redis实现分布式延时队列
文章目录
- 延时队列简介
- 应用场景
- 案例:
- 考虑:
- 实现:
- 整体思路:
- 具体实现
- 生产者
- 消费者
- 运行结果
- redis分布式延时队列优势
- redis分布式延时队列劣势
延时队列简介
延时队列是一种特殊的消息队列,它允许将消息在一定的延迟时间后再进行消费。延时队列的主要特点是可以延迟消息的处理时间,以满足定时任务或者定时事件的需求。
总之,延时队列通过延迟消息的消费时间,提供了一种方便、可靠的方式来处理定时任务和定时事件。它在分布式系统中具有重要的作用,能够提高系统的可靠性和性能。
延时队列的实现方式可以有多种,本文介绍一种redis实现的分布式延时队列。
应用场景
-
定时任务:可以将需要在特定时间执行的任务封装为延时消息,通过延时队列来触发任务的执行。
-
订单超时处理:可以将订单消息发送到延时队列中,并设置订单的超时时间,超过时间后,消费者从队列中获取到超时的订单消息,进行相应的处理。
-
消息重试机制:当某个消息处理失败时,可以将该消息发送到延时队列中,并设置一定的重试时间,超过时间后再次尝试处理。
案例:
12306火车票购买,抢了订单后,45分钟没有支付,自动取消订单
考虑:
数据持久化:redis是支持的,可以使用rdb,也可以使用aof
有序存储:因为只要最小的没过期,后面的肯定就没过期,这样的话检查最小的节点就行了,考虑使用redis中的zset结构
高可用:考虑哨兵或者cluster
高伸缩:因为12306用户量非常大,可能导致redis中存储的任务空间非常大,所以考虑扩展节点,从这个角度来说,使用cluster集群模式,哨兵只有一个节点即主节点写数据。
实现:
整体思路:
- 生产消费者模型:因为12306的用户量非常大,所以考虑生产者和消费者有多个节点;
- 采用cluster模式实现高可用以及高伸缩性;
- 采用zset存储延时任务(zadd key score member,score表示时间);
- 为了让数据均匀分布在cluster集群中的多个主节点中:构建多个zset,每个zset对应一个消费者,生产者随机向某个zset中生产数据。
具体实现
生产者
需要安装hiredis-cluster集群,安装编译如下:
git clone https://github.com/Nordix/hiredis-cluster.git
cd hiredis-cluster
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=RelWithDebInfo -
DENABLE_SSL=ON ..
make
sudo make install
sudo ldconfig
需要安装libevent库,最后编译时执行gcc producer.c -o producer -levent -lhiredis_cluster -lhiredis -lhiredis_ssl编译生产者可执行程序
#include <hiredis_cluster/adapters/libevent.h>
#include <hiredis_cluster/hircluster.h>
#include <event.h>
#include <event2/listener.h>
#include <event2/bufferevent.h>
#include <event2/buffer.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#include <sys/time.h>int64_t g_taskid = 0;#define MAX_KEY 10static int64_t hi_msec_now() {int64_t msec;struct timeval now;int status;status = gettimeofday(&now, NULL);if (status < 0) {return -1;}msec = (int64_t)now.tv_sec * 1000LL + (int64_t)(now.tv_usec / 1000LL);return msec;
}static int _vscnprintf(char *buf, size_t size, const char *fmt, va_list args) {int n;n = vsnprintf(buf, size, fmt, args);if (n <= 0) {return 0;}if (n <= (int)size) {return n;}return (int)(size-1);
}static int _scnprintf(char *buf, size_t size, const char *fmt, ...) {va_list args;int n;va_start(args, fmt);n = _vscnprintf(buf, size, fmt, args);va_end(args);return n;
}void connectCallback(const redisAsyncContext *ac, int status) {if (status != REDIS_OK) {printf("Error: %s\n", ac->errstr);return;}printf("Connected to %s:%d\n", ac->c.tcp.host, ac->c.tcp.port);
}void disconnectCallback(const redisAsyncContext *ac, int status) {if (status != REDIS_OK) {printf("Error: %s\n", ac->errstr);return;}printf("Disconnected from %s:%d\n", ac->c.tcp.host, ac->c.tcp.port);
