Kafka - 3.x Kafka消费者不完全指北
文章目录
- Kafka消费模式
- Kakfa消费者工作流程
- 消费者总体工作流程
- 消费者组原理
- 消费者组初始化流程
- 消费者组详细消费流程
- 独立消费者案例(订阅主题)
- 消费者重要参数

Kafka消费模式
Kafka的consumer采用pull(拉)模式从broker中读取数据。
| 模式 | 优点 | 缺点 |
|---|---|---|
| Push(推)模式 | - 快速传递消息 - 消息发送速率由broker决定 | - 难以适应不同消费者的消费速率 - 可能导致拒绝服务和网络拥塞 |
| Pull(拉)模式 | - 可以根据消费者的消费能力以适当速率消费消息 | - 潜在的循环问题,如果Kafka没有数据,消费者可能会一直返回空数据 - 需要设置轮询的timeout以避免无限等待时长过长 |
Kakfa消费者工作流程
消费者总体工作流程
Kafka消费者的总体工作流程包括以下步骤:
-
配置消费者属性:首先,你需要配置消费者的属性,包括Kafka集群的地址、消费者组、主题名称、序列化/反序列化器、自动偏移提交等。
-
创建消费者实例:使用配置创建Kafka消费者实例。
-
订阅主题:使用消费者实例订阅一个或多个Kafka主题。这告诉Kafka消费者你想要从哪些主题中接收消息。
-
轮询数据:消费者使用
poll()方法从Kafka broker中拉取消息。它会定期轮询(拉)Kafka集群以获取新消息。 -
处理消息:一旦从Kafka broker获取到消息,消费者会对消息进行处理,执行你的业务逻辑。这可能包括数据处理、计算、存储或其他操作。
-
提交偏移量:消费者可以选择手动或自动提交偏移量,以记录已处理消息的位置。这有助于防止消息重复处理。
-
处理异常:处理消息期间可能会出现异常,你需要处理这些异常,例如重试或记录错误日志。
-
关闭消费者:在不再需要消费者实例时,确保关闭它以释放资源。
这个工作流程涵盖了Kafka消费者从配置到数据处理再到资源管理的主要步骤。消费者通常是多线程或多进程的,以处理大量的消息,并能够根据需要调整消费速率。此外,Kafka的消费者库提供了很多功能,如自动负载均衡、自动偏移管理等,以简化消费者的开发和维护。
