LLM-Embedder
1. 目标
训出一个统一的embedding模型LLM-Embedder,旨在全面支持LLM在各种场景中的检索增强
2. 模型的四个关键检索能力
- knowledge:解决knowledge-intensive任务
- memory:解决long-context modeling
- example:解决in-context learning(上下文学习)
- tool:解决tool learning
3. 要解决的问题
- 嵌入模型必须优化其对LLM的最终检索增强影响,而不是仅仅关注中间检索结果
- 不同的检索任务旨在捕捉不同的语义关系,它们的影响可能受到相互干扰
4. base model
是在BAAI/bge-base-en的基础上训练的
5. 训练数据
- Question Answering
- MSMARCO(labeled)
- Natural Questions(labeled)
- Conversational Search
- QReCC(labeled)
- Tool Learning
- ToolLLM(labeled)
- Instruction Tuning
- FLAN(Non-labeled)
- UPRISE(Non-labeled)
- Generation
- Multi-Session Chat(Non-labeled)
- Books3(Non-labeled)
- ArXiv(Non-labeled)
- CodeParrot(Non-labeled)
6. 数据格式
training
{"query": str,"pos": List[str],"neg": List[str],"pos_index": Optional[List[int]], # 正样本在语料库里面的索引,如果没有全局语料库,则忽略"neg_index": Optional[List[int]], # 负样本在语料库里面的索引,如果没有全局语料库,则忽略 "teacher_scores": Optional[List[float]], # 一个LM或者一个reranker的分数,被用来进行蒸馏"answers": Optional[List[str]], # List of answers for the query, used for LM scoring.
}
evaluation
{"query": str,"pos_index": Optional[List[int]], # Indices of the positives w.r.t. corpus (retrieval) / w.r.t. keys (rerank). When there is no positives pre-defined (e.g. NQ), just ignore this field."answers": Optional[List[str]], # List of answers for computing NQ metrics."key": Optional[List[str]], # Collated retrieval results for the query / candidates to rank when there are no positives and negatives."key_index": Optional[List[int]], # Key indices w.r.t. the corpus when reranking and no positives & negatives.
}
7. 训练方法
(主要是Reward from LLM,Instruction-based Fine-Tuning,Homogeneous In-Batch Negative Sampling和Stabilized Distillation四个关键技术)
-
Reward from LLM
-
除了数据集中的hard labels,这里还将LLM的输出作为reward,这些reward可以作为soft labels
-
(1)式中C为一个检索到的候选,也就是一个中间结果,O是期望的LLM的输出,一个候选的reward被表示为 r C ∣ O r_{C|O} rC∣O。 o i o_i oi表示期望输出的第i个token, O : i − 1 O_{:i-1} O:i−1表示期望输出的前i-1个token
-
LLM reward的使用范围:问答(Question Answering),指令调整(Instruction Tuning),生成(Generation);在会话搜索(conversational search) 和 工具学习数据集(tool learning datasets)上不适用,因为在这些情况下对LLM的输出没有明确的期望
-
使用对比学习(contrastive learning)的方法去抓取hard labels所反应的语义关系,用知识蒸馏(knowledge distillation)的方法从LLM生成的soft reward中学习
-
-
对比学习
- 与一般的对比学习差不多,但为了提高embedding在不同应用场景中的辨别能力在对比学习框架中采用了几个关键设计:
- Instruction-based Fine-Tuning:给每一个任务设计了一个对应的instruction,计算embedding的时候将instruction和query合在一起计算: e q ← e n c o d e ( [ I t , q ] ) e_q\gets encode([I_t, q]) eq←encode([It,q])
- Homogeneous In-Batch Negative Sampling:使用了cross-device sharing,在这个方法里负样本一共有 B × K × N − 1 B\times K\times N-1 B×K×N−1个负样本,B是batch_size,K是GPU的数量,N是所有正样本和hard negative样本的数量。但是不同任务的数据会互相影响导致模型分辨能力下降,所以为了解决这一限制,引入了一种用于组织训练数据的正则化策略,其中来自同一任务的数据实例被分组为连续的小批量,该策略使大多数批内负样本来自同一数据集(即同质负样本),从而增强嵌入对每个特定任务的判别能力
- 与一般的对比学习差不多,但为了提高embedding在不同应用场景中的辨别能力在对比学习框架中采用了几个关键设计:
-
知识蒸馏
-
