SparkStreaming【实例演示】
前言
1、环境准备
- 启动Zookeeper和Kafka集群
- 导入依赖:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.4</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.2.4</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.2.4</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.30</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.10</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.14.2</version></dependency>2、模拟生产数据
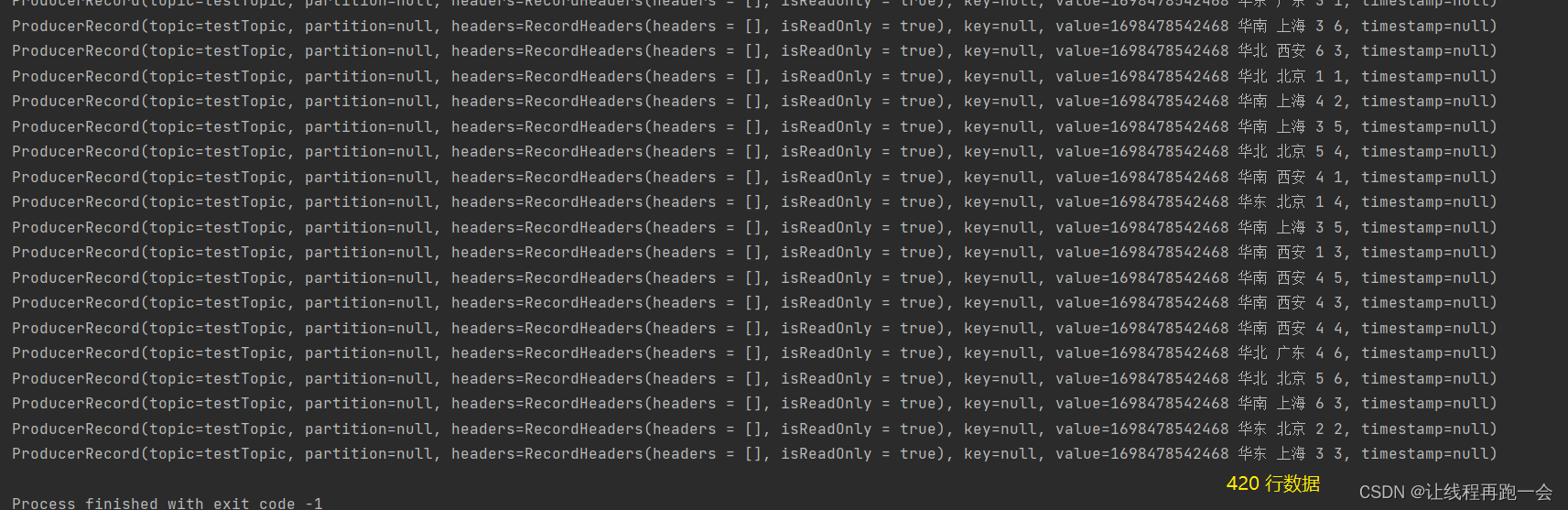
通过循环来不断生产随机数据、使用Kafka来发布订阅消息。
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}import java.util.Properties
import scala.collection.mutable.ListBuffer
import scala.util.Random// 生产模拟数据
object MockData {def main(args: Array[String]): Unit = {// 生成模拟数据// 格式: timestamp area city userid adid// 含义: 时间戳 省份 城市 用户 广告// 生产数据 => Kafka => SparkStreaming => 分析处理// 设置Zookeeper属性val props = new Properties()props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")val producer: KafkaProducer[String, String] = new KafkaProducer[String, String](props)while (true){mockData().foreach((data: String) => {// 向 Kafka 中生成数据val record = new ProducerRecord[String,String]("testTopic",data)producer.send(record)println(record)})Thread.sleep(2000)}}def mockData(): ListBuffer[String] = {val list = ListBuffer[String]()val areaList = ListBuffer[String]("华东","华南","华北","华南")val cityList = ListBuffer[String]("北京","西安","上海","广东")for (i <- 1 to 30){val area = areaList(new Random().nextInt(4))val city = cityList(new Random().nextInt(4))val userid = new Random().nextInt(6) + 1val adid = new Random().nextInt(6) + 1list.append(s"${System.currentTimeMillis()} ${area} ${city} ${userid} ${adid}")}list}}
3、模拟消费数据
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}// 消费数据
object Kafka_req1 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("kafka req1")val ssc = new StreamingContext(conf,Seconds(3))// 定义Kafka参数: kafka集群地址、消费者组名称、key序列化、value序列化val kafkaPara: Map[String,Object] = Map[String,Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG ->"lyh",ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])// 读取Kafka数据创建DStreamval kafkaDStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream[String,String](ssc,LocationStrategies.PreferConsistent, //优先位置ConsumerStrategies.Subscribe[String,String](Set("testTopic"),kafkaPara) // 消费策略:(订阅多个主题,配置参数))// 将每条消息的KV取出val valueDStream: DStream[String] = kafkaDStream.map(_.value())// 计算WordCountvalueDStream.print()// 开启任务ssc.start()ssc.awaitTermination()}}4、需求1 广告黑名单
实现实时的动态黑名单机制:将每天对某个广告点击超过 100 次的用户拉黑。(黑名单保存到 MySQL 中。)
先判断用户是否已经在黑名单中?过滤:判断用户点击是否超过阈值?拉入黑名单:更新用户的点击数量,并获取最新的点击数据再判断是否超过阈值?拉入黑名单:不做处理
需要两张表:黑名单、点击数量表。
create table black_list (userid char(1));CREATE TABLE user_ad_count (
dt varchar(255),
userid CHAR (1),
adid CHAR (1),
count BIGINT,
PRIMARY KEY (dt, userid, adid)
);JDBC工具类
import com.alibaba.druid.pool.DruidDataSourceFactoryimport java.sql.Connection
import java.util.Properties
