读图数据库实战笔记03_遍历
1. Gremlin Server只将数据存储在内存中
1.1. 如果停止Gremlin Server,将丢失数据库里的所有数据
2. 概念
2.1. 遍历(动词)
2.1.1. 当在图数据库中导航时,从顶点到边或从边到顶点的移动过程
2.1.2. 类似于在关系数据库中的查询行为
2.2. 遍历(名词)
2.2.1. 要在图数据库中执行的一个或多个操作
2.2.1.1. 要么返回数据,要么进行更改
2.2.2. 在关系数据库中与之对应的是实际的SQL查询
2.3. 遍历源(traversal source)
2.3.1. TinkerPop特有的概念
2.3.2. 表示遍历图操作的起点或基点
2.3.3. 通常用变量g表示,并且需要位于任何遍历的开头
2.3.4. 从遍历源开始遍历,通过每个分支发送一个遍历器来遍历图
2.4. 遍历器(traverser)
2.4.1. 与遍历执行特定分支相关联的计算过程
2.4.2. 遍历器维护相关图当前分支移动的所有元数据
2.4.2.1. 当前对象、循环信息、历史路径数据等
2.4.3. 唯一遍历器表示通过数据的每个分支
2.4.4. 可以被删除,也可以带着结果返回
3. 遍历图的过程
3.1. 找到起始顶点,确定要遍历的边,遍历该边,最后到达目标顶点完成遍历
3.2. 遍历图需要我们了解图的结构,我们任何时间在图中的位置,以及每个位置的相邻边、相邻顶点和可用属性
3.3. 遍历图数据库的重点是从一个元素遍历到另一个元素
3.3.1. 在清楚地陈述业务问题并彻底理解用例之后,应该会发现我们的逻辑模型和已识别出的相关模式元素有助于编写遍历
3.4. 通过多个并行进程遍历图
3.4.1. 每个并行进程都称为遍历器
3.5. 遍历是一系列操作
3.5.1. 遍历的每个操作都是从一个位置开始,并且(几乎总是)在不同的位置结束
3.5.2. 每个操作都从上一个操作结束的位置继续
3.6. 遍历需要知道我们在图中的位置
3.6.1. 在关系数据库中,SQL查询能够在查询的任意点连接任意两个表
3.6.2. 在图中,则只能使用图中当前位置旁边的边或顶点
3.6.3. 为了有效地在整个图中导航,必须跟踪我们在图数据模型结构中的位置
3.6.3.1. 最难掌握的技能
3.7. 边的方向很重要
3.7.1. 边的有向性是图数据库的一个关键能力,对于筛选或决定要遍历哪些边非常有用
3.7.2. 关系的这种方向性与关系数据库中不同,后者中的所有关系都是双向的
3.7.3. 在图数据库中,不仅要决定边的方向,还要确定我们希望如何遍历该边
3.7.3.1. 只遍历入边、出边,还是同时遍历两者
3.8. 遍历并不包含历史记录
3.8.1. 在图数据库中,从遍历返回的唯一值是结束顶点
4. 使用Gremlin编写遍历
4.1. TinkerPop允许在Gremlin代码中使用任何模式,因此本身完全避免了模式定义的问题
4.2. 所有图查询语言都普遍需要理解筛选及边的方向性才能在图中移动
4.3. 一旦从关系数据库转移到图数据库里这种根据当前位置来考虑遍历的思考方式,我们就养成了利用数据中关系的必备思维习惯
4.4. 遍历API
4.4.1. 按照惯例以变量g开头:g =graph.traversal()
4.5. 内部API
4.5.1. 专为创建图数据库引擎的开发人员而设计
4.5.2. 图API
4.5.2.1. 就像关系数据库中可以通过C/C++、C#或Java等编程语言直接操纵位于SQL语言抽象之下的具体数据库文件的API
4.5.3. 它是一个接口,用于为Vertex(顶点)、Edge(边)、VertexProperty(顶点属性)和Property(属性)对象的集合定义容器对象
4.5.4. 它也是一种数据结构,不能提供有效的导航方式,只能提供在图中定位单个数据元素的最基本能力
4.6. 谁是Ted的朋友
4.7. api
g.V().has('person', 'first_name', 'Ted').out('friends').values('first_name')
==>Josh4.7.1. g
4.7.1.1. 表示图的遍历源
4.7.1.2. 是所有遍历的基石
4.7.1.3. 可以任意命名,但是TinkerPop图数据库在事务模式下的惯例是使用g
4.7.1.4. Gremlin的关键概念:g != graph
4.7.1.4.1. g指遍历源,而不是图
4.7.2. V()操作
4.7.2.1. 返回一个包含图中每个顶点的迭代器
4.7.2.2. 两个全局图操作之一
4.7.2.3. 另一个全局图操作是E()
4.7.2.3.1. 返回一个包含图中每条边的迭代器
4.7.2.3.2. 为了维护或基于数据完整性考虑时才使用
4.7.2.4. 遍历的第二个操作始终是这两个操作之一
4.7.2.5. 使用V()从顶点开始遍历是目前最常见的做法
4.7.2.5.1. 在遍历中,几乎总是从V()开始
4.7.2.6. 为事务操作编写的每次遍历几乎都是从一个或一组顶点开始的
4.7.3. has()操作
4.7.3.1. 筛选操作
4.7.3.2. 它只经过满足以下筛选条件的顶点或边
4.7.3.2.1. 匹配指定的标签(如果指定了)
4.7.3.2.2. 具有与指定键-值对匹配的键-值对
4.7.3.3. hasLabel(label):返回匹配指定标签类型的所有顶点或边
4.7.3.4. has(key,value):返回匹配指定键-值对的所有顶点或边
4.7.3.5. has(label,key,value):返回同时匹配标签类型和指定键-值对的所有顶点或边
4.7.3.5.1. g.V().hasLabel('person').has('first_name', 'Ted')
4.7.3.5.1.1. 等同
4.7.3.6. 出于负载和性能的考虑必须尽快缩减起始遍历器的数量
4.7.3.7. 起始位置越少通常意味着遍历图的总体工作量越少
4.7.3.7.1. 在遍历的第一个操作中将可能的顶点筛选为具有一个或多个has()操作的小子集是很常见的
4.7.4. out(label)操作
4.7.4.1. 遍历操作
4.7.4.2. 遍历所有出边到带有指定标签的相邻顶点(如果指定了标签)
