[转载]C++序列化框架介绍和对比
Google Protocol Buffers
Protocol buffers 是一种语言中立,平台无关,可扩展的序列化数据的格式,可用于通信协议,数据存储等。
Protocol buffers 在序列化数据方面,它是灵活的,高效的。相比于 XML 来说,Protocol buffers 更加小巧,更加快速,更加简单。一旦定义了要处理的数据的数据结构之后,就可以利用 Protocol buffers 的代码生成工具生成相关的代码。甚至可以在无需重新部署程序的情况下更新数据结构。只需使用 Protobuf 对数据结构进行一次描述,即可利用各种不同语言或从各种不同数据流中对你的结构化数据轻松读写。
Protocol buffers 很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。--《 深入理解Protobuf原理与工程实践》
大家可能会觉得Google发明Protocol buffers是为了解决序列化速度的,其实真实的原因并不是这样的。Protocol buffers最先开始是Google为了解决服务器端新旧协议(高低版本)兼容性问题,名字也很体贴, “协议缓冲区”。只不过后期慢慢发展成用于传输数据。--《 深入理解Protobuf原理与工程实践》
Why the name "Protocol Buffers"? The name originates from the early days of the format, before we had the protocol buffer compiler to generate classes for us. At the time, there was a class called ProtocolBuffer which actually acted as a buffer for an individual method. Users would add tag/value pairs to this buffer individually by calling methods like AddValue(tag, value). The raw bytes were stored in a buffer which could then be written out once the message had been constructed. Since that time, the "buffers" part of the name has lost its meaning, but it is still the name we use. Today, people usually use the term "protocol message" to refer to a message in an abstract sense, "protocol buffer" to refer to a serialized copy of a message, and "protocol message object" to refer to an in-memory object representing the parsed message.
编码原理
Protobuf高效的秘密在于它的编码格式,它采用了T-(L)-V(Tag-Length-Value)编码格式。每个字段都有唯一的 tag 值,它是字段的唯一标识。length 表示 value 数据的长度,length 不是必须的,对于固定长度的 value,是没有 length 的。value 是数据本身的内容。

对于 tag 值,它有 field_number 和 wire_type 两部分组成。field_number 就是在前面的 message 中我们给每个字段的编号,wire_type 表示类型,是固定长度还是变长的。 wire_type 当前有0到5一共6个值,所以用3个 bit 就可以表示这6个值。tag 结构如下图。

wire_type 值如下表, 其中3和4已经废弃,我们只需要关心剩下的4种。对于 Varint 编码数据,不需要存储字节长度 length。这种情况下,TLV 编码格式退化成 TV 编码。对于64-bit和32-bit也不需要 length,因为type值已经表明了长度是8字节还是4字节。
| wire_type | 编码方法 | 编码长度 | 存储方式 | 数据类型 |
| 0 | Varint | 变长 | T-V | int32 int64 uint32 uint64 bool enum |
| 0 | Zigzag+Varint | 变长 | T-V | sint32 sint64 |
| 1 | 64-bit | 固定8字节 | T-V | fixed64 sfixed64 double |
| 2 | length-delimi | 变长 | T-L-V | string bytes packed repeated fields embedded |
| 3 | start group | 已废弃 | 已废弃 | |
| 4 | end group | 已废弃 | 已废弃 | |
| 5 | 32-bit | 固定4字节 | T-V | fixed32 sfixed32 float |
因为 Varint 和 Zigzag 编码可以自解析内容的长度,所以可以省略长度项。TLV 存储简化为了 TV 存储,不需 length 项。

