单变量回归问题
单变量回归问题
对于某房价问题,x为房屋大小,h即为预估房价,模型公式为:
hθ(x)=θ0+θ1xh_{\theta}(x)=\theta_{0}+\theta_{1}x hθ(x)=θ0+θ1x
要利用训练集拟合该公式(主要是计算θ0、θ1\theta_{0}、\theta_{1}θ0、θ1),需要代价函数(计算当前模型和测试集数据的误差),
J(θ0,θ1)=12m∑i=1m(hθ(x(i))−y(i))2J(\theta_{0},\theta_{1})=\frac{1}{2m}\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})^2} J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2
当代价函数得到最小值时,此时拟合的公式最好。一般利用梯度下降法来得到代价函数的局部(全局)最优解。批量梯度下降的公式为
θj:=θj−α∂∂θjJ(θ0,θ1)(forj=0andj=1)\theta_{j}:=\theta_{j}-\alpha\frac{\partial }{\partial \theta_{j}}J(\theta_{0},\theta_{1}) (for \quad j=0\quad and \quad j=1) θj:=θj−α∂θj∂J(θ0,θ1)(forj=0andj=1)
∂∂θjJ(θ0,θ1)=∂∂θj(12m∑i=1m(hθ(x(i))−y(i))2)\frac{\partial }{\partial \theta_{j}}J(\theta_{0},\theta_{1})=\frac{\partial }{\partial \theta_{j}}(\frac{1}{2m}\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})^2}) ∂θj∂J(θ0,θ1)=∂θj∂(2m1i=1∑m(hθ(x(i))−y(i))2)
j=0时,∂∂θ0J(θ0,θ1)=1m∑i=1m(hθ(x(i))−y(i))j=0时,\frac{\partial }{\partial \theta_{0}}J(\theta_{0},\theta_{1})=\frac{1}{m}\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})} j=0时,∂θ0∂J(θ0,θ1)=m1i=1∑m(hθ(x(i))−y(i))
j=1时,∂∂θ1J(θ0,θ1)=1m∑i=1m(hθ(x(i))−y(i))⋅x(i)j=1时,\frac{\partial }{\partial \theta_{1}}J(\theta_{0},\theta_{1})=\frac{1}{m}\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)})\cdot x^{(i)}} j=1时,∂θ1∂J(θ0,θ1)=m1i=1∑m(hθ(x(i))−y(i))⋅x(i)
α\alphaα为学习率,决定沿着代价函数下降程度最大的方向向下的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。
如果α\alphaα太小了,即我的学习速率太小,需要很多步才能到达最低点,可能会很慢;
如果α\alphaα太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛。
在梯度下降法中,当我们接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当我们接近局部最低点时,很显然在局部最低时导数等于零,所以当我们接近局部最低时,导数值会自动变得越来越小,所以梯度下降将自动采取较小的幅度,这就是梯度下降的做法。所以实际上没有必要再另外减小α\alphaα。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qARHfSRE-1677383475783)(C:\Users\20491\AppData\Roaming\Typora\typora-user-images\image-20230222172604462.png)]](https://img-blog.csdnimg.cn/2fd583aba931446d8b75b4280f9a43c5.png)
相关文章:
单变量回归问题
单变量回归问题 对于某房价问题,x为房屋大小,h即为预估房价,模型公式为: hθ(x)θ0θ1xh_{\theta}(x)\theta_{0}\theta_{1}x hθ(x)θ0θ1x 要利用训练集拟合该公式(主要是计算θ0、θ1\theta_{0}、\theta_{1}θ…...
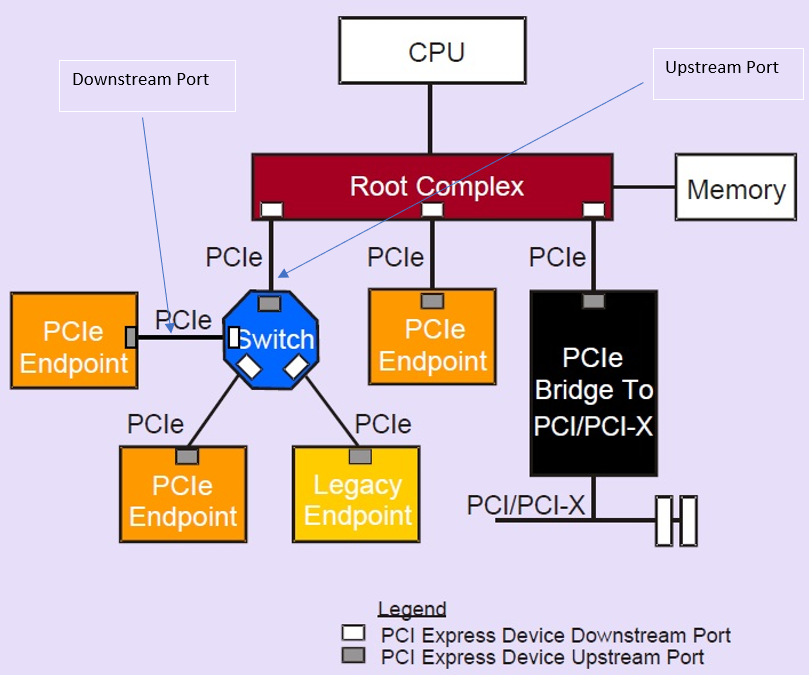
ubuntu/linux系统知识(36)linux网卡命名规则
文章目录背景命名规范系统默认命名规则优势背景 很久以前Linux 操作系统的网卡设备的传统命名方式是 eth0、eth1、eth2等,属于biosdevname 命名规范。 服务器通常有多块网卡,有板载集成的,同时也有插在PCIe插槽的。Linux系统的命名原来是et…...
java的一些冷知识
接口并没有继承Object类首先接口是一种特殊的类,理由就是将其编译后是一个class文件大家都知道java类都继承自Object,但是接口其实是并没有继承Object类的 可以自己写代码测试: 获取接口类的class对象后遍历它的methods,可以发现是不存在Obje…...

