Kafka - 3.x 消费者 生产经验不完全指北
文章目录
- 生产经验之Consumer事务
- 生产经验—数据积压(消费者如何提高吞吐量)

生产经验之Consumer事务
Kafka引入了消费者事务(Consumer Transactions)来确保在消息处理期间维护端到端的数据一致性。这使得消费者能够以事务的方式处理消息,包括从Kafka中读取消息、处理消息和提交消息的offset。以下是有关Kafka消费者事务的详细信息:
-
事务的引入:Kafka 0.11.0版本引入了消费者事务的功能。之前,Kafka的消费者通常使用手动提交offset的方式,但这种方式可能导致消息被重复消费或漏消费,特别是在处理消息和提交offset之间发生错误的情况下。
-
Consumer Transactions的目的:消费者事务的主要目的是确保消息被精确一次性地处理。这对于需要强一致性的应用程序非常重要,例如金融或电子商务领域。
-
核心概念:Kafka消费者事务依赖于以下核心概念:
- 事务ID:每个事务都有一个唯一的ID,用于跟踪和标识事务。
- 事务生命周期:一个事务有三个主要阶段:开始事务、处理消息、提交事务。
- 事务性消费:消费者在处理消息时将其包装在一个事务中,然后可以选择性地提交事务,以决定是否将offset提交到Kafka。
-
使用消费者事务:要使用消费者事务,消费者需要执行以下步骤:
- 开始事务:使用
beginTransaction()方法开始一个新的事务。 - 处理消息:在事务内处理Kafka中的消息。
- 提交或中止事务:使用
commitTransaction()提交事务或使用abortTransaction()中止事务。如果事务被提交,那么offset也会被提交;如果事务被中止,offset不会被提交。
- 开始事务:使用
-
事务保证:Kafka消费者事务提供了以下保证:
- Exactly-Once Semantics:确保消息在事务内被处理一次,从而避免了重复消费和漏消费。
- 事务性处理:事务内的消息处理要么全部成功,要么全部失败,从而保持数据的一致性。
-
事务的限制:消费者事务也有一些限制,包括:
- 消费者必须使用新的Kafka协议版本(0.11.0.0及以上)。
- 事务涉及到资源的分配,可能会引入一些开销,因此需要根据具体的用例来评估是否使用。
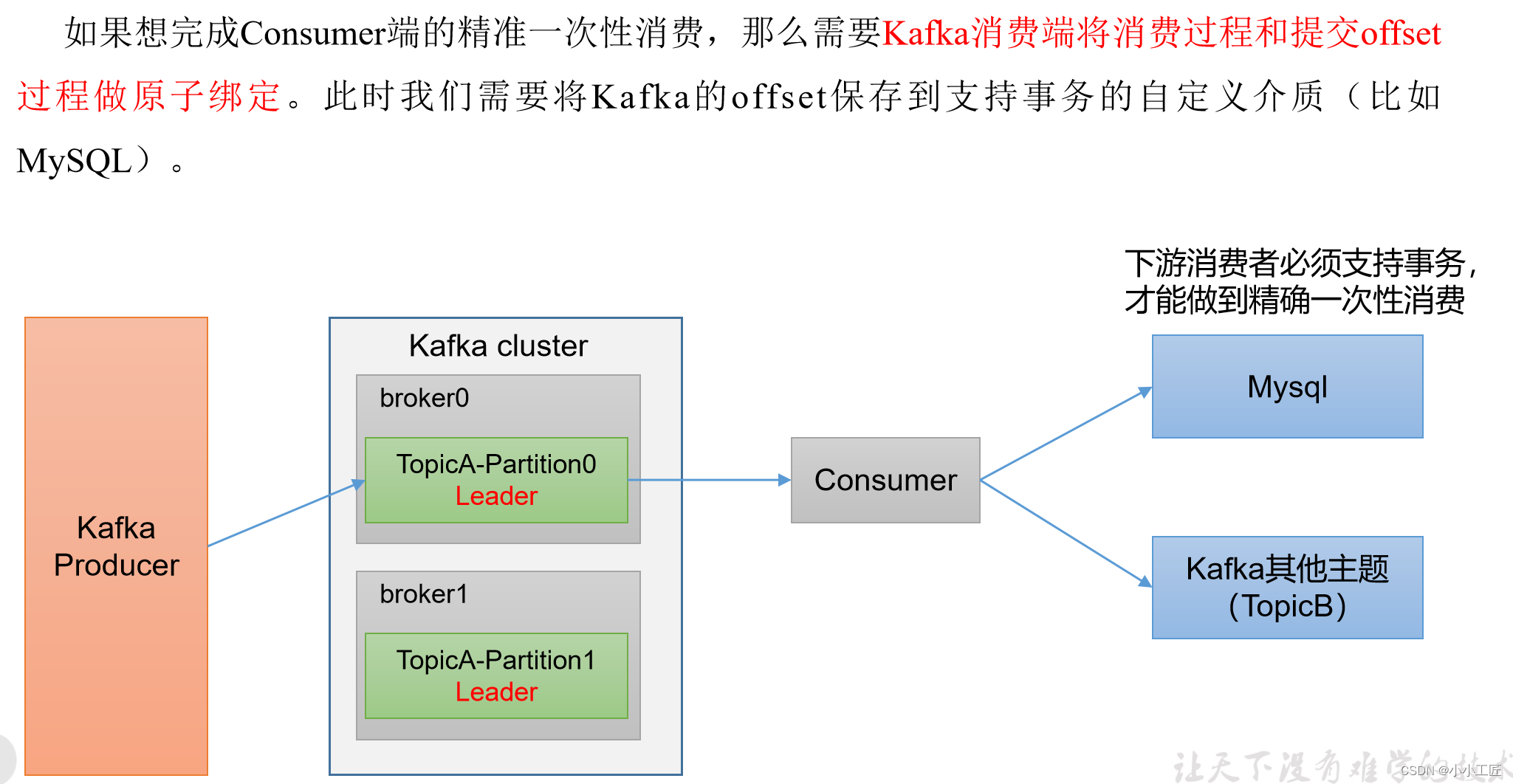
总的来说,Kafka消费者事务提供了可靠的消息处理机制,可以确保消息被精确一次性地处理。这对于需要强一致性的应用程序非常有价值,但也需要在使用时谨慎考虑性能开销和兼容性问题。
生产经验—数据积压(消费者如何提高吞吐量)
提高Kafka消费者的吞吐量是许多应用程序的关键优化目标,特别是在需要处理大量数据的情况下。以下是一些方法,可以帮助你提高Kafka消费者的吞吐量:
-
并行处理:使用多个消费者实例并行处理消息。每个消费者实例可以运行在不同的线程或进程中,从不同的分区中读取消息。这可以有效地利用多核CPU和多台机器的资源。
-
增加分区数:如果Kafka Topic的吞吐量不足,可以考虑增加分区数。更多的分区可以提高并行性,允许更多的消费者同时处理消息。
-
适当调整消费者参数:调整消费者的参数以提高性能。例如,增加
max.poll.records以一次获取更多的消息,或者适当增加fetch.max.bytes以增加每次获取的数据量。 -
使用高性能消费者:一些Kafka客户端库提供了高性能的消费者实现,如Apache Kafka的Java客户端,它具有较低的延迟和更高的吞吐量。选择适当的消费者库对性能至关重要。
-
优化消息处理逻辑:消息处理逻辑应尽量简化和优化,以降低处理每条消息的时间。使用多线程或异步处理可以提高效率,但要注意线程安全和异常处理。
-
合理设置批量处理:在消息处理中,可以考虑批量处理消息,而不是逐条处理。这可以减少网络开销和提高处理效率。
-
使用合适的分区分配策略:选择适当的分区分配策略,以确保分区分配在不同的消费者之间均匀分布,以充分利用多个消费者实例的并行性。
-
使用消息压缩:在网络带宽受限的情况下,启用消息压缩可以减少数据传输的开销,提高吞吐量。
-
使用本地缓存:为消息处理逻辑引入本地缓存,以减少对外部资源(例如数据库)的访问次数。这可以减少延迟并提高吞吐量。
