大模型冷思考:企业“可控”价值创造空间还有多少?
文 | 智能相对论
作者 | 叶远风
毫无疑问,大模型热潮正一浪高过一浪。
在发展进程上,从最开始的技术比拼到现在已开始全面强调商业价值变现,百度、科大讯飞等厂商都喊出类似“不能落地的大模型没有意义”等口号。
在模型类型上,除了百度文心大模型、讯飞星火认知大模型、阿里通义千问大模型等通用大模型,医药研发、金融等垂直大模型正积极涌现。几个月前,新华三集团在业内首提“私域大模型”概念,并发布融合了行业属性及地域属性的私域大模型——“百业灵犀”LinSeer,为行业增添了企业落地大模型的创新类型。

而在更直接的数字上,截止到2023年10月初,国内仅公开的大模型数量已达238个,百模大战正在升级千模大战。
……接近一年的热潮后大模型没有冷却的迹象,行业普遍的共识形成,这不是风口,而是技术革命。
然而,历史一次次证明,赛道越是热闹,参赛者越需要冷静的思考。
种种迹象显示,虽然看起来百花齐放,但事实上AI三大要素(算力、数据、算法),以及大模型发展的行业规则中,当下以及未来很多因素已经既定,一头热扎进去的企业们,更应该寻找的是那些不由既成的客观因素所限制、能够进行自我价值发挥的地方,才能尽可能获得相对竞争优势。
算力“积木化”,可控价值创造集中到“调度”环节
算力常常被视为大模型发展的瓶颈问题,但是,如果从是否“可控”的视角看,在业务层面企业能自己做出决定从而影响算力获取的地方,其实越来越少。
IT时代Windows+Intel构建起WinTel体,演变为移动互联网时代安卓+ARM(以高通为代表),到了大模型时代,又进一步演化为AI大模型+GPU——在当前,Nvidia已经成为大模型趋同的算力来源。
2021的Ampere(对应A100等)、2022年的Hopper(对应H100等)、2023的Ada架构……性价比高不高,要看Nvidia架构发展有多快。
算力不再是瓶颈,或者说,其“总体基本面”的提升并没有什么操作空间——要多少算力就需要多少资本投入,反过来有多少资本投入基本也能买来多少算力。
当算力“口子”被外部技术、内部预算等限定,通过调度提升既有资源利用效率,就成为企业“可控”的价值创造过程。特别是私域大模型,对于企业来说,AI大模型的大小需要平衡算力和能耗的开支,应选择适合行业特点和业务特点的大模型进行私域部署。
此时,如何榨取硬件资源提供的每一滴能力,加速模型的训练速度成为首要考虑的问题,而这方面术业有专攻,往往依赖基础设施服务厂商——针对算力等底层基础设施提供支撑成为考验各个服务厂商最基本的能力,其中尤以算力调度能力是其重点。

算力调度往往需要多维能力协同,所以,作为业内首倡私域大模型的新华三给出了自己的回答:依托通过傲飞算力平台实现算力调度的“最优解”,让算力可以最大化的按需调度。另一方面以绿洲平台实现大模型所需的数据支撑,同时在分布式训练等需求下以智能无损网络支持AI集群训练,配备高性能存储带来更好的底层存储支撑,甚至还建设有液冷数据中心来维持算力输出的稳定性,以此构成一套完整的智算解决方案。
而新华三算力调度的“主脑”傲飞算力平台则具备异构计算资源统一管理、多元算力资源智能调度的能力,提供包含智能标注、智能训练、智能调优、智能部署、智能推理的全流程算力智能调度能力。
按官方数据,该平台能够将算力利用率提高至70%以上。同时,还支持8000节点的算力调度,并发训练时间缩短至50%,且断点自动接续无感知训练更稳定,在既有GPU资源下能全方面提升大模型训练性能。
说白了,就是通过一系列算力流程环节的衔接优化(尤其是面对并行计算与分布式计算需求),在充分保障训练与应用需求的同时降低GPU的空闲时间,让巨大成本获取来的算力资源工作尽可能饱和。
总体而言,这一整套高性能算力集群及调度让客户能够实现算力、存力、运力协同感知,实现算力资源充分供给、灵活部署、异构算力最优调度——虽然有多少算力资源很难控制,但用好这些资源企业却能够做到完全可控。
当然,除了提升算力利用效率,行业中一些做法还在试图通过其他方式直接降低模型训练对GPU资源的要求,例如数据存储层面进行算子优化等,未来或也存在较大的价值开发空间。
数据“断面化”,以数据质量建设带来“护城河”成为企业的必然选择
目前,企业能够获得的数据量来源主要包括公开的数据集与自身沉淀。
在当下时间断面,这两种都只能被动等待或由时间积累,数据“量”其实很难有突破,优势有就是有,没有就是没有,并不可控。
当然,也有一些企业试图主动出击,例如国外公司Inflection AI以大规模提问的方式来主动提升数据沉淀速度,但这显然这并不会是主流。

