python爬虫,如何在代理的IP被封后立刻换下一个IP继续任务?
前言
在实际的爬虫应用中,爬虫程序经常会通过代理服务器来进行网络访问,以避免访问过于频繁而受到网站服务器的限制。但是,代理服务器的IP地址也可能被目标网站限制,导致无法正常访问。这时候,我们需要在代理IP被封后立刻换下一个IP继续任务,以保证爬虫的正常运行。
本文将介绍在Python中如何实现代理IP的动态切换,并给出相关的代码案例。在讲解具体实现方法之前,我们先了解一下代理服务器的基本原理。

一、 代理服务器的工作原理
代理服务器是一种在客户端与服务器之间进行转发的服务器。当客户端向服务器发起网络请求时,代理服务器会先接收这个请求,然后再将请求转发给目标服务器,最后将目标服务器返回的响应结果再转发给客户端。代理服务器在这个过程中扮演了中间人的角色,可以对客户端和服务器之间的通信进行拦截和修改。
代理服务器对爬虫程序的作用主要体现在以下两个方面:
- 隐藏客户端的真实IP地址,保护客户端的隐私和安全;
- 分散客户端的网络访问,降低被目标服务器封禁的风险。
代理服务器有多种工作模式,其中最常用的模式是HTTP代理。HTTP代理是基于HTTP协议的代理模式,客户端的HTTP请求会先被发送到代理服务器上,然后再由代理服务器转发给目标服务器,例如以下代码:
import requestsproxies = {'http': 'http://127.0.0.1:8080', # HTTP代理服务器地址和端口'https': 'http://127.0.0.1:8080' # HTTPS代理服务器地址和端口
}response = requests.get("http://www.example.com", proxies=proxies)在这个例子中,我们使用了requests库来发送HTTP请求,其中proxies参数指定了HTTP代理服务器的地址和端口。需要注意的是,这里使用的代理服务器是本机上的一个HTTP代理服务器,如果要使用其他代理服务器,需要替换IP地址和端口号。
为了实现代理IP的动态切换,我们需要了解如何使用Python来自动获取可用的代理IP列表,并在IP被封后自动切换到下一个可用的IP。接下来,我们将详细介绍这个过程。
二、获取可用的代理IP列表
获取可用的代理IP列表有多种方法,其中一种常用的方法是从代理IP网站上爬取代理IP信息。代理IP网站上通常会提供免费的代理IP列表,我们只需要对其进行爬取和验证即可得到可用的代理IP列表。
以下是一个实现自动获取代理IP列表的示例代码:
import requests
from bs4 import BeautifulSoup
import timedef get_proxy_list():# 获取代理IP列表的URLurl = "http://www.example.com/proxy_list.html"# 发送请求获取页面内容response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')# 解析HTML页面,获取代理IP列表proxy_list = []for tr in soup.find_all('tr'):tds = tr.find_all('td')if len(tds) == 2:ip = tds[0].get_text()port = tds[1].get_text()proxy = '{}:{}'.format(ip, port)proxy_list.append(proxy)return proxy_listdef test_proxy(proxy):# 测试代理IP的可用性try:proxies = {'http': 'http://{}'.format(proxy),'https': 'https://{}'.format(proxy)}response = requests.get('http://www.baidu.com', proxies=proxies, timeout=5)if response.status_code == 200:return Trueexcept:return Falsedef get_available_proxies(proxy_list):# 获取可用的代理IP列表available_proxies = []for proxy in proxy_list:if test_proxy(proxy):available_proxies.append(proxy)return available_proxiesif __name__ == '__main__':proxy_list = get_proxy_list()available_proxies = get_available_proxies(proxy_list)print('Available proxies: {}'.format(available_proxies))在这个示例代码中,我们首先定义了一个get_proxy_list函数,用于从网站上获取代理IP列表。该函数通过requests库发送HTTP请求,然后使用BeautifulSoup库解析HTML页面,获取代理IP列表。
接下来,我们定义了一个test_proxy函数,用于测试代理IP的可用性。该函数使用requests库发送HTTP请求,如果请求成功返回了200状态码,则认为该代理IP可用。
最后,我们定义了一个get_available_proxies函数,用于获取可用的代理IP列表。该函数遍历原始代理IP列表,依次测试每个代理IP的可用性,将可用的代理IP添加到新的列表中。
注意,在测试代理IP的可用性时,我们需要设置一个较短的超时时间,以避免因为等待时间过长而浪费时间。此外,由于测试代理IP的过程很可能会失败,因此我们还需要添加异常处理逻辑,确保程序不会因为一个代理IP的失效而停止运行。
三、实现代理IP的动态切换
在获取可用的代理IP列表后,我们需要实现代理IP的动态切换。具体思路是,在向目标服务器发送HTTP请求前,先从代理IP列表中选取一个可用的代理IP,如果该代理IP不能正常工作,则切换到下一个可用的代理IP,直到找到能正常工作的代理IP为止。
以下是一个实现代理IP的动态切换的示例代码:
import requests
from bs4 import BeautifulSoup
import random
import time# 全局变量,代理IP列表
PROXY_LIST = []def get_proxy_list():# 获取代理IP列表的URLurl = "http://www.example.com/proxy_list.html"# 发送请求获取页面内容response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')# 解析HTML页面,获取代理IP列表proxy_list = []for tr in soup.find_all('tr'):tds = tr.find_all('td')if len(tds) == 2:ip = tds[0].get_text()port = tds[1].get_text()proxy = '{}:{}'.format(ip, port)proxy_list.append(proxy)return proxy_listdef test_proxy(proxy):# 测试代理IP的可用性try:proxies = {'http': 'http://{}'.format(proxy),'https': 'https://{}'.format(proxy)}response = requests.get('http://www.baidu.com', proxies=proxies, timeout=5)if response.status_code == 200:return Trueexcept:return Falsedef get_available_proxies(proxy_list):# 获取可用的代理IP列表available_proxies = []for proxy in proxy_list:if test_proxy(proxy):available_proxies.append(proxy)return available_proxiesdef get_random_proxy():# 获取随机的代理IPglobal PROXY_LISTif not PROXY_LIST:# 第一次使用时,先获取可用的代理IP列表proxy_list = get_proxy_list()PROXY_LIST = get_available_proxies(proxy_list)if not PROXY_LIST:# 如果没有可用的代理IP,等待一段时间后重试time.sleep(60)proxy_list = get_proxy_list()PROXY_LIST = get_available_proxies(proxy_list)return random.choice(PROXY_LIST)def make_request(url):# 发送HTTP请求while True:# 从代理IP列表中随机选择一个IPproxy =get_random_proxy()proxies = {'http': 'http://{}'.format(proxy),'https': 'https://{}'.format(proxy)}try:# 发送HTTP请求response = requests.get(url, proxies=proxies, timeout=5)if response.status_code == 200:return responseexcept:# 如果代理IP失效,从列表中移除该IPPROXY_LIST.remove(proxy)if __name__ == '__main__':url = 'http://www.example.com'response = make_request(url)print(response.text)在这个示例代码中,我们定义了一个全局变量PROXY_LIST,用于保存可用的代理IP列表。首先,我们定义了一个get_random_proxy函数,用于从代理IP列表中随机选择一个代理IP,并在需要时动态更新可用的代理IP列表。