-
合理设置并监控资源:确保消费者实例拥有足够的CPU、内存和网络资源,并监控这些资源的使用情况,以及时发现和解决性能瓶颈。
-
分布式消费者组管理:如果你的应用需要高可用性和横向扩展,可以考虑使用分布式消费者组管理工具,如Apache Kafka Streams或其他流处理框架。
| 参数名称 | 描述 |
|---|---|
| fetch.max.bytes | 消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50MB),仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受message.max.bytes(broker配置)或max.message.bytes(主题配置)的影响。 |
| max.poll.records | 一次poll拉取数据返回消息的最大条数,默认是500条。 |
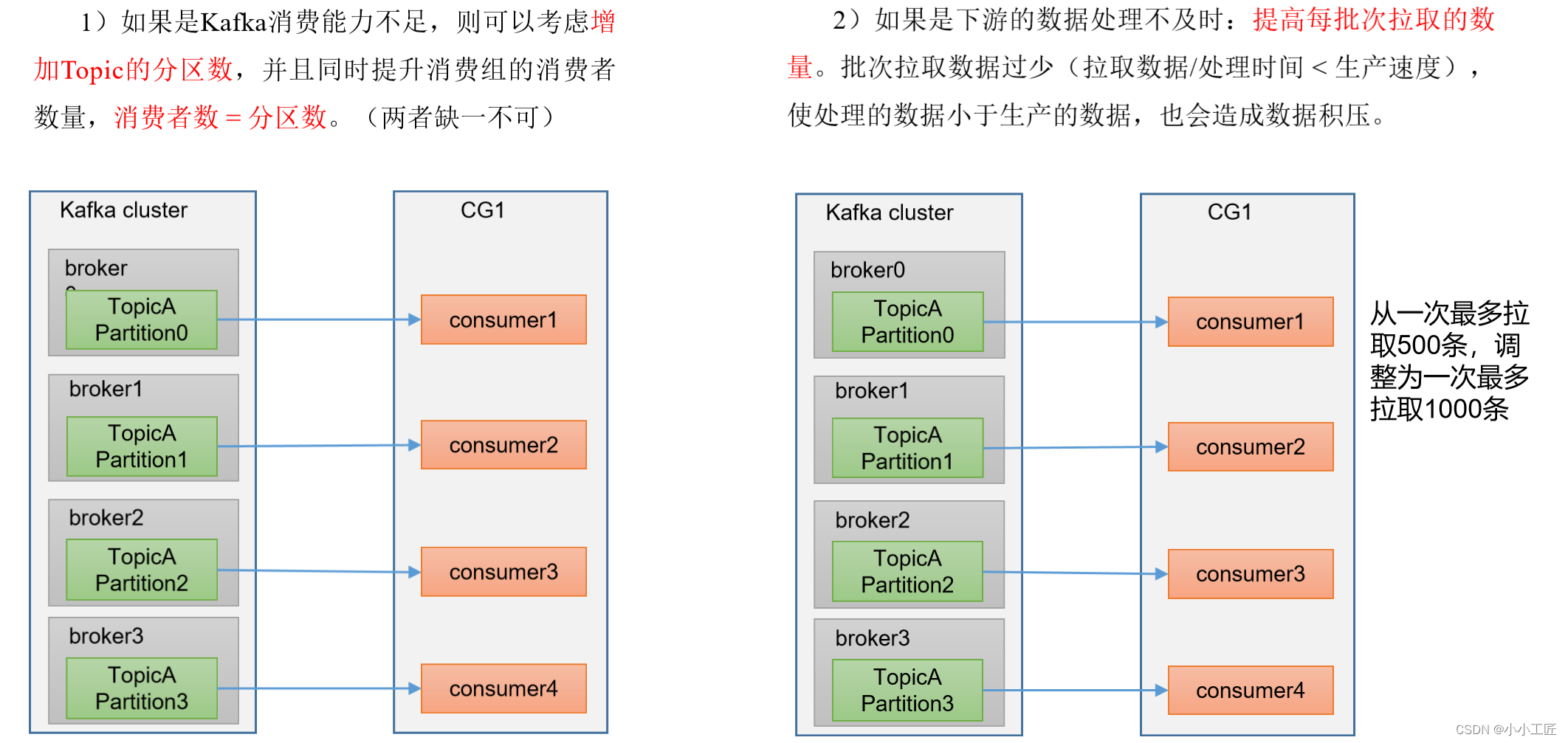
最终,提高Kafka消费者的吞吐量需要综合考虑多个因素,包括硬件资源、消费者配置、消息处理逻辑等。通过结合上述方法,你可以有效地提高消费者的性能和吞吐量。
相关文章:
Kafka - 3.x 消费者 生产经验不完全指北
文章目录 生产经验之Consumer事务生产经验—数据积压(消费者如何提高吞吐量) 生产经验之Consumer事务 Kafka引入了消费者事务(Consumer Transactions)来确保在消息处理期间维护端到端的数据一致性。这使得消费者能够以事务的方式…...
UDP网络编程的接受与发送信息
/发送端B>可以接受数据 public class UDPSenderB {public static void main(String[] args) throws IOException {//创建一个DatagramSocket 对象,准备发送和接受数据DatagramSocket socket new DatagramSocket(9998);//将需要发送的数据,封装到Data…...

