JVM篇之垃圾回收
一.如何判断对象可以回收
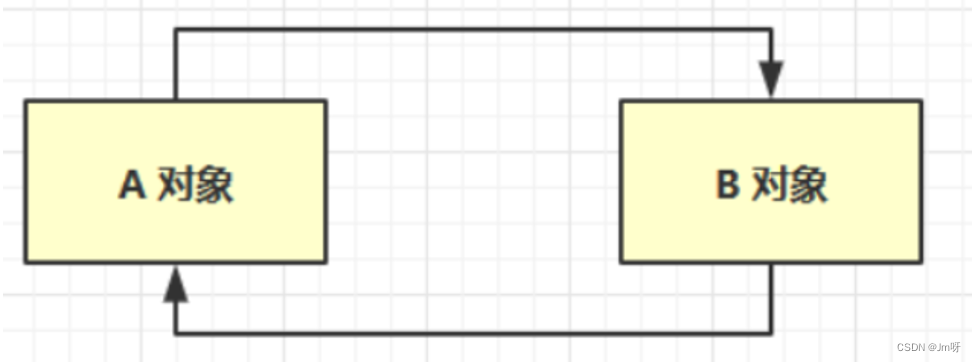
1.引用计数法
只要一个对象被其他变量所引用,就让它的计数加1,被引用了两次就让它的计数变成2,当这个变量的计数变成0时,就可以被垃圾回收;
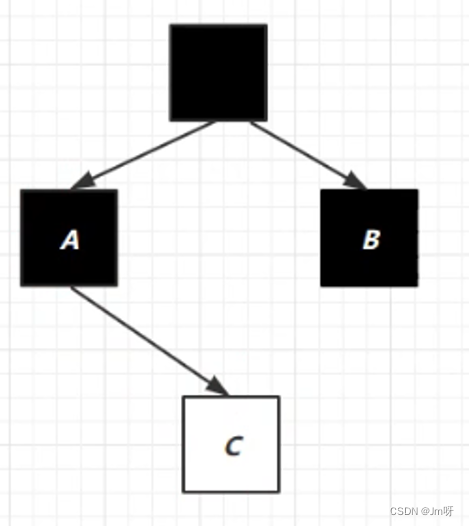
弊端:当出现如下图的情况,A对象引用了B对象,B对象也引用了A对象,所以A,B的计数均为1,但是没有其他的引用它们俩;虽然应该被垃圾回收,但是因为计数不为0,则无法进行回收
2.可达性计数法
-
Java 虚拟机中的垃圾回收器采用可达性分析来探索所有存活的对象
-
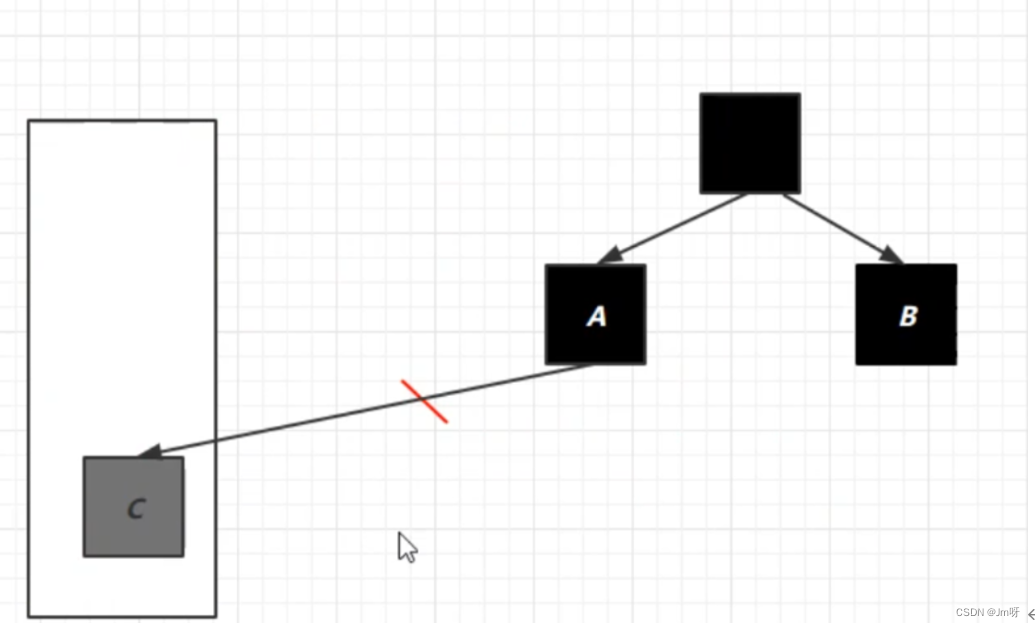
扫描堆中的对象,看是否能够沿着 GC Root对象(根对象) 为起点的引用链找到该对象,找不到,表示可以回收**(就是先确定好一定不会被回收的对象作为根对象,然后查找目标对象是否直接或者间接被根对象所引用)**
-
哪些对象可以作为 GC Root ?
- GCRoot对象包括:虚拟机栈终点局部变量表引用的对象,方法区中类静态属性引用和常量引用对象,本地方法栈中的对象
五种引用(面试常考)
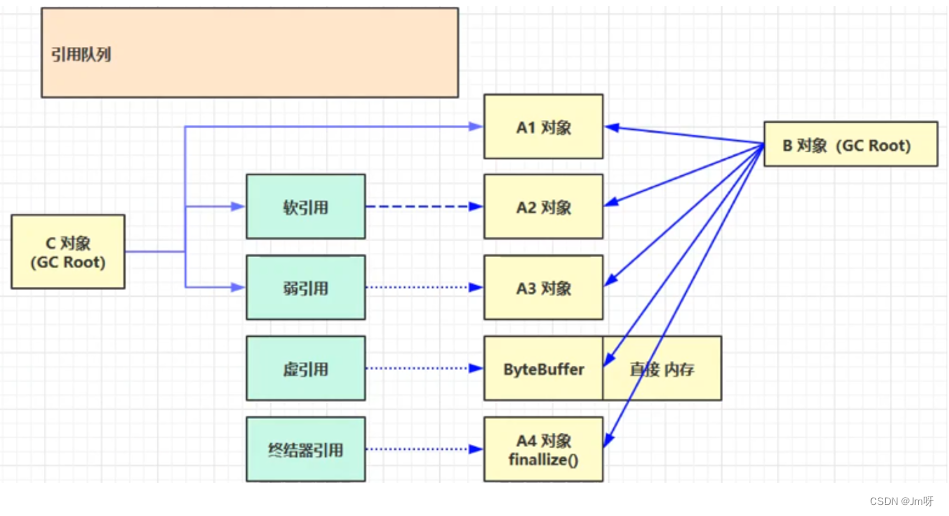
1) 强引用
只有所有 GC Roots 对象都不通过【强引用】引用该对象,该对象才能被垃圾回收
如上图、只有B、C对象都不引用A1对象时,A1对象才会在垃圾回收时被回收;
2) 软引用(SoftReference)
- 仅有软引用引用该对象时,在垃圾回收后,内存仍不足时会再次出发垃圾回收,回收软引用对象(实在不行了才回收软引用对象)
- 可以配合引用队列来释放软引用自身(因为软引用对象自身也是占一点内存的)
软引用的使用:
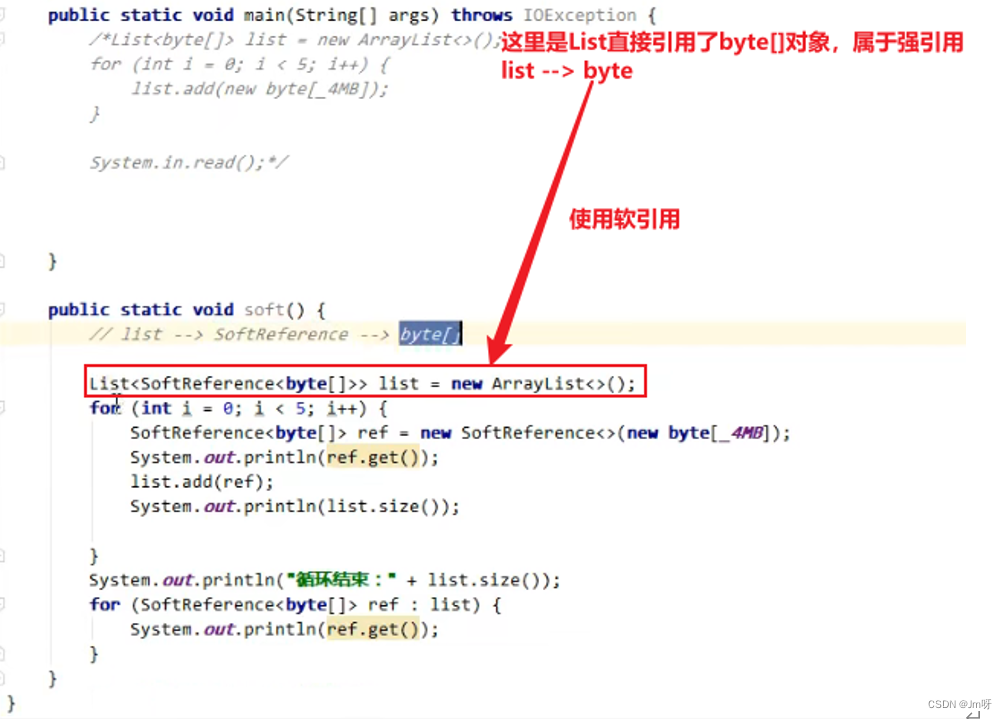

