0基础学习PyFlink——用户自定义函数之UDF
大纲
- 标量函数
- 入参并非表中一行(Row)
- 入参是表中一行(Row)
- alias
PyFlink中关于用户定义方法有:
- UDF:用户自定义函数。
- UDTF:用户自定义表值函数。
- UDAF:用户自定义聚合函数。
- UDTAF:用户自定义表值聚合函数。
这些字母可以拆解如下:
- UD表示User Defined(用户自定义);
- F表示Function(方法);
- T表示Table(表);
- A表示Aggregate(聚合);
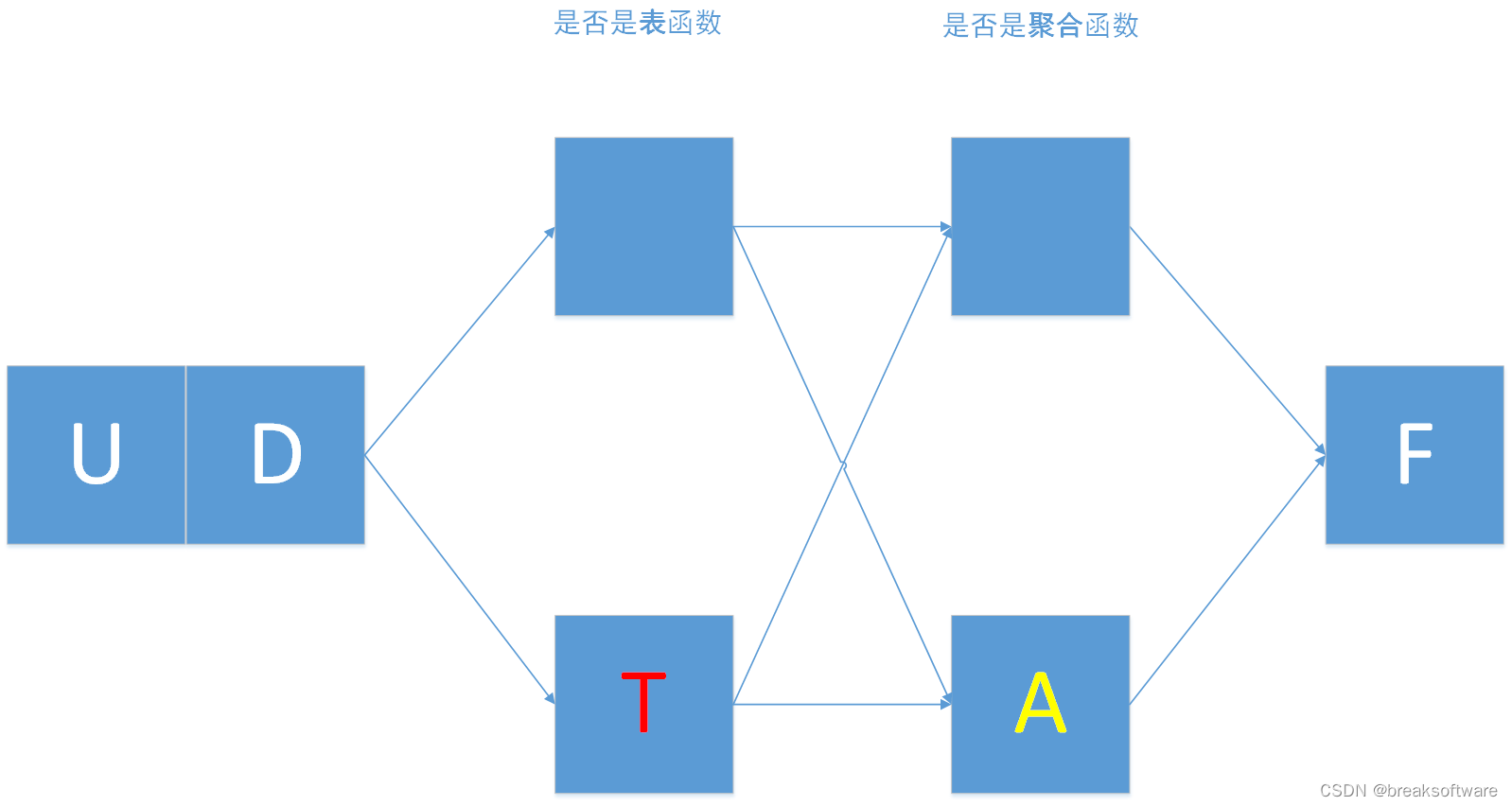
Aggregate(聚合)函数是指:以多行数据为输入,计算出一个新的值的函数。这块我们会在后续的章节介绍,本文我们主要介绍非聚合类型的用户自定义方法的简单使用。
标量函数
即我们常见的UDF。
def udf(f: Union[Callable, ScalarFunction, Type] = None,input_types: Union[List[DataType], DataType, str, List[str]] = None,result_type: Union[DataType, str] = None,deterministic: bool = None, name: str = None, func_type: str = "general",udf_type: str = None) -> Union[UserDefinedScalarFunctionWrapper, Callable]:
我们主要关注result_type和input_types,它们分别用于确定函数的输入和输出。
input_types可以是List[DataType], DataType, str, List[str]之一任何一种,这个要视使用者决定。UDTF也是这种类型,它们没啥区别。
result_type只能是DataType或str;而UDTF可以是List[DataType], DataType, str, List[str]任意之一。这也是UDF和UDTF最大的区别。
我们以一个例子来介绍它的用法。这个例子会将大写字符转换成小写字符,然后统计字符出现的次数。
在介绍例子之前,我们先构造Execute之前的准备环境
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf
import pandas as pd
from pyflink.table.udf import UserDefinedFunctionword_count_data = ["A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "A", "G"] def word_count():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('word', DataTypes.STRING())])tab_source = t_env.from_elements(map(lambda i: Row(i), word_count_data), row_type_tab_source)# define the sink schemasink_schema = Schema.new_builder() \.column("word", DataTypes.STRING().not_null()) \.column("count", DataTypes.BIGINT()) \.primary_key("word") \.build()# Create a sink descriptorsink_descriptor = TableDescriptor.for_connector('print')\.schema(sink_schema) \.build()t_env.create_temporary_table("WordsCountTableSink", sink_descriptor)
这段代码从读取数据word_count_data,并构造出tab_source作为输入数据暂存的表。下面我们看下入参不同时,UDF怎么写
入参并非表中一行(Row)
@udf(result_type=DataTypes.ROW([DataTypes.FIELD("lower_word", DataTypes.STRING())]), input_types=[DataTypes.STRING()])def colFunc(oneCol):return Row(oneCol.lower())
input_types我们设置成[DataTypes.STRING()],即该数组中只有一个参数,也表示修饰的方法只有一个参数,类型是String。如果觉得input_types写起来麻烦,这个参数可以不设置。
result_type我们设置为一个DataTypes.ROW([DataTypes.FIELD(“lower_word”, DataTypes.STRING())])。我们可以把它看成是一个新表的结构描述,即一行只有一个字段——lower_word,它的类型也是String。
tab_lower=tab_source.map(colFunc(col('word')))
map方法中,我们会给UDF修饰的方法传入原始表tab_source每行中的word字段的值。然后构造出一个新的表tab_lower。这个新的表没有word字段,只有UDF中result_type定义的lower_word。
def map(self, func: Union[Expression, UserDefinedScalarFunctionWrapper]) -> 'Table':
后续只要使用这个新表,新字段即可。
tab_lower.group_by(col('lower_word')) \.select(col('lower_word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()