4.7.4.3. 如果没有指定标签,那么就会遍历所有出边
4.7.4.4. 沿任一方向遍历关系的灵活性是图数据库的基本功能,但也可能是一把双刃剑
4.7.4.5. 方向性会筛选我们的遍历,虽然既有助于可读性又有助于性能,但也有局限性
4.7.4.6. 另一个常见的遍历操作是in(label),它将遍历所有入边到带有指定标签的相邻顶点(如果指定了标签)
4.7.4.7. both(label)
4.7.4.7.1. 沿着给定标签的边从一个顶点遍历到相邻顶点
4.7.4.7.2. 同时在入和出两个方向遍历边
4.7.5. values(keys...)操作
4.7.5.1. 值操作检索属性
4.7.5.2. 返回元素属性的值
4.7.5.3. 如果元素有N个属性,那么输出将包含N行
4.7.5.4. 如果指定了一个或多个键,则仅返回具有这些键的属性
4.7.5.5. valueMap(keys...),它返回匹配这些键的属性(包括键和值)
5. 递归遍历
5.1. 循环遍历
5.2. 处理需要连续多次执行遍历某些部分的问题
5.2.1. 物料清单
5.2.1.1. 标准物料清单由多个零件组成,每个零件又由多个零件组成,这些零件还是由多个零件组成
5.2.2. 地图导航
5.2.2.1. 给定地图上的两个位置,提供从起始位置到结束位置的街道和转弯的列表
5.2.2.2. 尽管这两个位置是相连的,但是无法提前预测所需的转弯次数
5.2.3. 任务依赖关系
5.2.3.1. 对于每一个项,都可以将其链接到任何它依赖的工作项,也就是说在图中将这些项连接到它们的依赖项,以此类推
5.3. 图数据库是为处理高度互连的数据而优化过的,因此图数据库的查询语言和底层数据结构也经过优化,能快速执行递归查询
5.3.1. 在关系数据库中,这可能会通过递归CTE来处理,很难编码和维护
6. 使用Gremlin编写递归遍历
6.1. 为Ted找到“朋友的朋友”
6.2. api
g.V().has('person', 'first_name', 'Ted').out('friends').out('friends').values('first_name')
==>Hank6.3. api
g.V().has('person','first_name','Ted').repeat(out()).until(has('person','first_name','Dave')).values('first_name')6.3.1. repeat(traversal)
6.3.1.1. 重复循环遍历操作,直到接收到停止指示为止
6.3.1.2. traversal参数表示要在循环中重复的一组Gremlin操作
6.3.2. until(traversal)
6.3.2.1. repeat()循环的修饰符
6.3.2.2. traversal参数表示要为每次循环计算一遍的一组Gremlin操作
6.3.2.3. 当traversal参数里的计算结果为true时,退出repeat()操作
6.3.2.4. 对于不知道需要递归多少次的情况,使用until()操作
6.3.2.5. until()操作允许持续循环,直到满足指定的条件为止
6.3.2.6. 可能会产生性能问题,因为遍历会一直运行到满足条件为止
6.3.2.7. 如果条件从未满足,则继续执行,直到耗尽图中所有可能的路径
6.3.2.7.1. 无界遍历
6.3.2.8. 建议使用times()操作指定最大迭代次数,或者使用timeLimit()操作指定时间限制
6.3.3. 如果until()操作在repeat()操作之前,则循环作为while-do循环运行
6.3.3.1. 在循环开始就检查
6.3.3.2. 可能根本不执行
6.3.3.3. api
g.V().has('person', 'first_name', 'Ted').until(has('person', 'first_name', 'Hank')).repeat(out('friends')).values('first_name')
==>Hank6.3.4. 如果until()操作在repeat()操作之后,则循环作为do-while循环运行
6.3.4.1. 在循环末尾才检查表达式
6.3.4.2. 总是至少执行一次
6.4. api
g.V().has('person', 'first_name', 'Ted').repeat(out('friends')).times(2).values('first_name')
==>Hank6.4.1. times(integer)
6.4.1.1. repeat()循环的修饰符
6.4.1.2. integer参数表示要循环执行的次数
6.5. api
g.V().has('person', 'first_name', 'Ted').until(has('person', 'first_name', 'Hank')).repeat(out('friends')).emit().values('first_name')
==>Josh
==>Hank
==>Hank6.5.1. emit()操作
6.5.1.1. emit()操作通知repeat()操作在循环当前位置发送值到控制台
6.5.1.2. emit()操作与until()操作类似,放在repeat()操作之前或之后会影响它的行为
6.5.1.3. 如果emit()放置在repeat()之前,会包含起始顶点
6.5.1.4. 如果emit()放置在repeat()之前,会包含起始顶点
6.5.1.5. 仅仅更改emit()操作的位置也会修改递归循环的结果
6.5.1.5.1. 灵活性是以增加复杂性为代价的
6.6. 如果将在图中编写递归查询的简单性与在SQL中回答相同类型问题的复杂性进行比较,你会开始注意到为什么图数据库擅长回答这类问题
相关文章:
读图数据库实战笔记03_遍历
1. Gremlin Server只将数据存储在内存中 1.1. 如果停止Gremlin Server,将丢失数据库里的所有数据 2. 概念 2.1. 遍历(动词) 2.1.1. 当在图数据库中导航时,从顶点到边或从边到顶点的移动过程 2.1.2. 类似于在关系数据库中的查…...

