在 Elasticsearch 中丰富你的 Elasticsearch 文档
作者:David Pilato

对于 Elasticsearch®,我们知道联接应该在 “索引时” 而不是查询时完成。 本博文是一系列三篇博文的开始,因为我们可以在 Elastic® 生态系统中采取多种方法。 我们将介绍如何在 Elasticsearch 中做到这一点。 下一篇博文将介绍如何使用集中式组件 Logstash 来实现这一点,上一篇博文将展示如何使用 Elastic Agent/Beats 在边缘实现这一点。
举一个简单的例子,假设我们是一个电子商务网站,在 kibana_sample_data_logs 中收集日志:
{"agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24","bytes": 1831,"clientip": "30.156.16.164","extension": "","geo": {"srcdest": "US:IN","src": "US","dest": "IN","coordinates": {"lat": 55.53741389,"lon": -132.3975144}},"host": "elastic-elastic-elastic.org","index": "kibana_sample_data_logs","ip": "30.156.16.163","machine": {"ram": 9663676416,"os": "win xp"},"memory": 73240,"message": "30.156.16.163 - - [2018-09-01T12:43:49.756Z] \"GET /wp-login.php HTTP/1.1\" 404 1831 \"-\" \"Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24\"","phpmemory": 73240,"referer": "http://www.elastic-elastic-elastic.com/success/timothy-l-kopra","request": "/wp-login.php","response": 404,"tags": ["success","info"],"timestamp": "2023-03-18T12:43:49.756Z","url": "https://elastic-elastic-elastic.org/wp-login.php","utc_time": "2023-03-18T12:43:49.756Z","event": {"dataset": "sample_web_logs"}
}请注意,你可以通过单击 “Sample web blogs” 框中的 “Add data”按钮,使用 Kibana® 示例数据集轻松导入此数据集:
我们还有一个 VIP 索引,其中包含有关我们客户的信息:
{ "ip" : "30.156.16.164", "vip": true, "name": "David P"
}要导入此示例数据集,我们只需运行:
DELETE /vip
PUT /vip
{"mappings": {"properties": {"ip": { "type": "keyword" },"name": { "type": "text" },"vip": { "type": "boolean" }}}
}
POST /vip/_bulk
{ "index" : { } }
{ "ip" : "30.156.16.164", "vip": true, "name": "David P" }
{ "index" : { } }
{ "ip" : "164.85.94.243", "vip": true, "name": "Philipp K" }
{ "index" : { } }
{ "ip" : "50.184.59.162", "vip": true, "name": "Adrienne V" }
{ "index" : { } }
{ "ip" : "236.212.255.77", "vip": true, "name": "Carly R" }
{ "index" : { } }
{ "ip" : "16.241.165.21", "vip": true, "name": "Naoise R" }
{ "index" : { } }
{ "ip" : "246.106.125.113", "vip": true, "name": "Iulia F" }
{ "index" : { } }
{ "ip" : "81.194.200.150", "vip": true, "name": "Jelena Z" }
{ "index" : { } }
{ "ip" : "111.237.144.54", "vip": true, "name": "Matt R" }要执行 “joins at index time”,我们需要丰富我们的数据集以获得如下所示的最终日志:
{"agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24","bytes": 1831,"clientip": "30.156.16.164","extension": "","geo": {"srcdest": "US:IN","src": "US","dest": "IN","coordinates": {"lat": 55.53741389,"lon": -132.3975144}},"host": "elastic-elastic-elastic.org","index": "kibana_sample_data_logs","ip": "30.156.16.163","machine": {"ram": 9663676416,"os": "win xp"},"memory": 73240,"message": "30.156.16.163 - - [2018-09-01T12:43:49.756Z] \"GET /wp-login.php HTTP/1.1\" 404 1831 \"-\" \"Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24\"","phpmemory": 73240,"referer": "http://www.elastic-elastic-elastic.com/success/timothy-l-kopra","request": "/wp-login.php","response": 404,"tags": ["success","info"],"timestamp": "2023-03-18T12:43:49.756Z","url": "https://elastic-elastic-elastic.org/wp-login.php","utc_time": "2023-03-18T12:43:49.756Z","event": {"dataset": "sample_web_logs"},"vip": true, "name": "David P"
}你可以使用摄取管道中的 Elasticsearch Enrich Processor 开箱即用地执行此操作。 让我们看看如何做到这一点。