嵌套类型编码
嵌套消息就是value又是一个字段消息,外层消息存储采用 TLV 存储,它的 value 又是一个 TLV 存储。整个编码结构如下图所示。

优缺点
优点:
- 效率高
从序列化后的数据体积角度,与XML、JSON这类文本协议相比,ProtoBuf通过T-(L)-V(Tag-Length-Value)方式编码,不需要", {, }, :等分隔符来结构化信息,同时在编码层面使用varint压缩,所以描述同样的信息,Protobuf序列化后的体积要小很多,在网络中传输消耗的网络流量更少,进而对于网络资源紧张、性能要求非常高的场景,Protobuf协议是不错的选择。
2. 支持跨平台、多语言
ProtoBuf是平台无关的,无论是Android与PC,还是C#与Java都可以利用Protobuf进行无障碍通讯。
proto3支持C++, Java, Python, Go, Ruby, Objective-C, C#。
3. 扩展性、兼容性好
具有向后兼容的特性,更新数据结构以后,老版本依旧可以兼容,这也是Protobuf诞生之初被寄予解决的问题。因为编译器对不识别的新增字段会跳过不处理。
4. 使用简单
Protobuf 提供了一套编译工具,可以自动生成序列化、反序列化的样板代码,这样开发者只要关注业务数据idl,简化了编码解码工作以及多语言交互的复杂度。
5. 具备一定的加密性
由于没有idl文件无法解析二进制数据流,Protobuf在一定程度上可以保护数据,提升核心数据被破解的门槛,降低核心数据被盗爬的风险。
缺点:
- 可读性差,缺乏自描述
XML,JSON是自描述的,而Protobuf则不是。
Protobuf是二进制协议,编码后的数据可读性差,如果没有idl文件,就无法理解二进制数据流,对调试不友好。
启用GZip压缩功能
但凡对带宽敏感的程序,无论采用何种编码方式都应该进行数据压缩。
#include <google/protobuf/io/gzip_stream.h>
#include <google/protobuf/io/zero_copy_stream_impl.h>std::string output; // 压缩序列化 google::protobuf::io::GzipOutputStream::Options options;
options.format = google::protobuf::io::GzipOutputStream::GZIP;
options.compression_level = 9; google::protobuf::io::StringOutputStream outputStream(&output);
google::protobuf::io::GzipOutputStream gzipStream(&outputStream, options);
person.SerializeToZeroCopyStream(&gzipStream) gzipStream.Flush(); //数据刷到储存中printf("COMPRESSION output size : %d\n", static_cast<int>(output.length())); // 解压缩反序列化 person.Clear();
google::protobuf::io::ArrayInputStream inputStream(output.data(), output.size());
google::protobuf::io::GzipInputStream gzipStream(&inputStream);
person.ParseFromZeroCopyStream(&gzipStream)
文件级别优化(optimize_for)
Protocol Buffers定义三种优化级别SPEED/CODE_SIZE/LITE_RUNTIME。缺省情况下是SPEED。
SPEED: 表示生成的代码运行效率高,但是由此生成的代码编译后会占用更多的空间。
CODE_SIZE: 和SPEED恰恰相反,代码运行效率较低,但是由此生成的代码编译后会占用更少的空间,通常用于资源有限的平台,如Mobile。
LITE_RUNTIME: 生成的代码执行效率高,同时生成代码编译后的所占用的空间也是非常少。这是以牺牲Protocol Buffers提供的反射功能为代价的。因此我们在C++中链接Protocol Buffers库时仅需链接libprotobuf-lite,而非libprotobuf。
syntax = "proto2";
// option optimize_for = SPEED;
option optimize_for = LITE_RUNTIME;
// option optimize_for = CODE_SIZE;
message Request {string version = 1; // 后台接口与客户端通讯协议版本
}SPEED和LITE_RUNTIME相比,在于调试级别上,例如 msg.SerializeToString(&str) 在SPEED模式下会利用反射机制打印出详细字段和字段值,但是LITE_RUNTIME则仅仅打印字段值组成的字符串; 因此:可以在程序调试阶段使用 SPEED模式,而上线以后使用提升性能使用 LITE_RUNTIME 模式优化。
Protobuf Arena
Protobuf从3.0版本开始对C++增加了Arena接口,可以用于使用连续的内存块分配内部对象,并且可以更容易精确地控制对象地生命周期,最终达到减少内存碎片地目的。
Nanopb
nanopb是也是一个轻量的、支持C语言的Protobuf,可以在STM32等单片机上使用。
nanopb的优点:
- 更小、更快、更简单。
- 解析速度快。
- 可扩展性强。
使用样例
idl文件:*.proto
pb_encode.h
/* Encode field header based on type and field number defined in the field* structure. Call this from the callback before writing out field contents. */
bool pb_encode_tag_for_field(pb_ostream_t *stream, const pb_field_t *field);/* Encode field header by manually specifying wire type. You need to use this* if you want to write out packed arrays from a callback field. */
bool pb_encode_tag(pb_ostream_t *stream, pb_wire_type_t wiretype, uint32_t field_number);/* Encode an integer in the varint format.* This works for bool, enum, int32, int64, uint32 and uint64 field types. */
#ifndef PB_WITHOUT_64BIT
bool pb_encode_varint(pb_ostream_t *stream, uint64_t value);
#else
bool pb_encode_varint(pb_ostream_t *stream, uint32_t value);
#endif/* Encode an integer in the zig-zagged svarint format.* This works for sint32 and sint64. */
#ifndef PB_WITHOUT_64BIT
bool pb_encode_svarint(pb_ostream_t *stream, int64_t value);
#else
bool pb_encode_svarint(pb_ostream_t *stream, int32_t value);
#endif/* Encode a string or bytes type field. For strings, pass strlen(s) as size. */
bool pb_encode_string(pb_ostream_t *stream, const pb_byte_t *buffer, size_t size);/* Encode a fixed32, sfixed32 or float value.* You need to pass a pointer to a 4-byte wide C variable. */
bool pb_encode_fixed32(pb_ostream_t *stream, const void *value);#ifndef PB_WITHOUT_64BIT
/* Encode a fixed64, sfixed64 or double value.* You need to pass a pointer to a 8-byte wide C variable. */
bool pb_encode_fixed64(pb_ostream_t *stream, const void *value);
#endif/* Encode a submessage field.* You need to pass the pb_field_t array and pointer to struct, just like* with pb_encode(). This internally encodes the submessage twice, first to* calculate message size and then to actually write it out.*/
bool pb_encode_submessage(pb_ostream_t *stream, const pb_field_t fields[], const void *src_struct);Protobuf-C
Protobuf-C是Google Protocol Buffers的C语言接口库。
使用样例
idl文件:*.proto, 以student.proto为例:
syntax = "proto2";
message Student {optional string name = 1;
}使用protoc生成student.pb-c.h和student.pb-c.c,下面代码是student.pb-c.h
/* Generated by the protocol buffer compiler. DO NOT EDIT! */
/* Generated from: student.proto */
#ifndef PROTOBUF_C_student_2eproto__INCLUDED
#define PROTOBUF_C_student_2eproto__INCLUDED
#include <protobuf-c/protobuf-c.h>PROTOBUF_C__BEGIN_DECLS#if PROTOBUF_C_VERSION_NUMBER < 1000000
# error This file was generated by a newer version of protoc-c which is incompatible with your libprotobuf-c headers. Please update your headers.#elif 1003003 < PROTOBUF_C_MIN_COMPILER_VERSION
# error This file was generated by an older version of protoc-c which is incompatible with your libprotobuf-c headers. Please regenerate this file with a newer version of protoc-c.
#endiftypedef struct _Student Student;/* --- enums --- */
/* --- messages --- */struct _Student{ProtobufCMessage base;char *name;
};#define STUDENT__INIT \{ PROTOBUF_C_MESSAGE_INIT (&student__descriptor), NULL }/* Student methods */
void student__init(Student *message);
size_t student__get_packed_size(const Student *message);
size_t student__pack(const Student *message, uint8_t *out);
size_t student__pack_to_buffer(const Student *message, ProtobufCBuffer *buffer);
Student* student__unpack(ProtobufCAllocator *allocator,size_t len,const uint8_t *data);
void student__free_unpacked(Student *message, ProtobufCAllocator *allocator);
/* --- per-message closures --- */typedef void (*Student_Closure)(const Student *message,void *closure_data);
/* --- services --- */
/* --- descriptors --- */extern const ProtobufCMessageDescriptor student__descriptor;PROTOBUF_C__END_DECLS#endif /* PROTOBUF_C_student_2eproto__INCLUDED */Flatbuffers
FlatBuffers 是一个开源的、跨平台的、高效的、提供了多种语言接口的序列化工具库。实现了与 Protocal Buffers 类似的序列化格式。主要由 Wouter van Oortmerssen 编写,并由 Google 开源。
- FlatBuffers是Google专门为游戏开发或其他性能敏感的应用程序需求而创建。尤其更适用于移动平台,这些平台上内存大小及带宽相比桌面系统都是受限的,而应用程序比如游戏又有更高的性能要求。它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而不需要任何解析开销。
- FlatBuffers支持“零拷贝”反序列化,在序列化过程中没有临时对象产生,没有额外的内存分配,访问序列化数据也不需要先将其复制到内存的单独部分,这使得以这些格式访问数据比需要格式的数据(如JSON,CSV 和 protobuf)快得多。
- FlatBuffers与Protocol Buffers确实比较相似,主要的区别在于 FlatBuffers 在访问数据之前不需要解析/解包。两者代码也是一个数量级的。但是 Protocol Buffers 既没有可选的文本导入/导出功能,也没有 union 这个语言特性,这两点 FlatBuffers 都有。
- FlatBuffers 专注于移动硬件(内存大小和内存带宽比桌面端硬件更受限制),以及具有最高性能需求的应用程序:游戏。
设计原理
Flatbuffers的序列化:
简单来说 FlatBuffers 就是把对象数据,保存在一个一维的数组中,将数据都缓存在一个 ByteBuffer 中,每个对象在数组中被分为两部分。元数据部分:负责存放索引。真实数据部分:存放实际的值。然而 FlatBuffers 与大多数内存中的数据结构不同,它使用严格的对齐规则和字节顺序来确保 buffer 是跨平台的。此外,对于 table 对象,FlatBuffers 提供前向/后向兼容性和 optional 字段,以支持大多数格式的演变。除了解析效率以外,二进制格式还带来了另一个优势,数据的二进制表示通常更具有效率。我们可以使用 4 字节的 UInt 而不是 10 个字符来存储 10 位数字的整数。
FlatBuffers 对序列化基本使用原则:
- 小端模式。FlatBuffers 对各种基本数据的存储都是按照小端模式来进行的,因为这种模式目前和大部分处理器的存储模式是一致的,可以加快数据读写的数据。
- 写入数据方向和读取数据方向不同。

