python sqlalchemy(ORM)- 03 增删改查
本节所有案例基于(第一节 python sqlalchemy(ORM)- 01 ORM简单使用)中的User、Address两个模型类
ORM更新数据
- 查询到模型类对象,直接修改其属性值,即可更新;
- 查看更新的实例 session.dirty ;
- 查看新添加的实例对象–> session.new;
- 新添加的对象在session 中,user_obj in session ->True
- 只有提交事务session.commit(),更新、添加才会同步到数据库中。
- 回滚事务session.rollback(),则所有的修改、添加 会恢复到之前的状态;
ORM查询
- 查询所有的字段,获取 Query 对象
from sqlalchemy.orm.query import Query
from sqlalchemy import text# 查询User的所有字段,并按照id升序排序
query_obj = session.query(User).order_by(text("id asc"))# 获取query对象中的数据
# 1. 遍历 获取每一个(记录)对象
# 2. query_obj.first()/.all()/.one()/.one_or_none() 获取对象#
- 查询局部字段,返回Query对象
# 查询name, fullname字段
query_obj = session.query(User.name, User.fullname)
# 对于query_obj 可遍历、也可直接调用获取数据对象的方法
# 结果[('tom', '李四'), ('jack', '张三')]# 查询User所有字段 + name字段
query_obj = session.query(User, User.name).all()
# 元组列表 [(tom, 'tom'), (jack, 'jack')]
# 元组第一个元素为User对象,第二个为name值# 为字段指定别名 相当于select name as user_name from user_t;
query_obj = session.query(User.name.label("user_name")).all()# 为模型类 指定别名
from sqlalchemy.orm import aliased
user_alias = aliased(User, name="user_alias")# 根据别名查询
query_obj = session.query(user_alias).all()
- 排序、分页
- 结果分片,实现分页;
- offset().limit() 实现分页
# 查询User的所有字段的数据,按照id降序排序,并分页获取第一条
result = session.query(User).order_by(-User.id)[:1] # 分片 分页
# 按照id升序排序,并分页获取第二条数据
result2 = session.query(User).order_by(User.id).offset(1).limit(1).all()
- 过滤查询
- filter 复杂过滤,条件如User.id > 3 or text(“id > 3”)
- filter_by 简单的等值过滤;
# 等值过滤
session.query(User.name).filter_by(fullname="Ed Jones")
# 复杂过滤
session.query(User.name).filter(User.fullname == "Ed Jones")
# 链式过滤
session.query(User).filter(User.name == "ed").filter(User.fullname == "Ed Jones")
- 过滤操作符
- _eq_() 等值匹配
- _ne_() 不等
- like 模糊匹配 (区分大小写) % 多个字符的通配符
- ilike 不区分大小写
- in_([]) 范围匹配
- not_in([]) 不在该范围,相当于 ~ xx.in_
- is_() 是None
- is_not() 不是None
- and_(条件1,条件2,…) 多个条件的与
- or_(条件1,条件2,…) 多个条件的或
- ~ 条件的取反
- match() 包含xxx sqlite数据库不支持
# __eq__()
user = session.query(User).filter(User.id==1).one()
# 等价于
user = session.query(User).filter(User.id.__eq__(1)).one()
# __ne__ 类似的用法# like 模糊查询(区分大小写) % 多个字符通配符 ilike 不分大小写
user_list = session.query(User).filter(User.name.like("lau%")).all()# in_() 列表范围查询/query对象 not_in()
query.filter(User.name.in_(["ed", "wendy", "jack"])).all()
# 嵌套查询
query.filter(User.name.in_(session.query(User.name).filter(User.name.like("%ed%"))))# use tuple_() for 复合查询, 多列一起 in_()
from sqlalchemy import tuple_
query.filter(tuple_(User.name, User.nickname).in_([("ed", "edsnickname"), ("wendy", "windy")])).all()# is_() is_not()
query.filter(User.name == None)
# 等价于
query.filter(User.name.is_(None))# use and_() 多个条件与
from sqlalchemy import and_
query.filter(and_(User.name == 'ed', User.fullname == 'Ed Jones'))
# 等价于
query.filter(User.name == 'ed', User.fullname == 'Ed Jones')
# 链式
query.filter(User.name == 'ed').filter(User.fullname == 'Ed Jones')# 多个条件或
from sqlalchemy import or_
query.filter(or_(User.name == 'ed', User.name == 'wendy'))
- 使用文本sql 过滤、排序等。
from sqlalchemy import text# 查询出 id < 3 的所有数据,并按照id 升序排序
session.query(User).filter(User.id<3).order_by(User.id).all()
# text sql
session.query(User).filter(text("id<3")).order_by(text("id asc")).all()# 参数化的文本sql
# 查询id > 3 且 name like lau% 的所有数据
session.query(User).filter(text("id<:id and name ilike :name")).params(
