transformers-Generation with LLMs
https://huggingface.co/docs/transformers/main/en/llm_tutorial![]() https://huggingface.co/docs/transformers/main/en/llm_tutorial停止条件是由模型决定的,模型应该能够学习何时输出一个序列结束(EOS)标记。如果不是这种情况,则在达到某个预定义的最大长度时停止生成。
https://huggingface.co/docs/transformers/main/en/llm_tutorial停止条件是由模型决定的,模型应该能够学习何时输出一个序列结束(EOS)标记。如果不是这种情况,则在达到某个预定义的最大长度时停止生成。
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
)from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, orange, purple, pink,'tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
model_inputs = tokenizer(["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
).to("cuda")
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['A list of colors: red, blue, green, yellow, orange, purple, pink,',
'Portugal is a country in southwestern Europe, on the Iber']生成策略有很多,
生成结果太短或太长
如果在GenerationConfig文件中未指定,则默认情况下generate返回最多20个标记。建议在generate调用中手动设置max_new_tokens来控制它可以返回的最大新标记数。请注意,LLM(更精确地说是仅解码器模型)还将输入提示作为输出的一部分返回。
model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")# By default, the output will contain up to 20 tokens
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'# Setting `max_new_tokens` allows you to control the maximum length
generated_ids = model.generate(**model_inputs, max_new_tokens=50)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'生成模式不正确
默认情况下,generate在每次迭代中选择最可能的标记(greedy decoding),除非在GenerationConfig文件中指定。
# Set seed or reproducibility -- you don't need this unless you want full reproducibility
from transformers import set_seed
set_seed(42)model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")# LLM + greedy decoding = repetitive, boring output
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'# With sampling, the output becomes more creative!
generated_ids = model.generate(**model_inputs, do_sample=True)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. Specifically, I am an indoor-only cat. I'边缘填充错误
LLM是仅解码器架构,这意味着它们会继续对输入提示进行迭代。如果您的输入长度不相同,那么它们需要被填充。由于LLM没有被训练以从填充标记继续生成,因此输入需要进行左填充。确保还记得将注意力掩码传递给generate函数!
# The tokenizer initialized above has right-padding active by default: the 1st sequence,
# which is shorter, has padding on the right side. Generation fails to capture the logic.
model_inputs = tokenizer(["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
).to("cuda")
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 33333333333'# With left-padding, it works as expected!
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
model_inputs = tokenizer(["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
).to("cuda")
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'错误的prompt
一些模型和任务需要特定的输入提示格式才能正常工作。如果未使用该格式,性能可能会出现悄然下降:模型可以运行,但效果不如按照预期的提示进行操作。
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
model = AutoModelForCausalLM.from_pretrained("HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
)
set_seed(0)
prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
input_length = model_inputs.input_ids.shape[1]
generated_ids = model.generate(**model_inputs, max_new_tokens=20)
print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
"I'm not a thug, but i can tell you that a human cannot eat"
# Oh no, it did not follow our instruction to reply as a thug! Let's see what happens when we write
# a better prompt and use the right template for this model (through `tokenizer.apply_chat_template`)set_seed(0)
messages = [{"role": "system","content": "You are a friendly chatbot who always responds in the style of a thug",},{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda")
input_length = model_inputs.shape[1]
generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
'None, you thug. How bout you try to focus on more useful questions?'
# As we can see, it followed a proper thug style 😎相关文章:
transformers-Generation with LLMs
https://huggingface.co/docs/transformers/main/en/llm_tutorialhttps://huggingface.co/docs/transformers/main/en/llm_tutorial停止条件是由模型决定的,模型应该能够学习何时输出一个序列结束(EOS)标记。如果不是这种情况,则在…...
maven之父子工程版本控制案例实战,及拓展groupId和artifactId的含义
<parent>标签 用于父子工程项目,什么是父子工程? 顾名思义,maven父子项目是一个有一个父项目,父项目下面又有很多子项目的maven工程,当然,子项目下面还可以添加子项目,从而形成一个树形…...