FlatBuffers 向 ByteBuffer 中写入数据的顺序是从 ByteBuffer 的尾部向头部填充,由于这种增长方向和 ByteBuffer 默认的增长方向不同,因此 FlatBuffers 在向 ByteBuffer 中写入数据的时候就不能依赖 ByteBuffer 的 position 来标记有效数据位置,而是自己维护了一个 space 变量来指明有效数据的位置,在分析 FlatBuffersBuilder 的时候要特别注意这个变量的增长特点。但是,和数据的写入方向不同的是,FlatBuffers 从 ByteBuffer 中解析数据的时候又是按照 ByteBuffer 正常的顺序来进行的。FlatBuffers 这样组织数据存储的好处是,在从左到右解析数据的时候,能够保证最先读取到的就是整个 ByteBuffer 的概要信息(例如 Table 类型的 vtable 字段),方便解析。
Flatbuffers的反序列化:
FlatBuffers 反序列化的过程就很简单了。由于序列化的时候保存好了各个字段的 offset,反序列化的过程其实就是把数据从指定的 offset 中读取出来。反序列化的过程是把二进制流从 root table 往后读。从 vtable 中读取对应的 offset,然后在对应的 object 中找到对应的字段,如果是引用类型,string / vector / table,读取出 offset,再次寻找 offset 对应的值,读取出来。如果是非引用类型,根据 vtable 中的 offset ,找到对应的位置直接读取即可。对于标量,分 2 种情况,默认值和非默认值。默认值的字段,在读取的时候,会直接从 flatc 编译后的文件中记录的默认值中读取出来。非默认值字段,二进制流中就会记录该字段的 offset,值也会存储在二进制流中,反序列化时直接根据offset读取字段值即可。
整个反序列化的过程零拷贝,不消耗占用任何内存资源。并且 FlatBuffers 可以读取任意字段,而不是像 Json 和 protocol buffer 需要读取整个对象以后才能获取某个字段。FlatBuffers 的主要优势就在反序列化这里了。所以 FlatBuffers 可以做到解码速度极快,或者说无需解码直接读取。
优缺点
优点:
- 对序列化数据的访问不需要打包和拆包——它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而没有任何解析开销;
- 内存效率和速度——访问数据时的唯一内存需求就是缓冲区,不需要额外的内存分配;
- 扩展性、灵活性——它支持的可选字段意味着不仅能获得很好的前向/后向兼容性(对于长生命周期的游戏来说尤其重要,因为不需要每个新版本都更新所有数据);
- 最小代码依赖——仅仅需要自动生成的少量代码和一个单一的头文件依赖(Header-Only),很容易集成到现有系统中。再次,看基准部分细节;
- 强类型设计——尽可能使错误出现在编译期,而不是等到运行期才手动检查和修正;
- 使用简单——生成的C++代码提供了简单的访问和构造接口;而且如果需要,通过一个可选功能可以用来在运行时高效解析Schema和类JSON格式的文本;
- 跨平台——支持C++11、Java,而不需要任何依赖库;在最新的gcc、clang、vs2010等编译器上工作良好;
缺点:
- 数据无可读性,必须进行数据可视化才能理解数据。
- 向后兼容性局限,在 schema 中添加或删除字段必须小心。
为什么不使用Protocol Buffers?
相对而言,Protocol Buffers 确实与 FlatBuffers 相似,主要区别在于 FlatBuffers 在访问数据之前不需要进行解析/解压缩步骤。Protocol Buffers需要进行每个对象的内存分配操作,代码也大了一个数量级。
基准测试



