【数据结构】二叉树的四种遍历方式——必做题

写在前面
学完上一篇文章的二叉树的遍历之后,来尝试下面的习题吧
开始做题
144. 二叉树的前序遍历 - 力扣(LeetCode)
94. 二叉树的中序遍历 - 力扣(LeetCode)
145. 二叉树的后序遍历 - 力扣(LeetCode)
为什么将这三道题放在一起呢?因为只要你学会了前序遍历,那么中序和后序遍历就自然不在话下(修改递归顺序),我就不写三个解析水字数了😅,一箭三雕,举一反三的时刻到了😁
敬告:先去做完,再看解析。为方便判错,力扣上的题加了很多限制,有些变量必要难以理解
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
题目简简单单就一句话,正是上一篇文章所讲的代码,但是参数却有些让人看不懂,我们通常这样写
void preorderTraversal(struct TreeNode* root)
{if (root == NULL) return; // 如果节点为空,返回printf("%d ", root->val); // 先访问根节点preorderTraversal(root->left); // 再递归遍历左子树preorderTraversal(root->right); // 最后递归遍历右子树但是力扣上的解析大都是这样的,为什么?
void PreOrder(struct TreeNode* root,int* arr,int* returnSize)
{if(root==NULL) return;arr[(*returnSize)++]=root->val;PreOrder(root->left,arr,returnSize);PreOrder(root->right,arr,returnSize);
}int* preorderTraversal(struct TreeNode* root, int* returnSize)
{int *arr=malloc(sizeof(int)*2000); //定义数组,用于存储遍历的返回值*returnSize=0;PreOrder(root,arr,returnSize);return arr;
}原因:要求不同造成,需要更多参数;
首先这道题不像上一篇文章我们写的那样,直接打印出来结点数值,而力扣要求将结点数值存进一个数组,返回时还得返回整个数组,这样我们就得先定义一个数组arr ,又因为需要malloc,故需要将数组定义成指针的形式;
那returnSize的意思就是数组的长度,为什么要用指针呢?因为只有传值调用,指针接收,才能通过函数内returnSize的改变,进而影响returnSize被原本值,在这里初始值设为0就很巧妙,因为可以当成数组的下标;
至于前序遍历在这里就可以必须要时刻更新这三个参数,干脆就直接再封装成一个函数来进行递归调用。
中序遍历和后序遍历就很简单了,一箭三雕,举一反三的时刻到了😁
102. 二叉树的层序遍历 - 力扣(LeetCode)
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
解析:这道题的难度有点大,耐心做
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*//*** Return an array of arrays of size *returnSize.* The sizes of the arrays are returned as *returnColumnSizes array.* Note: Both returned array and *columnSizes array must be malloced, assume caller calls free().*///用队列的顺序存储结构来实现,本身问题很简单,但上面的三条英文注释让整个题变得不简单起来
/*补充知识:二位动态整形数组的申请方法
int** arr=(int **)malloc(sizeof(int*)*3000);
arr[*returnSize] = (int*)malloc(sizeof(int) * (rear-front));
*/
int** levelOrder(struct TreeNode* root, int* returnSize, int** returnColumnSizes)
{*returnSize=0; //数组大小设置为0if(root==NULL) //根结点为空,没有遍历的必要,直接返回空return NULL;struct TreeNode *queue[3000]; //定义一个队列int **arr=(int**)malloc(sizeof(int*)*3000),front=0,rear=0;//定义一个二维数组*returnColumnSizes=(int*)malloc(sizeof(int)*3000);//根结点入队queue[rear++]=root;while(front!=rear)//这个是大循环{int temp=rear,k=0;arr[*returnSize] = (int*)malloc(sizeof(int) * (rear-front));while(front<temp)//rear会变化{struct TreeNode *p=queue[front++];//出队arr[*returnSize][k++] = p->val;if(p->left) //如果左结点不空,左节点入队{queue[rear++]=p->left;}if(p->right) //如果右节点不空,右节点入队{queue[rear++]=p->right;}}(*returnColumnSizes)[*returnSize] = k;(*returnSize)++;}return arr;
}问:这段代码中returnSize和returnColumnSizes是什么意思?
returnSize是一个指向整数的指针,用于存储二维数组arr的行数,即层序遍历结果的大小。在函数执行完毕后,通过修改returnSize来告知调用者结果的大小。
returnColumnSizes是一个指向整数指针的指针,用于存储每一层中节点的数目。
returnColumnSizes的指向的整数数组的大小应与arr的行数相同,即表示每一行中节点的数目。由于每一层的节点数目不同,因此我们需要动态分配一个整数数组来存储每一层中节点的数目。函数执行完毕后,returnColumnSizes指向的整数数组将包含每一层中节点的数目。
需要注意的是,如果函数中没有任何一层节点,那么returnSize将为0,而returnColumnSizes指向的数组应为NULL。
问:为什么前者使用一级指针,后者使用二级指针?
在这段代码中,returnSize使用一级指针,而returnColumnSizes使用二级指针,是因为它们所表示的信息不同。
returnSize指向的是整数类型的变量,用于表示层序遍历结果的行数,是一个单独的变量。因此,我们只需要通过一级指针将这个变量传递给函数,函数就可以修改这个变量的值,从而返回结果的行数。
returnColumnSizes指向的是整数类型的指针数组,用于表示每一行中节点的数目,是一个数组。由于这个数组的大小在函数调用时未知,因此我们需要使用二级指针将它传递给函数。在函数内部,我们需要先分配一个整数类型的数组,然后将这个数组的地址存储到returnColumnSizes所指向的地址中。因此,我们需要使用二级指针。
int** arr=(int **)malloc(sizeof(int*)*3000);
arr[*returnSize] = (int*)malloc(sizeof(int) * (rear-front));
第一行代码定义了一个名为arr的指向指针的指针变量,分配了一个大小为sizeof(int*)3000字节的内存,该内存用于存储二维数组的每个一维数组的地址
第二行代码则是为二维数组的一维数组分配内存,通过指针访问到第returnSize行,然后调用malloc函数分配一块大小为sizeof(int) * (rear-front)字节的内存,该内存用于存储一维数组中的元素,返回值为一维数组的首地址,使用强制类型转换将其转换为int类型,最后存储在arr[*returnSize]中,用于后续的访问。
写在最后
👍🏻 点赞,你的认可是我创作的动力!
⭐ 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富!
相关文章:
【数据结构】二叉树的四种遍历方式——必做题
写在前面学完上一篇文章的二叉树的遍历之后,来尝试下面的习题吧开始做题144. 二叉树的前序遍历 - 力扣(LeetCode)94. 二叉树的中序遍历 - 力扣(LeetCode)145. 二叉树的后序遍历 - 力扣(LeetCode)…...