“量”上不可控,则可控的价值创造空间必须更聚焦于“质”上。
中信智库《人工智能十大发展趋势》认为,“未来一个模型的好坏,80%由数据质量决定。”
从长远视角看,大模型的竞争并不是要比谁跑得更快,而是比谁走得更远,这就需要大模型真实的应用效果,也就需要通过各种方式提升数据质量,来锻造大模型发展的“内功”。
在数据的计划、获取、存储、共享、维护、应用等环节,都需要针对性的数据管理、治理,最终提升数据质量。这是一个系统性工程,也为市面上的基础设施服务商们带来了机会。
例如新华三的绿洲平台就以场景需求为导向,打造了一个围绕数据采集、存储、管理和应用的全栈数据平台。
通过内置AI算法,绿洲平台大大提升了数据标记能力,让数据治理、数据开发等过去很繁杂的流程工作变得极为简单,而知识图谱构建能力则帮助数据跃升为知识,从而能够更好地被业务场景所使用。
事实上,数据深加工带来高质量数据训练一直是前沿大模型的核心竞争力所在,OpenAI一贯公开其训练过程及算法,但对数据如何处理缄口不言。
回过头来看,数据的“要素化”与“资产化”正在让百行百业再次审视数据的价值,在数据越来越作为一种新型生产力要素的时代,大模型的本质可以视作一种挖掘数据要素价值的工具,而工具不决定价值,只决定效率。
大模型终将走入底层成为一种普遍的后端能力,技术本身越来越无法成为护城河,而数据则代表了企业在前端与客户/用户的连接程度,数据要素的价值释放将成为企业真正的“护城河”。
所有的数据类平台提升数据质量的过程,就是在帮助企业进一步挖掘数据要素价值、沉淀数据资产,真正打造企业的“护城河”。
算法“收敛化”,殊途同归下企业需聚焦训练效率提升
算法是大模型的能力核心,但长期来看,算法能力却终将“收敛”。
目前的大模型算法基本上都基于Transformer架构,该架构解决了过去RNN架构难以并行化等核心缺陷,是基因“优胜劣汰”的结果,BERT、GPT、T5、GLM等都其“衍生品”。
所以,算法生来都几乎有着相同的“基因”。
而在开发框架层面,伴随着开源生态建设,国外的TensorFlow、Pytorch,国内的MindSpore等几个主流框架逐步成为共同的选择。
这意味着,算法的后天的“成长环境”也逐步趋同。

