PSP - 蛋白质复合物 AlphaFold2 Multimer MSA Pairing 逻辑与优化
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/134144591
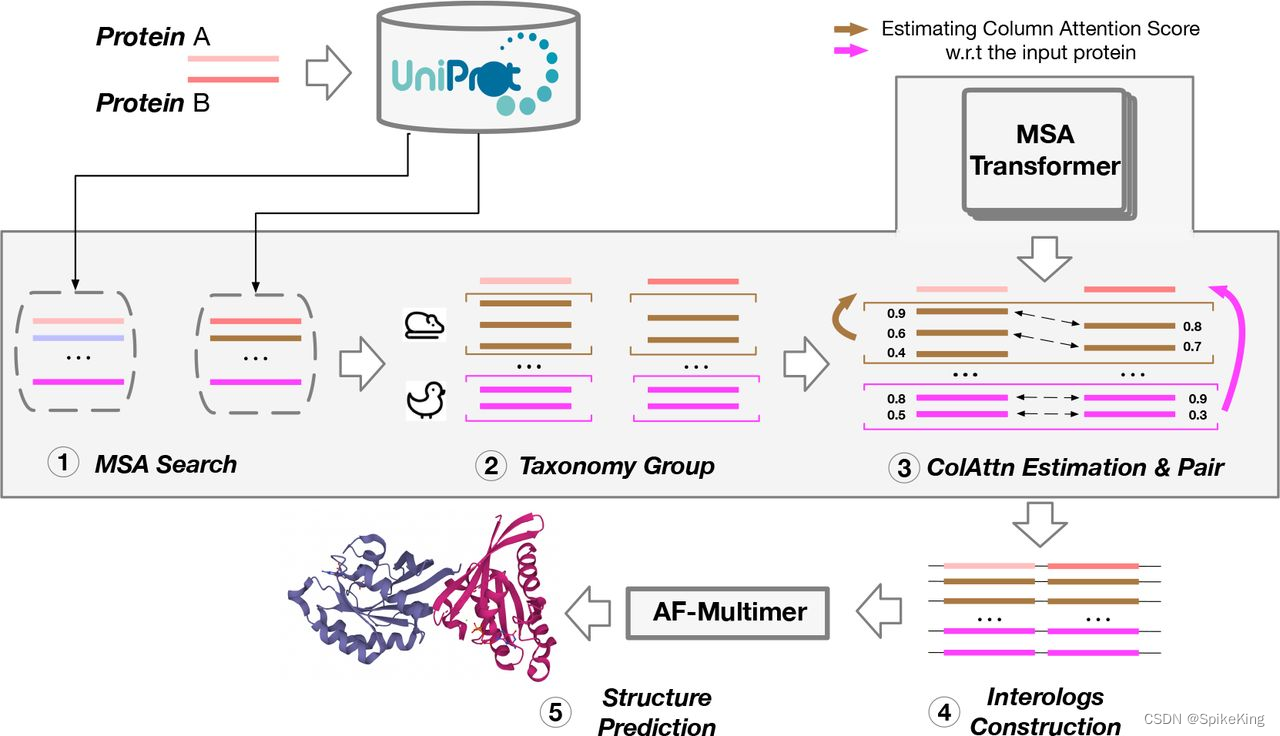
在蛋白质复合物结构预测中,当序列 (Sequence) 是异源多链时,无论是AB,还是AABB,都需要 MSA 配对,即 MSA Pairing。在 MSA 的搜索过程中,按照单链维度进行搜索,通过 MSA Pairing 进行合并,作为特征输入至 Multimer 结构预测。
控制 MSA 数量,包括需要 3 个超参数:
max_msa_crop_size,用于确定 MSA 的长度,默认设置 2048max_msa_clusters,用于确定推理中 MSA 特征的长度,默认设置 252max_extra_msa,用于限制推理中 Extra MSA 特征的长度,默认设置 1024
这 3 个参数,依次设定,从前到后相互包含,可以根据不同情况进行调节,其中 第1个参数 > (第2个参数 + 第3个参数)。
默认单链的搜索文件如下:
bfd_uniref_hits.a3m
mgnify_hits.sto
pdb_hits.sto
uniprot_hits.sto
uniref90_hits.sto
其中 uniref90_hits.sto 用于 MSA Pairing,pdb_hits.sto 用于 模版 (Template) 特征,bfd_uniref_hits.a3m、mgnify_hits.sto、uniref90_hits.sto,用于单链 MSA 特征。我们以 ABAB 格式的 4 链 PDB 进行假设。
优化1:MSA Pairing 默认只使用 uniprot_hits.sto,当数量较少时,可以使用 uniref90_hits.sto 作为补充。
源码 openfold/data/data_pipeline.py,如下:
# ++++++++++ 补充 MSA Pairing 源的逻辑 ++++++++++ #
# 标准的 AF2 Multimer 流程中没用 target_seq,即 target_seq 是 None
# logger.info(f"[CL] target_seq: {target_seq}")
msa = parsers.parse_stockholm(result, query_seq=target_seq)
msa = msa.truncate(max_seqs=self._max_uniprot_hits)msa_extra = parsers.parse_stockholm(result_extra, query_seq=target_seq)
msa_extra = msa_extra.truncate(max_seqs=self._max_uniprot_hits)logger.info(f"[CL] all_seq msa: {len(msa.sequences)}, add uniref msa: {len(msa_extra.sequences)}")
all_seq_features = make_msa_features([msa, msa_extra])
logger.info(f"[CL] all_seq msa: {all_seq_features['msa'].shape}")
# ++++++++++ 补充 MSA Pairing 源的逻辑 ++++++++++ #
优化2:当单链 MSA 数量较少时,使用 uniprot_hits.sto 作为 MSA 的补充。
源码 openfold/data/data_pipeline.py,如下:
# ++++++++++ 补充单链 MSA 序列的逻辑 ++++++++++ #
msa_seq_list = set()
for _, msa in msa_dict.items():for sequence_index, sequence in enumerate(msa.sequences):msa_seq_list.add(sequence)
msa_seq_list = list(msa_seq_list)
thr = 64 # 这影响没有 pairing 的序列,数值不宜过大
msa_size = len(msa_seq_list)
if msa_size < thr and uniprot_path:logger.info(f"[CL] single msa too small {msa_size} < {thr} (thr), uniprot_path: {uniprot_path}")with open(uniprot_path) as f:sto_string = f.read()msa_obj = parsers.parse_stockholm(sto_string)msa_seq_list += msa_obj.sequencesmsa_seq_list = list(set(msa_seq_list))diff_size = len(msa_seq_list) - msa_sizelogger.info(f"[CL] single msa from {msa_size} to {len(msa_seq_list)}, add {diff_size}")if diff_size > 0:msa_list.append(msa_obj) # 加入额外的数据
# ++++++++++ 补充单链 MSA 序列的逻辑 ++++++++++ #
优化3:当 MSA Pairing 数量过少时,尤其是 全链 Pairing 数量过少时,使用 其他物种 的 MSA 作为 MSA Pairing 的补充。
源码 openfold/data/msa_pairing.py,如下:
# ++++++++++ 补充 MSA Pairing 的逻辑 ++++++++++ #
thr = 128
num_all_pairing = len(tmp_dict1[num_examples])