import javax.sql.DataSourceobject JDBCUtil {var dataSource: DataSource = init()//初始化连接池def init(): DataSource = {val properties = new Properties()properties.setProperty("driverClassName", "com.mysql.jdbc.Driver")properties.setProperty("url", "jdbc:mysql://hadoop102:3306/spark-streaming?useUnicode=true&characterEncoding=UTF-8&useSSL=false")properties.setProperty("username", "root")properties.setProperty("password", "000000")properties.setProperty("maxActive", "50")DruidDataSourceFactory.createDataSource(properties)}//获取连接对象def getConnection(): Connection ={dataSource.getConnection}
}需求实现:
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}import java.sql.Connection
import java.text.SimpleDateFormat
import java.util.Date
import scala.collection.mutable.ListBuffer// 消费数据
object Kafka_req1 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("kafka req1")val ssc = new StreamingContext(conf,Seconds(3))// 定义Kafka参数: kafka集群地址、消费者组名称、key序列化、value序列化val kafkaPara: Map[String,Object] = Map[String,Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG ->"lyh",ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])// 读取Kafka数据创建DStreamval kafkaDStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream[String,String](ssc,LocationStrategies.PreferConsistent, //优先位置ConsumerStrategies.Subscribe[String,String](Set("testTopic"),kafkaPara) // 消费策略:(订阅多个主题,配置参数))val clickData: DStream[AdClickData] = kafkaDStream.map(kafkaData => {val data = kafkaData.value()val datas = data.split(" ")AdClickData(datas(0), datas(1), datas(2), datas(3),datas(4))})val ds: DStream[((String,String,String),Int)] = clickData.transform( //周期性地拿到 RDD 数据rdd => {// todo 周期性获取黑名单数据,就要周期性读取MySQL中的数据val black_list = ListBuffer[String]()val con: Connection = JDBCUtil.getConnection()val stmt = con.prepareStatement("select * from black_list")val rs = stmt.executeQuery()while (rs.next()) {black_list.append(rs.getString(1))}rs.close()stmt.close()con.close()// todo 判断用户是否在黑名单当中,在就过滤掉val filterRDD = rdd.filter(data => {!black_list.contains(data.user)})// todo 如果不在,那么统计点击数量filterRDD.map(data => {val sdf = new SimpleDateFormat("yyyy-MM-dd")val day = sdf.format(new Date(data.ts.toLong))val user = data.userval ad = data.ad((day, user, ad), 1) // 返回键值对}).reduceByKey(_ + _)})ds.foreachRDD(rdd => {rdd.foreach {case ((day, user, ad), count) => {println(s"$day $user $ad $count")if (count>=30){// todo 如果统计数量超过点击阈值(30),拉入黑名单val con = JDBCUtil.getConnection()val stmt = con.prepareStatement("""|insert into black_list values(?)|on duplicate key|update userid=?|""".stripMargin)stmt.setString(1,user)stmt.setString(2,user)stmt.executeUpdate()stmt.close()con.close()}else{// todo 如果没有超过阈值,更新到当天点击数量val con = JDBCUtil.getConnection()val stmt = con.prepareStatement("""|select *|from user_ad_count|where dt=? and userid=? and adid=?|""".stripMargin)stmt.setString(1,day)stmt.setString(2,user)stmt.setString(3,ad)val rs = stmt.executeQuery()if (rs.next()){ //如果存在数据val stmt1 = con.prepareStatement("""|update user_ad_count|set count=count+?