使用样例
idl文件:*.fbs, 以student.fbs为例:
namespace qcraft;table Student {name: string;
}使用flatc生成student_generated.h (Header-Only)
// automatically generated by the FlatBuffers compiler, do not modify#ifndef FLATBUFFERS_GENERATED_STUDENT_QCRAFT_H_
#define FLATBUFFERS_GENERATED_STUDENT_QCRAFT_H_#include "flatbuffers/flatbuffers.h"// Ensure the included flatbuffers.h is the same version as when this file was
// generated, otherwise it may not be compatible.
static_assert(FLATBUFFERS_VERSION_MAJOR == 22 &&FLATBUFFERS_VERSION_MINOR == 12 &&FLATBUFFERS_VERSION_REVISION == 6,"Non-compatible flatbuffers version included");namespace qcraft {struct Student;
struct StudentBuilder;struct Student FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {typedef StudentBuilder Builder;enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {VT_NAME = 4};const flatbuffers::String *name() const {return GetPointer<const flatbuffers::String *>(VT_NAME);}bool Verify(flatbuffers::Verifier &verifier) const {return VerifyTableStart(verifier) &&VerifyOffset(verifier, VT_NAME) &&verifier.VerifyString(name()) &&verifier.EndTable();}
};struct StudentBuilder {typedef Student Table;flatbuffers::FlatBufferBuilder &fbb_;flatbuffers::uoffset_t start_;void add_name(flatbuffers::Offset<flatbuffers::String> name) {fbb_.AddOffset(Student::VT_NAME, name);}explicit StudentBuilder(flatbuffers::FlatBufferBuilder &_fbb): fbb_(_fbb) {start_ = fbb_.StartTable();}flatbuffers::Offset<Student> Finish() {const auto end = fbb_.EndTable(start_);auto o = flatbuffers::Offset<Student>(end);return o;}
};inline flatbuffers::Offset<Student> CreateStudent(flatbuffers::FlatBufferBuilder &_fbb,flatbuffers::Offset<flatbuffers::String> name = 0) {StudentBuilder builder_(_fbb);builder_.add_name(name);return builder_.Finish();
}inline flatbuffers::Offset<Student> CreateStudentDirect(flatbuffers::FlatBufferBuilder &_fbb,const char *name = nullptr) {auto name__ = name ? _fbb.CreateString(name) : 0;return qcraft::CreateStudent(_fbb,name__);
}} // namespace qcraft
Cap'n proto
Cap'n Proto is an insanely fast data interchange format and capability-based RPC system.
Cap'n protocol由Protobuf的主要设计者kentonv主导,等价于Protobuf + RPC。提供序列化/反序列化、方法调用、异步Promise流水行等主要功能。
Cap'n Proto 相比 Protobuf 到底有多快呢?10 倍?100 倍?1000倍?官网给出了一张对比图:

特点
- 无encoding/decoding,基于内存布局的编码使得Cap'n Protocol的Structure可以直接写到磁盘上,以二进制文件的形式直接读出。这样在序列化/反序列化过程中,性能将大大提升。
- 异步Promise PipeLine(如下图),传统RPC实现 foo + bar 调用,需要3个步骤: 调用foo,得到返回值x,调用bar(x)。Async Promise Pipelie,不需要返回X这个中间结果,而是一下将请求发送给Server端,server端只需要返回一个Promise即可。

- Four Level RPC:作者将功能划分为4个Level,从低到高分别是Object references and promise pipelining、Persistent capabilities、Three-way interactions、Reference equality / joining,目前最新版0.9.1实现了前两个(Leve1和Leve2),作者给出的公告中说再1.0.0版本将实现 Three-way interactions(三向引用)。
Capnp组件图
capnp基于kj异步框架,使用promise、rpc功能。