100量子比特启动实用化算力标准!玻色量子重磅发布相干光量子计算机
2023年5月16日,北京玻色量子科技有限公司(以下简称“玻色量子”)在北京正大中心成功召开了2023年首场新品发布会,重磅发布了自研100量子比特相干光量子计算机——“天工量子大脑”。 就在3个月前,因“天工量子大脑”在…...

JAVA基础(JAVA SE)学习笔记(十)多线程
前言 1. 学习视频: 尚硅谷Java零基础全套视频教程(宋红康2023版,java入门自学必备)_哔哩哔哩_bilibili 2023最新Java学习路线 - 哔哩哔哩 第三阶段:Java高级应用 9.异常处理 10.多线程 11.常用类和基础API 12.集合框架 13.泛型 14…...

ChatGPT参数只有200亿?扩散代码模型,意外泄露
微软的研究部门发布了一篇关于预训练扩散代码模型CodeFusion的论文。在展示代码生成任务的基线数据对比时,发现了一个有趣的事情,ChatGPT(gpt-3.5-turbo)的参数只有200亿。 要知道,gpt-3.5-turbo是OpenAI中应用最多、…...

VR虚拟仿真教学在建筑学课堂中的应用
1. 增强真实感:VR技术能创造出近乎真实的虚拟环境,使学生仿佛置身其中,增强他们的感官体验。 2. 打破空间限制:VR教学可以打破时间和空间的限制,学生可以在任何时间、任何地点进行学习,无需担心课堂位置的…...

竞赛 深度学习实现行人重识别 - python opencv yolo Reid
文章目录 0 前言1 课题背景2 效果展示3 行人检测4 行人重识别5 其他工具6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习的行人重识别算法研究与实现 ** 该项目较为新颖,适合作为竞赛课题方向,…...

当代都市的时尚先锋:气膜建筑的魅力
当代城市的崛起如一部快速奔腾的时光流。在这个光速发展的都市中,时间被看作珍贵的黄金,而效率被视为无价的生命。而在这个节奏日益加快的现代都市背后,一个独特的“神器”——气膜建筑,悄然崭露头角,成为城市发展的领…...
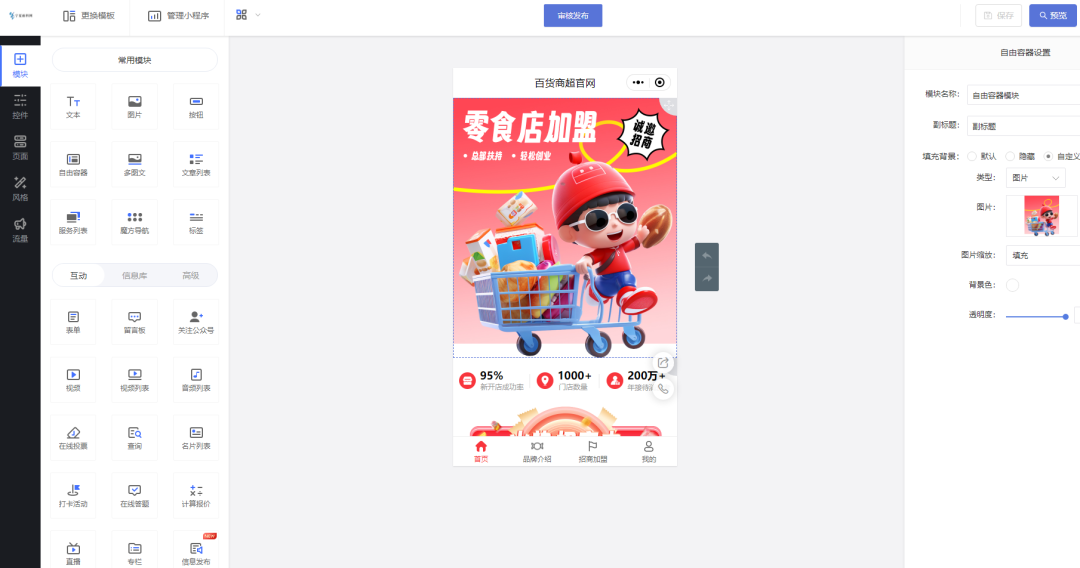
品牌加盟商做信息展示预约小程序的效果如何
很多行业都有中部或头部品牌,对实体品牌企业来说想要快速高效发展,除了多地直营店外还需要招募加盟商进而提升生意营收。 因此线上渠道变得尤为重要,除了网站外,小程序是连接多平台生态很好的工具,随时打开、直接触达…...
delphi 11.3 FastReport 多设备跨平台 打印之解决方法
以下能WINDOWS10 DELPHI 11.3 FastReport6.0上顺利通过 FastReport6.2对Multi-Device Application应用的支持不够友好,如下图;在palette FastReport6.0才出现几个制件。 非Multi-Device Application应用时是一大堆; 非Multi-Device Appl…...