可见前四次已经被回收了
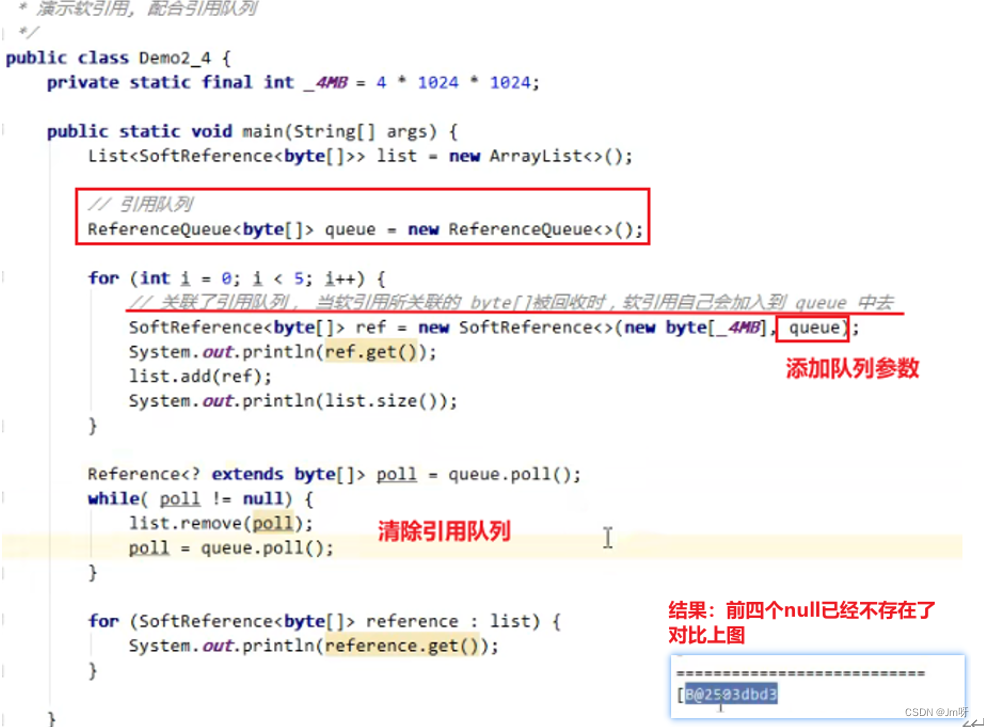
引用队列的使用:
如果在垃圾回收时发现内存不足,在回收软引用所指向的对象时,软引用本身不会被清理(就是上图结果中的null值)
如果想要清理软引用,需要使用引用队列
3) 弱引用(WeakReference)
仅有弱引用引用该对象时,在垃圾回收时,(full gc时)无论内存是否充足,都会回收弱引用对象
可以配合引用队列来释放弱引用自身
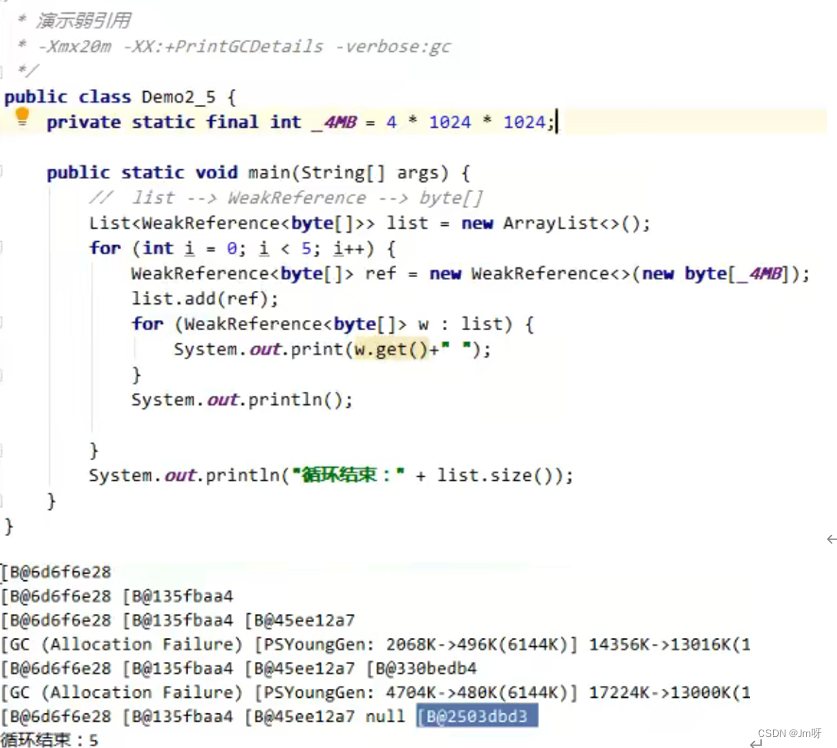
结合引用队列同软引用相似
4) 虚引用(PhantomReference)
必须配合引用队列使用,主要配合 ByteBuffer 使用,被引用对象回收时,会将虚引用入队由 Reference Handler 线程调用虚引用相关方法释放直接内存
5) 终结器引用(FinalReference)
无需手动编码,但其内部配合引用队列使用,在垃圾回收时,终结器引用入队(被引用对象暂时没有被回收),再由 Finalizer 线程通过终结器引用找到被引用对象并调用它的 finalize方法,第二次 GC 时才能回收被引用对象
二.垃圾回收算法(重要)
1.标记清除
定义:标记清除算法顾名思义,是指在虚拟机执行垃圾回收的过程中,先采用标记算法确定可回收对象,然后垃圾收集器根据标识清除相应的内容,给堆内存腾出相应的空间
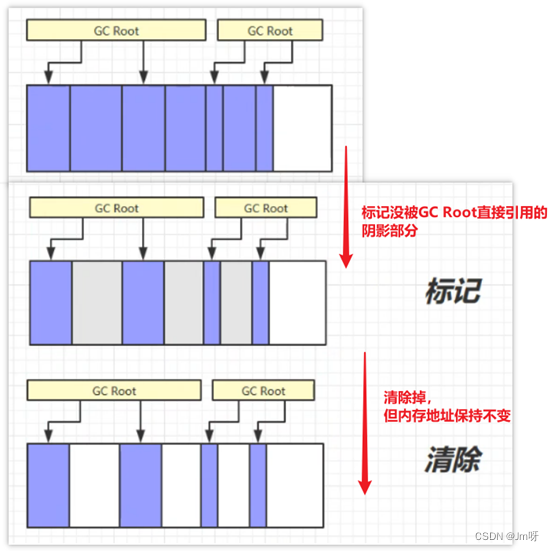
清除后,对于腾出内存空间并不是将内存空间的字节清0,而是会把被清除对象所占用内存的起始结束的地址记录下来,放入空闲的地址列表中,下次分配内存的时候,再选择合适的位置存入,直接覆盖
优点:速度快;
缺点:容易产生大量的内存碎片,可能无法满足大对象的内存分配,一旦导致无法分配对象,那就会导致jvm启动gc,一旦启动gc,我们的应用程序就会暂停,这就导致应用的响应速度变慢
2.标记整理
标记-整理 会将不被GC Root引用的对象回收,清楚其占用的内存空间。然后整理剩余的对象,速度慢、可以有效避免因内存碎片而导致的问题,但是因为整体需要消耗一定的时间,所以效率较低
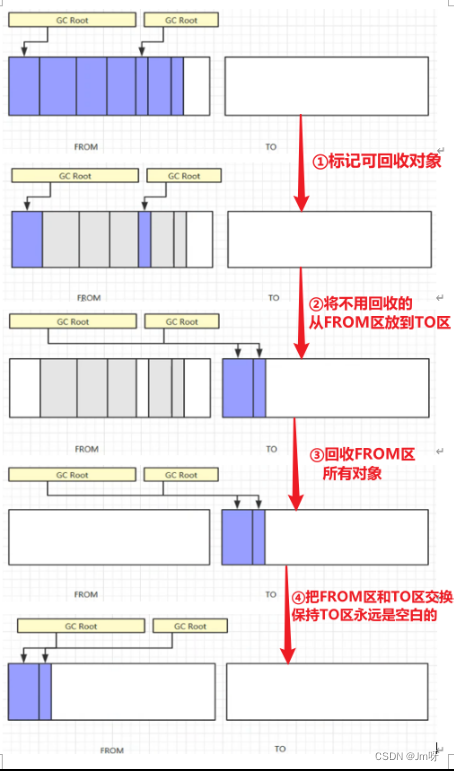
3.复制算法
复制算法将内存分为等大小的两个区域,FROM和TO(TO中始终为空)。先将被GC Root引用的对象从FROM放入TO中,再回收不被GC Root引用的对象。然后交换FROM和TO。这样也可以避免内存碎片的问题,但是会占用双倍的内存空间。
三.分代垃圾回收
1.回收流程
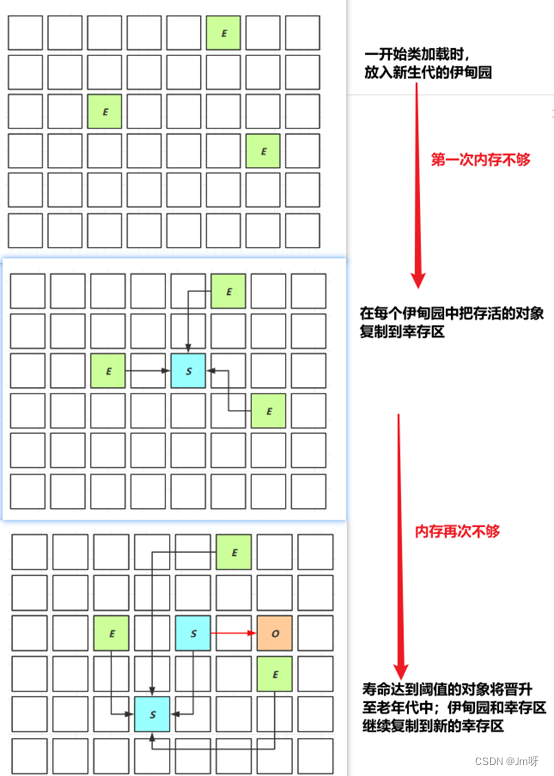
① 新创建的对象都被放在新生代的伊甸园(Eden)中
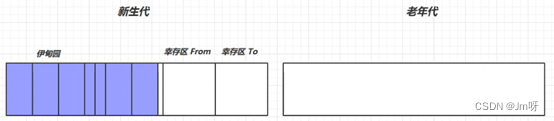
② 当伊甸园空间不足时,会采用复制算法进行垃圾回收,这时的回收叫做Minor GC;把伊甸园和幸存区From存活的对象先复制到幸存区To中,此时存活的对象寿命+1,并清理掉未存活的对象,最后再交换幸存区From和幸存区To;