QT如何检测当前系统是是Windows还是Uninx或Mac?以及是哪个版本?
简介 通过Qt获取当前系统及版本号,需要用到QSysInfo。 QSysInfo类提供有关系统的信息。 WordSize指定了应用程序编译所在的平台的指针大小。 ByteOrder指定了平台是大端序还是小端序。 某些常量仅在特定的平台上定义。您可以使用预处理器符号Q_OS_WIN和Q_OS_MACOS来…...
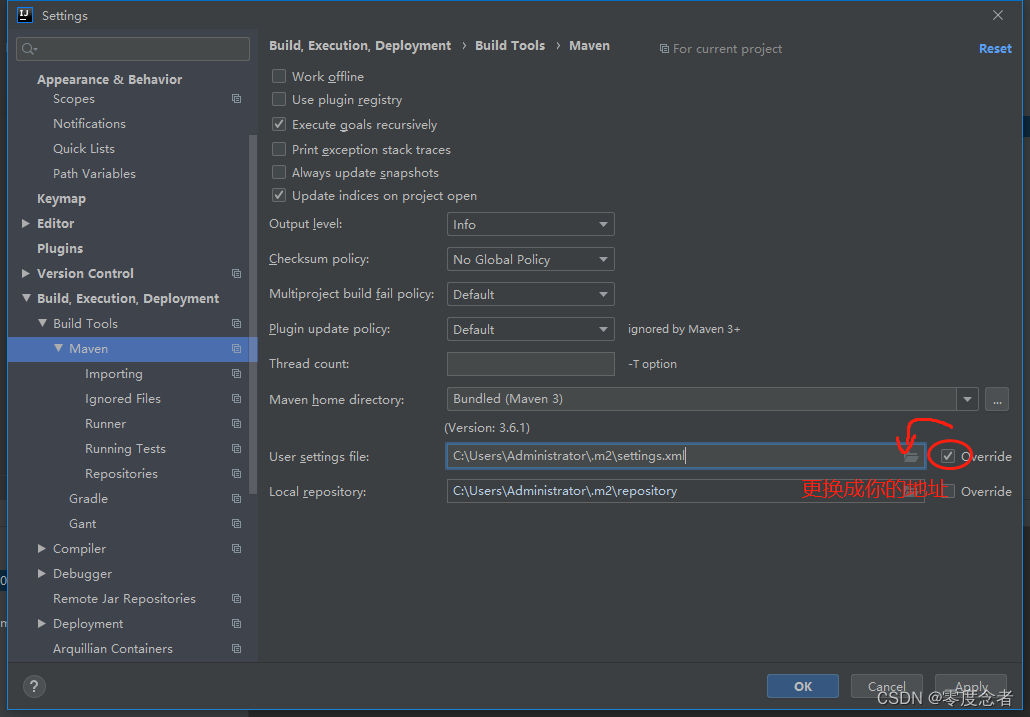
Maven配置阿里云中央仓库settings.xml
Maven配置阿里云settings.xml 前言一、阿里云settings.xml二、使用步骤1.任意目录创建settings.xml2.使用阿里云仓库 总结 前言 国内网络从maven中央仓库下载文件通常是比较慢的,所以建议配置阿里云代理镜像以提高jar包下载速度,IDEA中我们需要配置自己…...