在 Elasticsearch 中丰富 Elasticsearch 数据
摄取管道 - ingest pipeline
让我们首先使用摄取管道。
我们可以从一个空的开始,我们将用它来模拟我们想要的行为。 我们不需要原始数据集的完整字段集,因此我们对其进行了简化:
POST /_ingest/pipeline/_simulate
{"docs": [{"_source": {"clientip": "30.156.16.164"}}],"pipeline": {"processors": []}
}我们现在需要向我们的管道添加一个 enrich processor。 但为此,我们需要首先创建一个丰富的策略 (enrich policy):
PUT /_enrich/policy/vip-policy
{"match": {"indices": "vip","match_field": "ip","enrich_fields": ["name", "vip"]}
}创建丰富策略后,我们可以使用执行丰富策略 API 来执行它:
PUT /_enrich/policy/vip-policy/_execute我们现在可以模拟它:
POST /_ingest/pipeline/_simulate
{"docs": [{"_source": {"clientip": "30.156.16.164"}}],"pipeline": {"processors": [{"enrich": {"policy_name": "vip-policy","field": "clientip","target_field": "enriched"}}]}
}这给出如下的响应:
{"docs": [{"doc": {"_index": "_index","_id": "_id","_version": "-3","_source": {"enriched": {"name": "David P","vip": true,"ip": "30.156.16.164"},"clientip": "30.156.16.164"},"_ingest": {"timestamp": "2023-04-06T17:14:29.127569953Z"}}}]
}我们只需清理一下数据即可获得我们期望的结构:
POST /_ingest/pipeline/_simulate
{"docs": [{"_source": {"clientip": "30.156.16.164"}}],"pipeline": {"processors": [{"enrich": {"policy_name": "vip-policy","field": "clientip","target_field": "enriched"}},{"rename": {"field": "enriched.name","target_field": "name"}},{"rename": {"field": "enriched.vip","target_field": "vip"}},{"remove": {"field": "enriched"}}]}
}现在给出了预期的结果:
{"docs": [{"doc": {"_index": "_index","_id": "_id","_version": "-3","_source": {"name": "David P","vip": true,"clientip": "30.156.16.164"},"_ingest": {"timestamp": "2023-04-06T17:16:08.175186282Z"}}}]
}我们现在可以存储最终的管道:
PUT /_ingest/pipeline/vip
{"processors": [{"enrich": {"policy_name": "vip-policy","field": "clientip","target_field": "enriched"}},{"rename": {"field": "enriched.name","target_field": "name","ignore_failure": true}},{"rename": {"field": "enriched.vip","target_field": "vip","ignore_failure": true}},{"remove": {"field": "enriched","ignore_failure": true}}]
}请注意,我们通过添加一些 ignore_failure 指令对其进行了一些更改,因为我们可能在 vip 索引中找不到任何相关数据。
我们可以使用与源索引相同的映射来创建目标索引:
# Get the source mapping
GET /kibana_sample_data_logs/_mapping# Create the destination index
PUT /kibana_sample_data_logs_new
{// Paste the source mappings structure"mappings": {"properties": {// And add the properties we are adding"name": {"type": "keyword"},"vip": {"type": "boolean"}}}
}并调用重建索引 API:
POST _reindex
{"source": {"index": "kibana_sample_data_logs"},"dest": {"index": "kibana_sample_data_logs_new","pipeline": "vip"}
}让我们检查一下工作是否已完成:
GET /kibana_sample_data_logs_new/_search?filter_path=aggregations.by_name.buckets
{"size": 0,"aggs": {"by_name": {"terms": {"field": "name"}}}
}上述命令给出如下类似的响应:
{"aggregations": {"by_name": {"buckets": [{"key": "David P","doc_count": 100},{"key": "Philipp K","doc_count": 29},{"key": "Adrienne V","doc_count": 26},{"key": "Carly R","doc_count": 26},{"key": "Iulia F","doc_count": 25},{"key": "Naoise R","doc_count": 25},{"key": "Jelena Z","doc_count": 24},{"key": "Matt R","doc_count": 24}]}}
}运行时字段丰富
丰富数据的另一种方法是在搜索时而不是索引时执行此操作。 这与本文的第一句话相悖,但有时,你需要进行一些权衡。 在这里,我们想用搜索速度来交换灵活性。
运行时字段功能 (runtime field feature) 允许丰富搜索响应对象,但不能用于查询或聚合数据。 此功能的一个简单示例:
GET kibana_sample_data_logs/_search?filter_path=hits.hits.fields