先天+后天,算法创新当下看起来百花齐放,但在未来其价值创新的空间将逐步收窄,企业能够通过努力获得的相对优势将越来越少。
甚至,在Llama 2掀起的开源浪潮下,算法创新的价值被进一步压缩。
因此,从长期来看,企业最“可控”的价值创造将侧重到训练效率而非算法创新上——同样的能力与潜力,PK更快速地训练迭代。
很多厂商提供的开发工具链都在直接推进训练效率,而一些原本旨在提供算力服务的平台也实现了等价的功能。
例如,傲飞算力平台支持断点自动接续无感知训练,其原本目的在于降低参数迭代期间的GPU资源等待、提升资源利用效率,但客观上也直接带来训练效率的提升,让算法加速迭代,先把潜力跑出来。
毕竟,加速算法训练,就是在提升算力资源利用效率。
行业规则“沉淀化”:长期主义仍需回归到正确的价值观
大模型热潮中,人人都会不自觉追求技术与商业价值“上限”,但大模型“下限”问题也日益突出,例如数据隐私、数据安全、知识产权、技术滥用等。
从企业的视角看,行业规则建立迫在眉睫,但其形成过程同样存在着不由企业决定的“客观因素”。
关于行业发展的一些法律法规,监管部门在逐步沉淀,例如国家网信办联合多部门公布的《生成式人工智能服务管理暂行办法》,企业要做的是等待并尽力配合与落实。
关于行业统一共识,也需要一个个沉淀,例如,目前已经有从业者提议行业协作开发统一、可信的框架,在隐私保护、模型效用和训练效率之间取得平衡,企业要做的是积极响应、积极参与。
但在一些规则上,企业能够、也必须充分发挥“可控”的价值创造能力。
例如,大模型数据安全“容错率低”,企业必须加大投入。

很多基础设施厂商都提供了相关的服务,例如新华三的私域大模型百业灵犀以内置安全限制提示词和出入内容过滤拦截对所有场景下大模型生成内容进行安全性限制,针对所有出入流量和内容进行安全审计和敏感信息拦截。
当然,最直观反应大模型伦理、体现“下限”的是场景应用的选择问题。
科研、制造、医药、法律……大模型已经走向诸多能带来社会正向价值的场景。但是,诸如伪造视频进行诈骗等“场景应用”也已经出现,基于强力的大模型技术有着更强的欺骗性。
技术是刀,大模型是一把更锋利的刀,它的作用和价值由使用的人决定。
说到底,企业需要构建正确的价值观,将大模型能力导向数字经济的正向价值上,才能守住“下限”、实现大模型的长期健康发展。
结语
大模型赛道上,企业必须在“可控”的价值创造空间上发力,才能不断在各个维度获得更多相对竞争优势与发展可能性。
企业也必须以此为标准选择基础设施服务、大模型服务的厂商,尤其是在多个维度都能满足需要的厂商。
可以说,大模型给了这个时代全新的增量价值方向,只有帮助企业实现对“可控”价值创造的把握,才能让企业在这个全新方向更有着力点。
*本文图片均来源于网络
#智能相对论 Focusing on智能新产业新服务,这是智能的服务NO.245深度解读
此内容为【智能相对论】原创,
仅代表个人观点,未经授权,任何人不得以任何方式使用,包括转载、摘编、复制或建立镜像。
部分图片来自网络,且未核实版权归属,不作为商业用途,如有侵犯,请作者与我们联系。
•AI产业新媒体;
•澎湃新闻科技榜单月度top5;
•文章长期“霸占”钛媒体热门文章排行榜TOP10;
•著有《人工智能 十万个为什么》
•【重点关注领域】智能家电(含白电、黑电、智能手机、无人机等AIoT设备)、智能驾驶、AI+医疗、机器人、物联网、AI+金融、AI+教育、AR/VR、云计算、开发者以及背后的芯片、算法等。
相关文章:
大模型冷思考:企业“可控”价值创造空间还有多少?
文 | 智能相对论 作者 | 叶远风 毫无疑问,大模型热潮正一浪高过一浪。 在发展进程上,从最开始的技术比拼到现在已开始全面强调商业价值变现,百度、科大讯飞等厂商都喊出类似“不能落地的大模型没有意义”等口号。 在模型类型上࿰…...

ctfshow-web入门37-52
include($c);表达式包含并运行指定文件。 使用data伪协议 ?cdata://text/plain;base64,PD9waHAgc3lzdGVtKCdjYXQgZmxhZy5waHAnKTs/Pg PD9waHAgc3lzdGVtKCdjYXQgZmxhZy5waHAnKTs/Pg 是<?php system(cat flag.php);?> base64加密 源代码查看得到flag 38 多禁用了ph…...