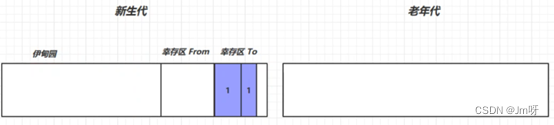
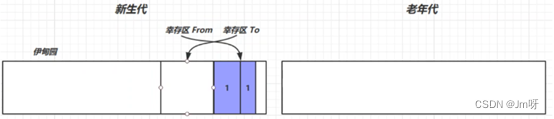
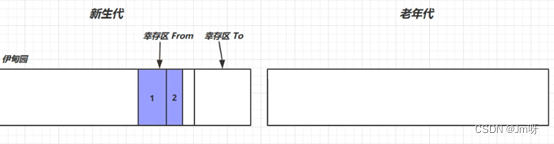
③ 再次创建对象,若新生代的伊甸园又满了,则同上;
④ 如果经历多次垃圾回收,某一对象均未被回收,寿命不断+1,当寿命达到阈值时(最大为15,4bit)就会被放入老年代中;
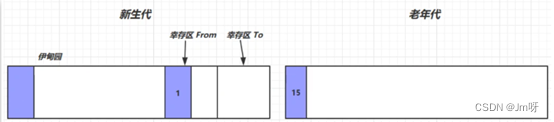
⑤ 如果老年代中的内存都满了,就会先触发Minor GC 如果内存还是不足,则会触发Full GC,扫描新生代和老年代中所有不再使用的对象并回收、
总结
-
对象首先分配在伊甸园区域
-
新生代空间不足时,触发 minor gc,伊甸园和 from 存活的对象使用 copy 复制到 to 中,存活的对象年龄加 1并且交换 from to
-
minor gc 会引发 stop the world,暂停其它用户的线程,等垃圾回收结束,用户线程才恢复运行
-
当对象寿命超过阈值时,会晋升至老年代,最大寿命是15(4bit)
-
当老年代空间不足,会先尝试触发 minor gc,如果之后空间仍不足,那么触发 full gc,STW的时间更长
2.GC 分析
1) 大对象处理策略
当遇到一个较大的对象时,就算新生代的伊甸园为空,也无法容纳该对象时,会将该对象直接晋升为老年代
2) 线程内存溢出(OOM)
某个线程的内存溢出了而抛异常(out of memory),不会让其他的线程结束运行
这是因为当一个线程抛出OOM异常后,它所占据的内存资源会全部被释放掉,从而不会影响其他线程的运行,进程依然正常
四.垃圾回收器
串行
-
单线程
-
堆内存较小,适合个人电脑
吞吐量优先
-
多线程
-
堆内存较大,多核 cpu
-
让单位时间内,STW 的时间最短 0.2 0.2 = 0.4,垃圾回收时间占比最低,这样就称吞吐量高(少餐多食)
响应时间优先
-
多线程
-
堆内存较大,多核 cpu
-
尽可能让单次 STW 的时间最短 0.1 0.1 0.1 0.1 0.1 = 0.5(少食多餐)
1.串行
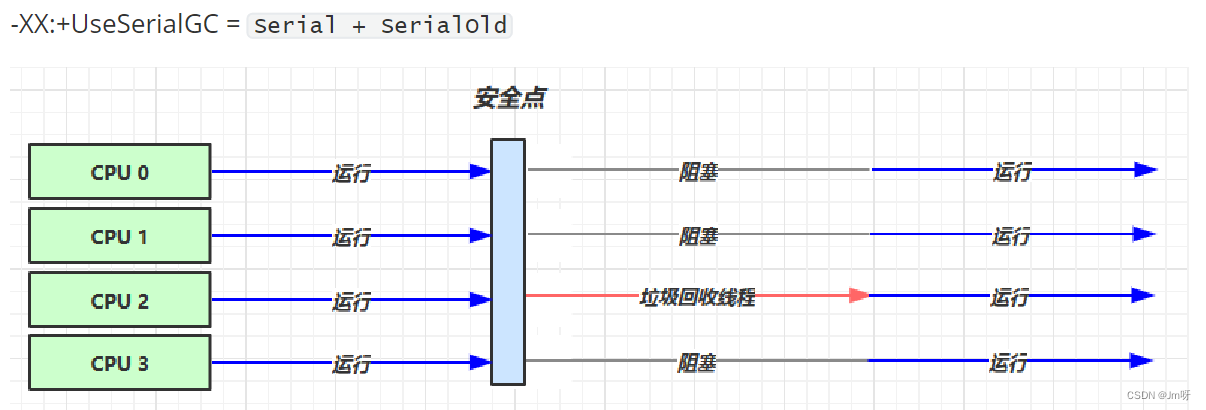
安全点:
让其他线程都在这个点停下来,以免垃圾回收时移动对象地址,使得其他线程找不到被移动的对象;因为是串行的,所以只有一个垃圾回收线程。且在该线程执行回收工作时,其他线程进入阻塞状态
Serial 收集器:
Serial收集器是最基本的、发展历史最悠久的收集器
特点:单线程、简单高效(与其他收集器的单线程相比),用于新生代采用复制算法。对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。
收集器进行垃圾回收时,必须暂停其他所有的工作线程,直到它结束(Stop The World)