if num_all_pairing < thr:logger.info(f"[CL] full msa pairing ({num_examples} chains) is too little ({num_all_pairing}<{thr}), "f"so add more!")tmp_dict2 = process_species(num_examples, common_species, all_chain_species_dict, prokaryotic, is_fake=True)# all_paired_msa_rows_dict = tmp_dict2tmp_item = list(tmp_dict1[num_examples]) + list(tmp_dict2[num_examples]) # 增补部分 MSAtmp_item = np.unique(tmp_item, axis=0) # 先去重tmp_item = tmp_item[:thr] # 再截取if len(tmp_item) > num_all_pairing:all_paired_msa_rows_dict[num_examples] = tmp_itemlogger.info(f"[CL] full msa pairing ({num_examples} chains) add to {len(tmp_item)}! ")
# ++++++++++ 补充 MSA Pairing 的逻辑 ++++++++++ #
假设序列是 AABB,顺序不重要,也可以是 ABAB,链式是 N c N_{c} Nc,MSA Pairing 只考虑 msa_all_seq 字段 (uniprot_hits 和 uniref90_hits 优化),即,A 链包括 MSA 数量是 L A L_{A} LA,B 链包括 MSA 数量是 L B L_{B} LB,MSA Pairing 数量是 L P a b L_{P_{ab}} LPab 。其中 MSA Pairing 包括 2 至 N c N_{c} Nc 个,例如 4 链,就是可以 Pairing 成2链、3链、4链等 4 种情况,只有 1 链时,被抛弃。
源码 openfold/data/msa_pairing.py,即:
# Skip species that are present in only one chain.
if species_dfs_present <= 1:continue
在 MSA Pairing 的过程中,修改 msa_all_seq 字段的 MSA 顺序,同时去除 只有 1 链 (没有配对) 的情况,假设最终 MSA Pairing 的数量是 L P a b L_{P_{ab}} LPab,全部链都是相同的,填补空位。
通过 msa_pairing.merge_chain_features() 函数,将单链 MSA 的合并至一起,即 bfd_uniref_hits.a3m、mgnify_hits.sto、uniref90_hits.sto 的全部 MSA,组成 msa 字段特征。其中 MSA 参数1 即 max_msa_crop_size,表示合并 MSA 的最大数量。例如 链 A 的 msa_all_seq 数量是 900,最大是 2048,则 单链 msa 字段的数量最多是 1148,其余随机舍弃,即1148+900=2048。
源码 openfold/data/msa_pairing.py,注意 feat_all_seq 在前,feat 在后,即 MSA Pairing 更重要,即:
def _concatenate_paired_and_unpaired_features(example: pipeline.FeatureDict,
) -> pipeline.FeatureDict:"""Merges paired and block-diagonalised features."""features = MSA_FEATURESfor feature_name in features:if feature_name in example:feat = example[feature_name]feat_all_seq = example[feature_name + "_all_seq"]merged_feat = np.concatenate([feat_all_seq, feat], axis=0)example[feature_name] = merged_featexample["num_alignments"] = np.array(example["msa"].shape[0], dtype=np.int32)return example
通过 openfold/data/data_transforms_multimer.py 函数,将输入的 msa 特征 (合并 msa 和 msa_all_seq) 进行截取,先截取 max_seq,再截取 max_extra_msa_seq,即第 2 个和第 3 个参数,max_msa_clusters 和 max_extra_msa,作为最终的训练或推理 msa 特征。
logits += cluster_bias_mask * inf
index_order = gumbel_argsort_sample_idx(logits, generator=g)
logger.info(f"[CL] truly use msa raw size: {len(index_order)}, msa: {max_seq}, extra_msa: {max_extra_msa_seq}")
sel_idx = index_order[:max_seq]
extra_idx = index_order[max_seq:][:max_extra_msa_seq]for k in ["msa", "deletion_matrix", "msa_mask", "bert_mask"]:if k in batch:batch["extra_" + k] = batch[k][extra_idx]batch[k] = batch[k][sel_idx]
通过不同的训练模型,与不同的参数,进行蛋白质复合物的结构预测。
相关文章:
PSP - 蛋白质复合物 AlphaFold2 Multimer MSA Pairing 逻辑与优化
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/134144591 在蛋白质复合物结构预测中,当序列 (Sequence) 是异源多链时,无论是AB,还是AABB,都需要 …...