由浅入深C系列八:如何高效使用和处理Json格式的数据
如何高效使用和处理JSON格式的数据 问题引入关于CJSON示例代码头文件引用处理数据 问题引入 最近的项目在用c处理后台的数据时,因为好多外部接口都在使用Json格式作为返回的数据结构和数据描述,如何在c中高效使用和处理Json格式的数据就成为了必须要解决…...
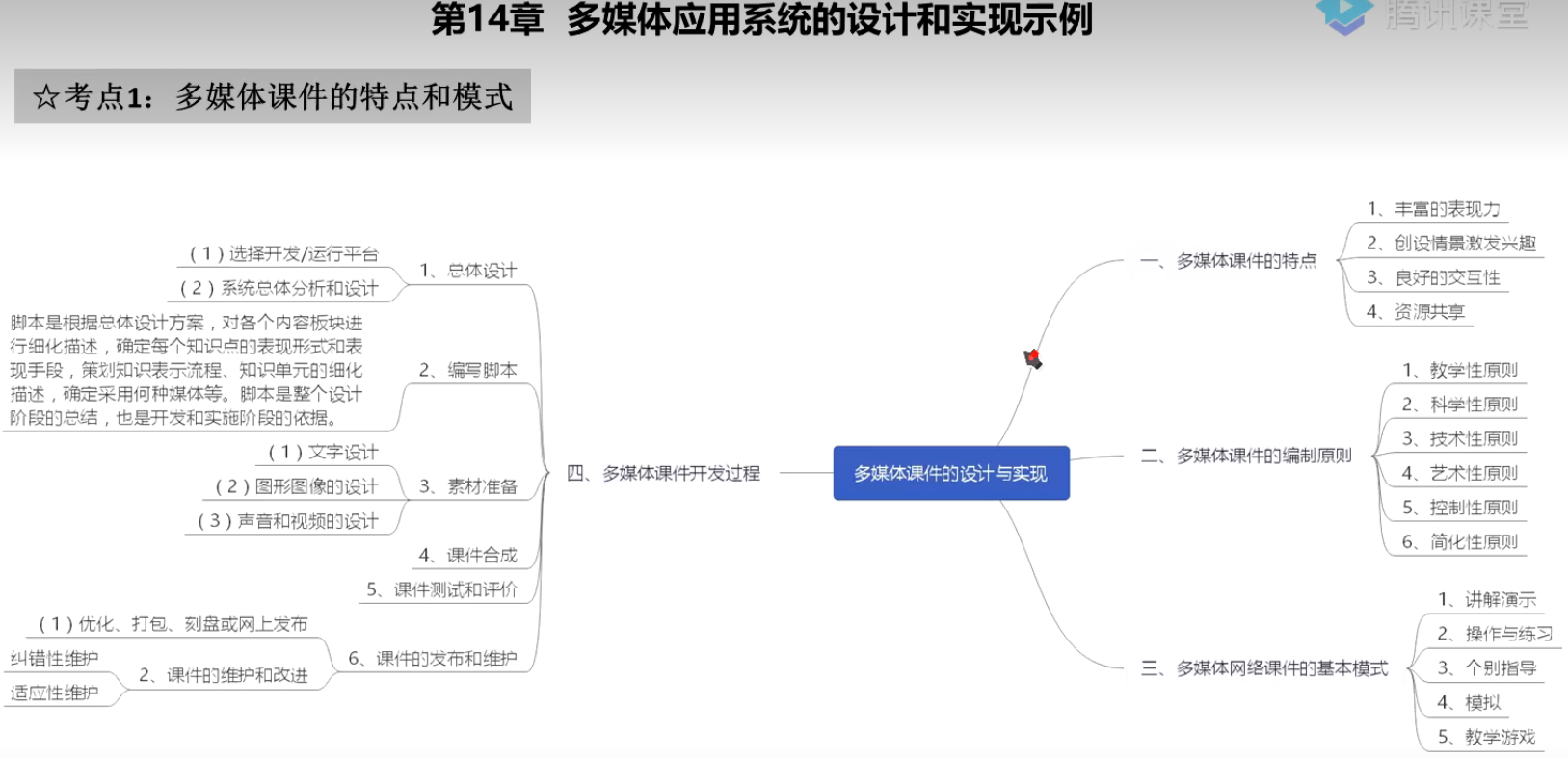
多媒体应用设计师 第16章 多媒体应用系统的设计和实现示例
口诀 思维导图 2020...