接下来,我们定义了一个make_request函数,用于发送HTTP请求。该函数在调用get_random_proxy函数获取代理IP后,使用requests库发送HTTP请求,并在请求成功后返回响应结果。如果请求失败,则说明代理IP失效,需要从可用的代理IP列表中移除该代理IP,并重新选择一个代理IP进行请求。
最后,在程序的主函数中,我们定义了一个URL地址,并调用make_request函数发送HTTP请求。如果请求成功,则输出响应内容。
至此,我们已经完成了代理IP的动态切换功能的实现。接下来,我们对上述代码进行修改,加入一些必要的异常处理逻辑和日志记录功能。
四、异常处理和日志记录
在实际的爬虫应用中,我们经常会遇到各种意外情况,例如代理IP失效、网络连接超时、目标网站返回错误响应等。为了保证程序的稳定性和可靠性,我们需要对这些情况进行合理的异常处理和日志记录。
以下是一个加入异常处理和日志记录的示例代码:
import requests
from requests.exceptions import ProxyError, Timeout, ConnectionError
from bs4 import BeautifulSoup
import random
import time
import logging# 全局变量,代理IP列表
PROXY_LIST = []def init_logging():# 初始化日志记录器logger = logging.getLogger()logger.setLevel(logging.INFO)formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')handler = logging.FileHandler('proxy.log')handler.setFormatter(formatter)logger.addHandler(handler)return loggerdef get_proxy_list():# 获取代理IP列表的URLurl = "http://www.example.com/proxy_list.html"# 发送请求获取页面内容response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')# 解析HTML页面,获取代理IP列表proxy_list = []for tr in soup.find_all('tr'):tds = tr.find_all('td')if len(tds) == 2:ip = tds[0].get_text()port = tds[1].get_text()proxy = '{}:{}'.format(ip, port)proxy_list.append(proxy)return proxy_listdef test_proxy(proxy):# 测试代理IP的可用性try:proxies = {'http': 'http://{}'.format(proxy),'https': 'https://{}'.format(proxy)}response = requests.get('http://www.baidu.com', proxies=proxies, timeout=5)if response.status_code == 200:return Trueexcept:return Falsedef get_available_proxies(proxy_list):# 获取可用的代理IP列表available_proxies = []for proxy in proxy_list:if test_proxy(proxy):available_proxies.append(proxy)return available_proxiesdef get_random_proxy():# 获取随机的代理IPglobal PROXY_LISTif not PROXY_LIST:# 第一次使用时,先获取可用的代理IP列表proxy_list = get_proxy_list()PROXY_LIST = get_available_proxies(proxy_list)if not PROXY_LIST:# 如果没有可用的代理IP,等待一段时间后重试time.sleep(60)proxy_list = get_proxy_list()PROXY_LIST = get_available_proxies(proxy_list)return random.choice(PROXY_LIST)def make_request(url):# 发送HTTP请求while True:# 从代理IP列表中随机选择一个IPproxy = get_random_proxy()proxies = {'http': 'http://{}'.format(proxy),'https': 'https://{}'.format(proxy)}try:# 发送HTTP请求response = requests.get(url, proxies=proxies, timeout=5)if response.status_code == 200:return responseexcept ProxyError as e:# 代理服务器错误,从列表中移除该IPPROXY_LIST.remove(proxy)logging.warning('ProxyError: {}'.format(str(e)))except Timeout as e:# 超时错误,重试logging.warning('Timeout: {}'.format(str(e)))except ConnectionError as e:# 连接错误,重试logging.warning('ConnectionError: {}'.format(str(e)))except Exception as e:# 其他未知错误,重试logging.warning('Exception: {}'.format(str(e)))if __name__ == '__main__':init_logging()url = 'http://www.example.com'response = make_request(url)print(response.text)在这个示例代码中,我们首先引入了requests.exceptions模块和logging模块。requests.exceptions模块提供了一些常见的网络请求异常类型,我们可以通过捕获这些异常类型来实现异常处理。logging模块则提供了一个日志记录器,我们可以使用它来记录程序运行时的异常和错误信息。
接下来,在程序的主函数中,我们调用了一个init_logging函数,用于初始化日志记录器。该函数设置了日志记录器的级别、格式和输出文件,并返回一个记录器实例。
最后,在make_request函数中,我们通过try-except语句对网络请求中可能出现的异常进行了捕获和处理。例如,如果代理服务器返回了错误码,我们将该代理IP从列表中移除,并记录警告日志。如果发生超时错误、连接错误或其他未知错误,我们直接记录警告日志,并在下一次循环中重试。
至此,我们已经完成了对代理IP的动态切换功能的实现,并加入了必要的异常处理和日志记录功能。
总结
为了实现在代理IP被封后立即切换到下一个IP,我们可以在爬虫程序中加入一个代理IP池,定时从可用的代理IP列表中随机选择一个IP,并发送HTTP请求。如果请求失败,我们可以将失败的代理IP从列表中移除,并在下一次选择IP时避开此IP。同时,我们需要加入必要的异常处理和日志记录功能,以保证程序的稳定性和可靠性。这样,即使某个代理IP被封,我们也能够及时切换到下一个可用的IP,继续执行爬虫任务。
相关文章:
python爬虫,如何在代理的IP被封后立刻换下一个IP继续任务?
前言 在实际的爬虫应用中,爬虫程序经常会通过代理服务器来进行网络访问,以避免访问过于频繁而受到网站服务器的限制。但是,代理服务器的IP地址也可能被目标网站限制,导致无法正常访问。这时候,我们需要在代理IP被封后…...