}void addTaskCallback(redisClusterAsyncContext *cc, void *r, void *privdata) {redisReply *reply = (redisReply *)r;if (reply == NULL) {if (cc->errstr) {printf("errstr: %s\n", cc->errstr);}return;}int64_t now = hi_msec_now() / 10;printf("add task success reply: %lld now=%ld\n", reply->integer, now);
}int addTask(redisClusterAsyncContext *cc, char *desc) {/* 转化为厘米秒 */int64_t now = hi_msec_now() / 10;g_taskid++;/* key */char key[256] = {0};// 为了让数据均匀分布在cluster集群中的多个主节点中:
// 构建多个zset,每个zset对应一个消费者,生产者随机向某个zset中生产数据,// 生产者可以有很多个,只需要保证向task_group:0-task_group:9中均匀的生产数据即可int len = _scnprintf(key, 255, "task_group:%ld", g_taskid % MAX_KEY);key[len] = '\0';/* member */char mem[1024] = {0};len = _scnprintf(mem, 1023, "task:%ld:%s", g_taskid, desc);mem[len] = '\0';int status;// 为每一个任务延时5秒中去处理status = redisClusterAsyncCommand(cc, addTaskCallback, "","zadd %s %ld %s", key, now+500, mem);printf("redisClusterAsyncCommand:zadd %s %ld %s\n", key, now+500, mem);if (status != REDIS_OK) {printf("error: err=%d errstr=%s\n", cc->err, cc->errstr);}return 0;
}void stdio_callback(struct bufferevent *bev, void *arg) {redisClusterAsyncContext *cc = (redisClusterAsyncContext *)arg;struct evbuffer *evbuf = bufferevent_get_input(bev);char *msg = evbuffer_readln(evbuf, NULL, EVBUFFER_EOL_LF);if (!msg) return;if (strcmp(msg, "quit") == 0) {printf("safe exit!!!\n");exit(0);return;}if (strlen(msg) > 1024-5-13-1) {printf("[err]msg is too long, try again...\n");return;}addTask(cc, msg);printf("stdio read the data: %s\n", msg);
}int main(int argc, char **argv) {printf("Connecting...\n");// 连接cluster集群,可以从cluster集群中任意一个节点出发连接集群redisClusterAsyncContext *cc =redisClusterAsyncConnect("127.0.0.1:7006", HIRCLUSTER_FLAG_NULL);printf("redisClusterAsyncContext...\n");if (cc && cc->err) {printf("Error: %s\n", cc->errstr);return 1;}struct event_base *base = event_base_new();redisClusterLibeventAttach(cc, base);redisClusterAsyncSetConnectCallback(cc, connectCallback);redisClusterAsyncSetDisconnectCallback(cc, disconnectCallback);// nodeIterator ni;// initNodeIterator(&ni, cc->cc);// cluster_node *node;// while ((node = nodeNext(&ni)) != NULL) {// printf("node %s:%d role:%d pad:%d\n", node->host, node->port, node->role, node->pad);// }struct bufferevent *ioev = bufferevent_socket_new(base, 0, BEV_OPT_CLOSE_ON_FREE);bufferevent_setcb(ioev, stdio_callback, NULL, NULL, cc);bufferevent_enable(ioev, EV_READ | EV_PERSIST);printf("Dispatch..\n");event_base_dispatch(base);printf("Done..\n");redisClusterAsyncFree(cc);event_base_free(base);return 0;