C++中vec.size()-1的坑
问题描述:如下代码, #include <iostream> #include <vector>using namespace std;int main() {vector<int> vec {};for (int i 0; i < vec.size() - 1; i) {cout << "i " << i << ", vec[i] …...

Flask Shell 操作 SQLite
一、前言 这段时间在玩Flask Web,发现用Flask Shell去操作SQLite还是比较方便的。今天简单地介绍一下。 二、SQLite SQLite是一种嵌入式数据库,它的数据库就是一个文件,处理速度快,经常被集成在各种应用程序中,在IO…...
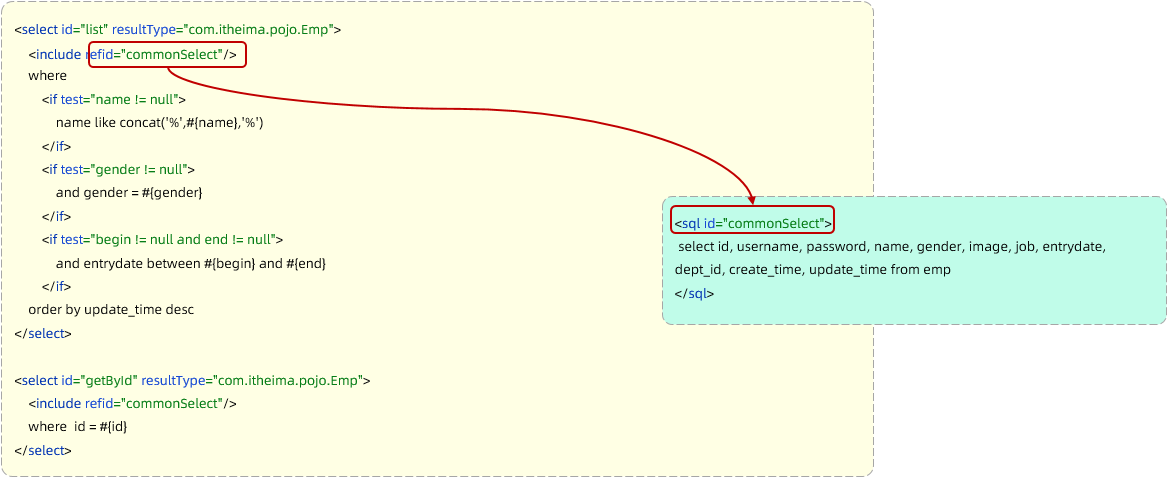
Mybatis—XML配置文件、动态SQL
学习完Mybatis的基本操作之后,继续学习Mybatis—XML配置文件、动态SQL。 目录 Mybatis的XML配置文件XML配置文件规范XML配置文件实现MybatisX的使用 Mybatis动态SQL动态SQL-if条件查询 \<if\>与\<where\>更新员工 \<set\>小结 动态SQL-\<forea…...
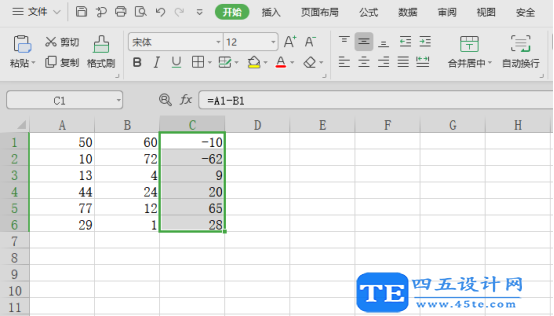
excel求差公式怎么使用?
利用excel求差,可能有许多的小伙伴已经会了,不过还是存在一些不太熟悉的朋友们,所以这里有必要讲解一下。其实求差的实现主要就是一个公式,就是用一个单元格中的数字“减去”另一个单元格中的数字“等于”第三个单元格。此公式掌握…...