|where dt=? and userid=? and adid=?|""".stripMargin)stmt1.setInt(1,count)stmt1.setString(2,day)stmt1.setString(3,user)stmt1.setString(4,ad)stmt1.executeUpdate()stmt1.close()// todo 如果更新后的点击数量超过阈值,拉入黑名单val stmt2 = con.prepareStatement("""|select *|from user_ad_count|where dt=? and userid=? and adid=?|""".stripMargin)stmt2.setString(1,day)stmt2.setString(2,user)stmt2.setString(3,ad)val rs1 = stmt2.executeQuery()if (rs1.next()){val stmt3 = con.prepareStatement("""|insert into black_list(userid) values(?)|on duplicate key|update userid=?|""".stripMargin)stmt3.setString(1,user)stmt3.setString(2,user)stmt3.executeUpdate()stmt3.close()}rs1.close()stmt2.close()}else{// todo 如果不存在数据,那么新增val stmt1 = con.prepareStatement("""|insert into user_ad_count(dt,userid,adid,count) values(?,?,?,?)|""".stripMargin)stmt1.setString(1,day)stmt1.setString(2,user)stmt1.setString(3,ad)stmt1.setInt(4,count)stmt1.executeUpdate()stmt1.close()}rs.close()stmt.close()con.close()}}}})// 开启任务ssc.start()ssc.awaitTermination()}// 广告点击数据case class AdClickData(ts: String,area: String,city: String,user: String,ad: String)}5、需求2 广告实时点击数据
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}import java.text.SimpleDateFormat
import java.util.Dateobject Kafka_req2 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("kafka req2")val ssc = new StreamingContext(conf,Seconds(3))// 定义Kafka参数: kafka集群地址、消费者组名称、key序列化、value序列化val kafkaPara: Map[String,Object] = Map[String,Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG ->"lyh",ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])// 读取Kafka数据创建DStreamval kafkaDStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream[String,String](ssc,LocationStrategies.PreferConsistent, //优先位置ConsumerStrategies.Subscribe[String,String](Set("testTopic"),kafkaPara) // 消费策略:(订阅多个主题,配置参数))// 对DStream进行转换操作val clickData: DStream[AdClickData] = kafkaDStream.map(kafkaData => {val data = kafkaData.value()val datas = data.split(" ")AdClickData(datas(0), datas(1), datas(2), datas(3),datas(4))})val ds: DStream[((String, String, String, String), Int)] = clickData.map((data: AdClickData) => {val sdf = new SimpleDateFormat("yyyy-MM-dd")val day = sdf.format(new Date(data.ts.toLong))val area = data.areaval city = data.cityval ad = data.ad((day, area, city, ad), 1)}).reduceByKey(_+_)ds.foreachRDD(rdd=>{rdd.foreachPartition(iter => {val con = JDBCUtil.getConnection()val stmt = con.prepareStatement("""|insert into area_city_ad_count (dt,area,city,adid,count)|values (?,?,?,?,?)|on duplicate key|update count=count+?|""".stripMargin)iter.foreach {case ((day, area, city, ad), sum) => {println(s"$day $area $city $ad $sum")stmt.setString(1,day)stmt.setString(2,area)stmt.setString(3,city)stmt.setString(4,ad)stmt.setInt(5,sum)stmt.setInt(6,sum)stmt.executeUpdate()}}stmt.close()con.close()})})ssc.start()ssc.awaitTermination()}// 广告点击数据case class AdClickData(ts: String,area: String,city: String,user: String,ad: String)}
需求3、一段时间内的广告点击数据
注意:窗口范围和滑动范围必须是收集器收集数据间隔的整数倍!!