Serial Old 收集器:
Serial Old是Serial收集器的老年代版本
特点:同样是单线程收集器,采用标记-整理算法
2.吞吐量优先
-XX:+UseParallelGC ~ -XX:+UserParallelOldGC:
开启吞吐量优先的回收器,1.8版本默认开启;UseParallelGC是新生代的,采用复制算法;UserParallelOldGC是在老年代的,采用标记整理算法
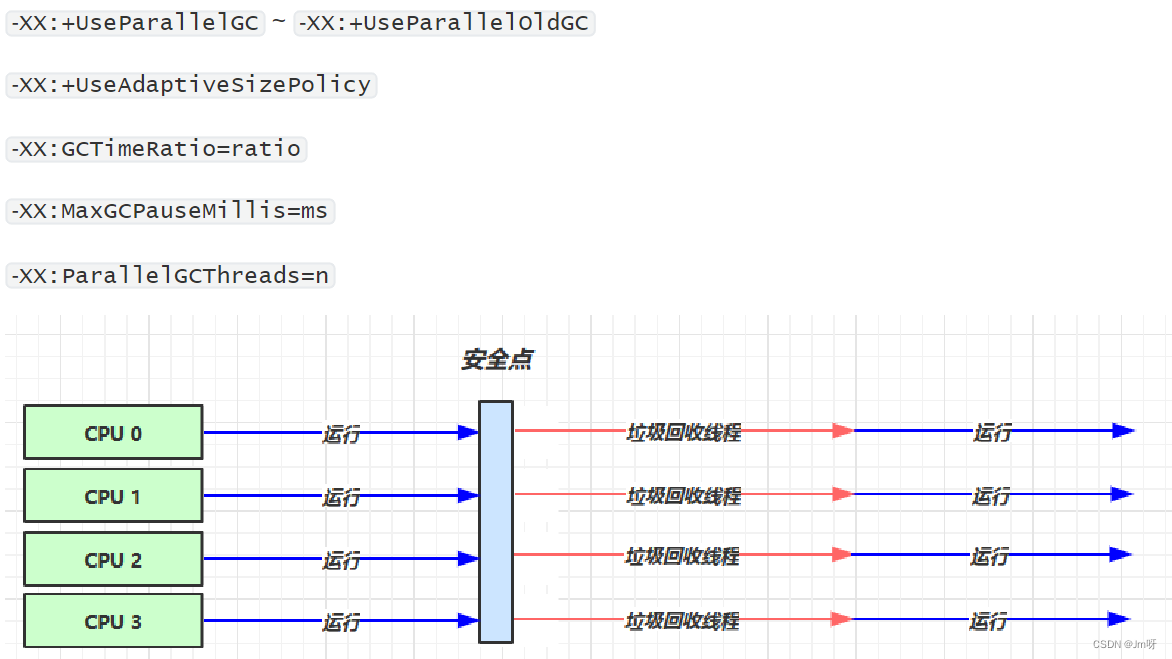
-XX:+UseAdaptiveSizePolicy
开启这个将采用自适应的大小调整策略,调整新生代的大小,包括堆的大小和晋升老年代的阈值大小等;种调节方式称为GC的自适应调节策略
-XX:GCTimeRatio=ratio
调整吞吐量的目标,即垃圾回收的时间与总时间的占比(1/(1+ratio)),默认ratio=99,1/(1+ratio))= 0.01,即垃圾回收的时间不能超过总时间的1%(比如总时间100分钟,垃圾回收的时间不能超过1分钟,如果超过1分钟,则GC会自适应的调整大小)
-XX:MaxGCPauseMillis=ms
指的是暂停的毫秒数,默认200ms,即上图红线(和Ratio对立,折中选取)
-XX:ParallelGCThreads=n
设置垃圾回收时运行的线程数
3.响应时间优先(CMS)
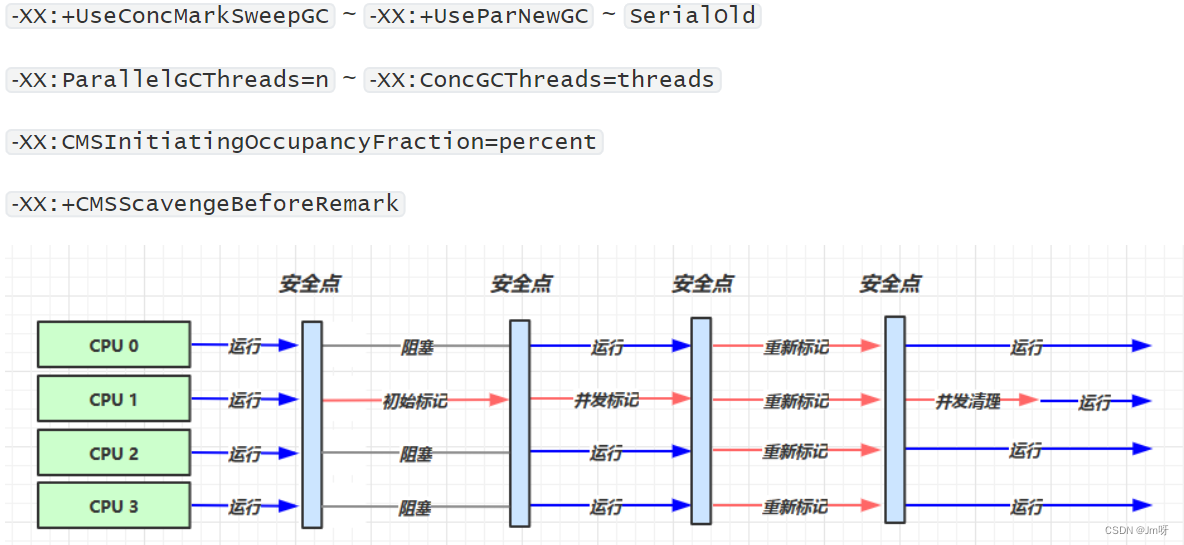
1) CMS 收集器
Concurrent Mark Sweep,一种以获取最短回收停顿时间为目标的老年代收集器
特点:基于标记-清除算法实现。并发收集、低停顿,但是会产生内存碎片
应用场景:适用于注重服务的响应速度,希望系统停顿时间最短,给用户带来更好的体验等场景下。如web程序、b/s服务
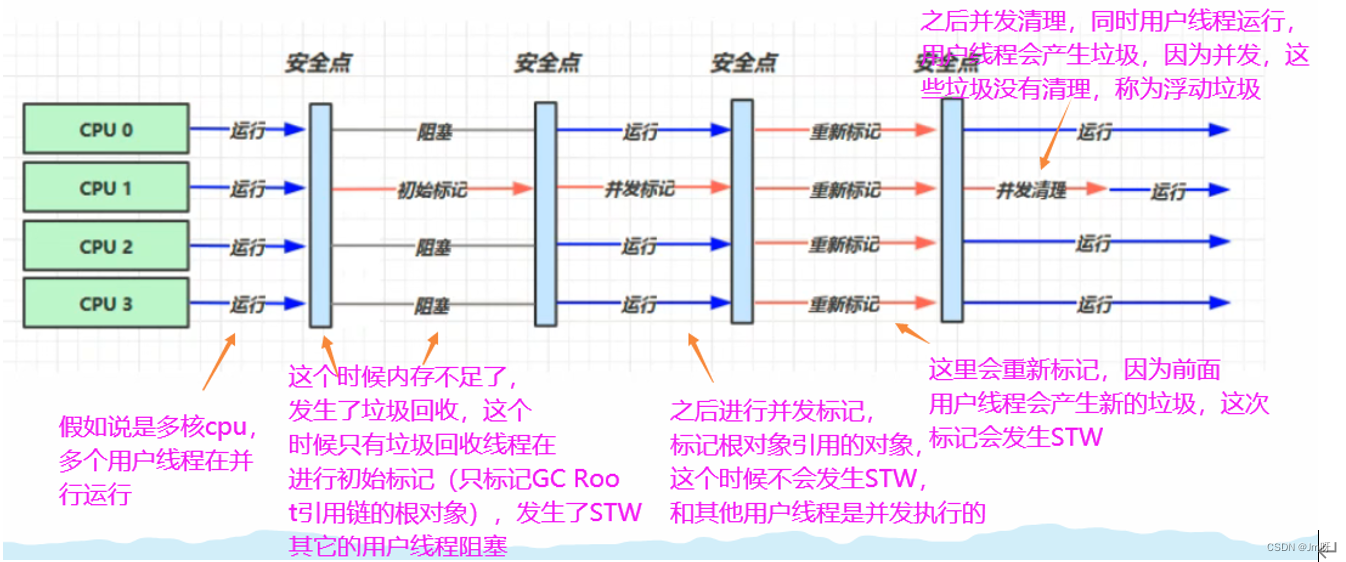
2) CMS的运行过程(4步)
初始标记:标记GC Roots能直接到的对象。速度很快但是仍存在Stop The World问题
并发标记:进行GC Roots Tracing 的过程,找出存活对象且用户线程可并发执行
重新标记:为了修正并发标记期间因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录。仍然存在Stop The World问题
并发清除:对标记的对象进行清除回收
CMS收集器的内存回收过程是与用户线程一起并发执行的
图解:
4.G1(Garbage First)
JDK1.9默认采用G1垃圾回收器,且废弃的CMS回收器
1) 适用场景
-
同时注重吞吐量(Throughput)和低延时(Low latency),默认的暂停目标是200ms
-
超大堆内存,会将堆划分为多个大小相等的区域,称为Region,每个区域都可以独立的作为伊甸园或者新生代或者老年代
-
整体上是标记-整理算法,在两个区域之间是复制算法
2) 相关jvm参数