id=3, name="lau%").order_by(-User.id).all()# 完整的text sql -> from_statement() 后面不能再跟条件
session.query(User).from_statement(text("SELECT * FROM users where name=:name")).params(name="ed").all()
# text sql 指定字段
stmt = text("SELECT name, id, fullname, nickname FROM users where name=:name")
stmt = stmt.columns(User.name, User.id, User.fullname, User.nickname)
session.query(User).from_statement(stmt).params(name="ed").all()
6. 聚合查询
# 统计查询的条数 query.count()
session.query(User).filter(User.name.like("%ed")).count()# 聚合函数
from sqlalchemy import func# 分组查询,label指定别名
r = session.query(func.count(User.sex).label("num"), User.sex.label("user_sex")).group_by(User.sex).all()# 统计行数
session.query(func.count("*")).select_from(User).scalar() # scalar() 获取第一行的第一列的值- 更多查询参考
ORM删除操作
pass
处理关系对象
- 当创建一个User对象时,它的addresses 关系属性(非表字段)是一个空列表;当然也可以配置为集合、或者字典等,方法参考 。
- 当添加User对象(主表记录)时,addresses列表中的Address对象会自动添加(子表记录自动添加)。
- 操作案例
# 创建User对象
jack = User(name="jack", fullname="Jack Bean", sex="male")
jack.addresses
# []# 添加地址
jack.addresses.append(Address(email_address="北京天安门"))
jack.addresses.append(Address(email_address="山东济南"))
# 一旦添加一个地址对象,用户、地址对象就建立双向关系
address0 = jack.addresses[0]
address0.user # 可以获取 jack 用户对象# 只需将jack对象,添加到数据库中,地址自动添加
session.add(jack)
session.commit()
- 当查询用户对象时,仅仅返回一个用户对象,并不处理addresses关系的查询,当用户对象调用addresses属性时,突然就触发地址对象的sql查询。
多表的关联查询
- 字段的等值多虑 ;
result = session.query(User, Address).filter(User.id == Address.user_id) # 字段等值过滤 连接.all()# [(jack, 北京), (jack, 河南), (tom, 武汉)]
# 对应sql
SELECT user_t.id AS u_id,user_t.name AS u_name,user_t.sex AS u_sex,address_t.id AS addr_id,address_t.email_address AS addr_email_address,address_t.user_id AS addr_user_id
FROM user_t, address_t
WHERE user_t.id = address_t.user_idAND address.email_address = ?
- query.join() 关系连接
# 有一个外键的情况下
session.query(User) # 仅查询User中的数据.join(Address) # 自动根据外键连接.filter(Address.email_address == "北京").all()
# [jack]
session.query(User, Address) # 仅查询User中的数据.join(Address) # 自动根据外键连接.filter(Address.email_address == "北京").all()
# [(jack, 北京)]# 有多个外键或者无外键, 使用关系连接
result = session.query(User, Address) # 查询两张表,返回Query对象.join(User.addresses) # 通过User.addresses 关系 连接两张表.filter(Address.email_address.match("北京")) # query对象过滤 包含‘北京’.all() # 获取所有的数据
# [(jack, 北京)] 两个对象的元组 列表- 关系连接,同时指定条件
r = session.query(User, Address).join(User.addresses.and_(~Address.title.match("北京"))) # 指定关系连接,同时指定过滤条件,地址不包含‘北京’.all()# [(jack, 河南), (tom, 武汉)]
- 查询的多个表中,默认从左到右依次连接,若要指定连接的第一个表,可以使用query.select_from(xxx)
query = session.query(User, Address) # 查询多个表.select_from(Address) # Address作为起始表 开始连接.join(Address.user) # 关系连接.filter(User.name.match("jack")) # 条件过滤.all()
# [(jack, 北京), (jack, 河南)]# 左外连接
result = session.query(User, Address).outerjoin(User.addresses) # 左连接 以左边表的所有记录为主,可多 不可少.all()# [(jack, 北京), (jack, 河南), (tom, 武汉), (lauf, None), (LAUF, None), (laufing, None)]- 连接指定的表
from sqlalchemy.orm import aliasedadd1 = aliased(Address, name="add1")
add2 = aliased(Address, name="add2")result = session.query(User, add1)
.join(add1, User.addresses) # 连接add1 相当于 join(User.addresses.of_type(add1))
.join(add2, User.addresses) # 连接add2
.all()
相关文章:
- 03 增删改查)
python sqlalchemy(ORM)- 03 增删改查
文章目录 ORM更新数据ORM查询ORM删除操作处理关系对象多表的关联查询 本节所有案例基于(第一节 python sqlalchemy(ORM)- 01 ORM简单使用)中的User、Address两个模型类 ORM更新数据 查询到模型类对象,直接修改其属性…...

