【推荐系统】推荐算法:冷启动-召回-粗排-精排-重排 解读
【推荐系统】推荐算法:冷启动-召回-粗排-精排-重排 解读
文章目录
- 【推荐系统】推荐算法:冷启动-召回-粗排-精排-重排 解读
- 1. 介绍
- 2. 冷启动
- 2.1 用户冷启动
- 2.1.1 利用用户注册信息冷启动
- 2.1.2 好物推荐冷启动
- 2.1.3 问题启发式冷启动
- 2.1.4 社交冷启动
- 2.1.5 联邦学习冷启动
- 2.1.6 模型冷启动
- 2.17 多域冷启动
- 2.2 Item 冷启动
- 2.2.1 用户粉丝冷启动
- 2.2.2 item基础信息冷启动
- 2.2.3 item相似性冷启动
- 2.2.4 item进退场机制
- 3. 召回
- 3.1 非个性化召回
- 3.2 个性化召回
- 4. 粗排
- 4.1 双塔粗排
- 4.2 交叉粗排
- 5. 精排
- 6. 重排(着重体现在策略上)
- 6.1 调权
- 6.2 强插
- 6.3 过滤
- 6.4 打散
- 6.5 多目标打分融合
- 6.6 模型重排
- 7. 总结
- 参考
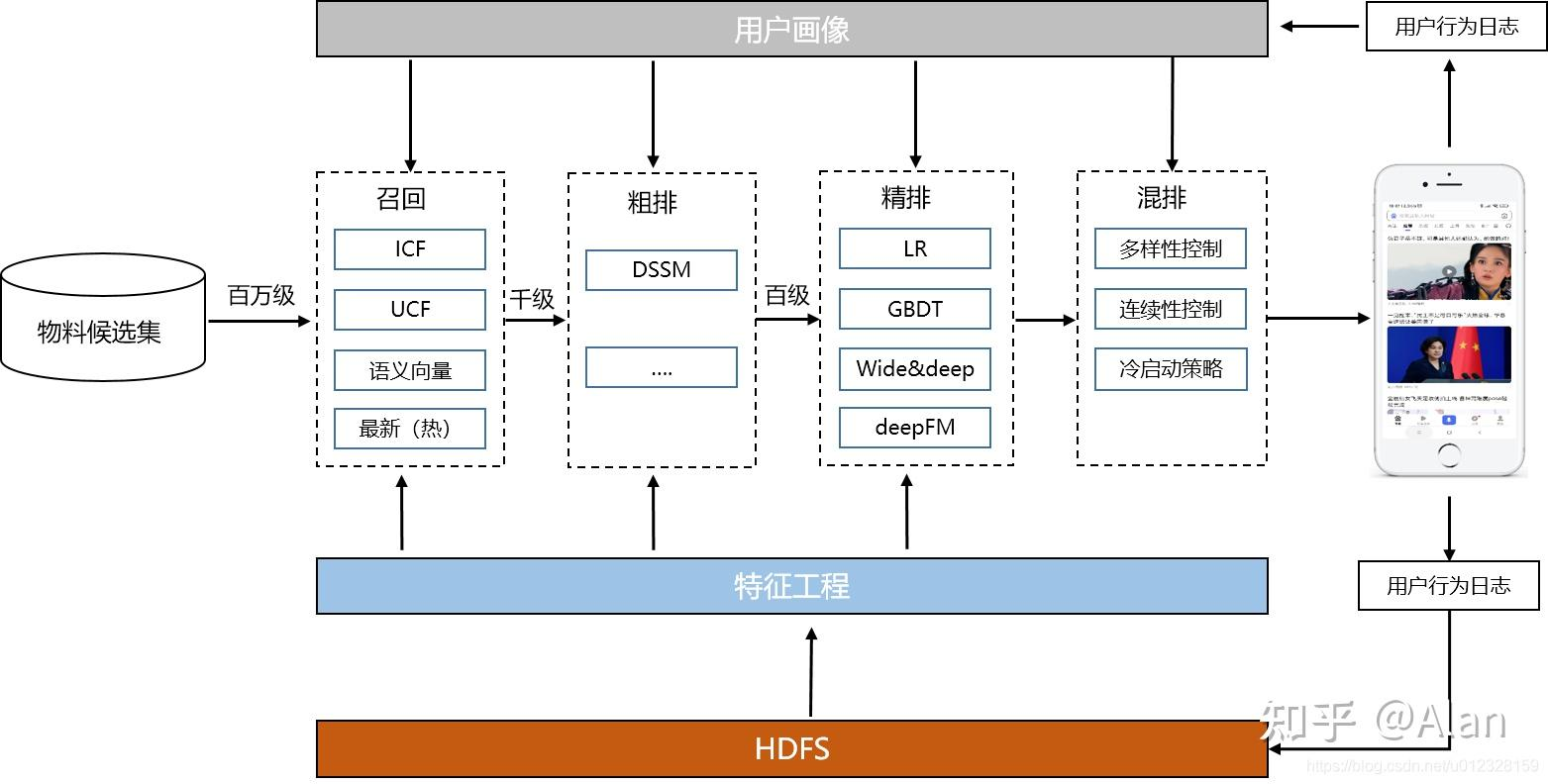
1. 介绍
目前工业界的推荐系统没有办法一次性对所有的候选item(量级上亿)去做预估,因此需要通过不同环节去处理庞大的候选池。每一层都是各司其职,冷启动决定用户初始体验,召回决定天花板,粗排为了性能效率,精排决定最终推荐精度、重排可以提升用户的多样性体验。目前市面上比较成熟的推荐系统分为:冷启动、召回、粗排、精排、重排五个阶段,
- 冷启动 相对而言很多时候是自成体系的,其主要起到的作用有两方面,
- 第一是item冷启动,即让新入库的item得到足够曝光,从而让一些新的高质量item能够迅速蹿起,从而快速下发给用户,满足用户的兴趣和需求。
- 第二是user冷启动,即新来了一个用户,怎么才能迅速找到用户的兴趣点,推送给用户感兴趣的内容,让用户留存下来,增强用户的粘性,从而让新用户转化为忠实用户。
- 召回 的主要作用就是尽可能的从海量的 item 中圈住用户可能感兴趣的item,要知道一般来说当一款产品需要推荐系统存在的时候,其一定是拥有大量的item,例如淘宝,每天的商品肯定是按亿级别来计算的,但是,最后展现给用户的也就不到10条。
- 而这个从亿级别到十级别的工作就是召回-粗排-精排-重排做的事情,整个系统就像一个漏斗由粗到细,同时精度也是从低到高,而召回就是第一步的粗筛,这一步要求并不是追求精准而是追求覆盖度,即不要求精准打击,要求的是炮火覆盖尽可能的把用所有感兴趣的item都覆盖住,而且因为召回针对的是所有的item库,所以,我们对召回还有一个要求就是快,所以,总的看下来召回的主要作用就是从上亿的物料库里面迅速找出上万(也可能是千或者百级别主要看item的规模)用户可能感兴趣的item,要求找出的这些item覆盖了用户大部分的兴趣。
- 粗排 来说就更像是一个中间过渡层,其对精度有一定要求,但是没有精排那么高,此外对于速度而言可以比召回慢一些,但是,也不能太慢至少是强于精排的,属于一个中间过渡层,其存在的目的主要还是因为精排算力吃不下那么多 item (如果能够吃掉就不需要粗排了),所以需要粗排层去过度一下,算是一个精度和速度的折中层。
- 精排 层就一个目的,在算力能够承载的最大限度下选出用户最感兴趣的 item,不要看只有短短的一句话,但是,事实上推荐系统的之前一半的时间都花在它上面,因为它直接决定了推出的item是否能够满足用户的兴趣需求,直接和用户体感和用户转化挂钩。
- 重排 层存在的目的主要有三个,
- 一是满足运营的一些业务需求,如果某些 item 需要被强行推送(如广告产品插入或者紧急新闻推送等)。
- 还有一方面是bias的规则消偏,具体来说就是精排模型不一定是完美的其也有某些学习不足的地方,那么bias消偏就是通过数据分析发现的某些规则去弥补精排的不足,比如,通过数据分析发现喜欢体育的用户从来不会点文艺的 item,但是我们发现精排模型会经常给体育用户推送文艺item,所以,我们可以在重排层把文艺item给过滤了。
- 第三是为了增加用户的多样性体感,我们不能够一直给用户推送某一类item,而是应该适当的给用户推送一些其他类的item,让用户不会产生兴趣疲劳。
- 总的来看重排层的主要作用主要是满足业务需求,弥补精排模型的不足和最大化用户体感。
2. 冷启动
冷启动不同于传统推荐链路(召回-粗排-精排-重排),其是单独的一路,会有专门的流量供给给冷启动链路,让 user 或者 item 进行冷启动进行过渡。工业上来说,
- 对于 item 冷启动,会专门留1-2个坑位或者推荐条数给冷启动的item,比如给用户展示的6个item中可能有1个是来自冷启动的 item 或者给用户发送的15个个性化 item 中,有1-2个是来自冷启动链路的 item。
- 对于user冷启动来说,因为新用户缺少行为数据,所以,不能直接用正常的个性化推荐链路,因为正常的个性化推荐链路,用户画像已经基本成型,其分布和新用户的分布是很不一样的,所以,需要通过其他途径进行用户冷启动。
- 还有一种冷启动是系统冷启动。系统冷启动主要解决如何在一个新开发的网站上(还没有用户,也没有用户行为,只有一些物品的信息)设计个性化推荐系统,从而在网站刚发布时就让用户体验到个性化推荐服务这一问题,这里主要依赖专家的整体设计。
2.1 用户冷启动
2.1.1 利用用户注册信息冷启动
- 用户冷启动最常用的方式是利用用户注册信息,在应用中,当新用户刚注册时,我们不知道他喜欢什么物品,于是只能给他推荐一些热门的商品。但如果我们知道她是一位女性,那么可以给她推荐女性都喜欢的热门商品,这也是一种个性化的推荐。当然这个个性化的粒度很粗,因为所有刚注册的女性看到的都是同样的结果,但相对于不区分男女的方式,这种推荐的精度已经大大提高了。
- 因此,利用用户的注册信息可以很好地解决注册用户的冷启动问题。
- 比较常用的方式就是通过注册信息建立热门倒排拉链进行推荐,比如可以建立一个关于性别的map,结构为{sex:item1->item2->item3->…->itemn},这里item的排序通常是通过点击率进行排序,越是热门的 item 排越前面。
- 同理,可以根据,年龄,职业,兴趣偏好,位置等信息建立倒排拉链进行推荐。
2.1.2 好物推荐冷启动
- 好物推荐冷启动是对于新用户直接展现一些具有代表性的 item(比如喜剧片来一个、武打片来一个等等),然后,通过 user 的点击反馈,迅速掌握 user 的兴趣动向,进行相关推荐。
- 但是要注意,这些具有代表性的 item 的选择一般具有多样性和热门性,因为只有多样性的 item 才能探索出 user 真正的兴趣,比如,对于网易云音乐的新用户来说,你给他狂推rap类和古风的音乐,他一个都不会点,反而会转到其他音乐平台,但是,如果你的音乐类型足够多,除了rap,古风,还有流行,蒸汽波,民谣,摇滚等类型的代表歌曲,给用户充足的选择(当然也不能太多,不然用户又会陷入布理丹效应),从而让系统接受到用户的初步兴趣,进行相关推荐。
2.1.3 问题启发式冷启动
- 这种方式有些类似于好物冷启动,只是从 item 展现变为了问答形式,从一系列的问题中去探寻用户的兴趣,比较典型的案列如B站的60问。但是,这种方式很容易引发用户的反感,所以,问题数不能设置太多,而且难度应该适中。
2.1.4 社交冷启动
- 从用户的社交网络去冷启动新用户,比较出名的案列是Facebook和微信,主要是利用用户的联系人或者好友的感兴趣的item去冷启动用户。
2.1.5 联邦学习冷启动
- 主要是利用外部数据进行用户的冷启动,比如现在腾讯和阿里都提供了数据接口,对于我们的app来说,新用户对我们是新用户,但是,对于腾讯或者阿里他们是老用户了,拥有大量的兴趣行为,我们可以通过买他们的数据接口实现用户冷启动,此方法可以迅速实现用户的冷启动,但是,相对来说,其价格并不便宜。
2.1.6 模型冷启动
- 模型冷启动的做法比较多,比如单独对新用户建模,利用用户间相似度,用相似用户点击item冷启,对新用户的userid emebdding设置固定值等,后面,模型篇会专门对此进行讲解。
2.17 多域冷启动
- 类似于联邦学习冷启动,但是一般主要发生在站内应用间的信息互传,比如,今日头条的用户冷启动可以用抖音的用户画像,百度外卖的用户冷启动可以用百度搜索的历史内容和关键字进行冷启动。
2.2 Item 冷启动
item 冷启动的主要作用有两个,
- 第一是让新入库的item得到充足的曝光,
- 第二是让高质量的item得到迅速下发,满足用户兴趣。比较经典的案列就是知乎对于新文章的曝光和下发。
2.2.1 用户粉丝冷启动
- 通常来说当一个作者发布新内容(新的 item)的时候,最感兴趣的应该是该作者的粉丝,所以,直接把新的item发送给作者的粉丝,是一个快速冷启动的方式。
2.2.2 item基础信息冷启动
