Python程序设计期末复习笔记
文章目录
- 一、数据存储
- 1.1 倒计时
- 1.2 os库
- 1.3 字符串操作
- 1.4 文件操作
- 1.5 列表操作
- 1.6 元组
- 1.7 字典
- 二、文本处理及可视化
- 2.1 jieba分词
- 2.2 集合操作
- 2.3 pdf文件读取
- 2.4 参数传递
- 2.5 变量作用域
- 三、数据处理分析
- 3.1 Sumpy
- 3.2 Matplotlib
- 3.3 Numpy
- 四、Pandas
- 4.1 索引操作
- 4.2 统计函数
- 4.3 数据清洗
- 4.4 MISC
- 五、分类与回归
- 5.1 分类
- 5.2 十折交叉验证
- 5.3 回归
- 六、聚类与降维
- 6.1 processing
- 6.2 聚类
- 6.3 降维
- 6.4 机器学习步骤
- 6.5 图像
- 七、Tensorflow
- 7.1 评价指标-分类
- 7.2 评价指标-回归
- 7.3 激活函数
- 7.4 使用Keras搭建神经网络
一、数据存储
1.1 倒计时
- time.strftime(“%Y:%m:%d:%H:%M:%S”) 年月日时分秒
1.2 os库
| 方法 | 含义 |
|---|---|
| os.path.join(“C:\Windows”, “love.jpg”) | 生成c\Windows\love.jpg路径 |
| os.rename(“D:\test1.txt”,“D:\test2.py”) | 将test1重命名为test2 |
| os.mkdir(“C:\TEST”) | 在当前目录下创建文件夹TEST |
| os.rmdir(“C:\TEST”) | 删除当前目录下的TEST文件夹 |
1.3 字符串操作
s = ‘华东理工大学’
| 操作 | 含义 |
|---|---|
| s[-1] | ‘学’ |
| s[0:2] | ‘华东’ |
| s[0:6:2] | ‘华理大’ |
| s.lower()、s.uppper() | 都转化为最小值,最大值 |
| s.split(‘分隔符’) | 返回list |
| s.find(‘子串’) | 搜索成功返回下标,搜索不到返回-1 |
| s.replace(‘理’,‘力’) | 华东力工大学 |
| s.strip() | 去除两边的空格及特殊符号(\n) |
1.4 文件操作
f = open(‘path’,‘r’), f.close() 或者直接使用 with open(‘path’,‘r’) as f:
| 操作 | 含义 |
|---|---|
| r | 读 |
| w | 写 与’a’不同,w会清空原文件 |
| a | 追加 with open(‘2.txt’, ‘a’) as f: f.write(‘dfgddfgfg\n’) |
| read() | 读取全部内容 |
| readline() | 读取文件第一行 |
| readlines() | 读取文件的每一行返回列表 file = f.readlines() p = [x.strip() for x in file ] |
1.5 列表操作
| 操作 | 含义 |
|---|---|
| sort(reverse=) | reverse默认是False,默认从小到大排序 |
| append(x) | 增加x到列表末尾 |
| remove(x) | 移除第一次出现的x |
| count(x) | x出现次数 |
| extend(newlist) | 将newlist逐个append到原列表后 |
| 索引操作 | 列表索引操作与字符串相同 |
1.6 元组
- tuple()
- 元组索引操作与字符串相同
1.7 字典
- d = dict()
- 键值对,键唯一且不可变:数字、字符串、元组
| 操作 | 含义 |
|---|---|
| d.keys() | 键列表 |
| d.values() | 值列表 |
| d.items() | 返回键-值 列表 借助lambda函数按值排序。 ①t = list(a.items()) ②t.sort(key=lambda x: x[1]) ③d = dict(t) |
| d.get(key, default) | 若key不存在返回default值,例如a = d.get(‘apple’,0)+1 |
| d.update(a) | 将字典a中的键值对逐个放入字典d,类似列表的extend操作 |
二、文本处理及可视化
会从头到尾写一个词云图生成代码结合字典,文件读写操作,使用jieba分词,结合字符串操作,imageio.v2读取图片,WordCloud生成词云(counts), matplotlib来show图片
2.1 jieba分词
| 方法 | 含义 |
|---|---|
| jieba.add_word(‘newword’) | 添加新词 |
| jieba.lcut(‘string’) | 精确模式 |
| jieba.lcut(‘string’, cut_all=True) | 全模式 |
| jieba.lcut_for_search(‘string’) | 搜索引擎模式 |
2.2 集合操作
集合:a、b set()
| 操作 | 含义 |
|---|---|
| a & b | 交集 |
| a | b |
| a - b | a - a&b |
| a ^ b | a |
| a < b | a是否为b的真子集 |
| a <= b | a是否为b的子集 |
| a == b | a与b两个集合是否相同 |
2.3 pdf文件读取
import pdfplumber