{"size": 1,"query": {"match": {"clientip": "30.156.16.164"}}, "runtime_mappings": {"enriched": {"type": "lookup", "target_index": "vip", "input_field": "clientip", "target_field": "ip", "fetch_fields": ["name", "vip"] }},"fields": ["clientip","enriched"],"_source": false
}上述命令给出如下的响应:
{"hits": {"hits": [{"fields": {"enriched": [{"name": ["David P"],"vip": [true]}],"clientip": ["30.156.16.164"]}}]}
}请注意,这也可以添加为映射的一部分:
PUT kibana_sample_data_logs/_mappings
{"runtime": {"enriched": {"type": "lookup", "target_index": "vip", "input_field": "clientip", "target_field": "ip", "fetch_fields": ["name", "vip"] }}
}GET kibana_sample_data_logs/_search
{"size": 1,"query": {"match": {"clientip": "30.156.16.164"}}, "fields": ["clientip","enriched"]
}但是,如果你希望能够搜索或聚合这些字段,则需要在搜索时实际发出 (emit) 一些内容。
请注意,我们不能使用此方法在另一个索引中进行查找。 因此,因为且仅仅因为列表的长度很小,我们可以使用脚本来动态进行 “丰富”:
PUT kibana_sample_data_logs/_mappings
{"runtime": {"name": {"type": "keyword","script": {"source": """def name=params.name;for (int i=0; i< params.lookup.length; i++) {if (params.lookup[i].ip == doc['clientip'].value) {emit(params.lookup[i].name);break;}}""","lang": "painless","params": {"name": "David P","lookup": [{ "ip" : "30.156.16.164", "vip": true, "name": "David P" },{ "ip" : "164.85.94.243", "vip": true, "name": "Philipp K" },{ "ip" : "50.184.59.162", "vip": true, "name": "Adrienne V" },{ "ip" : "236.212.255.77", "vip": true, "name": "Carly R" },{ "ip" : "16.241.165.21", "vip": true, "name": "Naoise R" },{ "ip" : "246.106.125.113", "vip": true, "name": "Iulia F" },{ "ip" : "81.194.200.150", "vip": true, "name": "Jelena Z" },{ "ip" : "111.237.144.54", "vip": true, "name": "Matt R" }]}}},"vip": {"type": "boolean","script": {"source": """def name=params.name;for (int i=0; i< params.lookup.length; i++) {if (params.lookup[i].ip == doc['clientip'].value) {emit(params.lookup[i].vip);break;}}""","lang": "painless","params": {"name": "David P","lookup": [{ "ip" : "30.156.16.164", "vip": true, "name": "David P" },{ "ip" : "164.85.94.243", "vip": true, "name": "Philipp K" },{ "ip" : "50.184.59.162", "vip": true, "name": "Adrienne V" },{ "ip" : "236.212.255.77", "vip": true, "name": "Carly R" },{ "ip" : "16.241.165.21", "vip": true, "name": "Naoise R" },{ "ip" : "246.106.125.113", "vip": true, "name": "Iulia F" },{ "ip" : "81.194.200.150", "vip": true, "name": "Jelena Z" },{ "ip" : "111.237.144.54", "vip": true, "name": "Matt R" }]}}}}
}我们可以再次聚合这些运行时字段:
GET /kibana_sample_data_logs/_search?filter_path=aggregations.by_name.buckets
{"size": 0,"aggs": {"by_name": {"terms": {"field": "name"}}}
}这给出了与我们之前看到的相同的结果,但当然有点慢:
{"aggregations": {"by_name": {"buckets": [{"key": "David P","doc_count": 100},{"key": "Philipp K","doc_count": 29},{"key": "Adrienne V","doc_count": 26},{"key": "Carly R","doc_count": 26},{"key": "Iulia F","doc_count": 25},{"key": "Naoise R","doc_count": 25},{"key": "Jelena Z","doc_count": 24},{"key": "Matt R","doc_count": 24}]}}
}同样,此方法不适用于大索引,因此如我们在第一部分中看到的那样重新索引数据将是首选方法。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
相关文章:
在 Elasticsearch 中丰富你的 Elasticsearch 文档
作者:David Pilato 对于 Elasticsearch,我们知道联接应该在 “索引时” 而不是查询时完成。 本博文是一系列三篇博文的开始,因为我们可以在 Elastic 生态系统中采取多种方法。 我们将介绍如何在 Elasticsearch 中做到这一点。 下一篇博文将介…...