java代理模式
代理模式 为什么要学习代理模式?因为这是SpringAOP的底层! 【SpringAOP和SpingMVC}】 代理模式的分类: 静态代理 动态代理 代理就像这里的中介,帮助你去做向房东租房,你不能直接解出房东,而房东和中介…...
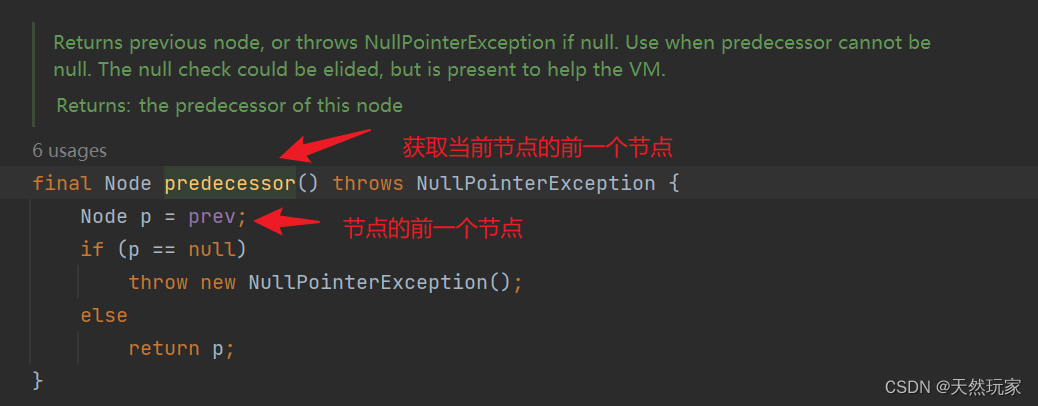
JUC包:CountDownLatch源码+实例讲解
1 缘起 有一次听到同事谈及AQS时,我有很多点懵, 只知道入队和出队,CLH(Craig,Landin and Hagersten)锁,并不了解AQS的应用, 同时结合之前遇到的多线程等待应用场景,发现…...