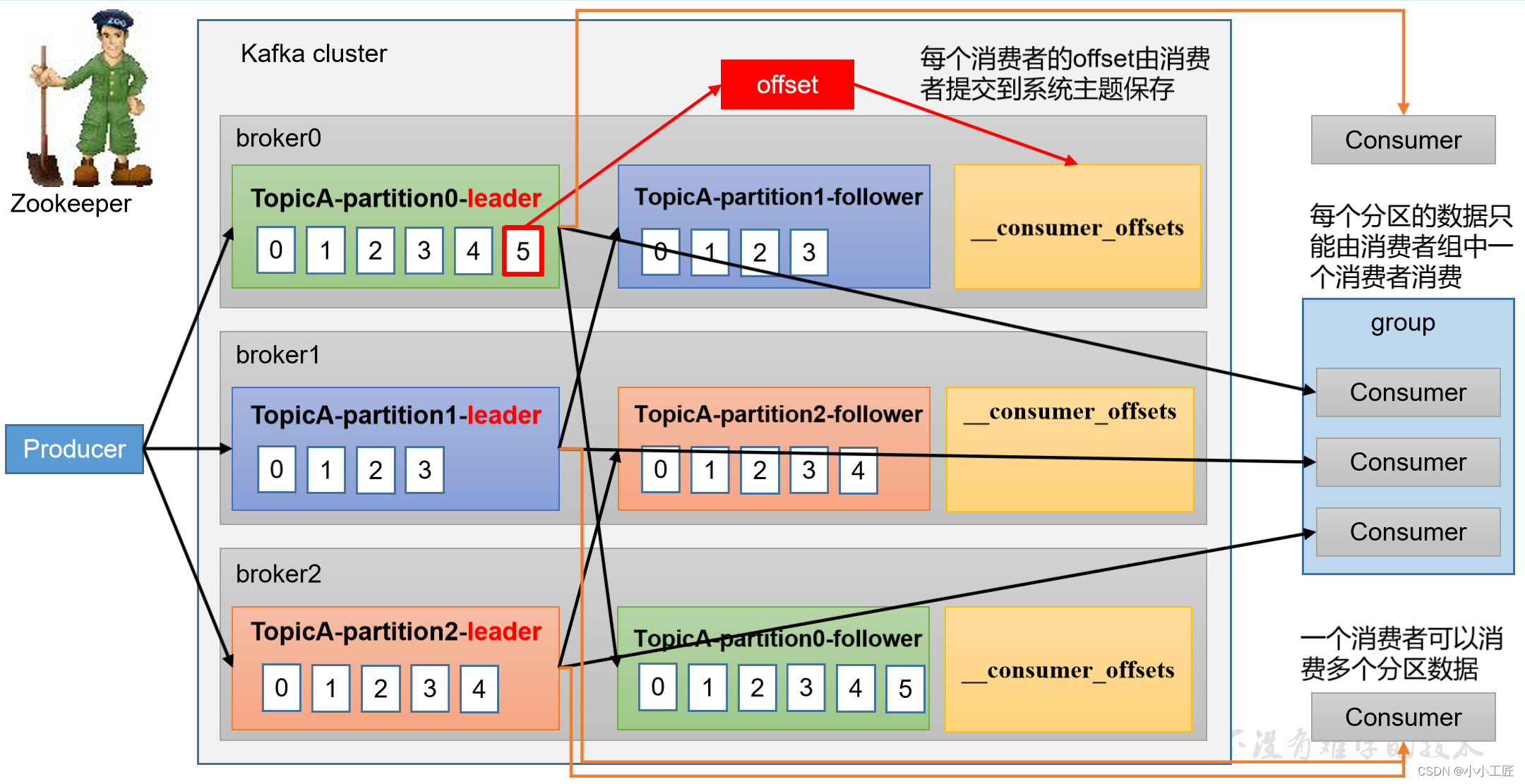
消费者组原理
Kafka消费者组(Consumer Group)是一种机制,用于协调和管理多个消费者并共同消费一个或多个Kafka主题的消息。消费者组的工作原理如下:
-
多个消费者:一个消费者组可以包含多个消费者实例,这些消费者实例协同工作以共同消费一个或多个主题的消息。
-
订阅主题:所有消费者实例都订阅相同的Kafka主题。这意味着每个消息都会被消费者组中的一个实例处理,从而实现消息的负载均衡。
-
消息分区:每个Kafka主题通常被分为多个分区,每个分区包含消息的一个子集。每个消费者实例负责消费一个或多个分区的消息。
-
协调者:消费者组中的消费者实例会选择一个协调者(Coordinator)来管理组内的消费者。协调者通常是ZooKeeper或Kafka自身的一个特殊主题。
-
偏移管理:协调者负责管理消费者组的偏移量(offset),这是消费者在主题分区中的当前位置。它会跟踪每个分区的消费进度,确保不会重复消费消息。
-
分配分区:协调者会定期重新分配分区给消费者实例,以确保负载均衡和故障恢复。如果有新消费者加入组或有消费者离开组,协调者会重新分配分区。
-
消费消息:每个消费者实例负责处理分配给它的分区中的消息。它会拉取消息,进行处理,并将偏移量提交给协调者。
-
自动重平衡:如果消费者实例加入或退出消费者组,或者分区的分配发生变化,消费者组会自动进行重新平衡,以确保消息均匀分配。
-
提交偏移量:消费者实例可以定期或根据需要提交已处理消息的偏移量,以便在故障时恢复消费进度。
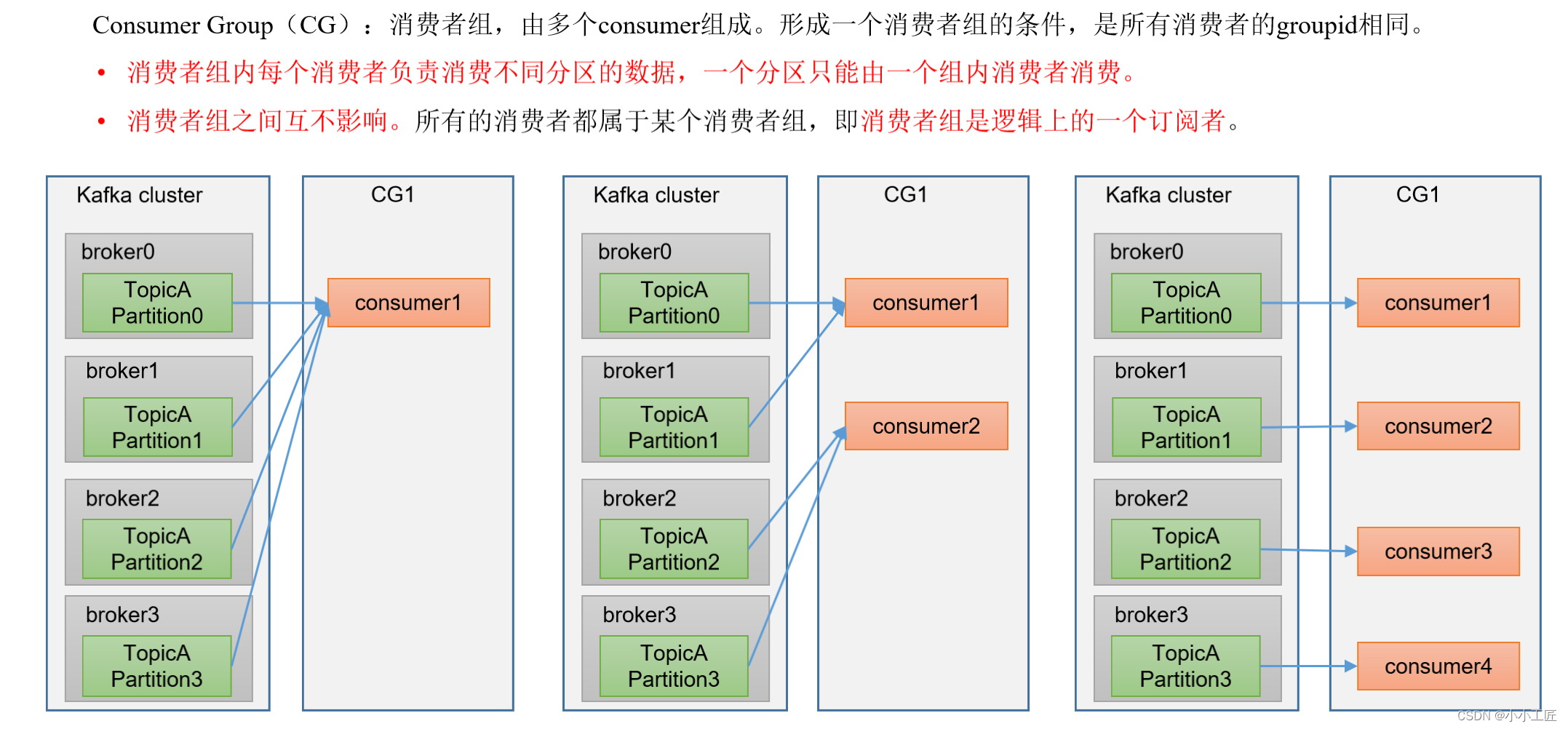
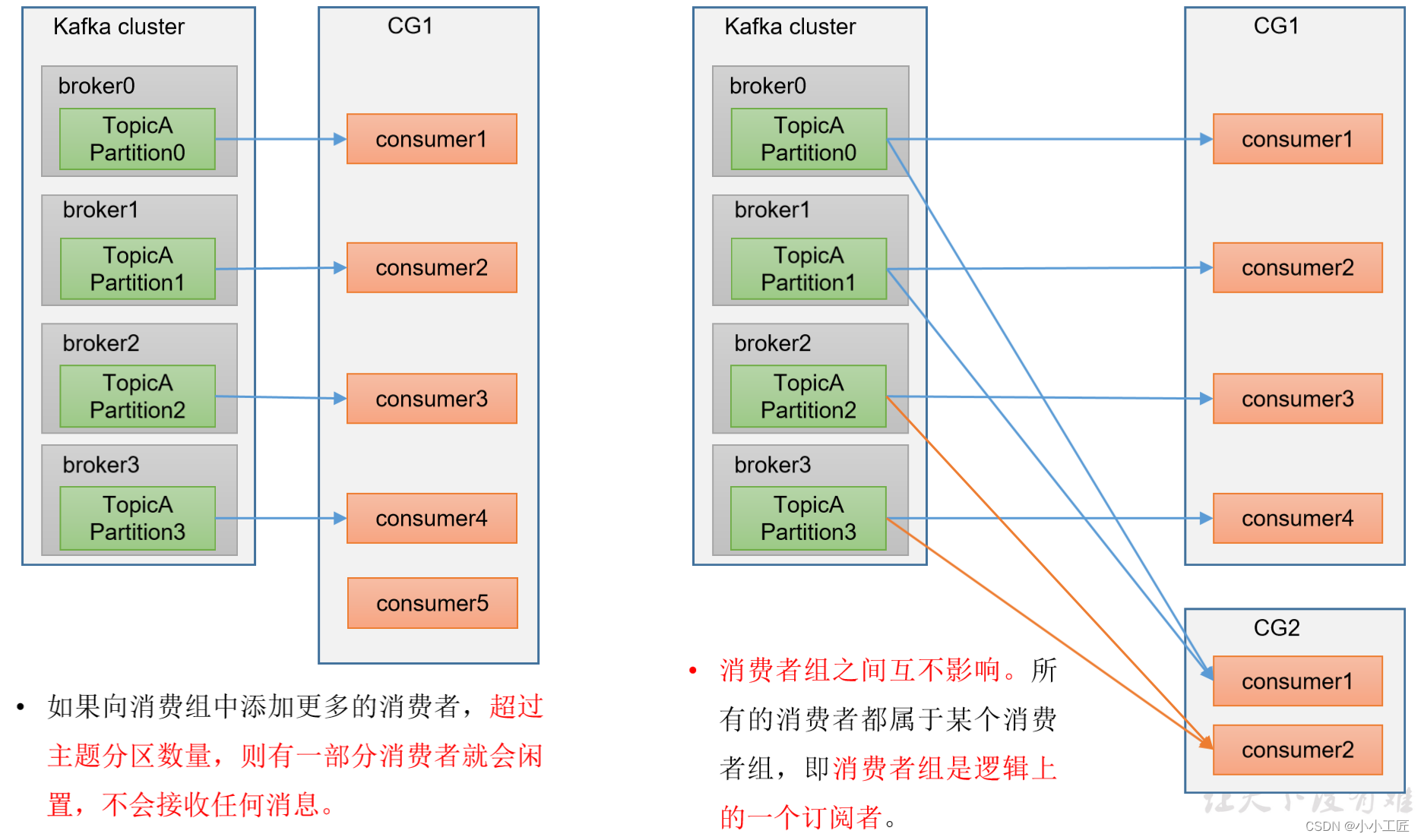
通过这种方式,Kafka消费者组能够实现高可用性、负载均衡和容错,允许多个消费者并行处理消息,并根据需求动态调整分区分配。这使得消费者组成为了处理大规模流式数据的理想工具。
消费者组初始化流程
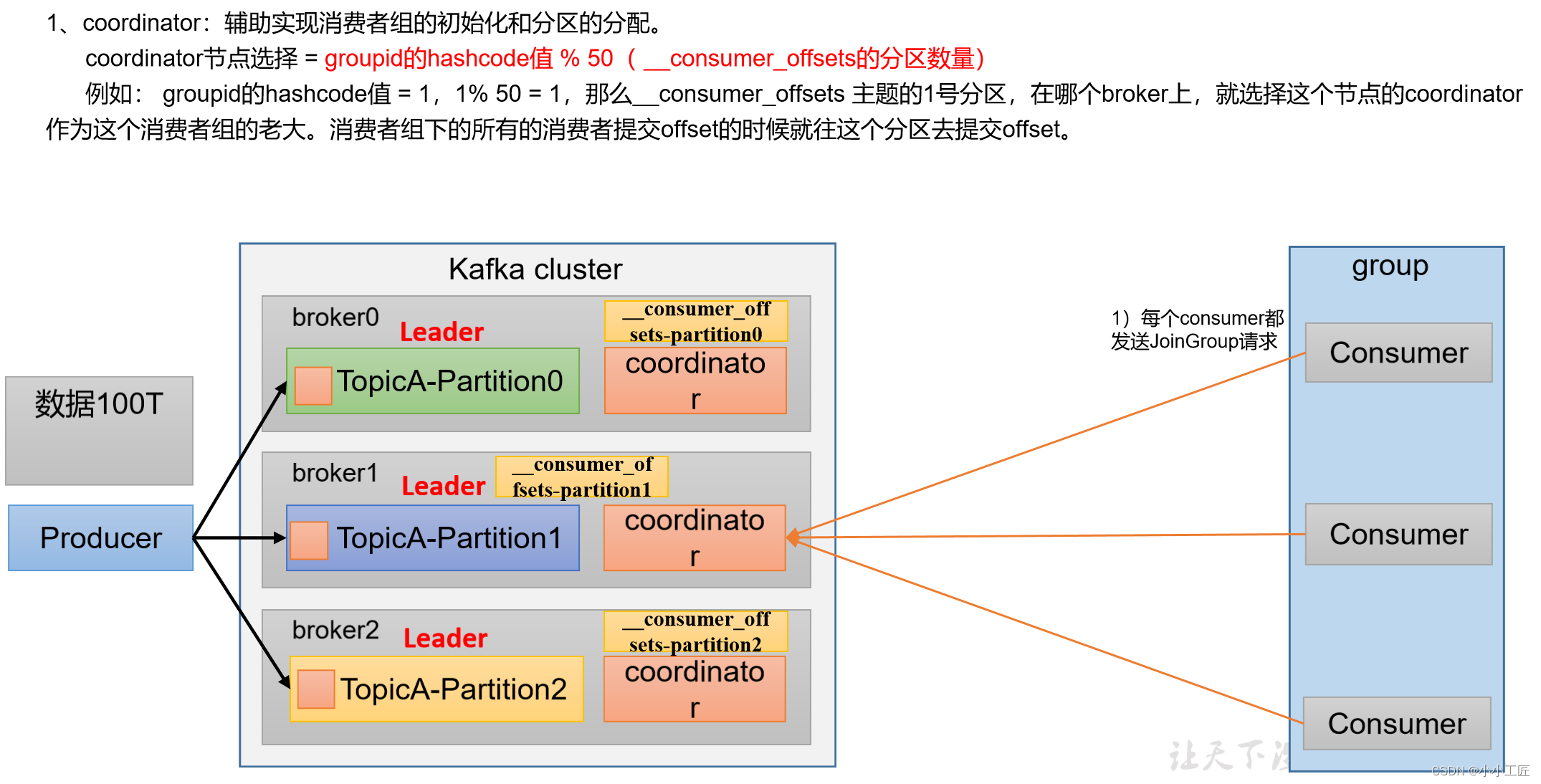
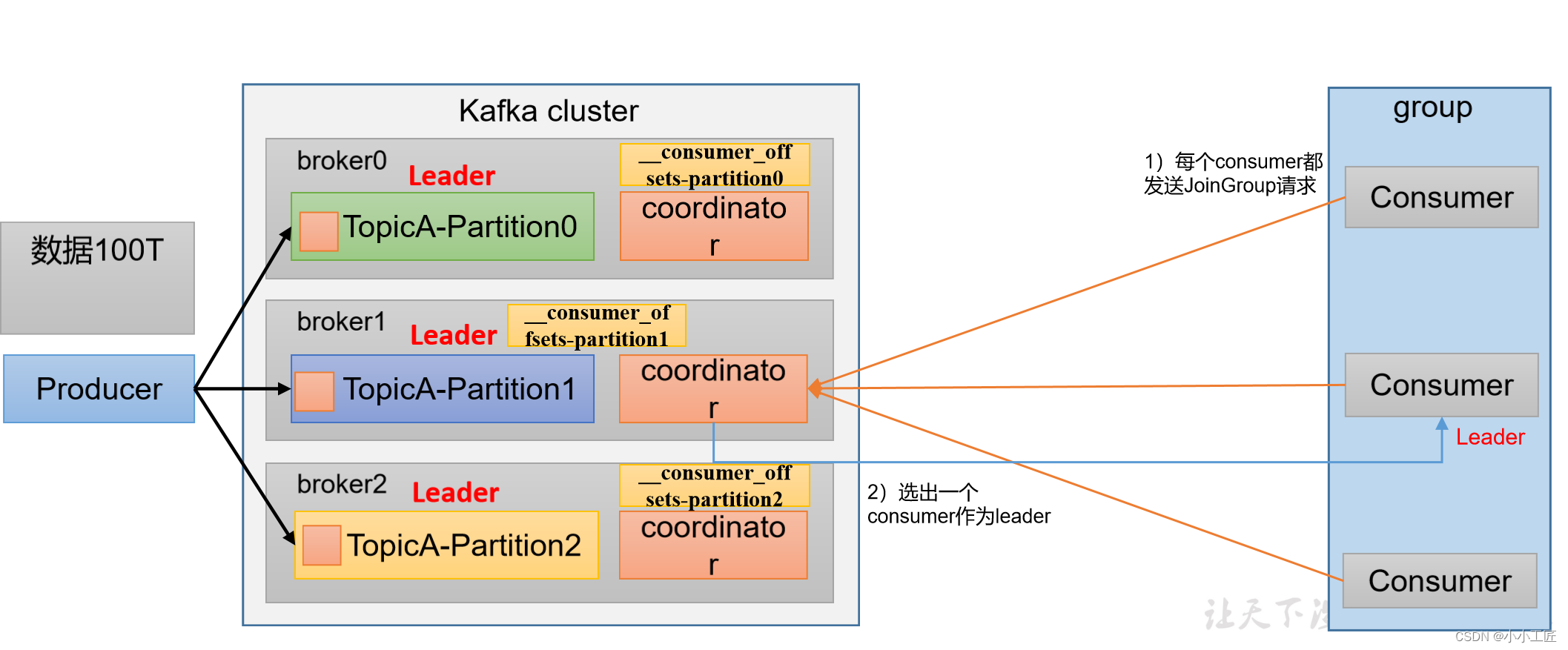