前端项目部署后,需要刷新页面才能看到更新内容
问题背景 前端项目部署更新后,通知业务验证,业务点击收藏的标签,打开网页后没有看到修改的内容,每次都需要手动刷新,用户体验非常不好。 问题原因:缓存未过期,浏览器直接读取本地缓存…...
android 13 write javaBean error at *** 错误
报错代码:红框处。 注意:android10 不会报错,运行正常。android13就报错 错误原因:对象中VerifyDownloadEntity,有个Bitmap成员变量 public class VerifyDownloadEntity {private Bitmap bitmap;private String cooki…...

Only fullscreen opaque activities can request orientation
出现Only fullscreen opaque activities can request orientation是谷歌爸爸在安卓8.0版本时为了支持全面屏,增加了一个限制:如果是透明的Activity,则不能固定它的方向,因为它的方向其实是依赖其父Activity的(因为透明…...
前端实验(一)单页面应用的创建
实验目的 掌握使用vite创建vue3单页面程序命令熟悉所创建程序的组织结构熟悉单页面程序运行原理能够编写简单的单页面程序 实验内容 创建一个名为vue-demo的单页面程序编写简单的单页面程序页面运行单页面程序 实验步骤 使用vite创建单页面程序 创建项目名为目录vue-demo的…...

数字人小灿:始于火山语音,发于 B 端百业
火爆的数字人市场又有新消息来袭:火山语音的数字人小灿来了! 数字人小灿首曝视频 今年以来,在生成式AI浪潮的助推下,大量企业争相布局数字人赛道。市场之所以如此火热,是因为AI数字人已被视为人工智能时代智能交互的入…...