Flutter笔记:完全基于Flutter绘图技术绘制一个精美的Dash图标(上)
Flutter笔记 完全基于Flutter绘图技术绘制一个精美的Dart语言吉祥物Dash(上) 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://…...

学习gorm:彻底弄懂Find、Take、First和Last函数的区别
在gorm中,要想从数据库中查找数据有多种方法,可以通过Find、Take和First来查找。但它们之间又有一些不同。本文就详细介绍下他们之间的不同。 一、准备工作 首先我们有一个m_tests表,其中id字段是自增的主键,同时该表里有3条数据…...
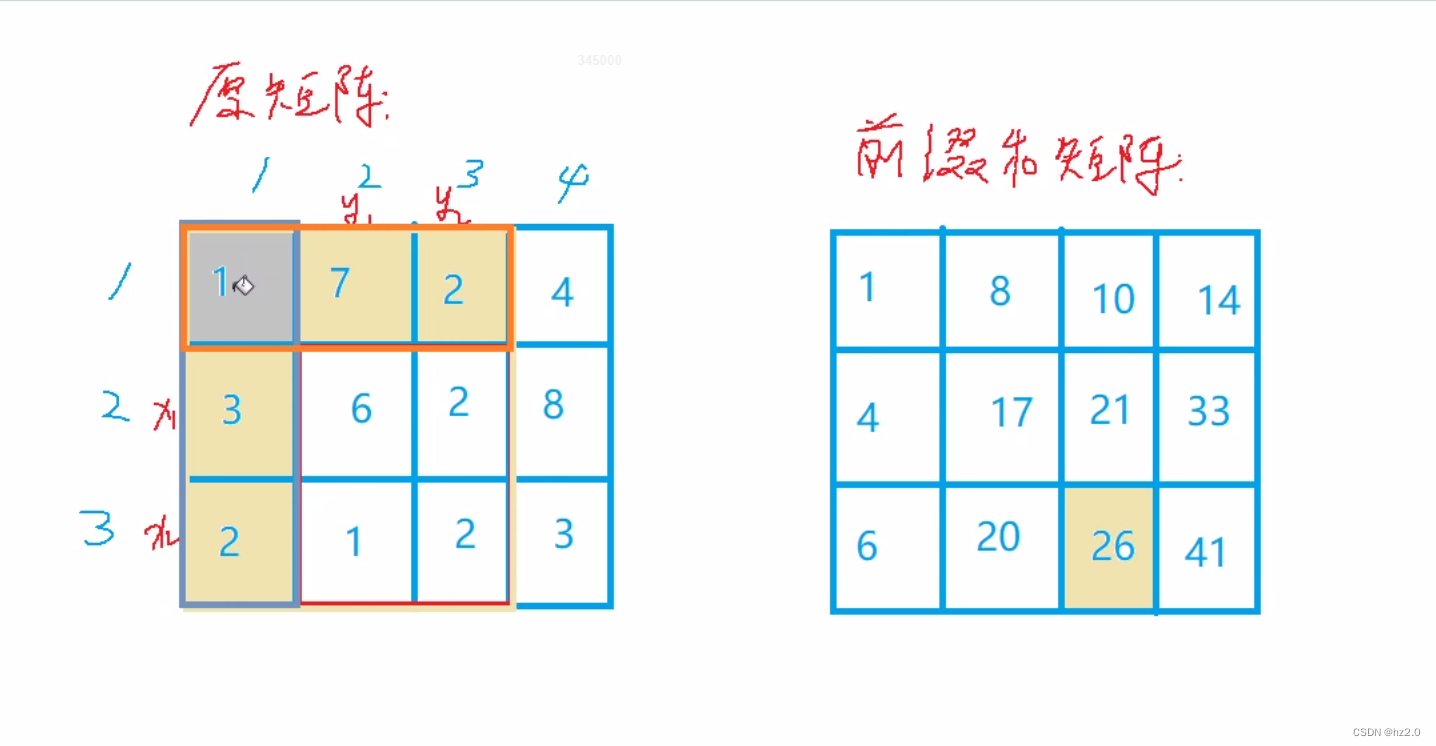
796. 子矩阵的和(二维前缀和)