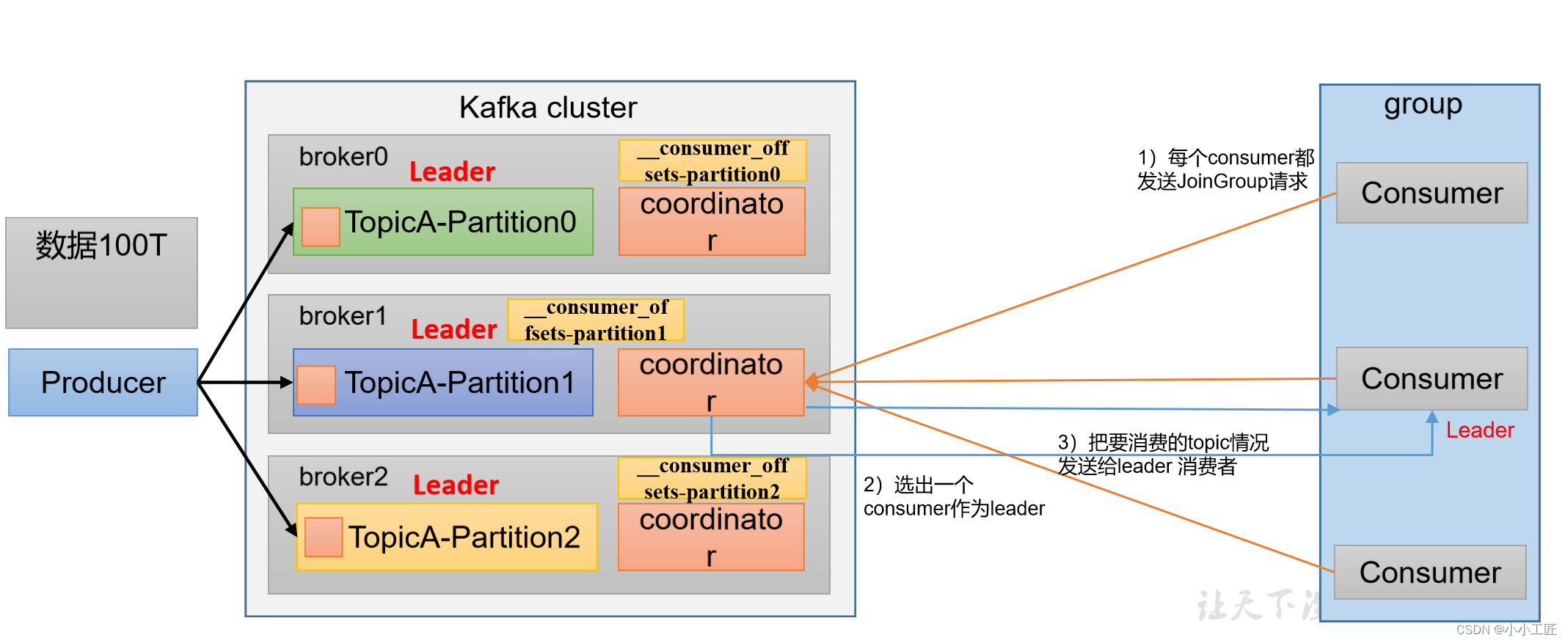
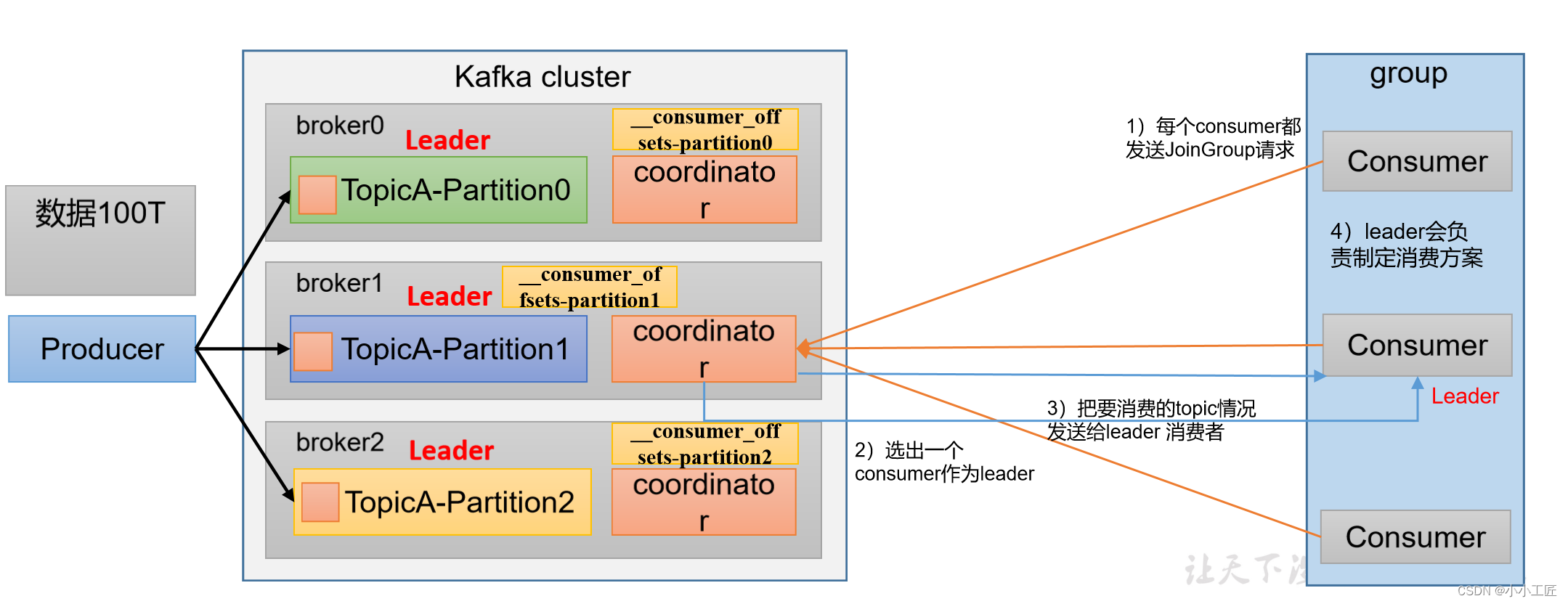
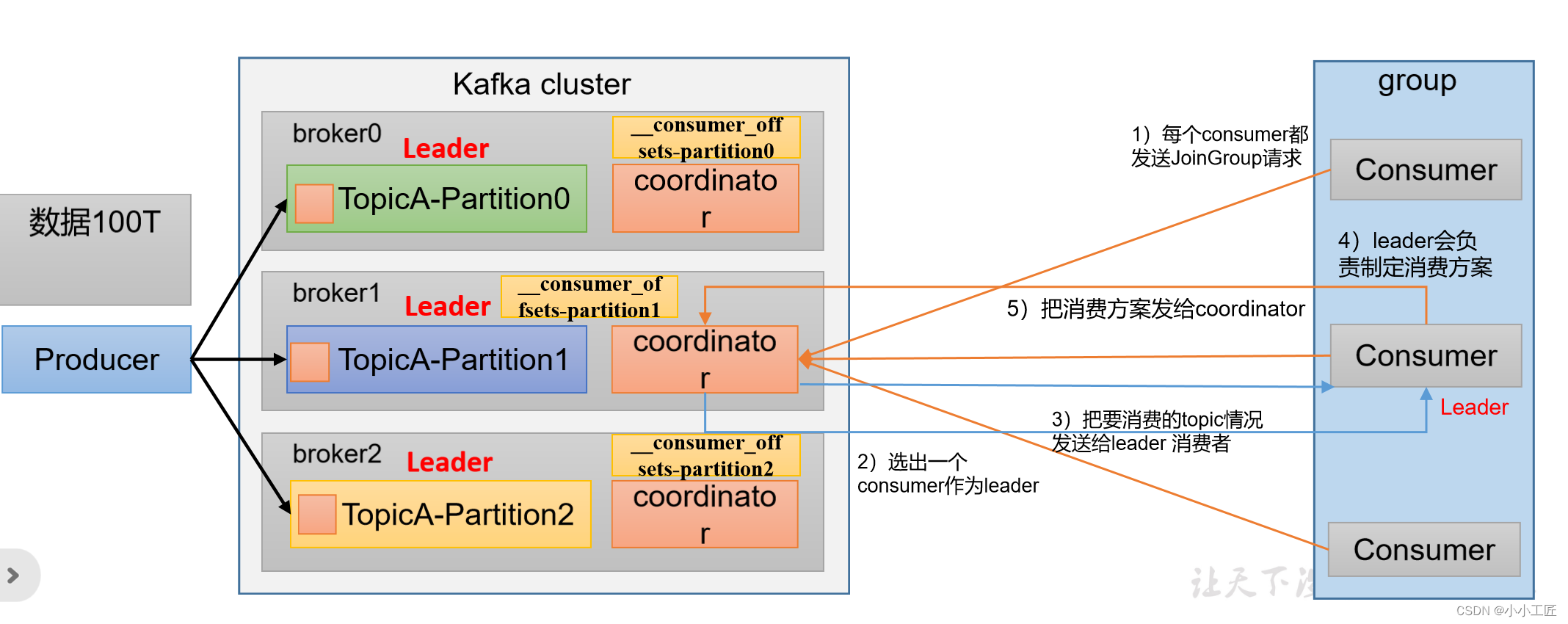
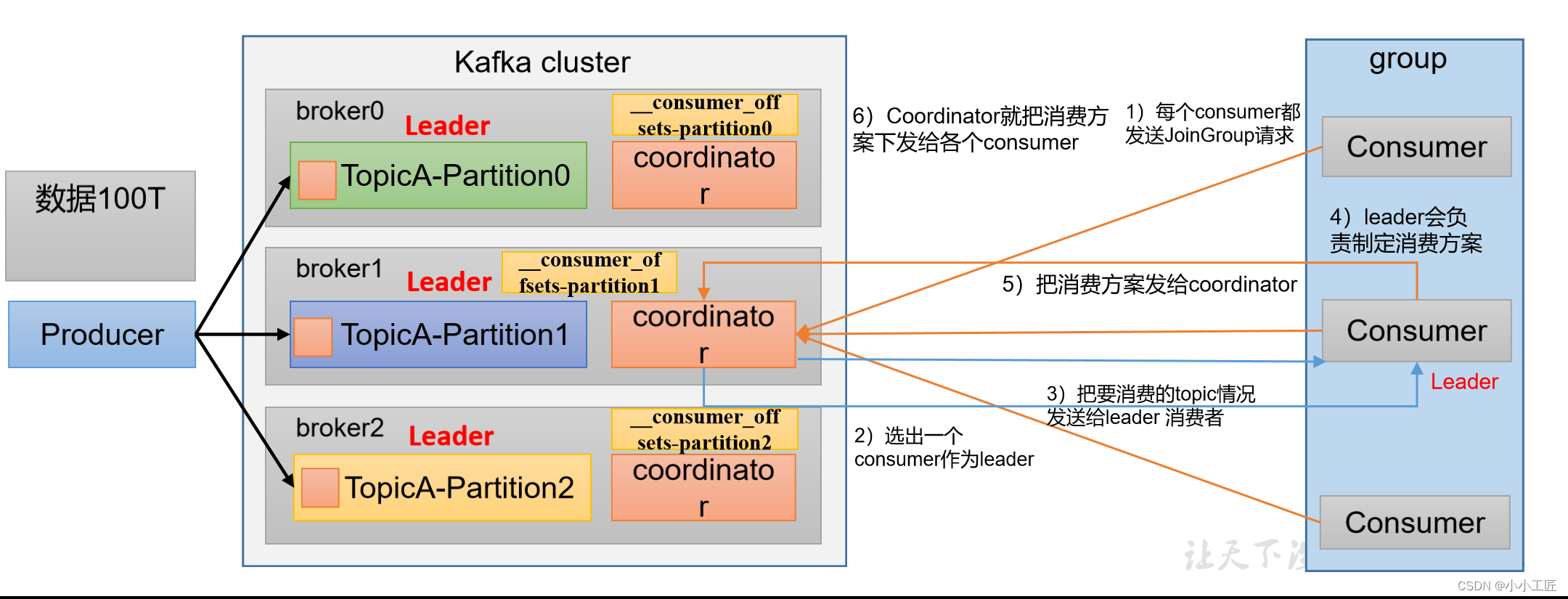
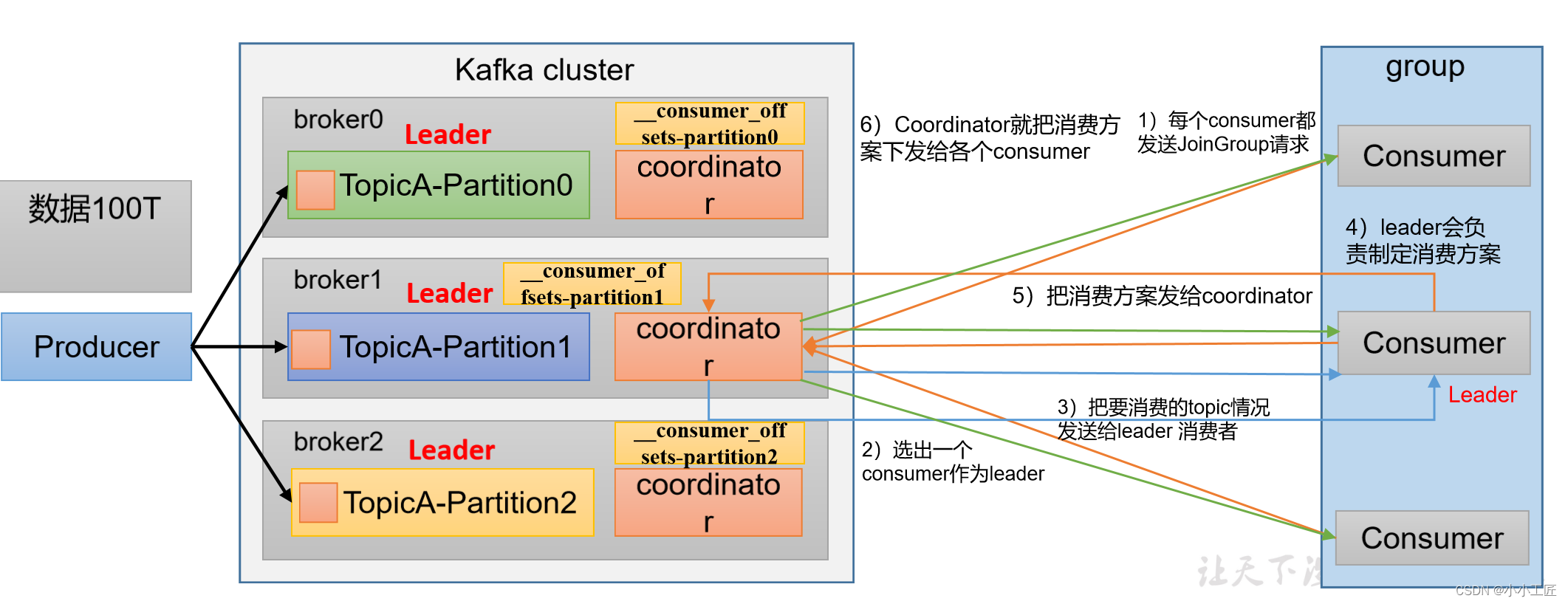
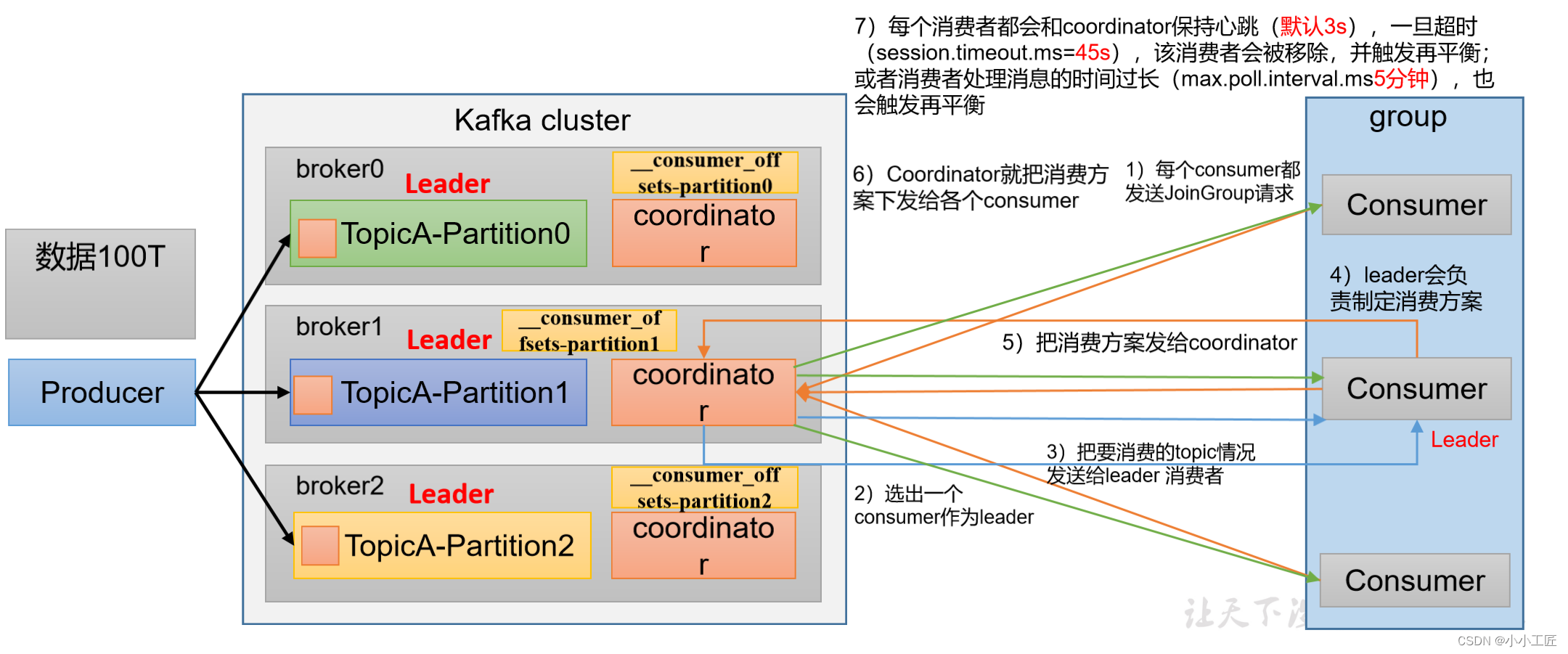
消费者组详细消费流程
Kafka消费者组的初始化流程包括一系列步骤,用于创建和配置消费者组的成员。以下是Kafka消费者组的初始化流程:
-
引入Kafka客户端库:首先,确保你的应用程序中引入了Kafka客户端库,以便能够使用Kafka相关的类和功能。
-
创建消费者配置:初始化消费者组前,需要创建一个消费者配置对象,其中包括了一些重要的属性,例如Kafka集群的地址、消费者组的ID、自动提交偏移量等。
-
创建消费者实例:使用消费者配置,创建一个或多个消费者实例。每个实例代表一个消费者组中的一个成员。实例会自动注册到Kafka broker,并与协调者建立连接。
-
订阅主题:通过消费者实例,使用
subscribe()方法订阅一个或多个Kafka主题。这告诉Kafka你希望从哪些主题中接收消息。 -
启动消费者:调用
poll()方法开始轮询消息。这将启动消费者实例并开始拉取消息。消费者组中的每个成员都会独立执行这个步骤。 -
消费消息:一旦消息被拉取,消费者实例会处理这些消息,执行你的业务逻辑。每个成员在自己的线程中处理消息。
-
提交偏移量:消费者实例可以选择手动或自动提交已处理消息的偏移量。这有助于记录每个分区中消息的处理进度。
-
处理异常:处理消息期间可能会出现异常,你需要适当地处理这些异常,例如重试消息或记录错误日志。
-
关闭消费者:当不再需要消费者实例时,确保关闭它以释放资源。
-
自动重平衡:如果有消费者实例加入或离开消费者组,或者分区的分配发生变化,Kafka会自动进行重新平衡,以确保消息均匀分配。
这个初始化流程涵盖了Kafka消费者组的基本步骤,从配置消费者组成员到消息的处理和消费。请注意,Kafka消费者组的初始化需要注意各个配置选项以及消费者组的协调过程,以确保正常运行和负载均衡。
独立消费者案例(订阅主题)
需求:创建一个独立消费者,消费artisan主题中的数据
注意:在消费者API代码中必须配置消费者组id。
package com.artisan.pc;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;/*** @author 小工匠* @version 1.0* @mark: show me the code , change the world*/
public class CustomConsumer {public static void main(String[] args) {// 1.创建消费者的配置对象Properties properties = new Properties();// 2.给消费者配置对象添加参数properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.126.171:9092");// 配置序列化 必须properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组 必须properties.put(ConsumerConfig.GROUP_ID_CONFIG, "artisan-group");// 3. 创建消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);// 4. 订阅主题ArrayList<String> topics = new ArrayList<>();topics.add("artisan");consumer.subscribe(topics);// 5. 拉取数据打印while (true) {ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 6. 遍历并输出消费到的数据for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}
}① 在IDEA中执行消费者程序
② 服务器上中创建kafka生产者,并输入数据