Nginx使用“逻辑与”配置origin限制,修复CORS跨域漏洞
目录1.漏洞报告2.漏洞复现3.Nginx 修复3.1 添加请求头3.2 配置origin限制2.3 调整origin限制1.漏洞报告 漏洞名称: CORS 跨域漏洞等级: 中危漏洞证明: Origin从任何域名都可成功访问,未做任何限制。漏洞危害: 因为同源…...
Laravel框架02:路由与控制器
Laravel框架02:路由与控制器一、路由配置文件二、路由参数三、路由别名四、路由群组五、控制器概述六、控制器路由七、接收用户输入一、路由配置文件 以web网页路由文件为例: 默认根路由 路由定义格式Route::请求方式(请求的URL, 匿名函数或控制响应的方…...
)
【POJ 2418】Hardwood Species 题解(映射)
描述 阔叶树是一种植物群,具有宽阔的叶子,结出果实或坚果,通常在冬天休眠。 美国的温带气候造就了数百种阔叶树种的森林,这些树种具有某些生物特征。例如,虽然橡树、枫树和樱桃都是硬木树,但它们是不同的物…...
)
React组件之间的通信方式总结(下)
一、写一个时钟 用 react 写一个每秒都可以更新一次的时钟 import React from react import ReactDOM from react-domfunction tick() {let ele <h1>{ new Date().toLocaleTimeString() }</h1>// Objects are not valid as a React child (found: Sun Aug 04 20…...
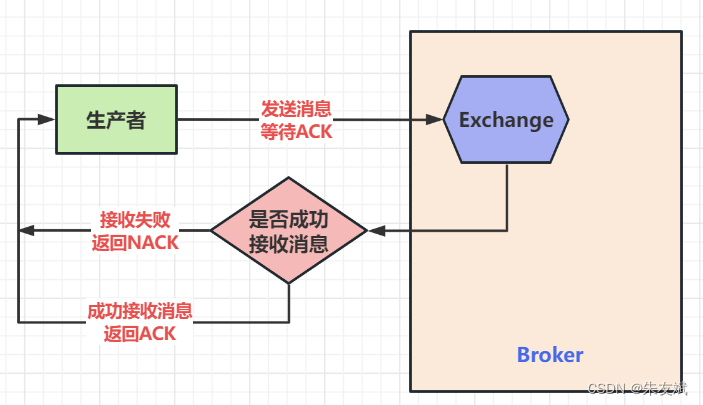
【RabbitMQ笔记07】消息队列RabbitMQ七种模式之Publisher Confirms发布确认模式
这篇文章,主要接收消息队列RabbitMQ七种模式之Publisher Confirms发布确认模式。 目录 一、消息队列 1.1、发布确认模式 1.2、案例代码 (1)引入依赖 (2)编写生产者【消息确认--单条确认】 (3…...