}// 需要安装 hiredis-cluster libevent
// gcc producer.c -o producer -levent -lhiredis_cluster -lhiredis -lhiredis_ssl
说明:
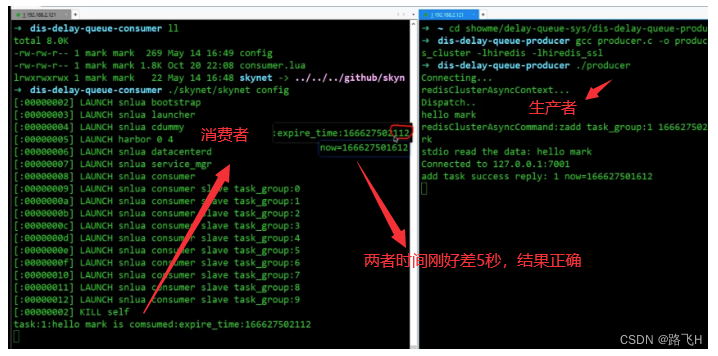
这里构建了10个zset,分别是task_group:0,task_group:1,…,task_group:9作为10个zset的key,zset的数据其实就代表着消费者的数量,通常消费者的功能是一摸一样的,生产者就不管你有多少个了,只需要将任务均匀的打散在不同的zset中就行了(具体实现可以搞一个全局的id,每一次添加任务时id++,然后再对zset个数10取模,最终可以得到0-9之间的一个数,然后再与task_group拼接,这样就可以将任务均匀的打散在不同的zset中)。
消费者
消费者是采用skynet+lua脚本实现的,每个消费者会不断的去检查redis中的任务有没有过期,如果过期,就取出来删除(这里只是demo,只是打印之后删除任务)
local skynet = require "skynet"local function table_dump( object )if type(object) == 'table' thenlocal s = '{ 'for k,v in pairs(object) doif type(k) ~= 'number' then k = string.format("%q", k) ends = s .. '['..k..'] = ' .. table_dump(v) .. ','endreturn s .. '} 'elseif type(object) == 'function' thenreturn tostring(object)elseif type(object) == 'string' thenreturn string.format("%q", object)elsereturn tostring(object)end
endlocal mode, key = ...
if mode == "slave" thenlocal rediscluster = require "skynet.db.redis.cluster"local function onmessage(data,channel,pchannel)print("onmessage",data,channel,pchannel)endskynet.start(function ()local db = rediscluster.new({{host="127.0.0.1",port=7001},},{read_slave=true,auth=nil,db=0,},onmessage)assert(db, "redis-cluster startup error")skynet.fork(function ()while true dolocal res = db:zrange(key, 0, 0, "withscores")if not next(res) thenskynet.sleep(50)elselocal expire = tonumber(res[2])local now = skynet.time()*100if now >= expire thenprint(("%s is comsumed:expire_time:%d"):format(res[1], expire))db:zrem(key, res[1])elseskynet.sleep(10)endendendend)end)elseskynet.start(function () -- // 启动10个程序,并把"slave"传入mode,task_group:i传入到key中,即每个程序只消费一个for i=0,9 doskynet.newservice(SERVICE_NAME, "slave", "task_group:"..i)
运行结果
redis分布式延时队列优势
1.Redis zset支持高性能的 score 排序。
2.Redis是在内存上进行操作的,速度非常快。
3.Redis可以搭建集群,当消息很多时候,我们可以用集群来提高消息处理的速度,提高可用性。
4.Redis具有持久化机制,当出现故障的时候,可以通过AOF和RDB方式来对数据进行恢复,保证了数据的可靠性
redis分布式延时队列劣势
使用 Redis 实现的延时消息队列也存在数据持久化, 消息可靠性的问题:
- 没有重试机制 - 处理消息出现异常没有重试机制, 这些需要自己去实现, 包括重试次数的实现等;
- 没有 ACK 机制 - 例如在获取消息并已经删除了消息情况下, 正在处理消息的时候客户端崩溃了, 这条正在处理的这些消息就会丢失, MQ 是需要明确的返回一个值给 MQ 才会认为这个消息是被正确的消费了。
总结:如果对消息可靠性要求较高, 推荐使用 MQ 来实现
相关文章:
redis实现分布式延时队列
文章目录 延时队列简介应用场景案例:考虑:实现:整体思路:具体实现生产者消费者 运行结果 redis分布式延时队列优势redis分布式延时队列劣势 延时队列简介 延时队列是一种特殊的消息队列,它允许将消息在一定的延迟时间…...