高效分割分段视频:提升您的视频剪辑能力
在数字媒体时代,视频剪辑已经成为一项重要的技能。无论是制作个人影片、广告还是其他类型的视频内容,掌握高效的视频剪辑技巧都是必不可少的。本文将介绍如何引用云炫AI智剪高效地分割和分段视频,以提升您的视频剪辑能力。以下是详细的操作步…...
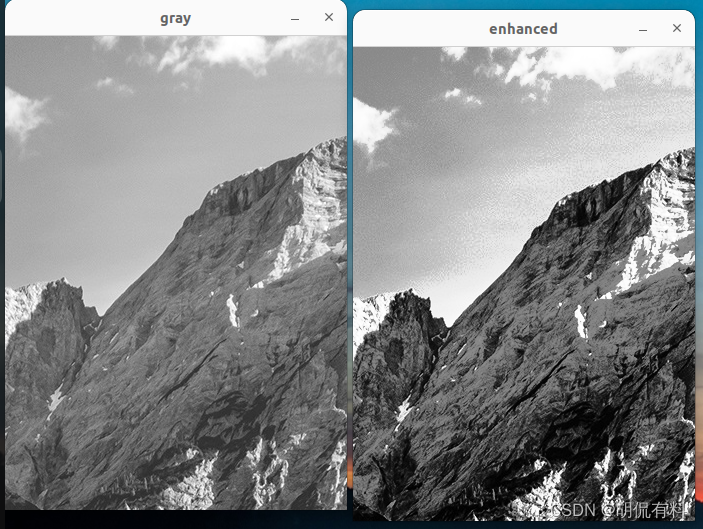
【c++|opencv】二、灰度变换和空间滤波---2.直方图和均衡化
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 图像直方图、直方图均衡化 1. 图像直方图 #include <iostream> #include <opencv2/opencv.hpp>using namespace cv; using namespace std;…...
)
【Windows】线程同步之信号量(Semaphores)
概述: semaphores 的说明和使用 微软官方文档: Semaphore Objects - Win32 apps | Microsoft Learn Semaphores是解决各种 producer/consumer问题的关键要素。这种问题会存有一个缓冲区,可能在同一时间内被读出数据或被写入数据。 理论可以证…...
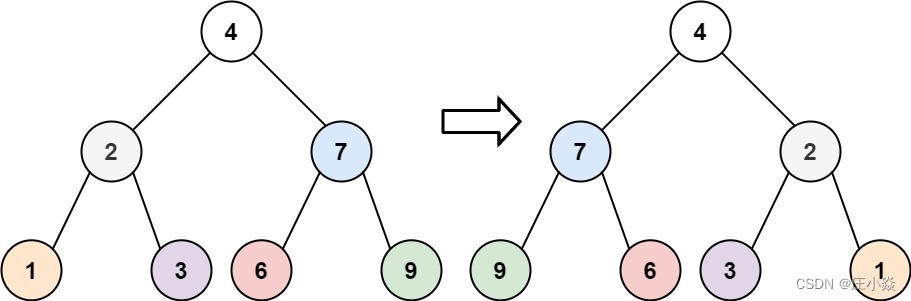
二叉树问题——前中后遍历数组构建二叉树
摘要 利用二叉树的前序,中序,后序,有序数组来构建相关二叉树的问题。 一、构建二叉树题目 105. 从前序与中序遍历序列构造二叉树 106. 从中序与后序遍历序列构造二叉树 889. 根据前序和后序遍历构造二叉树 617. 合并二叉树 226. 翻转二…...
)
Java保留n位小数的方法(超简洁)
要输出double类型保留n位小数的几种方法如下: 我们以保留6位小数为例 方法一:使用DecimalFormat类 import java.text.DecimalFormat;public class Main {public static void main(String[] args) {double number 3.141592653589793;DecimalFormat df …...