③ 在IDEA中观察接收到的数据
ConsumerRecord(topic = artisan, partition = 2, leaderEpoch = 0, offset = 34, CreateTime = 1698630425187, serialized key size = -1, serialized value size = 13, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = first message)
ConsumerRecord(topic = artisan, partition = 2, leaderEpoch = 0, offset = 35, CreateTime = 1698630429909, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = seconde message)消费者重要参数
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 向Kafka集群建立初始连接用到的host/port列表。 |
| key.deserializer | 指定接收消息的key的反序列化类型。需要写全类名。 |
| value.deserializer | 指定接收消息的value的反序列化类型。需要写全类名。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 默认值为true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 若enable.auto.commit=true,表示消费者提交偏移量的频率,默认为5秒。 |
| auto.offset.reset | 当Kafka中没有初始偏移量或当前偏移量在服务器中不存在时的处理方式。可选值包括"earliest"、“latest”、“none”、 |
| offsets.topic.num.partitions | __consumer_offsets的分区数,默认是50个分区。 |
| heartbeat.interval.ms | Kafka消费者和coordinator之间的心跳时间,默认为3秒。必须小于session.timeout.ms,也不应该高于session.timeout.ms的1/3。 |
| session.timeout.ms | Kafka消费者和coordinator之间连接超时时间,默认为45秒。超过该值,消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认为5分钟。超过该值,消费者被移除,消费者组执行再平衡。 |
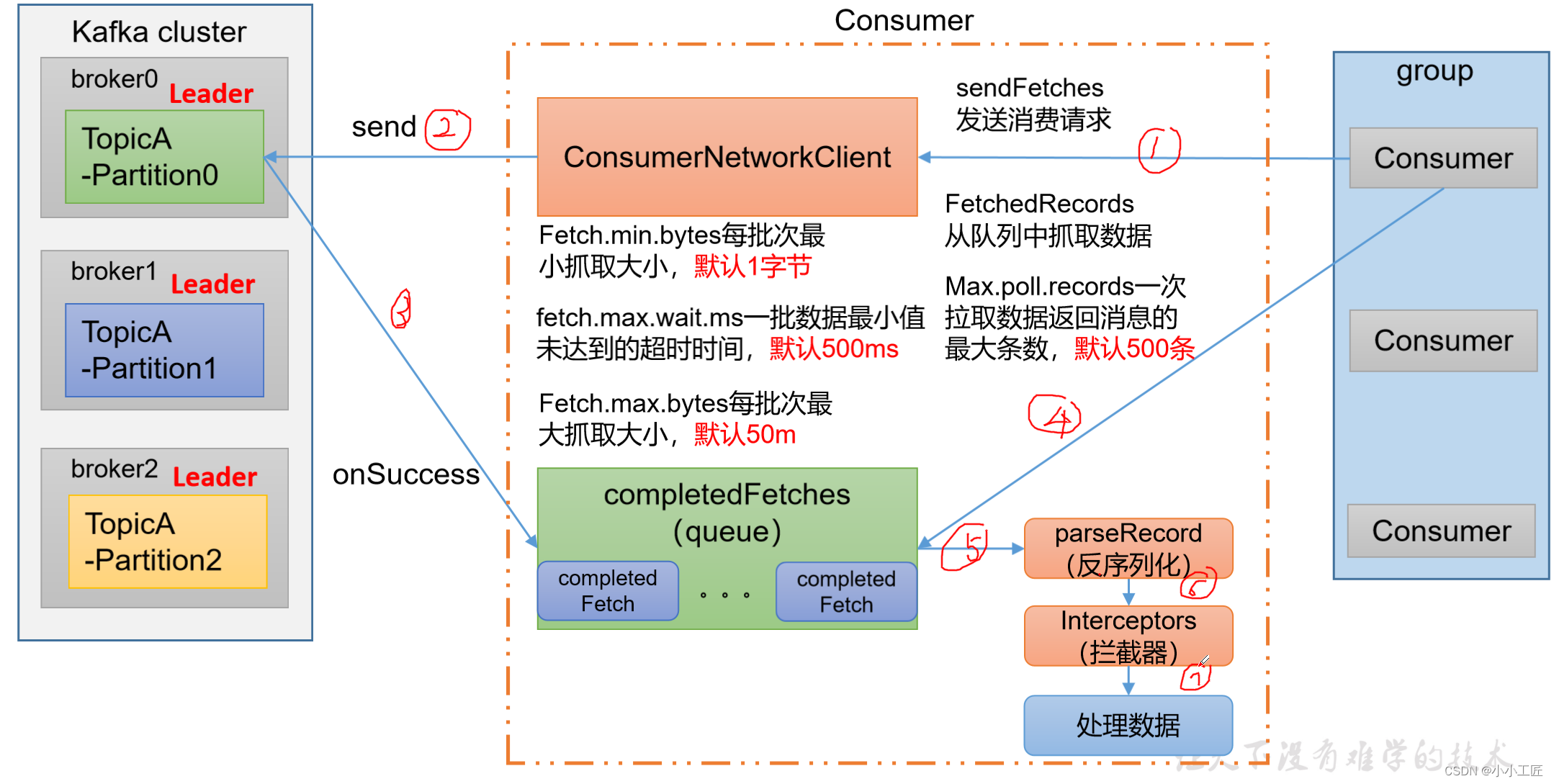
| fetch.min.bytes | 消费者获取服务器端一批消息最小的字节数,默认为1个字节。 |
| fetch.max.wait.ms | 默认为500毫秒。如果没有从服务器端获取到一批数据的最小字节数,等待时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认为52428800(50兆字节)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值,仍然可以拉取回这批数据,这不是一个绝对最大值,一批次的大小受message.max.bytes(broker配置)或max.message.bytes(topic配置)影响。 |
| max.poll.records | 一次poll拉取数据返回消息的最大条数,默认为500条。 |