探营云栖大会:蚂蚁集团展出数字人全栈技术,三大AI“机器人”引关注
一年一度的科技盛会云栖大会将于10月31日正式开幕。30日,记者来到云栖大会展区探营,提前打卡今年上新的“黑科技”。 记者在蚂蚁集团展馆看到,超1亿人参与的亚运“数字火炬手”全栈技术首次公开展示,还可体验基于数字人技术的“数…...
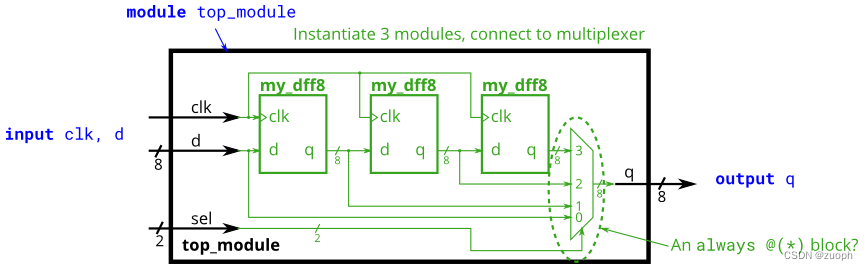
hdlbits系列verilog解答(8位宽移位寄存器)-24
文章目录 一、问题描述二、verilog源码三、仿真结果一、问题描述 这项练习是module_shift移位寄存器的延伸。模块端口不是只有单个引脚,我们现在有以向量作为端口的模块,您将在其上附加线向量而不是普通线网数据。与 Verilog 中的其他位置一样,端口的向量长度不必与连接到它…...
LeetCode 275. H 指数 II
原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题目描述 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数,citations 已经按照 升序排列 。计算并返回该研究者的 h…...
Android 优质的UI组件汇总
1、RuleView :Android自定义标尺控件(选择身高、体重等) 链接:https://github.com/cStor-cDeep/RuleView 2、DashboardView :Android自定义仪表盘View,仿新旧两版芝麻信用分、炫酷汽车速度仪表盘 链接:https://git…...