【华为OD机试模拟题】用 C++ 实现 - IPv4 地址转换成整数(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 去重求和(2023.Q1) 文章目录 最近更新的博客使用说明IPv4 地址转换成整数题目输入输出示例一输入输出说明示例一输入输出说明Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,...

闭包与高阶函数
文中内容均来自于曾探《JavaScript设计模式与开发实践》的学习笔记。闭包作用域变量的作用域,就是指变量的有效范围。局部变量、全局变量。变量的搜索是从内到外而非从外到内的。变量的生命周期对于全局变量莱索,全局变量的生命周期是永久的,…...

人工智能轨道交通行业周刊-第35期(2023.2.20-2.26)
本期关键词:重庆智慧轨道、智能运维主机、标准轨距、地方铁路公报、景深、机器视觉应用 1 整理涉及公众号名单 1.1 行业类 RT轨道交通人民铁道世界轨道交通资讯网铁路信号技术交流北京铁路轨道交通网上榜铁路视点ITS World轨道交通联盟VSTR铁路与城市轨道交通Rai…...

快慢指针判断链表是否有环
快慢指针判断链表是否有环 单链表有可能存在环,有些情况下要判断一个单链表是否有环。数组的有个快慢指针的方法,其实单链表和数组有相似的地方,可以使用快慢指针的方法。具体做法如下: 首先创建两个指针,它们初始时…...

《MongoDB入门教程》第26篇 聚合统计之$max/$min表达式
本文将会介绍两个 MongoDB 表达式,返回一组数据中最大值的 $max 表达式,以及返回一组数据中最小值的 $min 表达式。 $max 表达式 $max 表达式用于返回一组数据中的最大值,语法如下: { $max: <expression> }$max 表达式在…...

FPGA纯verilog解码SDI视频 纯逻辑资源实现 提供2套工程源码和技术支持
目录1、前言2、硬件电路解析SDI摄像头Gv8601a单端转差GTX解串SDI解码VGA时序恢复YUV转RGB图像输出FDMA图像缓存HDMI输出3、工程1详解:无缓存输出4、工程2详解:缓存3帧输出5、上板调试验证并演示6、福利:工程代码的获取1、前言 FPGA实现SDI视…...
JVM篇之垃圾回收
一.如何判断对象可以回收 1.引用计数法 只要一个对象被其他变量所引用,就让它的计数加1,被引用了两次就让它的计数变成2,当这个变量的计数变成0时,就可以被垃圾回收; 弊端:当出现如下图的情况࿰…...

尝试用程序计算Π(3.141592653......)
文章目录1. π\piπ2. 用微积分来计算π\piπ2.1 原理2.2 代码2.3 结果2.4 分析1. π\piπ π\piπ的重要性或者地位不用多说,有时候还是很好奇,精确地π\piπ值是怎么计算出来的。研究π\piπ的精确计算应该是很多数学家计算机科学家努力的方向…...

【异常检测三件套】系列3--时序异常检测综述
写在前面: 异常检测共包含3个内容,从多个方面剖析异常检测方法,本文为第三篇。过往内容请查看以下链接: 【异常检测三件套】系列1--14种异常检测算法https://blog.csdn.net/allein_STR/article/details/128114175?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%…...