3) G1垃圾回收阶段
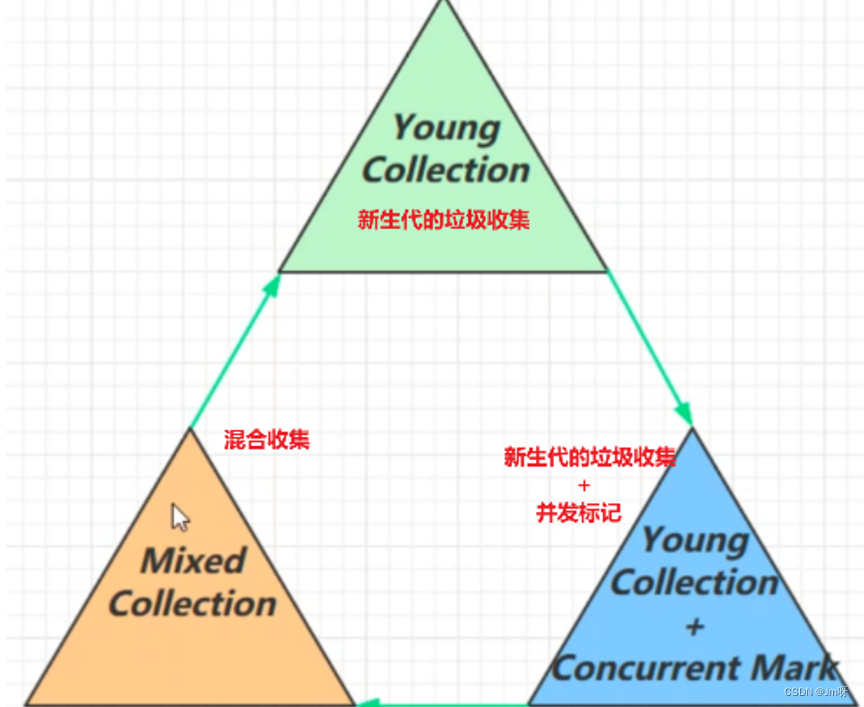
新生代伊甸园垃圾回收—–>内存不足,新生代回收+并发标记—–>回收新生代伊甸园、幸存区、老年代内存——>新生代伊甸园垃圾回收(重新开始)
Young Collection
Young Collection + CM
-
在 Young GC 时会进行 GC Root 的初始标记
-
并发标记(CM)是从GC Root出发顺着其引用链标记其他对象
-
老年代占用堆空间比例达到阈值时,进行并发标记(不会 STW),由下面的 JVM 参数决定
-XX:InitiatingHeapOccupancyPercent=percent (默认45%)如下图 O 占总的45%时进行并发标记
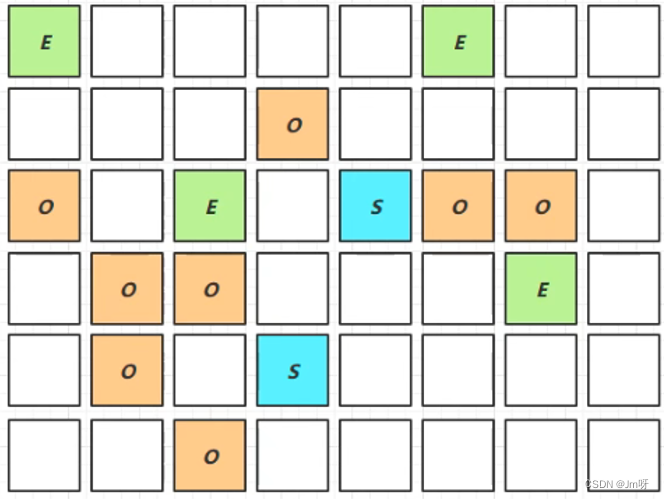
Mixed Collection
会对 E、S、O 进行全面垃圾回收
-
最终标记 会STW
-
拷贝存活 会 STW
-XX:MaxGCPauseMillis=ms
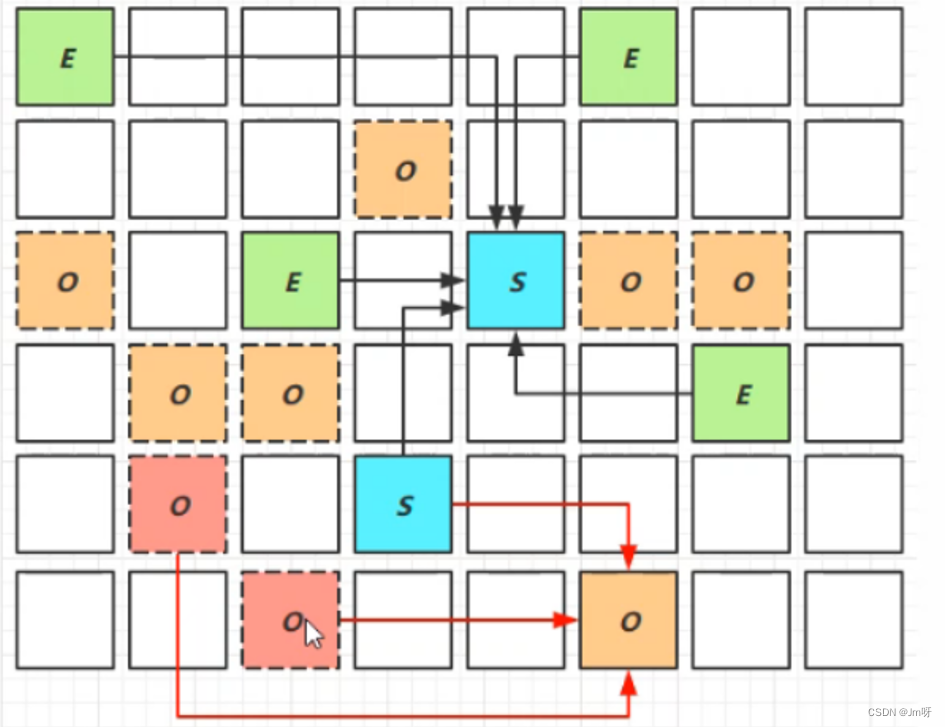
黑线:即新生代回收,包括伊甸园、幸存区
红线:复制老年代
问:为什么有的老年代被拷贝了,有的没拷贝?
答:因为指定了最大停顿时间,如果对所有老年代都进行回收,耗时可能过高。为了保证时间不超过设定的停顿时间,会回收最有价值的老年代(回收后,能够得到更多内存)
4) Full GC
G1在老年代内存不足时(老年代所占内存超过阈值)
如果垃圾产生速度慢于垃圾回收速度,不会触发Full GC,还是并发地进行清理
如果垃圾产生速度快于垃圾回收速度,便会触发Full GC,退化到串行,STW时间会很长
5) Young Collection跨代引用
即老年代引用新生代的问题,因为在新生代回收过程中会沿着GC Root去标记,这些GC Root可能存在于老年代中,而一般老年代中的对象较多,这样每次都需要遍历大量对象;
解决方法:
-
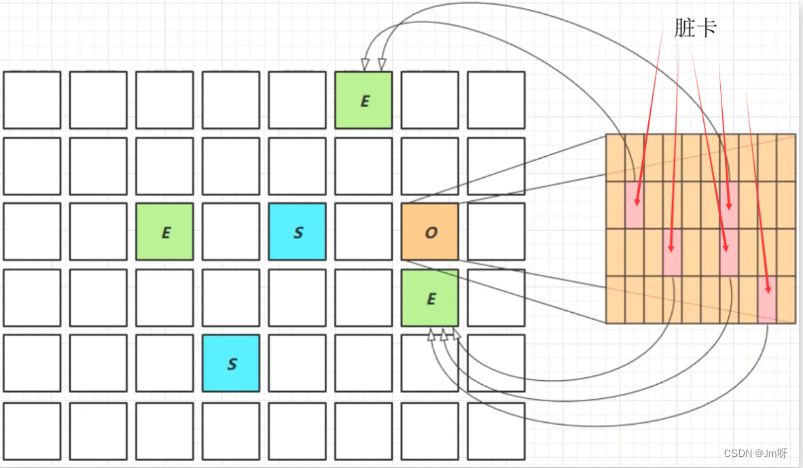
卡表与Remembered Set:
-
Remembered Set 存在于E中,用于保存新生代对象对应的脏卡,将来对新生代进行垃圾回收时,会根据Remembered Set判断有哪些脏卡,然后再从这些脏卡开始
-
脏卡:O被划分为多个区域(一个区域512K),如果该区域引用了新生代对象,则该区域被称为脏卡
-
-
在引用变更时通过post-write barried + dirty card queue,相当于更新脏卡
-
concurrent refinement threads 更新 Remembered Set
6) Remark重标记
黑色:已被处理,需要保留的
灰色:正在处理中的
白色:还未处理的
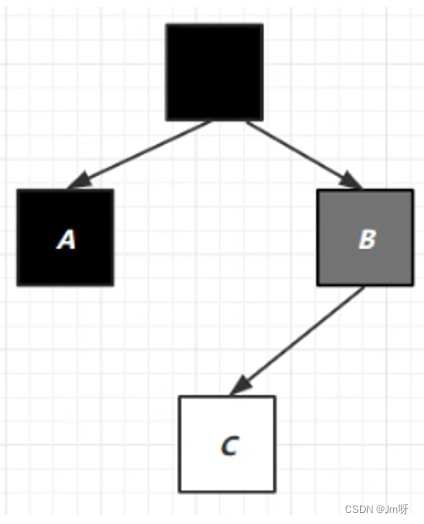
① 这个时候将处理B,处理结果如下:
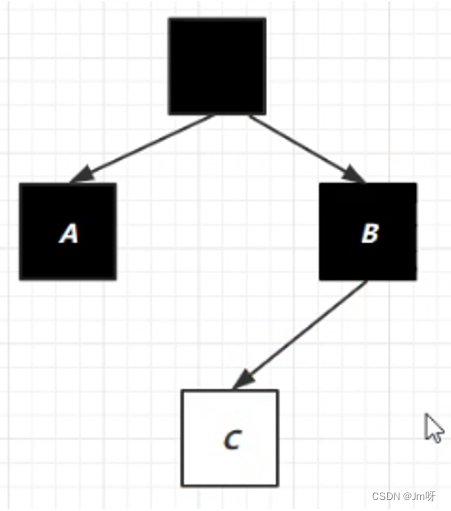
② 下一步将处理C,此时正在并发执行标记,用户线程可能改变B和C的引用关系,会产生如下情况:
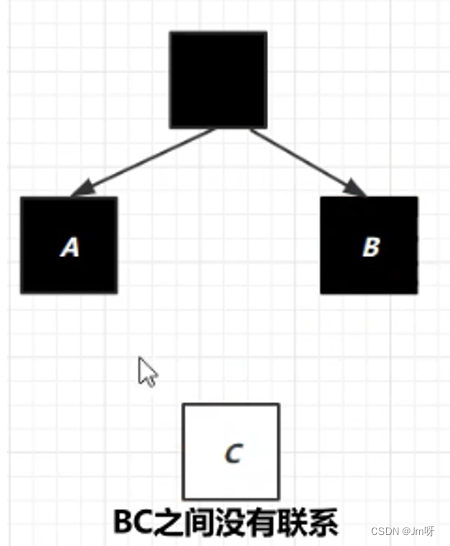
③ 此时C已经被处理完了,被标记成了白色,但是用户线程可能在这时又改变了C的引用:
④ 此时C应该被标记成黑色,但是标记动作已经结束,所以会产生误差
解决误差方法:采用Remark
① 之前C未被引用,这时A引用了C,就会给C加一个写屏障,写屏障的指令会被执行(只有发生引用改变就会执行),将C放入一个队列当中,并将C变为处理中状态
② 在并发标记阶段结束以后,重新标记阶段会STW,然后将放在该队列中的对象重新处理发现有强引用引用它,就会处理它
7) JDK8u20字符串去重
① 将所有新分配的字符串(底层是char[])放入一个队列
② 当新生代回收时,G1并发检查是否有重复的字符串
③ 如果字符串的值一样,就让他们引用同一个字符串对象