小程序开发——小程序项目的配置与生命周期
1.app.json配置属性 app.json配置属性 2.页面配置 app的页面配置指的是pages属性, pages数组的第一个页面将默认作为小程序的启动页。利用开发工具新建页面时,则pages属性对应的数组将自动添加该页面的路径,若是在硬盘中添加文件的形式则不…...
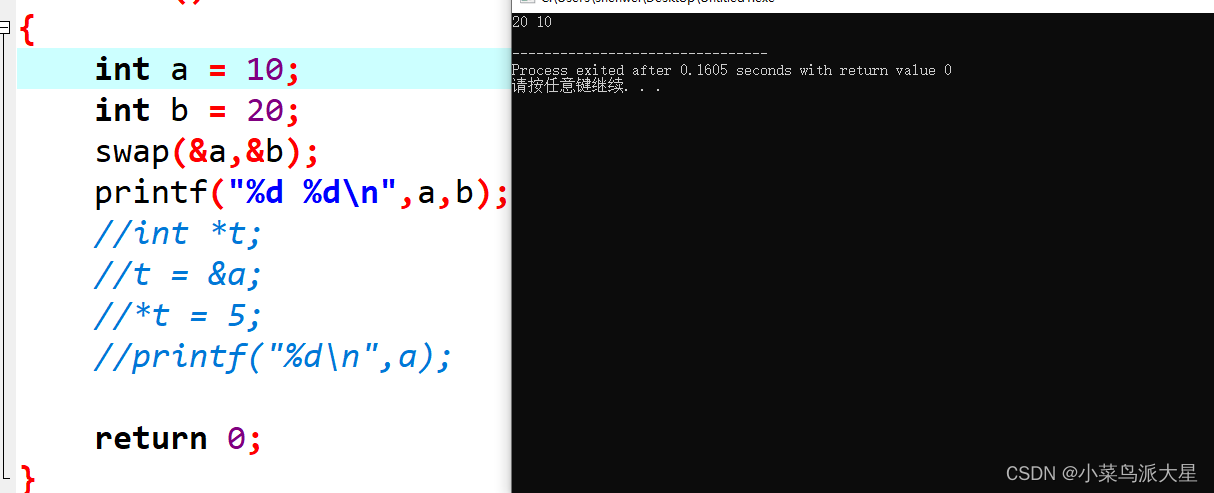
C语言之用指针交换两个数
1.指针存放是是地址,所以在用指针交换两个数的时候,需要对指针进行解引用(*p)。 用指针交换两个数,需要知道p1p2与*p1*p2。 p1p1是将p2的值赋值给p1. *p1*p2是将p2指针地址存放的值,赋值给p1指针地址存放的值,即p1地…...