配置vue 环境
一、安装Node.js及配置环境 环境变量配置 第一步:“此电脑”-右键-“属性”-“高级系统设置”-“高级”-“环境变量” 第二步(我的为:C:\Program Files\nodejs ),然后编辑path,新建,为…...
Visio文件编辑查看工具Visio Viewer for Mac
Visio Viewer mac版是一款Visio文件查看工具,可以使用本程序打开所有的visio文件数据,支持多种语言环境,可以对visio文件进行编辑、跳转参数等设置。 Visio Viewer for Mac可以打开和查看Visio文件(.vsd、.vdx和.vsdm文件&#x…...

现在软文发布平台都有哪些?如何在正规媒体发稿?
近年来,随着广告行业竞争愈加激烈,越来越多的企业开始注重软文宣传。软文推广平台是企业在网络上发布软文、传播信息和推广产品的重要工具。 媒介易软文平台介绍更好的品牌宣传和市场推广:软文推广发稿有哪些平台, 软文发稿好方法?软文不仅能…...

【卷积神经网络】YOLO 算法原理
在计算机视觉领域中,目标检测(Object Detection)是一个具有挑战性且重要的新兴研究方向。目标检测不仅要预测图片中是否包含待检测的目标,还需要在图片中指出它们的位置。2015 年,Joseph Redmon, Santosh Divvala 等人…...

云计算与ai人工智能对高防cdn的发展
高防CDN(Content Delivery Network)作为网络安全领域的一项关键技术,致力于保护在线内容免受各种网络攻击,包括分布式拒绝服务攻击(DDoS)等。然而,随着人工智能(AI)和大数…...

Web3时代:探索DAO的未来之路
Web3 的兴起不仅代表着技术进步,更是对人类协作、创新和价值塑造方式的一次重大思考。在 Web3 时代,社区不再仅仅是共同兴趣的聚集点,而变成了一个价值交流和创新的平台。 去中心化:超越技术的革命 去中心化不仅仅是 Web3 的技术…...