- item相对user来说有更详细的信息,比如item的类别,关键字,主题等,我们可以用过建立item基础信息的user倒排索引实现item冷启动,如{‘篮球’:user1->user2->…->usern},倒排规则通常为用户活跃度。
2.2.3 item相似性冷启动
- 通过item之间的相似性,找到与新item相似的高热item,然后,下发给点过这些高热item的用户。具体的做法有对item的title进行embedding化,然后计算item间的相似度,找到相似item,再进行用户圈选,或者对item的基础属性进行数值化,然后,再利用cosine或者欧式距离计算相似度。具体做法模型篇会进行详细讲解
2.2.4 item进退场机制
- item进退场机制又称为保量,主要是针对新的item进行单独的个性化推荐,对于整个系统而言,将所有新入库的item建立起一个冷门item池子,然后单独针对这部分item进行模型训练,即所谓的个性化保量,此外可以根据item所处的下发量设立进退场机制,每一个进退场都起着不同的作用,比如在item下发量0-1000区间,我们可以对每个item进行强保量到1000,主要起的作用就是让item得到充足下发,实现高质item的初筛,然后对于下发量在1000-2000的item我们可以挑选点击率高的item进行二次推量强推,保证高质的item得到持续的下发,对于2000以后的item我们就可以让其进入正常的推荐item库中,让其自己和其他item自由竞争。item进退场机制后面会出专案进行讲解。
3. 召回
召回最重要的一点是全面,覆盖所有的用户可能会消费的item,它决定着整个推荐算法的天花板。而由于面对上亿级别的池子,因此recall是一个及其简单的模型/规则。这些规则是并行计算的,保证recall的效率。召回针对的是 item 库中的全部 item,主要作用是全而不漏,将user的可能感兴趣的物品一网打尽。因此很多时候召回往往不是一路召回而是多路召回,
- 每一路召回都从不同的用户兴趣出发点去捞取一定量的item,
- 然后再将每一路召回的 item 融合去重再送入粗排,
- 这其中的还有一点要注意的就是速度必须要快,因为后续还有一系列的链路,所以,给予召回层的时间并不是很充分的。
- 召回方法主要分两类一类是非个性化召回,主要根据 item热度,item的质量,运营策略等去召回item,个性化是根据用户和item的匹配度去进行item召回。
3.1 非个性化召回
非个性化召回与用户无关,可以离线构建好,主要有:
-
热门召回
- 比如最近7天点击高,成交高,评论量高,点赞高的样本,但是热门召回的量不应该太大,因为一般来说热门样本都属于高质量样本,用户大概率会点,但是这并不能完全表达用户真的是因为兴趣去点的 (可能就是因为热度点的,比如唐山打人事件)。
-
高效率召回
- 比如高CTR、高完播率、高人均时长的item,这类item效率较高,但是因为还没有得到大量的下发所以未进入热门召回。
-
运营策略召回
- 例如运营构建的各个类目的榜单、片单,最新上架 item 等。
3.2 个性化召回
个性化召回主要是根据user和item的基本信息去进行匹配召回,主要有:
-
内容召回
- 根据用户的基础信息,比如年龄,职业,兴趣爱好,历史行为,地域等,建立倒排索引,具体做法类似于,冷启动中的user冷启动方法。内容召回的优点是速度快,而且和兴趣比较相关(前提是你的画像团队比较给力),但是,缺点也很明显,就是随着基础特征的增多,倒排拉链将越来越多,维护成本大,而且需要算法工程师对业务有很强的理解能力。
-
CF召回
- 之前我们在推荐系统的历史一文中粗略的介绍过CF算法,我们可以通过CF算法去找出目标 user 相关的 user,然后拿这些相关user点击过的item作为召回item,这种方法就是典型的 U2U2I 形式的召回。
-
图召回(其实它是属于CF召回的,现在好多研究都是拿图去做CF)
- 图召回,主要是通过建图的方式去描述 user 和 item(i2u),或者 user 和 user(u2u2i),或者 item 和item(i2i)的关系,然后,从这些关系中进行信息抽离,进而进行召回。
- 图召回的建图方式对于算法工程师的业务理解也有很高的要求,如何定义节点,如何定义两个节点建边的关系,如何设定边的权重都是需要细细考量的。
- 这里给出一个例子,进行初步讲解,我们可以采用deepwalk+word2vec的方式建立一个U2U2i 的召回模型,具体步骤如下:
- 确定所有 user 为图的 node,边为如果两个用户点击过同一个item,那么两个node就产生一条边,此外还可以根据两个用户的点击过同一item的次数为边设置权重。
- 建图完毕以后,通过随机游走的方式(因为图太大了不可能拿所有的相关node去训练),得到一系列的相关node序列。
- 通过这些相关序列采用 word2vec 方式训练,得到每个user的embedding,此时的user embedding已经具有相似特性
- 对于target user拿到其对应embedding,对其他用户进行检索,获取到与他最相似的n个相似user,然后这些user点击过的 item 作为召回 item。
-
Embedding模型召回(冷启动没有CF和图召回严重)
- Embedding模型召回本质上属于 U2I 召回,也被称为双塔模型,主要是把 user 和 item 的数据分别用模型进行处理(可以是FM,也可以是 DNN 甚至可以直接 embedding concat),然后输出仅代表user和item的embedding,再将user和item embedding进行内积,进行监督学习。
- Embedding模型召回的方式满足了个性化的需求,比起图召回更直接表达用户的兴趣,比起内容召回更个性化,而且因为检索算法的进步,耗时也达到了一个可接受的范围,而且因为embedding是可以被离线缓存起来的,所以,很多很复杂的算法都可以被实现并在此阶段落地,后面会有文章针对此召回,进行详细讲解。
- 不过事实上,Embedding模型召回还是有它的不足,大量实验表明,在同样数据集情况下,双塔模型因为缺少 user feature 和 item feature的特征交叉,无论是gauc还是auc都远弱于DNN。
4. 粗排
粗排是召回的下一层,主要的作用选取优质的 item 送给精排模型,通常即使通过召回阶段,item的数量还是很多,因此,需要粗排进行二次筛选(当然如果item并不多,比如召回后只有100条item,粗排就不需要了)。
- 粗排其实像是精排和召回的一个折中点,它也需要速度的保证,但是,并不需要召回那么快,因为经过召回层的筛选,其面对的item量已经被大大的衰减。
- 但是,精度相对来说要求就要比召回要更准了,不过因为后面还有一个精排层,所以,也不用特别精准,因此,粗排层更像是一个召回和精排的折中,其更像一个精排的影子,但是,速度是强于精排的。
4.1 双塔粗排
DSSM 粗排模型仍然是各个大厂常用的粗排算法,
-
主要优点正如 Embedding模型召回所说快,而且个性化强,但是有人会说它不是和embedding 召回重复了吗?
- 区别主要在于样本的不同。对于召回来说,其正样本通常来说是曝光点击样本,负样本为 batch 内负采样或者全局随机负采样,这是因为对于召回来说其面对的item池子是整个item库,里面的 item 对于user来说大部分是不感兴趣的,只有少部分是user感兴趣的,所以,
- 不用曝光未点击的样本直接作为负样本,因为曝光未点击的样本基本上是大概率 user 感兴趣的样本,这些样本都是千挑万选选出来的,分布和item库是很不一样的。
- 不可能用整个库里面的 user 未点击的 item 作为负样本,因为,会把潜在的正样本误杀,而且,算力也吃不下。所以,采用负采样的方式构建负样本满足了两点需求,
- 一是拟合了item库的分布,
- 二是减少了算力的压力。
- 对于粗排就不一样了,
- 首先粗排是去模拟精排的分布,而且其面对的 item 池子经过召回已经大大降低了数量,所以此阶段可以用曝光未点击样本作为负样本,去拟合精排,不再那么需要样本负采样。
- 其次,为了可以更贴近精排的分布,可以采用精排打分的前n作为正样本或者精排打分的后n作为负样本加入训练样本。这么做的原因是,对于精排前n来说,其前n打分是精排认为特别好的样本,可以作为一个伪正样本,增强粗排辨别精排所喜欢的样本的能力,那么精排打分的后n作为负样本,主要是让粗排知道这些并不是精排喜欢的样本,以后不要再送过来了。
- 区别主要在于样本的不同。对于召回来说,其正样本通常来说是曝光点击样本,负样本为 batch 内负采样或者全局随机负采样,这是因为对于召回来说其面对的item池子是整个item库,里面的 item 对于user来说大部分是不感兴趣的,只有少部分是user感兴趣的,所以,
-
此外,还有一种方式便是让粗排模型对精排模型蒸馏,具体做法是用精排模型的打分作为一个softlabel,用kl散度或者mse去建立精排打分和粗排模型打分的损失函数,让粗排模型更好的拟合精排的分布。