使用KL散度来最小化使用LLM奖励计算的候选分布与嵌入模型预测的候选分布之间的差距。对于每个query q q q都有一个候选列表 P : [ p 1 , ⋯ , p N ] \mathcal P:[p_1,\cdots,p_N] P:[p1,⋯,pN],然后通过公式(1)获得大模型对候选的奖励,表示为 R : [ r 1 , ⋯ , r N ] R:[r_1,\cdots,r_N] R:[r1,⋯,rN],为了使得大模型的rewards适合蒸馏,将每个reward转化为标准化的权重: w i ← s o f t m a x R ( r i / α ) w_i\gets softmax_R(r_i/\alpha) wi←softmaxR(ri/α),其中 α \alpha α表示温度系数
-
简单理解就是rewards越大( w i w_i wi越大)越好,query和正样本的相似度越大越好( e x p ( ⟨ e q , e p ⟩ ) / τ exp(\big\langle e_q, e_p \rangle\big)/\tau exp(⟨eq,ep⟩)/τ越大),query和负样本的相似度越小越好( ∑ p ′ ∈ P e x p ( ⟨ e q , e p ′ ⟩ ) / τ \sum_{p\prime \in \mathcal P} exp(\big\langle e_q, e_p\prime \rangle\big)/\tau ∑p′∈Pexp(⟨eq,ep′⟩)/τ越小)
-
由于来自不同任务的不同训练样本,LLM的奖励幅度可能表现出高度波动,导致训练效果不好
-
为了解决多任务场景下reward的波动问题,提出Stabilized Distillation
- 基于LLM的rewards R : [ r 1 , ⋯ , r N ] R:[r_1,\cdots,r_N] R:[r1,⋯,rN],我们将候选从高到低排序,这样就生成了一个新的候选集,定义为 P : [ p 1 , ⋯ , p N ] \mathbb P:[p_1,\cdots,p_N] P:[p1,⋯,pN],其中 r i ≥ r i + 1 r_i\ge r_{i+1} ri≥ri+1。在上面的式子中 P \mathbb P P由两部分组成:排名比 p i p_i pi低的候选 [ p i + 1 , ⋯ , p N ] [p_{i+1},\cdots,p_N] [pi+1,⋯,pN]以及in-batch negative samples
- 这个调整过的公式从两方面来稳定波动的rewards:一方面,该模型经过持续的训练以促进 p i p_i pi 与排名较低的同一个候选集的item [ p i + 1 , ⋯ , p N ] [p_{i+1},\cdots,p_N] [pi+1,⋯,pN]进行比较, 这意味着,无论rewards的绝对价值如何,模型都能够从LLM的偏好中学习;另一方面,当排名第一的候选比其他候选获得明显更高的reward时,权重将变成one-hot,在这种情况下,提取过程将简化为对比学习的形式,排名第一的候选将被视为正样本。
- 简单理解就是:一方面我们拿到的负样本中的 [ p i + 1 , ⋯ , p N ] [p_{i+1},\cdots,p_N] [pi+1,⋯,pN]部分都是在LLM给出的reward比正样本低的,这样避免了出现负样本reward比正样本要高的情况,减少了波动;另一方面当排名第一的候选比其他候选获得明显更高的reward时,式子就变成了:
m i n − l o g e x p ( ⟨ e q , e i ⟩ ) / τ ∑ p ′ ∈ P e x p ( ⟨ e q , e p ′ ⟩ ) / τ min -log \frac{exp(\big\langle e_q, e_i \rangle\big)/\tau}{\sum_{p\prime \in \mathbb P} exp(\big\langle e_q, e_p\prime \rangle\big)/\tau} min−log∑p′∈Pexp(⟨eq,ep′⟩)/τexp(⟨eq,ei⟩)/τ
-
8. LLMs的检索增强
-
Knowledge Enhancement:将知识语料库里面的文档进行编码并存入向量数据库中,在许多情况下对于用户提出的问题可以直接查用于查询向量数据库,在其他情况下生成过程中的上下文可以用作查询,然后在大模型里用[knowledge, query] → answer方式得到答案
-
Long-Context Modeling:当处理长上下文时,可以对整个历史进行分块、编码,并将其加载到向量数据库中,生成过程中的上下文可用于查询向量数据库中的相关chunk。在很多情况下查询到的相关chunk比如chunk_i以及其后面的chunk_i+1都会被用来增强记忆,因为后续的chunk对生成下文来说可能更为关键。[retrieved chunks, current context] → new generation.
-
In-context Learning(上下文学习):演示示例以“((task instruction, expected output)”的形式组织,可以在向量数据库中进行编码和预存。当给出一个新任务时,该任务的指令(instruction)用于查询向量数据库,检索到的示例与任务的指令相连接,在此基础上可以进行上下文学习。[retrieved examples, instruction] → response.
In-context Learning的示例:
- Few shot(示例出现多个)):6+7=13,6+6=12,5+5=10,8+9=?
- One shot(示例出现一个)): 5+5=10,8+9=?
- Zero shot(示例没有出现)): 8+9=?
-
Tool Learning:该工具的功能可以用语言描述,并与其API配对:“(description,API)”,这样向量数据库就可以根据被编码的description来管理一个庞大的工具包,考虑到涉及工具使用的用户请求,可以对该用户请求进行编码并用于查询向量DB。[user request, tool’s execution result] → generation
9. 论文中四个关键技术的工程实现
- Reward from LLM
- 通过给case选择正负样本实现,因为正负样本都通过计算LLMs的输出logits和label的交叉熵给出了分数,所以根据分数选择更好的正负样本就实现了Reward from LLM
- Instruction-based Fine-Tuning
- 通过给query和正负样本添加instruction实现
- Homogeneous In-Batch Negative Sampling
- 记录每种task数据的index范围,然后只在每种task的index范围内进行shuffle,然后在训练的时候将相同task的数据分到一个batch里面
- Stabilized Distillatio
- 跟据teacher_scores(即LLM给样本的打分)对负样本进行排序,选择分数较低的一部分样本作为负样本
论文链接
项目的github地址
相关文章:

LLM-Embedder
1. 目标 训出一个统一的embedding模型LLM-Embedder,旨在全面支持LLM在各种场景中的检索增强 2. 模型的四个关键检索能力 knowledge:解决knowledge-intensive任务memory:解决long-context modelingexample:解决in-context learn…...

xsync 集群远程同步脚本
xsync 集群分发 脚本 (1)需求:循环复制文件到所有节点的相同目录下 (2)需求分析: (a)rsync 命令原始拷贝: rsync -av /opt/module roothadoop103:/opt/(b&am…...

30秒get视频号视频如何下载,保存视频号视频到本地方法!
终于可以告别无法下载视频号视频的烦恼啦!下面是一些只需 30 秒就能get到的t视频号视频如何下载方法,让我们一起来探索如何保存视频号视频到本地方法吧! 首先,要记得这些方法仅适用于个人观看或学习使用,不可用于商业用…...
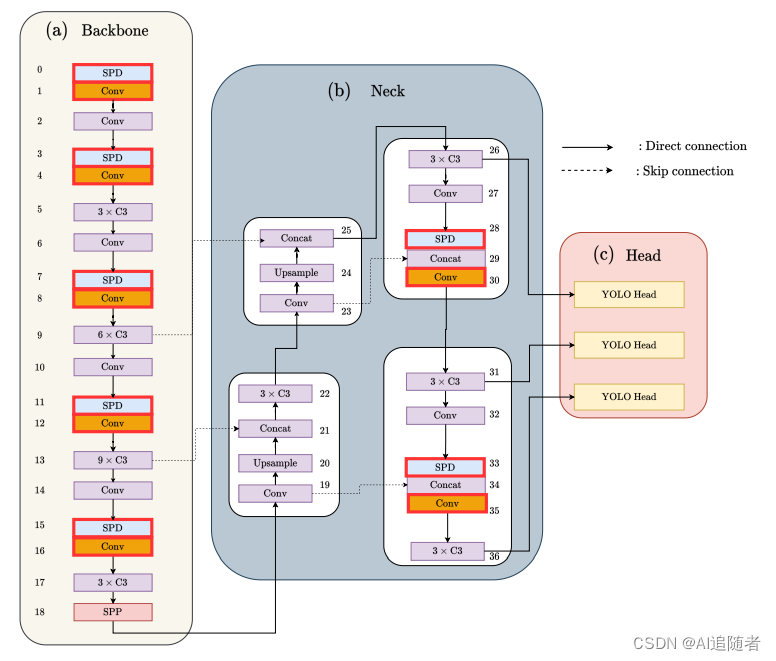
优化改进YOLOv5算法:加入SPD-Conv模块,让小目标无处遁形——(超详细)
1 SPD-Conv模块 论文:https://arxiv.org/pdf/2208.03641v1.pdf 摘要:卷积神经网络(CNNs)在计算即使觉任务中如图像分类和目标检测等取得了显著的成功。然而,当图像分辨率较低或物体较小时,它们的性能会灾难性下降。这是由于现有CNN常见的设计体系结构中有缺陷,即使用卷积…...