pdf = pdfplumber.open('Attention.pdf')
pages = pdf.pages
pages[0].extract_text()
2.4 参数传递
| 传递方式 | 含义 |
|---|---|
| fun(2,3) | 位置传递 |
| fun(b=3,a=2) | 关键字传递 |
| fun(a, b=2), fun(7) | 默认值参数传递 |
| fun(*number) | 元组类型变长 |
| fun(**d) | 字典类型变长 |
| f = lambda x : x**3 | labmda匿名函数 f(3) = 27 |
2.5 变量作用域
global 全局变量:在函数块中引用全局变量时需要先用global x 声明一下才能修改全局变量,否则只是修改局部变量
三、数据处理分析
3.1 Sumpy
创建符号变量 x,y=symbols(‘x y’) #x是符号变量名称,'x’是符号变量的值
| opention | 例子 |
|---|---|
| 极限 | limit(sin(x)/x,x,0) |
| 导数 z=sin(x)+x**2*exp(y) | diff(z,y,1) |
| 定积分 | integrate(sin(2*x),(x,0,pi)) |
| 求解代数方程组 | solve([x**2+y**2-1, x-y], [x, y]) |
| 级数求和 | k,n=symbols(‘k n’) ,summation(k**2,(k,1,n)) |
| 因式分解 | factor() |
3.2 Matplotlib
必考,画图是重点,大概率结合subplot
| 方法 | 含义 |
|---|---|
| plot(X, y, linestyle= , color=, marker= , label= ) | 折线图 |
| bar(name, value), 水平条形图:barh() | 垂直条形图 |
| pie(x = value, explode= , labels= ,autopct= ‘%.1f%%’, shadow= True) | 饼图 |
| sctter(name, value) | 散点图 |
| hist(x=, bins= ) | 直方图 |
| boxplot() | 箱线图 |
| figure(figsize=(w,h)) | 指定图像大小 |
| title | 图像标题 |
| xlabel | 添加X轴标签,ylabel同理 |
| xlim([0,8]) | 指定X轴区间,ylim同理 |
| xticks([0,2,4,6,8] | 指定X轴取值,yticks同理 |
| legend(loc=‘upper right’) | 指定图label位置 |
| subplot | 绘制子图 |
| suptitle | 多个子图的大标题 |
常见的颜色字符:‘r’、‘g’、‘b’、‘y’、‘w’等
常见的线型字符:’-‘(直线)、’–‘(虚线)、’:‘(点线)等.
常用的描点标记:‘o’(圆圈)、‘s’(方块)、’^'(三角形)等
3.3 Numpy
| 方法 | 含义 |
|---|---|
| a = np.array([1,3,4,6]) | |
| np.linespace(0,10,100) | #0~10 分成100份 |
| np.arange(0,5,0.1) | 0~5,步长为0.1, 步长默认为1,起点默认为0 |
| a.reshape(20,5) | reshape |
| a.flatten() | 变为一维 |
| np.random.randint(n= , size= ) | 生成[0,n)之间的整数,n可以是一个数,size可以是一维也可以是二维 |
| np.random.uniform(n= , size= ) | 生成浮点数 |
| np.loadtxt(“trade.csv”,delimiter=“,”) | 加载文件 |
| np.savetxt(‘result.csv’) | 保存文件 |
| np.zeros((a,b)), np.ones() | 生成指定格式0,1矩阵 |
| np.identify(n) | 生成指定维度单位阵 |
| a.astype(‘int’), ‘float’ | 数据类型转化 |
| a.transpose() | 转置 |
| a.sum() | 求a数组总数的和 |
| a.max() | a所有元素中的最大值 |
| np.dot(a, 2) | a数组的每个元素都乘以2 |
四、Pandas
这章比较重要,会使用pands读取数据,数据清洗预处理,结合matplotlib,会画饼图、折线图等,会独立编写ppt里面的案例代码。
- data = pd.read_csv(‘path’) 数据读取
- Series pd.Series(data, index=[‘a’,‘b’,‘c’,‘d’,‘e’]) 生成pandas序列
- DataFrame(data= , columns= , index= ) 数据、列名、索引
4.1 索引操作
- 基于位置序号选取(大概率考与loc区别)
| 函数名 | 含义 |
|---|---|
| data.iloc[a,b] | 选取a行b列 |
| data.iloc[list1, list2] | 选取多行多列,都是数字 |
| data.iloc[a:b, c:d] | 选取ab-1行的cd-1列数据 |
- 基于索引名选取
| 函数名 | 含义 |
|---|---|
| data[‘col’] | 选取col列 |
| data[colList] | 选取多列 |
