排序呢?
可以设置 sort_values() 函数的 key 参数。
df_sort=df_col.sort_values(by=['sport'],key=lambda col:col.str.lower())
df_sort
| Name | course1 | course2 | sport | |
|---|---|---|---|---|
| 5 | Anna | 85 | 86 | baseball |
| 1 | Paul | 85 | 90 | basketball |
| 4 | Philip | 84 | 71 | Basketball |
| 3 | Betty | 90 | 79 | football |
| 2 | Richard | 83 | 82 | Volleyball |
此时的排序结果就是按字母顺序排列。
4. 修改原数据
前面介绍的操作中,每次都生成了一个新的数据 df_sort,并没有改变原数据。
df_col
| Name | course1 | course2 | sport | |
|---|---|---|---|---|
| 1 | Paul | 85 | 90 | basketball |
| 2 | Richard | 83 | 82 | Volleyball |
| 3 | Betty | 90 | 79 | football |
| 4 | Philip | 84 | 71 | Basketball |
| 5 | Anna | 85 | 86 | baseball |
但是,有时可能数据太大,而原数据后续不再使用。为了节省空间,想直接在原数据上改动。应该怎么办呢?
只要在 sort_values() 函数中设置 inplace=True。
df_col.sort_values(by='course2',inplace=True)
df_col
| Name | course1 | course2 | sport | |
|---|---|---|---|---|
| 4 | Philip | 84 | 71 | Basketball |
| 3 | Betty | 90 | 79 | football |
| 2 | Richard | 83 | 82 | Volleyball |
| 5 | Anna | 85 | 86 | baseball |
| 1 | Paul | 85 | 90 | basketball |
二、 按行的值对数据排序
需要注意的是,这种情况只适用于各列数据类型相同的情况,例如下面例子中的数据,每一列数据都是数值型。而前面例子的数据既有数值型,又有字符型,无法按行的值排序。
df_row = pd.DataFrame({'course1':[91,85,90,84,92],'course2':[72,81,76,71,79],'course3':[93,85,88,94,86]},index=['Paul','Richard', 'Betty', 'Philip','Anna'])
df_row
| course1 | course2 | course3 | |
|---|---|---|---|
| Paul | 91 | 72 | 93 |
| Richard | 85 | 81 | 85 |
| Betty | 90 | 76 | 88 |
| Philip | 84 | 71 | 94 |
| Anna | 92 | 79 | 86 |
按行的值排序时,设置 by 参数为某行的 index 名,并且 axis=1。
df_sort=df_row.sort_values(by='Anna',axis=1)
df_sort
| course2 | course3 | course1 | |
|---|---|---|---|
| Paul | 72 | 93 | 91 |
| Richard | 81 | 85 | 85 |
| Betty | 76 | 88 | 90 |
| Philip | 71 | 94 | 84 |
| Anna | 79 | 86 | 92 |
按行值排序在 sort_values() 函数中设置 ascending, key, inplace 等参数的方式都与前面介绍的按列值排序相同。这里仅以按多行的值对数据排序为例。
df_sort=df_row.sort_values(by=['Richard','Paul'],axis=1,ascending=False)
df_sort
| course3 | course1 | course2 | |
|---|---|---|---|
| Paul | 93 | 91 | 72 |
| Richard | 85 | 85 | 81 |
| Betty | 88 | 90 | 76 |
| Philip | 94 | 84 | 71 |
| Anna | 86 | 92 | 79 |
参考
1.https://www.geeksforgeeks.org/sort-rows-or-columns-in-pandas-dataframe-based-on-values/#courses
2.https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.sort_values.html
本文对您有帮助的话,请点赞支持一下吧,谢谢!
关注我 宁萌Julie,互相学习,多多交流呀!
相关文章:

pandas 中如何按行或列的值对数据排序?
在处理表格型数据时,常会用到排序,比如,按某一行或列的值对表格排序,要怎么做呢? 这就要用到 pandas 中的 sort_values() 函数。 一、 按列的值对数据排序 先来看最常见的情况。 1.按某一列的值对数据排序 以下面…...