RK3588开发笔记-USB3.0接口调试
目录 前言 一、资源介绍 二、硬件连接 三、设备树配置...
AI绘画|midjourney入门保姆教程,30秒出专业大片,国内直接使用
同学们,之前大家想用midjourney还需要魔法上网和很复杂的注册配置,现在微信里就能使用midjourney了, 还支持中文,大家赶紧来试试吧。 AI写稿专家 www.promptspower.comhttp://www.promptspower.com 我们还给大家提供了各个行业的…...

阿里发布AI编码助手:通义灵码,兼容 VS Code、IDEA等主流编程工具
今天是阿里云栖大会的第一天,相信场外的瓜,大家都吃过了。这里就不说了,有兴趣可以看看这里:云栖大会变成相亲现场,最新招婿鄙视链来了... 。 这里主要说说阿里还发布了一款AI编码助手,对于我们开发者来说…...

【Linux】-进程控制(深度理解写时拷贝、exit函数、return的含义以及makefile编译多个程序)-进程创建、进程终止、进程等待、进程程序替换
💖作者:小树苗渴望变成参天大树🎈 🎉作者宣言:认真写好每一篇博客💤 🎊作者gitee:gitee✨ 💞作者专栏:C语言,数据结构初阶,Linux,C 动态规划算法🎄 如 果 你 …...
【mfc/VS2022】计图实验:绘图工具设计知识笔记3
实现类对串行化的支持 如果要用CArchive类保存对象的话,那么这个对象的类必须支持串行化。一个可串行化的类通常有一个Serialize成员函数。要想使一个类可串行化,要经历以下5个步骤: 1、从CObject派生类 2、重写Serialize成员函数 3、使用DE…...

Leetcode—1488.避免洪水泛滥【中等】
2023每日刷题(十四) Leetcode—1488.避免洪水泛滥 算法思想 将晴天的日期全部记录在set<int> sun中使用unordered_map<int, int> lakeRainy来记录每个湖泊上一次下雨的日期遇到晴天时先不用管抽哪个湖当下雨时,湖泊已经装满水时…...