| data.loc[index, ‘col’] | 选取index行, col列 |
| data.loc[indexList, colList] | 选取多行多列 |
4.2 统计函数
| 函数名 | 含义 |
|---|---|
| data.describe() | 基本统计量及分位数 |
| data.mean() | 取每一列的平均值 |
| data.count() | 返回列个数 |
| data.max(),data.min() | 按列取最大值 |
| data.sum() | 取每一列的sum |
| data.head(n) | 取前几行,默认为5 |
| data.tail(n) | 取后几行,默认为5 |
| data.corr() | 相关系数 相关矩阵plt.matshow() |
| data.mode() | 众数 |
4.3 数据清洗
| 函数名 | 含义 |
|---|---|
| data.dropna() | 某行存在空值,删去改行 |
| data.dropna(axis=1) | 某列存在空值,删除该列 |
| data.dropna(how= ‘all’, thresh= n) | how代表指定维度全空时才删除, thresh表示指定维度存在n个数时保留。 |
| data.fillna(value= , method= ) | value是单个值时,所有的空值都用该值补充,value是字典时根据键对应列,空值对应值。method可以取, ffill, bfill |
| data.replace(value) | value可以是两个值,也可以是字典 |
| data.drop_duplicates | 取出重复数据 |
| pd.concat([data1,data2],axis = ) | 需要叠加的数据,axis=0按行追加,1按列 |
| pd.merge() | how,内连接、外连接,数据库的相关操作 |
| data.sort_index(ascending= ) | 按照索引号排序,默认下ascending为True,升序 |
| data.sort_value(by = [collist]) | 按照by指定列进行排序,默认是升序 |
| 注 | 所有数据操作要加inplace=True |
4.4 MISC
- 相关性
|r|<0.4 弱、 0.4<=|r|<0.7 中、 0.7<=|r| 高
- Scatter-matrix 矩阵图
pd.plotting.scatter_matrix(data)
plt.show()
- 数据选取
data.iloc[condition, colist]
data.loc[condition, colist]
五、分类与回归
会使用一种算法进行数据预处理,模型训练、预测、评估的代码。包括分类、回归、聚类
5.1 分类
| 算法 | 引入包名 | 名称 |
|---|---|---|
| KNN | from sklean.neighbors import KNeighborsClassifier | K近邻 |
| NB | from sklearn.naive_bayes import GaussianNB | 贝叶斯 |
| SVM | from sklearn.svm import SVC | 支持向量机 |
| DT | from sklearn.tree import DecisionTreeClassifier | 决策树 |
| Logistic Regression | from sklearn.linear_model import LogisticRegression | 逻辑回归 |
5.2 十折交叉验证
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
cv_results = cross_val_score(models[key], X, Y, cv=kfold)
5.3 回归
| 算法 | 包名 | 名称 |
|---|---|---|
| LR | from skelarn.linear_model import LinearRegression | 线性回归 |
六、聚类与降维
6.1 processing
| 方法名称 | 含义 | 例子 |
|---|---|---|
| 归一化(MinMaxScaler) | 转化为0~1之间 | mms = MinMaxScaler(); x_bin = mms.fit_transform(X) |
| 标准化(StandardScaler) | Z = x − μ σ Z = \frac{x-μ}{σ} Z=σx−μ | 声明+转化 |
| 正则化(Normalizer) | 去除不同特征范围不同 | 同上 |
| 二值化(LabelBinarizer) | 二值化 | 同上 |
6.2 聚类
- KMeans
from sklearn.cluster import KMeans
model = KMeans(n_clusters= )
...
model.labels_
6.3 降维
- PCA
from sklearn.decomposition import PCA
pca = PCA(n_components= )
x = pca(X)
指定n_components为降维后的维度
- 3D图
from mpl_toolkits.mplot3d import Axes3D
6.4 机器学习步骤
① 导入数据
② 数据概览
③ 数据可视化
④ 模型评估
⑤ 实施预测
6.5 图像
| 概念 | 含义 |
|---|---|
| 二值图像 | 0,1。1个二进制位 |
| 灰度图像 | 0~255。8位无符号整数, convert(‘L’) |