关于SAP 错误日志解析
有时候启动或操作sap会出现故障,只是察看sap用户当前目录下的日志文件可能不得要领,此时有必要察看work目录下的一些trace. 以Linux系统为例,其他的也差不多。 instance说明 如下 DVEBMGS?? ABAP Central Instance D?? …...
java:自定义变量加载到系统变量后替换shell模版并执行shell
这里的需求前提是,在项目中进行某些操作前,需要在命令后对shell配置文件的进行修改(如ip、port),这个对于用户是不友好的,需要改为用户页面输入ip、port,后台自动去操作修改配置;那么…...
Redis高级删除策略与数据淘汰
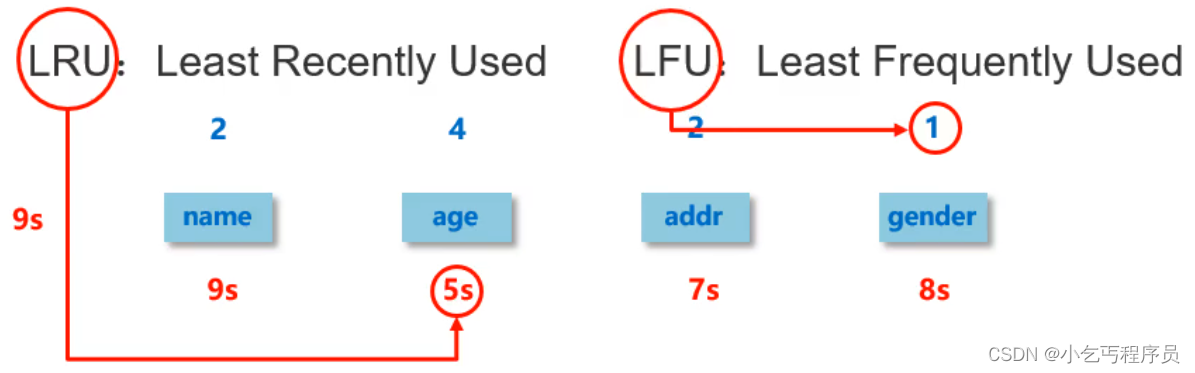
第二章:Redis高级 学习目标 目标1:能够说出redis中的数据删除策与略淘汰策略 目标2:能够说出主从复制的概念,工作流程以及场景问题及解决方案 目标3:能够说出哨兵的作用以及工作原理,以及如何启用哨兵 …...
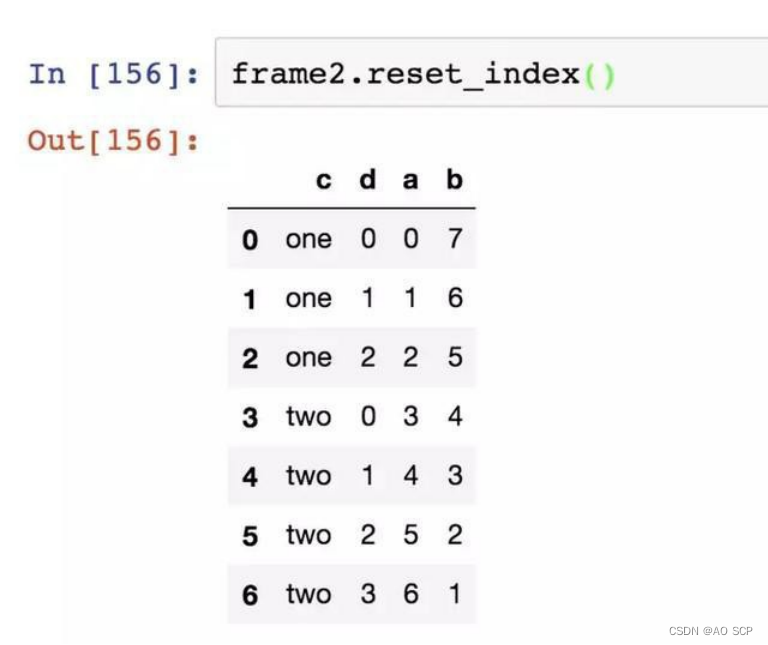
社畜大学生的Python之pandas学习笔记,保姆入门级教学
接上期,上篇介绍了 NumPy,本篇介绍 pandas。 目录 pandas 入门pandas 的数据结构介绍基本功能汇总和计算描述统计处理缺失数据层次化索引 pandas 入门 Pandas 是基于 Numpy 构建的,让以 NumPy 为中心的应用变的更加简单。 Pandas是基于Numpy…...
20_FreeRTOS低功耗模式
目录 低功耗模式简介 STM32低功耗模式 Tickless模式详解 Tickless模式相关配置 实验源码 低功耗模式简介 很多应用场合对于功耗的要求很严格,比如可穿戴低功耗产品、物联网低功耗产品等。 一般MCU都有相应的低功耗模式,裸机开发时可以使用MCU的低功耗模式。 FreeRTOS也…...
:终极技巧汇总:高级玩家必备的邪修操作)
Excel高效使用技巧(十五):终极技巧汇总:高级玩家必备的邪修操作
“Excel的终极奥义,不是你会多少公式,而是你知道多少’不该用Excel’的时刻,以及如何优雅地让Excel和其他工具联动。” —— 卡兹克 前言:你的Excel到达哪个段位? 经过十四篇文章的洗礼,你现在应该已经掌握了: 数据清洗:Power Query玩得飞起 数据分析:透视表+DAX不在…...