golang平滑重启库overseer实现原理
overseer主要完成了三部分功能: 1、连接的无损关闭,2、连接的平滑重启,3、文件变更的自动重启。 下面依次讲一下: 一、连接的无损关闭 golang官方的net包是不支持连接的无损关闭的,当主监听协程退出时,…...
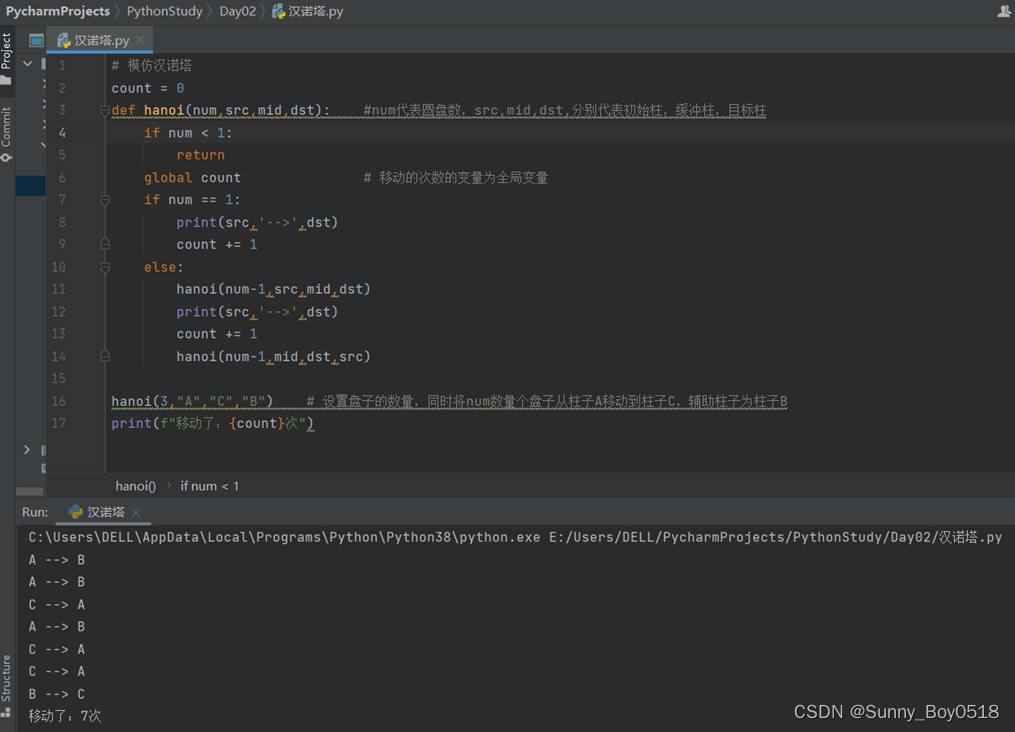
用Python定义一个函数,用递归的方式模拟汉诺塔问题
【任务需求】 定义一个函数,用递归的方式模拟汉诺塔问题,三个柱子,分别为A、B、C,其中A柱子上有N个盘子,从小到大编号为1到N,盘子大小不同。现在要将这N个盘子从A柱子移动到C柱子上,但移动的过…...