Log4j2基本使用
文章目录1. Log4j2入门2. Log4j2配置3. Log4j2异步日志4. Log4j2的性能Apache Log4j 2是对Log4j的升级版,参考了logback的一些优秀的设计,并且修复了一些问题,因此带 来了一些重大的提升,主要有: 异常处理,…...

A2L在CAN FD总线的使用
文章目录 前言CAN时间参数BTL CyclesTime Quantum时间份额SWJ同步跳转宽度波特率计算采样点计算CAN FD的第二采样点SSP推荐配置A2L配置总结前言 A2L作为XCP标定协议的载体,包括了总线信息的定义。本文介绍如何将基于CAN总线的A2L扩展为支持CAN-FD的A2L CAN时间参数 在介绍配…...

Android JetPack之启动优化StartUp初始化组件的详解和使用
一、背景 先看一下Android系统架构图 在Android设备中,设备先通电(PowerManager),然后加载内核层,内核走完,开始检查硬件,以及为硬件提供的公开接口,然后进入到库的加载。库挂载后开…...
[11]云计算|简答题|案例分析|云交付|云部署|负载均衡器|时间戳
升级学校云系统我们学校要根据目前学生互联网在线学习、教师教学资源电子化、教学评价过程化精细化的需求,计划升级为云教学系统。请同学们根据学校发展实际考虑云交付模型包含哪些?云部署采用什么模型最合适?请具体说明。9月3日买电脑还是租…...

C++11/C++14:lambda表达式
概念 lambda表达式:是一种表达式,是源代码的组成部分闭包:是lambda表达式创建的运行期对象,根据不同的捕获模式,闭包会持有数据的副本或引用闭包类:用于实例化闭包的类,每个lambda表达式都会触…...

算法课堂-分治算法
分治算法 把一任务分成几部分(通常是两部分)来完成(或只完成一部分),从而实现整个任务的完成 或者你可以把递归理解为分治算法的一部分 因为递归就是把问题分解来解决问题 例子 称假币 最笨的方法:两两称…...

操作系统权限提升(十六)之绕过UAC提权-CVE-2019-1388 UAC提权
系列文章 操作系统权限提升(十二)之绕过UAC提权-Windows UAC概述 操作系统权限提升(十三)之绕过UAC提权-MSF和CS绕过UAC提权 操作系统权限提升(十四)之绕过UAC提权-基于白名单AutoElevate绕过UAC提权 操作系统权限提升(十五)之绕过UAC提权-基于白名单DLL劫持绕过UAC提权 注&a…...
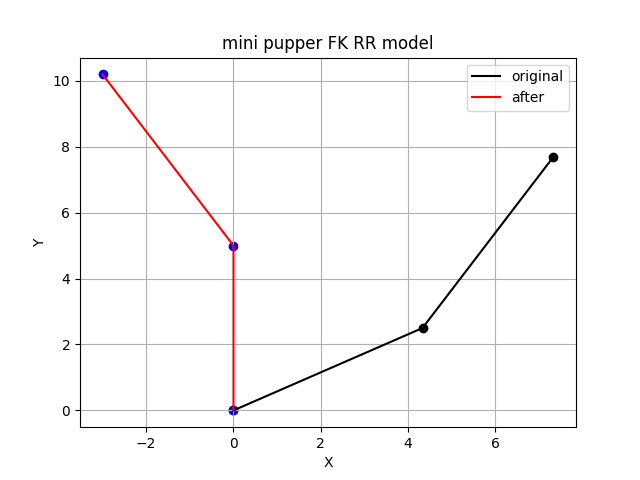
实例9:四足机器人运动学正解平面RR单腿可视化
实例9:四足机器人正向运动学单腿可视化 实验目的 通过动手实践,搭建mini pupper四足机器人的腿部,掌握机器人单腿结构。通过理论学习,熟悉几何法、旋转矩阵法在运动学正解(FK)中的用处。通过编程实践&…...
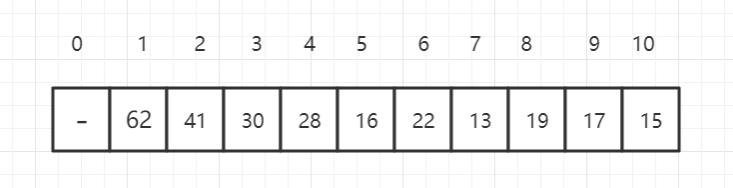
堆的基本存储
一、概念及其介绍堆(Heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵完全二叉树的数组对象。堆满足下列性质:堆中某个节点的值总是不大于或不小于其父节点的值。堆总是一棵完全二叉树。二、适用说明堆是利用完全二叉树的结构来维护一组数…...