优缺点
优点:
- 无encode和decode。
- 异步Promise PipeLine。
缺点:
- 不支持广播、组播。
- 无服务动态方法。
- 无Qos
- 无加密传输
- 没有E2E安全校验
Cap'n proto实现了一套简单的Ez(easy promise base rpc),只适用于简单的点对点通信场景。但是复杂场景下的通信,比如系统状态广播这种,无法原生支持。目前版本,同系统内的进程间通信,仍然是socket通信,效率不高。并且没有服务发现功能,在跨域的通信场景下,与其他方式比如(someip)相比,目前的版本下无明显的优势。
使用样例
idl文件:*.capnp, 以student.capnp为例:
@0xead5e4c3b2579756;$import "/capnp/c++.capnp".namespace("qcraft");struct Student {name @0 :List(Text);
}
https://capnproto.org/capnp-tool.html
capnp compile -oc++ student.capnp生成student.capnp.h和student.capnp.c++。
eProsima Fast Buffers
eProsima Fast Buffers是一款针对性能进行了优化的序列化引擎,针对简单结构和复杂结构都击败了 Apache Thrift 和Google Protocol Buffers。
eProsima Fast Buffers根据接口描述语言(IDL)中的定义为结构化数据生成序列化代码。如果在运行时需要动态类型定义,可以使用eProsima Dynamic Fast Buffers。
eProsima Dynamic Fast Buffers
eProsima Dynamic Fast Buffers是一个高性能序列化库,使用了与传统序列化框架不同的方
在传统的序列化框架中,例如eProsima Fast Buffers, Google Protocol Buffers或嵌入在产品中的如Apache Thrift,用户需要在IDL中定义序列化的数据类型,然后使用IDL编译器解析该文件以生成序列化代码,以将其添加到应用程序源文件并进行最终编译。
对于eProsima Dynamic Fast Buffers,数据类型通过应用代码中友好的API进行定义,并且序列化支持在运行时生成。该框架生成序列化“字节码”非常高效,与传统方式相比只增加大约20%的性能开销。
有几种情况需要这种方式:
- 您想要使用现有的应用程序的数据类型:想象一下您已经有一个正在工作的应用,您希望使用已经存在的数据类型进行发布,传统的序列化框架要强制您创建IDL并使用生成的数据类型。eProsima Dynamic Fast Buffers允许您使用自己的数据类型,从而省去了来回拷贝生成数据类型的麻烦。
- 数据类型结构事先不知道,例如用户定义的数据类型,动态发现的结构(数据库管理,远程自描述服务等),序列化反射(reflection)的对象等。
- 为了简单起见,您不想维护IDL文件。
使用样例
idl文件:*.idl, 以 HelloWorld.idl 为例:
struct HelloWorld
{string message;
};生成对应HelloWorld.h和HelloWorld.cpp, 下文是HelloWorld.h:
/************************************************************************** Copyright (c) 2013 eProsima. All rights reserved.** This generated file is licensed to you under the terms described in the* FAST_BUFFERS_LICENSE file included in this Fast Buffers distribution.*************************************************************************** * @file HelloWorld.h* This header file contains the declaration of the described types in the IDL file.** This file was generated by the tool fastbuffers.*/#ifndef _HelloWorld_H_
#define _HelloWorld_H_// TODO Poner en el contexto.#include <stdint.h>
#include <array>
#include <string>
#include <vector>#if defined(_WIN32)
#if defined(EPROSIMA_USER_DLL_EXPORT)
#define eProsima_user_DllExport __declspec( dllexport )
#else
#define eProsima_user_DllExport
#endif
#else
#define eProsima_user_DllExport
#endifnamespace eprosima
{namespace fastcdr{class Cdr;}
}/*!* @brief This class represents the structure HelloWorld defined by the user in the IDL file.* @ingroup HELLOWORLD*/
class eProsima_user_DllExport HelloWorld
{
public:/*!* @brief Default constructor.*/HelloWorld();/*!* @brief Default destructor.*/~HelloWorld();/*!* @brief Copy constructor.* @param x Reference to the object HelloWorld that will be copied.*/HelloWorld(const HelloWorld &x);/*!* @brief Move constructor.* @param x Reference to the object HelloWorld that will be copied.*/HelloWorld(HelloWorld &&x);/*!* @brief Copy assignment.* @param x Reference to the object HelloWorld that will be copied.*/HelloWorld& operator=(const HelloWorld &x);/*!* @brief Move assignment.* @param x Reference to the object HelloWorld that will be copied.*/HelloWorld& operator=(HelloWorld &&x);/*!* @brief This function sets a value in member message* @param _message New value for member message*/inline void message(std::string _message){m_message = _message;}/*!* @brief This function returns the value of member message* @return Value of member message*/inline std::string message() const{return m_message;}/*!* @brief This function returns a reference to member message* @return Reference to member message*/inline std::string& message(){return m_message;}/*!* @brief This function returns the maximum serialized size of an object* depending on the buffer alignment.* @param current_alignment Buffer alignment.* @return Maximum serialized size.*/static size_t getMaxCdrSerializedSize(size_t current_alignment = 0);/*!* @brief This function serializes an object using CDR serialization.* @param cdr CDR serialization object.*/void serialize(eprosima::fastcdr::Cdr &cdr) const;/*!* @brief This function deserializes an object using CDR serialization.* @param cdr CDR serialization object.*/void deserialize(eprosima::fastcdr::Cdr &cdr);private:std::string m_message;
};#endif // _HelloWorld_H_
Apache Avro
avro是RPC和数据序列化系统(data serialization system),使用JSON定义数据类型及通信协议,使用压缩二进制来序列化数据,是Hadoop持久化数据的一种序列化格式。
Apache Thrift
Thrift是一个轻量级、跨语言的远程服务调用框架,最初由Facebook开发,后面进入Apache开源项目。它通过自身的IDL中间语言, 并借助代码生成引擎生成各种主流语言的RPC服务端/客户端模板代码。Thrift支持多种不同的编程语言,包括C++、Java、Python、PHP、Ruby等,本系列主要讲述基于Java语言的Thrift的配置方式和具体使用。
使用样例
idl文件:*.thrift, 以 test.thrift为例:
namespace cpp qcraftstruct Record {1: required list<i64> ids,2: required list<string> strings
}thrift --gen <language> <Thrift filename>生成源码
Apache Thrift系列详解
Others
boost,msgpack,cereal和yas等序列化工具库,无需idl文件。
各种序列化工具性能评测
Size