| 通道分割 | split |
| 通道合并 | merge |
| 轮廓提取 | filter |
七、Tensorflow
会使用keras搭建序列网络、卷积网络。ppt的图像分类例子会独立编写。
7.1 评价指标-分类
| 名称 | 含义 | 计算公式 |
|---|---|---|
| 混淆矩阵 | 预测结果与真是结果组成矩阵 | TP预测为正实际为正,TN预测为副实际为副,FN,预测为负实际为正,FP预测为正实际为负 |
| 精确率(metrics.precison_score) | 预测为正中实际为正比例 | P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP |
| 召回率(recall_score) | 实际为正的样本中预测为正的样本 | R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP |
| F1-Score(f1_score) | 2 ∗ P ∗ R P + R \frac{2*P*R}{P+R} P+R2∗P∗R | |
| 准确率(accuracy_score) | 预测正确的样本比例 | T P + T N T P + T N + F P + F N \frac{TP+TN}{TP+TN+FP+FN} TP+TN+FP+FNTP+TN |
7.2 评价指标-回归
| 名称 | 含义 | 计算公式 |
|---|---|---|
| 平均绝对误差(metrics.mean_absolute_error) | MAE | 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \frac{1}{n}\sum\limits_{i=1}^{n} \lvert y_i - \hat y_i \rvert n1i=1∑n∣yi−y^i∣ |
| 均方误差(mean_squared_error) | MSE | 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \frac{1}{n} \sum\limits_{i=1}^{n}(y_i - \hat y_i)^2 n1i=1∑n(yi−y^i)2 |
| 决定系数(r2_score) | R 2 R^2 R2 | R 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ i ) 2 R^2 = 1 - \frac{\sum\limits_{i=1}^{n}(y_i-\hat y_i)^2}{\sum\limits_{i=1}^{n}(y_i - \bar y_i)^2} R2=1−i=1∑n(yi−yˉi)2i=1∑n(yi−y^i)2,其中 y ˉ = 1 n ∑ i = 1 n y i \bar y = \frac{1}{n} \sum\limits_{i=1}^{n}y_i yˉ=n1i=1∑nyi |
7.3 激活函数
| 函数名 | 表达式 | 备注 |
|---|---|---|
| Sigmoid | f ( x ) = 1 1 + e − x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1 | 值域0~1 |
| tanh | f ( x ) = e x − e − x e x + e − x f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} f(x)=ex+e−xex−e−x | 值域-1~1 |
| ReLU | f ( x ) = m a x 0 , x f(x) = max{0,x} f(x)=max0,x | 值域>=0 |
7.4 使用Keras搭建神经网络
- 步骤
载入数据、数据预处理、构建Sequntial模型,使用compile编译模型,使用fit函数训练模型、模型评估与预测
- 序列
model = tf.keras.models.Sequential([tf.keras.layers.Dense(50, input_dim= 28*28, activation='relu', name='Hidden'),tf.keras.layers.Dense(10, activation='softmax', name='Output')
])- 卷积
model = tf.keras.models.Sequential([#卷积tf.keras.layers.Conv2D(32,(3,3), activation='relu', input_shape=(28,28,1)),#池化tf.keras.layers.MaxPooling2D((2,2)),#dropouttf.keras.layers.Dropout(rate=0.2),#全连接tf.keras.layers.Flatten(),tf.keras.layers.Dense(50, activation='relu'),tf.keras.layers.Dense(10, activation='softmax')
])
相关文章:
Python程序设计期末复习笔记
文章目录 一、数据存储1.1 倒计时1.2 os库1.3 字符串操作1.4 文件操作1.5 列表操作1.6 元组1.7 字典 二、文本处理及可视化2.1 jieba分词2.2 集合操作2.3 pdf文件读取2.4 参数传递2.5 变量作用域 三、数据处理分析3.1 Sumpy3.2 Matplotlib3.3 Numpy 四、Pandas4.1 索引操作4.2 …...