注意,其与String.intern的区别:
-
intern关注的是字符串对象
-
字符串去重关注的是char[]
-
在JVM内部,使用了不同的字符串标
优点与缺点:
-
节省了大量内存
-
新生代回收时间略微增加,导致略微多占用CPU
8) JDK 8u40 并发标记类卸载
在并发标记阶段结束以后,就能知道哪些类不再被使用。如果一个类加载器的所有类都不在使用,则卸载它所加载的所有类
-XX:+ClassUnloadingWithConcurrentMark 默认启用
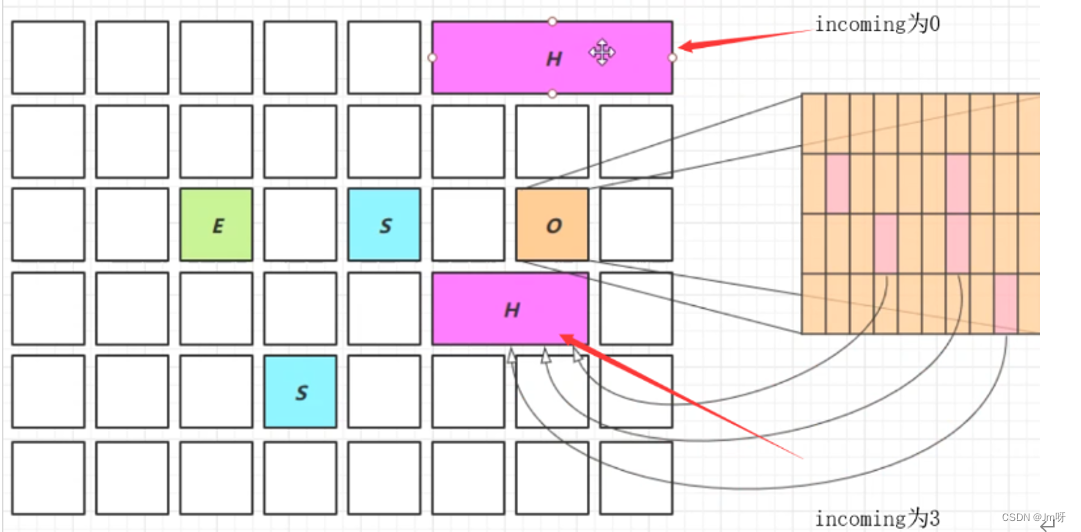
9) JDK 8u60 回收巨型对象
- 一个对象大于region的一半时,就称为巨型对象
- G1不会对巨型对象进行拷贝
- 回收时被优先考虑
- G1会跟踪老年代所有incoming引用,如果老年代incoming引用为0的巨型对象就可以在新生代垃圾回收时处理掉
10) JDK9并发标记起始时间的调整
4)提到当垃圾产生速度快于垃圾回收速度,便会触发Full GC,STW的时间就会变长,这个时候就可以通过调整提前开始并发标记来优化
-
并发标记必须在堆空间占满前完成,否则退化为 FullGC
-
JDK 9 之前需要使用 -XX:InitiatingHeapOccupancyPercent
-
JDK 9 可以动态调整
-XX:InitiatingHeapOccupancyPercent 用来设置初始值
进行数据采样并动态调整
总会添加一个安全的空档空间
五. 垃圾回收调优
1.确定调优领域
- 内存
- 锁竞争
- CPU占用
- IO
- GC
2.确定目标
低延迟/高吞吐量? 选择合适的GC
- CMS(JDK8默认)、 G1(JDK9推荐) 、ZGC(JDK12体验)
- ParallelGC(高吞吐量)
- Zing(另一种虚拟机)
3.最快的GC是不发生GC
首先排除减少因为自身编写的代码而引发的内存问题
-
查看Full GC前后的内存占用,考虑以下几个问题
-
数据是不是太多?(比如select *)
-
数据表示是否太臃肿
- 对象图
- 对象大小(比如用Integer换成int会小很多)
-
是否存在内存泄漏(采用软、弱引用;第三方缓存实现等)
4.新生代调优
新生代的特点:
-
所有的new操作分配内存都是非常廉价的
-
死亡对象回收零代价
-
大部分对象用过即死(朝生夕死)
-
MInor GC 所用时间远小于Full GC
问:新生代内存越大越好么?
答:不是
-
新生代内存太小:频繁触发Minor GC,会STW,会使得吞吐量下降
-
新生代内存太大:老年代内存占比有所降低,会更频繁地触发Full GC。而且触发Minor GC时,清理新生代所花费的时间会更长
-
新生代内存设置为能容纳所有【并发量*(请求-响应)】的数据为宜
5.幸存区调优
-
幸存区需要能够保存 当前活跃对象+需要晋升的对象
-
晋升阈值配置得当,让长时间存活的对象尽快晋升
-XX:MaxTenuringThreshold=threshold
-XX:+PrintTenuringDistribution
6.老年代调优
以 CMS 为例
-
CMS 的老年代内存越大越好
-
先尝试不做调优,如果没有 Full GC 那么程序已经执行的很ok了,否则先尝试调优新生代
-
观察发生 Full GC 时老年代内存占用,将老年代内存预设调大 1/4 ~ 1/3
-XX:CMSInitiatingOccupancyFraction=percent
相关文章:
JVM篇之垃圾回收
一.如何判断对象可以回收 1.引用计数法 只要一个对象被其他变量所引用,就让它的计数加1,被引用了两次就让它的计数变成2,当这个变量的计数变成0时,就可以被垃圾回收; 弊端:当出现如下图的情况࿰…...