4.2 交叉粗排
交叉粗排产生的原因是还是因为 user 特征和 item 特征交叉的强大能力,因此,为了克服模型交叉其耗时大的缺点,工程师们决定对模型进行瘦身,让其可以在特征交叉的情况下,满足速度的要求,比较典型的代表是 COLD: Towards the Next Generation of Pre-Ranking System。
- 交叉粗排的第一点就是参数要少,计算复杂度要低,速度要快,模型方面比较建议的结构如LR或者FM这种计算速度快的的模型结构,
- 第二点就是,特征不能多,所以,首先要用XGB或者senet这种能够筛选特征重要性的模型进行特征筛选,然后,选择重要特征,进行特征裁剪,降低模型复杂度。
- 第三就是工程方面的优化,比如模型精度为 float32 可以降到 float16,总是来说就是牺牲部分精度换取速度。
5. 精排
精排其实是推荐系统最重要的一环,直接表现了用户个性化的优劣与否,好的精排模型直接决定了用户的留存和转化,因为其推出的item就直接代表了用户的兴趣点,如果精排模型出现差错,直接的表现就是点击率大幅下降,用户将逐渐流失,转化也会逐渐减少,因此精排是非常重要的一环。
- 正如推荐系统的历史所说,其实最初的推荐系统并不存在冷启动,召回,粗排和重排,仅仅只有一层精排,CF就是最早的精排模型,这时候仅仅只考虑用户和item的点击共现关系,
- 后面LR的出现开始在各大公司大行其道,其中的优秀代表作就是百度的大规模特征工程+LR,其主要作用就是将user的基础特征和item的基础特征提取出来,加上大量的人造特征提取user和item的共性,然后运用梯度下降让模型去学习 user 和 item 的关系,其主要优点就是速度快,而且只要特征工程做的好,其精度丝毫不弱于dnn,但是缺点也很明显,需要大量的特征工程去堆砌和实验。
- 2014年,基于树模型的gbdt 开始被广泛应用于市场,因为其对于连续特征的处理的优秀能力,其经常被用来作为连续特征的提取器提取叶子特征,供给LR使用。
- 之后精排开始进入深度学习时代,特征开始进入embedding化,模型也出现了几个不同的优化分支,
- 第一个分支是模型侧的特征交叉,主要的代表作有FM,FFM,deepfm,DCN,DCNv2,Fibinet等。
- 第二个分支是序列特征的兴趣提取,主要代表作有DIN,DIEN,SIM等。
- 第三个分支是多目标模型的研究,主要代表作有 ESSM,MMOE,SNR和PLE等。
总的来说在精排层,最主要的目的就是在算力能够承受的最大压力下尽可能的提高模型的精度,满足用户的兴趣点,提高用户满意度,对于正常推荐系统来说,一个好的精排模型应该满足 user 对粗排送上的 item 的序关系(即越容易被user点击和喜欢的item排在越前面),对于广告推荐来说,精排模型不止要满足序关系还要满足值关系即精排打分应该和 item的点击率是1:1的关系,这个指标被称为COPC,即 (实际点击率 / 模型预测的点击率) 。之所以要满足值关系的原因是因为在广告推荐中精排打分将会直接被用于广告定价,可见精排对于广告推荐来说是更加的重要。
- 还有一个点要注意,就是要定时对模型进行迭代或者模型冷启动,如果精排模型长期不进行迭代,产生的训练数据会逐渐拟合模型的分布,模型将和数据合二为一,那么之后的新模型将很难超过当前的模型,甚至连持平都很困难,这种模型就是推荐工程师最讨厌的老汤模型。这时候只能通过更长周期的训练数据让新模型去追赶老模型或者去加载老模型的参数热启动新模型,但是,这种热启动的方式很难去改变模型的结构,模型建模受限大。所以,算法工程师们在初次建模的时候就要考虑到老汤模型的问题,定时对精排模型进行迭代或者每隔一段时间(比如3个月)就将模型重训-进行数据冷启动,这么做的方式是让模型忘记之前过时的分布,着重拟合当前的分布。
6. 重排(着重体现在策略上)
重排的主要作用是为了提升用户的多样性体验,扶持业务产品,弥补精排的个性化不足和实现多目标的最优解。主要的策略为调权,强插,过滤,打散,多目标打分融合和模型重排。
6.1 调权
调权主要是对精排的 item 打分进行提升和打压,最简单的做法就是将精排打分乘以一个系数。
-
个性化调权
- 举个例子,如果我们经过数据分析发现在整体预估 ctr 和实际 ctr 的比值为1即整体COPC=1的情况下,体育类item的预估 ctr 是低于其实际 ctr 的,那么我们就需要对体育类的item乘以一个系数 ,去对体育类的item进行调权。同理,如果发现某个类别的实际ctr是低于预估ctr的应该对其降权。(本质就是调低它的分数)
-
冷启动调权
- 对于某些需要冷启动的item,可以对其进行加权,让其进行快速曝光,但是,为了保证效果,一般建议对精排的前10%item进行冷启动调权。
6.2 强插
- 强插主要是针对某些运营安排的特定item,比如,某个突发新闻的报道或者广告的插入,进行强制下发,业务驱动比较强。
6.3 过滤
- 过滤主要是针对一些负反馈过多的item或者明显不合理的item的下发,如学生不推送烟酒产品。
6.4 打散
- 打散主要是针对用户兴趣疲劳的一个机制,提高用户多样性体验。主要是统计用户当天的历史下发品类,然后尽可能的保证推送给用户的item的品类是足够多的,而不是一味的只推送某一品类的item,从而让用户产生兴趣疲劳。
6.5 多目标打分融合
多目标打分融合是一个全局目标优化的策略,主要是针对多个目标的共同优化。正如前文推荐算法在工业界的应用说的,我们的应用优化目标只有一个是用户满意度和cvr,但是很多时候我们拿不到纸面的用户满意度所以我们用点击率ctr,成交率cvr,观看6秒,接通电话30秒,评论,点赞,收藏和多样性覆盖率等一系列指标去作为用户满意度的替代品。那其实我们的目标是有多个,那么同样的,我们就有多个目标的精排打分,怎么把这多个目标的打分统一起来,最终形成一个用户满意度打分用来进行最终的排序就是多目标融合打分的工作。
-
naive权重分配
- 最简单的办法,就是给各个优化目标打分安排权重然后得到一个最终打分 :用户满意度留存留存 = a*点击率ctr + b* 成交率cvr,通过在线调节每个目标的权重,查看每个目标的在线效果直到调到一个业务最优的状态。
- 但是,这个方法缺点也很明显,就是需要大量的实验,时间耗费大,而且随着模型的迭代,参数也会跟着变化。
-
动态权重分配
- 强化学习-动态权重分配
- 可以通过强化学习的方式,设定用户的状态(一般为静态属性(如性别,年龄,购买力等)和环境状态(时间,浏览深度等))),再设定奖励(如浏览时长,点击,购买等),最后设定action(对w的调整),当拿到state,action,reward之后就可以进行强化学习,学习出最优的权重。
6.6 模型重排
模型重排主要是针对精排展现 item 的位置调整,主要是通过调节item的展现而获得长期的收益,举个例子就是依次给用户展现 itemA,itemB和itemC,用户点击了A,但是没有点击B和C,但是,如果我们依次展现的是itemB,itemA和itemC,用户对A,B和C都产生了点击。这种情况比较适合有强序列关系的业务场景,一般是用 listwise 的建模方式,让模型去学习item间的序列关系。
7. 总结
推荐系统主要分为冷启动-召回-粗排-精排-重排5个阶段,(在召回的评价指标更着重于hitrate,粗排考虑auc/gauc/ndcg,精排考虑auc/gauc)其中,
- 冷启动又分为用户冷启动,item冷启动和系统冷启动,而且如果冷启动的物品池足够大,完全可以重启一整套为冷启动服务的推荐流程。
- 召回的主要目的是实时快速的炮火覆盖打击,尽可能的囊括目标用户感兴趣的物品,
- 粗排的主要作用是能够快速的从召回item中选择用户最感兴趣的item给精排,其可以当作精排的影子。
- 精排是最重要的一层,直接决定了用户的满意度,所以力求精准。
- 重排主要作用是为了提升用户的多样性体验,扶持业务产品,弥补精排的个性化不足和实现多目标的最优解。
其实,对于一个最开始item和user还不多的应用来说,推荐系统最开始的设计最开始仅仅需要一个简单的精排+重排就足够了,后面随着item和user的增多,逐步添加召回层和粗排层,当item和user达到一个较大的量级,冷启动才是需要重点关注的。
参考
【1】https://zhuanlan.zhihu.com/p/572998087
【2】https://link.zhihu.com/?target=https%3A//www.6aiq.com/article/1649894824064
相关文章:
【推荐系统】推荐算法:冷启动-召回-粗排-精排-重排 解读
【推荐系统】推荐算法:冷启动-召回-粗排-精排-重排 解读 文章目录 【推荐系统】推荐算法:冷启动-召回-粗排-精排-重排 解读1. 介绍2. 冷启动2.1 用户冷启动2.1.1 利用用户注册信息冷启动2.1.2 好物推荐冷启动2.1.3 问题启发式冷启动2.1.4 社交冷启动2.1.…...