人大与加拿大女王大学金融硕士—与您共创辉煌
生活的本质就是有意识的活着,而生活的智慧就是活出了自己想要的样子,那些真正厉害的人,从来都在默默努力,伴随着金融人才的需求日益增长,中国人民大学与加拿大女王大学联合推出了人大女王金融硕士项目,旨在…...
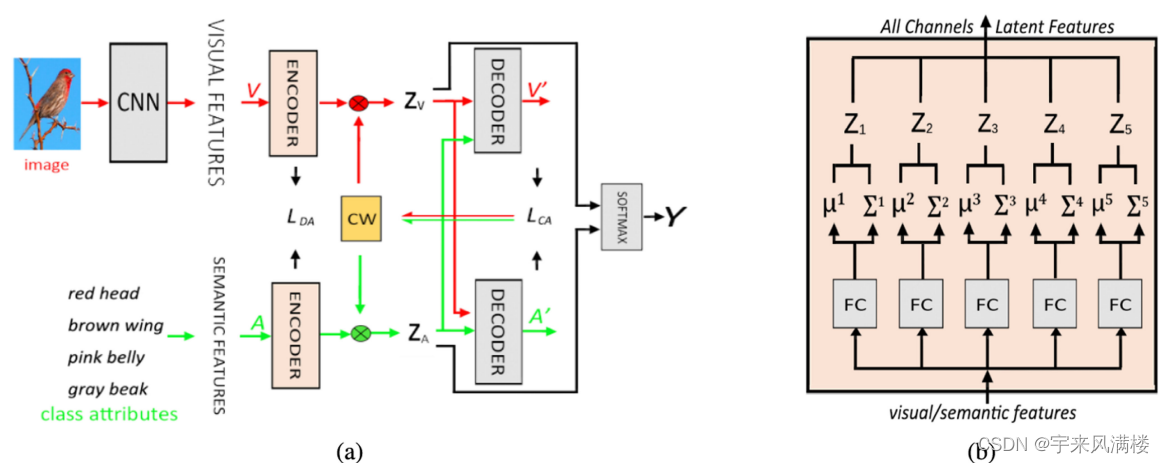
Generalized Zero-Shot Learning With Multi-Channel Gaussian Mixture VAE
L D A _{DA} DA最大化编码后两种特征分布之间的相似性 辅助信息 作者未提供代码...
)
10.30 知识总结(标签分类、css介绍等)
一、 标签的分类 1.1 单标签 img br hr <img /> 1.2 双标签 a h p div <a></a> 1.3 按照标签属性分类 1.3.1 块儿标签 即自己独自占一行 h1-h6 p div 1.3.2 行内(内联)标签 即自身文本有多大就占多大 a span u i b s 二、 标签的嵌套 标签之间是可以互相…...
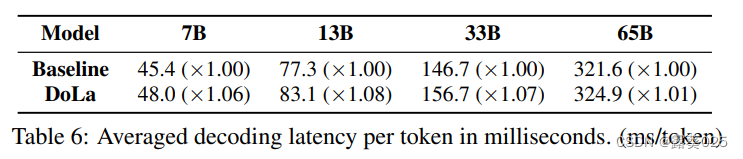
DoLa:对比层解码提高大型语言模型的事实性
DoLa:对比层解码提高大型语言模型的事实性 摘要1 引言2 方法2.1 事实知识在不同层级上演化2.2 动态早期层选择2.3 预测对比 3 实验3.1 任务3.2 实验设置3.3 多项选择3.3.1 TruthfulQA:多项选择3.3.2 FACTOR:维基、新闻 3.4 开放式文本生成3.4…...

