深度学习_2 数据操作
数据操作
机器学习包括的核心组件有:
- 可以用来学习的数据(data);
- 如何转换数据的模型(model);
- 一个目标函数(objective function),用来量化模型的有效性;
- 调整模型参数以优化目标函数的算法(algorithm)。
我们要从数据中提取出特征,机器学习、深度学习通过特征来进一步计算得到模型。因此下面主要介绍的是对数据要做哪些操作。
基本操作
深度学习里最多操作的数据结构是N维的数组。
0维:一个数,一个标量,比如1.
1维:比如一个一维数组,他的数据是一个一维的向量(特征向量)。
2维:比如二维数组(特征矩阵)。
当然还有更多维度,比如视频的长,宽,时间,批量大小,通道……
如果我们想创建这样一个数组,需要明确的因素:
- 数组结构,比如3*4.
- 数组数据类型,浮点?整形?
- 具体每个元素的值。
访问元素的方式:
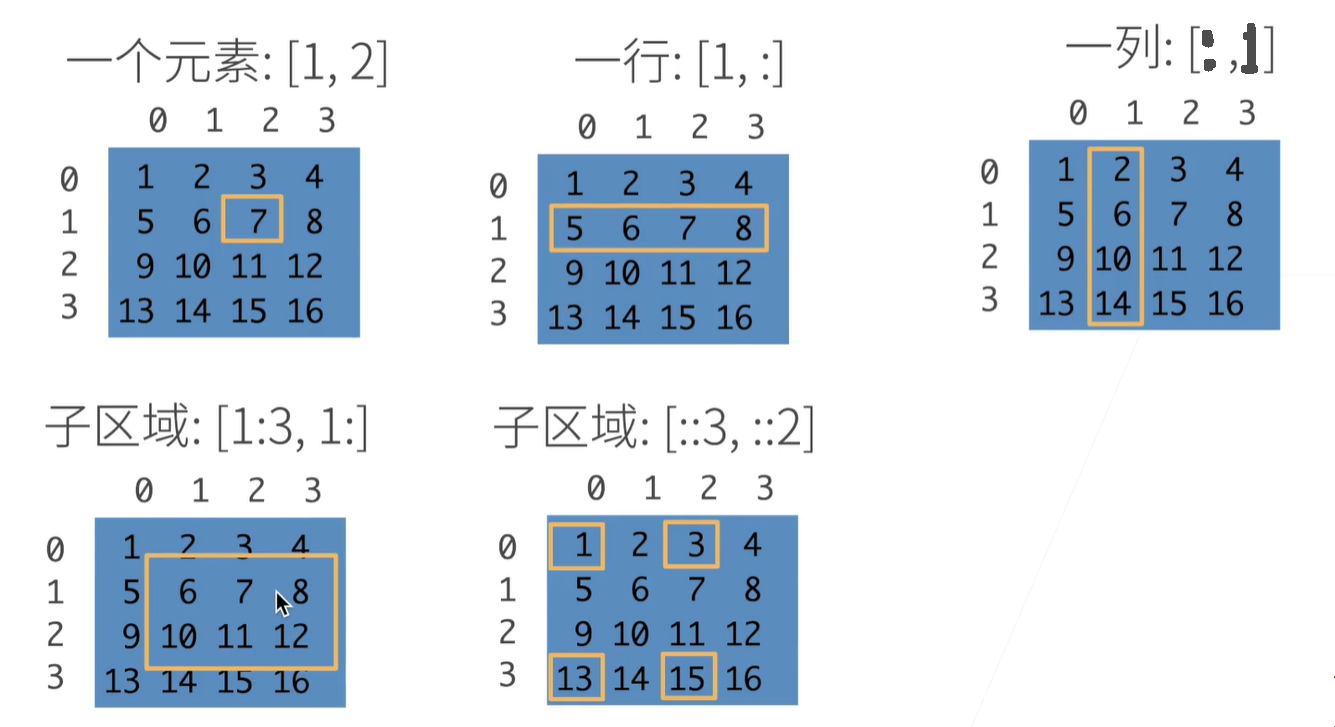
1:3 是左闭右开,表示不包含第3行。
双冒号是跳着访问,后跟步长。比如 ::3 表示从第0行开始访问,每3行访问一次。
明白了这些,那接下来我们就创建一个数组。在机器学习中这种数据的容器一般被称作张量.
创建张量
这部分代码在 jupyter/pytorch/chapter_preliminaries/ndarray.ipynb 里。
在其中可以运行尝试代码部分,创建一维张量:
import torch
X = torch.arange(12) # 自动创建 0-11 的一维张量。输入 X 查看 X 内元素数据,输出:
# tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
X.shape # 查看向量形状。输出 torch.Size([12]),指长12的一维向量
X.numel() # 只获取长度,输出12
X = X.reshape(3, 4) # 重新改成了3行4列形状。变成了0123 4567 891011
torch.zeros((2, 3, 4)) # 创建了一个形状为(2,3,4)的全0张量
# tensor([[[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]],
#
# [[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]]])
# torch.ones 同理,是全1的
# torch.randn 是取随机数,随机数是均值=0,方差=1的一个高斯分布中取
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]) # 给定值创建
torch.exp(X) # 求e^x中每个元素值得到的新张量
reshape 很有意思,它不是复制原数组后重新开辟了一片空间,而是还是对原数组元素的操作(只不过原来是连续12个数,现在我们把他们视作4个一行的3行元素。存储空间都是连续的)。因此如果我们对 reshape 后的数组赋值,原数组值也会改变。
算术运算
对于两个相同形状的向量可以进行+ - * / **(求幂运算)运算。
x = torch.tensor([1.0, 2, 4, 8]) # 1.0 为了让这个数组变成浮点数组
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
# Output:
(tensor([ 3., 4., 6., 10.]),tensor([-1., 0., 2., 6.]),tensor([ 2., 4., 8., 16.]),tensor([0.5000, 1.0000, 2.0000, 4.0000]),tensor([ 1., 4., 16., 64.]))
x==y # 每一项分别判断是否相等。我试了一下,数据类型不影响。2.0==2
x.sum() # 所有元素求和
张量连接
X = torch.arange(12, dtype=torch.float32).reshape((3,4)) # 创建 float32 位的张量
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1) # 行和列两个维度的拼接
# Output:
(tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[ 2., 1., 4., 3.],[ 1., 2., 3., 4.],[ 4., 3., 2., 1.]]),tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],[ 4., 5., 6., 7., 1., 2., 3., 4.],[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
# 这里我看到弹幕前辈的讲解,感觉很受用。行是样例,列是特征属性,这个类似 MySQL 的关系数据库理解
广播机制
即使两个张量形状不同,也有可能通过广播机制进行按元素操作。
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b