NB-IOT的粮库挡粮门异动监测装置
一种基于NBIOT的粮库挡粮门异动监测装置,包括若干个NBIOT开门监测装置,物联网后台管理系统,NBIOT低功耗广域网络和用户访问终端;各个NBIOT开门监测装置通过NBIOT低功耗广域网络与物联网后台管理系统连接,物联网后台管理系统与用户访问终端连接.NBIOT开门监测装置能够对粮库挡粮…...
六、【图像去水印】
文章目录 裁剪法移动复制法内容识别去水印色阶法去水印消失点法去水印反相混合法 裁剪法 处于边缘的水印,通过裁剪去除,如下图: 移动复制法 移动复制法适用于水印的背景这部分区域比较相似的情况下使用,如下图先使用矩形选区选中…...
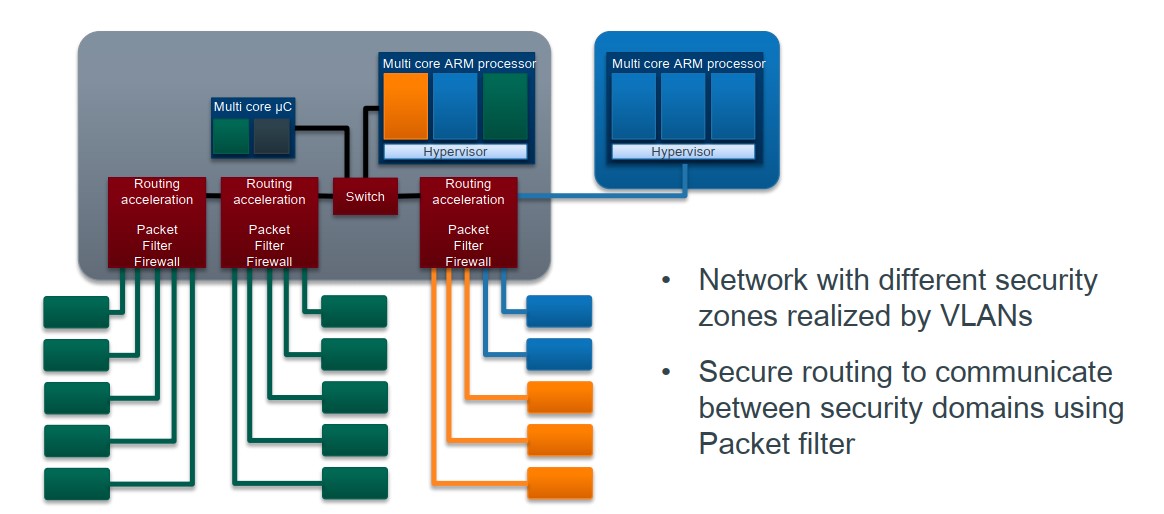
电子电器架构 —— 车载网关初入门(二)
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 PS:小细节,本文字数5000+,详细描述了网关在车载框架中的具体性能设置。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 没有人关注你。也无需有人关注你。你必须承认自己的价值,你不能站在他…...
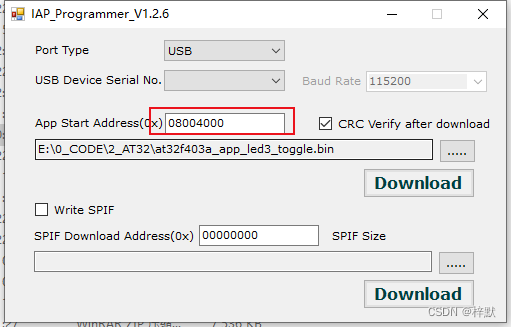
AT32固件库外设使用,ArduinoAPI接口移植,模块化
目录 一、ArduinoAPI移植一、通用定时器使用1.计时1.2.ETR外部时钟计数4.ArduinoAPI - timer 三、ADC1.ADC初始化(非DMA)2.ADC_DMA 规则通道扫描 六、USB HID IAP1.准备好Bootloader和app2.配置好时钟,一定要打开USB3.将生成的时钟配置复制到…...
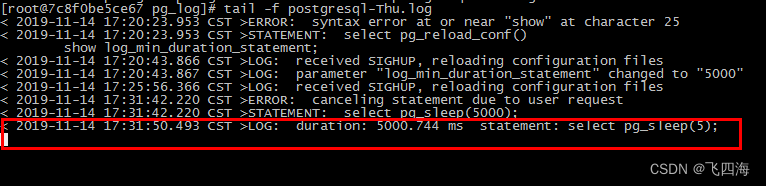
【Postgres】Postgres常用命令
文章目录 1、导出数据库某张表2、导入某张表到数据库3、查看数据库占用磁盘页数情况4、查看数据库大小5、查看数据表大小6、查看索引大小7、对数据库中表索引按照大小排序8、对数据库中表按照大小排序9、回收空间(建议先回收指定表)10、设置主键自增序列…...