蓝桥杯刷题
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析(3) 👉🏻最大降雨量 原题链接࿱…...
Go Metrics SDK Tag 校验性能优化实践
背景 Metrics SDK 是与字节内场时序数据库 ByteTSD 配套的用户指标打点 SDK,在字节内数十万服务中集成,应用广泛,因此 SDK 的性能优化是个重要和持续性的话题。本文主要以 Go Metrics SDK 为例,讲述对打点 API 的 hot-path 优化的…...
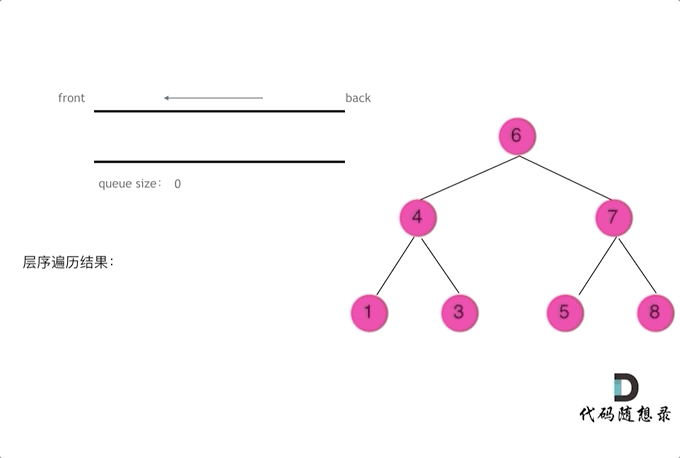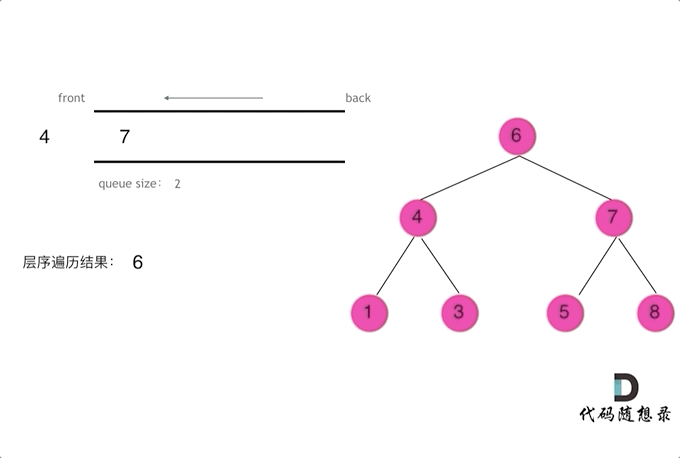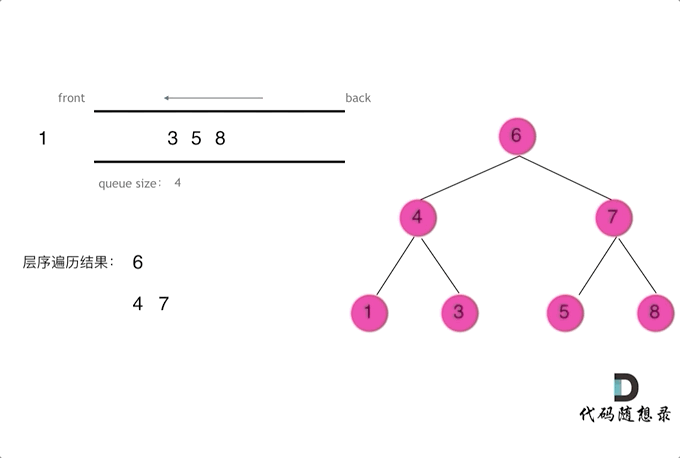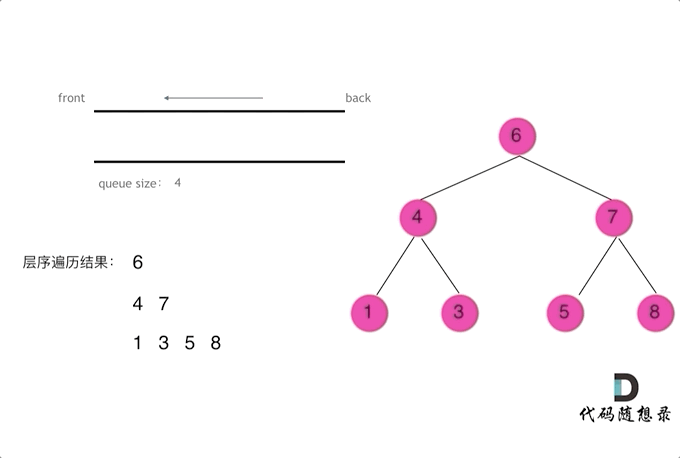
二叉树问题——前/中/后/层遍历问题(递归与栈)
摘要 博文主要介绍二叉树的前/中/后/层遍历(递归与栈)方法 一、前/中/后/层遍历问题 144. 二叉树的前序遍历 145. 二叉树的后序遍历 94. 二叉树的中序遍历 102. 二叉树的层序遍历 103. 二叉树的锯齿形层序遍历 二、二叉树遍历递归解析 // 前序遍历递归LC144_二叉树的前…...