题目: 796. 子矩阵的和 - AcWing题库 思路: 1.暴力搜索(搜索时间复杂度为O(n2),很多时候会超时) 2. 前缀和(左上角(二维)前缀和):本题特殊在不是直接求前…...
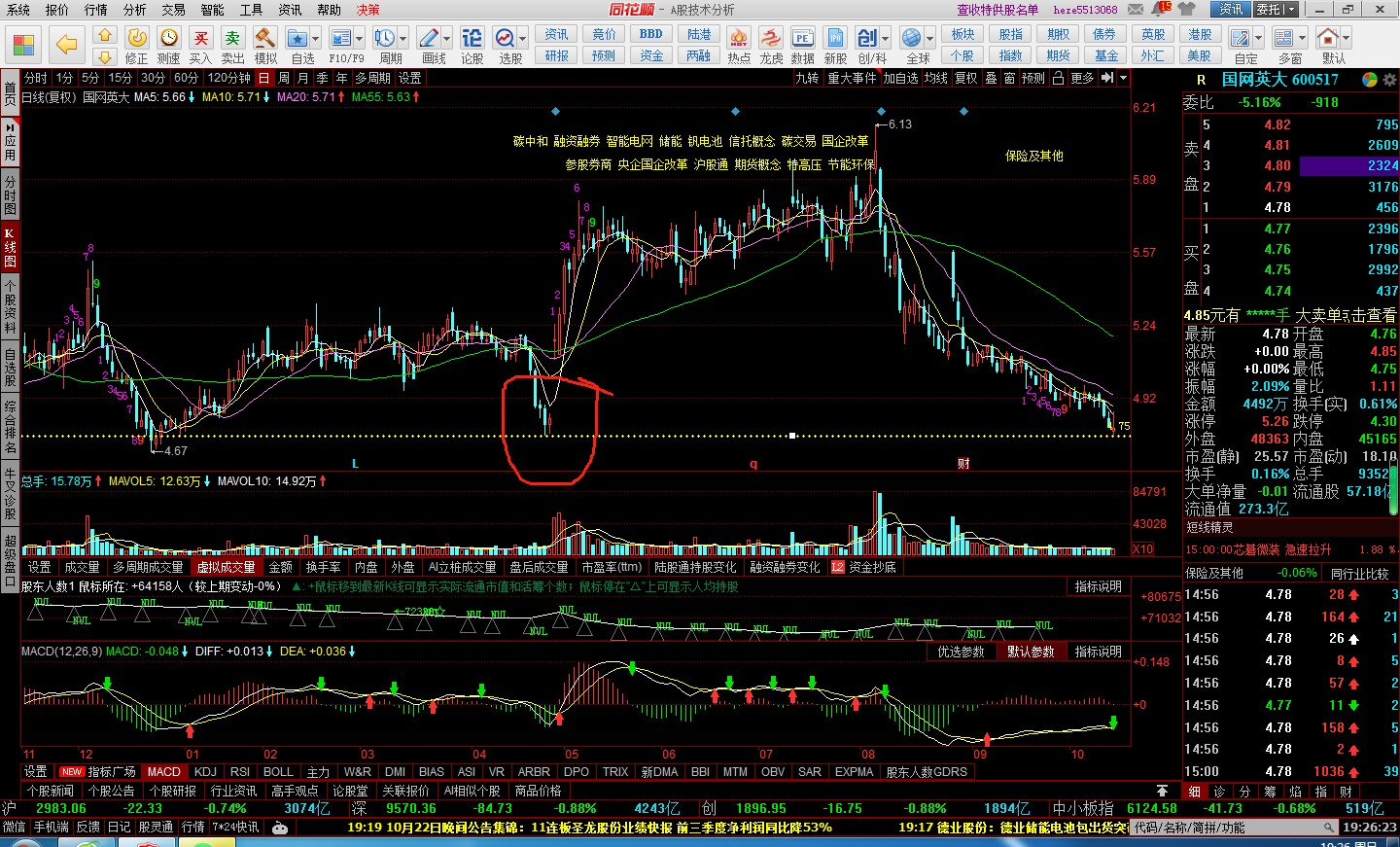
利用ChatGPT进行股票走势分析
文章目录 1. 股票分析2. 技巧分析3. 分析技巧21. 股票分析 这张图片显示了一个股票交易软件的界面。以下是根据图片内容的一些解读: 股票代码: 图片右上角显示的代码是“600517”,这是股票的代码。 图形解读: 该图展示了股票的日K线图。其中,蜡烛图表示每日的开盘、收盘、最…...
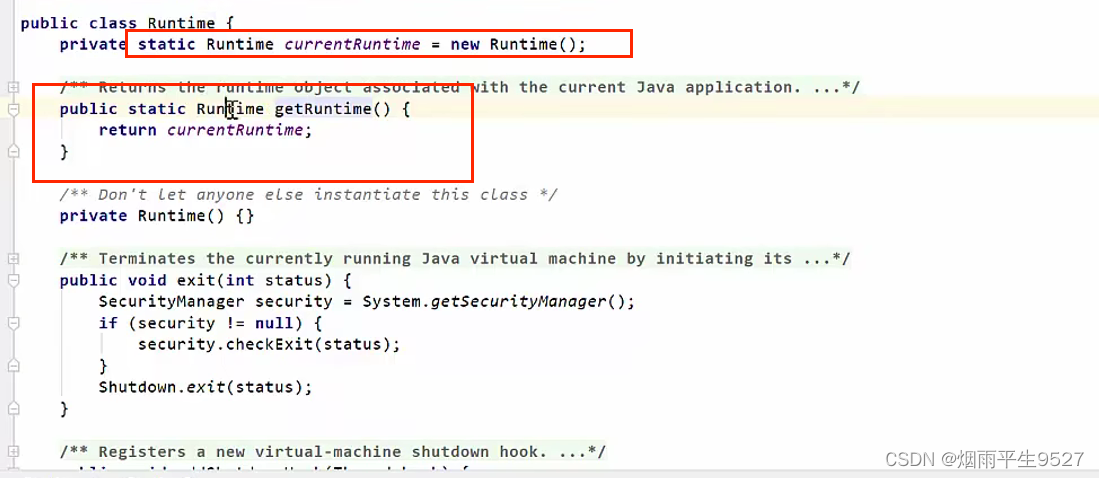
万字解析设计模式之单例模式
一、概述 1.1简介 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保…...