Day 48 动态规划 part14
Day 48 动态规划 part14 解题理解1143103553 3道题目 1143. 最长公共子序列 1035. 不相交的线 53. 最大子数组和 解题理解 1143 设dp[i][j]为text10: i-1text20: j-1的最长公共子序列。 class Solution:def longestCommonSubsequence(self, text1: str, text2: str) -> …...
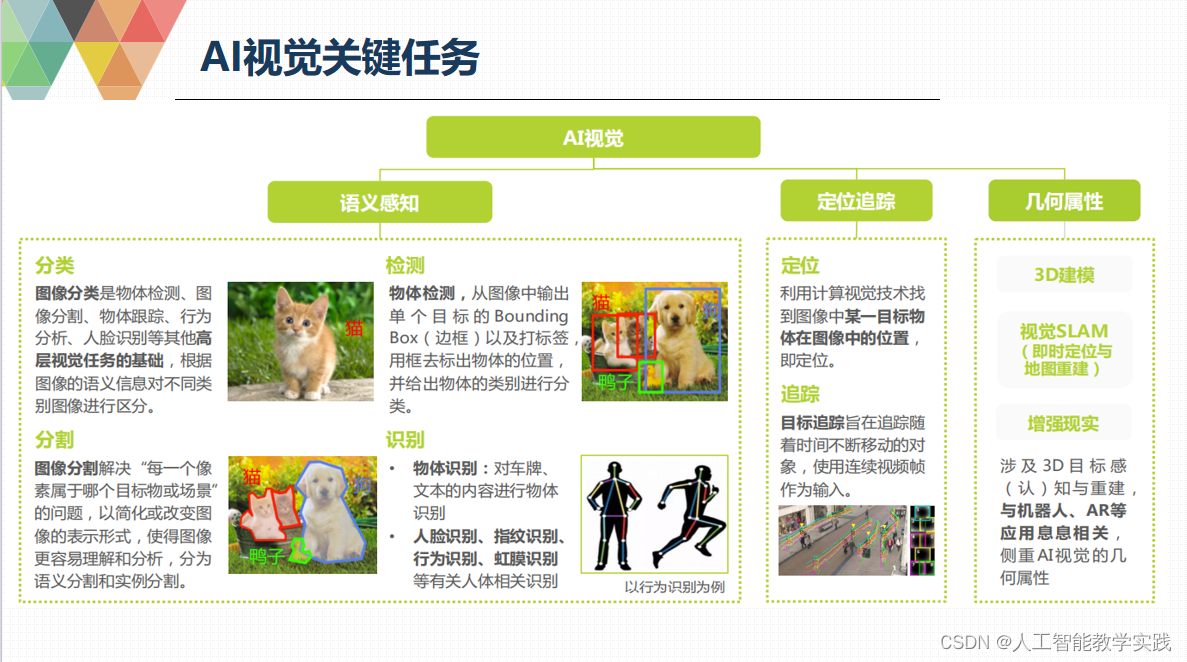
目标检测与图像识别分类的区别?
目标检测与图像识别分类的区别 目标检测和图像识别分类是计算机视觉领域中两个重要的任务,它们在处理图像数据时有一些区别。 目标检测是指在图像中定位和识别多个目标的过程。其主要目标是确定图像中每个目标的边界框位置以及对应的类别标签。目标检测任务通常涉…...
群晖设置DDNS (服务商Godaddy被墙 DDNS-GO无法解析 采用自定义脚本方式完成DDNS更新)
起因&解决思路 事情的开始大概是这样的。。godaddy买了个域名,好好的用了半个月。。然后一直更新失败发现被狗东西墙了 在提一嘴DDNS-GO 解析失败原因 DDNS-GO必须要先向godaddy请求自己的IP地址[这里被墙卡住了],然后比对,再决定是否上…...