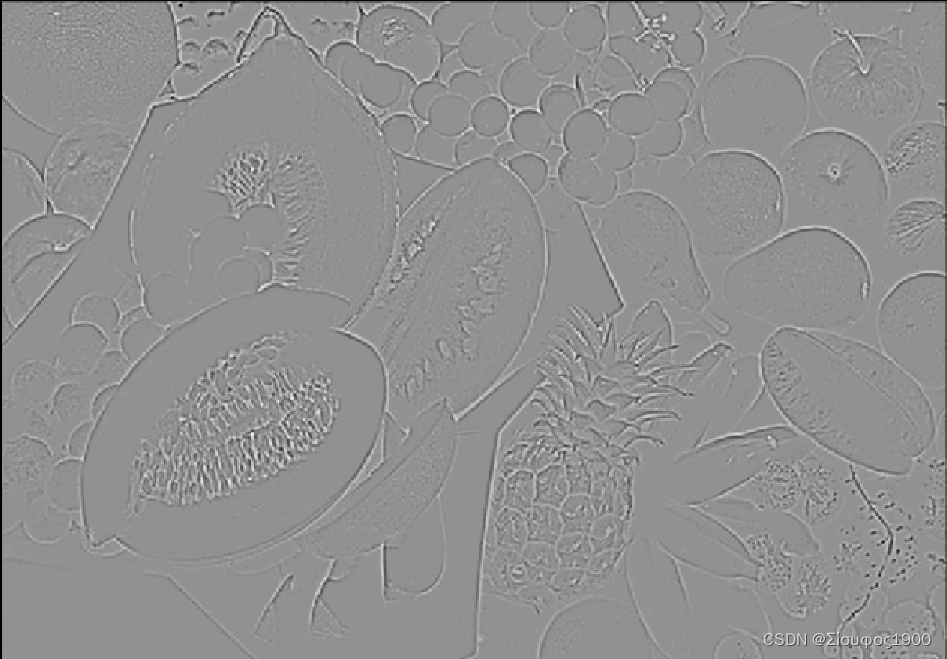
halcon roberts、 prewitt_amp、 sobel_amp、 edges_image、 laplace_of_gauss 对比
原图 灰度: roberts 算子: prewitt算子 sobel 算子 canny算子 拉普拉斯 代码: read_image (Image, C:/Users/alber/Desktop/opencv_images/canny.png) rgb1_to_gray (Image, GrayImage)* 测试 roberts 算子 roberts (GrayImage, ImageRoberts…...
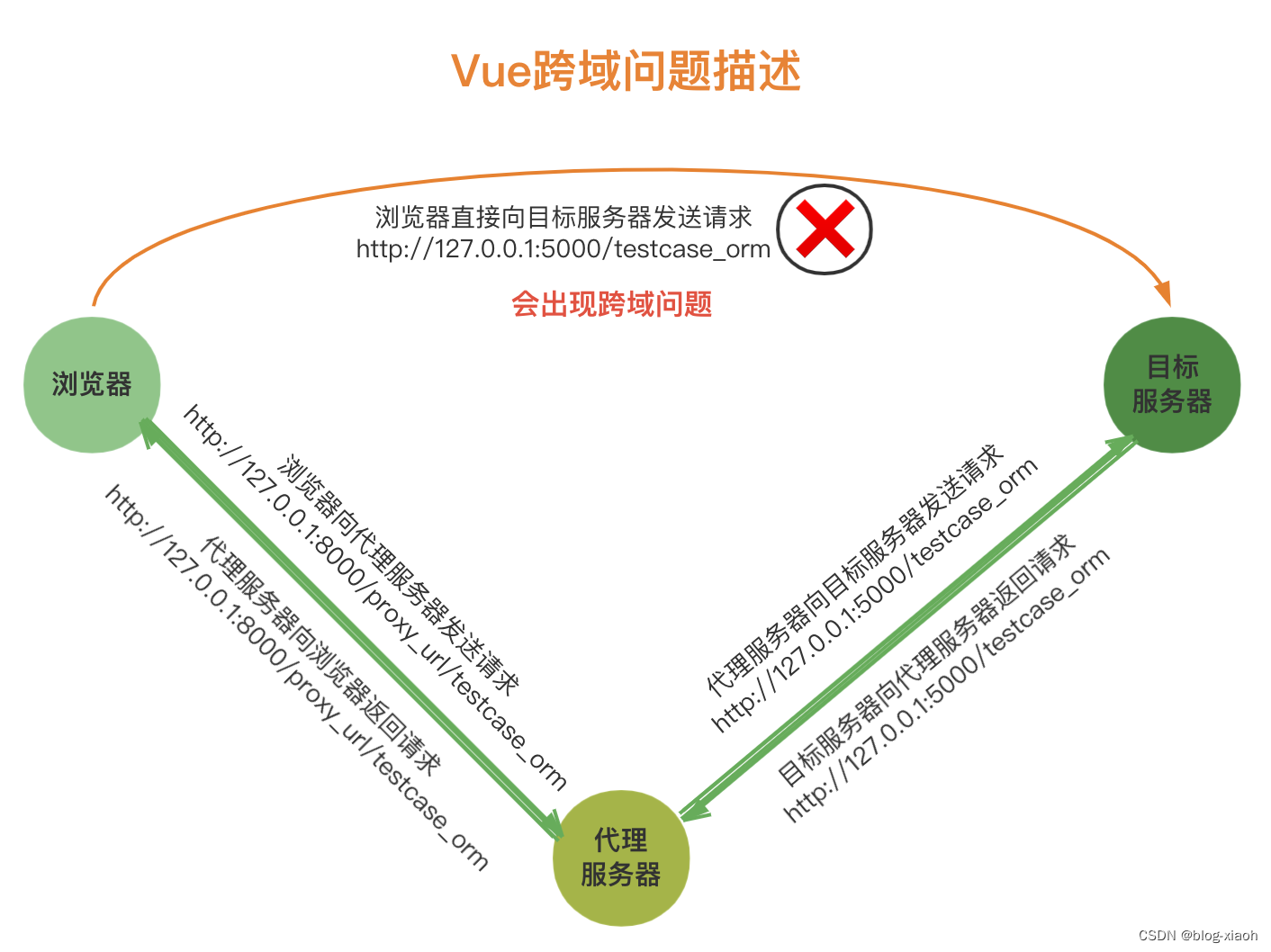
Vue2 跨域问题报错AxiosError net::ERR_FAILED、 Network Error、ERR_NETWORK
请求场景: 当前页面URL:http://127.0.0.1:8000/testcase 跳转请求页面URL:http://127.0.0.1:5000/testcase_orm 使用axios请求 时 页面提示跨域报错 跨域报错信息 > Access to XMLHttpRequest at http://127.0.0.1:5000/testcase_orm fr…...