# Output:
(tensor([[0],[1],[2]]),tensor([[0, 1]]))a + b # 把a按列复制2份,b按行复制3份,都变成3*2的张量进行操作
# Output:
tensor([[0, 1],[1, 2],[2, 3]])
索引
X[-1], X[1:3] # 这里和前面介绍的概念一样。-1 是倒数第一个元素(一个n-1维度张量),1:3 是第2,第3个元素不包括第4个元素。
# Output:
(tensor([ 8., 9., 10., 11.]),tensor([[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]]))
X[1,2]=9 # 写入
X[0:2, :] = 12 # 批量写入,给0-1行,所有列写成12
X
# Output:
tensor([[12., 12., 12., 12.],[12., 12., 12., 12.],[ 8., 9., 10., 11.]])
节省内存
有一些操作会分配新内存。比如 Y=Y+X,并不是直接在 Y 的原地址上加了X,而是在新地址上计算得到 Y+X,让 Y 指向新地址。
可以通过 id(X) 函数来查看地址。
Y[:]=Y+X 或者 Y+=X 会在原地执行计算,Y 地址不变。
类型转换
转换为 numpy 张量:A=X.numpy()
张量转换为标量:
a=torch.tensor([3.5])
a.item() # 3.5
float(a) # 3.5
int(a) # 3
数据预处理
实际处理数据的时候我们并不是从张量数据类型开始的,我们可能得到一个 excel 文件,自己把它转换成 python 张量。以及在转换之前,我们可能对数据进行预处理,比如把其中的空值统一赋值为0之类的操作。以下是转换步骤。
首先我们创建一个 csv 文件作为原始数据集。
import osos.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')
三个属性分别是 room 数量,走廊状态(比如铺了地板),价格。
然后我们把这个数据读入 python,加载原始数据集。
# 如果没有安装pandas,只需取消对以下行的注释来安装pandas
# !pip install pandas
import pandas as pddata = pd.read_csv(data_file)
这个数据集里还是有很多 NaN 项的,我们要对其进行修改替换。数值类典型处理方式是插值和删除。
首先最后一列数据是完整不需要修改的,那么我们只要处理前两列,我们把前两列数据单独拿出来做完处理最后进行张量拼接。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
然后我们把 NumEooms 中的 NaN 值用均值替代,
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
# Output:NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
对于 Alley 列,只有两种状态:NaN 和 Pave。我们用 pandas 的方法,把 NaN 也视作一个类,自动拆成两列设置值。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
# Output:NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
最后,我们将前两列处理后得到的结果与最后一列转换为张量后进行拼接。
import torchX = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
y=y.reshape(4,1)
torch.cat((X,y),dim=1)
# Output:
tensor([[3.0000e+00, 1.0000e+00, 0.0000e+00, 1.2750e+05],[2.0000e+00, 0.0000e+00, 1.0000e+00, 1.0600e+05],[4.0000e+00, 0.0000e+00, 1.0000e+00, 1.7810e+05],[3.0000e+00, 0.0000e+00, 1.0000e+00, 1.4000e+05]], dtype=torch.float64)
相关文章:
深度学习_2 数据操作
数据操作 机器学习包括的核心组件有: 可以用来学习的数据(data);如何转换数据的模型(model);一个目标函数(objective function),用来量化模型的有效性&…...
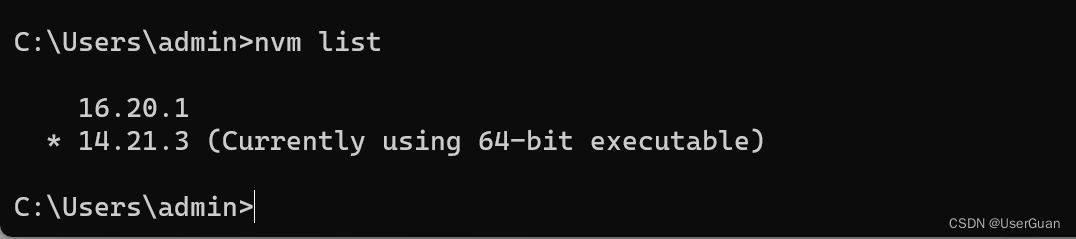
win 下安装 nvm 的使用与配置
nvm 全名 node.js version management,是一个 nodejs 的版本管理工具。通过它可以安装和切换不同版本的 nodejs。 注:如果已经安装了 nodejs 需先卸载后再安装 nvm 为了确保 nodejs 已彻底删除,可以看看安装目录中是否有 node 文件夹&#x…...