博客摘录「 MySQL不区分大小写设置」2023年10月31日
操作系统的大小写是否敏感决定了数据库大小写是否敏感,而 Windows 系统是对大小写不敏感的,Linux 系统对大小写敏感。 mysql创建表时, 字符集需要设置"编码集(charset)"和"校验规则(collation)"。 编码集比较常用的有utf8和utf8mb4…...
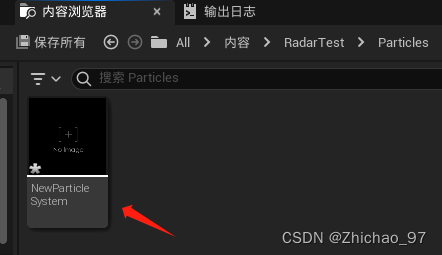
【UE5】如何在UE5.1中创建级联粒子系统
1. 可以先新建一个actor蓝图,然后在该蓝图中添加一个“Cascade Particle System Component” 2. 在右侧的细节面板中,点击“模板”一项中的下拉框,然后点击“Cascade粒子系统(旧版)” 然后就可以选择在哪个路径下创建级…...
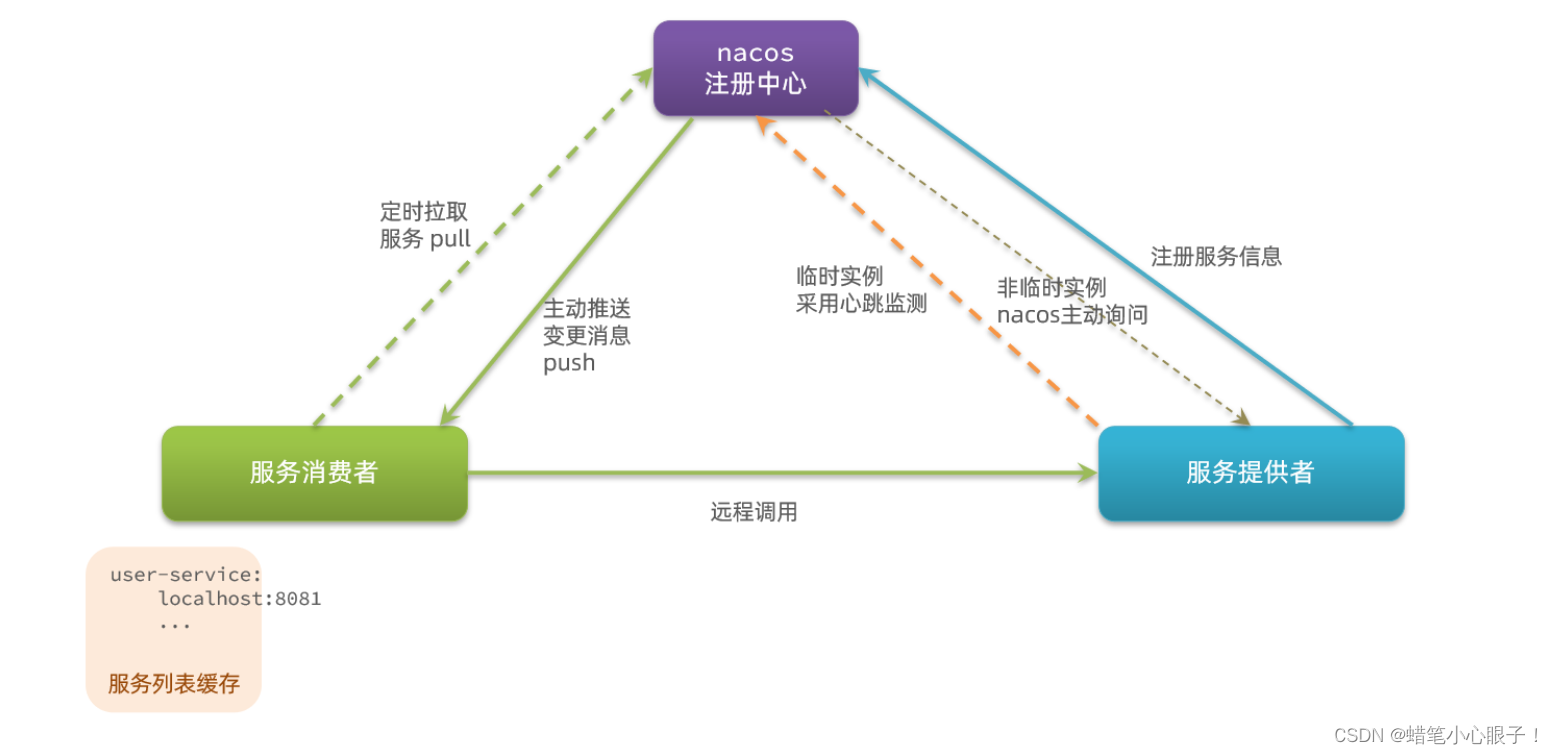
SpringCloud(五) Eureka与Nacos的区别
SpringCloud(二) Eureka注册中心的使用-CSDN博客 SpringCloud(四) Nacos注册中心-CSDN博客 在这两篇博文中我们详细讲解了Eureka和Nacos分别作为微服务的注册中心的使用方法和注意事项,但是两者之间也有一些区别. 一, Nacos实例分类 Nacos实例分为两种类型: 临时实例:如果实例…...