JavaEE-博客系统1(数据库和后端的交互)
本部分内容包括网站设计总述,数据库和后端的交互; 数据库操作代码如下: -- 编写SQL完成建库建表操作 create database if not exists java_blog_system charset utf8; use java_blog_system; -- 建立两张表,一个存储博客信息&am…...
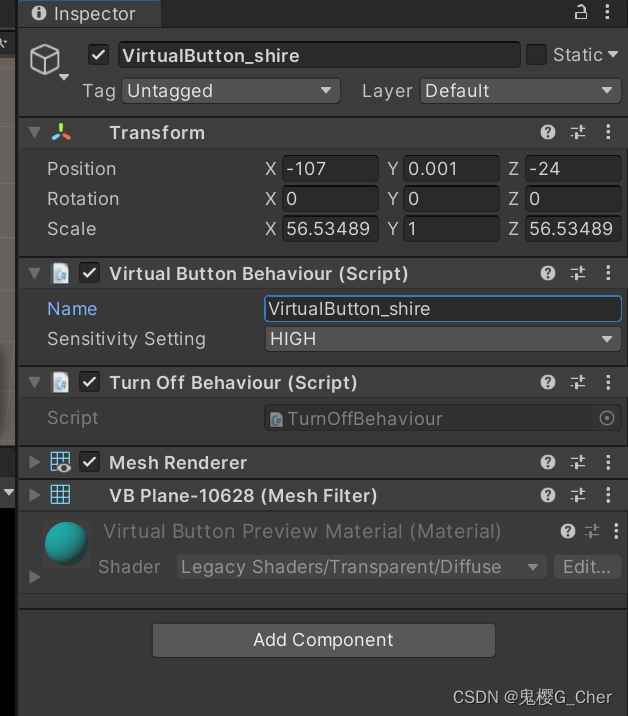
【unity/vufornia】Duplicate virtual buttons with name.../同一个ImageTarget上多个按钮失灵
问题:在同一个ImageTarget上添加多个按钮时无法触发对应按钮的事件。 解决过程: 1.查看报错:“Duplicate virtual buttons with name...”这一行,顾名思义,命名重复。 2.英文搜索到以下文章,应该在inspe…...