Git笔记
删除最后一次提交 git reset --hard HEAD~1...

省钱兄共享茶室共享娱乐室小程序都有哪些功能
随着共享经济的兴起,共享茶室和共享娱乐室作为一种新型的共享空间,逐渐受到了年轻人的青睐。省钱兄共享茶室共享娱乐室小程序作为该领域的优秀代表,集多种功能于一身,为用户提供了一个便捷、舒适、高效的社交娱乐平台。本文将详细…...

vue-cli方式创建vue3工程
创建工程前,可先用命令行查看是否安装vue-cli。 通过命令行查看vue-cli版本 vue --version 如果已安装vue-cli,则会显示当前安装版本 vue/cli 4.5.13 如果没有安装vue-cli,会提示安装 vue : 无法识别“vue”命令 需要通过npm全局安装v…...

四、W5100S/W5500+RP2040树莓派Pico<TCP Server数据回环测试>
文章目录 1. 前言2. 协议简介2.1 简述2.2 优点2.3 应用 3. WIZnet以太网芯片4. TCP Server数据回环测试4.1 程序流程图4.2 测试准备4.3 连接方式4.4 相关代码4.5 测试现象 5. 注意事项6. 相关链接 1. 前言 在计算机网络中,TCP Server是不可或缺的角色,它…...