「牛客网C」初学者入门训练BC139,BC158
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练 🔥座右铭:“不要等到什么都没有了,才下定决心去做” 🚀🚀🚀大家觉不错…...
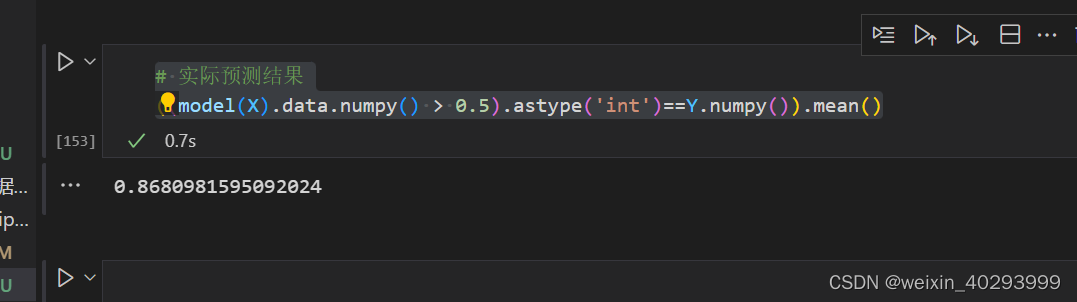
【深度学习】线性回归、逻辑回归、二分类,多分类等基础知识总结
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言1. 线性回归2、逻辑回归3. 单层神经元的缺陷&多层感知机softmax 多分类最后再来一个 二分类的例子前言 入行深度学习快2年了,是时间好好总结下基础知识了.现…...

【MySQL】调控 字符集
一、 MySQL 启动选项 & 系统变量 启动选项 是在程序启动时我们程序员传递的一些参数,而 系统变量 是影响服务器程序运行行为的变量 1.1 启动项 MySQL 客户端设置项包括: 允许连入的客户端数量 、 客户端与服务器的通信方式 、 表的默认存储引擎 、…...
FME+YOLOV7写DNF自动刷图脚本
目录 前言 一、难点分析 二、实现流程 1.DNF窗口位置获取 2.获取训练数据 3.数据标注 4.数据格式转换 5.数据训练 5.刷图逻辑编写 前言 这是一篇不务正业的研究,首先说明,这不是外挂!这不是外挂!这不是外挂!这只是用a…...

Java语法面试题
多线程锁 Synchronized:一次只能被一个线程占有ReadWriteLock:被多个线程持有,写锁只能被一个线程占有ReentrantLock:一个线程的多个流程能获取同一把锁,就是可重入锁,即在一个线程中可以被重复的获取自旋锁…...

location
目录 匹配的目标 格式 匹配符号: 优先级 要表达不匹配条件,则用 if 实现 例子:根目录的匹配最弱 例子:区分大小写 和 不区分大小写 例子:以根开头 和 不区分大小写 例子:等号 匹配的目标 ng…...

简述RBAC模型
RBAC(Role-Based Access Control)模型是一种常用的访问控制模型,用于管理和控制用户对系统资源的访问权限。RBAC模型通过将用户分配给角色,并授予角色相应的权限,来实现安全的资源访问管理。 在RBAC模型中,…...

倒计时2天:中国工程院院士谭建荣等嘉宾确认出席,“警务+”时代来临...
近日伴随公安部、科技部联合印发通知,部署推进科技兴警三年行动计划(2023-2025年),现代科技手段与警务工作相结合的方式,正式被定义为未来警务发展的新趋势。 21世纪以来,随着科技的不断发展和创新…...
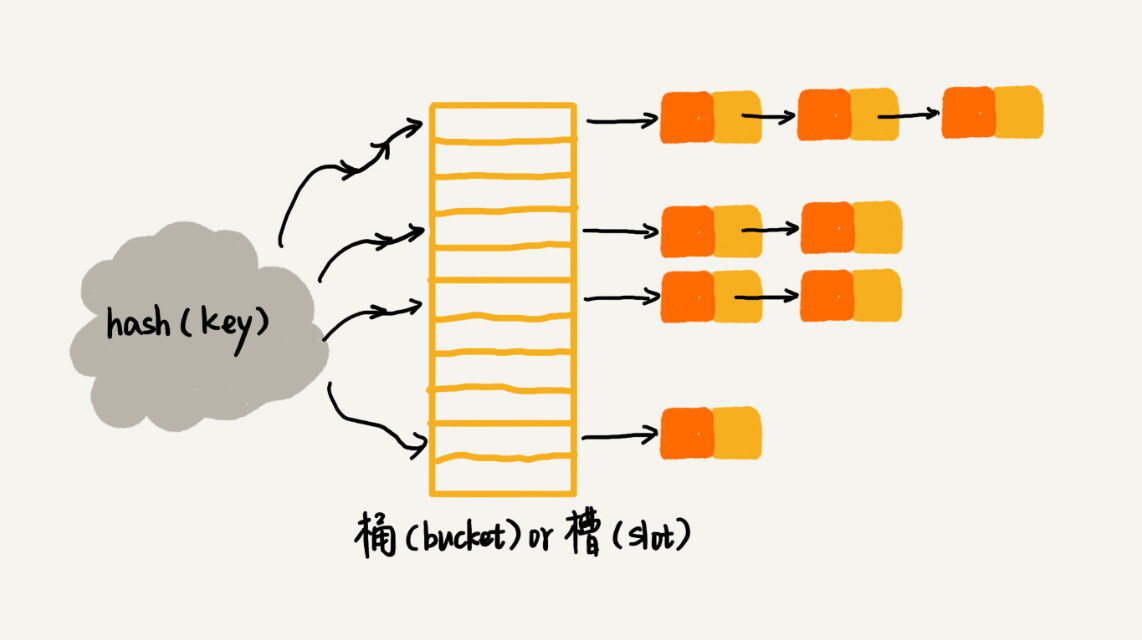
Python蓝桥杯训练:基本数据结构 [哈希表]
Python蓝桥杯训练:基本数据结构 [哈希表] 文章目录Python蓝桥杯训练:基本数据结构 [哈希表]一、哈希表理论基础知识1、开放寻址法2、链式法二、有关哈希表的一些常见操作三、力扣上面一些有关哈希表的题目练习1、[有效的字母异位词](https://leetcode.cn…...