C语言 DAY07:预编译,宏,选择性编译,库(静态库,动态库)
声明与定义分离 声明:将声明单独封装成一个以.h为后缀名的头文件 定义:将定义的变量,函数,数组所在的源文件单独封装成一个.c文件。其实就是在源文件基础上将定义过的所有东西的声明分离出去就是了。 注意:1.声明的…...
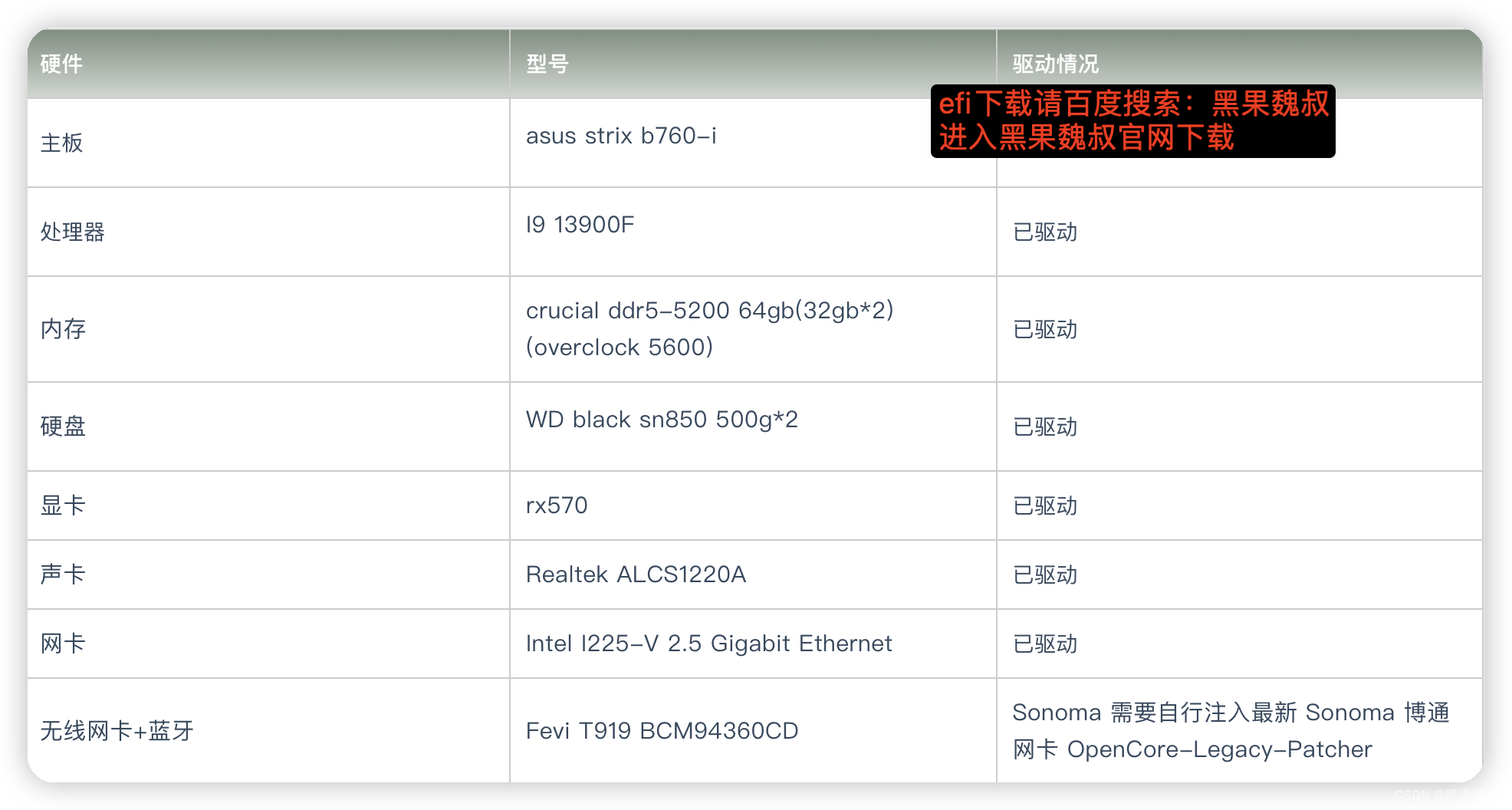
[EFI]asus strix b760-i 13900F电脑 Hackintosh 黑苹果efi引导文件
硬件型号驱动情况主板 asus strix b760-i 处理器 I9 13900F 已驱动内存crucial ddr5-5200 64gb(32gb*2)(overclock 5600)已驱动硬盘 WD black sn850 500g*2 已驱动显卡rx570已驱动声卡Realtek ALCS1220A已驱动网卡Intel I225-V 2.5 Gigabit Ethernet已驱动无线网卡蓝牙Fevi T91…...

力扣383.赎金信
原题链接:383.赎金信 根据题意得出,需要判断第一个字符串内的字符有没有都在第二个字符串内出现(会有重复字符),并且范围限制在26个英文小写字母 此时可以考虑用一个数组map 作哈希法映射操作 先将遍历第一个字符串,并让每个字符…...