【数据结构】搜索树 与 Java集合框架中的Set,Map
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《JAVA数据结构》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力…...

掌握组件缓存:解开Vue.js中<keep-alive>的奥秘
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

Ajax学习笔记第5天
无论做什么,都请记得那是为自己而做,那就毫无怨言! 【1. 跨域】 1.什么是跨域 跨域是指浏览器不能执行其他网站的脚本。它是浏览器同源策略造成的,是浏览器对JS实施的安全限制。 2.常见的跨域场景 3.什么事同源策略 ÿ…...

20.1 OpenSSL 字符BASE64压缩算法
OpenSSL 是一种开源的加密库,提供了一组用于加密和解密数据、验证数字证书以及实现各种安全协议的函数和工具。它可以用于创建和管理公钥和私钥、数字证书和其他安全凭据,还支持SSL/TLS、SSH、S/MIME、PKCS等常见的加密协议和标准。 OpenSSL 的功能非常…...

Panda3d 教程
Panda3d 教程 偶然之余看到了 Panda3d 这个3D引擎,觉得代码开源然后又比较轻量级,感觉还是比较好上手的,因此就想去学习一下,然后把学习过程记录下来。 网上也都找了不少关于Panda3d 方面的教程,但是感觉都不是很好&a…...
除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂…...

干洗店小程序上门洗鞋店管理软件功能介绍;
干洗店小程序上门洗鞋店管理软件功能介绍; 营销工具-洗鞋店管理软件多渠道玩法,拓客留客 支付-会员管理系统多种支付方式,灵活经营 提供洗鞋店管理软件服务,实现会员精细化运营 会员档案-洗鞋店管理软件记录会员的全方位信…...
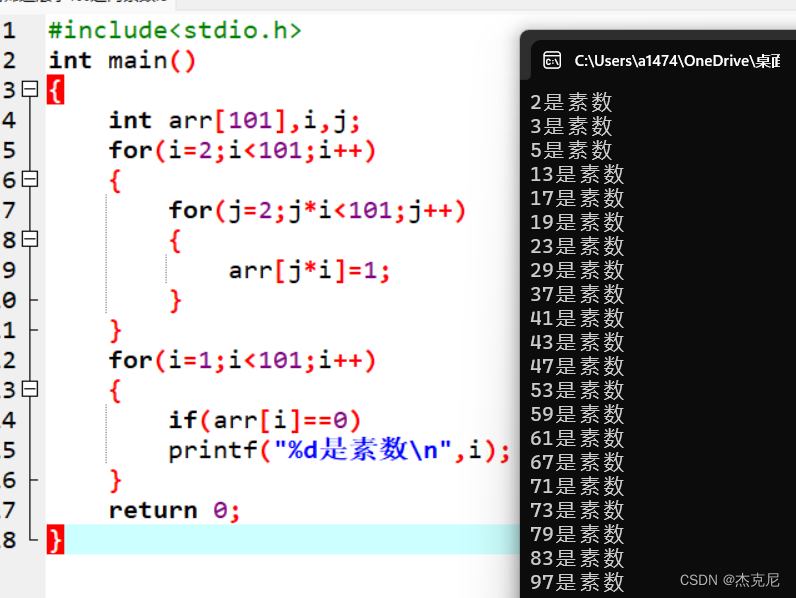
【C语言初学者周冲刺计划】1.1用筛选法求100之内的素数
目录 1解题思路: 2代码如下: 3运行代码如图所示: 4总结: (前言周冲刺计划:周一一个习题实操,依次类推加一,望各位读者可以独自实践敲代码) 1解题思路: 首先了解筛选法定义:先把…...