CSS与基本选择器
<div class"c1" id"d1"></div> CSS基本知识 什么是css:CSS(Cascading Style Sheet,层叠样式表)定义如何显示HTML元素。 当浏览器读到一个样式表,他就会按照这个样式l来进行渲染。其实就是让HT…...
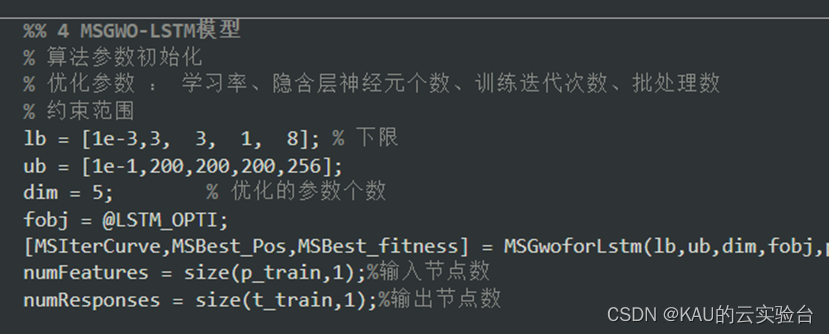
回归算法|长短期记忆网络LSTM及其优化实现
本期文章将介绍LSTM的原理及其优化实现 序列数据有一个特点,即“没有曾经的过去则不存在当前的现状”,这类数据以时间为纽带,将无数个历史事件串联,构成了当前状态,这种时间构筑起来的事件前后依赖关系称其为时间依赖&…...
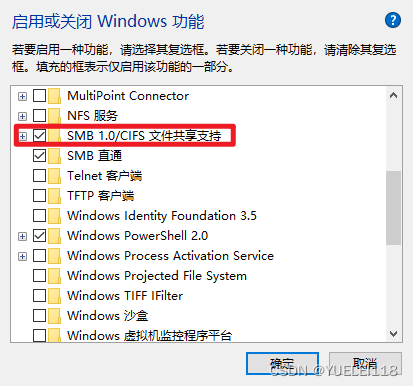
小米电视播放win10视频 win10共享问题
解决的方法就是安装SMB1.0协议 重启就OK了...

uniApp开发注意要点提炼-xyphf
我们在使用uniApp开发的时候,很多朋友由于对多端兼容性的不了解,结果在多端编译的时候经常出这样或者那样的问题,而不断的说uniApp这坑那坑的,下面我基于自身经验和官网说明提炼一些常见的注意要点。 因为很多公司时常初衷是开发一…...

DHorse改用fabric8的SDK与k8s集群交互
现状 在dhorse 1.4.0版本之前,一直使用k8s官方提供的sdk与k8s集群交互,官方sdk的Maven坐标如下: <dependency><groupId>io.kubernetes</groupId><artifactId>client-java</artifactId><version>18.0.0…...

如何在阿里云国际站服务器上添加IP白名单?
跟着云核算的发展,越来越多的企业和个人开始使用阿里云服务器。为了确保服务器的安全,咱们需要在阿里云服务器上增加IP白名单。这篇文章将具体解说如何在阿里云服务器上增加IP白名单。 增加IP白名单是保证服务器安全的重要手法之一。通过增加IP白名单&am…...