CORS的原理以及在Node.js中的使用
在前端浏览器中的JavaScript代码发起HTTP请求到服务器的Node.js程序,CORS(跨域资源共享)会在以下几个步骤中发挥作用: 前端JavaScript代码发起请求: 前端浏览器中的JavaScript代码使用XMLHttpRequest对象或Fetch API等…...

kotlin实现单例模式
kotlin实现单例模式,大体分为两种方式,一种饿汉式单例模式,一种懒汉式单例模式。 1.饿汉式单例模式 在类前面加上object关键字,就实现了饿汉式单例模式: object singletonDemo { }在kotlin中,使用这种方式…...

【Java】LinkedList 集合
LinkedList集合特点 LinkedList 底层基于双向链表实现增删 效率非常高,查询效率非常低。 LinkedList源码解读分析 LinkedList 是双向链表实现的 ListLinkedList 是非线程安全的(线程是不安全的)LinkedList 元素允许为null,允许重复元素Linked…...
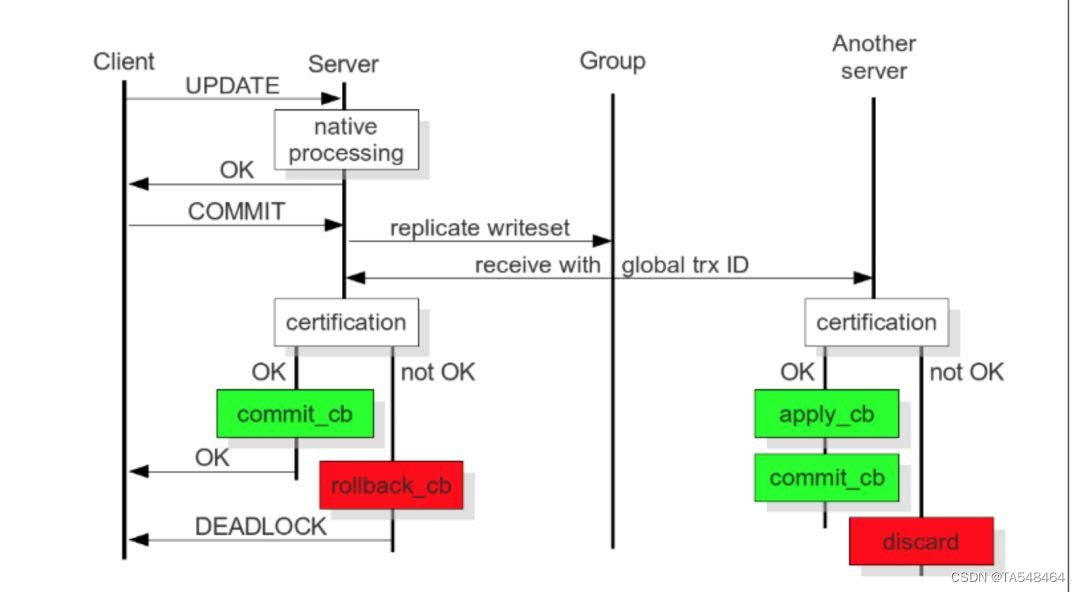
MySQL-Galera-Cluster集群详细介绍
目录 一、什么是Mysql集群?1.单节点mysql存在的常见问题2.mysql集群介绍3.Mysql集群的优点和风险 二、Mysql集群的一些疑问1.mysql的AB复制和Galera Cluster有什么区别?2.什么情况下适用AB复制,什么情况下使用Galera cluster?3.可…...

JavaScript从入门到精通系列第二十六篇:详解JavaScript中的Math对象
大神链接:作者有幸结识技术大神孙哥为好友,获益匪浅。现在把孙哥视频分享给大家。 孙哥连接:孙哥个人主页 作者简介:一个颜值99分,只比孙哥差一点的程序员 本专栏简介:话不多说,让我们一起干翻J…...
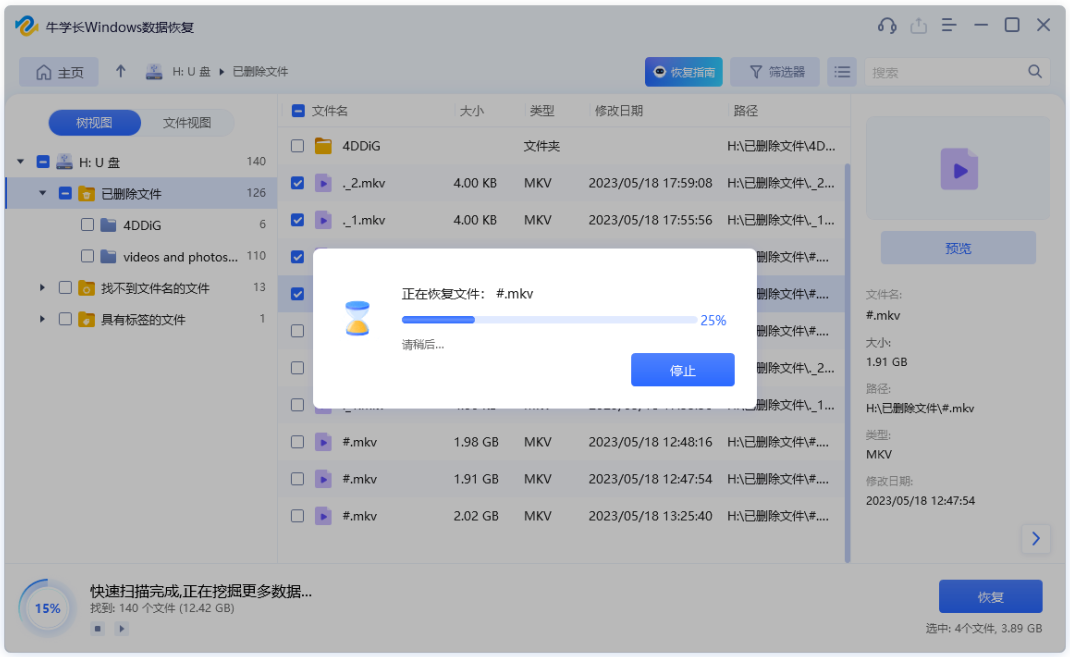
u盘直接拔出文件丢失怎么找回?u盘文件恢复办法分享!
u盘作为一种便捷的数据存储设备,被广泛地使用。通过u盘,我们可以在不同设备之间轻松传输文件,然而有时候,我们可能因为匆忙或疏忽并未安全弹出u盘,而是直接将u盘拔出,进而导致重要文件丢失,u盘直…...