如何获取物体立体信息通过一个相机
大家都知道的3D 技术是通过双眼视觉差异 得到的 但是3D的深度并没有那么强 为什么眼睛看到的就那么强 这无法让我们相信这个视觉差理论是和人眼睛立体感是一个原理 这个如今3D 电影都在用的技术 是和真正的人眼立体感 不一样的 或者说是有瑕疵的 分析一下现在的立体感技术 是通…...
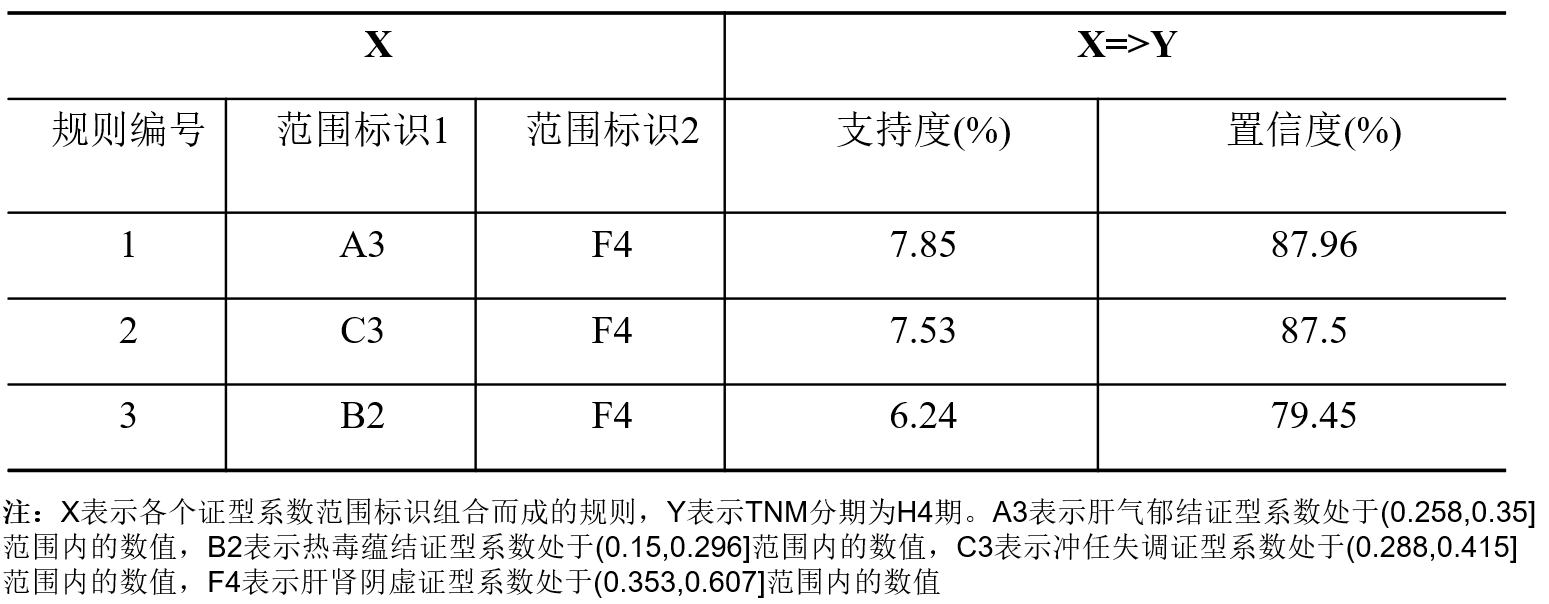
【数据挖掘实战】——中医证型的关联规则挖掘(Apriori算法)
目录 一、背景和挖掘目标 1、问题背景 2、传统方法的缺陷 3、原始数据情况 4、挖掘目标 二、分析方法和过程 1、初步分析 2、总体过程 第1步:数据获取 第2步:数据预处理 第3步:构建模型 三、思考和总结 项目地址:Data…...