解决由于找不到mfc140u.dll无法继续执行此代码问题的4个方法
mfc140u.dll是Microsoft Foundation Class(微软基础类库)中的一个动态链接库文件,它包含了许多用于实现Windows应用程序的基本功能。当我们在编写或运行基于MFC的程序时,如果系统中缺少这个文件,就会出现“找不到mfc14…...

MySQL高性能优化规范建议
当涉及到MySQL数据库的性能优化时,有许多方面需要考虑。以下是一些通用的MySQL性能优化规范建议: 合适的索引: 确保表中的字段使用了适当的索引。这能大幅提升检索速度。但避免过多索引,因为它会增加写操作的成本。 优化查询语句…...
pytorch 入门 (五)案例三:乳腺癌识别-VGG16实现
本文为🔗小白入门Pytorch内部限免文章 🍨 本文为🔗小白入门Pytorch中的学习记录博客🍦 参考文章:【小白入门Pytorch】乳腺癌识别🍖 原作者:K同学啊 在本案例中,我将带大家探索一下深…...

vue中electron与vue通信(fs.existsSync is not a function解决方案)
electron向vue发送消息 dist/main.js (整个文件配置在另一条博客里) win new BrowserWindow({width:1920,height:1080,webPreferences: {// 是否启用Node integrationnodeIntegration: true, // Electron 5.0.0 版本之后它将被默认false// 是否在独立 JavaScript 环境中运行…...