Apache ActiveMQ 远程代码执行漏洞复现(CNVD-2023-69477)
Apache ActiveMQ 远程代码执行RCE漏洞复现(CNVD-2023-69477) 上周爆出来的漏洞,正好做一下漏洞复现,记录一下 1.漏洞描述 Apache ActiveMQ 中存在远程代码执行漏洞,具有 Apache ActiveMQ 服务器TCP端口ÿ…...

项目管理-科学管理基础-线性规划介绍及例题
项目管理中的线性规划是什么? 在项目管理中,线性规划是一种数学建模和优化技术,用于解决资源分配和进度规划的问题。线性规划的目标是在给定的资源限制下,找到最佳的资源分配方案,以满足项目的需求并优化特定的目标,如成本最小化或时间最短化。 线性规划的基本元素包括…...
如何利用自定义数据对象(元数据)实现全场景身份数据治理
在数字化时代背景下,5G、云计算、大数据、物联网、人工智能等技术的发展,为企业数据管理提供了基础技术支撑。数字化浪潮推动企业快速升级迭代,在数据管理和数字化转型过程中,企业内部的数据情况常常错综复杂,并伴随着…...
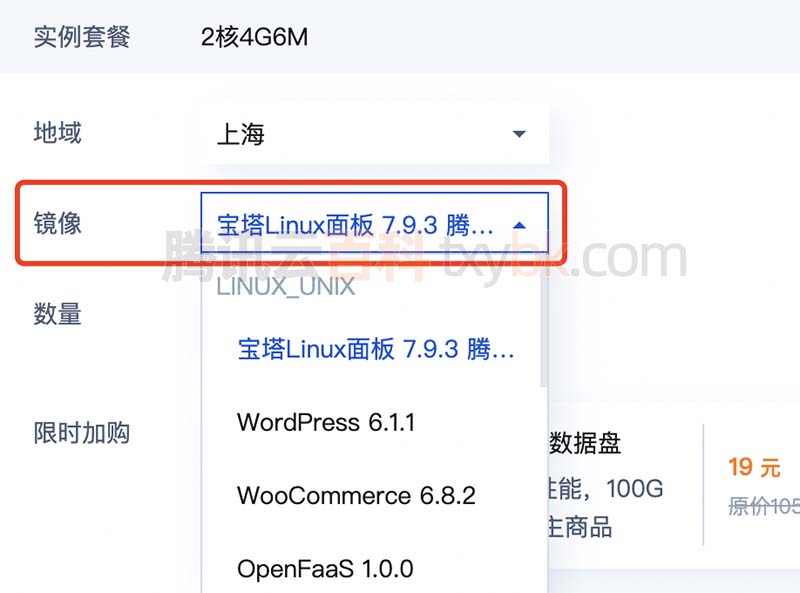
腾讯云轻量级服务器哪个镜像比较好?
腾讯云轻量应用服务器镜像是什么?镜像就是操作系统,轻量服务器镜像系统怎么选择?如果是用来搭建网站腾讯云百科txybk.com建议选择选择宝塔Linux面板腾讯云专享版,镜像系统根据实际使用来选择,腾讯云百科来详细说下腾讯…...