第五章 I/O管理 四、I/O软件的层次结构
目录 一、层次图 二、用户层软件 三、设备独立性软件 主要实现的功能: 编辑四、中断处理程序 五、总结 注意: 一、层次图 二、用户层软件 三、设备独立性软件 主要实现的功能: ①向上层提供统一的调用接口(如read/write…...

云服务器安装Hbase
文章目录 1. HBase安装部署2.HBase服务的启动3.HBase部署高可用(可选)4. HBase整合Phoenix4.1 安装Phoenix4.2 **Phoenix Shell** 操作4.3 表的映射4.4 Phoenix二级索引4.4.1 全局索引(global index)4.4.2 包含索引(covered index…...
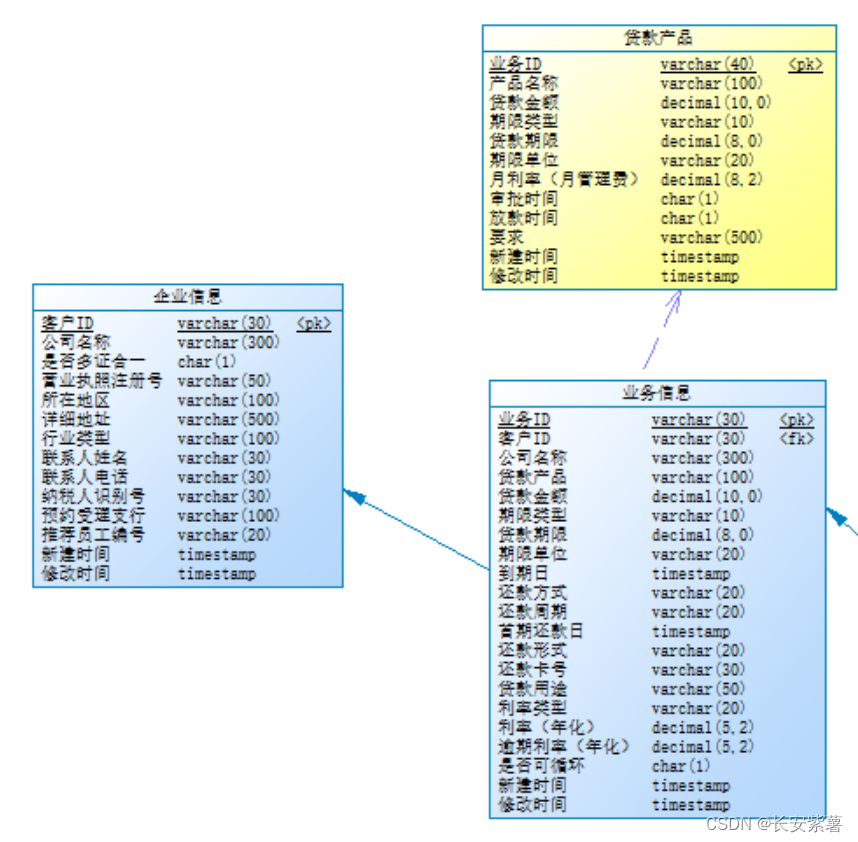
黑豹程序员-架构师学习路线图-百科:PowerDesigner数据库建模的行业标准
PowerDesigner最初由Xiao-Yun Wang(王晓昀)在SDP Technologies公司开发完成。 目前PowerDesigner是Sybase的企业建模和设计解决方案,采用模型驱动方法,将业务与IT结合起来,可帮助部署有效的企业体系架构,并…...
)
Iterator 和 ListIterator 的区别(简要说明)
Iterator 和 ListIterator 的区别 ListIterator有add()方法,可以向List中添加对象,而Iterator不能 ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法&am…...