odbcinst文件
odbcinst文件是ODBC(Open Database Connectivity)驱动程序管理器的配置文件。ODBC是一种标准的数据库访问接口,允许应用程序通过统一的方式连接和访问不同类型的数据库。 odbcinst文件通常位于操作系统的特定目录中,并且用于定义…...
)
(CQUPT 的某数据结构homework)
CQUPT 的某数据结构homework 基于线性表的图书信息管理基于栈的算术表达式求值基于字符串模式匹配算法的病毒感染检测问题 基于哈夫曼树的数据压缩算法基于二叉树的表达式求值算法基于 Dijsktra 算法的最短路基于广度优先搜索的六度空间排序算法的实现与分析 基于线性表的图书信…...
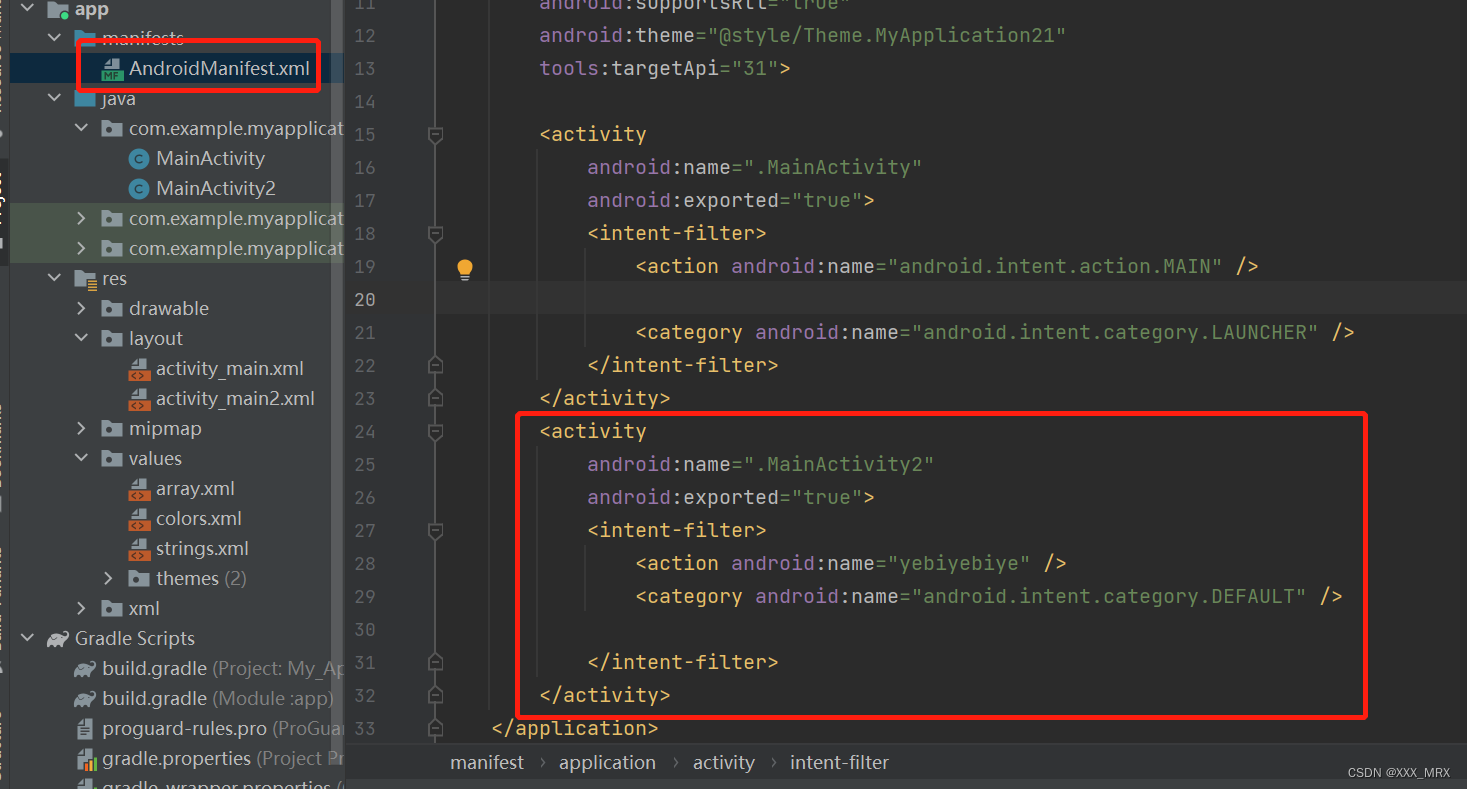
Android页面周期、页面跳转
1.什么是Activity? Activity是Android的四大组件之一,它是一种可以包含用户界面的组件,主要用于和用户进行交互。Activity用于显示用户界面,用户通过Activity交互完成相关操作,一个APP允许有多个Activity。 2.Activi…...

腾讯云轻量应用镜像、系统镜像、Docker基础镜像、自定义镜像和共享镜像介绍
腾讯云轻量应用服务器镜像类型分为应用镜像、系统镜像、Docker基础镜像、自定义镜像和共享镜像,腾讯云百科txybk.com来详细说下不同镜像类型说明和详细介绍: 轻量应用服务器镜像类型说明 腾讯云轻量应用服务器 应用镜像:独有的应用镜像除了包…...