技术视角下的跑腿小程序开发:关键挑战和解决方案
跑腿小程序作为连接服务提供者和用户的桥梁,面临着诸多技术挑战。本文将聚焦于技术层面的关键挑战,并提供解决方案,以帮助开发者应对技术上的复杂问题。 1. 实时性与性能挑战 挑战: 跑腿小程序需要实时地匹配订单、更新状态和提…...
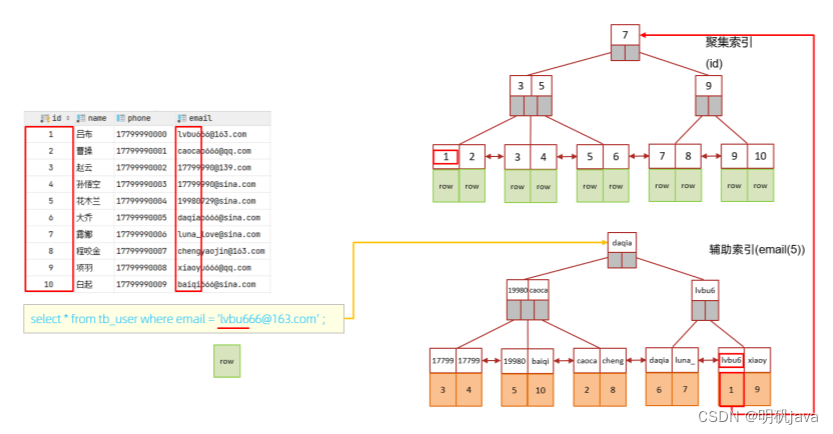
Mysql进阶-索引篇(下)
SQL性能分析 SQL执行频率 MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次,通过sql语句的访问频次,我们可…...

从龙湖智创生活入选金钥匙联盟,透视物业服务力竞争风向
假设你是业主,物业“服务”和“管理”,哪个名词看起来更加亲切、讨喜? 站在个人角度,“服务”更让人感受到温度。但对于一个要长期运营下去的住宅或者商企项目来说,整体的管理又必不可少。前者面向人,后者…...

什么是 CNN? 卷积神经网络? 怎么用 CNN 进行分类?(2)
参考视频:https://www.youtube.com/watch?vE5Z7FQp7AQQ&listPLuhqtP7jdD8CD6rOWy20INGM44kULvrHu 视频4:CNN 中 stride 的概念 如上图,stride 其实就是 ”步伐“ 的概念。 默认情况下,滑动窗口一次移动一步。而当 stride …...
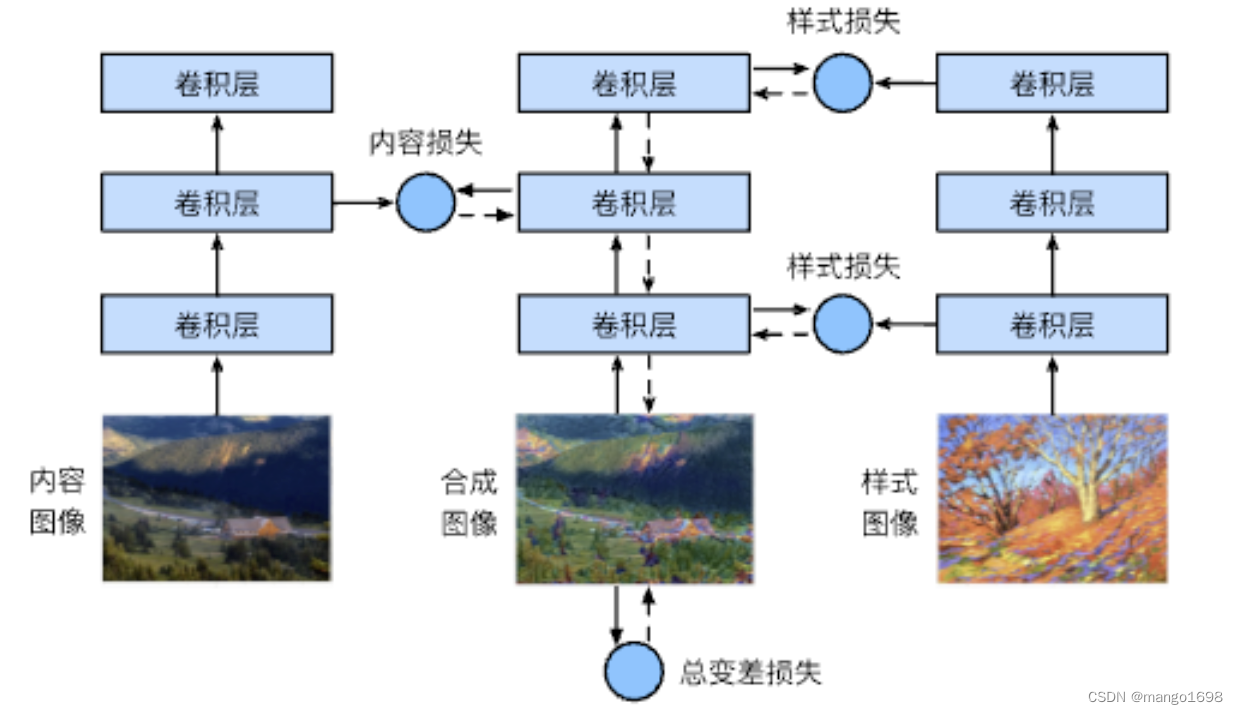
样式迁移 - Style Transfer
所谓风格迁移,其实就是提供一幅画(Reference style image),将任意一张照片转化成这个风格,并尽量保留原照的内容(Content)。 将样式图片中的样式迁移到内容图片上,得到合成图片。 基于CNN的样式迁移 奠基性工作: 首先…...