完整代码
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf
import pandas as pd
from pyflink.table.udf import UserDefinedFunctionword_count_data = ["A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "A", "G"] def word_count():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('word', DataTypes.STRING())])tab_source = t_env.from_elements(map(lambda i: Row(i), word_count_data), row_type_tab_source )# define the sink schemasink_schema = Schema.new_builder() \.column("word", DataTypes.STRING().not_null()) \.column("count", DataTypes.BIGINT()) \.primary_key("word") \.build()# Create a sink descriptorsink_descriptor = TableDescriptor.for_connector('print')\.schema(sink_schema) \.build()t_env.create_temporary_table("WordsCountTableSink", sink_descriptor)@udf(result_type=DataTypes.ROW([DataTypes.FIELD("lower_word", DataTypes.STRING())]), input_types=[DataTypes.STRING()])def colFunc(oneCol):return Row(oneCol.lower())tab_lower=tab_source.map(colFunc(col('word'))) tab_lower.group_by(col('lower_word')) \.select(col('lower_word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()if __name__ == '__main__':word_count()
入参是表中一行(Row)
@udf(result_type=DataTypes.ROW([DataTypes.FIELD("lower_word", DataTypes.STRING())]), input_types=row_type_tab_source)def rowFunc(row):return Row(row[0].lower())tab_lower=tab_source.map(rowFunc) tab_lower.group_by(col('lower_word')) \.select(col('lower_word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()
主要的区别是map方法直接传递udf修饰的方法,而不是直接其调用返回值。input_types是原始表的行结构——RowType,而不是一个参数数组。
map方法给rowFunc传递原始表tab_source的每行数据,然后构造出一个新表tab_lower。新表的字段也在udf的result_type中定义了,它是String类型的lower_word。后面我们对新表就要聚合统计这个新的字段,而不是老表中的字段。
alias
前面两个案例,在定义UDF时,我们严格设置了result_type和input_types。实际input_types可以不用设置,但是result_type必须设置。上面例子中,result_type我们都设置为RowType,即表行的结构。如果觉得这样写很麻烦,可以考虑使用alias来实现。
@udf(result_type=DataTypes.STRING())def colFunc(oneCol):return oneCol.lower()tab_lower=tab_source.map(colFunc(col('word'))).alias('lower_word')tab_lower.group_by(col('lower_word')) \.select(col('lower_word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()
@udf(result_type=DataTypes.STRING())def rowFunc(row):return row[0].lower()tab_lower=tab_source.map(rowFunc).alias('lower_word')tab_lower.group_by(col('lower_word')) \.select(col('lower_word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()
这样我们在定义udf时,只是指定了返回类型是个字符串,也不知道它在新表中叫啥名字(实际叫f0)。但是为了便于后续使用,我们使用alias给它取了一个别名lower_word。这样就可以让其参与后续的计算了。
相关文章:
0基础学习PyFlink——用户自定义函数之UDF
大纲 标量函数入参并非表中一行(Row)入参是表中一行(Row)alias PyFlink中关于用户定义方法有: UDF:用户自定义函数。UDTF:用户自定义表值函数。UDAF:用户自定义聚合函数。UDTAF&…...