vue2.x 二次封装element ui 中的el-dialog
在做后台管理系统的时候,dialog组件是我们使用频率比较高的组件,但是有一些需求现有的组件是不满足的。因此会需要我们做二次封装。 组件本身的属性我们保留,只需要根据需求添加,然后在使用的时候props去拿取使用就可以了。 本次遇…...

ssh连接Ubuntu虚拟机出现connection reset by ip地址 port 22怎么解决
使用前提:我是用Windows去连接安装在本机的Ubuntu虚拟机的时候出现的这个问题。 解决的方法:我使用了很多网络上方法,都没有用,发现我把IP地址搞错了 请继续看下去,因为有可能你会错过解决的方法。 在Windows网络连…...

树莓派4B安装ffmpeg
环境: piraspberrypi:~/x264 $ lsb_release -aNo LSB modules are available.Distributor ID: RaspbianDescription: Raspbian GNU/Linux 10 (buster)Release: 10Codename: buster 装H264 git clone --depth 1 https://code.videolan.org/video…...
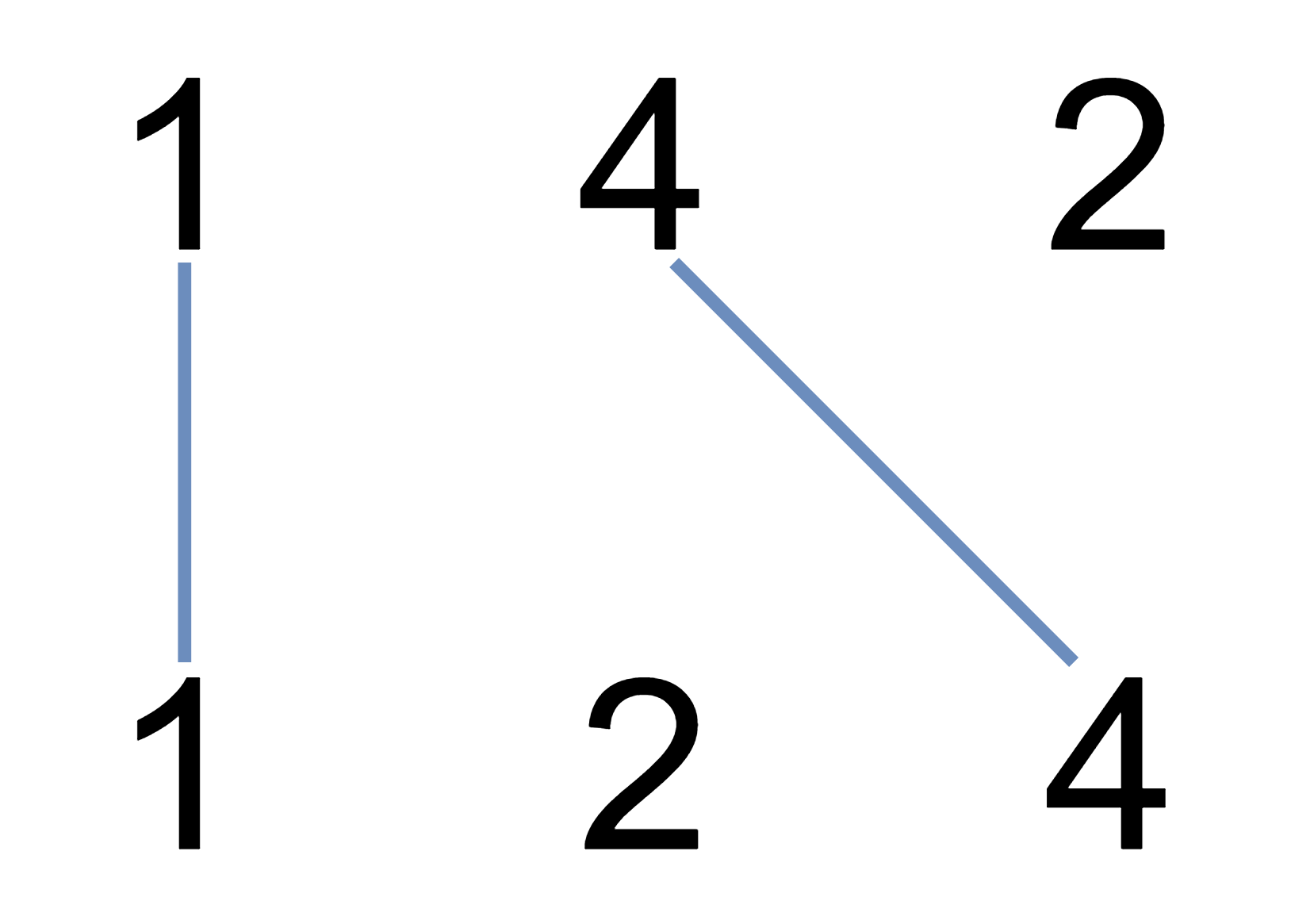
LeetCode|动态规划|1035. 不相交的线 、53. 最大子数组和
目录 一、1035. 不相交的线 1.题目描述 2.解题思路 3.代码实现 二、53. 最大子数组和 1.题目描述 2.解题思路 3.代码实现(动态规划解法) 一、1035. 不相交的线 1.题目描述 在两条独立的水平线上按给定的顺序写下 nums1 和 nums2 中的整数。 现…...
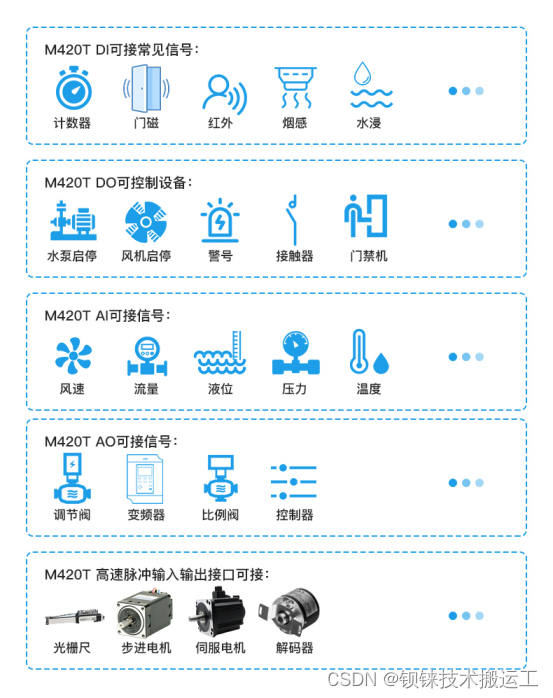
一体式IO模块:汽车行业的数字化转型助推器
随着市场经济需求的不断增长,汽车行业的自动化和智能化已经成为行业发展的必然趋势。在这个背景下,汽车行业的工作流程变得越来越复杂,工业机器人的广泛应用为汽车生产提供了强有力的支持,它们扮演着装配工、操作工、焊接工等多种…...