UE5.3启动C++项目报错崩溃
最近尝试用C来练习,碰到一个启动崩溃的事情 按照官方给的步骤做的:官方链接 结果是自定义的Character的问题,在自定义Character的构造函数里调用了: check(GEngine ! nullptr); GEngine->AddOnScreenDebugMessage(-1, 5, FCol…...

C/S架构和B/S架构
1. C/S架构和B/S架构简介 C/S 架构(Client/Server Architecture)和 B/S 架构(Browser/Server Architecture)是两种不同的软件架构模式,它们描述了客户端和服务器之间的关系以及数据交互的方式。 C/S 架构(…...

【AD9361 数字接口CMOS LVDSSPI】C 并行数据 LVDS
接上一部分,AD9361 数字接口CMOS &LVDS&SPI 目录 一、LVDS模式数据路径和时钟信号LVDS模式数据通路信号[1] DATA_CLK[2] FB_CLK[3] Rx_FRAME[4] Rx_D[5:0][5] Tx_FRAME[6]Tx_D[5:0][7] ENABLE[8] TXNRX系列 二、LVDS最大时钟速率和信…...
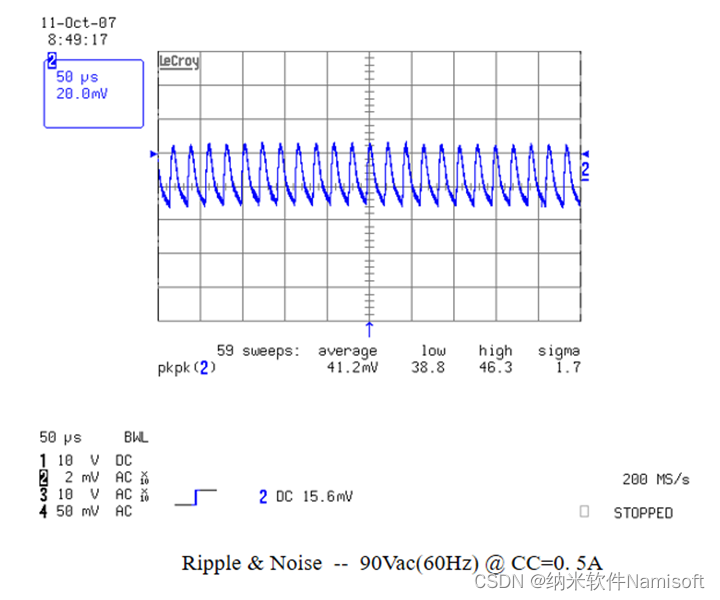
开关电源测试方案分享:电源纹波及噪声测试方法、测试标准
纹波及噪声影响着设备的性能和稳定性,是开关电源测试的重要环节。通过电源纹波噪声测试,检测电源纹波情况,从而提升开关电源的性能。纳米软件开关电源自动化测试软件助力纹波和噪声测试,提升测试效能。 开关电源纹波及噪声测试方法…...
git的使用——如何创建.gitignore文件,排除target、.idea文件夹的提交
前言 git作为开发人员必备的技能,需要熟练掌握,本篇博客记录一些git使用的场景,结合具体问题进行git使用的记录。以gitee的使用为例。 本篇博客介绍如何创建.gitignore文件,排除一些文件夹的提交,比如排除target、.i…...