英语小作文模板(06求助+描述;07描述+建议)
06 求助描述: 题目背景及要求 第一段 第二段 第三段 翻译成中文 07 描述+建议: 题目背景及要求 第一段 第二段...

为什么感觉假期有时候比上班还累?
假期比上班还累的感觉可能由以下几个原因造成: 计划过度:在假期里,人们往往会制定各种计划,如旅游、聚会、休息等,以充分利用这段时间。然而,如果这些计划过于紧张或安排得过于紧密,就会导致身…...
推理还是背诵?通过反事实任务探索语言模型的能力和局限性
推理还是背诵?通过反事实任务探索语言模型的能力和局限性 摘要1 引言2 反事实任务2.1 反事实理解检测 3 任务3.1 算术3.2 编程3.3 基本的句法推理3.4 带有一阶逻辑的自然语言推理3.5 空间推理3.6 绘图3.7 音乐3.8 国际象棋 4 结果5 分析5.1 反事实条件的“普遍性”5…...
《利息理论》指导 TCP 拥塞控制
欧文费雪《利息原理》第 10 章,第 11 章对利息的几何说明是普适的,任何一个负反馈系统都能引申出新结论。给出原书图示,本文依据于此,详情参考原书: 将 burst 看作借贷是合理的,它包含成本(报文)…...
)
Bsdiff,Bspatch 的差分增量升级(基于Win和Linux)
目录 背景 内容 准备工作 在windows平台上 在linux平台上 正式工作 生成差分文件思路 作用差分文件思路 在保持相同目录结构进行差分增量升级 服务端(生成差分文件) 客户端(作用差分文件) 背景 像常见的Android 的linux平台,游戏,系统更新都…...

【3妹教我学历史-秦朝史】2 秦穆公-韩原之战
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 3妹:2哥,今天下班这么早&#…...

车载控制器
文章目录 车载控制器电动汽车上都有什么ECU 车载控制器 智能汽车上的控制器数量因车型和制造商而异。一般来说,现代汽车可能有50到100个电子控制单元(ECU)或控制器。这些控制器负责管理各种系统,如发动机管理、刹车、转向、空调、…...
回归预测 | Matlab实现RIME-CNN-SVM霜冰优化算法优化卷积神经网络-支持向量机的多变量回归预测
回归预测 | Matlab实现RIME-CNN-SVM霜冰优化算法优化卷积神经网络-支持向量机的多变量回归预测 目录 回归预测 | Matlab实现RIME-CNN-SVM霜冰优化算法优化卷积神经网络-支持向量机的多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.RIME-CNN-SVM霜冰优化算…...