Times

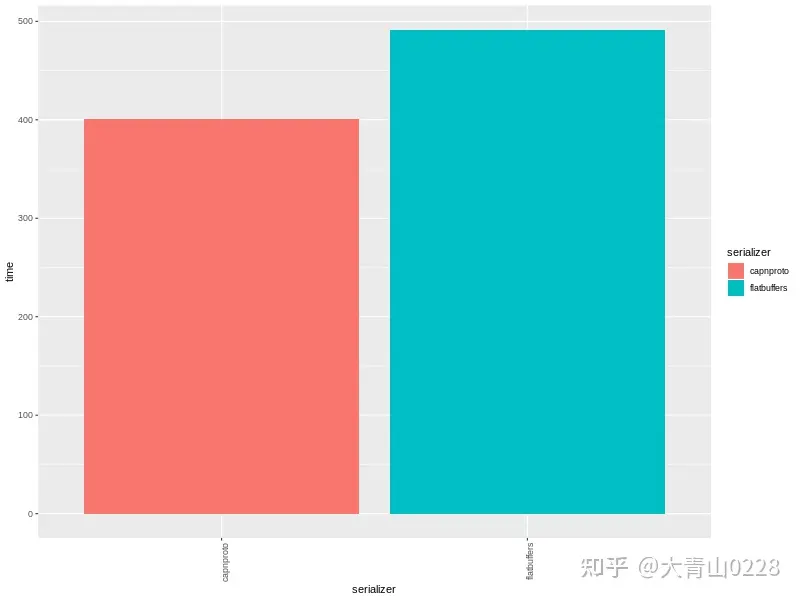
对于Cap'n proto和Flatbuffers,因为它们已经以“序列化”的形式存储数据,并且序列化基本上意味着获取指向内部存储的指针,因此我们测量完整的构建/序列化/反序列化周期。在排除其他库的情况下,我们测量已经构建好的数据结构的序列化/反序列化执行周期。
| serializer | object's size(bytes) | avg. total time (ms) |
| capnproto | 17768 | 400.98 |
| flatbuffers | 17632 | 491.5 |
Protobuf 作者不建议在 Deno 中使用 Protobuf
I was surprised by the choice of Protobuf for intra-process communications within Deno. Protobuf's backwards compatibility guarantees and compact wire representation offer no benefit here, while the serialize/parse round-trip on every I/O seems like it would be pretty expensive.
大概意思是:kentonv 对于 Deno 选择 Protobuf 感到很吃惊,因为 Protobuf 的兼容性优势并不是 Deno 需要的,相反,Protobuf 的序列化和反序列化非常消耗 I/O 性能。
相关文章:
[转载]C++序列化框架介绍和对比
Google Protocol Buffers Protocol buffers 是一种语言中立,平台无关,可扩展的序列化数据的格式,可用于通信协议,数据存储等。 Protocol buffers 在序列化数据方面,它是灵活的,高效的。相比于 XML 来说&…...

分类预测 | Matlab实现KOA-CNN-BiLSTM-selfAttention多特征分类预测(自注意力机制)
分类预测 | Matlab实现KOA-CNN-BiLSTM-selfAttention多特征分类预测(自注意力机制) 目录 分类预测 | Matlab实现KOA-CNN-BiLSTM-selfAttention多特征分类预测(自注意力机制)分类效果基本描述程序设计参考资料 分类效果 基本描述 1…...