尝试用程序计算Π(3.141592653......)
文章目录1. π\piπ2. 用微积分来计算π\piπ2.1 原理2.2 代码2.3 结果2.4 分析1. π\piπ π\piπ的重要性或者地位不用多说,有时候还是很好奇,精确地π\piπ值是怎么计算出来的。研究π\piπ的精确计算应该是很多数学家计算机科学家努力的方向…...

【异常检测三件套】系列3--时序异常检测综述
写在前面: 异常检测共包含3个内容,从多个方面剖析异常检测方法,本文为第三篇。过往内容请查看以下链接: 【异常检测三件套】系列1--14种异常检测算法https://blog.csdn.net/allein_STR/article/details/128114175?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%…...

关于SAP 错误日志解析
有时候启动或操作sap会出现故障,只是察看sap用户当前目录下的日志文件可能不得要领,此时有必要察看work目录下的一些trace. 以Linux系统为例,其他的也差不多。 instance说明 如下 DVEBMGS?? ABAP Central Instance D?? …...
java:自定义变量加载到系统变量后替换shell模版并执行shell
这里的需求前提是,在项目中进行某些操作前,需要在命令后对shell配置文件的进行修改(如ip、port),这个对于用户是不友好的,需要改为用户页面输入ip、port,后台自动去操作修改配置;那么…...
Redis高级删除策略与数据淘汰
第二章:Redis高级 学习目标 目标1:能够说出redis中的数据删除策与略淘汰策略 目标2:能够说出主从复制的概念,工作流程以及场景问题及解决方案 目标3:能够说出哨兵的作用以及工作原理,以及如何启用哨兵 …...
社畜大学生的Python之pandas学习笔记,保姆入门级教学
接上期,上篇介绍了 NumPy,本篇介绍 pandas。 目录 pandas 入门pandas 的数据结构介绍基本功能汇总和计算描述统计处理缺失数据层次化索引 pandas 入门 Pandas 是基于 Numpy 构建的,让以 NumPy 为中心的应用变的更加简单。 Pandas是基于Numpy…...
20_FreeRTOS低功耗模式
目录 低功耗模式简介 STM32低功耗模式 Tickless模式详解 Tickless模式相关配置 实验源码 低功耗模式简介 很多应用场合对于功耗的要求很严格,比如可穿戴低功耗产品、物联网低功耗产品等。 一般MCU都有相应的低功耗模式,裸机开发时可以使用MCU的低功耗模式。 FreeRTOS也…...

Hive的使用方式
操作Hive可以在Shell命令行下操作,或者是使用JDBC代码的方式操作 针对命令行这种方式,其实还有两种使用 第一个是使用bin目录下的hive命令,这个是从hive一开始就支持的使用方式 后来又出现一个beeline命令,它是通过HiveServer2服…...

Flume三大核心组件
Flume的三大核心组件: Source:数据源 Channel:临时存储数据的管道 Sink:目的地 Source:数据源:通过source组件可以指定让Flume读取哪里的数据,然后将数据传递给后面的 channel Flume内置支持读…...
数据结构(六)二叉树
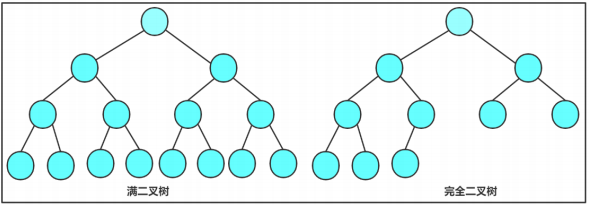
一、树形结构概念树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:1、有一个…...
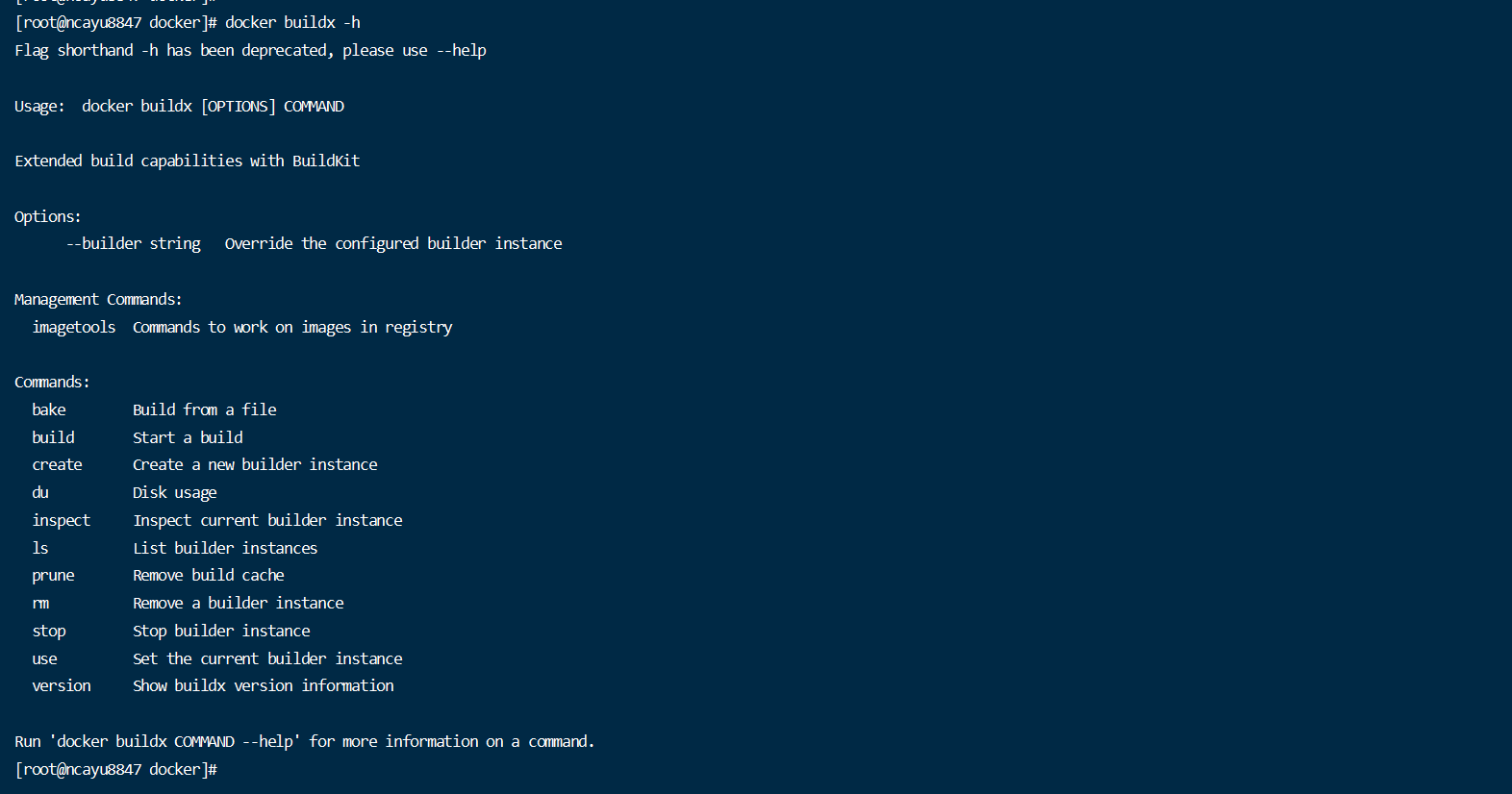
Docker buildx 的跨平台编译
docker buildx 默认的 docker build 命令无法完成跨平台构建任务,我们需要为 docker 命令行安装 buildx 插件扩展其功能。buildx 能够使用由 Moby BuildKit 提供的构建镜像额外特性,它能够创建多个 builder 实例,在多个节点并行地执行构建任…...