使用Jaeger进行分布式跟踪:学习如何在服务网格中使用Jaeger来监控和分析请求的跟踪信息
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

添加多个单元对象
开发环境: Windows 11 家庭中文版Microsoft Visual Studio Community 2019VTK-9.3.0.rc0vtk-example参考代码 demo解决问题:不同阶段添加多个单元对象。 定义一个点集和一个单元集合,单元的类型可以是点、三角形、矩形、多边形等基本图形。只…...
十八、模型构建器(ModelBuilder)快速提取城市建成区——批量掩膜提取夜光数据、夜光数据转面、面数据融合、要素转Excel(基于参考比较法)
一、前言 前文实现批量投影栅格、转为整型,接下来重点实现批量提取夜光数据,夜光数据转面、夜光数据面数据融合、要素转Excel。将相关结果转为Excel,接下来就是在Excel中进行阈值的确定,阈值确定无法通过批量操作,除非采用其他方式,但是那样的学习成本较高,对于参考比较…...

HarmonyOS开发:基于http开源一个网络请求库
前言 网络封装的目的,在于简洁,使用起来更加的方便,也易于我们进行相关动作的设置,如果,我们不封装,那么每次请求,就会重复大量的代码逻辑,如下代码,是官方给出的案例&am…...
【杂记】Ubuntu20.04装系统,安装CUDA等
装20.04系统 安装系统的过程中,ROG的B660G主板,即使不关掉Secure boot也是可以的,不会影响正常安装,我这边出现问题的主要原因是使用了Ventoy制作的系统安装盘,导致每次一选择使用U盘的UEFI启动,就会跳回到…...

040-第三代软件开发-全新波形抓取算法
第三代软件开发-全新波形抓取算法 文章目录 第三代软件开发-全新波形抓取算法项目介绍全新波形抓取算法代码小解 关键字: Qt、 Qml、 抓波、 截获、 波形 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML(Qt Meta-Object …...
分享一个基于asp.net的供销社农产品商品销售系统的设计与实现(源码调试 lw开题报告ppt)
💕💕作者:计算机源码社 💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流! 💕&…...
Java基于SpringBoot的线上考试系统
1 摘 要 基于 SpringBoot 的在线考试系统网站,功能模块具有课程管理、成绩管理、教师管理、学生管理、考试管理以及基本信息的管理等,通过将系统分为管理员、授课教师以及学生,从不同的身份角度来对用户提供便利,将科技与教学模式…...

flask socketio 实时传值至html上【需补充实例】
目前版本如下 Flask-Cors 4.0.0 Flask-SocketIO 5.3.6from flask_socketio import SocketIO, emit 跨域问题网上的普通方法无法解决。 参考这篇文章解决 Flask教程(十九)SocketIO - 迷途小书童的Note迷途小书童的Note (xugaoxiang.com) app Flask(__name__) socketio Sock…...
C# Onnx P2PNet 人群检测和计数
效果 项目 代码 using Microsoft.ML.OnnxRuntime; using Microsoft.ML.OnnxRuntime.Tensors; using OpenCvSharp; using System; using System.Collections.Generic; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms;namespace Onnx…...
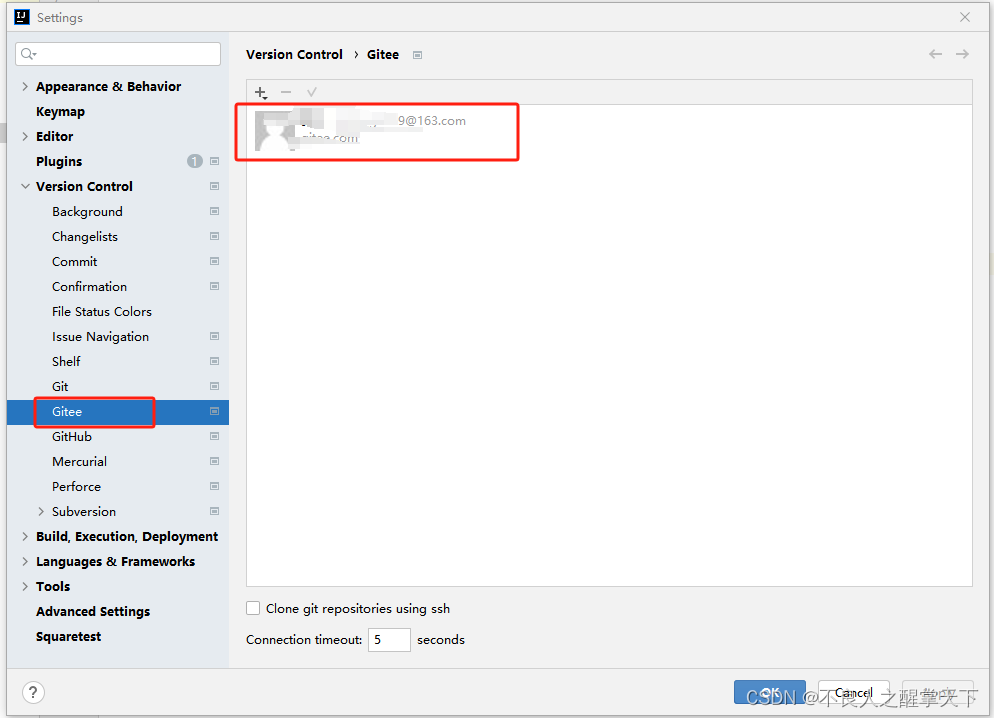
idea提交代码一直提示 log into gitee
解决idea提交代码一直提示 log into gitee问题 文章目录 打开setting->Version control->gitee,删除旧账号,重新配置账号,删除重新登录就好 打开setting->Version control->gitee,删除旧账号,重新配置账号,删除重新登…...