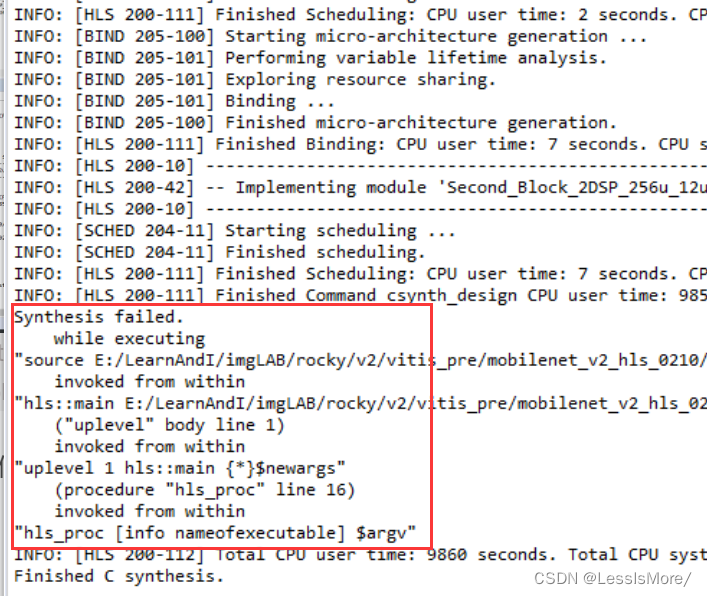
一些硬件学习的注意事项与快捷方法
xilinx系列软件 系统适用版本 要安装在Ubuntu系统的话,要注意提前看好软件适用的版本,不要随便安好了Ubuntu系统又发现对应版本的xilinx软件不支持。 如下图,发行说明中会说明这个版本的软件所适配的系统版本。 下载 vivado vitis这些都可以…...
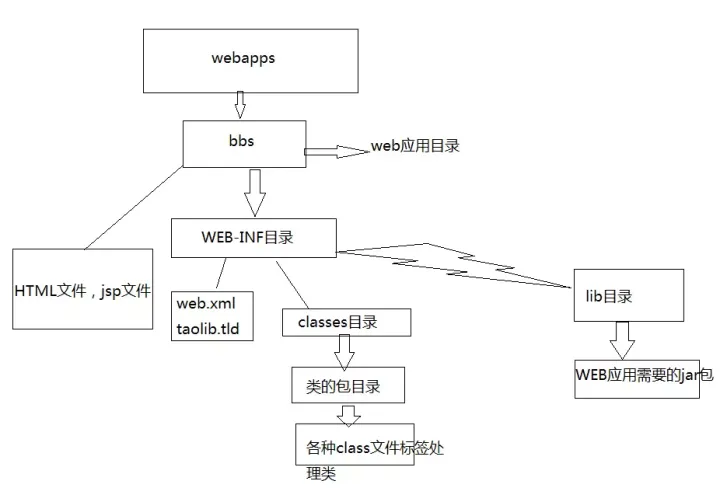
【Tomcat】Tomcat安装及环境配置
文章目录什么是Tomcat为什么我们需要用到Tomcattomcat下载及安装1、进入官网www.apache.org,找到Projects中的project List2、下载之后,解压3、找到tomcat目录下的startup.bat文件,双击之后最后结果出现多少多少秒,表示安装成功4、…...