react-antd组件 input输入框: 实现按回车搜索
目录 法1: 法2: 法1: 在Input组件上绑定onKeyUp方法 import { Input, message } from antd;class App extends React.Component{handeleSousuo () > {this.props.form.validateFields((error, values) > {if(!error){axios.post().t…...
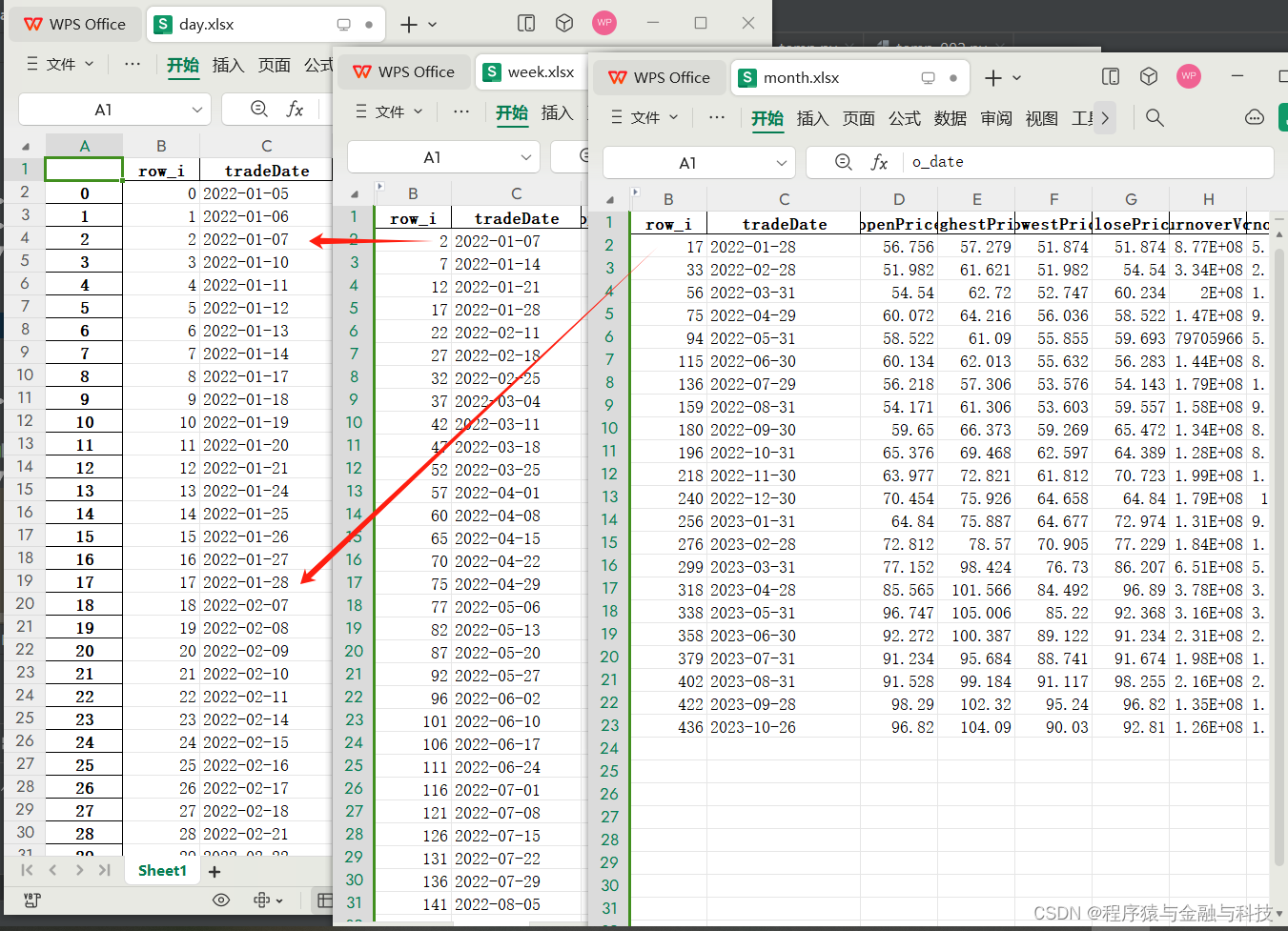
python_PyQt5日周月K线纵向对齐显示_1_数据处理
目录 写在前面: 图形结果显示: 数据设计: 代码: 从日数据中计算周数据、月数据 生成图形显示需要的数据格式 写在前面: “PyQt5日周月K线纵向对齐显示”,将分三篇博文描述 1 数据处理。将数据处理成…...

leetcode经典面试150题---4.删除有序数组中的重复项II
目录 题目描述 前置知识 代码 方法一 双指针 思路 图解 实现 复杂度 题目描述 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数组空间&…...