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}object Kafka_req3 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("kafka req3")val ssc = new StreamingContext(conf,Seconds(5)) //每5s收集器收集一次数据形成一个RDD加入到DStream中// 定义Kafka参数: kafka集群地址、消费者组名称、key序列化、value序列化val kafkaPara: Map[String,Object] = Map[String,Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG ->"lyh",ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])// 读取Kafka数据创建DStreamval kafkaDStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream[String,String](ssc,LocationStrategies.PreferConsistent, //优先位置ConsumerStrategies.Subscribe[String,String](Set("testTopic"),kafkaPara) // 消费策略:(订阅多个主题,配置参数))val adClickData = kafkaDStream.map((kafkaData: ConsumerRecord[String, String]) => {val data = kafkaData.value()val datas = data.split(" ")AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))})val ds = adClickData.map(data => {val ts = data.ts.toLong/*** 为了结果展示的时候更加美观: ts=1698477282712ms* 我们希望统计的数据的是近一分钟的数据(每10s展示一次):* 15:10:00 ~ 15:11:00* 15:10:10 ~ 15:11:10* 15:10:20 ~ 15:11:20* ...* ts/1000 => 1698477282s (我们把秒换成0好看点) ts/10*10=1698477280s => 转成ms ts*1000 = 1698477282000ms* 所以就是 ts / 10000 * 10000*/val newTs = ts / 10000 * 10000(newTs, 1)}).reduceByKeyAndWindow((_: Int)+(_:Int), Seconds(60), Seconds(10)) //windowDurations和slideDuration都必须是收集器收集频率的整数倍ds.print()ssc.start()ssc.awaitTermination()}// 广告点击数据case class AdClickData(ts: String,area: String,city: String,user: String,ad: String)}运行结果:格式(毫秒,点击次数)
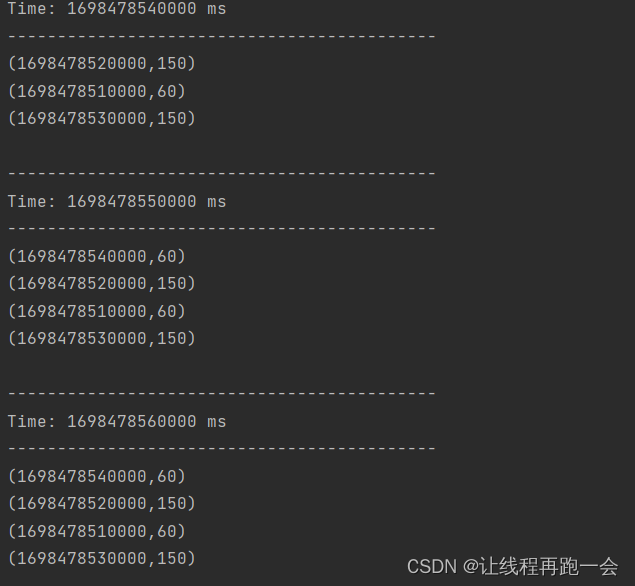
产生的数据
相关文章:
SparkStreaming【实例演示】
前言 1、环境准备 启动Zookeeper和Kafka集群导入依赖: <dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.4</version></dependency><dependency>&l…...

提高抖音小店用户黏性和商品销量的有效策略
抖音小店是抖音平台上的电商模式,用户可以在抖音上购买各类商品。要提高用户黏性和商品销量,四川不若与众帮你整理了需要注意以下几个方面。 首先,提供优质的商品和服务。在抖音小店中,用户会通过观看商品展示视频和用户评价来选…...

提高公众意识:共同防范AI诈骗
随着人工智能技术的飞速发展,AI诈骗成为了一个不容忽视的威胁,影响到我们的社交、金融和个人隐私安全。在这个数字时代,提高公众对AI诈骗的意识至关重要,以下是一些关于如何提高公众意识以防范AI诈骗的观点: 认知AI诈…...