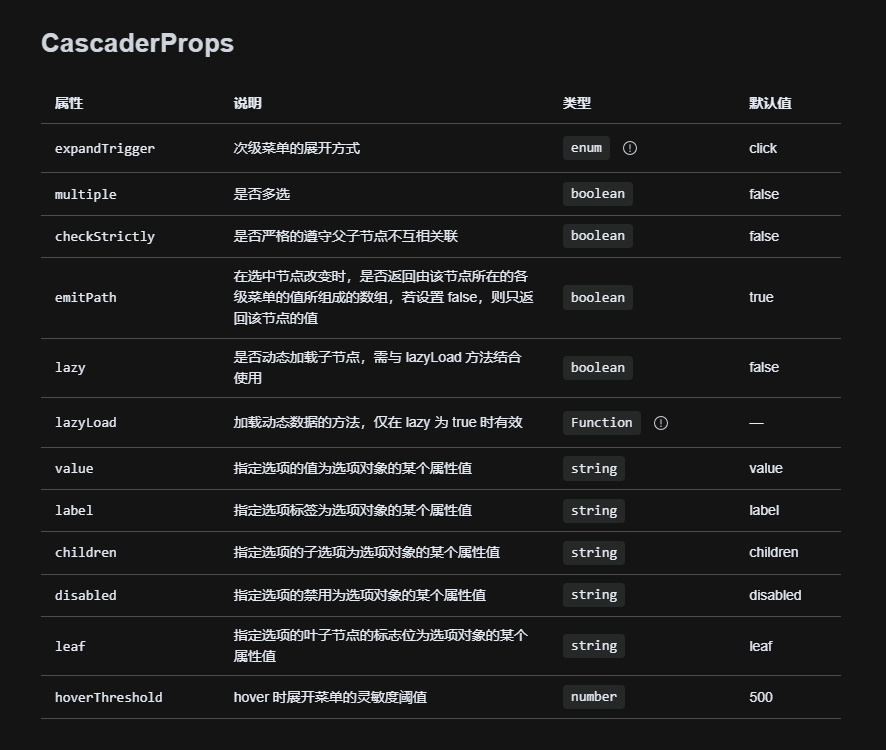
Vue3问题:如何实现级联菜单的数据懒加载?
前端功能问题系列文章,点击上方合集↑ 序言 大家好,我是大澈! 本文约3100字,整篇阅读大约需要5分钟。 本文主要内容分三部分,第一部分是需求分析,第二部分是实现步骤,第三部分是问题详解。 …...
STM32-电源管理(实现低功耗)
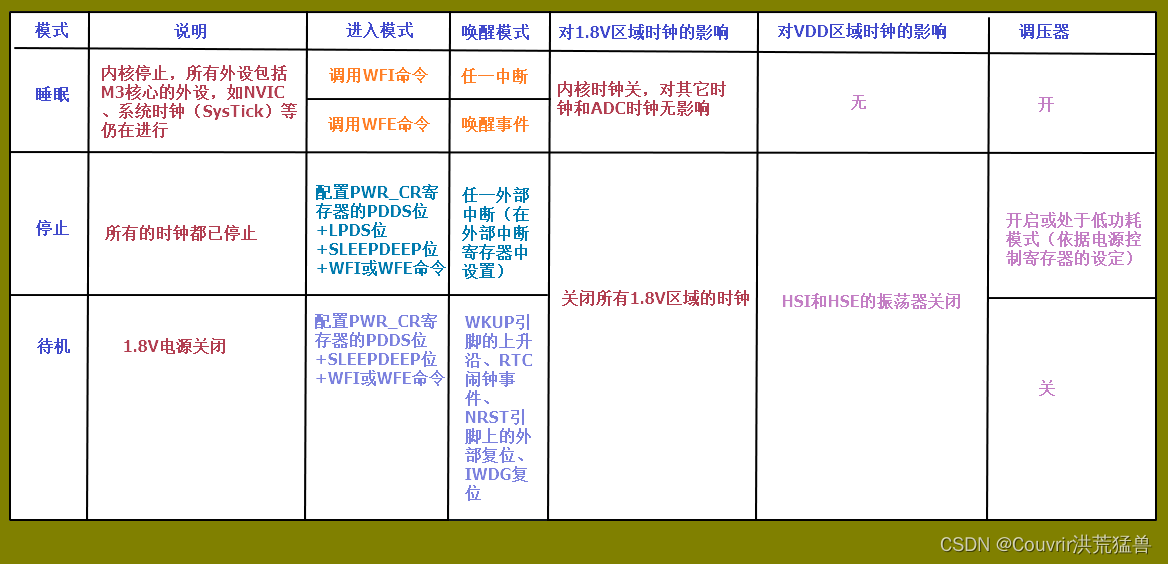
电源管理 STM32 HAL库对电源管理提供了完善的函数和命令。 工作模式(高功耗->低功耗):运行、睡眠、停止、待机。 若备份域电源正常供电,备份域内的RTC都可以正常运行,备份域内的寄存器的数据会被保存,不…...
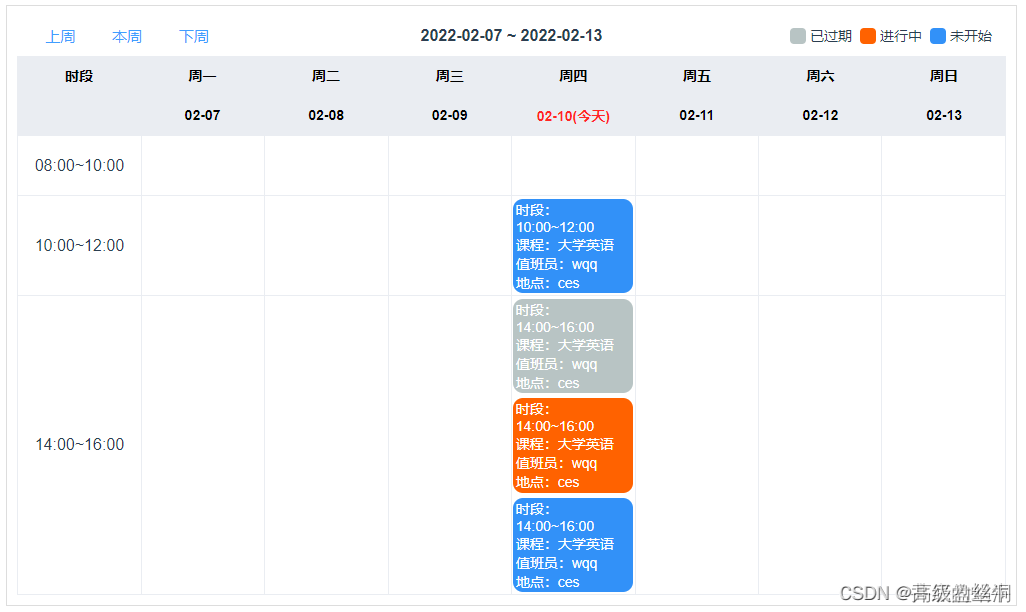
vue 自己捣鼓周日程日历组件
需求:想要一个周日程表,记录每天的计划,点击可查看详情。可自定义时间段通过后台获取时间段显示 分析: 通过需求,超级课程表app这款软件其中课表和这个需求很像,只不过这个需求第一列的时间段是自定义的,不是上午下午两个,但是原理都差不多 原本想找一些第三方插件使…...