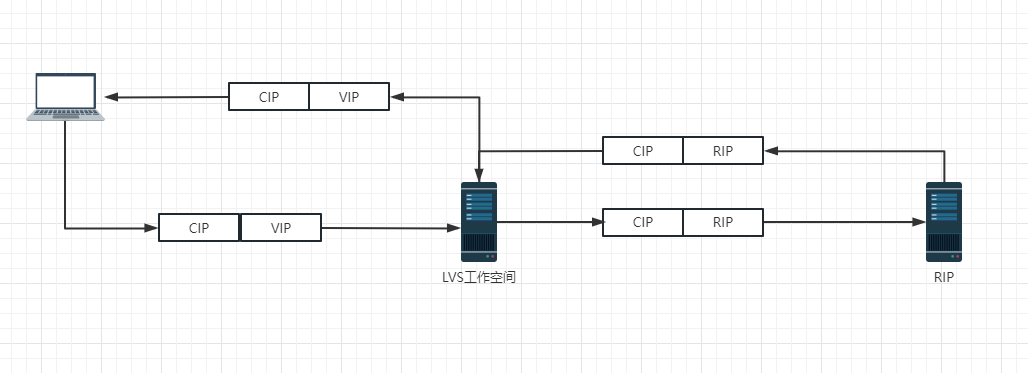
负载均衡:LVS 笔记(二)
文章目录LVS 二层负载均衡机制LVS 三层负载均衡机制LVS 四层负载均衡机制LVS 调度算法轮叫调度(RR)加权轮叫调度(WRR)最小连接调度(LC)加权最小连接调度(WLC)基于局部性的最少链接调…...
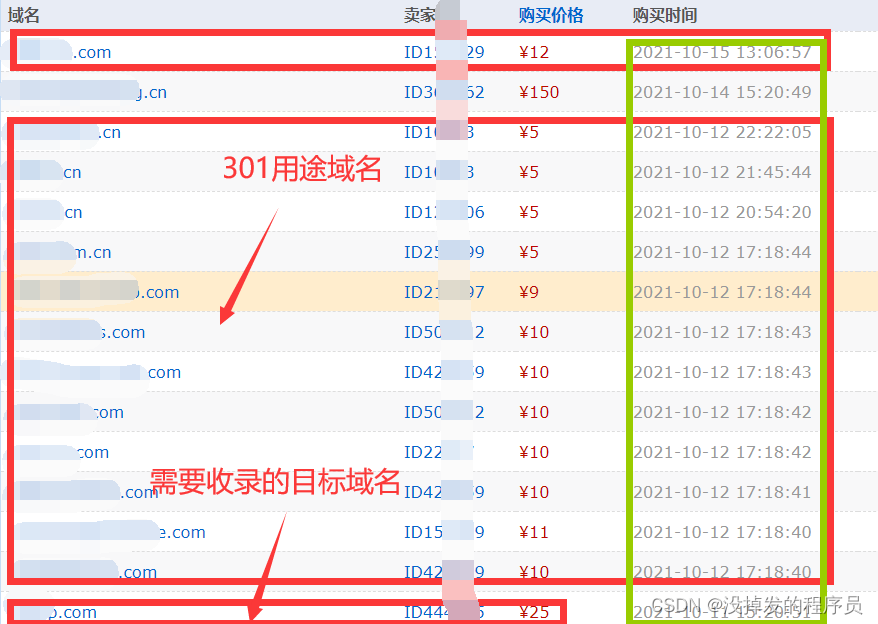
SEO优化:干货技巧分享,包新站1-15天100%收录首页
不管是老域名还是新域名,不管是多久没有收录首页的站,此法周期7-30天,包首页收录!本人不喜欢空吹牛逼不实践的理论,公布具体操作:假如你想收录的域名是a.com,那么准备如下材料1.购买5-10个最便宜…...