pthread 读写锁使用详解
pthread 读写锁使用 读写锁:提供了一种高效的机制来控制对共享资源的访问。允许多个线程同时读取共享资源,但只允许一个线程独占地写入访问。适用于读取远远超过写入的场景下,因为写入操作需要独占地访问资源,可能会影响读取操作…...

MySQL扩展语句
if not exists xiaobu:xiaobu这个表不存在,才会创建 zerofill:自动填充位置 1 0001 primary key:当前表的主键,主键只能有一个,而且唯一,而且不能为空 auto_increment:表示该字段…...
在连接wifi的情况下部分机型下存在的问题)
阿里云号码认证服务(一键登录)在连接wifi的情况下部分机型下存在的问题
手机型号: vivo S16 存在的现象: 安装手机卡(联通卡),且连接wifi的情况下,APP登录唤起阿里云一键登录服务大概有90%左右必超时(按照阿里云一键登录官方文档设置的超时时间为5秒)。 解决方案: 1、APP端增加超时判断&…...

电脑屏幕监控软件,能够帮助企业完成哪些事情?
电脑屏幕监控软件是一种能够监控和管理员工在电脑上的操作行为的软件。分为两种监控方式:实时监控和屏幕记录监控。实时监控是对电脑屏幕进行实时录像,屏幕记录监控则是以屏幕快照的形式保存下来,供使用者随时查看。电脑屏幕监控软件…...