Transformer英语-法语机器翻译实例
依照Transformer结构来实例化编码器-解码器模型。在这里,指定Transformer编码器和解码器都是2层,都使用4头注意力。为了进行序列到序列的学习,我们在英语-法语机器翻译数据集上训练Transformer模型,如图11.2所示。 da…...

ClawdOS:为AI Agent构建可视化操作系统的全栈实践
1. 项目概述:为你的AI大脑装上眼睛和手如果你和我一样,是OpenClaw(前身是Moltbot/Clawdbot)的早期用户,那你一定经历过这种场景:在终端里,你的AI助手聪明绝顶,能写代码、查资料、分析…...

苹果为何拒绝TD-SCDMA特供版iPhone?复盘技术标准与市场时机的战略博弈
1. 项目概述:一场关于苹果与中国移动的世纪猜想2012年的科技圈,空气中弥漫着一股躁动与期待。几乎所有的行业分析师和手机发烧友都在讨论同一个话题:苹果公司是否会为了全球最大的移动运营商——中国移动,专门推出一款支持TD-SCDM…...

Midjourney生成伪3D到真3D渲染的临界点在哪?——基于1327组渲染样本的Z-depth一致性、法线贴图兼容性与Blender导入成功率实测报告
更多请点击: https://intelliparadigm.com 第一章:Midjourney生成伪3D到真3D渲染的临界点在哪? Midjourney 本身不生成可编辑的 3D 几何体,其输出始终是静态二维图像——即便使用 --style raw 或 --v 6.1 配合 3D render、octane…...

为个人AI助手项目集成多模型API实现成本与性能平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为个人AI助手项目集成多模型API实现成本与性能平衡 构建个人AI助手是许多独立开发者热衷的项目。在开发过程中,一个常见…...

ServerPackCreator终极指南:3分钟自动化创建Minecraft服务器包 [特殊字符]
ServerPackCreator终极指南:3分钟自动化创建Minecraft服务器包 🚀 【免费下载链接】ServerPackCreator Create a server pack from a Minecraft Forge, NeoForge, Fabric, LegacyFabric or Quilt modpack! 项目地址: https://gitcode.com/gh_mirrors/s…...

CentOS 8系统下EMQX 4.3.8安装避坑实录:解决crypto和libncurses依赖报错
CentOS 8系统下EMQX 4.3.8深度部署指南:从依赖解析到高可用架构 在物联网和边缘计算领域,MQTT协议凭借其轻量级和高效性已成为设备通信的事实标准。而EMQX作为基于Erlang/OTP平台开发的开源MQTT消息服务器,其单节点支持200万连接的能力使其成…...

羽毛球每天必练的基本功:拉吊四方球战术、吊杀结合战术
文章目录 引言 I 羽毛球每天必练的基本功 1. 握拍练习 2. 挥拍动作 3. 步法训练 4. 球感练习 5. 发力技巧 II 发力 正确发力 握拍 反手发力 III 羽毛球单打战术 拉吊四方球战术 直线变斜线战术 重复落点战术 吊杀结合战术 追身球压制战术 防守反击战术 引言 打球前必须热身(活…...

泛微OA ecology 9实战:手把手教你写一个能取表单数据的Java自定义接口
泛微OA Ecology 9深度开发:构建高效表单数据交互的Java接口实践 在当今企业数字化转型浪潮中,办公自动化系统(OA)作为核心支撑平台,其灵活性和扩展性直接影响着企业运营效率。泛微OA Ecology 9作为国内领先的协同办公平台,提供了丰…...

用Wireshark抓包分析Powerlink协议:从数据帧看懂主站轮询与从站响应
Wireshark实战:深度解析Powerlink协议的主从站通信机制 工业以太网协议Powerlink凭借其确定性实时通信能力,在自动化控制领域占据重要地位。本文将带您通过Wireshark抓包分析,揭开Powerlink主站轮询与从站响应的核心机制。不同于基础配置教程…...

so_arm101上传云端并握手
采集数据集:一个腕部摄像头lerobot-record \--robot.typeso101_follower \--robot.port/dev/tty.usbmodem5B415317841 \--robot.idzihao_follower_arm \--robot.cameras"{ front: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 60, fourc…...