OpenClaw容器化部署:Docker打包Kimi-VL-A3B-Thinking多模态服务的完整流程
OpenClaw容器化部署:Docker打包Kimi-VL-A3B-Thinking多模态服务的完整流程 1. 为什么选择容器化部署OpenClaw 去年我在本地尝试部署OpenClaw对接Kimi-VL多模态模型时,经历了整整三天的依赖地狱。不同版本的CUDA驱动、Python包冲突、系统库缺失等问题让…...

OpenClaw+Qwen3.5-9B组合优势:3个不可替代的使用场景
OpenClawQwen3.5-9B组合优势:3个不可替代的使用场景 1. 为什么选择OpenClawQwen3.5-9B组合 去年夏天,当我第一次尝试用Python脚本自动化处理医疗研究数据时,遇到了一个尴尬的问题:要么忍受公有云API的数据隐私风险,要…...
)
【2026企业级Blazor落地白皮书】:金融/医疗场景下SSR+Hydration+Streaming SSR三模混合渲染实战(附GCP/Azure边缘部署Checklist)
第一章:Blazor 2026企业级落地战略全景图 Blazor 正在从“可选框架”跃迁为 2026 年企业级 .NET 应用的默认前端架构范式。其核心驱动力并非仅限于 C# 全栈统一,更在于 WebAssembly 运行时成熟度、AOT 编译稳定性提升、以及与 Azure Static Web Apps、Mi…...

红黑树:从入门到精通的C++实战
从零到一掌握红黑树:数据结构中的平衡之道红黑树是一种自平衡的二叉搜索树,它通过颜色属性和特定规则来确保树的高度大致平衡,从而保证查找、插入和删除操作的时间复杂度为$O(\log n)$。在C中,红黑树常用于实现标准库中的std::map…...
)
什么是引线键合(WireBonding)
引线键合(WireBonding)引线键合是一种使用细金属线,利用热、压力、超声波能量为使金属引线与基板焊盘紧密焊合,实现芯片与基板间的电气互连和芯片间的信息互通。在理想控制条件下,引线和基板间会发生电子共享或原子的相…...

JPEGENC:4KB RAM下运行的嵌入式JPEG编码器
1. JPEGENC:面向资源受限MCU的轻量级JPEG编码器深度解析1.1 设计哲学与工程定位JPEGENC并非对libjpeg或mozjpeg等通用JPEG库的简单裁剪,而是在裸机(Bare-metal)约束下重构的嵌入式专用编码器。其核心设计目标直指MCU开发中最尖锐的…...

如何解决数位板跨平台兼容难题?OpenTabletDriver开源驱动的一站式配置体验
如何解决数位板跨平台兼容难题?OpenTabletDriver开源驱动的一站式配置体验 【免费下载链接】OpenTabletDriver Open source, cross-platform, user-mode tablet driver 项目地址: https://gitcode.com/gh_mirrors/op/OpenTabletDriver OpenTabletDriver是一款…...
✅)
计算机毕业设计:Python智慧水网监测与水位预测大屏 Flask框架 数据分析 可视化 大数据 AI 线性回归 河流数据 水位预测(建议收藏)✅
1、项目介绍 技术栈 采用 Python 语言开发,基于 Flask 框架搭建后端服务,使用 Vue 框架构建前端交互界面,MySQL 数据库进行数据存储,运用机器学习线性回归预测算法实现水位预测,结合 Echarts 可视化技术搭建数据大屏&a…...

# Excel模板转PDF合并单元格边框全乱了?逐个格子读取边线信息再还原
Excel模板转PDF合并单元格边框全乱了?逐个格子读取边线信息再还原 非科班野生程序员,深耕政务信息化20年。从VC到PB再到Java,自研框架browise也打磨了十几年。最近整理框架代码,发现不少有趣的决策,写出来和大家聊聊。…...

嵌入式Linux开发常见问题解决:内核编译与NFS根文件系统启动卡住
在移植Linux系统到ARM开发板的过程中,编译内核和通过NFS启动根文件系统是两个常见环节,但也经常遇到各种“小坑”。本文结合两个实际案例,分析问题原因并给出解决方案。一、编译内核时出现 lzop: not found 错误问题现象在执行 make zImage 编…...