TypeScript - 函数 - 剩余参数
什么是剩余参数 剩余参数就是 一个数组。剩余参数有什么注意事项 剩余参数必须放在所有参数的最后! 剩余参数必须放在所有参数的最后! 剩余参数必须放在所有参数的最后! 【无论是普通参数、可选参数、有默认值的参数,剩余参数都…...

Python之前端
标签的分类 1. 单标签img br hr <img /> 2. 双标签a h p div <a></a> 3. 按照标签属性分类1. 块儿标签# 自己独自占一行h1-h6 p div2. 行内(内联)标签# 自身文本有多大就占多大a span u i b s div标签和span标签 这两个标签它是没有任意意义的,主…...
iOS iGameGuardian修改器检测方案
一直以来,iOS 系统的安全性、稳定性都是其与安卓竞争的主力卖点。这要归功于 iOS 系统独特的闭源生态,应用软件上架会经过严格审核与测试。所以,iOS端的作弊手段,总是在尝试绕过 App Store 的审查。 常见的 iOS 游戏作弊…...

显示一个文件夹下所有图片的直方图之和
针对3D图像的,因为所有3D图像的2D切片都在一个文件夹里,所以要进行直方图各个像素值数量的累加。 import sys import cv2 import numpy as np import os, glob from skimage import data,io import matplotlib.pyplot as plt np.set_printoptions(thres…...
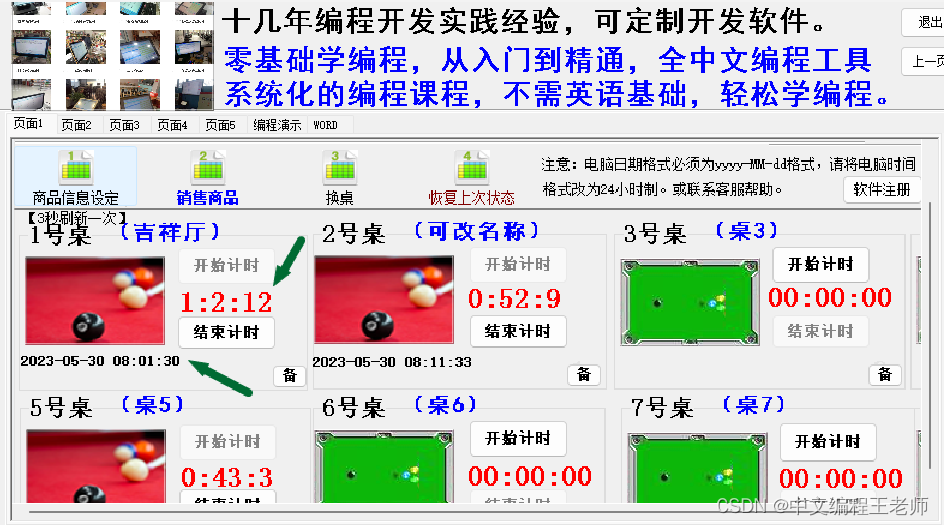
编程实例:操作简单的台球计时计费软件推荐,可以连接灯控硬件设备以及灯控器布线图编程
编程实例:操作简单的台球计时计费软件推荐,可以连接灯控硬件设备以及灯控器布线图编程 1、计时计费功能 :开台时间和所用的时长直观显示,每3秒即可刷新一次时间。 2、销售商品功能 :商品可以绑定桌子最后一起结账&…...
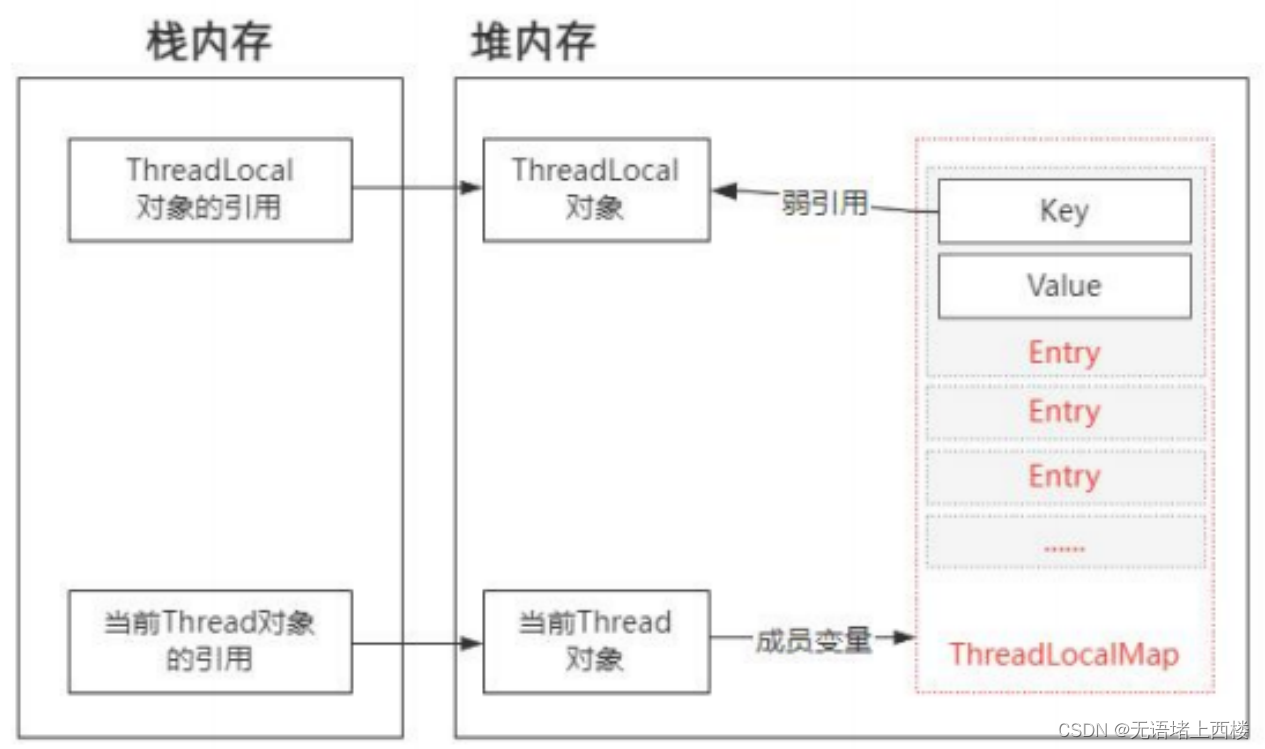
ThreadLocal 会出现内存泄漏吗?
ThreadLocal ThreadLocal 是一个用来解决线程安全性问题的工具。它相当于让每个线程都开辟一块内存空间,用来存储共享变量的副本。然后每个线程只需要访问和操作自己的共享变量副本即可,从而避免多线程竞争同一个共享资源。它的工作原理很简单࿰…...