MES的物料管理
----物料管理的定义和作用---- 物料管理在制造执行系统(MES)中扮演着至关重要的角色。通过有效的物料管理,企业可以实现生产过程的高效性、准确性和可靠性,从而提高生产效率并降低成本。 一、物料管理的定义 物料管理是指对生产过…...
正点原子嵌入式linux驱动开发——Linux 多点电容触摸屏
随着智能手机的发展,电容触摸屏也得到了飞速的发展。相比电阻触摸屏,电容触摸屏有很多的优势,比如支持多点触控、不需要按压,只需要轻轻触摸就有反应。ALIENTEK的三款RGB LCD屏幕都支持多点电容触摸,本章就以ATK7016这…...
Git基础命令实践
文章目录 简介git的安装配置git的安装git的配置 git使用的基本流程创建版本库时光机穿梭版本回退工作区和暂存区管理修改撤销修改删除文件 远程仓库添加远程库从远程库克隆 总结 简介 本文主要记录了我在学习git操作的过程,以及如何使用GitHub。建议先参考廖雪峰的…...
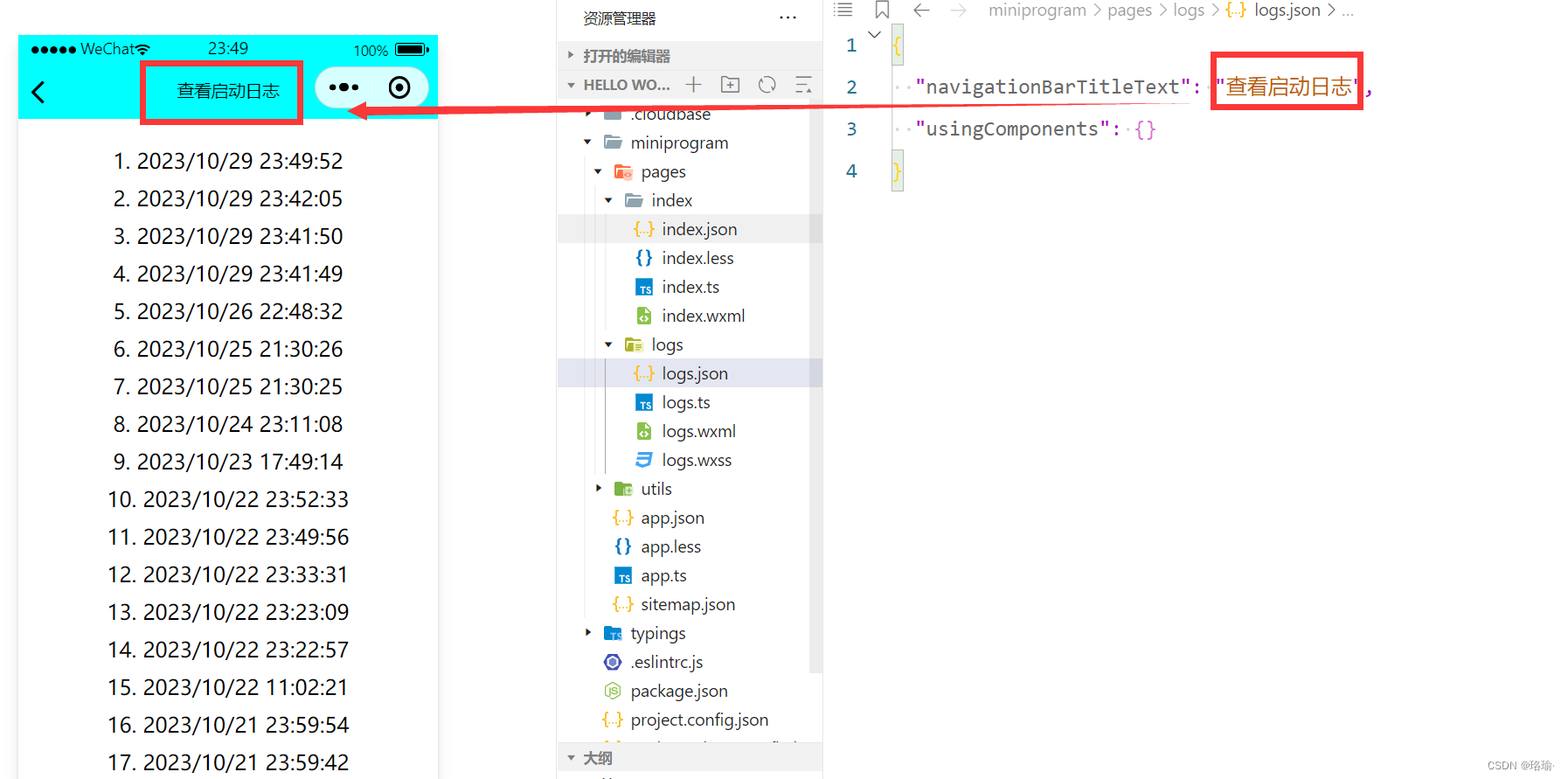
微信小程序设计之页面文件pages
一、新建一个项目 首先,下载微信小程序开发工具,具体下载方式可以参考文章《微信小程序开发者工具下载》。 然后,注册小程序账号,具体注册方法,可以参考文章《微信小程序个人账号申请和配置详细教程》。 在得到了测…...
VScode 自定义主题各参数解析
参考链接: vscode自定义颜色时各个参数的作用(史上最全)vscode编辑器,自己喜欢的颜色 由于 VScode 搜索高亮是在是太不起眼了,根本看不到此时选中到哪个搜索匹配了,所以对此进行了配置,具体想增加更多可配置项可参考…...