【java基础】方法重载和方法重写
文章目录方法重载方法重写方法重载 方法重载就是可以在一个类里面定义多个相同名称的方法,只需要参数列表的个数或者类型不同就行。 public class Overload {public int add(int a, int b) {return a b;}public double add(double a, double b) {return a b;}}对…...
Gradle7.4安装与基本使用
文章目录一.前言二.下载Gradle三.Gradle镜像源-全局级配置四.配置Gradle wrapper-项目级配置五.Gradle对测试的支持五.生命周期5.1 settings文件六.Gradle任务入门6.1 任务行为6.2 任务依赖方式七. Dependencies依赖引入7.1 依赖冲突及解决方案八.Gradle整合多模块SpringBoot九…...

[系统安全] 虚拟化安全之虚拟化概述
本文为笔者从零基础学习系统安全相关内容的笔记,如果您对系统安全、逆向分析等内容感兴趣或者想要了解一些内容,欢迎关注。本系列文章将会随着笔者在未来三年的读研过程中持续更新,由于笔者现阶段还处于初学阶段,不可避免参照复现各类书籍内容,如书籍作者认为侵权请告知,…...

如何从零开始系统的学习项目管理?
经常会有人问,项目管理到底应该学习一些什么?学习考证之后能得到什么价值? 以下我就总结一下内容 一,学习项目管理有用吗? 有效的项目管理带来的益处大致包括以下几个方面:更有效达成业务目标、满足相关…...

面试题-----
面试题---- 一.HTML 1.常用哪些浏览器进行测试,对应有哪些内核? ①IE------------------->Trident ②Chrome---------->以前是Webkit现在是Blink ③Firefox------------>Gecko ④Safari-------------->Webkit ⑤Opera--------------&…...
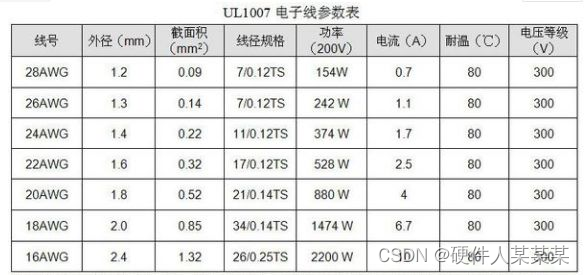
线材-电子线载流能力
今天来讲的是关于电子线的一个小知识,可能只做板子的工程师遇到此方面的问题会比较少,做整机的工程师则必然会遇到此方面问题,那就是线材问题。 下面主要说下电子线的过电流能力。(文末有工具下载)电子线(h…...
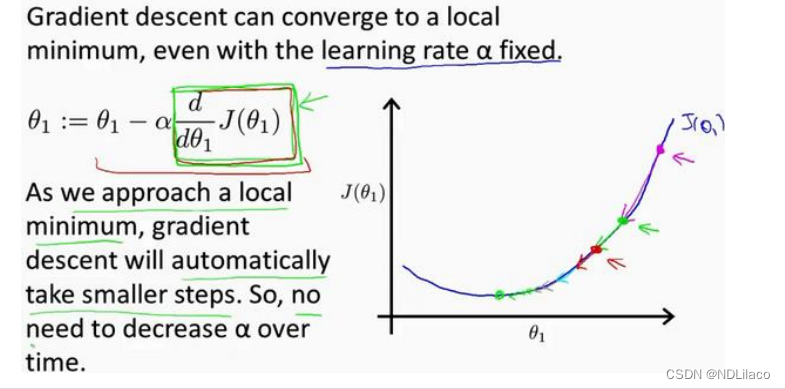
单变量回归问题
单变量回归问题 对于某房价问题,x为房屋大小,h即为预估房价,模型公式为: hθ(x)θ0θ1xh_{\theta}(x)\theta_{0}\theta_{1}x hθ(x)θ0θ1x 要利用训练集拟合该公式(主要是计算θ0、θ1\theta_{0}、\theta_{1}θ…...
ubuntu/linux系统知识(36)linux网卡命名规则
文章目录背景命名规范系统默认命名规则优势背景 很久以前Linux 操作系统的网卡设备的传统命名方式是 eth0、eth1、eth2等,属于biosdevname 命名规范。 服务器通常有多块网卡,有板载集成的,同时也有插在PCIe插槽的。Linux系统的命名原来是et…...

基于Agent-Next框架的Polymarket模拟交易机器人构建指南
1. 项目概述与核心价值最近在逛GitHub的时候,发现了一个挺有意思的项目,叫agent-next/polymarket-paper-trader。光看这个名字,可能很多朋友会有点懵,这到底是个啥?简单来说,这是一个基于agent-next框架&am…...

DRAM计算内存的电源传输网络优化策略
1. DRAM计算内存中的电源传输网络挑战与优化在数据密集型应用爆炸式增长的今天,传统冯诺依曼架构面临严峻的"内存墙"挑战。计算内存(Compute-in-Memory, CIM)技术通过在内存内部执行计算任务,从根本上改变了数据处理范式…...

ARM Firmware Suite与Integrator开发板嵌入式开发指南
1. ARM Firmware Suite与Integrator开发板概述ARM Firmware Suite(AFS)是ARM架构下专为嵌入式系统开发设计的固件套件,在Integrator系列开发板上发挥着核心作用。这套工具链最初由ARM Limited在1999-2002年间开发,至今仍在许多传统…...

ElevenLabs Enterprise方案深度拆解:从API限流策略到GDPR语音数据主权管理的7层安全加固实践
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs Enterprise方案全景概览 ElevenLabs Enterprise 是面向中大型组织构建的语音合成与语音识别一体化平台,专为高并发、多租户、合规性敏感场景设计。其核心能力覆盖实时TTS流式输出…...

用Qt快速搭建一个局域网文件传输工具:QTcpServer/QTcpSocket完整项目实战
用Qt快速搭建一个局域网文件传输工具:QTcpServer/QTcpSocket完整项目实战 在数字化办公场景中,局域网文件传输是高频刚需。想象这样的场景:会议室里需要快速共享设计稿,实验室多台设备要同步采集数据,或者家庭网络中手…...

别再只怪芯片了!拆解一个智能家居产品,看它的EMC静电防护设计到底哪里出了问题
智能家居静电防护失效分析:从产品拆解看EMC设计盲区 最近一位做智能门锁的创业者朋友向我吐槽:他们的旗舰产品在北方冬季频繁出现用户触摸时死机的情况,售后返修率飙升到15%。拆机检测却显示主板芯片完好,问题究竟出在哪里&#…...
)
集合进阶(Collection)
一、集合概述和分类1.1 集合的分类如下图所示:一类是单列集合元素是一个一个的,另一类是双列集合元素是一对一对的。 主要学习Collection单列集合。Collection是单列集合的根接口,也称之为顶层接口,Collection接口下面又有两个子接…...

告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境
告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境 当你的笔记本风扇开始像喷气发动机一样轰鸣,而PySpark脚本才处理到第3万条数据时,就该考虑换个战场了。去年我用一台16GB内存的MacBook Pro分析800万条电商日志&…...

LIO-SAM源码逐行解析:从因子图构建到多传感器融合实战
1. LIO-SAM技术架构解析 LIO-SAM(Lidar Inertial Odometry via Smoothing and Mapping)是Tixiao Shan博士在LeGO-LOAM基础上开发的激光-惯性紧耦合SLAM系统。它的核心创新点在于采用因子图优化框架,将IMU预积分、激光里程计、GPS和闭环检测四…...

英雄联盟LCU工具:如何用LeagueAkari提升你的游戏效率
英雄联盟LCU工具:如何用LeagueAkari提升你的游戏效率 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款基于英雄联…...