相关文章:
Kafka - 3.x Kafka消费者不完全指北
文章目录 Kafka消费模式Kakfa消费者工作流程消费者总体工作流程消费者组原理消费者组初始化流程消费者组详细消费流程 独立消费者案例(订阅主题)消费者重要参数 Kafka消费模式 Kafka的consumer采用pull(拉)模式从broker中读取数据…...

Gerrit | 重磅! 2.x 版本升级到 3.x 版本----转
Gerrit | 重磅! 2.x 版本升级到 3.x 版本 为什么要做版本升级? 2.x known bugs 重大问题不一一列举,这里仅仅是举几个例子: 安全或权限问题:普通用户能看到敏感数据,例如看到其他用户的 hashed api 密码,…...

使用c++编程语言,用递归的方法求第n个斐波那契数,代码如下
#include<iostream> using namespace std;int fib_1(int n) {if (n < 1){return n;}return fib_1(n - 1) fib_1(n - 2); }int main() {cout << fib_1(6);return 0; }...

git config pull.rebase false
git pull 默认使用merge 可以使用 git pull --rebase 命令使用rebase 或者配置 git config pull.rebase true 使 git pull命令执行 git pull --rebase git config pull.rebase false 的作用是设置 Git 在执行 git pull 命令时默认使用 merge 而不是 rebase。 git pull 命…...

Spring面试题:(一)IoC,DI,AOP和BeanFactory,ApplicationContext
IoC,DI,AOP思想 IOC就是控制反转,是指创建对象的控制权的转移。以前创建对象的主动权和时机是由自己把控的,而现在这种权力转移到Spring容器中,并由容器根据配置文件去创建实例和管理各个实例之间的依赖关系。对象与对…...

RabbitMQ如何保证消息不丢失呢?
RabbitMQ 是一个流行的消息队列系统,用于在分布式应用程序之间传递消息。要确保消息不会丢失,可以采取以下一些措施: 持久化消息: RabbitMQ 允许你将消息标记为持久化的。这意味着消息将被写入磁盘,即使 RabbitMQ 服务…...

VR步进式漫游,轻松构建三维模型,带来展示新形式!
引言: 虚拟现实(Virtual Reality,简称VR)已经成为当今科技领域的一项创新力量,它正在逐渐渗透到不同的领域,其中步进式漫游是VR技术的一项重要应用,它能在各个行业的宣传中发挥重要作用。 一&a…...

英语——分享篇——常用人物身份
常用人物身份 家庭成员类 father 父亲 mother 母亲 grandmother(外)祖母 grandfather(外)祖父 son 儿子 daughter 女儿 uncle 叔叔,舅舅 aunt 婶母,舅母 brother 兄弟 sister 姐妹 nephew 侄子 niece…...