LSTM-Based Anomaly Detection of Process Instances Benchmark and Tweaks翻译
论文《LSTM-Based Anomaly Detection of Process Instances Benchmark and Tweaks》翻译 LSTM-Based Anomaly Detection of Process Instances Benchmark and Tweaks翻译...

文件类漏洞总结, 文件包含, 文件上传, 文件下载
文件类漏洞总结 一, 文件包含 1. 文件包含绕过 实际环境中不是都是像$_GET[file]; incude $file 这样直接把变量传入包含函数的。 在很多时候包含的变量文件不是完全可控的,比如下面这段代码指定了前缀和后缀: <?php $file S_GET[filename]; include /opt/…...

SpringBoot篇---第四篇
系列文章目录 文章目录 系列文章目录一、springboot常用的starter有哪些二、 SpringBoot 实现热部署有哪几种方式?三、如何理解 Spring Boot 配置加载顺序? 一、springboot常用的starter有哪些 spring-boot-starter-web 嵌入tomcat和web开发需要servlet…...
 -- 在不同版本SpringBoot,选用不同的Knife4j相关的jar包)
Knife4j使用教程(一) -- 在不同版本SpringBoot,选用不同的Knife4j相关的jar包
目录 1. Knife4j的项目背景 2. Knife4j的选择 2.1 选用 Spring Boot 版本在 2.4.0~3.0.0之间 2.2 选用 Spring Boot 版本在 3.0.0之上...
Octave Convolution学习笔记 (附代码)
论文地址:https://export.arxiv.org/pdf/1904.05049 代码地址:https://gitcode.com/mirrors/lxtgh/octaveconv_pytorch/overview?utm_sourcecsdn_github_accelerator 1.是什么? OctaveNet网络属于paper《Drop an Octave: Reducing Spatia…...
SpringSecurity 认证实战
一. 项目数据准备 1.1 添加依赖 <dependencies><!--spring security--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId></dependency><!--web起步依赖-…...
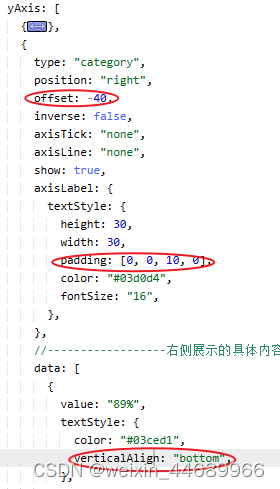
echarts中横向柱状图的数字在条纹上方
实现效果: 数字在条纹的上方 实现方法:这些数字是用新添加一个坐标轴来实现的 直接添加坐标轴数字显示是在条纹的正右边 所以需要配置一下偏移 完整代码 var option {grid: {left: "3%",right: "4%",bottom: "3%",cont…...

【仙逆】尸阴宗始祖现身,王林修得黄泉生窍诀,阿呆惊险逃生
【侵权联系删除】【文/郑尔巴金】 深度爆料最新集,王林终于成功筑基,这一集的《仙逆》动漫真是让人热血沸腾啊!在这个阶段,王林展现出了他的决心和毅力,成功地击杀了藤厉,并采取了夺基大法,从藤…...

C++二叉树剪枝
文章目录 C二叉树剪枝题目链接题目描述解题思路代码复杂度分析 C二叉树剪枝 题目链接 LCR 047. 二叉树剪枝 - 力扣(LeetCode) 题目描述 给定一个二叉树 根节点 root ,树的每个节点的值要么是 0,要么是 1。请剪除该二叉树中所有节…...
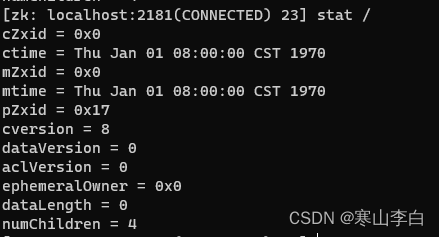
ZooKeeper中节点的操作命令(查看、创建、删除节点)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...
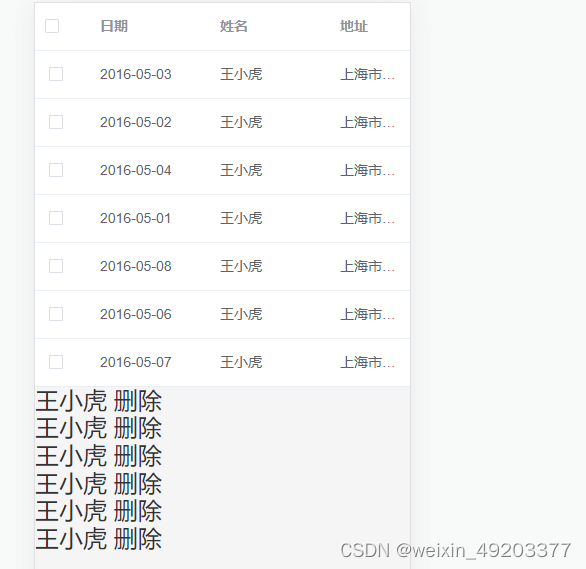
el-table多选表格 实现默认选中 删除选中列表取消勾选等联动效果
实现效果如下: 代码如下: <template><div><el-tableref"multipleTable":data"tableData"tooltip-effect"dark"style"width: 100%"selection-change"handleSelectionChange"><…...