Linux 下使用 Docker 安装 Redis
1、下载 redis docker pull redis:6.2.62、提前创建挂载目录 mkdir -p /mydata/redis/conf mkdir -p /mydata/redis/data mkdir -p /mydata/redis/log touch /mydata/redis/conf/redis.conf touch /mydata/redis/log/redis.log chmod 777 /mydata/redis/log/redis.log3、启动…...
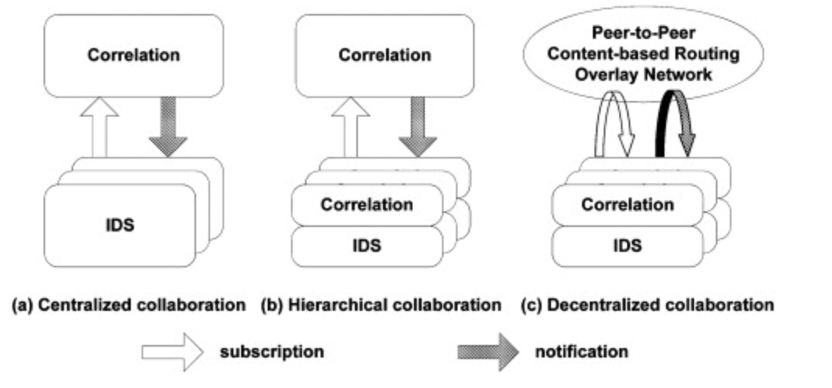
协同网络入侵检测CIDS
协同网络入侵检测CIDS 1、概念2、CIDS的分类3、解决办法4、CIDS模型5、挑战与不足 ⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计2598字,阅读大概需要3分钟 🌈更多学习内容&…...
PC端自动化测试-C#微信接收消息并自动回复)
(13)PC端自动化测试-C#微信接收消息并自动回复
本篇文章实现了微信自动接收最新的实时聊天信息,并对当前实时的聊天信息做出对应的回复。 可以自行接入人工智能或者结合自己的业务来做出自动回复。 下面视频是软件实际效果 自动接收消息并回复 实现的逻辑是实时监控微信的聊天面板中UI对象来判断是否有最新的消…...

终极英雄联盟工具集:3大核心功能让你轻松掌控游戏全局
终极英雄联盟工具集:3大核心功能让你轻松掌控游戏全局 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit…...

SpringBoot+Redis实现高并发短信登录:双拦截器设计背后的架构思考
SpringBootRedis高并发短信登录架构深度解析:双拦截器设计与性能优化实战 1. 高并发场景下的登录架构挑战 在当今互联网应用中,短信验证码登录已成为主流的身份验证方式之一。但当系统面临高并发请求时,传统的Session-based方案会暴露出诸多瓶…...

5分钟彻底告别风扇噪音!FanControl终极静音配置完全指南
5分钟彻底告别风扇噪音!FanControl终极静音配置完全指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/…...

双项目驱动:AI教育轻创合伙人对比传统教育创业的显著优势
随着人工智能技术的飞速发展,AI教育正成为教育行业的新风口。在这一背景下,轻创合伙模式应运而生,为创业者提供了低门槛、高潜力的入局机会。本文将深入分析AI教育轻创合伙人相较于传统教育创业的核心优势,探讨其规模化路径的实现…...

Qt网络编程实战:基于QTcpSocket构建带进度反馈的可靠文件传输系统
1. 为什么需要带进度反馈的文件传输系统 在开发桌面应用时,文件传输是个绕不开的刚需功能。特别是传输大文件时,用户最怕的就是看着界面发呆——不知道传输进行到哪一步了,也不知道还要等多久。我做过一个医疗影像传输系统,医生们…...

5分钟快速上手LosslessCut:零编码视频剪辑的终极指南
5分钟快速上手LosslessCut:零编码视频剪辑的终极指南 【免费下载链接】lossless-cut The swiss army knife of lossless video/audio editing 项目地址: https://gitcode.com/gh_mirrors/lo/lossless-cut 你是否曾因视频剪辑导致画质下降而烦恼?是…...

AI赋能.NET开发:让快马平台智能生成Redis缓存与消息队列集成代码
最近在做一个电商系统的订单模块,发现缓存和消息队列这两个组件几乎是标配。但每次从零开始集成Redis和RabbitMQ都要查半天文档,配置各种连接字符串,写一堆样板代码。直到尝试用InsCode(快马)平台的AI辅助功能,才发现原来这些重复…...

视频防抖新范式:从陀螺仪数据到稳定画面的技术革命——影像创作者的开源解决方案
视频防抖新范式:从陀螺仪数据到稳定画面的技术革命——影像创作者的开源解决方案 【免费下载链接】gyroflow Video stabilization using gyroscope data 项目地址: https://gitcode.com/GitHub_Trending/gy/gyroflow 一、技术原理解析:GyroFlow如…...

3个技巧让Blender对齐效率提升10倍:QuickSnap插件全攻略
3个技巧让Blender对齐效率提升10倍:QuickSnap插件全攻略 【免费下载链接】quicksnap Blender addon to quickly snap objects/vertices/points to object origins/vertices/points 项目地址: https://gitcode.com/gh_mirrors/qu/quicksnap 在三维建模的日常工…...

告别复杂安装:用快马AI一键生成opencode可运行原型
最近在折腾一个开源项目时,被各种依赖安装和环境配置搞得头大。作为一个经常需要快速验证想法的开发者,我一直在寻找能跳过这些繁琐步骤的工具。直到发现了InsCode(快马)平台,它彻底改变了我的开发流程。 传统安装的痛点 以前要运行一个openc…...