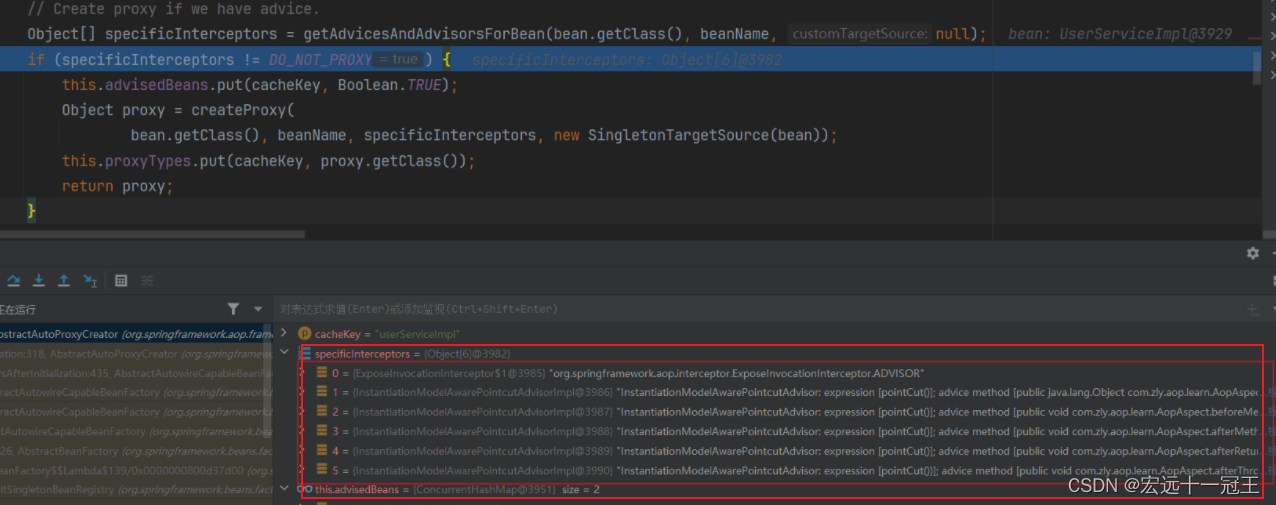
Spring AOP源码解读
今天我们来分析Spring中AOP的源码,主要是关于SpringAOP是如何发挥作用的。 前期准备 首先我们需要有一个Spring AOP项目,添加好了SpringAOP的依赖。 <dependency><groupId>org.springframework</groupId><artifactId>spring-co…...

JavaScript基础入门01
目录 1.初识 JavaScript 1.1JavaScript 是什么 1.2发展历史 1.3JavaScript 和 HTML 和 CSS 之间的关系 2.JavaScript 的组成 3.前置知识 3.1第一个程序 4.JavaScript 的书写形式 4.1 行内式 4.2. 内嵌式 4.3.外部式 5.注释 6.输入输出 6.1输入: prompt 6.2输出: …...
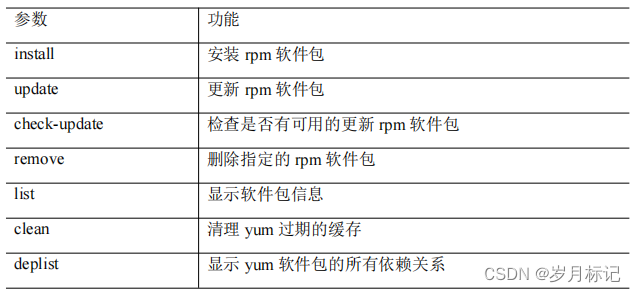
yum 命令
基本语法 yum [选项] [参数] 选项说明 -y 对所有提问都回答“yes” 参数说明 实操 yum list | grep firefox yum -y remove firefox yum -y install firefox...
Nginx 部署多个安全域名,多个服务【工作记录】
以下是本人通过Docker 部署的Nginx挂载出来的文件目录 先看下 nginx.conf 配置文件内容:如下 ps:当前文件就是安装后的初始内容,无修改。主要关注最后一行 include /etc/nginx/conf.d/*.conf;表示引入其他目录下的.conf配置文件;…...

性能测试QPS+TPS+事务基础知识分析
本篇文章是性能测试基础篇,主要介绍了性能测试中对QPSTPS事务的基础知识分析,有需要的朋友可以借鉴参考下,希望可以对广大读者有所帮助 事务 就是用户某一步或几步操作的集合。不过,我们要保证它有一个完整意义。比如用户对某一…...