java--方法的其他形式
1.方法定义时:需要按照方法解决的实际业务需求,来设计合理的方法形式解决问题。 1.注意事项 ①如果方法不需要返回数据,返回值类型必须申明成void(无返回值申明),此时方法内部不可以使用return返回数据。 ②方法如果不需要接收数…...
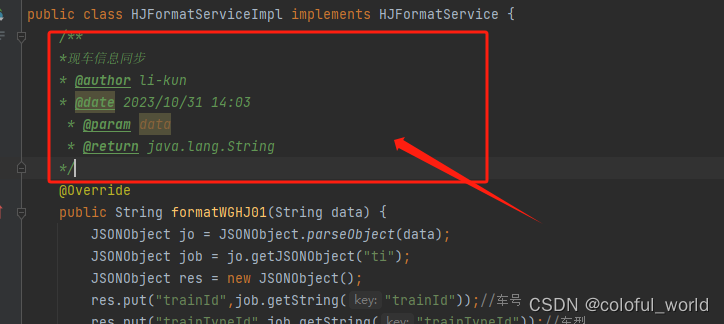
IDEA配置类、方法注释模板
一、打开 IDEA 的 Settings,点击 Editor–>File and Code Templates,点击右边 File 选项卡下面的 Class,在其中添加图中红框内的内容: /** * author li-kun * date ${YEAR}年${MONTH}月${DAY}日 ${TIME} */当你创建一个新的类…...

PowerDesigner 16数据库(mysql)逆向生成pdm
1、配置数据源 2、测试数据源 but~~~~没成功,shift...

Spring Cloud 之Feign
前言 Feign是一个声明式的Web服务客户端,使得编写HTTP客户端变得更简单。在Java程序中,只需要在方法前加上FeignClient注解,Feign就会自动创建一个HTTP客户端,向指定的URL发送请求。 核心概念 1、注解:在服务接口方…...