202310-宏基组学物种分析工具-MetaPhlAn4安装和使用方法-Anaconda3- centos9 stream
MetaPhlAn 4是一种基于DNA序列的微生物组分析工具,它能够从宏基因组测序数据中识别和分离微生物的组成。以下是安装和使用MetaPhlAn 4的步骤: 安装MetaPhlAn 4: 裸机环境,手动安装 1. 安装依赖项: MetaPhlAn 4需要…...
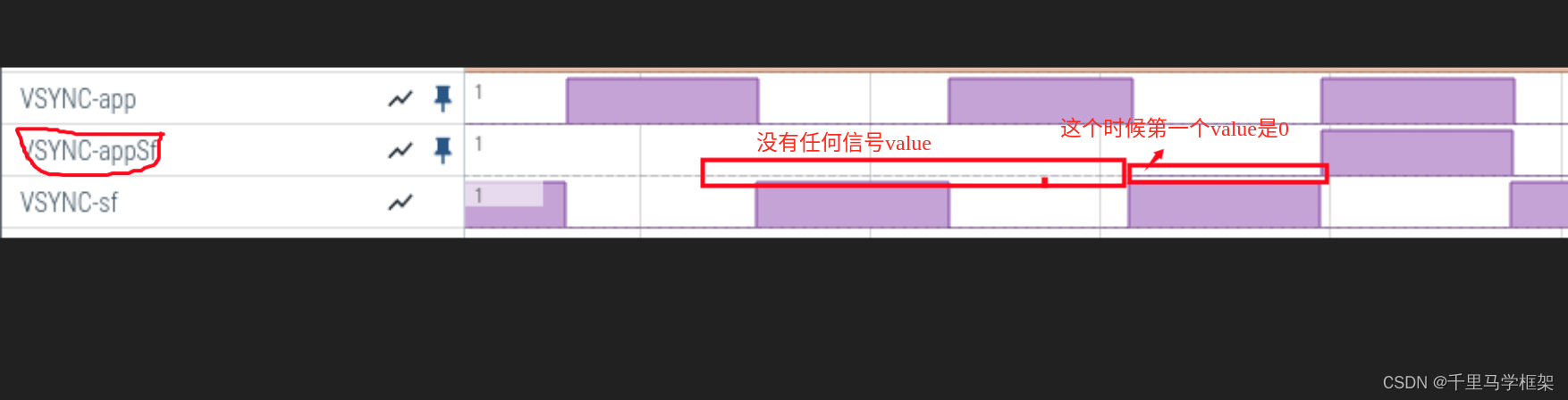
systrace/perfetto如何看surfaceflinger的vsync信号方法-android framework实战车载手机系统开发
背景: hi,粉丝朋友们: 大家好!近期分享了surfaceflinger相关的一些blog,有同学就对相关的一些内容产生了一些疑问。 比如:vsync查看问题,即怎么才可以说是vsync到来了。 比如perfetto中surfac…...
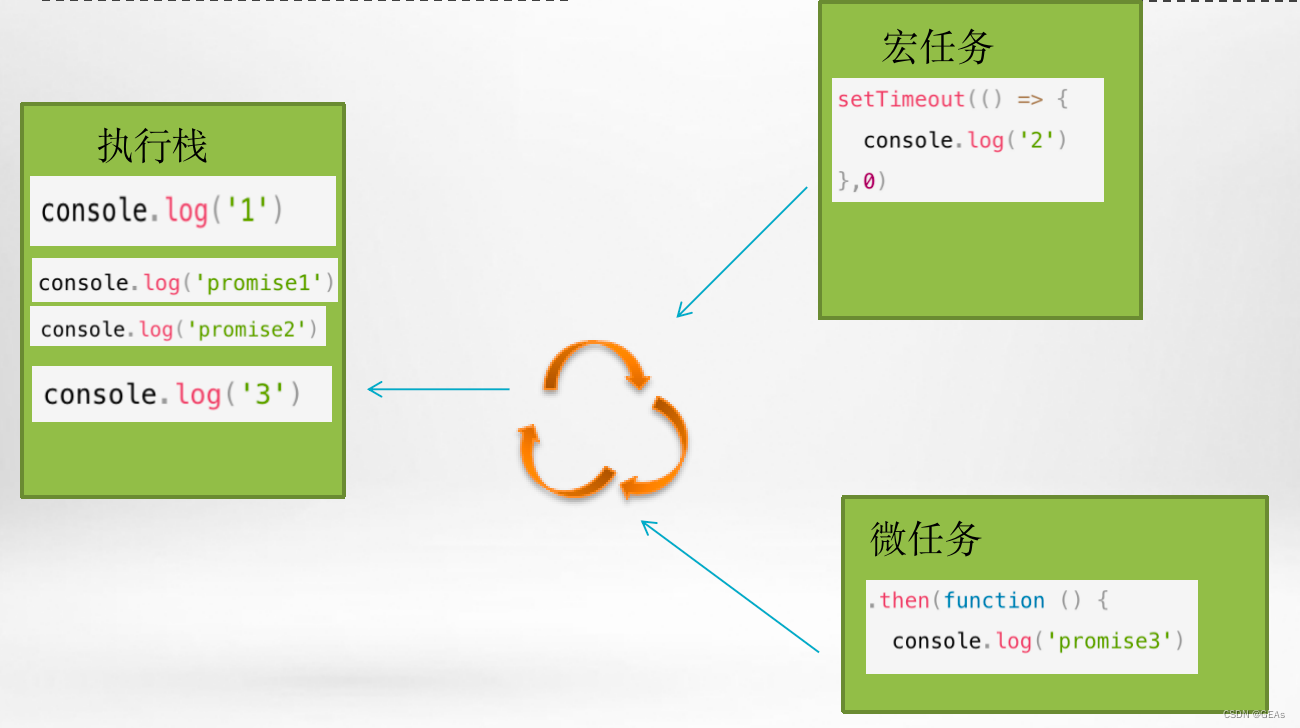
一文带你彻底弄懂js事件循环(Event Loop)
JavaScript事件循环是JavaScript运行时环境中处理异步操作的机制。它允许JavaScript在执行同步代码的同时处理异步任务,以避免阻塞线程并提供更好的用户体验。 本文将在浏览器异步执行原理基础上带你彻底弄懂js的事件循环机制。 浏览器JS异步执行原理 js是单线程…...
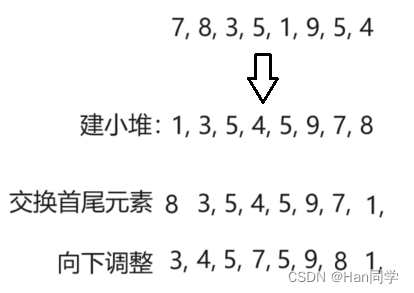
数据结构与算法:二叉树之“堆排序”
目录 一、树概念及结构 二、二叉树树概念及结构 特殊的二叉树 三、堆的概念及结构 四、堆的创建 1、声明结构体 2、初始化 3、销毁 4、添加新元素 5、交换元素 6、向上调整 7、判断堆是否为空 8、移除堆顶元素 9、向下调整 10、获取堆元素个数 五、使用堆排序…...
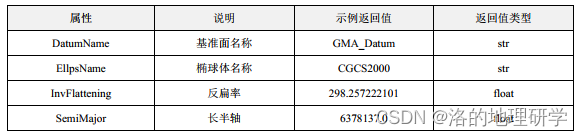
gma 2 教程(三)坐标参考系统:2.基准面/椭球体
安装 gma:pip install gma 地球是一个近似于椭球体的三维物体,而地球上的各种测量和计算都需要一个基准面来进行。基准面是一个虚拟的平面,用于测量和计算地球上的各种物理量。在地球科学中,基准面通常是一个参考椭球体࿰…...

【1day】复现广联达-Linkworks 协同办公管理平台信息泄露漏洞
注:该文章来自作者日常学习笔记,请勿利用文章内的相关技术从事非法测试,如因此产生的一切不良后果与作者无关。 目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现...
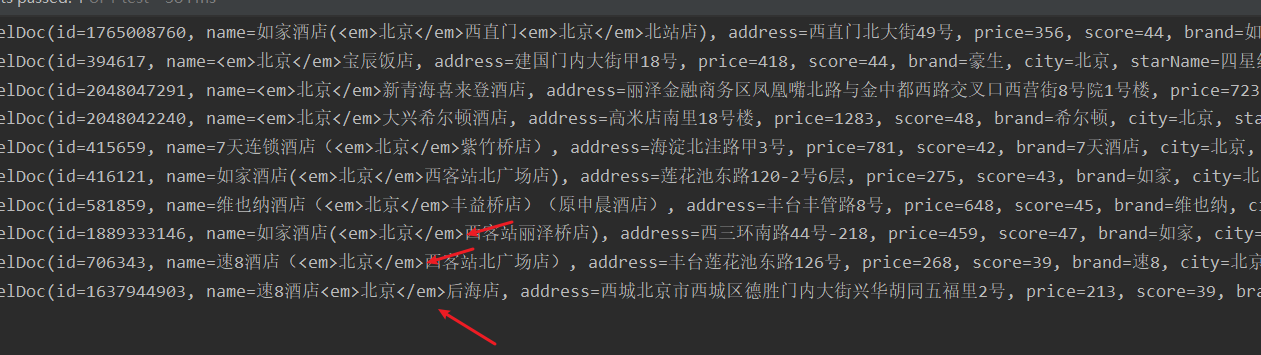
Spring Cloud之ElasticSearch的学习【详细】
目录 ElasticSearch 正向索引与倒排索引 数据库与elasticsearch概念对比 安装ES、Kibana与分词器 分词器作用 自定义字典 拓展词库 禁用词库 索引库操作 Mapping属性 创建索引库 查询索引库 删除索引库 修改索引库 文档操作 新增文档 查找文档 修改文档 全量…...
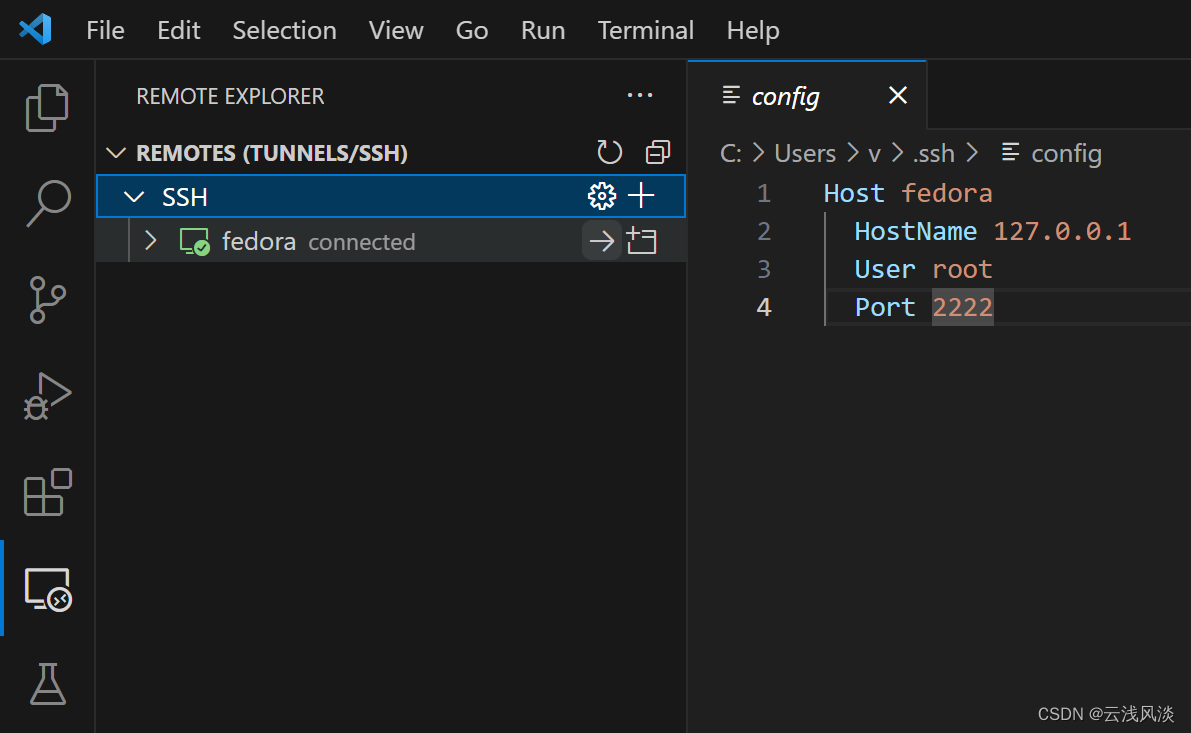
vscode免密码认证ssh连接virtual box虚拟机
文章目录 安装软件virtual box配置vscode配置创建并传递密钥连接虚拟机最后 安装软件 安装vscode和virtual box,直接官网下载对应软件包,下载之后,点击执行,最后傻瓜式下一步安装即可 virtual box配置 创建一个仅主机网络的网卡 …...