二手的需求
案例1030 某天项目经理小王,从用户现场带回了需求,以图形的方式,交给了产品经理。告诉他就照这样设计,结果是项目经理放弃让产品经理出效果图。 原因是产品经理觉得项目经理带回来的需求有问题。项目经理解释产品经理不接受&…...
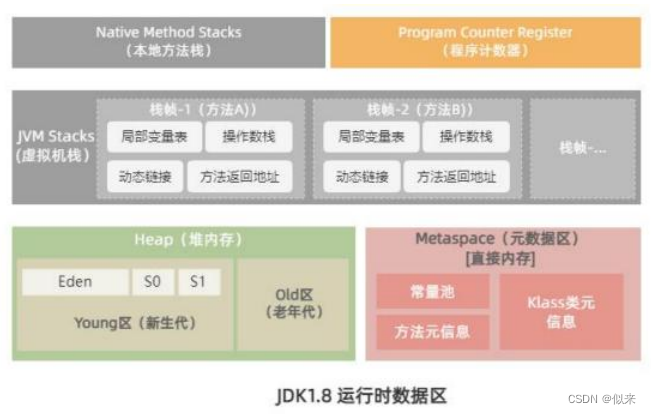
大厂面试题-JVM为什么使用元空间替换了永久代?
目录 面试解析 问题答案 面试解析 我们都知道Java8以及以后的版本中,JVM运行时数据区的结构都在慢慢调整和优化。但实际上这些变化,对于业务开发的小伙伴来说,没有任何影响。 因此我可以说,99%的人都回答不出这个问题。 但是…...
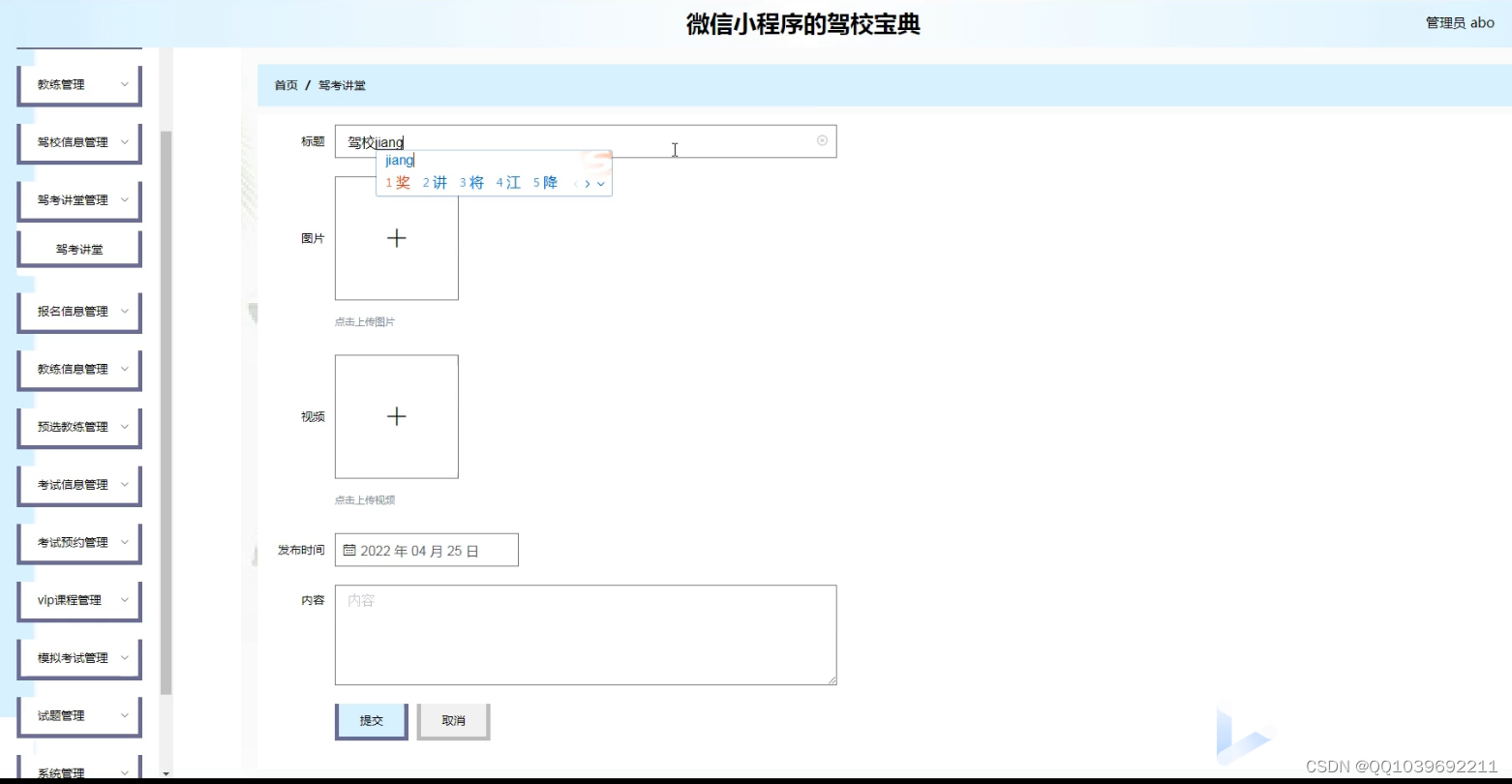
基本微信小程序的驾校宝典系统-驾照考试系统
项目介绍 系统模块分析是对系统的各个模块做出相应的说明以及解释。此系统的模块分别有用户模块、服务端模块和管理端模块这两大基本模块,其中服务端模块包括了首页、教练信息、教练咨讯、考试预约、我的等;而管理端模块则包括了个人中心、用户管理、教…...
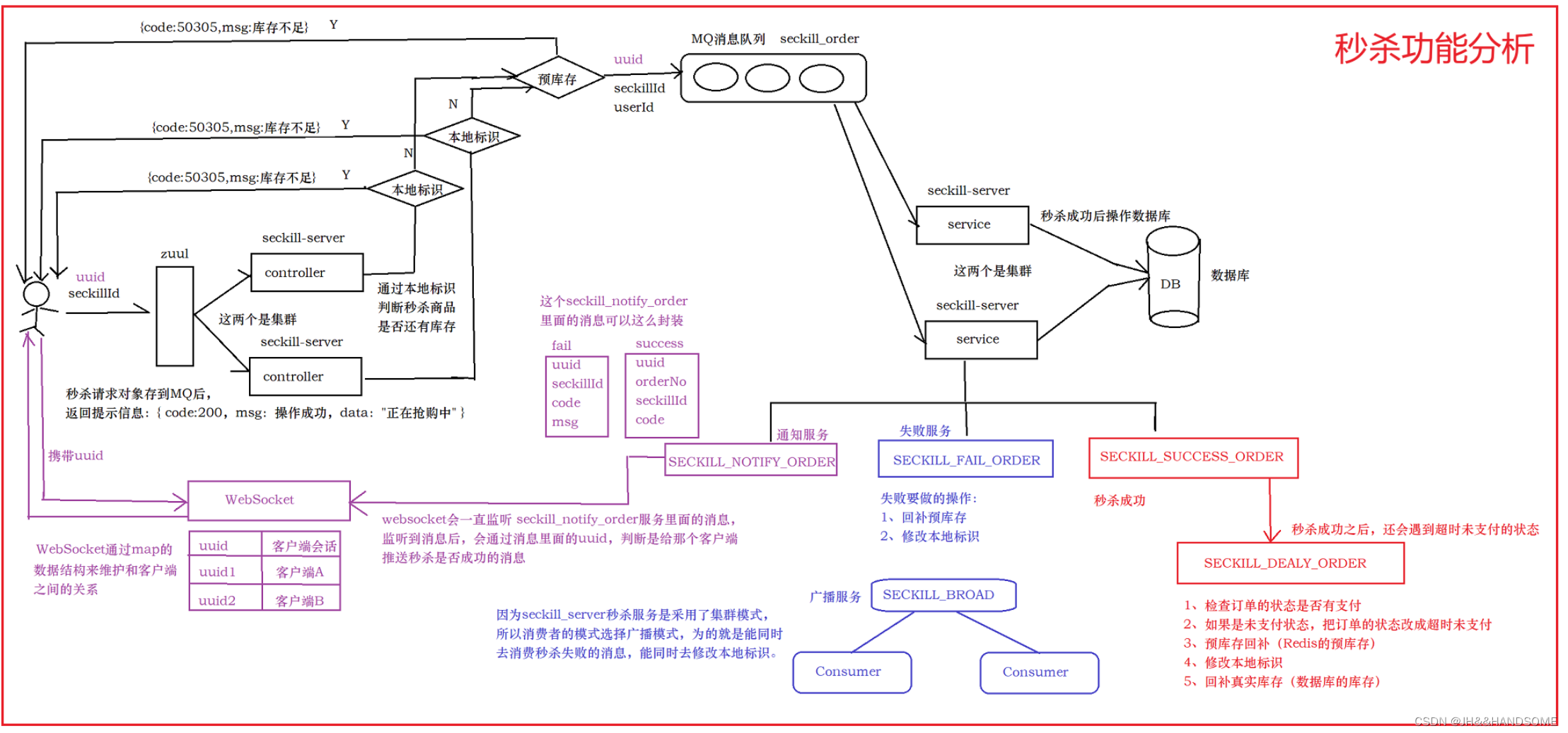
02、SpringCloud -- Redis和Cookie过期时间刷新功能
目录 需求:代码流程过滤器类工具类过滤判断远程调用feign接口gitee 配置接口实现过滤器run方法测试:问题:秒杀功能完整分析图 需求: cookie应该写在网关中,网关中可以自定义filter过滤器,用来实现cookie的刷新和redis中key的刷新,延长用户的操作时间。 就是让用户每操…...