通用开源自动化测试框架 - Robot Framework
一、什么是 Robot Framework? 1. Robot Framework 的历史由来 Robot Framework是一种通用的自动化测试框架,最早由Pekka Klrck在2005年开发,并由Nokia Networks作为内部工具使用。后来,该项目以开源形式发布,并得到了…...
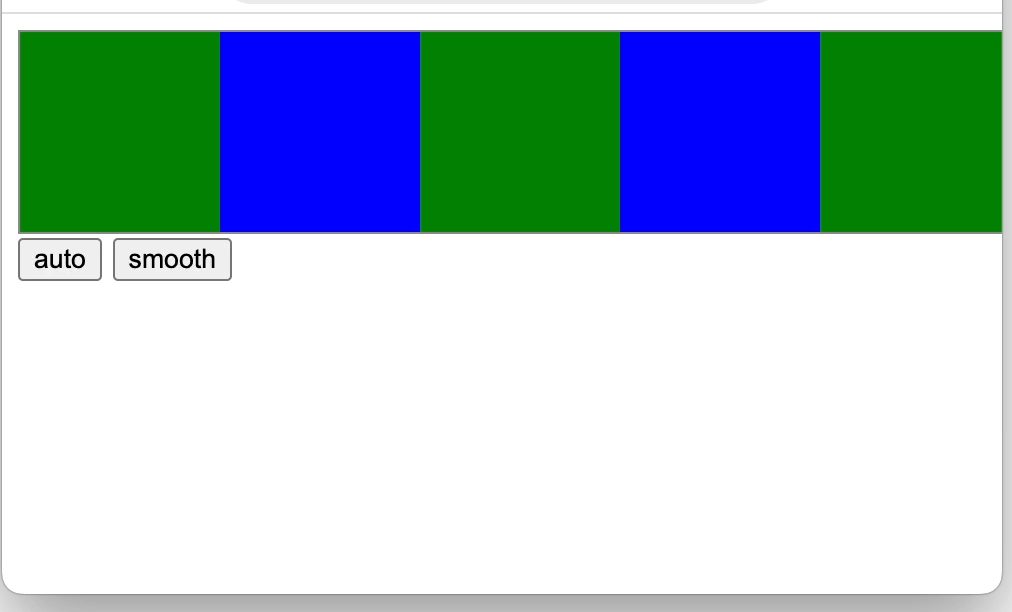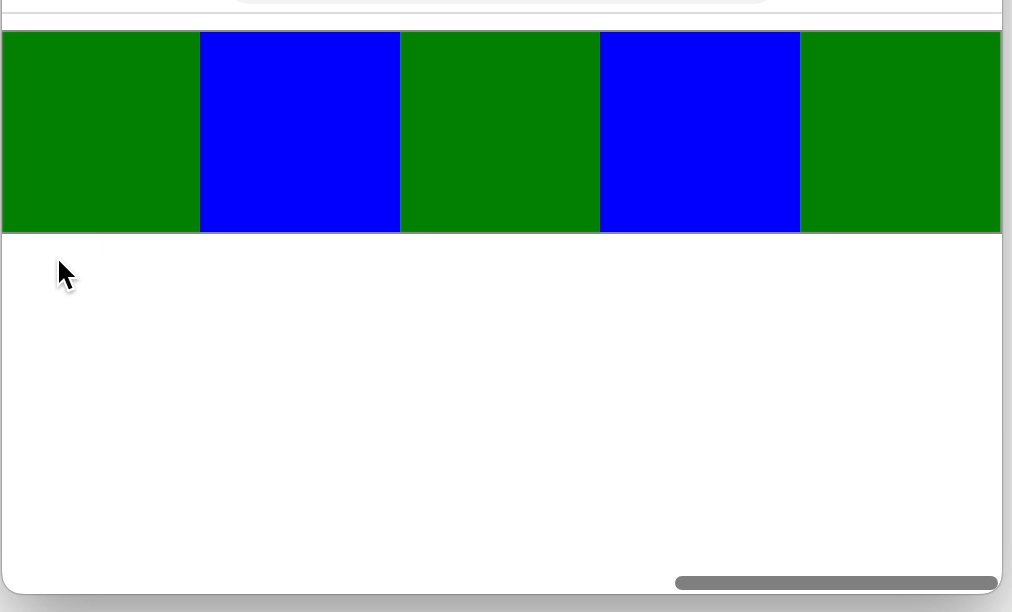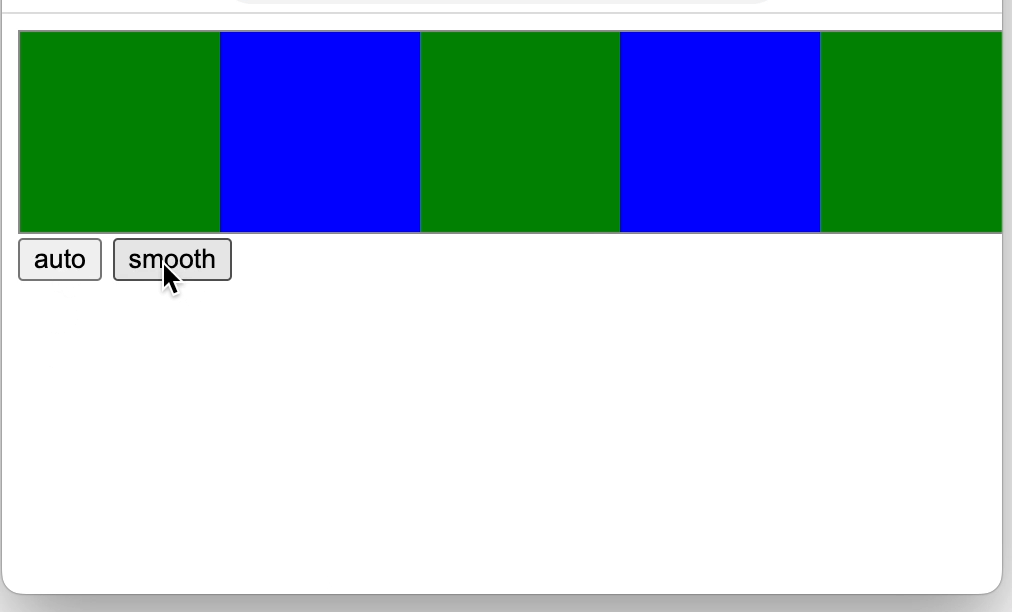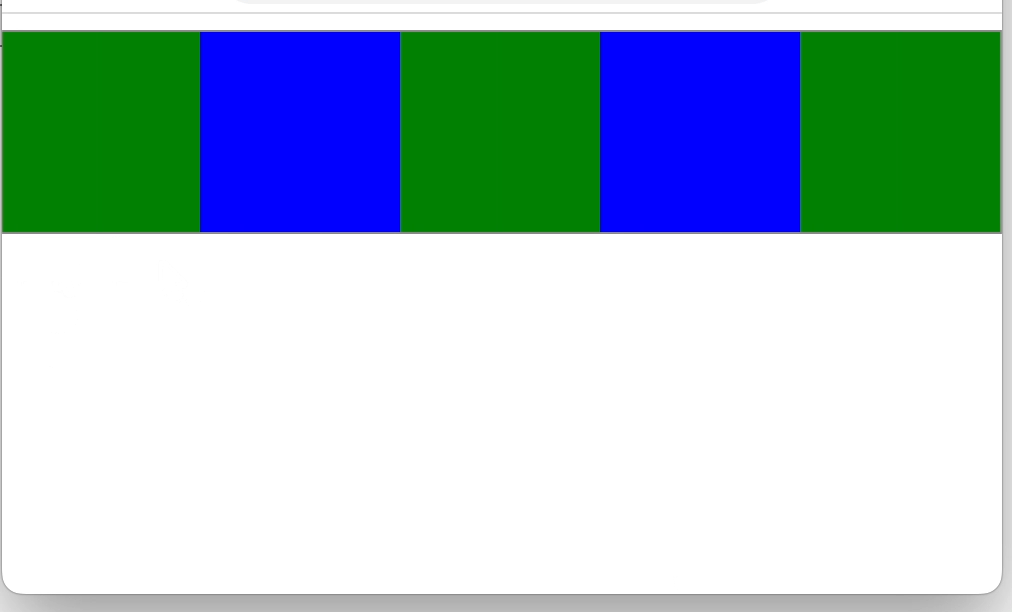
css position属性与js滚动
“视口”就是浏览器窗口中实际显示文档内容的区域,不包含浏览器的“外框”,如菜单、工具条和标签。文档则是指整个网页。 1 css 的position static 正常定位,是元素position属性的默认值,元素遵循常规流。 relative 相对定位&…...