【力扣】2127. (分类讨论 + 拓扑排序)参加会议的最多员工数
【力扣】2127. (分类讨论 拓扑排序)参加会议的最多员工数 文章目录 【力扣】2127. (分类讨论 拓扑排序)参加会议的最多员工数1. 题目介绍2. 思路(**分类讨论 拓扑排序**)3. 解题代码4. Danger参考 1. 题…...
使用教程)
Flutter——最详细(Map)使用教程
Map简介 键值对的集合,您可以使用其关联的键从中检索值。 普通的 HashMap是无序的(不保证顺序),LinkedHashMap 按键插入顺序迭代,而像 SplayTreeMap 这样的排序映射按排序顺序迭代键。 1,添加元素 addEntri…...

vue的入门第一课
Vue.js是一款流行的JavaScript框架,用于构建交互式Web应用程序。本文将详细介绍Vue.js的基础知识,包括Vue.js的历史、设计模式、构造函数参数、el、data、computed、method、watch以及差值的使用。 Vue.js是什么? Vue.js是一款用于构建用户…...

已解决:conda找不到对应版本的cudnn如何解决?
1.解决方法 配置深度学习环境时,打算安装cudatoolkit11.2和cudnn8.1,当使用conda install cudnn8.0时,却搜索不到这个版本的包,解决方法如下: conda search cudnn -c conda-forge然后就可以使用如下命令进行安装对应…...

大语言模型的学习路线和开源模型的学习材料《二》
第三层 LLMs to Artifact 第一重 langchain 【LLMs 入门实战 —— 十二 】基于 本地知识库 的高效 🤖langchain-ChatGLM 介绍:langchain-ChatGLM是一个基于本地知识的问答机器人,使用者可以自由配置本地知识,用户问题的答案也是基于本地知识生成的。【LLMs 入门实战 ——…...

Flask-SQLAlchemy事件钩子介绍
一、前言 前几天在搜资料的时候无意中看到有介绍SQLAlchemy触发器,当时感觉挺奇怪的,触发器不是数据库层面的概念吗,怎么flask-SQLAlchemy这个ORM框架会有这玩意。 二、SQLAlchemy触发器一个简单例子 考虑到效率博客表中有两个字段…...