MacOS 配置 Fvm环境
系统环境:MacOS 13,M1芯片 1. 安装HomeBrew: /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" speed 2. 使用brew安装Fvm: brew tap leoafarias/fvm brew install fvm 3…...
 介绍 Python 编程语言)
Python小白入门- 01( 第一章,第1节) 介绍 Python 编程语言
1. 介绍 Python 编程语言 1.1 Python 是什么 Python 是一种高级的、解释型、面向对象的编程语言,具有简洁、易读、易写的语法特点。Python 由 Guido van Rossum 于 1989 年在荷兰创造,并于 1991 年正式发布。 Python 语言广泛应用于数据科学、Web 开发、人工智能、自动化测…...

高并发系统设计之缓存
本文已收录至Github,推荐阅读 👉 Java随想录 这篇文章来讲讲缓存。缓存是优化网站性能的第一手段,目的是让访问速度更快。 说起缓存,第一反应可能想到的就是Redis。目前比较好的方案是使用多级缓存,如CPU→Ll/L2/L3→…...

【N32WB03x SDK使用指南】
【N32WB03x SDK使用指南】1. 简介1.1 产品简介1.2 主要资源1.3 典型应用2. SDK/开发固件文件目录结构2.1 doc2.2 firmware2.3 middleware2.4 utilities2.5 projects Projects3. 项目配置与烧录3.1 编译环境安装3.2 固件支持包安装3.3 编译环境配置3.4 编译与下载3.5 BLE工程目录…...

pytest测试框架——pytest.ini用法
这里写目录标题一、pytest用法总结二、pytest.ini是什么三、改变运行规则pytest.inicheck_demo.py执行测试用例四、添加默认参数五、指定执行目录六、日志配置七、pytest插件分类八、pytest常用插件九、改变测试用例的执行顺序十、pytest并行与分布式执行十一、pytest内置插件h…...
2023版)
KAFKA安装与配置(带Zookeeper)2023版
KAFKA安装与配置(带Zookeeper) 一、环境准备: Ubuntu 64位 22.04,三台 二、安装JDK1.8 下载JDK1.8,我这边用的版本是jdk1.8.0_2022、解压jdk tar -zxvf jdk1.8.0_202.tar.gz 3、在/usr/local创建java文件夹,并将解压的jdk移动到/usr/local/java sudo mv jdk1.8.0_202…...

深入浅出解析ChatGPT引领的科技浪潮【AI行研商业价值分析】
Rocky Ding写在前面 【AI行研&商业价值分析】栏目专注于分享AI行业中最新热点/风口的思考与判断。也欢迎大家提出宝贵的意见或优化ideas,一起交流学习💪 大家好,我是Rocky。 2022年底,ChatGPT横空出世,火爆全网&a…...