SC密封件的材料成分
SC密封件也称为轴密封件,是许多机械系统中的关键组件,提供防止润滑剂泄漏和污染物进入的屏障。但SC密封件是由什么材料制成的呢? SC密封型材由带有橡胶涂层的单个金属保持架和带有集成弹簧的主密封唇组成。这种材料的组合为密封件提供了其基本特性&…...
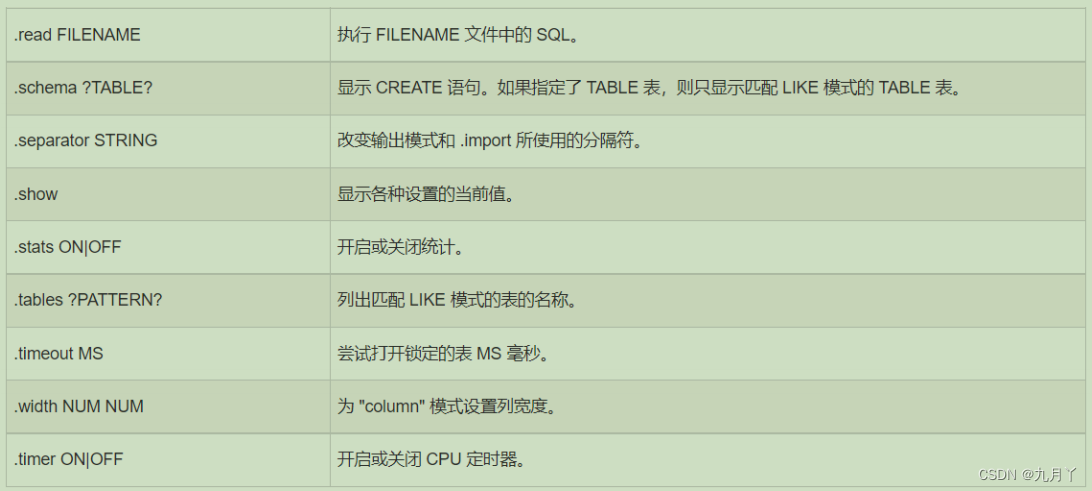
常用 sqlite3 命令
本次将向您讲解 SQLite 编程人员所使用的简单却有用的命令。这些命令被称为 SQLite 的点命令,这些命令的不同之处在于它们不以分号 ; 结束。 让我们在命令提示符下键入一个简单的 sqlite3 命令,在 SQLite 命令提示符下,您可以使 用各种 …...
SpringMVC Day 08 : 文件上传下载
前言 文件上传和下载是 Web 开发中的重要环节,但它们往往不那么容易实现。幸运的是,Spring MVC 提供了一套简单而又强大的解决方案,让我们可以专注于业务逻辑,而不必过多关注底层的文件处理细节。 在本篇博客中,我们…...
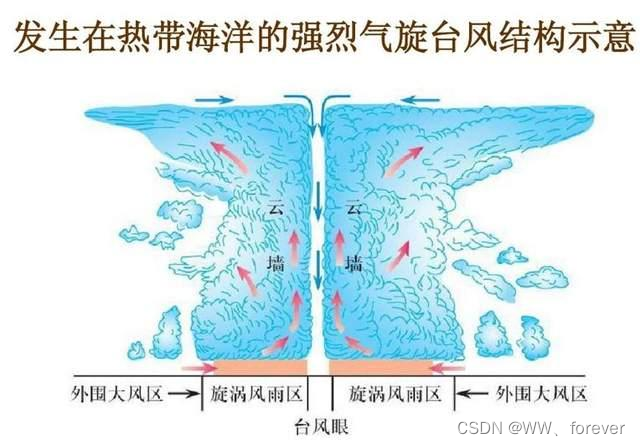
【热带气旋】基本介绍:定义、标准、结构等
热带气旋基本介绍 热带气旋(Tropical Cyclone, TC)1 热带气旋定义2 热带气旋标准2.1 热带低压(Tropical Depression)2.2 热带风暴(Tropical storm)2.3 强热带风暴(Severe tropical storm&#x…...