浮点数和定点数(上):怎么用有限的Bit表示尽可能多的信息?
目录 背景 浮点数的不精确性 定点数的表示 浮点数的表示 小结 背景 在我们日常的程序开发中,不只会用到整数。更多情况下,我们用到的都是实数。比如,我们开发一个电商 App,商品的价格常常会是 9 块 9;再比如&…...
一文详解汽车电子LIN总线
0.摘要 汽车电子LIN总线不同于CAN总线。 LIN总线基本上是CAN总线的廉价补充,相比于CAN总线,它提供较低的可靠性和性能。同时LIN总线也是一个应用非常广泛的网络协议,并且越来越受欢迎。 再一次,我们准备了一个关于LIN总线的简要…...
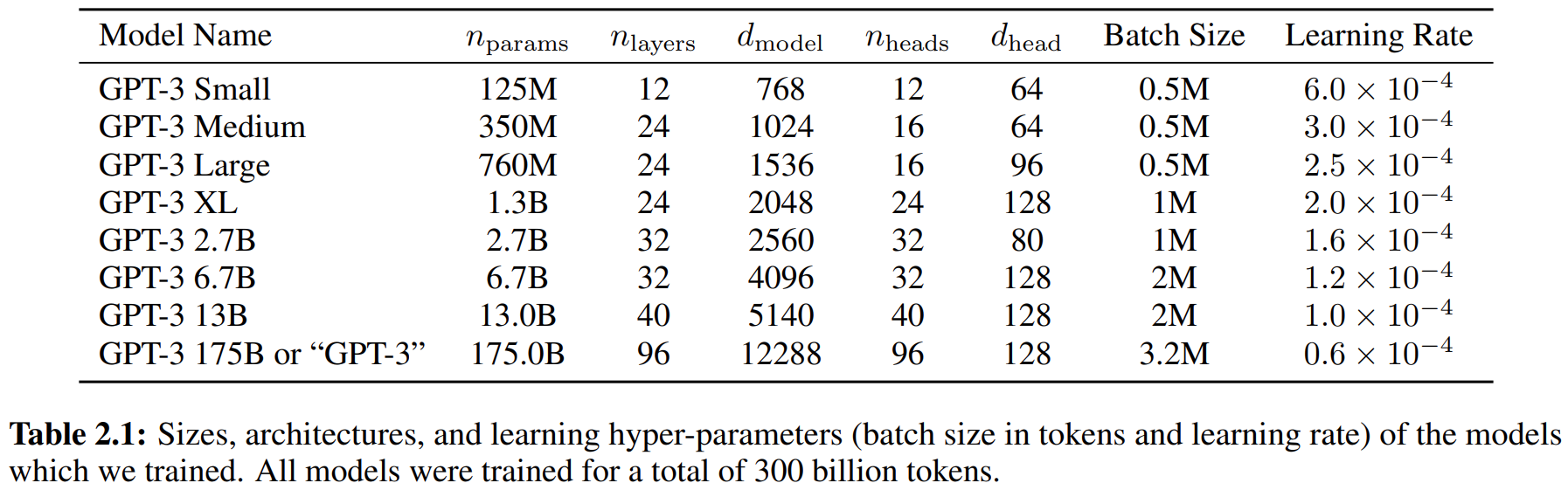
论文阅读——GPT3
来自论文:Language Models are Few-Shot Learners Arxiv:https://arxiv.org/abs/2005.14165v2 记录下一些概念等。,没有太多细节。 预训练LM尽管任务无关,但是要达到好的效果仍然需要在特定数据集或任务上微调。因此需要消除这个…...
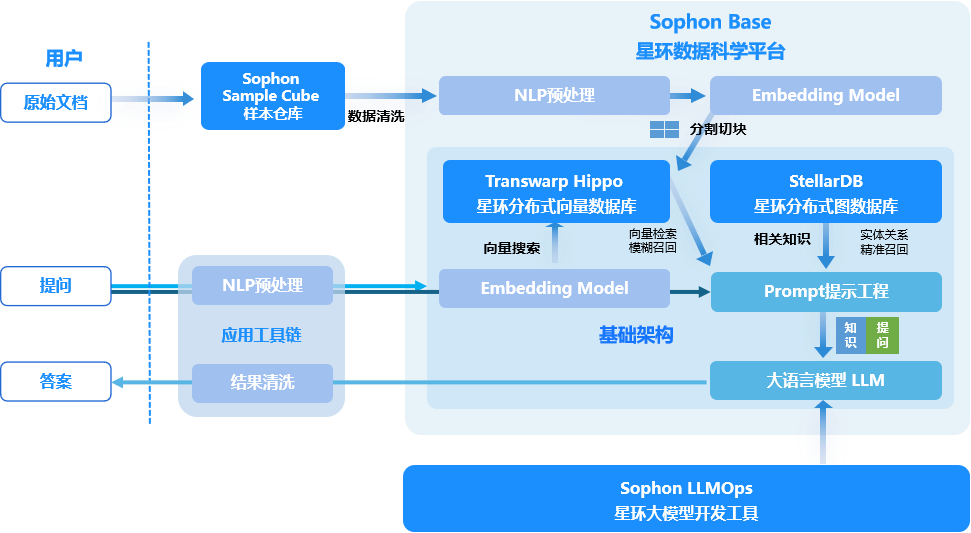
星环科技分布式向量数据库Transwarp Hippo正式发布,拓展大语言模型时间和空间维度
随着企业、机构中非结构化数据应用的日益增多以及AI的爆发式增长所带来的大量生成式数据,所涉及的数据呈现了体量大、格式和存储方式多样、处理速度要求高、潜在价值大等特点。但传统数据平台对这些数据的处理能力较为有限,如使用文件系统、多类不同数据…...
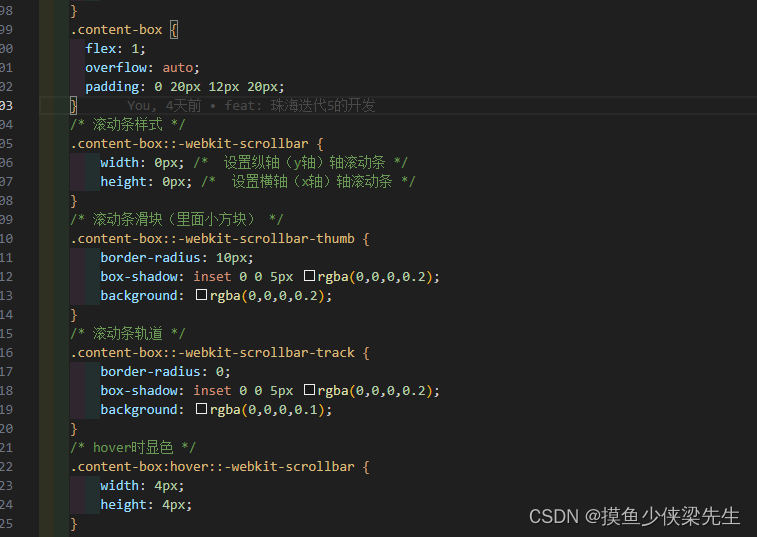
滚动条默认是隐藏的只有鼠标移上去才会显示
效果 在设置滚动条的类名中写 /* 滚动条样式 */.content-box::-webkit-scrollbar {width: 0px; /* 设置纵轴(y轴)轴滚动条 */height: 0px; /* 设置横轴(x轴)轴滚动条 */}/* 滚动条滑块(里面小方块) */.…...
Go学习第十五章——Gin参数绑定bind与验证器
Go web框架——Gin(参数绑定bind与验证器) 1 bind参数绑定1.1 JSON参数1.2 Query参数1.3 Uri绑定动态参数1.4 ShouldBind自动绑定 2 验证器2.1 常用验证器2.2 gin内置验证器2.3 自定义验证的错误信息2.4 自定义验证器 1 bind参数绑定 在Gin框架中&#…...

EtherCAT的4种寻址方式解析
我们知道,一个EtherCAT数据帧(frame)里面包含很多个报文(datagram),不管是什么样式的报文,它们的目的只有一个,就是读写从站寄存器或内存。所以寻址就是以什么方式访问哪个从站的哪个…...
Trino 源码剖析
Functions function 反射和注册 io.trino.operator.scalar.annotations.ScalarFromAnnotationsParser 这里是提取注解元素的方法 String baseName scalarFunction.value().isEmpty() ? camelToSnake(annotatedName(annotated)) : scalarFunction.value(); 这里如果 scala…...

element表格自定义筛选
文章目录 前言一、简介二、效果展示三、源码总结 前言 提示:这里可以添加本文要记录的大概内容: …待续 提示:以下是本篇文章正文内容,下面案例可供参考 一、简介 修改el-table的筛选…待续 二、效果展示 三、源码 使用方法…...

全方位 Linux 性能调优经验总结
Part1Linux性能优化 1性能优化 性能指标 高并发和响应快对应着性能优化的两个核心指标:吞吐和延时 图片来自: www.ctq6.cn 应用负载角度:直接影响了产品终端的用户体验系统资源角度:资源使用率、饱和度等 性能问题的本质就是系统资源已经…...