Linux进程等待
文章目录 1. 为什么要进程等待2. 进程等待的方法waitwaitpid非阻塞轮询 1. 为什么要进程等待 子进程退出,如果父进程还未结束,没有管这个子进程,那么就可能会造成“僵尸进程”问题,进而出现内存泄漏 如果这个进程变成了“僵尸进程…...
python设计模式笔记1:创建型模式 工厂模式和抽象工厂模式
1.工厂模式 (1) 导入所需的模块( json 和 ElementTree )。 (2) 定义 JSON数据提取器类( JSONDataExtractor )。 (3) 定义 XML数据提取器类( XMLDataExtractor )。 (4) 添加工厂函数 dataextraction_factor…...

第五章 I/O管理 一、I/O设备的基本概念和分类
目录 一、什么是I/O设备 1、定义: 2、按特性分类: 3、按传输速率分类: 4、按信息交换的方式分类: 二、总结 一、什么是I/O设备 1、定义: I/O设备就是可以将数据输入到计算机,或者可以接收计算机输出…...
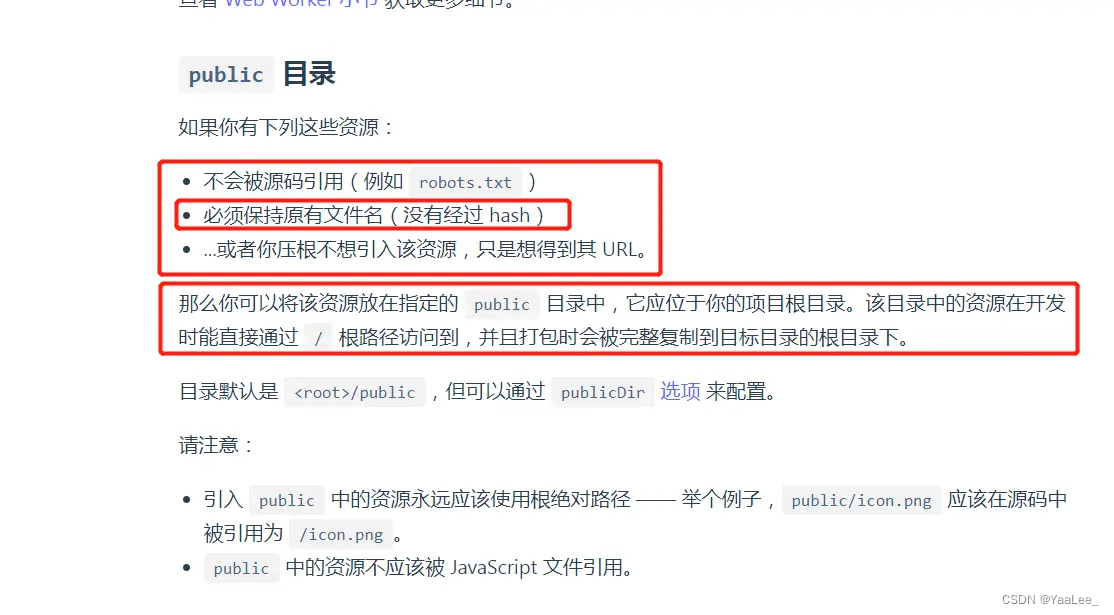
vue3动态引入图片(:src)
vite 官方默认的配置,如果资源文件在assets文件夹打包后会把图片名加上 hash值,但是直接通过 :src"imgSrc"方式引入并不会在打包的时候解析,导致开发环境可以正常引入,打包后却不能显示的问题 实际上我们不希望资源文…...