百度网盘直链解析工具:3分钟突破限速实现满速下载
百度网盘直链解析工具:3分钟突破限速实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾为百度网盘的下载速度而烦恼?非会员用户经常…...

如何用nmrpflash拯救你的Netgear路由器:从“变砖“到重生的完整指南
如何用nmrpflash拯救你的Netgear路由器:从"变砖"到重生的完整指南 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器固件升级失败、意外断电或系统崩溃后无法启动…...

终极解密指南:Windows平台NCM音频文件一键转换实战
终极解密指南:Windows平台NCM音频文件一键转换实战 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾因网易云音乐的NCM加密格式而烦恼&…...

STM32CubeIDE实战指南:从代码编译到一键下载的完整流程解析
1. STM32CubeIDE开发环境概述 对于刚接触STM32开发的工程师来说,选择一款合适的集成开发环境(IDE)至关重要。STM32CubeIDE是ST官方推出的免费开发工具,它集成了代码编辑、编译、调试和下载功能于一体,特别适合新手快速上手。我在实际项目中使…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...

如何免费高效优化电脑性能:UXTU终极调优指南
如何免费高效优化电脑性能:UXTU终极调优指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility Universal x86 Tuning…...

开源项目容器镜像全流程实践:从命名规范到生产部署
1. 项目概述:从镜像名到开源协作生态的深度解构看到mco-org/mco这个镜像名,很多人的第一反应可能是去 Docker Hub 或 GitHub 上搜索,看看它具体是什么。但今天,我想从一个更本质、更实战的角度来聊聊这个话题。mco-org/mco不是一个…...

告别时间混乱:一份超全的Hive日期函数使用手册与常见错误排查
告别时间混乱:一份超全的Hive日期函数使用手册与常见错误排查 在数据开发领域,时间数据处理一直是高频且易错的环节。无论是日志分析、用户行为追踪还是财务报表生成,准确的时间计算都是确保数据质量的基础。Hive作为大数据生态中广泛使用的数…...

从仿生结构到步态算法:8自由度并联腿机器狗行走全解析
1. 8自由度并联腿机器狗的结构奥秘 第一次拆解机器狗时,我对着那些复杂的连杆结构发了半小时呆。直到发现它的腿部运动原理和公园里的跷跷板惊人相似——这个发现让我瞬间理解了8自由度并联腿的精妙之处。这种结构就像给机器人装上了"机械肌腱"࿰…...

构建个人技能库:用GitHub+Markdown打造开发者的第二大脑
1. 项目概述:从“我的Copaw技能”看个人技能库的构建与管理最近在GitHub上看到一个挺有意思的项目,叫“my-copaw-skill”。这个项目名本身就很有故事感,“Copaw”这个词,我猜是“Code”和“Paw”(爪子)的结…...