Linux机器网络检查
查看DNS file: dianTestLRSSnapshot:~$ cat /etc/resolv.conf # This file is managed by man:systemd-resolved(8). Do not edit. # # This is a dynamic resolv.conf file for connecting local clients to the # internal DNS stub resolver of systemd-resolved. This file…...

使用示例和应用程序全面了解高效数据管理的Golang MySQL数据库
Golang,也被称为Go,已经成为构建强大高性能应用程序的首选语言。在处理MySQL数据库时,Golang提供了一系列强大的库,简化了数据库交互并提高了效率。在本文中,我们将深入探讨一些最流行的Golang MySQL数据库库ÿ…...

ubuntu 22.04 源码安装 apollo 8.0
对于其他的关于GPU的安装包需求,这里不再列出,因为我之前安装过,偷个懒就不写了,哈哈哈哈1, 安装docker 安装docker命令(这里的安装命令都是在docker官网,还有安装包): 1, 设置docker的apt仓库 # Add Do…...

RK3588编译MXNet框架
目录 1. 背景 2.编译MXNet准备 3.开发板编译 1. 背景 MXNet(也称为Apache MXNet或incubator-mxnet)是一个开源的深度学习框架,它最初由华为和亚马逊AWS共同开发,并于2017年成为Apache软件基金会的孵化项目。MXNet旨在提供高效、…...

港府Web3宣言周年思考:合规困境中的“隐患”
出品|欧科云链研究院 作者|毕良寰 距离《有关虚拟资产在港发展的政策宣言》已过去一年,我们欧科云链研究院在分析全球几个主要国家和地区对Web3的监管政策及态度后,对港府的雄心壮志充满期待。然而,由于近期一些庞氏骗…...

vue点击按钮跳转页面
在Vue.js中,你可以使用<router-link>或this.$router.push()来实现点击按钮跳转页面的功能,前提是你已经配置了Vue Router。以下是两种不同的方法来实现页面跳转: 方法一:使用<router-link> <router-link> 是Vu…...

大中小企业对CRM系统的需求
在以前,CRM客户管理系统是大型企业的专属。如今,不论何种规模的企业都能够使用CRM系统。市面上的CRM有着丰富的功能类型,管理者可以从企业自身规模出发,选择适合的CRM系统。下面说说,大中小企业对CRM系统的需求。 一句…...

.net core iis 发布后登入的时候请求不到方法报错502
.net core iis 发布后登入的时候请求不到方法报错502 502 bad gateway 502 - Web 服务器在作为网关或代理服务器时收到了无效响应。 您要查找的页面有问题,无法显示。当 Web 服务器(作为网关或代理)与上游内容服务器联系时,收到来自内容服务器的无效…...

Video2X:你的AI视频画质修复专家,让老旧视频重获新生
Video2X:你的AI视频画质修复专家,让老旧视频重获新生 【免费下载链接】video2x A machine learning-based video super resolution and frame interpolation framework. Est. Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trendin…...

Ubuntu下编译与测试libwebsockets:从x86环境验证到嵌入式移植
1. 项目概述与背景 在嵌入式开发中,尤其是涉及到网络通信模块时,我们常常会遇到一个典型的困境:直接在资源受限的目标板(比如ARM架构的开发板)上进行代码的编译、调试和功能验证,过程往往非常痛苦。编译速…...

3分钟掌握ncmdump:网易云音乐NCM文件终极解密方案
3分钟掌握ncmdump:网易云音乐NCM文件终极解密方案 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM格式音乐无法在其他播放器使用而烦恼吗?ncmdump这款免费开源工具正是你的完美解决…...

【免费下载】 探索双面神技:STM32G474的USB跨界应用
探索双面神技:STM32G474的USB跨界应用 在物联网与嵌入式开发的世界里,寻找一款能兼顾数据传输与控制沟通的神器是每个开发者的心头好。今天,我们就来揭秘这样一个宝藏项目——STM32G474实现USB的MSCCDC组合功能,它巧妙地将STM32G4…...
)
数据结构第8章查找:单元测试15题全解析(顺序查找+折半查找+分块查找+哈希查找)
第8章 查找 单元测试1. 线性表只有以( A )方式存储,才能进行折半查找。A. 顺序B. 链接C. 二叉树D. 关键字有序的2. 有序表为{2,4,10,13,33,42,46,64&#x…...

思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析
思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版烦恼吗?字体选择困…...

Watchify常见问题解决方案:解决监视失败的7个实用技巧
Watchify常见问题解决方案:解决监视失败的7个实用技巧 【免费下载链接】watchify watch mode for browserify builds 项目地址: https://gitcode.com/gh_mirrors/wa/watchify Watchify作为Browserify的监视模式工具,能在文件变化时自动重新构建&a…...

《Kubernetes应用篇:使用Helm工具部署mongodb 8.2.7副本集群》
总结:整理不易,如果对你有帮助,可否点赞关注一下? 更多详细内容请参考:《K8S集群运维指南》 一、简介 使用Helm结合Bitnami Chart是部署生产级mongodb到Kubernetes集群的事实标准方案。整个过程高度自动化,可以极大地简化运维复杂度。 在实际生产环境中,为了保障稳定运…...

NotebookLM赋能图书馆学研究:3大颠覆性应用+5个未公开工作流
更多请点击: https://kaifayun.com 第一章:NotebookLM赋能图书馆学研究:范式跃迁与学科再定义 传统图书馆学长期依托文献分类、编目规则与用户行为统计等静态分析范式,而NotebookLM作为Google推出的基于引用感知(cita…...

CODESYS硬件平台适配实战:从实时系统到工业控制生态
1. 项目概述:一次工业控制领域的“握手”最近,我们团队完成了一次与CODESYS技术团队的关键联合调测。这次调测的核心,是将我们自主研发的嵌入式硬件平台,与全球领先的工业自动化软件框架CODESYS进行深度适配与验证。对于不熟悉工业…...