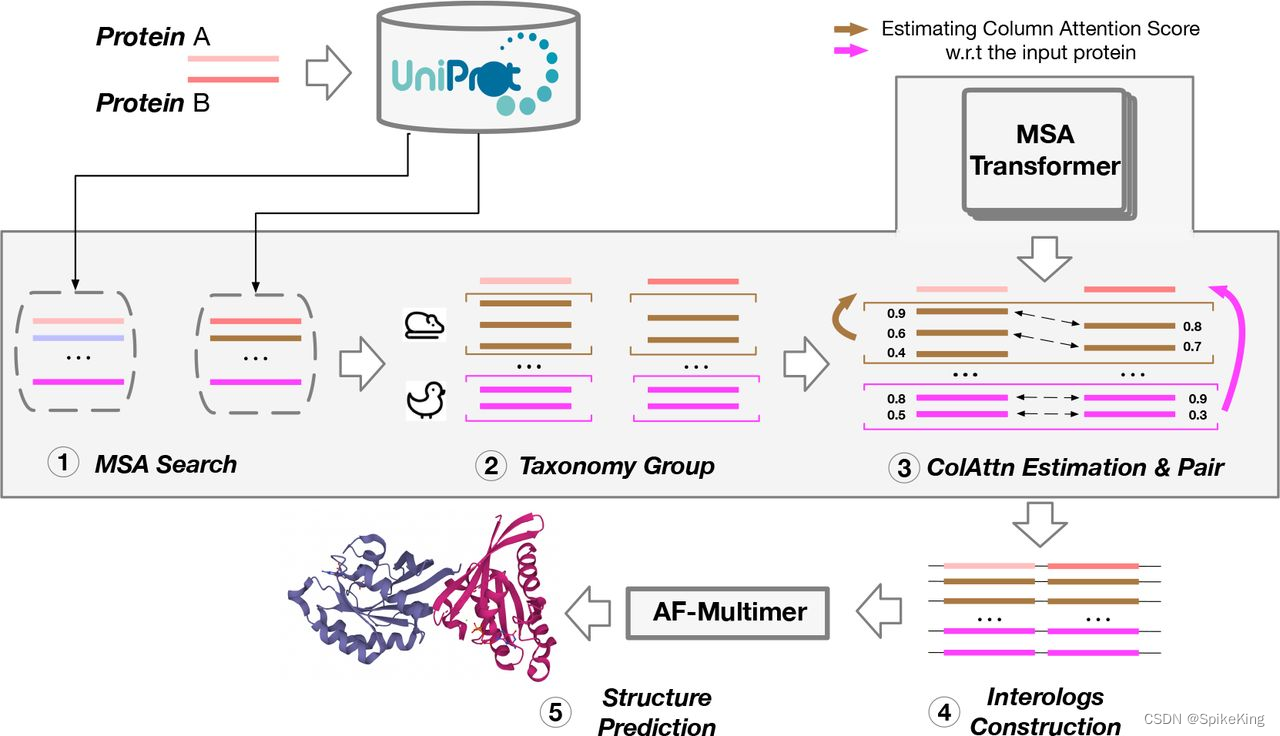
PSP - 蛋白质复合物 AlphaFold2 Multimer MSA Pairing 逻辑与优化
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/134144591 在蛋白质复合物结构预测中,当序列 (Sequence) 是异源多链时,无论是AB,还是AABB,都需要 …...

C++中vec.size()-1的坑
问题描述:如下代码, #include <iostream> #include <vector>using namespace std;int main() {vector<int> vec {};for (int i 0; i < vec.size() - 1; i) {cout << "i " << i << ", vec[i] …...

Flask Shell 操作 SQLite
一、前言 这段时间在玩Flask Web,发现用Flask Shell去操作SQLite还是比较方便的。今天简单地介绍一下。 二、SQLite SQLite是一种嵌入式数据库,它的数据库就是一个文件,处理速度快,经常被集成在各种应用程序中,在IO…...