【报错】kali安装ngrok报错解决办法(zsh: exec format error: ./ngrok)
问题描述 kali安装ngrok令牌授权失败 在安装配置文件的时候报错:zsh: exec format error: ./ngrok 原因分析: 在Kali Linux上执行./ngrok时出现zsh exec格式错误的问题可能是由于未安装正确版本的ngrok或操作系统不兼容ngrok导致的。以下是一些可能的解…...

<学习笔记>从零开始自学Python-之-常用库篇(十三)内置小型数据库shelve
一、shelve简介: shelve是Python当中数据储存的方案,类似key-value数据库,便于保存Python对象,shelve只有一个open()函数,用来打开指定的文件(字典),会返回一…...

Redis快速上手篇七(集群-六台虚拟机)
Redis集群 主从复制的场景无法吗满足主机单点故障时需要引入集群配置 一般数据库要处理的读请求远大于写请求 ,针对这种情况,我们优化数据库可以采用读写分离的策略。我们可以部 署一台主服务器主要用来处理写请求,部署多台从服务器 &#…...

LeetCode 301. 删除无效的括号【字符串,回溯或BFS】困难
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

面试经典159题——Day25
文章目录 一、题目二、题解 一、题目 125. Valid Palindrome A phrase is a palindrome if, after converting all uppercase letters into lowercase letters and removing all non-alphanumeric characters, it reads the same forward and backward. Alphanumeric charact…...
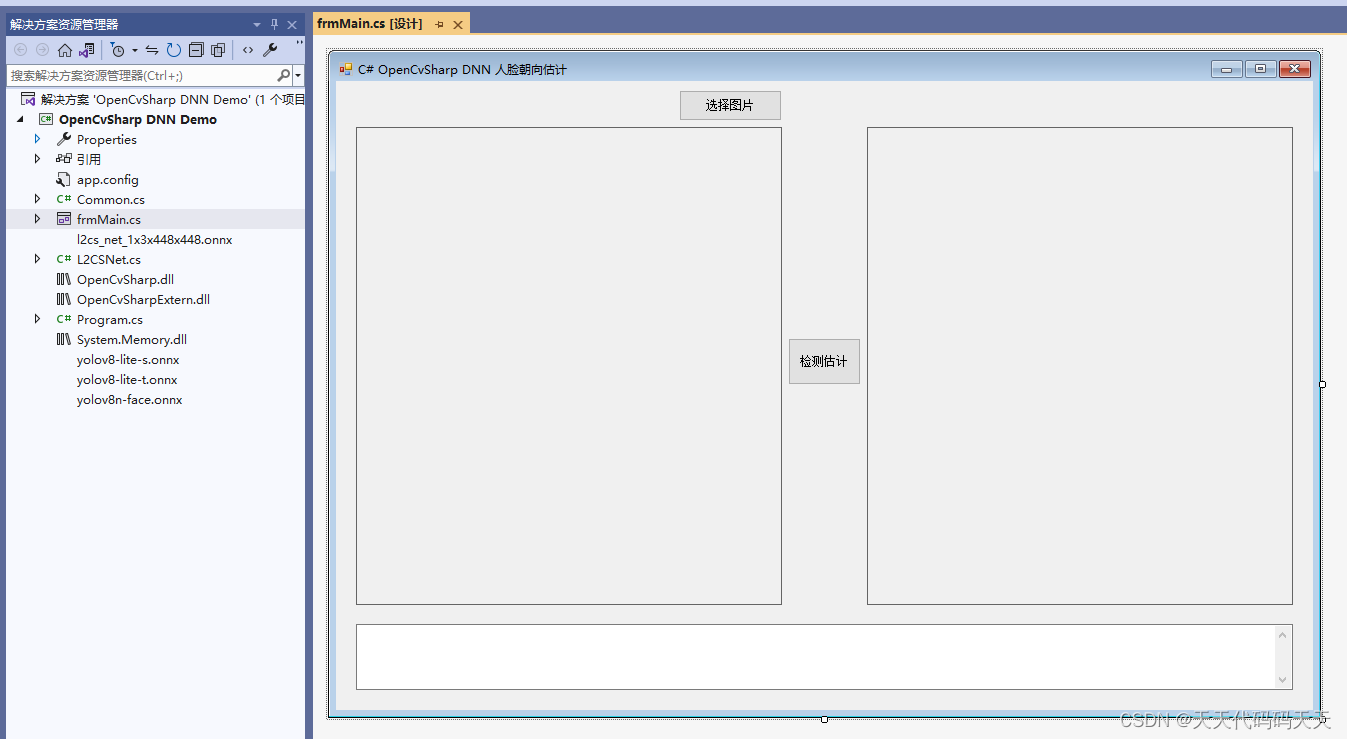
C# OpenCvSharp DNN 部署L2CS-Net人脸朝向估计
效果 项目 代码 using OpenCvSharp; using OpenCvSharp.Dnn; using System; using System.Collections.Generic; using System.Drawing; using System.Drawing.Drawing2D; using System.Linq; using System.Text; using System.Windows.Forms;namespace OpenCvSharp_DNN_Demo …...
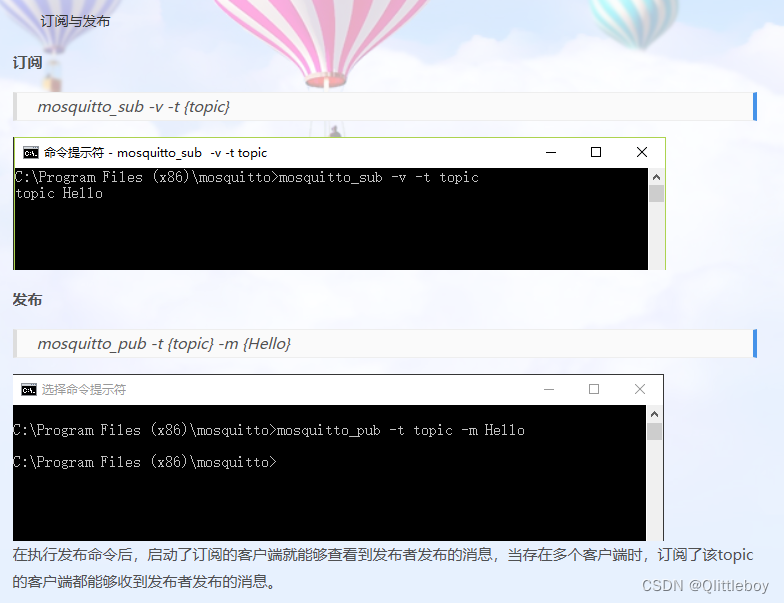
Windows环境下MosQuitto服务器搭建,安装mqtt服务端软件
1、下载、安装MosQuitto服务器 下载地址:http://mosquitto.org/files/binary/ 根据平台选择相应的代码下载。 安装完成后,安装文件夹下部分文件的功能...
web前端JS基础-----制作进度条
1,参考代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><progress id"pro" max"100" value"0"></progress><scrip…...