1.Vue—简介、实例与容器、MVVM模型
文章目录 一、Vue简介1.1 特点1.2 搭建Vue开发环境1.2.1 开发版1.2.2 生产版 1.3 下载Vue开发工具1.3.1 GitHub方式1.3.2 国内方式 1.4 消除环境提示 二、 入门程序2.1 HelloWord2.2 分析Hello案例2.3.1 多容器对一实例2.3.2 多实例对应一容器2.3.3 总结 三、MVVM模型 一、Vue简…...
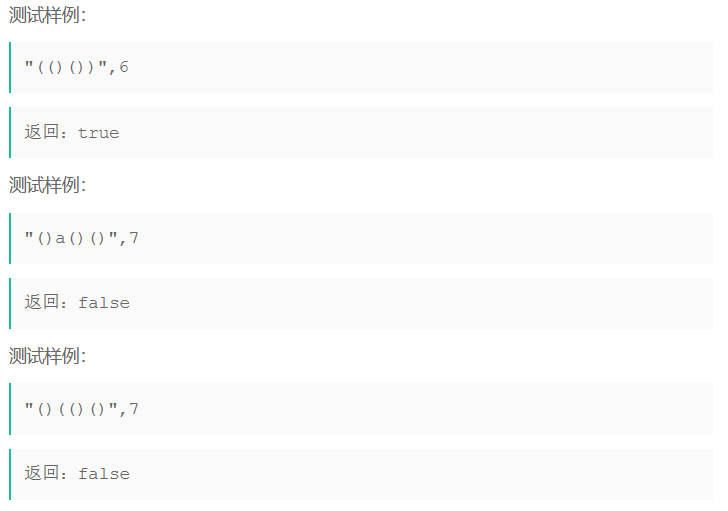
【Java笔试强训】Day7(WY22 Fibonacci数列、CM46 合法括号序列判断)
Fibonacci数列 链接:Fibonacci数列 题目: Fibonacci数列是这样定义的: F[0] 0 F[1] 1 for each i ≥ 2: F[i] F[i-1] F[i-2] 因此,Fibonacci数列就形如:0, 1, 1, 2, 3, 5, 8, 13, …,在Fibonacci数列…...

Linux进程的概念
一:冯诺依曼体系结构 什么叫做体系结构??? 计算机组成 / 芯片架构 输入单元:键盘、话筒、摄像头、usb、鼠标、磁盘(ROM)/ssd、网卡、显卡 存储器:内存(RAM)…...
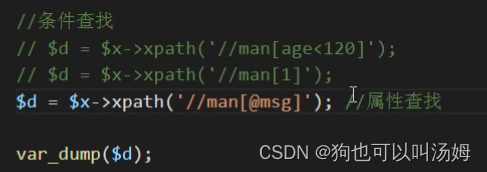
XML教学视频(黑马程序员精讲 XML 知识!)笔记
第一章XML概述 1.1认识XML XML数据格式: 不是html但又和html有点相似 XML数据格式最主要的功能就是数据传输(一个服务器到另一个服务器,一个网站到另一个网站)配置文件、储存数据当做小型数据可使用、规范数据格式让数据具有结…...

自定义组件实现v-model
要使自定义的Vue组件支持v-model,需要实现一个名为value的prop和一个名为input的事件。在组件内部,将value prop 绑定到组件的内部状态,然后在对内部状态进行修改时触发input事件。 自定义UI组件 <template><input :value"va…...

【自动驾驶】Free space与Ray casting
文章目录 1 Free space是什么2 Ray casting是什么3 它俩啥关系4 TODO 1 Free space是什么 在自动驾驶领域,free space即可行驶区域,在结构化道路的十字路口/非结构化道路都有很大作用。 2 Ray casting是什么 ray casting是计算机视觉领域,…...

RHCE---正则表达式
文章目录 目录 文章目录 前言 一. 文本搜索工具 二.正则表达式 元字符 ^行首与$行尾 点(.) 与星号(*) 扩展正则 总结 前言 正则表达式是文本三剑客中及其重要的一环,称之为灵魂也不为过,到底什么是正则表达式呢,让我们一起来了解以下…...
3D RPG Course | Core 学习日记一:初识URP
前言 最近开始学习Unity中文课堂M_Studio(麦大)的3D RPG Course,学习一下3D RPG游戏核心功能的实现,第一课我们学习到的是地图场景的编辑,其中涉及到了URP渲染。 我们首先进入Unity资源商店把地图素材和人物素材导入好…...