3分钟学会Charticulator:零代码制作专业数据图表的终极指南
3分钟学会Charticulator:零代码制作专业数据图表的终极指南 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 还在为制作专业图表而头疼吗?…...

从Mid360到自主移动:基于Fast-LIO与Move_Base的机器人导航实战拆解
1. Mid360激光雷达与Fast-LIO的适配实战 第一次拿到Livox Mid360激光雷达时,我完全被它36059的超大视场角惊艳到了。这款固态激光雷达不仅体积小巧,而且完全不用担心传统机械式雷达的电机磨损问题。但真正开始用它做SLAM时,才发现实物开发和仿…...

游戏存档管理终极指南:告别背包焦虑的5大解决方案
游戏存档管理终极指南:告别背包焦虑的5大解决方案 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为游戏中的装备堆积如山而烦恼吗?每次冒险归来…...
实战:D310T9362V1SPEC触摸屏驱动从零适配与调试(竖屏))
RK3566(泰山派)实战:D310T9362V1SPEC触摸屏驱动从零适配与调试(竖屏)
1. RK3566与D310T9362V1SPEC屏幕简介 RK3566是瑞芯微推出的一款高性能嵌入式处理器,采用四核Cortex-A55架构,主频可达1.8GHz。这款芯片在工业控制、智能家居和物联网设备中广泛应用,特别适合需要图形显示和触摸交互的场景。我最近在一个智能终…...

【NotebookLM统计方法选择权威指南】:20年数据科学家亲授5大避坑法则与3步决策框架
更多请点击: https://kaifayun.com 更多请点击: https://intelliparadigm.com 第一章:NotebookLM统计方法选择的核心挑战与认知重构 NotebookLM 作为 Google 推出的面向研究者与知识工作者的 AI 助手,其核心能力依赖于对用户上传…...

多线程渲染与路径算法重构:HiveWE如何革新魔兽争霸III地图编辑
多线程渲染与路径算法重构:HiveWE如何革新魔兽争霸III地图编辑 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 技术痛点:二十年技术债务下的地图创作瓶颈 魔兽争霸III地图编辑器自2…...

Agent 工程化系列 · 第 13 篇_Agent安全与可靠性如何保障
Agent 工程化系列 第 13 篇 Agent 的安全与可靠性如何保障? Agent 最危险的不是回答错,而是执行错开篇定位 前面我们已经讲过:LLM 是能力核心,Agent 是执行系统;Function Call 让模型能够调用工具;MCP 负责…...

终极装备管家:TQVaultAE如何彻底解决《泰坦之旅》仓库爆满难题
终极装备管家:TQVaultAE如何彻底解决《泰坦之旅》仓库爆满难题 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为《泰坦之旅》中堆积如山的传奇装备无处安放…...

Linux高手必备:从安全操作到高效运维的12个核心习惯
1. 为什么说“习惯”是Linux高手的护城河刚接触Linux那会儿,我总觉得高手和菜鸟的区别在于记住了多少命令、会不会写复杂的脚本。后来踩了无数坑、熬了无数夜、甚至搞崩过几次生产环境后,我才恍然大悟:真正的分水岭,其实藏在那些日…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...