ANSI转义序列封装:cursor-reset库实现终端光标精准控制
1. 项目概述与核心价值 最近在折腾一些自动化工具链,发现一个挺有意思的小项目,叫 zhitrend/cursor-reset 。乍一看名字,你可能会觉得这只是一个重置光标位置的小工具,但实际用下来,我发现它解决的痛点非常精准&…...

别再死记硬背截止、放大、饱和了!用Arduino+面包板,5分钟直观理解NPN/PNP三极管三种状态
用Arduino点亮三极管:5分钟可视化实验理解电子开关的三种状态 你是否曾被三极管的"截止"、"放大"、"饱和"这些术语困扰?教科书上的电压公式和载流子运动图虽然精确,却难以形成直观认知。今天我们将用Arduino和…...

Perplexity Stack Overflow查询响应延迟超8秒?紧急修复指南:从token压缩到领域微调的4层加速方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity Stack Overflow查询响应延迟超8秒?紧急修复指南:从token压缩到领域微调的4层加速方案 当Perplexity在Stack Overflow数据源上出现平均响应延迟 > 8s 的告警时&am…...

i.MX 6UL/6ULL开发环境配置与驱动开发实战
1. i.MX 6UL/6ULL开发环境配置实战1.1 虚拟机环境搭建要点对于Windows平台下的i.MX开发,VirtualBox虚拟机是最经济实惠的选择。根据实际项目经验,建议配置如下:内存至少4GB(复杂项目推荐8GB)硬盘空间预留100GB…...

城市级智慧停车平台建设思路:如何整合多个停车项目的数据
引言随着城市化进程的加速和机动车保有量的持续攀升,"停车难、停车乱"已经成为困扰各大城市的普遍性问题。根据公安部统计数据,截至2025年底,全国机动车保有量已突破4.5亿辆,而城市停车位缺口预计超过8000万个。与此同时…...
:从理论基石到信号分解实战)
经验小波变换(EWT):从理论基石到信号分解实战
1. 经验小波变换(EWT)的前世今生 我第一次接触EWT是在处理一段轴承振动信号时。当时用传统EMD方法分解出的IMF分量里,高频噪声和故障特征频率完全混在一起,就像把咖啡和牛奶搅成了拿铁——虽然都是白色液体,但根本分不…...

Cloudflare + PlanetScale:在边缘运行全栈应用,数据库也不例外
全栈开发者面对的一道老难题 Cloudflare Workers 解决了计算层的全球分发问题——你的代码跑在 Cloudflare 遍布全球的 300 多个数据中心里,离用户近,启动快,不需要管理任何服务器。 但数据不一样。 数据库天然是"有状态的"&#x…...

市场营销Agent:自动生成内容与投放策略
市场营销Agent:自动生成内容与投放策略——从痛点分析到落地实践的全栈指南 引言 痛点引入 在数字营销的战场上,每天都有无数的团队在重复着「内容绞肉机」和「投放试错场」的噩梦: 内容产出端:为了覆盖小红书、抖音、知乎、微信公众号、TikTok、LinkedIn等数十个主流渠…...
用C++实现信奥题 P8563 Magenta Potion)
打卡信奥刷题(3245)用C++实现信奥题 P8563 Magenta Potion
P8563 Magenta Potion 题目描述 给定一个长为 nnn 的整数序列 aaa,其中所有数的绝对值均大于等于 222。有 qqq 次操作,格式如下: 1 i k\texttt{1 i k}1 i k,表示将 aia_iai 修改为 kkk。保证 $k $ 的绝对值大于等于 222。 2 l r…...