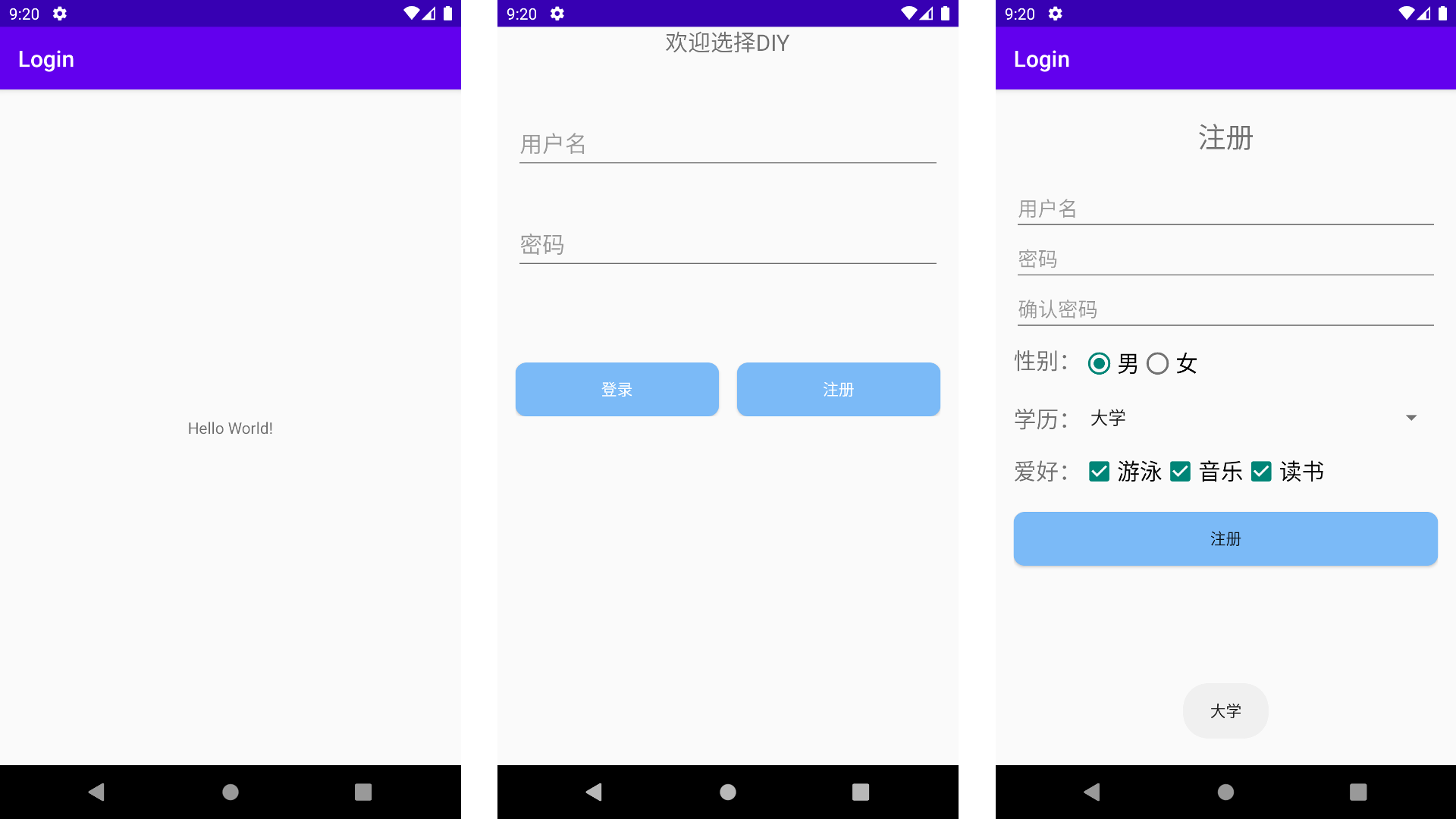
Android-登录注册页面(第三次作业)
第三次作业 - 登录注册页面 题目要求 嵌套布局。使用线性布局的嵌套结构,实现登录注册的页面。(例4-3) 创建空的Activity 项目结构树如下图所示: 注意:MainActivity.java文件并为有任何操作,主要功能集中…...