别再死记硬背了!用Python和C语言手把手带你理解CRC32查表法的实现原理
从数学到代码:用Python和C语言彻底搞懂CRC32查表法的实现 在数据传输和存储过程中,错误检测是确保数据完整性的关键环节。CRC32作为一种广泛应用的校验算法,从网络协议到压缩工具,再到文件系统,几乎无处不在。但很多开…...

工业 AI 赋能采购:智能供应商匹配重构招标流程
Q1:传统企业采购招标,供应商对接与筛选存在哪些固有痛点?传统工业企业采购招标模式高度依赖人工经验,存在三大核心痛点:供应商资源固化:每次招标都需从零手动联络供应商,仅依靠采购人员个人记忆…...

技术生态依赖的实质与破局:从Android到自主可控的实践路径
1. 项目背景与核心议题解析最近在整理行业资料时,翻到一篇2013年的旧文,讨论的是当时中国工信部对国内移动产业过度依赖Android系统的担忧。虽然时过境迁,但文中提到的“技术自主可控”与“全球生态融入”之间的张力,在今天看来依…...

Lumi Diary:基于OpenClaw Skill的本地AI记忆伴侣设计与实践
1. 项目概述:一个住在你设备里的记忆精灵如果你和我一样,对把生活点滴交给云端总有点不放心,但又渴望有一个能懂你、能帮你把碎片记忆编织成故事的伙伴,那么 Lumi Diary 的出现,可能正是时候。这不是又一个需要你手动打…...

处理电商分类难题:我是如何用XGBoost为Otto数据集做多类别预测的
电商商品分类实战:XGBoost在Otto数据集上的高阶应用 当面对海量商品需要精准分类时,传统人工规则往往力不从心。Otto Group Product Classification Challenge正是这样一个典型场景——需要将数十万商品准确划分到93个类别中。本文将分享如何用XGBoost构…...

告别AT指令恐惧症:用ESP-01S和51单片机,5分钟搞定手机远程开关灯
从零到一的智能家居初体验:ESP-01S与51单片机极简联动方案 第一次接触物联网硬件开发时,那些密密麻麻的AT指令确实容易让人望而生畏。但当我真正用ESP-01S模块配合最基础的51单片机,在五分钟内实现了手机远程开关LED灯的那一刻,所…...

LaMa图像修复:基于傅里叶卷积的大掩码鲁棒修复方法
1. 项目概述:这不是又一个“修图工具”,而是一次对图像修复底层逻辑的重新定义LaMa——全称Large Mask Inpainting,直译是“大区域掩码图像修复”,但它的实际能力远超字面。我第一次在CVPR 2022论文里看到它时,第一反应…...

LyricsX:一站式macOS歌词同步解决方案,让音乐体验更智能
LyricsX:一站式macOS歌词同步解决方案,让音乐体验更智能 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是macOS平台上功能最全面的歌词同步工具ÿ…...

CodeBuddy ai对话框上面的git docs terminal Rulds 干嘛用的,以thinkphp fastadmin 为例,插件市场
CodeBuddy(或同类 AI 编程助手)里的**「上下文注入(Context Injection)」功能模块**,作用是把项目/环境信息喂给 AI,让它“看得懂你的项目”,而不是凭空瞎编代码。 插件市场###ai对对话框 逐个拆…...

5步掌握OpenCore Configurator:黑苹果配置终极可视化指南
5步掌握OpenCore Configurator:黑苹果配置终极可视化指南 【免费下载链接】OpenCore-Configurator A configurator for the OpenCore Bootloader 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Configurator 如果你正在为黑苹果系统的复杂配置而烦恼…...