从恒流源到差动放大:铂电阻测温电路的优化路径与实践
1. 铂电阻测温基础与设计挑战 铂电阻作为工业测温的中坚力量,其核心优势在于稳定的物理特性。PT100在0℃时标称电阻为100Ω,温度系数为0.385Ω/℃。这个看似简单的参数背后,却隐藏着电路设计的三大矛盾:灵敏度与噪声的博弈、线性度…...

婚宴座位规划中的优化算法:量子与经典方法对比
1. 婚宴座位规划中的优化算法对决:量子与经典方法谁更胜一筹?筹备婚礼时,最令人头疼的任务之一就是安排座位。去年我为自己婚礼设计座位表时,尝试了各种方法——从手工调整Excel表格到使用专业活动策划软件,结果都不尽…...

终极指南:如何解决Pretty TypeScript Errors的10个常见问题与故障排除技巧
终极指南:如何解决Pretty TypeScript Errors的10个常见问题与故障排除技巧 【免费下载链接】pretty-ts-errors 🔵 Make TypeScript errors prettier and human-readable in VSCode 🎀 项目地址: https://gitcode.com/gh_mirrors/pr/pretty-…...

终极Blender 3MF插件:如何快速实现3D打印文件的无缝转换
终极Blender 3MF插件:如何快速实现3D打印文件的无缝转换 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat Blender3mfFormat是一款专为Blender设计的开源插件&a…...

AI相册搜索效率提升300%?Gemini驱动的Google Photos智能检索全解析,含实测对比数据与隐私边界警告
更多请点击: https://intelliparadigm.com 第一章:AI相册搜索效率提升300%?Gemini驱动的Google Photos智能检索全解析,含实测对比数据与隐私边界警告 Google Photos 近期将 Gemini Pro 1.5 深度集成至其搜索后端,支持…...

无人机安全测试终极实战指南:3大攻击向量深度解析与防护策略
无人机安全测试终极实战指南:3大攻击向量深度解析与防护策略 【免费下载链接】Drone-Hacking-Tool Drone Hacking Tool is a GUI tool that works with a USB Wifi adapter and HackRF One for hacking drones. 项目地址: https://gitcode.com/gh_mirrors/dr/Dron…...

如何用开源工具永久保存你的微信聊天记忆?完整指南揭秘数据备份终极方案
如何用开源工具永久保存你的微信聊天记忆?完整指南揭秘数据备份终极方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_…...

StreamCap:让直播录制变得如此简单的跨平台自动录制工具
StreamCap:让直播录制变得如此简单的跨平台自动录制工具 【免费下载链接】StreamCap Multi-Platform Live Stream Automatic Recording Tool | 多平台直播流自动录制客户端 基于FFmpeg 支持监控/定时/转码 项目地址: https://gitcode.com/gh_mirrors/st/StreamC…...

DES算法C++实现踩坑实录:S盒置换与比特操作的那些坑
DES算法C实现中的五大典型陷阱与解决方案 在实现DES算法的过程中,许多开发者都会遇到一些看似简单却容易导致加密结果错误的细节问题。本文将聚焦于实际编码中最常见的五个"坑点",通过具体案例分析和解决方案,帮助开发者快速定位和…...
)
Google Calendar智能安排深度拆解(Gemini原生集成技术白皮书级解析)
更多请点击: https://intelliparadigm.com 第一章:Gemini Google Calendar智能安排技术全景概览 Gemini 与 Google Calendar 的深度集成标志着日程管理进入语义理解驱动的新阶段。该能力并非简单调用 API,而是依托 Gemini 模型对自然语言指…...