【Linux】Centos yum源替换
YUM是基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。 CentOS 8操作系统版本结束了生命周期(EOL)࿰…...
)
uniapp组件初始化的销毁(监听隐藏事件)
onHide是监听隐藏事件onHide() {console.log("销毁");this.clearTimer(); }, onShow(){console.log("初始化");this.getOrderInfo() },...
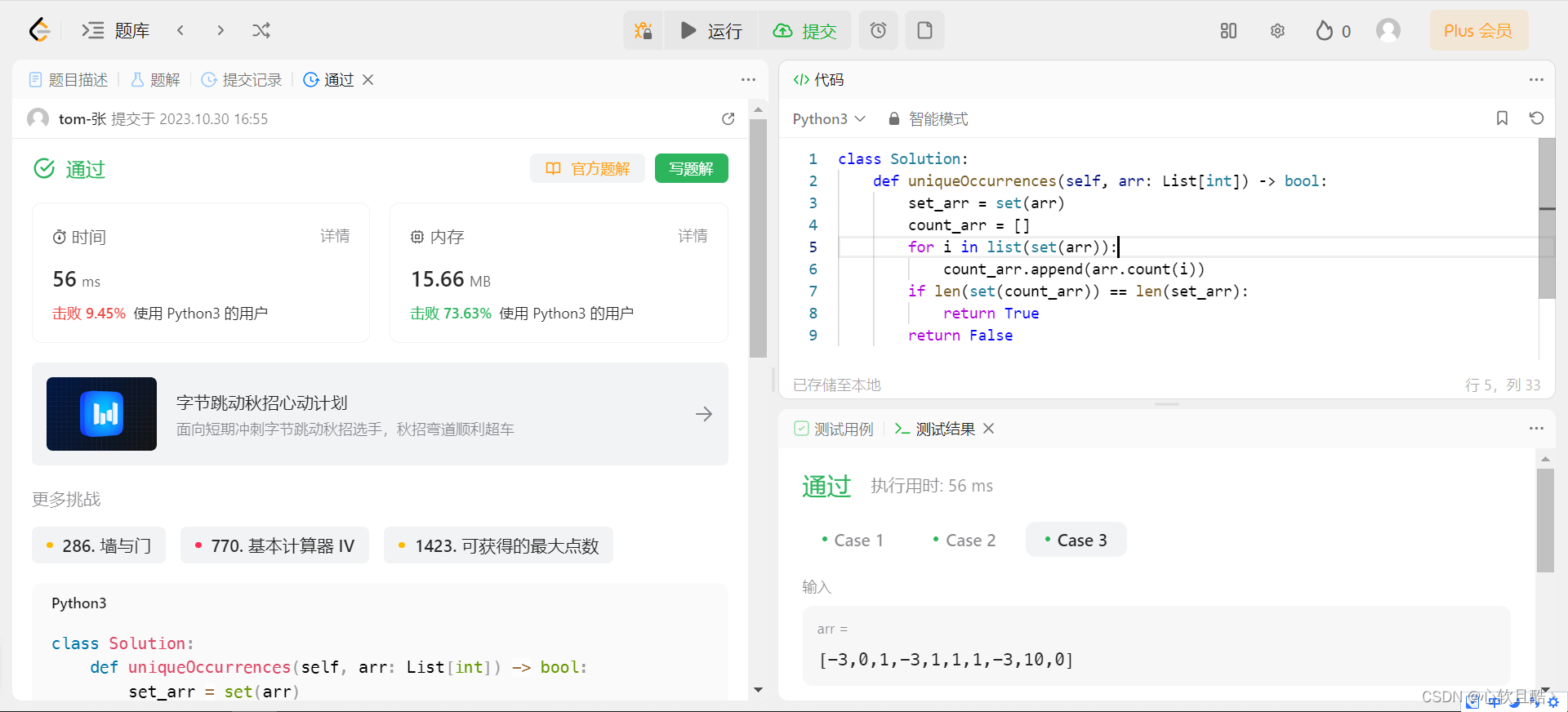
leetcode:1207. 独一无二的出现次数(python3解法)
难度:简单 给你一个整数数组 arr,请你帮忙统计数组中每个数的出现次数。 如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。 示例 1: 输入:arr [1,2,2,1,1,3] 输出:true 解释&…...

2023秋《论文写作》课程总结
2023秋《论文写作》课程总结 授课教师为闵帆教授,原文链接《论文写作》 文章目录 2023秋《论文写作》课程总结一、关于写作工具二、关于写作中的单词、短语、语法等三、关于论文题目四、关于摘要和关键词五、关于引言部分六、关于方法及实验部分七、关于结论八、关…...

Anubi基金会为何押注Cassava?深度解析Web3数据层+社交任务的黄金组合
Anubi基金会战略投资Cassava:Web3社交任务与数据层的价值重构 当Web3世界从DeFi的金融实验转向更广泛的社会化应用时,基础设施的演进正在经历一场静默的革命。Anubi基金会近期对Cassava Network的战略投资,揭示了两个关键趋势:社交…...

ESP8266高精度脉冲计数波形发生器库
1. 项目概述esp8266_waveformPulseCounter是一款面向 ESP8266 平台的高精度脉冲计数型波形发生器库,其核心设计目标是在硬件级精确控制下生成指定脉冲数量的方波/矩形波信号,并在计数完成时触发用户定义的回调动作。该库并非通用波形合成工具,…...

小米测试开发面试全解析:从理论到实战
1. 小米测试开发面试全流程解析 第一次参加小米测试开发面试的朋友可能会有点懵,不知道从哪开始准备。作为一个经历过完整面试流程的"过来人",我来分享一下我的真实经历。小米的测试开发面试一般分为2-3轮,每轮侧重点不同ÿ…...

Gemma-3-12B-IT WebUI保姆级教程:多模型切换与Gemma-3-27B对比体验
Gemma-3-12B-IT WebUI保姆级教程:多模型切换与Gemma-3-27B对比体验 1. 开篇:为什么你需要一个更聪明的AI助手? 想象一下,你手头有一个能写代码、能解答技术难题、还能陪你聊天的AI助手。它运行在你自己的服务器上,数…...

新手也能懂:用Altium Designer搞定SPI Flash、eMMC和USB3.0的PCB等长与阻抗控制
Altium Designer实战:SPI Flash、eMMC与USB3.0的等长布线及阻抗控制指南 刚接触高速PCB设计时,面对密密麻麻的规则手册总让人望而生畏。3H原则、500mil误差、阻抗匹配这些术语听起来像天书,但当你用Altium Designer(AD)…...

3分钟彻底搞定Axure RP汉化:免费中文语言包完整指南
3分钟彻底搞定Axure RP汉化:免费中文语言包完整指南 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包,不定期更新。支持 Axure 9、Axure 10。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在…...

如何通过智能求职助手提升职位时间筛选效率?揭秘高效求职新方法
如何通过智能求职助手提升职位时间筛选效率?揭秘高效求职新方法 【免费下载链接】boss-show-time 展示boss直聘岗位的发布时间 项目地址: https://gitcode.com/GitHub_Trending/bo/boss-show-time 在当今竞争激烈的就业市场中,职位时间筛选已成为…...

数据库优化:高效查询GUID的技巧
在日常的数据库操作中,如何高效地查询数据是一个永恒的话题。特别是当我们处理大型数据集和需要在文本字段中查找特定模式(如GUID)时,查询效率显得尤为关键。今天,我将分享一种优化查询GUID的方法,帮助你从长达数小时的查询时间中解脱出来。 背景 假设我们有一个数据库…...

音乐标签编辑器:让本地音乐元数据管理效率提升90%的开源工具
音乐标签编辑器:让本地音乐元数据管理效率提升90%的开源工具 【免费下载链接】music-tag-web 音乐标签编辑器,可编辑本地音乐文件的元数据(Editable local music file metadata.) 项目地址: https://gitcode.com/gh_mirrors/mu/…...

从长城杯赛题到实战:基于ZeroShell防火墙的威胁流量深度狩猎
1. 从CTF赛题到真实威胁狩猎的思维转换 第一次接触长城杯那道ZeroShell防火墙的赛题时,我还在纳闷:这种刻意设计的漏洞场景,在真实企业里真的存在吗?直到上个月帮某制造业客户做安全巡检,亲眼看到他们的ZeroShell 3.9.…...