六边形地理索引的终极指南:H3算法如何革新空间数据分析
六边形地理索引的终极指南:H3算法如何革新空间数据分析 【免费下载链接】h3 Hexagonal hierarchical geospatial indexing system 项目地址: https://gitcode.com/gh_mirrors/h3/h3 你是否曾为处理大规模地理空间数据而头疼?传统的地理索引系统在…...
)
Qt实战:用QTreeWidget打造班级管理系统(含右键菜单完整源码)
Qt实战:用QTreeWidget构建高交互班级管理系统 在Qt框架中,QTreeWidget作为展示层级数据的利器,特别适合教育管理系统的开发需求。不同于简单的列表控件,树形结构能直观呈现班级、年级、学生等多级关系,配合右键菜单可实…...

革命性AI身份系统:Second Me如何重新定义数字分身技术
革命性AI身份系统:Second Me如何重新定义数字分身技术 【免费下载链接】Second-Me 开源 AI 身份系统,通过本地训练和部署,模仿用户思维和学习风格,创建专属AI替身,保护隐私安全。 项目地址: https://gitcode.com/gh_…...
GeoSeg终极指南:基于Transformer的遥感图像语义分割实战教程
GeoSeg终极指南:基于Transformer的遥感图像语义分割实战教程 【免费下载链接】GeoSeg UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery, ISPRS. Also, including other vision transformers and C…...

IntelliJ IDEA终极教程:从零基础到高效开发的完整指南
IntelliJ IDEA终极教程:从零基础到高效开发的完整指南 【免费下载链接】IntelliJ-IDEA-Tutorial IntelliJ IDEA 简体中文专题教程 项目地址: https://gitcode.com/gh_mirrors/in/IntelliJ-IDEA-Tutorial IntelliJ IDEA 是目前所有 IDE 中最具备沉浸式的 JVM …...
:无锁队列与并发控制的设计与实现3(源码解析))
Iceoryx(冰羚):无锁队列与并发控制的设计与实现3(源码解析)
接上篇设计4: 索引管理层( MpmcIndexQueue / CyclicIndex)Subscriber存储数据使用的是queue,是为了保证数据的读取顺序。MpmcLockFreeQueue 为了满足多个进程同时写的情况,采用了索引数据分离的方案(底层的索引实现为 …...

MBPFan:解决MacBook Linux系统散热难题的智能温控工具
MBPFan:解决MacBook Linux系统散热难题的智能温控工具 【免费下载链接】mbpfan 项目地址: https://gitcode.com/gh_mirrors/mb/mbpfan 当你在Linux系统下使用MacBook处理文档、编写代码或观看视频时,是否遇到过设备突然发烫、风扇噪音忽大忽小的…...

嵌入式C语言变量初始化技术详解
## 1. 嵌入式C语言变量初始化技术详解### 1.1 初始化的重要性与基本原则在嵌入式系统开发中,变量初始化是防止未定义行为的关键步骤。由于嵌入式编译器特性的差异,未初始化的变量可能包含随机值,导致系统出现不可预测的行为。根据变量类型的不…...

Sodaq_RN2483库详解:LoRaWAN Class A终端嵌入式实现
1. Sodaq_RN2483库深度解析:面向Class A LoRaWAN终端的嵌入式通信实现 1.1 库定位与工程价值 Sodaq_RN2483是一个专为Microchip RN2483 LoRaWAN模块设计的Arduino兼容C库,其核心目标是为资源受限的嵌入式系统提供稳定、可复用、符合LoRaWAN协议规范的无…...

RWKV7-1.5B-g1a镜像部署教程:CSDN平台一键拉起Web服务,7860端口直连体验
RWKV7-1.5B-g1a镜像部署教程:CSDN平台一键拉起Web服务,7860端口直连体验 1. 模型简介 rwkv7-1.5B-g1a 是基于新一代 RWKV-7 架构的多语言文本生成模型,特别适合中文场景下的轻量级应用。这个1.5B参数的版本在保持较高生成质量的同时&#x…...