rust学习-LinkedList
介绍 A doubly-linked list with owned nodes. 自有节点的双向链表 pub struct LinkedList<T, A = Global> whereA: Allocator, {/* private fields */ }使用 Vec 或 VecDeque 几乎总是更好,因为基于数组的容器通常更快、内存效率更高,并且可以更好地利用 CPU 缓存 …...
搭上直播快车,文旅迎来了更大爆发期?
“直播累计观看人数1083万人次,同期在线峰值10万人,抖音平台销售额800万元,荣登食遍天下榜第一名”。 10月28日,“东方甄选看世界”无锡专场直播落幕,又创造了新成绩,“文旅直播”这一新带货模式的发展可行…...

DownKyi完全指南:三步解锁B站8K视频下载的终极方案
DownKyi完全指南:三步解锁B站8K视频下载的终极方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

DeepSeek LeetCode 2421. 好路径的数目 Python3实现
给你 Python3 版本的代码,思路和之前的 Java 实现一致: 完整代码 python class Solution: def numberOfGoodPaths(self, vals: List[int], edges: List[List[int]]) -> int: n len(vals) # 1. 构建邻接表 gr…...

AI模型部署实战:基于FastAPI与Tauri构建OpenClaw模型GUI应用
1. 项目概述与核心价值最近在AI应用开发圈里,一个名为“GrahamMiranda-AI/openclaw-model-gui”的项目引起了我的注意。乍一看这个标题,它融合了“openclaw-model”和“gui”两个关键部分,这让我立刻联想到一个典型的场景:一个已经…...

立体孪生全域可视,实现仓储人货动线全周期透明管控
立体孪生全域可视,实现仓储人货动线全周期透明管控副标题:动态三维实时还原库区人员、物资、车辆立体态势,运用库区无感定位、跨货架跨镜长距跟踪、身体指纹在岗确权,出入库、巡检、值守、调度全程透明可追溯一、方案总览现代规模…...

MCP服务器自动发现与管理工具mcpfinder详解
1. 项目概述:一个用于发现与管理MCP服务器的工具如果你正在构建或使用基于模型上下文协议(Model Context Protocol, 简称MCP)的应用,那么你很可能遇到过这样的困扰:手头有几个不同功能的MCP服务器ÿ…...

番茄小说下载器终极指南:3分钟打造你的私人数字图书馆
番茄小说下载器终极指南:3分钟打造你的私人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更小说时,突然发现网络连接中断?…...

[具身智能-766]:机器人在运动过程中需要实时定位,AMCL 每一次都需要全局撒粒子重搜吗?还是一旦定位后,后续的移动过程中,只需要局部匹配?
直白结论完全不需要每次全局撒粒子重搜定位成功稳定后,机器人全程只做局部小范围匹配,只有丢位置、被挪动时,才会重新全局撒粒子搜索。一、分两种状态1. 正常行走(已定位成功)粒子只聚集在机器人真实位置周边很小一片区…...

开源流程编排引擎FlowCue:基于DAG与事件驱动的自动化工作流实践
1. 项目概述:FlowCue是什么,以及它为何值得关注如果你是一名开发者,尤其是经常和API、数据流、自动化任务打交道的后端或全栈工程师,那么你肯定对“流程编排”这个概念不陌生。简单来说,就是把一系列独立的操作&#x…...

【197期】视频一键转图文笔记
这期分享一个自己一直在用的视频转图文笔记工具,把视频文件和对应的字幕文件拖进去,一键就能生成详细的图文笔记。目前自媒体平台上的文章基本都靠这个流程来出,不用另外再写一遍,效率高了很多。使用方式很简单,把视频…...