GPT实战系列-ChatGLM2模型的微调训练参数解读
GPT实战系列-ChatGLM2模型的微调训练参数解读 目录 GPT实战系列-ChatGLM2模型的微调训练参数解读ChatGLM2模型1、P-Tuning模型微调2、微调训练配置参数train.sh中配置参数训练配置信息模型配置信息附录:训练正常运行打印信息 ChatGLM2模型 ChatGLM-6B是开源的文本生…...
RabbitMQ入门到实战教程,消息队列实战,改造配置MQ
RabbitMQ入门到实战教程,MQ消息中间件,消息队列实战-CSDN博客 3.7.Topic交换机 3.7.1.说明 Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。 只不过Topic类型Exchange可以让队列在绑定BindingKey 的时候…...
phar反序列化学习
PHP反序列化常见的是使用unserilize()进行反序列化,除此之外还有其它的反序列化方法,不需要用到unserilize()。就是用到phar反序列化。 Phar phar文件 Phar是将php文件打包而成的一种压缩文档,类似于Java中的jar包。它有一个特性就是phar文…...
十年回望 -- JAVA
十年 十年时间,弹指一挥,好像一直都是在为工作奔波,匆匆忙忙的十年。 一、个人介绍 本人毕业于一所很普通的公办专科院校(全日制统招大专),专业是软件技术,当初能进入计算机这一行业࿰…...

Linux 环境下 安装 Elasticsearch 7.13.2
Linux 环境下 安装 Elasticsearch 7.13.2 前言镜像下载(国内镜像地址)解压安装包修改配置文件用 Es 自带Jdk 运行配置 Es 可被远程访问然后启动接着启动本地测试一下能不能连 Es 前言 借公司的 centos 7 服务器,搭建一个 Es,正好熟…...
心理咨询预约小程序
随着微信小程序的日益普及,越来越多的人开始关注如何利用小程序来提供便捷的服务。对于心理咨询行业来说,搭建一个心理咨询预约小程序可以大大提高服务的效率和用户体验。本文以乔拓云平台为例,详细介绍如何轻松搭建一个心理咨询预约小程序。…...

Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别
Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维…...

制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践
制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造与工业4.0的浪潮中,制造业企业面临着…...

ARMv8-AArch64 异常处理实战:从寄存器解析到调试技巧
1. ARMv8-AArch64异常处理入门指南 第一次接触ARMv8架构的异常处理时,我被那一堆寄存器搞得头晕眼花。ELR、ESR、FAR...这些缩写看起来就像天书一样。但经过几个实际项目的磨练后,我发现只要掌握几个关键点,异常处理其实并没有想象中那么难。…...

3DS游戏格式转换实战指南:5步完成CCI到CIA的高效转换
3DS游戏格式转换实战指南:5步完成CCI到CIA的高效转换 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 作为一名3…...

UEFITool深度解析:实战指南与高效使用技巧
UEFITool深度解析:实战指南与高效使用技巧 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款专为UEFI固件分析设计的开源工具,能够将复杂的二进制固件映像…...

基于Readability算法的网页内容提取服务:从原理到工程实践
1. 项目概述:一个为现代阅读而生的开源工具 最近在折腾个人知识库和稍后读系统时,我一直在找一个能完美解决“网页内容净化与结构化”痛点的工具。市面上的方案要么太重,要么太简陋,直到我遇到了 Cat-tj/web-reader 。这不仅仅是…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...

实战指南:用UABEA高效解析Unity资源结构的5个关键要点
实战指南:用UABEA高效解析Unity资源结构的5个关键要点 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity开发的世界里,资源管理往往是项目优化中最棘手的一环。你是否曾经…...

如何3分钟快速上手企业级后台管理系统:终极配置秘籍
如何3分钟快速上手企业级后台管理系统:终极配置秘籍 【免费下载链接】ant-design-vue3-admin 一个基于 Vite2 Vue3 Typescript tsx Ant Design Vue 的后台管理系统模板,支持响应式布局,在 PC、平板和手机上均可使用 项目地址: https://…...

ANSYS APDL函数方程加载:从GUI操作到命令流集成的完整指南
1. 项目概述:为什么我们需要函数方程加载?在ANSYS的仿真世界里,我们经常遇到一个头疼的问题:载荷不是一成不变的。比如,一个大型储罐的侧壁,水压会随着深度线性增加;一个高速旋转的叶片…...