OpenCV官方教程中文版 —— Hough 直线变换
OpenCV官方教程中文版 —— Hough 直线变换 前言一、原理二、OpenCV 中的霍夫变换三、Probabilistic Hough Transform 前言 目标 • 理解霍夫变换的概念 • 学习如何在一张图片中检测直线 • 学习函数:cv2.HoughLines(),cv2.HoughLinesP() 一、原理…...
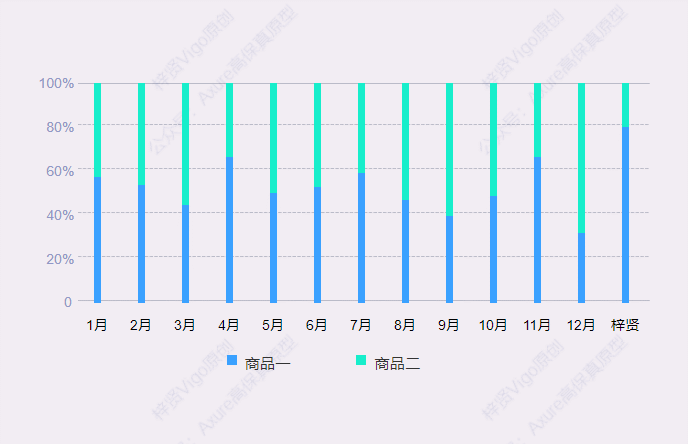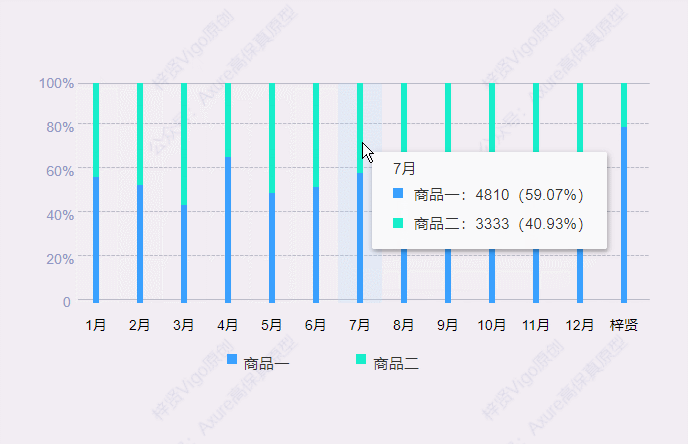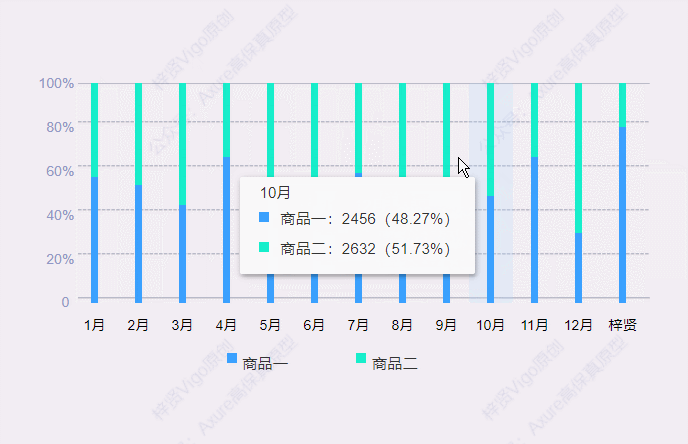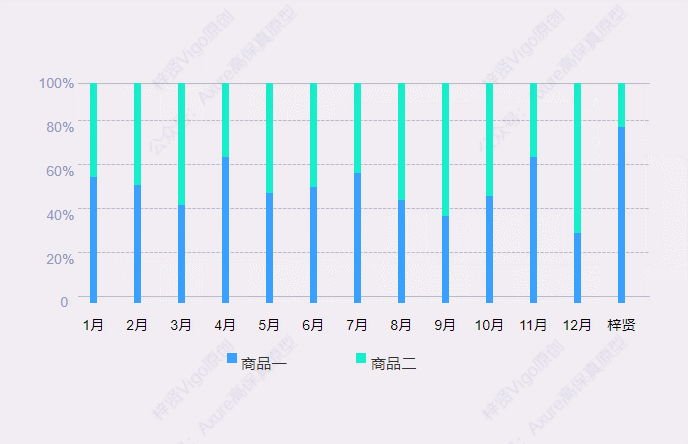
【Axure高保真原型】百分比堆叠柱状图
今天和大家分享百分比堆叠柱状图的的原型模板,鼠标移入堆叠柱状图后,会显示数据弹窗,里面可以查看具体项目对应的数据和占比。那这个原型模板是用中继器制作的,所以使用也很方便,只需要在中继器表格里维护项目数据信息…...

Vue.js中的双向数据绑定(two-way data binding)
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...

TFN 2.5G SDH传输分析仪 FT100-D300S
今天给大家带来一款TFN 2.5G SDH传输分析仪--TFN FT100-D300S. D300S SDH测试模块,是FT100智能网络测试平台产品家族的一部分,是一个坚固耐用、锂电池超长供电的传统PDH/SDH测试解决方案,支持2.5Gbps到2.048Mbps速率的传输链路测试。支持在线…...
电脑录像功能在哪?一文帮你轻松破解
“电脑录像功能在哪里呀?最近因工作上的原因,需要使用电脑来录像,但是找了一上午都找不到在哪里,眼看已经快没时间了,现在真的很急,希望大家帮帮我。” 电脑已经成为了人们生活和工作中必不可少的工具&…...

基于长短期神经网络的可上调容量PUP预测,基于长短期神经网络的可下调容量PDO预测,LSTM可调容量预测
目录 背影 摘要 代码和数据下载:基于长短期神经网络的可上调容量PUP预测,基于长短期神经网络的可下调容量PDO预测,LSTM可调容量预测(代码完整,数据齐全)资源-CSDN文库 https://download.csdn.net/download/abc991835105/88230834 LSTM的基本定义 LSTM实现的步骤 基于长短…...