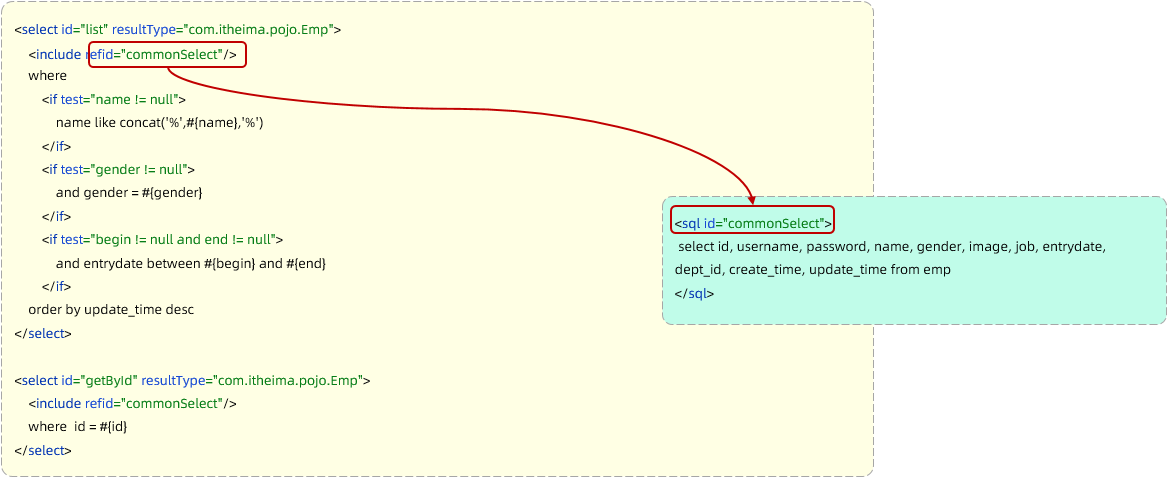
Mybatis—XML配置文件、动态SQL
学习完Mybatis的基本操作之后,继续学习Mybatis—XML配置文件、动态SQL。 目录 Mybatis的XML配置文件XML配置文件规范XML配置文件实现MybatisX的使用 Mybatis动态SQL动态SQL-if条件查询 \<if\>与\<where\>更新员工 \<set\>小结 动态SQL-\<forea…...
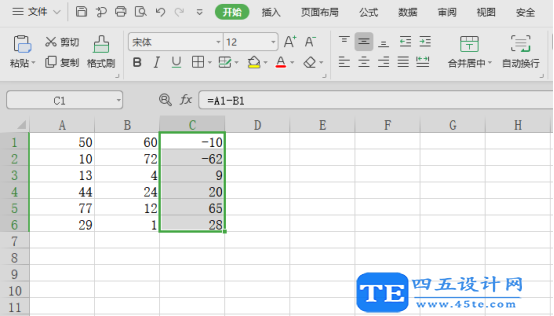
excel求差公式怎么使用?
利用excel求差,可能有许多的小伙伴已经会了,不过还是存在一些不太熟悉的朋友们,所以这里有必要讲解一下。其实求差的实现主要就是一个公式,就是用一个单元格中的数字“减去”另一个单元格中的数字“等于”第三个单元格。此公式掌握…...

高效分割分段视频:提升您的视频剪辑能力
在数字媒体时代,视频剪辑已经成为一项重要的技能。无论是制作个人影片、广告还是其他类型的视频内容,掌握高效的视频剪辑技巧都是必不可少的。本文将介绍如何引用云炫AI智剪高效地分割和分段视频,以提升您的视频剪辑能力。以下是详细的操作步…...
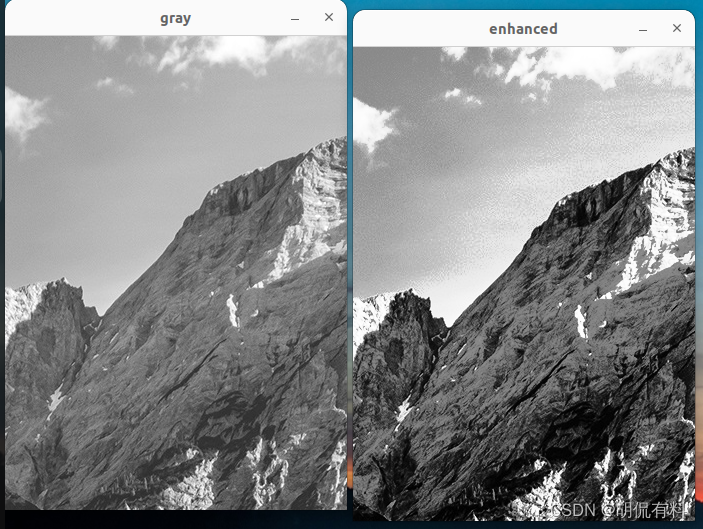
【c++|opencv】二、灰度变换和空间滤波---2.直方图和均衡化
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 图像直方图、直方图均衡化 1. 图像直方图 #include <iostream> #include <opencv2/opencv.hpp>using namespace cv; using namespace std;…...