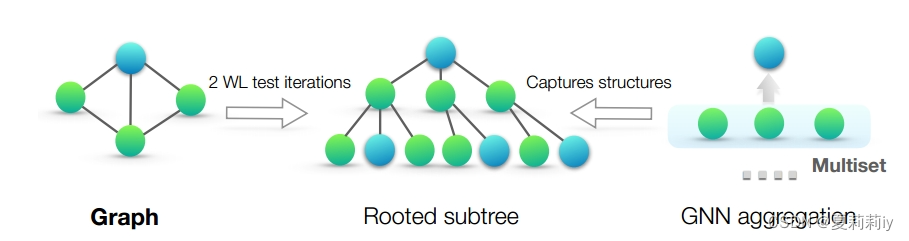
[论文精读]How Powerful are Graph Neural Networks?
论文原文:[1810.00826] How Powerful are Graph Neural Networks? (arxiv.org) 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记&#x…...

Redis实现分布式锁之----超时和失效(非原子性)问题----解决方案
Redis实现分布式锁之----超时和失效(非原子性)问题----解决方案 超时和失效(非原子性)问题 原子性问题:上锁时存入线程名称,删除时要先判断锁内的名称是不是自己的,是再删除,但是后…...

Android使用Hilt依赖注入,让人看不懂你代码
前言 之前接手的一个项目里有些代码看得云里雾里的,找了半天没有找到对象创建的地方,后来才发现原来使用了Hilt进行了依赖注入。Hilt相比Dagger虽然已经比较简洁,但对初学者来说还是有些门槛,并且网上的许多文章都是搬自官网&…...

ZYNQ连载01-ZYNQ介绍
ZYNQ连载01-ZYNQ介绍 1. ZYNQ 参考文档:《ug585-zynq-7000-trm.pdf》 ZYNQ分为PS和PL两大部分,PS即ARM,PL即FPGA,PL作为PS的外设。 2. 方案 ZYNQ7020为双核A9架构,多核处理器常用的运行模式为AMP(非对称多处理)和…...

第十节——Vue组件
一、什么是组件 组件(Component)是vue.js中很强大的一个功能,可以将一些可重用的代码进行封重用。 所有的Vue 组件同时也是Vue 的实例,可以接受使用相同的选项对象和提供相同的生命周期钩子。 一句话概括:组件就是可以扩展HTML元素ÿ…...

Redis(01)| 数据结构
这里写自定义目录标题 Redis 速度快的原因除了它是内存数据库,使得所有的操作都在内存上进行之外,还有一个重要因素,它实现的数据结构,使得我们对数据进行增删查改操作时,Redis 能高效的处理。 因此,这次我…...

SpringBoot工程启动时自动创建数据库、数据表
文章目录 一,序二,自动创建数据库1. 数据源配置2. 修改支持数据库创建 三,自动创建数据库表以及数据1. 准备DDL、DML语句1.)典型DDL语句2.)典型DML语句 2. 设置初始化参数 四、源码传送 一,序 针对Java工程…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...