python内置模块hashlib对于字符串的加密解密加盐
hash是一类算法而hashlib模块是Python的一个内置模块,主要功能是使用对应的hash算法,加密二进制内容解密二进制内容 常见的hash算法有md5、sha1,sha256, sha512等 特点 1.内容敏感,那怕一个很小的字符发生改变都很明显 2.不可逆,不能逆向求值…...

获取客户端请求IP及IP所属城市
添加pom依赖 <dependency> <groupId>org.lionsoul</groupId> <artifactId>ip2region</artifactId> <version>2.6.5</version> </dependency> public class IpUtil { private…...
)
【洛谷 P1106】删数问题 题解(贪心+字符串)
删数问题 题目描述 键盘输入一个高精度的正整数 N N N(不超过 250 250 250 位),去掉其中任意 k k k 个数字后剩下的数字按原左右次序将组成一个新的非负整数。编程对给定的 N N N 和 k k k,寻找一种方案使得剩下的数字组成…...
【Python · PyTorch】线性代数 微积分
本文采用Python及PyTorch版本如下: Python:3.9.0 PyTorch:2.0.1cpu 本文为博主自用知识点提纲,无过于具体介绍,详细内容请参考其他文章。 线性代数 & 微积分 1. 线性代数1.1 基础1.1.1 标量1.1.2 向量长度&…...
和MSB8020错误的根治方法)
别再只改项目属性了!彻底搞懂Visual Studio平台工具集(Platform Toolset)和MSB8020错误的根治方法
深入解析Visual Studio平台工具集:从MSB8020错误到构建系统精要 当你在Visual Studio中打开一个历史项目时,是否曾被突如其来的MSB8020错误打断工作流程?这个看似简单的"找不到生成工具"提示背后,隐藏着Visual Studio构…...

保姆级教程:用PaddlePaddle的PP-LiteSeg在Cityscapes数据集上实现实时语义分割
从零实现PP-LiteSeg:Cityscapes实时语义分割全流程实战 1. 环境配置与数据准备 在开始PP-LiteSeg的实战之前,我们需要搭建完整的开发环境。推荐使用Anaconda创建独立的Python环境以避免依赖冲突: conda create -n paddleseg python3.8 conda …...

Windows电脑运行安卓应用终极指南:APK安装器完整教程
Windows电脑运行安卓应用终极指南:APK安装器完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过,在Windows电脑上直接运行安…...
)
别再死记ResNet结构了!用PyTorch手把手带你复现ResNet-50(附完整代码与可视化)
从零构建ResNet-50:PyTorch实战与架构解密 当你第一次看到ResNet的残差连接时,是否曾被那个"跳跃"的结构所困惑?为什么简单的跨层连接就能解决深度网络的退化问题?本文将以工程师视角,带你用PyTorch从第一行…...
)
从MySQL DBA转型ES:我的踩坑笔记与核心概念对比(Mapping/查询/索引篇)
从MySQL DBA转型ES:我的踩坑笔记与核心概念对比(Mapping/查询/索引篇) 当第一次接触Elasticsearch时,我习惯性地用MySQL的思维去理解它——结果可想而知。作为从业十年的MySQL DBA,转型过程中踩过的坑让我意识到&#…...

如何用LyricsX在Mac桌面显示歌词:免费开源工具终极指南
如何用LyricsX在Mac桌面显示歌词:免费开源工具终极指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 你是否曾在听歌时想要跟着歌词一起唱,却不…...

QMC音频解密技术深度解析:算法实现与性能优化
QMC音频解密技术深度解析:算法实现与性能优化 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder QMC音频解密工具是一款专注于QQ音乐加密格式解密的开源解决方案&a…...

抖音下载器终极指南:3步实现批量无水印下载,提升内容创作效率90%
抖音下载器终极指南:3步实现批量无水印下载,提升内容创作效率90% 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and b…...

从Windows迁移者的视角:中兴新支点NewStartOS上手初体验与软件兼容性实测
从Windows迁移者的视角:中兴新支点NewStartOS上手初体验与软件兼容性实测 作为一名长期使用Windows系统的普通用户,第一次接触国产操作系统时难免会有诸多疑虑:界面是否熟悉?常用软件能否运行?外设驱动是否完善&#…...

【免费下载】 树莓派4B原理图资源下载
树莓派4B原理图资源下载 【下载地址】树莓派4B原理图资源下载分享 树莓派4B原理图资源下载本仓库提供了一个方便的途径,供大家下载树莓派4B的原理图资源文件 项目地址: https://gitcode.com/open-source-toolkit/ae590 本仓库提供了一个方便的途径࿰…...