站群服务器有哪些优势?
站群服务器有哪些优势? 站群服务器是单独为一个网站或者多个网站配置独立IP的一种服务器。企业或是用户如果想组建多个网站的话就需要用站群服务器了。 站群服务器可以提高搜索引擎多个网站的关注度,提高网站文章的收录以及网站文章的访问量。站群服务器有哪些优势…...

故障诊断模型 | Maltab实现LSTM长短期记忆神经网络故障诊断
文章目录 效果一览文章概述模型描述源码设计参考资料效果一览 文章概述 故障诊断模型 | Maltab实现LSTM长短期记忆神经网络故障诊断 模型描述 长短记忆神经网络——通常称作LSTM,是一种特殊的RNN,能够学习长的依赖关系。 他们由Hochreiter&Schmidhuber引入,并被许多人进行了…...

【WSL 2】Windows10 安装 WSL 2,并配合 Windows Terminal 和 VSCode 使用
【WSL 2】Windows10 安装 WSL 2,并配合 Windows Terminal 和 VSCode 使用 1 安装 Windows Terminal2 安装 WSL 23 在 Windows 文件资源管理器中打开 WSL 项目4 在 VSCode 中使用 WSL 24.1 必要准备4.2 从 VSCode 中 Connect WSL4.3 从 Linux 中打开 VSCode 1 安装 W…...

空洞骑士模组管理革命:Scarab如何让复杂变简单?
空洞骑士模组管理革命:Scarab如何让复杂变简单? 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装而头疼吗?每次手动…...

AI 写作一键生成超简单,焦圈儿免费积分福利等你来领
「现在写一篇公众号推文,没三四个小时都下不来。」一位做个人 IP 的朋友跟我抱怨。问题不在于工具太少,而在于门槛太高, 要么你得自己熬夜改稿,要么你得学一堆复杂 Prompt,才能把 AI 伺候好。内容行业正在进入一个悖论…...

SolidWorks插件开发避坑指南:手把手教你搞定工具栏图标和菜单注册表清理
SolidWorks插件开发深度优化:图标管理与注册表清理实战 当你在SolidWorks插件开发中精心设计了功能完备的工具栏,却遭遇图标显示异常、工具栏名称重复或旧插件残留等问题时,那种挫败感每个开发者都深有体会。这些看似简单的界面问题背后&…...

JetBrains IDE试用期重置插件:简单三步恢复30天完整功能
JetBrains IDE试用期重置插件:简单三步恢复30天完整功能 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains IDE试用期到期而烦恼吗?ide-eval-resetter插件是你需要的终极解决…...

Formation:macOS前端开发环境一键配置终极指南
Formation:macOS前端开发环境一键配置终极指南 【免费下载链接】formation 💻 macOS setup script for front-end development 项目地址: https://gitcode.com/gh_mirrors/fo/formation Formation是一款专为macOS设计的前端开发环境配置脚本&…...

从堆叠到双线性:手把手图解注意力机制的‘进化史’与PyTorch实现对比
从堆叠到双线性:手把手图解注意力机制的‘进化史’与PyTorch实现对比 在计算机视觉与自然语言处理的交叉领域,注意力机制早已从最初的简单加权求和发展为具有复杂交互能力的计算范式。本文将带您穿越注意力机制的进化长廊,通过PyTorch实战演示…...

STM32F4/F7上跑AI手写识别:从CUBEMX配置到串口通信的完整避坑指南
STM32F4/F7实战AI手写识别:从模型部署到数据处理的工程化解决方案 在嵌入式设备上部署神经网络进行手写识别,正逐渐从实验室走向工业现场。STM32F4/F7系列凭借其平衡的性能与功耗,成为边缘AI应用的理想选择。本文将深入探讨从模型准备到实际部…...
)
毕设救星:手把手教你用Android Studio和OkHttp3搞定OneNET新版API数据获取(附完整Java代码)
物联网毕设实战:Android Studio对接OneNET新版API全流程解析 在物联网相关专业的毕业设计中,如何快速构建一个能实际运行的设备数据监控APP往往是让本科生头疼的难题。本文将手把手带你完成从零开始的完整开发流程,重点解决三个核心痛点&…...

如何用智能去重工具高效清理重复图片:AntiDupl.NET完整使用指南
如何用智能去重工具高效清理重复图片:AntiDupl.NET完整使用指南 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾面对电脑里杂乱无章的图片库感到束…...

告别通用OCR:如何用PaddleOCR针对银行卡场景做定制化检测模型优化?
告别通用OCR:如何用PaddleOCR针对银行卡场景做定制化检测模型优化? 银行卡识别一直是金融科技领域的高频需求,但通用OCR模型在应对银行卡这类特殊场景时往往力不从心。我曾参与过多个银行的移动端项目,亲眼见证过通用模型在识别卡…...