.net 批量导出文件,以ZIP压缩方式导出
1. 首先Nuget ICSharpCode.SharpZipLib <script type"text/javascript">$(function () {$("#OutPutLink").click(function () { // 单击下文件时$.ajax({ // 先判断条件时间内没有文件url: "/Home/ExistsFile?statTime" $(&q…...
数据分析:某电商优惠卷数据分析
数据分析:某电商优惠卷数据分析 作者:AOAIYI 专栏:python数据分析 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可…...
性能测试流程
性能测试实战一.资源指标分析1.判断CPU是否瓶颈的方法2.判断内存是否瓶颈的方法3.判断磁盘I/O是否瓶颈的方法4.判断网络带宽是否是瓶颈的方法二.系统指标分析三.性能调优四.性能测试案例1.项目背景2.实施规划(1)需求分析(2)测试方…...

从OBS源码看WASAPI实战:Windows音频采集的‘静音循环’修复与高精度时间戳处理
从OBS源码剖析WASAPI音频采集:静音循环修复与高精度时间戳的工程实践 在直播软件OBS的音频处理模块中,WASAPI接口的高效运用直接决定了音画同步质量与系统资源占用率。本文将深入OBS源码,揭示其解决Windows音频采集两大核心难题的技术方案&am…...

VSCode集成clang-tidy实现多语言命名规范自动化检查
1. 为什么需要自动化命名规范检查 在团队协作开发中,代码命名规范就像交通规则一样重要。想象一下,如果每个司机都按照自己的习惯开车,那道路会乱成什么样子?代码也是如此。我曾经接手过一个遗留项目,发现同一个变量在…...

终极jscpd API编程指南:如何在项目中集成代码重复检测功能
终极jscpd API编程指南:如何在项目中集成代码重复检测功能 【免费下载链接】jscpd Copy/paste detector for programming source code. 项目地址: https://gitcode.com/gh_mirrors/js/jscpd jscpd是一个强大的开源代码重复检测工具,支持150编程语…...

Rivets.js实际项目案例:构建电商应用的数据绑定架构
Rivets.js实际项目案例:构建电商应用的数据绑定架构 【免费下载链接】rivets Lightweight and powerful data binding. 项目地址: https://gitcode.com/gh_mirrors/ri/rivets Rivets.js是一个轻量级且功能强大的数据绑定库,它能帮助你快速构建响应…...

终极AI图像增强神器Upscayl:让每一张照片重获新生
终极AI图像增强神器Upscayl:让每一张照片重获新生 【免费下载链接】upscayl 🆙 Upscayl - Free and Open Source AI Image Upscaler for Linux, MacOS and Windows built with Linux-First philosophy. 项目地址: https://gitcode.com/GitHub_Trending…...

阿里云:数据分析Agent白皮书——AI重构数据消费 2026
这份由阿里云与瓴羊发布的《数据分析 Agent 白皮书 ——AI 重构数据消费》,立足 DataAI 融合趋势,系统阐述了数据分析 Agent 的发展背景、技术架构、代表产品、行业实践、落地方法与未来方向,核心围绕AI 重构企业数据消费模式展开,…...

Qt状态机实战指南:从基础到高级应用
1. Qt状态机基础入门 第一次接触Qt状态机时,我完全被它的设计哲学惊艳到了。想象一下你家的智能电饭煲:待机、煮饭、保温就是三个典型状态,按下按钮就是触发状态转换的信号——这就是状态机最接地气的理解方式。Qt中的QStateMachine框架&…...

零代码部署YOLOv9:官方镜像5分钟快速上手,实测效果惊艳
零代码部署YOLOv9:官方镜像5分钟快速上手,实测效果惊艳 1. 为什么选择YOLOv9官方镜像 目标检测领域的最新突破YOLOv9已经发布,但很多开发者在尝试部署时遇到了各种环境配置问题。这个官方预构建的镜像解决了三大核心痛点: 环境配置…...
)
PyTorch版本冲突?手把手教你用conda解决torch和torchvision依赖问题(附常见错误排查)
PyTorch版本冲突?手把手教你用conda解决torch和torchvision依赖问题(附常见错误排查) 深度学习开发中,PyTorch环境的配置往往是项目启动的第一道门槛。许多开发者在安装torch和torchvision时都遇到过令人头疼的版本冲突问题——明…...

利用快马平台快速构建openclaw网页抓取原型,十分钟验证技术方案
最近在做一个数据采集相关的项目,需要快速验证网页抓取方案的可行性。经过调研发现openclaw这个Python库很适合做轻量级的网页抓取,但搭建完整的开发环境太费时间。后来在InsCode(快马)平台上尝试了一下,没想到十分钟就搞定了原型验证。这里分…...