C++——list
目录 list介绍 list的函数接口 构造函数 push_front和pop_front push_back和pop_back insert erase 迭代器 front和back size resize empty clear list::sort unique reverse 迭代器的实现 list介绍 list是一种可以在常数范围内在任意位置进行插入和删除的序列…...
)
用Python从零搭建GridWorld环境:手把手教你实现值迭代与策略迭代(附完整代码)
用Python从零搭建GridWorld环境:手把手教你实现值迭代与策略迭代(附完整代码)在强化学习领域,GridWorld就像编程界的"Hello World",是理解基础算法的最佳试验场。不同于理论推导的抽象,亲手构建一…...

Keil µVision许可证失效问题解析与解决方案
1. 问题现象与背景解析最近遇到一个挺有意思的案例:一位工程师在安装了Windows Media Center后,突然发现Keil Vision IDE变成了评估版模式。这种情况其实在嵌入式开发领域并不罕见,但很多开发者第一次遇到时都会感到困惑。本质上,…...

ABAP 关键用户版本语句白名单全解析:从语法限制到实战案例
在很多 SAP S/4HANA Cloud 项目里,业务关键用户已经不再满足于只提需求、等 IT 做开发。通过 Custom Fields and Logic 这类 Fiori 应用,关键用户可以直接在浏览器里写 ABAP 代码,自助实现校验、默认值、计算逻辑等扩展。这背后真正跑的,就是一个专门为关键用户设计的受限语…...

手把手教你用Linux命令‘偷看’UEFI启动日志,排查系统启动失败问题
实战指南:用Linux命令深度解析UEFI启动日志当你的Linux系统卡在启动界面,或是反复重启无法进入桌面时,那种焦虑感每个运维人员都深有体会。UEFI启动过程就像一场精心编排的交响乐,任何一个环节出错都可能导致系统启动失败。本文将…...

Exchange渗透:从邮件服务器到AD特权代理的系统化利用
1. 为什么Exchange渗透不是“扫个端口爆破邮箱”就完事了?很多人一听到“Exchange渗透”,脑子里立刻跳出几个关键词:OWA登录页、Autodiscover、EWS接口、NTLM中继、ProxyLogon——然后顺手丢个nuclei模板去扫,再跑一遍爆破脚本&am…...

Landsat8数据EVI计算踩坑实录:从辐射定标到大气校正,你的公式真的写对了吗?
Landsat8数据EVI计算全流程避坑指南:从数据预处理到公式验证第一次用Landsat8数据计算EVI指数时,我盯着屏幕上那些超出[-1,1]范围的数值发愣——这显然不对劲。作为遥感领域最常用的植被指数之一,EVI的正常值范围应该是-1到1之间。经过整整两…...
)
在CentOS7服务器上装Win10?手把手教你用Ventoy搞定双系统(附网卡驱动安装避坑指南)
在CentOS7服务器上实现Win10双系统:Ventoy实战与驱动避坑指南 当Linux服务器遇上Windows需求,双系统成为了一种优雅的解决方案。本文将带你深入探索在CentOS7生产环境中部署Win10双系统的完整流程,特别针对服务器硬件特性提供定制化指导。 …...

Unity游戏实时翻译工程化实践:从XUnity.AutoTranslator配置到本地化流水线构建
1. 这不是“加个插件就完事”的翻译方案,而是游戏本地化工程的起点你刚在Unity Asset Store里搜到XUnity.AutoTranslator,点开文档看到“支持实时翻译”“自动注入UI文本”,心里一热:终于能绕过繁琐的多语言资源表管理,…...

量子机器学习提升软件测试效率的混合优化框架
1. 量子机器学习如何革新软件测试效率在DevOps和敏捷开发成为主流的今天,软件测试面临着前所未有的挑战。传统测试方法在应对现代复杂系统时显得力不从心——根据行业调研,大型系统中测试环节消耗的开发资源高达40-50%。更棘手的是,随着微服务…...
)
保姆级教程:手把手教你用NVIDIA Surround搞定Prepar3D多屏显示(Win10/Win11通用)
沉浸式飞行体验:NVIDIA Surround多屏配置全攻略 飞行模拟爱好者追求的不仅是操作的真实感,更是视觉上的沉浸体验。当你在驾驶舱内环顾四周,透过虚拟舷窗看到连贯的地平线时,那种身临其境的感觉是单屏无法比拟的。本文将带你从零开…...