)
【Windows】线程同步之信号量(Semaphores)
概述: semaphores 的说明和使用 微软官方文档: Semaphore Objects - Win32 apps | Microsoft Learn Semaphores是解决各种 producer/consumer问题的关键要素。这种问题会存有一个缓冲区,可能在同一时间内被读出数据或被写入数据。 理论可以证…...
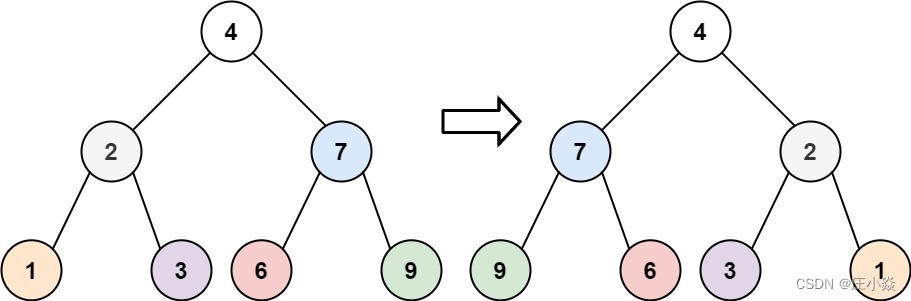
二叉树问题——前中后遍历数组构建二叉树
摘要 利用二叉树的前序,中序,后序,有序数组来构建相关二叉树的问题。 一、构建二叉树题目 105. 从前序与中序遍历序列构造二叉树 106. 从中序与后序遍历序列构造二叉树 889. 根据前序和后序遍历构造二叉树 617. 合并二叉树 226. 翻转二…...
)
Java保留n位小数的方法(超简洁)
要输出double类型保留n位小数的几种方法如下: 我们以保留6位小数为例 方法一:使用DecimalFormat类 import java.text.DecimalFormat;public class Main {public static void main(String[] args) {double number 3.141592653589793;DecimalFormat df …...

JavaEE-博客系统1(数据库和后端的交互)
本部分内容包括网站设计总述,数据库和后端的交互; 数据库操作代码如下: -- 编写SQL完成建库建表操作 create database if not exists java_blog_system charset utf8; use java_blog_system; -- 建立两张表,一个存储博客信息&am…...
【unity/vufornia】Duplicate virtual buttons with name.../同一个ImageTarget上多个按钮失灵
问题:在同一个ImageTarget上添加多个按钮时无法触发对应按钮的事件。 解决过程: 1.查看报错:“Duplicate virtual buttons with name...”这一行,顾名思义,命名重复。 2.英文搜索到以下文章,应该在inspe…...

Apache ActiveMQ 远程代码执行漏洞复现(CNVD-2023-69477)
Apache ActiveMQ 远程代码执行RCE漏洞复现(CNVD-2023-69477) 上周爆出来的漏洞,正好做一下漏洞复现,记录一下 1.漏洞描述 Apache ActiveMQ 中存在远程代码执行漏洞,具有 Apache ActiveMQ 服务器TCP端口ÿ…...

项目管理-科学管理基础-线性规划介绍及例题
项目管理中的线性规划是什么? 在项目管理中,线性规划是一种数学建模和优化技术,用于解决资源分配和进度规划的问题。线性规划的目标是在给定的资源限制下,找到最佳的资源分配方案,以满足项目的需求并优化特定的目标,如成本最小化或时间最短化。 线性规划的基本元素包括…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

OpenClaw用户如何快速接入Taotoken并开始Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始Agent工作流 对于使用OpenClaw框架构建AI智能体的开发者而言,快速接入稳定、多…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...