Linux命令解压多个tar.gz包
命令行解压单个tar.gz包: tar zxvf package.tar.gz 命令行解压多个tar.gz包: for f in *.tar.gz; do tar zxvf "$f"; done 这个命令会循环遍历当前目录下的所有tar.gz包,然后逐个解压。 注:如果想要解压到指定的目…...

AsrTools终极指南:三步实现免费语音转文本,效率提升300%的完整方案
AsrTools终极指南:三步实现免费语音转文本,效率提升300%的完整方案 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn yo…...

使用Chandra构建数学建模助手:美赛备战全攻略
使用Chandra构建数学建模助手:美赛备战全攻略 1. 引言 数学建模竞赛就像一场智力马拉松,需要在有限时间内解决复杂问题。每年美赛期间,无数团队熬夜奋战,只为找到最优解决方案。但现实往往是:选题纠结、算法选择困难…...

从MATLAB验证到FPGA上板:双频信号叠加的完整开发闭环实战
从MATLAB验证到FPGA上板:双频信号叠加的完整开发闭环实战 在数字信号处理领域,实现双频信号的精确叠加是一个常见但极具挑战性的任务。无论是通信系统中的载波调制,还是音频处理中的音效合成,都需要工程师能够准确地在硬件层面实现…...

别再纠结了!.NET后台任务调度,Hangfire和Quartz.NET到底怎么选?
Hangfire与Quartz.NET深度抉择指南:从业务场景到技术实现的精准匹配 在.NET生态系统中,后台任务调度是几乎所有企业级应用都无法绕开的核心需求。无论是电商平台的订单状态更新、金融系统的日终批处理,还是内容管理系统的定时数据同步&#x…...
:微服务架构详解与微服务部署,及同步问题总览(第一篇,总共三篇))
【Oracle篇】基于OGG 21c全程图形化实现9TB数据从Oracle 11g到19c的不停机迁移(上):微服务架构详解与微服务部署,及同步问题总览(第一篇,总共三篇)
💫《博主主页》: 🔎 CSDN主页: 奈斯DB 🔎 IF Club社区主页: 奈斯、 🔎 微信公众号: 奈斯DB 🔥《擅长领域》: 🗃️ 数据库…...

Bilibili-Evolved性能优化实战:突破60fps流畅播放全解析
Bilibili-Evolved性能优化实战:突破60fps流畅播放全解析 【免费下载链接】Bilibili-Evolved 强大的哔哩哔哩增强脚本 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Evolved Bilibili-Evolved作为强大的哔哩哔哩增强脚本,通过深度优化浏…...
之核心模块回调函数解析)
DRM驱动(三)之核心模块回调函数解析
1. DRM驱动回调函数的核心作用 如果你曾经在Linux系统下开发过显示驱动,一定会对DRM(Direct Rendering Manager)框架不陌生。作为现代Linux显示系统的核心,DRM框架通过一系列精心设计的回调函数,让硬件厂商能够灵活地适…...

Qwen3.5-9B实战案例:用128K上下文做法律合同比对与风险提示
Qwen3.5-9B实战案例:用128K上下文做法律合同比对与风险提示 1. 项目概述 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,在专业领域的逻辑推理和长文本处理方面表现出色。本文将重点展示如何利用其128K tokens的超长上下文能力,实现法律合…...

终极指南:如何使用RPGMakerDecrypter轻松解密游戏资源
终极指南:如何使用RPGMakerDecrypter轻松解密游戏资源 【免费下载链接】RPGMakerDecrypter Tool for extracting RPG Maker XP, VX and VX Ace encrypted archives. 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerDecrypter RPGMakerDecrypter是一款…...

BAGEL终极指南:解密多模态AI模型的三大核心组件协同机制
BAGEL终极指南:解密多模态AI模型的三大核心组件协同机制 【免费下载链接】Bagel BAGEL是一个开源的多模态基础模型,拥有70亿个活跃参数(总共140亿个),在大规模交错的多模态数据上进行了训练。BAGEL在标准的多模态理解排…...